
Abstract
Background
The aim of the project was to develop a novel method for diabetic retinopathy screening based on the examination of tear fluid biomarker changes. In order to evaluate the usability of protein biomarkers for pre-screening purposes several different approaches were used, including machine learning algorithms.
Methods
All persons involved in the study had diabetes. Diabetic retinopathy (DR) was diagnosed by capturing 7-field fundus images, evaluated by two independent ophthalmologists. 165 eyes were examined (from 119 patients), 55 were diagnosed healthy and 110 images showed signs of DR. Tear samples were taken from all eyes and state-of-the-art nano-HPLC coupled ESI-MS/MS mass spectrometry protein identification was performed on all samples. Applicability of protein biomarkers was evaluated by six different optimally parameterized machine learning algorithms: Support Vector Machine, Recursive Partitioning, Random Forest, Naive Bayes, Logistic Regression, K-Nearest Neighbor.
Results
Out of the six investigated machine learning algorithms the result of Recursive Partitioning proved to be the most accurate. The performance of the system realizing the above algorithm reached 74% sensitivity and 48% specificity.
Conclusions
Protein biomarkers selected and classified with machine learning algorithms alone are at present not recommended for screening purposes because of low specificity and sensitivity values. This tool can be potentially used to improve the results of image processing methods as a complementary tool in automatic or semiautomatic systems.
Similar content being viewed by others

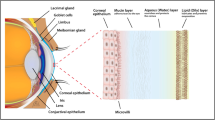

Background
Diabetic retinopathy screening
Diabetic retinopathy (DR) is the most common complication of diabetes mellitus and is currently the leading cause of blindness in the economically active population in developed countries [1]. The initially latent disease could lead to vision loss without any symptoms initially. Timely diagnosis and therapy however can significantly decelerate its progress, necessitating regular DR screening or appropriate follow-up in all patients with diabetes. Screening can be carried out by direct and indirect ophthalmology or increasingly by using photographic methods [2].
The effectiveness of different screening modalities has been widely investigated. UK studies show sensitivity levels for the detection of sight-threatening diabetic retinopathy of 41-67% for general practitioners, 48-82% for optometrists, 65% for ophthalmologists, and 27-67% for diabetologists and hospital physicians using direct ophthalmoscopy [3, 4]. Sensitivity for the detection of referable retinopathy by optometrists have been found to be 77-100%, with specificity of 94-100% [5].
Photographic methods currently use digital images with subsequent grading by trained individuals. Sensitivity for the detection of sight-threatening diabetic retinopathy have been found 87-100% for a variety of trained personnel reading mydriatic 45° retinal photographs, with specificities of 83-96% [6]. The British Diabetic Association (Diabetes UK) has established standard values for any diabetic retinopathy screening programme of at least 80% sensitivity and 95% specificity [7, 8].
Regular DR screening is centralized in several developed countries due to cost-efficiency and quality control issues [9]. Digital fundus images are captured at the place of patient care and forwarded to a grading center for evaluation by specially trained human graders or ophthalmologists [10]. The system operates with high accuracy but due to its labor intensive nature, it might be poorly scalable in economically challenged countries [11].
In order to improve scalability and cost-effectiveness, many research groups are working on developing automated image analysis technologies [12]. Introducing these technologies in DR screening could substitute first phase examinations performed by human graders. Following automated pre-screening, human graders would only have to examine images that are either questionable or true positive, and potentially carry out quality control on a subset of those deemed normal by the software [13]. Preliminary results are promising, sensitivity and specificity indicators of automated systems are close to that of human graders [14–16]. An international Retinopathy Online Challenge is available in order to compare the results of image processing based algorithms for DR identification via mycroaneurism detection. The system developed by our team currently performs the best on this challenge [17].
The aim of this paper is to describe a pilot study, conducted as a first attempt to examine the use of tear fluid proteomics for DR pre-screening. Our hypothesis was that it is possible to categorize patients with unknown clinical status into a DR or a non-DR group, based on the protein pattern identified in the tear fluid sample.
