
Abstract
Background
The accurate estimation of outcome in patients with malignant disease is an essential component of the optimal treatment, decision-making and patient counseling processes. The prognosis and disease outcome of breast cancer patients can differ according to geographic and ethnic factors. To our knowledge, to date these factors have never been validated in a homogenous loco-regional patient population, with the aim of achieving accurate predictions of outcome for individual patients. To clarify this topic, we created a new comprehensive prognostic and predictive model for Taiwanese breast cancer patients based on a range of patient-related and various clinical and pathological-related variables.
Methods
Demographic, clinical, and pathological data were analyzed from 1 137 patients with breast cancer who underwent surgical intervention. A survival prediction model was used to allow analysis of the optimal combination of variables.
Results
The area under the receiver operating characteristic (ROC) curve, as applied to an independent validation data set, was used as the measure of accuracy. Results were compared by comparing the area under the ROC curve.
Conclusions
our model building exercise of mortality risk was able to predict disease outcome for individual patients with breast cancer. This model could represent a highly accurate prognostic tool for Taiwanese breast cancer patients.
Similar content being viewed by others


Background
Breast cancer is a serious threat to women's health. In Taiwan, breast cancer ranked fourth among the top 10 causes of death among women in the period from 1995 to 2003 [1]. The investigative results published by the Bureau of Health Promotion, Department of Health, Taiwan, indicate that the incidence and mortality of breast cancer increase almost every year. The incidence rate and the age-adjusted incidence rate have both increased almost two-fold when compared with those calculated for the period from 1995 to 2003. The corresponding mortality also increased: the mortality rate increased from 8.9 per 10000 people to 12.45 per 10000 people and the age-adjusted death rate increased from 8.79 per 10000 people to 11.07 per 10000 people [2]. Improved surgical procedures and chemotherapy regimens seem not to have effectively diminished breast cancer incidence and mortality [3, 4]. It is therefore important to identify risk factors that significantly affect survival among women with breast cancer, as the control of these risk factors.
Unlike most countries in Asia, which have produced few publications on cancer recurrence risk analyses among breast cancer patients, many such studies have been published in Western countries [5–8]. Among them, meta-analyses are widely used to discuss causal relationships between risk factors and breast cancer survival [9, 10]. Meta-analyses are secondary analyses that derive results from data reported in different studies addressing similar research topics. A different combination of methods can lead to different meta-analytical outcomes. Furthermore, it is extremely difficult to predict the disease outcome of cancer patients. To solve this problem, we used a logistic regression approach to simultaneously investigate the relationships between all significantly effected risk factors, including demographic, clinical, and pathological data, and the survival status of breast cancer patients.
Methods
The original data was collected from 1 190 patients with breast cancer diagnosed between January 1, 1995 and August 31, 2005 at the National Cheng Kung University Hospital, Tainan, Taiwan. As our objective was to study the prognostic factors of breast cancer and to develop more precise predictive mortality risk models, both patients with stage IV disease and patients who were followed up for less than one year were excluded from our analyses. Among the remaining 1 137 patients, 70 died and the other 1 067 were censored. The median age of the patients was 49 years (range, 20-88 years). Ethical approval was provided by Human Experiment and Ethics committee of the National Cheng Kung University Hospital (ER-99-076).
A variety of potential breast cancer risk factors were constructed for each patient. The demographic data included marriage status, education level, familial history of breast cancer, presence of other underlying diseases, and menopause status. The clinical data included physical examination (PE), ultrasound (US), fine-needle aspiration cytology (FNAC), core needle biopsy (CNB), mammography, type of breast surgery, and type of axillary lymphatic surgery. Finally, the pathological findings included tumor size, nodal status, tumor grade, estrogen receptor (ER) status, progesterone receptor (PR) status, Her-2/neu status, extensive intraductal carcinoma (EIC), presence of lymphatic tumor emboli (LTE), hepatitis B and C status, and hepatitis B surface antigen (HBsAg) and hepatitis C virus antibody (HCV Ab). The clinical and pathological data were classified into four categories: benign (B), intermediate (I), suspicious (S), and malignant (M). The different treatment modalities, including anti hormone therapy, radiotherapy, and chemotherapy, were also included in our analysis.
