
Abstract
Background
Blindness due to diabetic retinopathy (DR) is the major disability in diabetic patients. Although early management has shown to prevent vision loss, diabetic patients have a low rate of routine ophthalmologic examination. Hence, we developed and validated sparse learning models with the aim of identifying the risk of DR in diabetic patients.
Methods
Health records from the Korea National Health and Nutrition Examination Surveys (KNHANES) V-1 were used. The prediction models for DR were constructed using data from 327 diabetic patients, and were validated internally on 163 patients in the KNHANES V-1. External validation was performed using 562 diabetic patients in the KNHANES V-2. The learning models, including ridge, elastic net, and LASSO, were compared to the traditional indicators of DR.
Results
Considering the Bayesian information criterion, LASSO predicted DR most efficiently. In the internal and external validation, LASSO was significantly superior to the traditional indicators by calculating the area under the curve (AUC) of the receiver operating characteristic. LASSO showed an AUC of 0.81 and an accuracy of 73.6% in the internal validation, and an AUC of 0.82 and an accuracy of 75.2% in the external validation.
Conclusion
The sparse learning model using LASSO was effective in analyzing the epidemiological underlying patterns of DR. This is the first study to develop a machine learning model to predict DR risk using health records. LASSO can be an excellent choice when both discriminative power and variable selection are important in the analysis of high-dimensional electronic health records.
Similar content being viewed by others

Background
A major goal of diabetic medicine is to accurately predict diabetic complications and to prevent their progression [1]. Diabetic retinopathy (DR) is the most common ocular complication of diabetes. Blindness due to retinopathy is the major disability in patients with diabetes [2]. DR is common in diabetic patients but is asymptomatic until a significant visual impairment occurs. Late diagnosis of DR results in the socio-economic burden of illness associated with diabetes [3]. Several studies have shown that early ophthalmologic examination is important in screening, diagnosing, and monitoring DR [2–4]. Early appropriate management methods such as diabetic drugs, blood pressure control, and laser photocoagulation have proven to prevent vision loss and blindness [5]. However, only a third of diabetic patients in Korea have received routine ophthalmologic examination in recent years [6]. In the U.S., approximately a half of diabetic patients do not receive any kind of examination for detecting DR although the American Diabetes Association has recommended an annual fundus examination by an ophthalmologist [7]. Therefore, clinicians face a significant challenge in identifying patients who are at a high risk of DR in a timely and appropriate manner.
DR results from diabetes-induced damage to microvascular cells. The incidence of DR is closely related to the control of serum glucose level, while other metabolic disorders also contribute to the progression of DR [2]. Recent findings suggest that an early detection of DR can be assisted by the knowledge of several biomarkers. The traditional indicators of DR included serum glucose, HbA1c (glycated hemoglobin), duration of diabetes, blood pressure, and lipid levels [8, 9]. The optimal cut-off points of the traditional indicators for DR prediction have been calculated on the basis of several population-based studies [8, 10]. These studies have shown that HbA1c is a more reliable predictor of DR than other traditional indicators. Other methods have been based on a combination of risk factors of DR using classical statistical methods [11, 12]. However, these risk prediction methods for DR were inefficient owing to their poor prediction performance. Moreover, although these studies considered classical risk factors, they did not select important informative variables that could really contribute to DR.
Since a number of studies have shown that the pathogenesis of DR is complex and multi-factorial, understanding the whole biomarker patterns of diabetic patients will facilitate the identification of the risk of DR. However, ordinary regression shows over-fitting and instability of coefficients when a number of inter-correlated biomarkers are used [13]. Stepwise variable selection, including forward and backward stepwise selection, do not show suitability to predict disease with good discriminative ability in high-dimensional data [14]. Recently, in the field of bioinformatics, sparse learning has emerged as a tool for analyzing large-scale biomarker patterns [15, 16]. Sparse learning is an area of machine learning research which can be used to find a small number of important predictors to achieve optimal prediction accuracy. Sparse learning techniques, such as least absolute shrinkage and selection operator (LASSO) and elastic net, have been widely applied to the analysis of genetic, genomic, and proteomic data [16]. When the number of variables is large or when variables are highly correlated, these techniques can offer a better regression solution than classical regression methods and other machine learning methods such as support vector machine (SVM) [15]. Due to its abilities to select important features and to detect relationships between biomarkers and diseases, sparse learning has been successfully used in medical decision support systems [16–18].
In this study, we developed and validated sparse learning models with the aim of identifying the risk of DR in diabetic patients. The objective of this study was to select diabetic patients who should receive fundus examination by an ophthalmologist in order to increase the effectiveness of screening for DR. The sparse learning techniques identified the important biomarkers to have a real effect on prediction models of DR. We compared the performance of sparse learning techniques and traditional clinical biomarkers, including HbA1c, fasting plasma glucose (FPG), and duration of diabetes.