Tear fluid proteomics
Besides computer based image processing other methods can also support DR screening. Tear fluid proteomics is such a possible novel tool for population screening, which is based on the pre-screening of a large number of patients and uses human graders only in positive or ambiguous cases. The protein composition of tear fluid has been investigated by numerous research groups and more than 500 proteins are already proven to be present there [18, 19]. Reports confirm protein profile changes in tear fluid under irregular physiological and pathological conditions (like wound healing or inflammatory diseases etc.) [20]. Besides the proteins secreted by the lacrimal glands, tear fluid might contain proteins from epithelial cells covering the eye surface. Furthermore proteins normally residing in the blood can get into the tear fluid through increased permeability of the conjunctival vessels [21].
Physiological and pathological conditions of the retina also induce changes in the protein composition of the vitreous humour, especially when the blood-retinal barrier (BRB) is damaged [22]. Breakdown of the inner endothelial BRB, occurs in diabetic retinopathy, age-related macular degeneration, retinal vein occlusions, uveitis and other chronic retinal diseases [23]. DR is a complex disease, characterized by vascular alterations, inflammation, and neuronal cell death that involve heat-shock and crystalline proteins. The central mechanism of altered BRB function is a change in the permeability characteristics of retinal endothelial cells caused by elevated levels of growth factors, cytokines, advanced glycation end products, inflammation, hyperglycemia and loss of pericytes. Subsequently, paracellular but also transcellular transport across the retinal vascular wall increases via opening of endothelial intercellular junctions and qualitative and quantitative changes in endothelial caveolar transcellular transport, respectively. Functional changes in pericytes and astrocytes, as well as structural changes in the composition of the endothelial glycocalyx and the basal lamina around BRB endothelium further facilitate BRB leakage. As Starling's rules apply, active transcellular transport of plasma proteins by the BRB endothelial cells causing increased interstitial osmotic pressure is probably the main factor in the formation of macular edema [23]. Recent studies using whole proteome analysis demonstrate that general stress response lead to the induction of heat-shock proteins. The alpha-crystallin is expressed in the retina and over-expressed during diabetes as an adaptive response of retinal cells [24]. These changes are more specific to DR than alteration of tear fluid proteome. However, the invasive sampling method makes it difficult to introduce vitreous humour proteomics in the daily clinical practice.
According to recent publications the protein composition of tear fluid reflects normal or abnormal conditions, which justifies the use of tear fluid for screening purposes. Electrophoresis and chromatography also support that protein patterns of healthy and diabetic people are significantly different [25, 26].
Qualitative and quantitative methods used for tear fluid examinations include one and two dimensional electrophoresis, enzyme-linked immunosorbent assay and high throughput liquid chromatography [27–29]. Recently, high sensitivity and high resolution procedures were used for the assessment of the effects of trauma and various diseases in tear fluid of microliter quantity. In these cases, protein profiles were characterized by mass spectrometers MALDI-TOF, SELDI-TOF and LC/MS [30–33].
In a previous study we examined the changes of tear protein concentrations in DR aiming to identify and characterize proteins–potential biomarkers-present in tear fluid in DR patients. Tear fluid samples were examined by quantitative mass spectrometry, and 6 potential biomarkers namely lipocalin 1, lactotransferrin, lacritin, lysozyme C, lipophilin A and immunoglobulin lambda chain were identified. The results of that study have already been published elsewhere [34].
In this paper, we evaluate the usefulness of the previously identified DR marker proteins in tear fluid sample for diagnostic purposes and introduce a method based on whole protein pattern analysis, which can be integrated into the screening of DR as a pre-screening procedure.
Machine learning
Machine learning is an area of artificial intelligence. IT systems using machine learning methods are capable to learn from training datasets and predict possible outcomes based on new observations. In our case the input data are coming from proteomics experiments and the predicted outcomes are diseased and non-diseased cases (DR or Non-DR). In the learning phase both input data and outcomes are used by the system. During the pre-screening process the trained machine learning system will classify cases into diseased or non-diseased groups.
In our pilot study, we intended to ensure the objectivity of the assessment by using the following 6 different machine learning methods: Support Vector Machine (SVM), Recursive Partitioning (rpart), Random Forest (randomForest), Naive Bayes (naïveBayes), Logistic Regression (logReg), K-Nearest Neighbor (k-NN). Possible positive and negative cases for DR can be identified by machine learning algorithms, allowing the pre-screened population (possible positives) to undergo human screening by using digital retinal imaging. The approach presented in this paper is unique in nature, as no previous study was found in the scientific literature investigating the applicability of tear fluid proteomics based methods for DR screening.
