
Abstract
In this study, both theoretical results and numerical methods are derived for solving different classes of systems of nonlinear matrix equations involving Lipshitzian mappings.
2000 Mathematics Subject Classifications: 15A24; 65H05.
Similar content being viewed by others

1 Introduction
Fixed point theory is a very attractive subject, which has recently drawn much attention from the communities of physics, engineering, mathematics, etc. The Banach contraction principle [1] is one of the most important theorems in fixed point theory. It has applications in many diverse areas.
Definition 1.1 Let M be a nonempty set and f: M → M be a given mapping. We say that x* ∈ M is a fixed point of f if fx* = x*.
Theorem 1.1 (Banach contraction principle [1]). Let (M, d) be a complete metric space and f: M → M be a contractive mapping, i.e., there exists λ ∈ [0, 1) such that for all x, y ∈ M,
Then the mapping f has a unique fixed point x* ∈ M. Moreover, for every x0 ∈ M, the sequence (x k ) defined by: xk+1= fx k for all k = 0, 1, 2, ... converges to x*, and the error estimate is given by:
Many generalizations of Banach contraction principle exists in the literature. For more details, we refer the reader to [2–4].
To apply the Banach fixed point theorem, the choice of the metric plays a crucial role. In this study, we use the Thompson metric introduced by Thompson [5] for the study of solutions to systems of nonlinear matrix equations involving contractive mappings.
We first review the Thompson metric on the open convex cone P(n) (n ≥ 2), the set of all n×n Hermitian positive definite matrices. We endow P(n) with the Thompson metric defined by:
where M(A/B) = inf{λ > 0: A ≤ λB} = λ+(B-1/2AB-1/2), the maximal eigenvalue of B-1/2AB-1/2. Here, X ≤ Y means that Y - X is positive semidefinite and X < Y means that Y - X is positive definite. Thompson [5] (cf. [6, 7]) has proved that P(n) is a complete metric space with respect to the Thompson metric d and d(A, B) = ||log(A-1/2BA-1/2)||, where ||·|| stands for the spectral norm. The Thompson metric exists on any open normal convex cones of real Banach spaces [5, 6]; in particular, the open convex cone of positive definite operators of a Hilbert space. It is invariant under the matrix inversion and congruence transformations, that is,
for any nonsingular matrix M. The other useful result is the nonpositive curvature property of the Thompson metric, that is,
By the invariant properties of the metric, we then have
for any X, Y ∈ P(n) and nonsingular matrix M.
Lemma 1.1 (see [8]). For all A, B, C, D ∈ P(n), we have
In particular,
2 Main result
In the last few years, there has been a constantly increasing interest in developing the theory and numerical approaches for HPD (Hermitian positive definite) solutions to different classes of nonlinear matrix equations (see [8–21]). In this study, we consider the following problem: Find (X1, X2, ..., X m ) ∈ (P(n)) m solution to the following system of nonlinear matrix equations:
where r i ≥ 1, 0 < |α ij | ≤ 1, Q i ≥ 0, A i are nonsingular matrices, and F ij : P(n) → P (n) are Lipshitzian mappings, that is,
If m = 1 and α11 = 1, then (5) reduces to find X ∈ P(n) solution to Xr = Q + A*F(X)A. Such problem was studied by Liao et al. [15]. Now, we introduce the following definition.
Definition 2.1 We say that Problem (5) is Banach admissible if the following hypothesis is satisfied:
Our main result is the following.
Theorem 2.1 If Problem (5) is Banach admissible, then it has one and only one solution. Moreover, for any (X1(0), X2(0), ..., X m (0)) ∈ (P(n)) m, the sequences (X i (k))k≥0, 1 ≤ i ≤ m, defined by:
converge respectively to, and the error estimation is
where
Proof. Define the mapping G: (P(n)) m → (P(n)) m by:
for all X = (X1, X2, ..., X m ) ∈ (P(n)) m , where
for all i = 1, 2, ..., m. We endow (P(n)) m with the metric d m defined by:
for all X = (X1, X2, ..., X m ), Y = (Y1, Y2, ..., Y m ) ∈ (P (n)) m . Obviously, ((P(n)) m , d m ) is a complete metric space.