Methods
Data sources
This cross-sectional study investigated prediction models for the incidence of DR. All analyses were based on the Korean National Health and Nutrition Examination Survey (KNHANES, online at http://knhanes.cdc.go.kr/). The study protocol was approved by the institutional review board at the Korea Centers for Disease Control and Prevention (IRB No: 2010-02CON-21-C, 2011-02CON-06-C). We collected health records from Korean diabetic patients based on the KNHANES V conducted in 2010 and 2011. The KNHANES V is a nationwide and population-based cross-sectional survey that was conducted by the Division of Chronic Disease Surveillance, Korea Centers for Disease Control and Prevention [19]. KNHANES consists of health records based on a health interview, a health examination, and a nutrition survey. Each participant was interviewed and asked to complete a questionnaire on his or her alcohol consumption, smoking status, diabetes mellitus, hypertension, and physical activity level. The level of physical activity was calculated using the metabolic equivalent of task values based on self-reported frequency and duration of activities during the week [20]. Height, weight, and waist circumference were measured, and the body mass index (BMI) was calculated. Measurements of HbA1c, FPG, liver enzymes, serum lipid and lipoprotein, blood urea nitrogen (BUN), and serum creatinine level were taken in local community health centers. Blood pressure (BP) was also measured by health professionals. Urinary protein, glucose, ketone, bilirubin, blood, and urobilinogen were measured by dipstick test, and urinary creatinine and sodium were measured with a chemistry analyzer. In order to assess the retinopathy status, fundus examination was done by two trained ophthalmologists according to the Early Treatment for Diabetic Retinopathy Study [21, 22].
The input variables of the prediction models were collected from demographic data, medical history, blood pressure, blood test, and urine test. The primary outcome variable was the presence of DR diagnosed by fundus examination. Data from the KNHANES V-1, conducted in 2010, was used to develop risk prediction models (Figure 1). Among 8958 participants who participated in the KNHANES V-1, 556 were diabetic patients who satisfied the diagnostic criteria of glucose level and HbA1c defined by the American Diabetes Association [23]. Diabetes was diagnosed in participants with FPG ≥ 126 mg/dL, non-fasting glucose ≥ 200 mg/dL or HbA1c ≥ 6.5%. We excluded participants who did not receive eye examination. Finally, 490 participants were included in this study, and the data from them were used as a development dataset. The development dataset was separated randomly into training and internal validation sets. The training set, comprised of two thirds (327 patients) of the entire dataset, was used to construct prediction models. The internal validation set, comprised of one third (164 patients) of the dataset, was used to assess the ability to predict DR in diabetic patients.

Dataset used in the development and validation of diabetic retinopathy risk prediction. This flowchart shows the process of training, internal validation, external validation, and validation in the newly-diagnosed diabetic patients. KNHANES, Korean National Health and Nutrition Examination Survey; LASSO, least absolute shrinkage and selection operator; LR-BS, logistic regression with backward stepwise selection; OLR, ordinary logistic regression; ROC, receiver operating characteristic.
In order to obtain an unbiased prediction performance, the prediction models should be validated in external data. Therefore, performance of the prediction model was evaluated in independent data collected from the KNHANES V-2, conducted in 2011. Since the participants were re-selected using random sampling, the KNHANES V-2 was comprised of different participants from the KNANES V-1. Data from the KNHANES V-2 also followed the same inclusion and exclusion criteria, and 562 participants were included in the external validation dataset.
It is important to identify the patients with diabetic complications among the first-visit patients with undiagnosed diabetes, especially for clinicians [24]. Therefore, we also evaluated the discriminative ability to predict DR in newly-diagnosed diabetic patients (participants with undiagnosed diabetes). The prediction models were also validated among 144 participants (32 participants from the internal validation dataset and 112 from the external validation dataset) with undiagnosed diabetes.
Sparse learning techniques
The form of logistic regression was used for all prediction models due to dichotomous clinical outcome. It is given as,
Where ‘p’ is the probability of the disease, β0 is the constant and βi is the coefficient of a specific predictor Xi. This calculation of logit operator is equivalently:
and the likelihood L is
where ‘Y’ is the presence of the disease encoded as a binary categorical variable. In ordinary logistic regression (OLR), maximum likelihood estimation is used to solve for the best fitting model.