Methods
Patient examination
119 patients with diabetes were enrolled in the study. In case of 73 patients one of the eyes were examined due to difficulties in tear fluid sampling (e.g. keratoconjunctivitis sicca, operated eye, noncompliance) or because the retinal image couldn’t be taken (e.g. cataract, hemorrhage, angle-closure glaucoma) or assessed (technical difficulties). Diabetic retinopathy was diagnosed by capturing 7-field fundus images of the patients, evaluated by two independent ophthalmologists. Megaplus Camera Model 1,6i/10 BIT Zeiss (Carl Zeiss Ophthalmic System A6, Jena, Germany) was used for taking images. Out of the 165 eyes examined, 55 were diagnosed healthy and 110 showed signs of DR. One patient had DR in one eye only.
Tear fluid samples were collected from the examined eyes by a trained assistant under standardized conditions [35]. Tear samples were collected with glass capillaries immediately before the pupil dilatation for fundus examination under slit lamp illumination from the lower tear meniscus (a horizontal thickening of the pre-corneal tear film by the lower margin) at the lateral canthus. Care was taken not to touch the conjunctiva. The duration of the sampling process was recorded and the secretion rate was calculated in microl/min, dividing the obtained tear volume by the time of sample collection. Samples used in this investigation had secretion rates of 5–15 μl/min. Samples were centrifuged (1800 rpm) for 8–10 minutes immediately after sample collection, supernatants were deep-frozen at −80°C and were thawed only once for measurements. Tear samples were examined using state-of-the-art nano-HPLC coupled ESI-MS/MS mass spectrometry protein identification as described elsewhere [29]. During the protein-based screening procedure pre-proliferative and proliferative retinopathy patients were both considered important, the term ’patient’ includes both groups diagnosed by using retina images. Global pattern of protein concentrations and its changes were described by the examination of the concentrations of 34 different proteins.
Application of machine learning methods
By using machine learning algorithms we intended to predict the possible fulfillment of certain future events–using empirical data containing incomplete information. In the present special case, input data (features) are protein levels measured in tear fluids from patients with diabetes and clinical data regarding their DR status (dichotomous variable of none or some). As the method is designed to be used in screening in the future, high sensitivity values were considered as the primary criteria for the construction of the classifier. This was aimed at minimizing the number of false negative cases, thus reducing the chance for missing sight threatening disease. The goal of this machine learning approach is to assess the best classification performance achievable by fitting different models to the dataset (model selection). In order to reach the best possible results, we tested several classifying algorithms (SVM, rpart, randomForest, naiveBayes, logReg, k-NN).
A further objective was to design a marker score for marker selection, targeting the best performance of the tested models. In order to guarantee comparability at the parameter adjustment of the different classifiers, we applied the settings providing the best performance regarding the particular model. In order to monitor the classifier’s performance on the dataset, the testing was accomplished with k-fold cross validation procedure [36]. During the k-fold cross validation the data set is divided into k equal parts. The first k-1 set (training set) is used for model construction and later on it is tested on the k-fold set (test set). In the further k-1 iteration the same procedure is followed, on the first k-2 and k-fold set the model is learning and on the k-1 it is validated. At the end of the cross validation, the estimate is determined as the mean of the features of the k-fold model. In this study 5-fold cross validation was used. Standard measures were applied to assess the performance of the different models, e.g.: specificity, sensitivity, accuracy, F-measure (harmonic mean of precision and sensitivity–as a single measure for the performance of the model).
Data analysis software tools
We collected experimental (proteomics) and clinical data (DR/Non-DR) in an Excel file which was used as input data for the analysis.
During the data analysis process the R statistical framework and the following packages have been used: Support Vector Machine: “e1071”; Recursive Partitioning: “rpart”; Random Forest: “randomForest”; Naive Bayes: “naiveBayes”; Logistic Regression: “glmnet” and for visualization purpose: “ggplot2” [37]. We have developed our own solution for the K-Nearest Neighbor model.
We ran cross validation using the three different approaches below in order to find the best combination of input data and the different models.
First, we used data from all 34 identified proteins for model development.