Statistical methods
The overall survival function for breast cancer patients was calculated using the Kaplan-Meier method: the log-rank test was used to test the significance of different stage groups [11]. To investigate the association between survival status and each potential risk factor, odds ratios were computed and p values were evaluated by using univariate logistic regression test, where applicable [12]. Odds ratios were used to evaluate the relative odds of death caused by breast cancer between two groups sorted under a risk factor, and p values were calculated to assess significance of results. A multivariable logistic regression analysis was used to measure the significance of several risk factors simultaneously and to predict the survival probability of breast cancer patients [12]. To determine the accuracy of our model, Bootstrap method was used, which can be implemented by obtaining a number of re-samples of our observed dataset [13]. The predictive model, which was built using forward stepwise analyses, included only the risk factors that showed significance in the univariate analyses. Statistical significance was set at p < 0.05.
Three methods were used for the evaluation of the fitness of the multivariable logistic regression model. First, ROC curves (using FORTRAN programs) [14] were plotted to estimate the sensitivity and specificity of the predictive model. The closer that the area under ROC curve is to 1, the better the fit of the model. Second, the Hosmer-Lemeshow test, written as for the statistic being tested (where is the number of patients in the kth group, and and p k are the predicted and real possibilities of death, respectively, in the kth group) was used to examine the fitness of the predictive model by considering the difference between the predicted and observed probabilities of death caused by breast cancer. Patients were divided into several groups according to ordered predicted probability of death. The statistic Ĉ is well approximated by the chi-square distribution with g-2 degrees of freedom, X 2 g-2 . The larger the p value obtained using the Hosmer-Lemeshow test, (which corresponds to a smaller Ĉ), the smaller the square of the distance between and p k , and hence, the better the fit of the model [15, 16]. The comparison was performed based on the confidence interval of both models using the SPSS software, version 11.
Results
The overall median duration of patient follow-up was 60.3 months (range, 11.93-150.3 months). According to the staging rules of practice guidelines in oncology from the National Comprehensive Cancer Network, 70 patients (6.2%) patients had stage 0 disease, 310 patients (27.2%) had stage I disease, 506 patients (44.5%) had stage II disease, and 251 patients (22.1%) had stage III disease. The median duration of patient follow-up was similar for each stage (close to five years), with the exception of stage 0. The five-year survival probability for breast cancer was greater than 90%, and even for patients with stage III disease, the survival probability for five years was 84.33%. Log-rank testing showed that the differences in survival at the different stages were significant (p < 0.0001) (Figure 1).

The Kaplan-Meier survival curve in each stage of the patients.
Associations of breast cancer mortality with demographic, clinical, and pathological factors
Patients for whom risk factor values were missing were excluded from the analytical process. Among the demographic data, only age and menopause correlated significantly with breast cancer survival. The mortality was lowest for patients between the ages of 36 and 57 years (4.5%). Conversely, patients aged from 20 to 35 years had the highest mortality (12%). The mortality difference for these two age groups was significant (p = 0.002). Regarding the menopausal status, the mortality of postmenopausal patients was higher than that of premenopausal patients, or of patients who had hysterectomy or oophorectomy (p = 0.0082); however, the effect of the menopause status on breast cancer mortality could be a reflection of the age of the patients. (Table 1) The analysis of the clinical data revealed that all clinical risk factors were correlated with survival status. (Table 2) In what concerns the pathology data, the survival rate did not correlate with hepatitis status, HBsAg, or HCV Ab. In contrast, the following pathology outcomes were positively associated with increased breast cancer mortality: higher tumor grade (p < 0.0001), negative ER status (p = 0.0086), negative PR status (p = 0.0086), positive Her-2/Neu status (p = 0.0137), absence of EIC (p = 0.0323), presence of LTE (p = 0.0004), increased tumor size (p < 0.0001), axillary lymph nodes (p < 0.0001), and abandonment or refusal of chemotherapy treatment (p < 0.0001) (Table 3).