In this setting, we consider the use of penalized logistic regression methods to select predictors and to predict DR in high-dimensional clinical information data. Penalized regression methods including ridge, elastic net, and LASSO have been widely used as sparse learning tools in bioinformatics [13]. Ridge is a continuous process that shrinks coefficients and improves the prediction performance of ordinary regression [25]. However, ridge solves a fitting problem with non-zero coefficients and does not offer an easily interpretable regression model. Recently, LASSO has emerged as the most well-known sparse learning technique [26]. LASSO leads to a sparse solution of coefficients corresponding to the most important predictors, and has been known to show better performance for the prediction model selection and better identification of predictors than classical regression methods [18]. Elastic net is a generalized extension of ridge and LASSO with a mixture of ridge and LASSO penalties in likelihood function [27]. These penalized regression methods provide the stability and uniqueness of regression coefficients. In the penalized logistic regression, the general objective function for maximum likelihood estimation can be written as
where the penalty component f(β) is a function of the regression coefficients and λ is the sparseness control parameter. In this study, we used the Glmnet software [27, 28]. In this software, the objective function of the penalized logistic regression is
Where and are the penalty functions of ridge and LASSO, respectively. The mixing parameter α determines the strength of the penalty components of ridge and LASSO. When α = 0, this problem is equivalent to ridge regression. If 0 < α < 1, this formulation is used to solve the regression problem inelastic net. We implemented elastic net with α = 0.4 according to a previous study which included the penalized logistic regression [28]. When α = 1, this problem is equivalent to LASSO. We obtained the optimized solutions of each penalized logistic regression using Glmnet.
In all penalized regression methods, it is necessary to determine the sparseness control parameter λ. In the training dataset, we designed the 5-fold cross validation not only to assess performance, but also to optimize λ. The area under the curve (AUC) of the receiver operating characteristic (ROC) is known as a strong predictor of performance, especially with regard to imbalanced problems. Due to the imbalanced data in this study, prediction accuracy might not be a good criterion for assessing performance since the minor class has less influence on accuracy than the major class. Therefore, we investigated the AUC during the 5-fold cross validation as λ increased. The λ that indicated the highest AUC was chosen for the final training condition.
The relative importance of predictors was estimated by standardized regression coefficients of sparse learning. Standardized regression coefficients were calculated using standardized input variables, and facilitated the interpretation and comparison of the relative importance of predictors [29]. A predictor is more important to predict DR if it has a larger standardized regression coefficients.
In order to compare the performance of the sparse learning techniques, classical regression method including OLR and logistic regression with backward stepwise selection (LR-BS) were also constructed using the same training dataset.
Model selection and validation
We constructed five prediction models including OLR, LR-BS (with a significance of 0.1 to remove the non-significant variables), ridge, elastic net, and LASSO. After training process with the whole training dataset, in order to select the best prediction model, we evaluated diagnostic abilities based on the Bayesian information criterion (BIC) in the internal validation dataset. BIC is widely used in model selection and an effective indicator to compare the prediction performance when different numbers of covariates or predictors are included in the prediction models [30]. BIC penalizes the number of variables to avoid an unstable or over-fitting model [31]. In our study, BIC can be written as:
where ‘L’ is likelihood of the prediction model in internal validation dataset, ‘k’ is the number of predictors, and ‘n’ is the number of samples of internal validation dataset. The best model is the one that gives the lowest BIC value, which means the largest marginal likelihood of data. We finally tested the selected prediction models on the internal and external validation groups using ROC analysis.
Three different clinical scenarios were developed in this study. Scenario 1 was based on the clinical variables, except the laboratory measurements. The variables obtained from the anthropometric measurements, medical history, and blood pressures were entered in the scenario. In this scenario, invasive procedure for blood sampling is not required. Therefore, the prediction models were designed for use in simple setting to predict an individual's risk using clinical variables that can be self-assessed or easily identified by the public health center. Scenario 2 was developed by adding the result of blood test to scenario 1. Since diabetes mellitus is generally diagnosed by plasma glucose level or HbA1c from blood test, this scenario was done to evaluate the effect of general clinical information obtained from clinicians’ practice. Scenario 3 was developed by adding the result of urine test to scenario 2. When the patient visits to the clinic for diabetes, urine test is routinely performed to detect diabetic nephropathy. We evaluated the additional effect of clinical information from the urine test in this scenario.
The final prediction models were validated in two populations: the KNHANES V-1 (internal validation group) and the KNHANES V-2 (external validation group). The AUC, accuracy, sensitivity, and specificity of the sparse learning models and the traditional clinical biomarkers were calculated in ROC analysis. We generated the ROC curves and selected cut-off points that maximized Youden's index [32]. Participants above the cut-off points were classified as being at high risk in each prediction model. We used SPSS 18.0 (SPSS Inc., Chicago, IL) for statistical analysis and MedCalc 12.3 (MedCalc, Mariakerke, Belgium) for ROC analysis.
Results
The background characteristics of the development dataset (KNHANES V-1) are presented in Table 1. Eighty-four (17.1%) of 490 diabetic patients had DR. By comparison with the patients in the control group, diabetic patients in the development dataset were of significantly higher duration of diabetes, HbA1c, and FPG, and were of significantly lower BMI, diastolic BP, hemoglobin, and urine sodium level. Diabetic patients were more likely to have proteinuria, glycosuria, and diabetic histories including diagnosed diabetes, insulin therapy, anti-diabetic drug, and nondrug anti-diabetic therapy.