However, we also wanted to analyze the changes in the performance of the classifiers if we only use a subset of the data. Thus, second, only 6 marker proteins (out of the 34)–previously extracted by classical statistical methods–were used for decision making, applying the six machine learning algorithms. Third, we wanted to further evaluate the performance of the models by reducing the number of input variables therefore we applied principal component analysis (PCA). In this case, we performed dimension reduction to compress the information included in the original dataset with principal component analysis and used it for the visualization of the complex dataset in a 2D plane. With this method the number of input features could be decreased while as much of the variation in data as possible could be retained. Thus, we had fewer input features which are the linear combinations of the original variables and uncorrelated with each other.
Statement of ethics
We certify that all applicable institutional and governmental regulations concerning the ethical use of human volunteers were followed during this research (Regional and Institutional Ethics Committee, Medical and Health Science Center, University of Debrecen).
Results and discussion
Evaluation of the six classifiers on the data
Out of the six different machine learning algorithms, rpart methodology was found to be the most efficient if we used the dataset of the six marker proteins identified by classical statistical methods. Standard measures (Table 1) show that the model based on the Recursive Partitioning classifier outperforms the other five models (74% sensitivity, 48% specificity and 65% accuracy; rpart/marker). Naive Bayes method shows higher sensitivity but low specificity (38%), if we were using the marker proteins only as input variables (80%; naiveBayes/marker). Random Forest method performs slightly worse than Recursive Partitioning.
Six proteins were identified as independent biomarkers out of the 34 candidate protein, by using statistical hypothesis testing.
There is additional information in the joint distribution of the whole dataset, thus we wanted to examine the maximum possible performance of the model.
Our reason for examining the performance of the reduced set was to develop a practical method for screening, without compromising the performance of the test.
We have found that neither the models built on just the 6 marker proteins nor the models built on the PCA preprocessed data performed better or worse than the models built on the whole protein patterns. After Principal Component Analysis the first two components retained 22% of the variation of the original data set. Table 1 shows that in case of retaining the first two components only, performance measures does not change considerably. As a visual presentation of the data we have generated a scatter plot of the first two components. Figure 1 presents the lack of clear decision boundary separating the two classes.

Scatter plot. Scatter plot of the PCA transformed data set. X1 and X2 are the two components retained after the transformation. 0 refers to non-DR, 1 refers to DR patients.
As part of our descriptive analysis we evaluated and visualized the correlation between the predictor variables (protein levels) and also between predictor and outcome variables (DR or non-DR) to have a better understanding on the structure of the data set. According to the probability density function of the correlation values in most of the cases there are low correlation between predictors and predictors/outcomes (Figure 2). These figures suggest that the predictors used separately will not be sufficient for the classification.

Probability density function. Probability density function of the correlation values between predictors (on the left) and between predictors and outcome variables (on the right).
Data set size effect on performance
In order to evaluate the impact of the training set size on the reliability of the results we compared the learning curves for each of the cases. With this method we can have an insight to the relation of the bias and variance of the different models and also further improvement possibilities. For more accurate evaluation of the performance of our methods we have to examine if there are any effects of increasing data volume on the performance of the different machine learning methods (Figure 3).

Learning curves. Learning curves of Support Vector Machine (SVM), Recursive Partitioning (Rpart) Logistic Regression (Logreg) and Naive Bayes (naiveBayes) classifiers for original data set.
We used learning curve to display the test and training errors for different training set sizes.
The distance of the curves shows a gap between the error rates of training and test set in case of Support Vector Machine (SVM) and Recursive Partitioning (Rpart). This finding suggests that these classifiers have high variance and getting more training data might help with the performance. In case of Logistic Regression (Logreg) and Naive Bayes (naiveBayes) we do not see a gap, but both training and test errors are high, indicating that the models are too simple, thus, we have underfit the data.
Conclusions
We hypothesized at the beginning of the study, that the system may be utilized for pre-screening purposes, substantially-in long term-reducing the cost of regular screening and the need for health professionals in the process. A possible advantage of this method is that the pre-screening of the risk population (i.e. diabetic patients) can be performed at the patient’s home. Patients can take tear sample by their own, using sampling capillaries delivered by post, and then returning it to the laboratory. Only those with positive screening results should visit a DR screening center.
Based on this pilot study, sensitivity and specificity values of the system examined on a test database were not found high enough to unequivocally support its use as a pre-screening method prior to currently applied screening procedures. However, the results of the system may be further improved by the enlargement of the learning database.