Multivariable logistic regression
Of the original 1 067 patients, 818 patients with complete data were included in the multivariable logistic regression analysis. Among them, 43 patients died and 775 were censored. As shown in Table 4, the odds ratio for patients aged 36-60 years versus patients aged 20-35 years is 0.254, which means that the odds of death for a patient in the latter age group is approximately four times (1/0.254) greater than that for patients in the former age group (p = 0.0029). The odds ratio of patients with an ultrasound examination showing malignancy were also around two times higher than those with benign, intermediate, or suspicious ultrasound results (odds ratio = 2.028, p < 0.0001). In what concerns the remaining four chosen pathological risk factors, the odds of death were positively correlated with a higher tumor grade (odds ratio = 1.626, p = 0.01) or lymph node involvement (odds ratio = 3.054, p < 0.0001): the odds increased about two times when the tumor grade was II versus grade I, or grade II versus grade III, and three times when lymph node status was N1 or N2 versus N0 or N3 versus N1 or N2. Patients who abandoned or refused chemotherapy had approximately three times greater odds of death than patients who completed chemotherapy treatment (odds ratio = 0.242, p = 0.0016). Compared to the univariate logistic analysis, multivariable logistic analysis and Bootstrap for variables showed only difference in the patient group examined with ultrasound (p = < 0.0001, <0.0001 and 0.111 respectively).
Goodness of fit
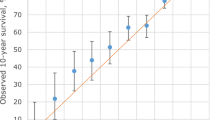
Our model showed a good fit based on both the ROC curve and the Hosmer-Lemeshow test. The area under the ROC curve was 0.894 with asymmetric confidence interval equals (0.8405, 0.9318), not concluding 0.5. The larger area, farther from 0.5 and closer to 1, showed the excellence of the model's performance. Best cutoff value showed p = 0.0419, sensitivity = 0.86, specificity = 0.756, positive predictive value (PPV) = 0.1889 and negative predictive value (NPV) = 0.9879 (Figure 2). The Hosmer-Lemeshow test also showed excellent performance of the model (p = 0.9448) (Figure 3). The curve of the observed probability of death is much closer to that of the predicted probability of death.

ROC curve calculated by the multiple logistic regression model.

The curve of the predicted and observed probability of death.
Discussion
In recent years, several improvements in medical treatment modalities in breast cancer were observed; [4, 17–19] however, the overall prognosis and predictive values for breast cancer patients remains ambiguous [5, 6]. It is important to improve the efficiency of predicting the survival of breast cancer patients; therefore, a model building exercise can be extended to include any number of prognostic or risk factors, while also providing treatment predictions. The TNM classification system has long been the accepted predictive tool for breast cancer and provides useful information for the clinical decision-making process in these patients; [20] however, this system is based solely on disease-related parameters and does not include diverse variables, including diagnostic methods, which may influence the outcome of patients. Furthermore, a comprehensive predictive model should also take into account treatment modalities, including chemotherapy, hormone therapy or targeted therapy, which are currently either in use or are under study [21–23].
The impact of the race of the individual on the survival of breast cancer patients has been reported [24–26]. To our knowledge, the current study is the first to demonstrate systematically the influence of prognostic factors on the survival of patients with breast cancer in Asian and Pacific Islander populations. Admittedly, the design of the model and the selection of variables should have considerable clinical applicability. The main purpose of our study was to construct a suitable survival prediction formula for Taiwanese women. To create a survival prediction model for breast cancer, we used a comprehensive dataset that included clinico-pathological data, diagnostic modalities, and treatment variables from Taiwanese patients who suffering from this disease.
Our model building exercise showed that age, ultrasound diagnostic classification, mammography diagnostic classification, diagnosis by core biopsy, tumor grade, ER/PR status, lymph node status, and chemotherapy are the most important predictive factors for breast cancer in Taiwanese women. The combination of these risk factors using multivariable logistic regression analysis, led to the development of a predictive formula for breast cancer survival. Our data also draw attention to the importance and influence of diagnostic modalities on breast cancer survival rate. In our model building exercise, the use of ultrasound, mammography, and core biopsy technologies had a high impact on disease outcome.
The prognostic power in a disease context can be improved by applying a predictive model, even when using TNM data or other predictive factors [7, 22, 27]. Burke et al. [28] demonstrated that the predictive accuracy for breast and colon carcinoma could be improved by using an ANN-based model using TNM information exclusively. Similarly, in the current study we created an additional model for the prediction of survival in patients with breast cancer using data that was more complete than TNM staging information.