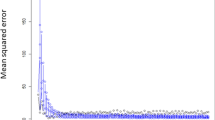
Figure 2 shows the AUC of the penalized logistic regression models using the 5-fold cross validation as λ is varied. We found that the optimal values of λ were different in the different clinical scenarios. When the optimal values of λ were applied for training the penalized logistic regression including ridge, elastic net, and LASSO, the resulting coefficients models that we obtained are given in Additional file 1. The coefficients of OLR and LR-BS were also calculated. While OLR and ridge utilized all variables, LR-BS showed the smallest number of predictors among the five prediction methods–10, 12, and 16 predictors in scenarios 1, 2, and 3, respectively. The most popular sparse learning technique, that is, LASSO, selected 12, 14, and 19 variables as important predictors in scenarios 1, 2, and 3, respectively. Table 2 shows the standardized coefficients of the final LASSO prediction model. In scenario 1, duration of diabetes was the most important predictor. In scenarios 2 and 3, which included the results of blood test, FPG was the most important predictor.

Performance (AUC) of the penalized logistic regression models using the 5-fold cross validation. The penalized logistic regression models included ridge (A), elastic net (B), and LASSO (C). In order to optimize λ, we investigated the AUC during the 5-fold cross validation as λ increased. The λ that indicated the highest AUC was chosen for the final training condition.
To assess the ability of the models for predicting DR, we applied our methods to a testing set composed of the independent data from the training set. Figure 3 describes the performance comparison of the prediction models in the internal validation group. We found that the penalized logistic regression methods showed better discriminative ability than OLR and LR-BS. Ridge had the smallest root mean square error and the highest Spearman's correlation value. When we investigated BIC to consider the effectiveness of the prediction models, LASSO showed a lower value of BIC than other methods. In other words, the LASSO model predicted DR most efficiently. Application of the BIC criteria to DR prediction resulted in a final LASSO model of fewer independent predictors with only a small loss in discrimination than ridge and elastic net.

Performance comparison of the prediction models in the internal validation group. BP, blood pressure; BT, blood test; DE, demographics; LASSO, least absolute shrinkage and selection operator; LR-BS, logistic regression with backward stepwise selection; MH, medical history; OLR, ordinary logistic regression; RMS, root mean square; UT, urine test.
Additionally, we analyzed ROC curves of our methods in the internal and external validation datasets. Because LASSO and LR-BS had the lowest BIC among the penalized regression methods and classical methods, respectively, we compared their ROC curves. The traditional clinical biomarkers, including HbA1c, FPG, and duration of diabetes, were also included for comparison with LASSO and LR-BS developed in scenario 3. As a result, the LASSO model was the best discriminator between the control diabetic patients and the patients with DR (Figure 4). In the internal validation dataset, the LASSO model yielded an AUC of 0.81, accuracy of 73.6%, sensitivity of 77.4%, and specificity of 72.7%. Consistent results were observed in the external validation dataset. The LASSO predicted DR with an AUC of 0.82, accuracy of 75.2%, sensitivity of 72.1%, and specificity of 76.0% in the external validation. Considering AUC as a performance metric, the LASSO was significantly superior to the HbA1c, FPG, and duration of diabetes in both the internal and external validation (Table 3). The ROC analysis results of the LASSO models in scenarios 1 and 2 are shown in Additional file 2.

ROC curves for diabetic retinopathy prediction. The prediction models were tested in the internal (A) and external (B) validation groups. The LASSO and LR-BS models were trained in scenario 3. FPG, fasting plasma glucose; HbA1c, glycated hemoglobin; LASSO, least absolute shrinkage and selection operator; LR- BS, logistic regression with backward stepwise selection.
The LASSO and LR-BS prediction models were also validated among 144 participants who had undiagnosed diabetes (Table 4). Although the newly-diagnosed diabetic patients had the same value of zero-duration of diabetes, the prediction models showed a similar performance to the results in Table 3. The LASSO predicted DR with an AUC of 0.90, accuracy of 89.2%, sensitivity of 75.0%, and specificity of 89.6% in the newly-diagnosed diabetic patients. Based on these findings, if we assume that 1,000 first-visit participants with undiagnosed diabetes will be examined by the LASSO model, then, 196 cases of diabetic patients would be accurately identified as having retinopathy or non-retinopathy when compared to HbA1c that is the most reliable traditional marker.
To show the effectiveness of the proposed method in predicting DR, we also implemented several commonly used algorithms from the literature [33, 34]. Five algorithms, including SVM, artificial neural network (ANN), Random forest, Naïve Bayes classifier, and k-Nearest Neighbors, were tested on the same validation dataset (Table 5). Among these algorithms, the best prediction was provided by SVM in both the internal and external validation dataset. LASSO showed a similar but slightly lower AUC value than SVM in the internal validation dataset. In the external validation dataset, LASSO outperformed the other algorithms. We found no statistically significant difference in the AUC between LASSO and SVM (p = 0.304 and 0.684 in the internal and external validation dataset, respectively).