Another promising application of proteomics based machine learning methods is the support of image processing based automated methods by improving their performance to be able to substitute traditional human screening methods in the future. Given constantly dropping price of high throughput technologies, methodologies based on such technologies will be available both for routine point of care diagnostics and screenings [38]. On the other hand, costs of human workforce significantly increase along with the decreasing accessibility of qualified health care professionals. The net result of these forces accelerates the future spread of such technologies.
This study opens up the possibility of including features other than protein analysis: e.g. anamnestic clinical data, results of image processing procedures. Applying more individual parameters as system inputs may considerably improve the sensitivity indicators of a combined system in contrast to the proteomics-alone or image processing-alone systems. This statement is further emphasized as the results of procedures based on image processing are highly promising. The system built on combined procedures may be applied in the future clinical practice.
Authors’ information
Agnes Molnar: CIHR Strategic Training Fellow and Peterborough KM Hunter Charitable Foundation Fellow in the ACHIEVE Research Partnership: Action for Health Equity Interventions.
References
Klonoff DC, Schwartz DM: An economic analysis of interventions for diabetes. Diabetes Care. 2000, 23 (3): 390-404.
Cheung N, Mitchell P, Wong TY: Diabetic retinopathy. Lancet. 2010, 376 (9735): 124-136.
Gibbins RL, Owens DR, Allen JC, Eastman L: Practical application of the European Field Guide in screening for diabetic retinopathy by using ophthalmoscopy and 35 mm retinal slides. Diabetologia. 1998, 41 (1): 59-64.
Sundling V, Gulbrandsen P, Straand J: Sensitivity and specificity of Norwegian optometrists’ evaluation of diabetic retinopathy in single-field retinal images, a cross-sectional experimental study. BMC Health Serv Res. 2013, 13: 17-
Prasad S, Kamath GG, Jones K, Clearkin LG, Phillips RP: Effectiveness of optometrist screening for diabetic retinopathy using slit-lamp biomicroscopy. Eye (Lond). 2001, 15 (Pt 5): 595-601.
O'Hare JP, Hopper A, Madhaven C, Charny M, Purewell TS, Harney B, Griffiths J: Adding retinal photography to screening for diabetic retinopathy: a prospective study in primary care. BMJ. 1996, 312 (7032): 679-682.
Screening for Diabetic Retinopathy: http://www.mrcophth.com/focus1/Screening%20for%20Diabetic%20Retinopathy.htm,
Harding S, Garvican L, Talbot J: The impact of national diabetic retinopathy screening on ophthalmology: the need for urgent planning. Eye (Lond). 2005, 19 (9): 1009-1011.
Silva PS, Cavallerano JD, Aiello LM, Aiello LP: Telemedicine and diabetic retinopathy: moving beyond retinal screening. Arch Ophthalmol. 2011, 129 (2): 236-242.
Garg S, Davis RM: Diabetic retinopathy screening update. Clinical Diabetes. 2009, 27 (4): 140-145.
Bragge P, Gruen RL, Chau M, Forbes A, Taylor HR: Screening for presence or absence of diabetic retinopathy: a meta-analysis. Arch Ophthalmol. 2011, 129 (4): 435-444.
Gibson OR, Segal L, McDermott RA: A simple diabetes vascular severity staging instrument and its application to a Torres Strait Islander and Aboriginal adult cohort of north Australia. BMC Health Serv Res. 2012, 12: 185-
Sotland GS, Philip S, Fleming AD, Goatman KA, Sharp PF, McNamee P, Prescott GJ, Fonseca S, Olson JA: Manual vs. automated: the diabetic retinopathy screening debate. Ophthalmol Times. 2008, 4: 2-
Bouhaimed M, Gibbins R, Owens D: Automated detection of diabetic retinopathy: results of a screening study. Diabetes Technol Ther. 2008, 10 (2): 142-148.
Fleming AD, Goatman KA, Philip S, Prescott GJ, Sharp PF, Olson JA: Automated grading for diabetic retinopathy: a large-scale audit using arbitration by clinical experts. Br J Ophthalmol. 2010, 94 (12): 1606-1610.
Larsen N, Godt J, Grunkin M, Lund-Andersen H, Larsen M: Automated detection of diabetic retinopathy in a fundus photographic screening population. Invest Ophthalmol Vis Sci. 2003, 44 (2): 767-771.