We claim that
For all X, Y ∈ (P(n)) m , We have
On the other hand, using the properties of the Thompson metric (see Section 1), for all i = 1, 2, ..., m, we have
Thus, we proved that for all i = 1, 2, ..., m, we have
Now, (9) holds immediately from (10) and (11). Applying the Banach contraction principle (see Theorem 1.1) to the mapping G, we get the desired result. □
3 Examples and numerical results
3.1 The matrix equation:
We consider the problem: Find X ∈ P(n) solution to
where B i ≥ 0 for all i = 1, 2, 3.
Problem (12) is equivalent to: Find X1 ∈ P (n) solution to
where r1 = 2, Q1 = B3, A1 = I n (the identity matrix), α11 = 1/3 and F11 : P(n) → P (n) is given by:
Proposition 3.1 F11is a Lipshitzian mapping with k11 ≤ 1/4.
Proof. Using the properties of the Thompson metric, for all X, Y ∈ P(n), we have
Thus, we have k11 ≤ 1/4. □
Proposition 3.2 Problem (13) is Banach admissible.
Proof. We have
This implies that Problem (13) is Banach admissible. □
Theorem 3.1 Problem (13) has one and only one solution. Moreover, for any X1(0) ∈ P(n), the sequence (X1(k))k≥0defined by:
converges to, and the error estimation is
where q1 = 1/4.
Proof. Follows from Propositions 3.1, 3.2 and Theorem 2.1. □
Now, we give a numerical example to illustrate our result given by Theorem 3.1.
We consider the 5 × 5 positive matrices B1, B2, and B3 given by:
and
We use the iterative algorithm (14) to solve (12) for different values of X1(0):
and
For X1(0) = M1, after 9 iterations, we get the unique positive definite solution
and its residual error
For X1(0) = M2, after 9 iterations, the residual error
For X1(0) = M3, after 9 iterations, the residual error
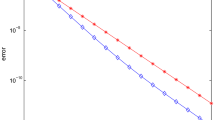
The convergence history of the algorithm for different values of X1(0) is given by Figure 1, where c1 corresponds to X1(0) = M1, c2 corresponds to X1(0) = M2, and c3 corresponds to X1(0) = M3.

Convergence history for Eq. (12).
3.2 System of three nonlinear matrix equations
We consider the problem: Find (X1, X2, X3) ∈ (P(n))3 solution to
where A i are n × n singular matrices.
Problem (16) is equivalent to: Find (X1, X2, X3) ∈ (P(n))3 solution to
where r1 = r2 = r3 = 1, Q1 = Q2 = Q3 = I n and for all i, j ∈ {1, 2, 3}, α ij = 1,
Proposition 3.3 For all i, j ∈ {1, 2, 3}, F ij : P(n) → P(n) is a Lipshitzian mapping with k ij ≤ γ ij θ ij .
Proof. For all X, Y ∈ P(n), since θ ij , γ ij ∈ (0, 1), we have
Then, F ij is a Lipshitzian mapping with k ij ≤ γ ij θ ij . □
Proposition 3.4 Problem (17) is Banach admissible.
Proof. We have
This implies that Problem (17) is Banach admissible. □
Theorem 3.2 Problem (16) has one and only one solution. Moreover, for any (X1(0), X2(0), X3(0)) ∈ (P(n))3, the sequences (X i (k))k≥0, 1 ≤ i ≤ 3, defined by:
converge respectively to, and the error estimation is
where q3 = 1/6.
Proof. Follows from Propositions 3.3, 3.4 and Theorem 2.1. □
Now, we give a numerical example to illustrate our obtained result given by Theorem 3.2.
We consider the 3 × 3 positive matrices B1, B2 and B3 given by:
We consider the 3 × 3 nonsingular matrices A1, A2 and A3 given by:
and
We use the iterative algorithm (18) to solve Problem (16) for different values of (X1(0), X2(0), X3(0)):
and
The error at the iteration k is given by:
For X1(0) = X2(0) = X3(0) = M1, after 15 iterations, we obtain
and
The residual error is given by:
For X1(0) = X2(0) = X3(0) = M2, after 15 iterations, the residual error is given by:
For X1(0) = X2(0) = X3(0) = M3, after 15 iterations, the residual error is given by:
The convergence history of the algorithm for different values of X1(0), X2(0), and X3(0) is given by Figure 2, where c1 corresponds to X1(0) = X2(0) = X3(0) = M1, c2 corresponds to X1(0) = X2(0) = X3(0) = M2 and c3 corresponds to X1(0) = X2(0) = X3(0) = M3.