Discussion
In this study, we introduced a bioinformatics-inspired method using sparse learning techniques in order to predict DR risk among diabetic patients. Our proposed LASSO model was designed for use in the self-assessment setting (scenario 1) and in the clinical setting with better prediction of DR (scenarios 2 and 3). Consistent results were observed when we applied the prediction model to the newly-diagnosed diabetic patients. We expect that the clinical information recorded in the electronic health records can be easily used by our proposed method for identifying diabetic populations who are at a high risk of DR. To our knowledge, this is the first study to develop a sparse learning model for DR risk prediction using population-based health records. No prior report has investigated the ability of machine learning to predict DR risk in a clinical manner.
The LASSO, the most well-known sparse learning technique, predicted DR most efficiently. ROC analysis supported that the LASSO model had a statistically significant improvement in predicting DR. This finding is consistent with previous studies on the comparison of sparse learning and conventional methods in various complex discriminating problems for predicting disease with genetic data [17, 35]. The strengths of our proposed sparse learning method are feature selection, good prediction performance, and easily interpretable results. Several studies have earlier pointed out that SVM and ANN can be considered an incomprehensible black-box due to its complexity [36, 37]. Whereas, the LASSO model is composed of easily interpretable regression coefficients that can provide an insight into risk factors of DR. In our study, LASSO offered a prediction model with important predictor selection as well as a similar performance to SVM, which has shown to perform well in multiple research areas lately [15]. Therefore, LASSO can be an excellent choice when both discriminative power and variable selection are important in a high-dimensional clinical problem [38].
The need for fundus examination at the time of diagnosis of diabetes has been confirmed [2, 39]. However, several reports have revealed that many patients neglect ophthalmologic examination due to asymptomatic eye status in the early stage and poor access to ophthalmologic care, and that the rate of referrals from primary care physicians to ophthalmologists is low [6, 40]. We expect that our method will be especially useful in the population with poor access to ophthalmologic care. Most experts predicted DR risk using level of HbA1c or FPG [8]. However, our study has shown the poor performance of HbA1c and FPG in predicting DR. Our proposed sparse learning method has shown significantly better performance than HbA1c and FPG. If the LASSO prediction model retains good performance after validation in a larger population, it will be possible to use this technique to determine candidates for evaluation with fundus examination and also to prevent visual impairment due to progression of DR.
In this study, when all clinical data were available, in the LASSO model, the presence of DR was associated with the 19 predictors. LASSO algorithm identified FPG, triglyceride (TG), low BMI, and insulin therapy as strong predictors (absolute standardized regression coefficient > 0.2). In general, smoking, anemia (low level of hemoglobin), high level of HbA1c, FPG, and TG were shown as the common modifiable risk factors of DR in previous studies [8, 41]. The young age of the diabetic patients was also an important predictor. Several studies have shown that diagnosis of diabetes at a young age is closely related to long duration of diabetes and DR [42, 43]. Long duration of diabetes may affect the severity of diabetes that is associated with weight loss (low BMI) and history of insulin therapy [44, 45]. Since diabetic nephropathy is also caused by microvascular damage, the biomarkers of kidney dysfunction, including elevated BUN and urine dipstick test positive, are closely related to DR [24, 46, 47]. We found that low diastolic blood pressure was a better predictor of DR in contrast with several previous studies [2]. There is a theoretical basis for assuming that pulse pressure (systolic pressure-diastolic pressure) has stronger effect on microvascular cell damage than simple hypertension [9]. Therefore, it is possible that diabetic complications could be affected by low diastolic pressure. Alcohol consumption was also an unexpected factor. Recent studies have proposed that moderate alcohol consumption may prevent cardiovascular complications in diabetic patients [48]. However, more research is needed to reveal the relationship between alcohol consumption and DR.
There are several limitations to this study. First, the study was based on a cross-sectional survey that had several defects due to medical views. For example, BMI, physical activity status, FPG, and blood pressure could differ according to the time of measurement. Secondly, we did not distinguish between type 1 and type 2 diabetes mellitus. According to an epidemiologic study, in Korea, the incidence of type 1 diabetes mellitus is 0.6 per 100,000 which is very small number, while the incidence of type 2 is 8,290 per 100,000 [6, 49]. Therefore, we assumed that all patients had type 2 diabetes mellitus. However, we cannot exclude the possibility that our findings were influenced by type 1 diabetic patients. Third, this is an Asian-specific study performed at the level of a single country. Generally, the incidence and progression of diabetes are influenced by ethnic differences and genetic backgrounds [43, 50]. Thus, it is uncertain whether the results will be equally applicable to the general clinical practice.