The high predictive accuracy of the current model may stem from several factors. First, in other models, investigators often relied strongly on input data that were weighted toward tumor histopathological parameters, rather than toward clinical or demographic patient data [6, 17, 19, 21, 27]. This is in contrast to the current model, in which several parameters, including diagnostic and treatment modalities or demographic data, represented the majority of the selected optimal variable datasets. Second, the current study is the first to use prognostic factors as a predictive tool in Asian breast cancer populations.
Caution should nevertheless be employed when generating and interpreting data using our model building exercise. First, the current model was based on data assembled at a single institution; therefore, the validity of this model should be verified before its application to patients from other populations or institutions. The variability in survival rates observed for breast cancer patients from different countries seems to support this argument [25, 26]. A possible method for overcoming this limitation may be the inclusion of patients from other Asian populations in the construction of a new model. Thus, the identification and evaluation of universally applicable variables may require collaborations between different institutions or nations. Nevertheless, the current pilot study serves as a proof-of-principle strategy that underscores the utility of this model building exercise. Second, the data used here were not established from prospective and randomized studies. If other users wish to adopt our model building exercise for the selection of therapeutic methods, then any variables pertaining to focused treatment methods should be compared with standardized protocols. If treatment variables were included, any result would be biased by case-by-case selection criteria for that particular treatment; [7, 8] therefore, a web-based prediction engine may facilitate its use by clinicians in the future.
Conclusions
We have designed an effective model for predicting outcomes in Taiwanese breast cancer patients by combining demographic, clinical, and pathological data, including multiple tumor-related and patient-related variables. Our model building exercise showed a strong potential to enhance the prediction of patient survival and to identify important variables that have an impact on disease outcomes. Information provided by this model building exercise may improve the selection of appropriate and effective therapy for breast cancer patients.
References
Taiwan Cancer Registry. [http://crs.cph.ntu.edu.tw/]
Bureau of Health Promotion Department of Health, TAIWAN. 2007, [http://www.bhp.doh.gov.tw/BHPnet/Portal/]
Goldhirsch A, Wood WC, Gelber RD, Coates AS, Thurlimann B, Senn HJ: Progress and promise: highlights of the international expert consensus on the primary therapy of early breast cancer 2007. Ann Oncol. 2007, 18 (7): 1133-1144. 10.1093/annonc/mdm271.
Loprinzi CL, Thome SD: Understanding the utility of adjuvant systemic therapy for primary breast cancer. J Clin Oncol. 2001, 19 (4): 972-979.
De Laurentiis M, De Placido S, Bianco AR, Clark GM, Ravdin PM: A prognostic model that makes quantitative estimates of probability of relapse for breast cancer patients. Clin Cancer Res. 1999, 5 (12): 4133-4139.
Hwa HL, Kuo WH, Chang LY, Wang MY, Tung TH, Chang KJ, Hsieh FJ: Prediction of breast cancer and lymph node metastatic status with tumour markers using logistic regression models. J Eval Clin Pract. 2008, 14 (2): 275-280. 10.1111/j.1365-2753.2007.00849.x.
Lundin M, Lundin J, Burke HB, Toikkanen S, Pylkkanen L, Joensuu H: Artificial neural networks applied to survival prediction in breast cancer. Oncology. 1999, 57 (4): 281-286. 10.1159/000012061.
Ravdin PM, Siminoff LA, Davis GJ, Mercer MB, Hewlett J, Gerson N, Parker HL: Computer program to assist in making decisions about adjuvant therapy for women with early breast cancer. J Clin Oncol. 2001, 19 (4): 980-991.
Shapiro S: Screening: assessment of current studies. Cancer. 1994, 74 (1 Suppl): 231-238. 10.1002/cncr.2820741306.
Effects of chemotherapy and hormonal therapy for early breast cancer on recurrence and 15-year survival: an overview of the randomised trials. Lancet. 2005, 365 (9472): 1687-1717. 10.1016/S0140-6736(05)66544-0.
Klein JP, Moeschberger ML: Survival analysis. 2003, Springer, 2
Agresti A: Categorical data analysis. 2002, New York: Wiley, 2
Davison AC, Hinkley DV: Bootstrap Methods and their Application. 2006, Cambridge: Cambridge university press, 8
Metz CE, Herman BA, Shen JH: Maximum likelihood estimation of receiver operating characteristic (ROC) curves from continuously-distributed data. Stat Med. 1998, 17 (9): 1033-1053. 10.1002/(SICI)1097-0258(19980515)17:9<1033::AID-SIM784>3.0.CO;2-Z.