Convergence history for Sys. (16).
References
Banach S: Sur les opérations dans les ensembles abstraits et leur application aux équations intégrales. Fund Math 1922, 3: 133–181.
Agarwal R, Meehan M, O'Regan D: Fixed Point Theory and Applications. Cambridge Tracts in Mathematics, Cambridge University Press, Cambridge, UK 2001., 141:
Ćirić L: A generalization of Banach's contraction principle. Proc Am Math Soc 2,45(2):273–273.
Kirk W, Sims B: Handbook of Metric Fixed Point Theory. Kluwer, Dordrecht; 2001.
Thompson A: On certain contraction mappings in a partially ordered vector space. Proc Am Math Soc 1963, 14: 438–443.
Nussbaum R: Hilbert's projective metric and iterated nonlinear maps. Mem Amer Math Soc 1988,75(391):1–137.
Nussbaum R: Finsler structures for the part metric and Hilbert' projective metric and applications to ordinary differential equations. Differ Integral Equ 1994, 7: 1649–1707.
Lim Y:Solving the nonlinear matrix equation via a contraction principle. Linear Algebra Appl 2009, 430: 1380–1383. 10.1016/j.laa.2008.10.034
Duan X, Liao A:On Hermitian positive definite solution of the matrix equation . J Comput Appl Math 2009, 229: 27–36. 10.1016/j.cam.2008.10.018
Duan X, Liao A, Tang B:On the nonlinear matrix equation . Linear Algebra Appl 2008, 429: 110–121. 10.1016/j.laa.2008.02.014
Duan X, Peng Z, Duan F: Positive defined solution of two kinds of nonlinear matrix equations. Surv Math Appl 2009, 4: 179–190.
Hasanov V: Positive definite solutions of the matrix equations X ± A * X-qA = Q . Linear Algebra Appl 2005, 404: 166–182.
Ivanov I, Hasanov V, Uhilg F: Improved methods and starting values to solve the matrix equations X ± A * X-1A = I iteratively. Math Comput 2004, 74: 263–278. 10.1090/S0025-5718-04-01636-9
Ivanov I, Minchev B, Hasanov V:Positive definite solutions of the equation . In Application of Mathematics in Engineering'24, Proceedings of the XXIV Summer School Sozopol'98 Edited by: Heron Press S. 1999, 113–116.
Liao A, Yao G, Duan X: Thompson metric method for solving a class of nonlinear matrix equation. Appl Math Comput 2010, 216: 1831–1836. 10.1016/j.amc.2009.12.022
Liu X, Gao H: On the positive definite solutions of the matrix equations Xs ± ATX- tA = I n . Linear Algebra Appl 2003, 368: 83–97.
Ran A, Reurings M, Rodman A: A perturbation analysis for nonlinear selfadjoint operators. SIAM J Matrix Anal Appl 2006, 28: 89–104. 10.1137/05062873
Shi X, Liu F, Umoh H, Gibson F: Two kinds of nonlinear matrix equations and their corresponding matrix sequences. Linear Multilinear Algebra 2004, 52: 1–15. 10.1080/0308108031000112606
Zhan X, Xie J: On the matrix equation X + ATX-1A = I . Linear Algebra Appl 1996, 247: 337–345.
Dehgham M, Hajarian M: An efficient algorithm for solving general coupled matrix equations and its application. Math Comput Modeling 2010, 51: 1118–1134. 10.1016/j.mcm.2009.12.022
Zhoua B, Duana G, Li Z: Gradient based iterative algorithm for solving coupled matrix equations. Syst Control Lett 2009, 58: 327–333. 10.1016/j.sysconle.2008.12.004
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
All authors contributed equally and significantly in writing this paper. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Berzig, M., Samet, B. Solving systems of nonlinear matrix equations involving Lipshitzian mappings. Fixed Point Theory Appl 2011, 89 (2011). https://doi.org/10.1186/1687-1812-2011-89
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1687-1812-2011-89