Conclusion
In summary, this study leads to the conclusion that sparse learning techniques using LASSO can contribute to the advancement of clinical decision-making tools with a good discriminative ability and to our understanding of risk factors for DR. This study supports that LASSO can be an effective prediction model not only in a bioinformatics problem, but also in the analysis of high-dimensional electronic health records. We hope that this study helps diabetic patients to reduce the risk of DR, which is the major cause of blindness in such patients.
References
Golubnitschaja O: Advanced diabetes care: three levels of prediction, prevention personalized treatment. Curr Diabetes Rev. 2010, 6: 42-51. 10.2174/157339910790442637.
Cheung N, Mitchell P, Wong TY: Diabetic retinopathy. Lancet. 2010, 376: 124-136. 10.1016/S0140-6736(09)62124-3.
Zhang X, Saaddine JB, Chou C-F, Cotch MF, Cheng YJ, Geiss LS, Gregg EW, Albright AL, Klein BEK, Klein R: Prevalence of diabetic retinopathy in the United States, 2005–2008. JAMA. 2010, 304: 649-656. 10.1001/jama.2010.1111.
Askew DA, Crossland L, Ware RS, Begg S, Cranstoun P, Mitchell P, Jackson CL: Diabetic retinopathy screening and monitoring of early stage disease in general practice: design and methods. Contemp Clin Trials. 2012, 33: 969-975. 10.1016/j.cct.2012.04.011.
Mohamed Q, Gillies MC, Wong TY: Management of diabetic retinopathy: a systematic review. JAMA. 2007, 298: 902-916. 10.1001/jama.298.8.902.
Shin KH, Chi MJ: Fundus examination rate in diabetics and the public health factors associated with fundus examination rate. J Korean Ophthalmol Soc. 2009, 50: 1319-10.3341/jkos.2009.50.9.1319.
Abràmoff MD, Niemeijer M, Suttorp-Schulten MSA, Viergever MA, Russell SR, van Ginneken B: Evaluation of a system for automatic detection of diabetic retinopathy from color fundus photographs in a large population of patients with diabetes. Diabetes Care. 2008, 31: 193-198.
Cho NH, Kim TH, Woo SJ, Park KH, Lim S, Cho YM, Park KS, Jang HC, Choi SH: Optimal HbA1c cutoff for detecting diabetic retinopathy. Acta Diabetol. 2013, doi:10.1007/s00592-013-0452-3
Knudsen ST, Poulsen PL, Hansen KW, Ebbehøj E, Bek T, Mogensen CE: Pulse pressure and diurnal blood pressure variation: association with micro- and macrovascular complications in type 2 diabetes. Am J Hypertens. 2002, 15: 244-250. 10.1016/S0895-7061(01)02281-6.
Colagiuri S, Lee CMY, Wong TY, Balkau B, Shaw JE, Borch-Johnsen K: Glycemic thresholds for diabetes-specific retinopathy: implications for diagnostic criteria for diabetes. Diabetes Care. 2011, 34: 145-150. 10.2337/dc10-1206.
Hosseini SM, Maracy MR, Amini M, Baradaran HR: A risk score development for diabetic retinopathy screening in Isfahan-Iran. J Res Med Sci Off J Isfahan Univ Med Sci. 2009, 14: 105-110.
Aspelund T, Thornórisdóttir O, Olafsdottir E, Gudmundsdottir A, Einarsdóttir AB, Mehlsen J, Einarsson S, Pálsson O, Einarsson G, Bek T, Stefánsson E: Individual risk assessment and information technology to optimise screening frequency for diabetic retinopathy. Diabetologia. 2011, 54: 2525-2532. 10.1007/s00125-011-2257-7.
Waldron L, Pintilie M, Tsao M-S, Shepherd FA, Huttenhower C, Jurisica I: Optimized application of penalized regression methods to diverse genomic data. Bioinforma Oxf Engl. 2011, 27: 3399-3406. 10.1093/bioinformatics/btr591.
Yuan M, Lin Y: Model selection and estimation in regression with grouped variables. J R Stat Soc Ser B Stat Methodol. 2005, 68: 49-67.
Roth V: The generalized LASSO. IEEE Trans Neural Networks Publ IEEE Neural Networks Counc. 2004, 15: 16-28. 10.1109/TNN.2003.809398.
Cheng Q: A sparse learning machine for high-dimensional data with application to microarray gene analysis. IEEEACM Trans Comput Biol Bioinforma IEEE ACM. 2010, 7: 636-646.
Wang H, Nie F, Huang H, Kim S, Nho K, Risacher SL, Saykin AJ, Shen L: Identifying quantitative trait loci via group-sparse multitask regression and feature selection: an imaging genetics study of the ADNI cohort. Bioinforma Oxf Engl. 2012, 28: 229-237. 10.1093/bioinformatics/btr649.