Hosmer DW, Lemeshow S: Applied logistic regression. 1989, New York: Wiley
Zhou XH, Obuchowski NA, McClish DK: Statistical method in diagnostic medicine. 2002, New York: Wiley, 100-36.
Berg WA, Blume JD, Cormack JB, Mendelson EB, Lehrer D, Bohm-Velez M, Pisano ED, Jong RA, Evans WP, Morton MJ: Combined screening with ultrasound and mammography vs mammography alone in women at elevated risk of breast cancer. JAMA. 2008, 299 (18): 2151-2163. 10.1001/jama.299.18.2151.
Levine M: Clinical practice guidelines for the care and treatment of breast cancer: adjuvant systemic therapy for node-negative breast cancer (summary of the 2001 update). CMAJ. 2001, 164 (2): 213-
Tewari M, Krishnamurthy A, Shukla HS: Predictive markers of response to neoadjuvant chemotherapy in breast cancer. Surg Oncol. 2008
Sobin LH, Wittekind C: TNM classification of malignant tumor. 2002, Hoboken, New Jersey: John Wiley & Sons, 6
Weir L, Speers C, D'Yachkova Y, Olivotto IA: Prognostic significance of the number of axillary lymph nodes removed in patients with node-negative breast cancer. J Clin Oncol. 2002, 20 (7): 1793-1799. 10.1200/JCO.2002.07.112.
Whelan T, Sawka C, Levine M, Gafni A, Reyno L, Willan A, Julian J, Dent S, Abu-Zahra H, Chouinard E: Helping patients make informed choices: a randomized trial of a decision aid for adjuvant chemotherapy in lymph node-negative breast cancer. J Natl Cancer Inst. 2003, 95 (8): 581-587. 10.1093/jnci/95.8.581.
Truong PT, Yong CM, Abnousi F, Lee J, Kader HA, Hayashi A, Olivotto IA: Lymphovascular invasion is associated with reduced locoregional control and survival in women with node-negative breast cancer treated with mastectomy and systemic therapy. J Am Coll Surg. 2005, 200 (6): 912-921. 10.1016/j.jamcollsurg.2005.02.010.
Ghafoor A, Jemal A, Ward E, Cokkinides V, Smith R, Thun M: Trends in breast cancer by race and ethnicity. CA Cancer J Clin. 2003, 53 (6): 342-355. 10.3322/canjclin.53.6.342.
Smigal C, Jemal A, Ward E, Cokkinides V, Smith R, Howe HL, Thun M: Trends in breast cancer by race and ethnicity: update 2006. CA Cancer J Clin. 2006, 56 (3): 168-183. 10.3322/canjclin.56.3.168.
Hausauer AK, Keegan TH, Chang ET, Clarke CA: Recent breast cancer trends among Asian/Pacific Islander, Hispanic, and African-American women in the US: changes by tumor subtype. Breast Cancer Res. 2007, 9 (6): R90-10.1186/bcr1839.
Oldenhuis CN, Oosting SF, Gietema JA, de Vries EG: Prognostic versus predictive value of biomarkers in oncology. Eur J Cancer. 2008, 44 (7): 946-953. 10.1016/j.ejca.2008.03.006.
Burke HB, Goodman PH, Rosen DB, Henson DE, Weinstein JN, Harrell FE, Marks JR, Winchester DP, Bostwick DG: Artificial neural networks improve the accuracy of cancer survival prediction. Cancer. 1997, 79 (4): 857-862. 10.1002/(SICI)1097-0142(19970215)79:4<857::AID-CNCR24>3.0.CO;2-Y.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1472-6947/10/43/prepub
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
CTW designed the concept of this study, drafted the manuscript and performed treatment. CTW collected the data and performed the statistical analysis. KYL approved the final manuscript. KYL designed the concept of this study and provided treatment coordination. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Chang, T.W., Kuo, Y.L. A model building exercise of mortality risk for Taiwanese women with breast cancer. BMC Med Inform Decis Mak 10, 43 (2010). https://doi.org/10.1186/1472-6947-10-43
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1472-6947-10-43