Lee H, Lee DS, Kang H, Kim B-N, Chung MK: Sparse brain network recovery under compressed sensing. IEEE Trans Med Imaging. 2011, 30: 1154-1165.
Oh K, Lee J, Lee B, Kweon S, Lee Y, Kim Y: Plan and operation of the 4th Korea national health and nutrition examination survey (KNHANES IV). Korean J Epidemiol. 2007, 29: 139-145.
Ainsworth BE, Haskell WL, Whitt MC, Irwin ML, Swartz AM, Strath SJ, O’Brien WL, Bassett DR, Schmitz KH, Emplaincourt PO, Jacobs DR, Leon AS: Compendium of physical activities: an update of activity codes and MET intensities. Med Sci Sports Exerc. 2000, 32 (9 Suppl): S498-S504.
Early Treatment Diabetic Retinopathy Study Research Group: Grading diabetic retinopathy from stereoscopic color fundus photographs-an extension of the modified Airlie house classification. Ophthalmology. 1991, 98 (5 Suppl): 786-806.
Yoon K-C, Mun G-H, Kim S-D, Kim S-H, Kim CY, Park KH, Park YJ, Baek S-H, Song SJ, Shin JP, Yang S-W, Yu S-Y, Lee JS, Lim KH, Park H-J, Pyo E-Y, Yang J-E, Kim Y-T, Oh K-W, Kang SW: Prevalence of eye diseases in South Korea: data from the Korea national health and nutrition examination survey 2008–2009. Korean J Ophthalmol KJO. 2011, 25: 421-433. 10.3341/kjo.2011.25.6.421.
American Diabetes Association: Diagnosis and classification of diabetes mellitus. Diabetes Care. 2012, 35 (Suppl 1): S64-S71.
Esmatjes E, Castell C, Gonzalez T, Tresserras R, Lloveras G: Epidemiology of renal involvement in type II diabetics (NIDDM) in Catalonia. The Catalan diabetic nephropathy study group. Diabetes Res Clin Pract. 1996, 32: 157-163. 10.1016/0168-8227(96)01256-9.
Hoerl AE, Kennard RW: Ridge regression: biased estimation for Nonorthogonal problems. Technometrics. 1970, 12: 55-67. 10.1080/00401706.1970.10488634.
Tibshirani R: Regression shrinkage and selection via the lasso. J R Stat Soc Ser B Methodol. 1996, 58: 267-288.
Zou H, Hastie T: Regularization and variable selection via the elastic net. J R Stat Soc Ser B Stat Methodol. 2005, 67: 301-320. 10.1111/j.1467-9868.2005.00503.x.
Ayers KL, Cordell HJ: SNP selection in genome-wide and candidate gene studies via penalized logistic regression. Genet Epidemiol. 2010, 34: 879-891. 10.1002/gepi.20543.
Schielzeth H: Simple means to improve the interpretability of regression coefficients. Methods Ecol Evol. 2010, 1: 103-113. 10.1111/j.2041-210X.2010.00012.x.
Kass RE, Raftery AE: Bayes factors. J Am Stat Assoc. 1995, 90: 773-795. 10.1080/01621459.1995.10476572.
Vrieze SI: Model selection and psychological theory: a discussion of the differences between the Akaike information criterion (AIC) and the Bayesian information criterion (BIC). Psychol Methods. 2012, 17: 228-243.
Fluss R, Faraggi D, Reiser B: Estimation of the Youden Index and its associated cutoff point. Biom J. 2005, 47: 458-472. 10.1002/bimj.200410135.
Hsieh C-H, Lu R-H, Lee N-H, Chiu W-T, Hsu M-H, Li Y-CJ: Novel solutions for an old disease: diagnosis of acute appendicitis with random forest, support vector machines, and artificial neural networks. Surgery. 2011, 149: 87-93. 10.1016/j.surg.2010.03.023.
Jamal S, Periwal V, Scaria V: Predictive modeling of anti-malarial molecules inhibiting apicoplast formation. BMC Bioinforma. 2013, 14: 1-8. 10.1186/1471-2105-14-1.
Cai Z, Ducatez MF, Yang J, Zhang T, Long L-P, Boon AC, Webby RJ, Wan X-F: Identifying antigenicity-associated sites in highly pathogenic H5N1 influenza virus hemagglutinin by using sparse learning. J Mol Biol. 2012, 422: 145-155. 10.1016/j.jmb.2012.05.011.
Martens D, Baesens B, Gestel TV: Decompositional rule extraction from support vector machines by active learning. IEEE Trans Knowl Data Eng. 2009, 21: 178-191.
Heiat A: Comparison of artificial neural network and regression models for estimating software development effort. Inf Softw Technol. 2002, 44: 911-922. 10.1016/S0950-5849(02)00128-3.
Xu C, Ladouceur M, Dastani Z, Richards JB, Ciampi A, Greenwood CMT: Multiple regression methods show great potential for rare variant association tests. PLoS One. 2012, 7: e41694-10.1371/journal.pone.0041694.
Fong DS, Aiello L, Gardner TW, King GL, Blankenship G, Cavallerano JD, Ferris FL, Klein R: Retinopathy in diabetes. Dia Care. 2004, 27 (suppl 1): s84-s87.
Chew EY: Screening options for diabetic retinopathy. Curr Opin Ophthalmol. 2006, 17: 519-522. 10.1097/ICU.0b013e328010948d.
Aiello LP, Cahill MT, Wong JS: Systemic considerations in the management of diabetic retinopathy. Am J Ophthalmol. 2001, 132: 760-776. 10.1016/S0002-9394(01)01124-2.
Hamman RF, Mayer EJ, Moo-Young GA, Hildebrandt W, Marshall JA, Baxter J: Prevalence and risk factors of diabetic retinopathy in non-hispanic whites and hispanics with NIDDM: San Luis valley diabetes study. Diabetes. 1989, 38: 1231-1237. 10.2337/diabetes.38.10.1231.
Chen H, Zheng Z, Huang Y, Guo K, Lu J, Zhang L, Yu H, Bao Y, Jia W: A microalbuminuria threshold to predict the risk for the development of diabetic retinopathy in type 2 diabetes mellitus patients. PLoS One. 2012, 7: e36718-10.1371/journal.pone.0036718.
Looker HC, Knowler WC, Hanson RL: Changes in BMI and weight before and after the development of type 2 diabetes. Dia Care. 2001, 24: 1917-1922. 10.2337/diacare.24.11.1917.
Turner RCCC: Glycemic control with diet, sulfonylurea, metformin, or insulin in patients with type 2 diabetes mellitus: progressive requirement for multiple therapies (ukpds 49). JAMA. 1999, 281: 2005-2012. 10.1001/jama.281.21.2005.
Ishihara M, Yukimura Y, Yamada T, Ohto K, Yoshizawa K: Diabetic complications and their relationships to risk factors in a Japanese population. Dia Care. 1984, 7: 533-538. 10.2337/diacare.7.6.533.
Lyons TJ, Jenkins AJ, Zheng D, Lackland DT, McGee D, Garvey WT, Klein RL: Diabetic retinopathy and serum Lipoprotein Subclasses in the DCCT/EDIC cohort. Invest Ophthalmol Vis Sci. 2004, 45: 910-918. 10.1167/iovs.02-0648.
Kalter-Leibovici O, Wainstein J, Ziv A, Harman-Bohem I, Murad H, Raz I: Clinical, socioeconomic, and lifestyle parameters associated with erectile dysfunction among diabetic men. Dia Care. 2005, 28: 1739-1744. 10.2337/diacare.28.7.1739.
Karvonen M, Tuomilehto J, Libman I, LaPorte R: A review of the recent epidemiological data on the worldwide incidence of type 1 (insulin-dependent) diabetes mellitus. Diabetologia. 1993, 36: 883-892. 10.1007/BF02374468.
Davis MD, Fisher MR, Gangnon RE, Barton F, Aiello LM, Chew EY, Ferris FL, Knatterud GL: Risk factors for high-risk proliferative diabetic retinopathy and severe visual loss: early treatment diabetic retinopathy study report #18. Invest Ophthalmol Vis Sci. 1998, 39: 233-252.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1472-6947/13/106/prepub
Acknowledgements
The authors have no support or funding to report. Particular thanks go to Prof. S.M. Hong from the Institute of Vision Research, Department of Ophthalmology, Yonsei University College of Medicine for her support in the design of this study.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
EO collected the data, analyzed the experimental results, provided feedback on the paper, and revised the manuscript. TKY designed and conducted the experiments, analyzed the results, and drafted the research article. ECP collected the data, and provided feedback on the paper. All authors read and approved the final paper. EO and TKY contributed equally to this work.
Ein Oh, Tae Keun Yoo contributed equally to this work.
Electronic supplementary material
12911_2013_725_MOESM1_ESM.docx
Additional file 1:Regression coefficients of the classical logistic regression models and the sparse learning models trained with the training dataset.(DOCX 31 KB)
12911_2013_725_MOESM2_ESM.docx
Additional file 2:Diagnostic performance of the LASSO models in the different scenarios, the support vector machine model, and the artificial neural network model.(DOCX 91 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Oh, E., Yoo, T.K. & Park, EC. Diabetic retinopathy risk prediction for fundus examination using sparse learning: a cross-sectional study. BMC Med Inform Decis Mak 13, 106 (2013). https://doi.org/10.1186/1472-6947-13-106
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1472-6947-13-106