Niemeijer M, van Ginneken B, Cree MJ, Mizutani A, Quellec G, Sanchez CI, Zhang B, Hornero R, Lamard M, Muramatsu C, Wu X, Cazuguel G, You J, Mayo A, Li Q, Hatanaka Y, Cochener B, Roux C, Karray F, Garcia M, Fujita H, Abramoff MD: Retinopathy online challenge: automatic detection of microaneurysms in digital color fundus photographs. IEEE Trans Med Imaging. 2010, 29 (1): 185-195.
de Souza GA, Godoy LM, Mann M: Identification of 491 proteins in the tear fluid proteome reveals a large number of proteases and protease inhibitors. Genome Biol. 2006, 7 (8): R72-
Li N, Wang N, Zheng J, Liu XM, Lever OW, Erickson PM, Li L: Characterization of human tear proteome using multiple proteomic analysis techniques. J Proteome Res. 2005, 4 (6): 2052-2061.
Csutak A, Silver DM, Tozser J, Steiber Z, Bagossi P, Hassan Z, Berta A: Plasminogen activator inhibitor in human tears after laser refractive surgery. J Cataract Refract Surg. 2008, 34 (6): 897-901.
Zhou L, Beuerman RW, Chan CM, Zhao SZ, Li XR, Yang H, Tong L, Liu S, Stern ME, Tan D: Identification of tear fluid biomarkers in dry eye syndrome using iTRAQ quantitative proteomics. J Proteome Res. 2009, 8 (11): 4889-4905.
Shitama T, Hayashi H, Noge S, Uchio E, Oshima K, Haniu H, Takemori N, Komori N, Matsumoto H: Proteome profiling of vitreoretinal diseases by cluster analysis. Proteomics Clin Appl. 2008, 2 (9): 1265-1280.
Klaassen I, Van Noorden CJ, Schlingemann RO: Molecular basis of the inner blood-retinal barrier and its breakdown in diabetic macular edema and other pathological conditions. Prog Retin Eye Res. 2013, 34: 19-48. 10.1016/j.preteyeres.2013.02.001. Epub 2013 Feb 13
Heise EA, Fort PE: Impact of diabetes on alpha-crystallins and other heat shock proteins in the eye. J Ocul Biol Dis Infor. 2011, 4 (1–2): 62-69.
Green-Church KB, Nichols KK, Kleinholz NM, Zhang L, Nichols JJ: Investigation of the human tear film proteome using multiple proteomic approaches. Mol Vis. 2008, 14: 456-470.
Grus FH, Augustin AJ: High performance liquid chromatography analysis of tear protein patterns in diabetic and non-diabetic dry-eye patients. Eur J Ophthalmol. 2001, 11 (1): 19-24.
Herber S, Grus FH, Sabuncuo P, Augustin AJ: Changes in the tear protein patterns of diabetic patients using two-dimensional electrophoresis. Adv Exp Med Biol. 2002, 506: 623-626.
Molloy MP, Bolis S, Herbert BR, Ou K, Tyler MI, van Dyk DD, Willcox MD, Gooley AA, Williams KL, Morris CA, et al: Establishment of the human reflex tear two-dimensional polyacrylamide gel electrophoresis reference map: new proteins of potential diagnostic value. Electrophoresis. 1997, 18 (15): 2811-2815.
Reitz C, Breipohl W, Augustin A, Bours J: Analysis of tear proteins by one- and two-dimensional thin-layer iosoelectric focusing, sodium dodecyl sulfate electrophoresis and lectin blotting. Detection of a new component: cystatin C. Graefes Arch Clin Exp Ophthalmol. 1998, 236 (12): 894-899.
Fung KY, Morris C, Sathe S, Sack R, Duncan MW: Characterization of the in vivo forms of lacrimal-specific proline-rich proteins in human tear fluid. Proteomics. 2004, 4 (12): 3953-3959.
Grus FH, Podust VN, Bruns K, Lackner K, Fu S, Dalmasso EA, Wirthlin A, Pfeiffer N: SELDI-TOF-MS ProteinChip array profiling of tears from patients with dry eye. Invest Ophthalmol Vis Sci. 2005, 46 (3): 863-876.
Versura P, Nanni P, Bavelloni A, Blalock WL, Piazzi M, Roda A, Campos EC: Tear proteomics in evaporative dry eye disease. Eye (Lond). 2010, 24 (8): 1396-1402.
Zhou L, Huang LQ, Beuerman RW, Grigg ME, Li SF, Chew FT, Ang L, Stern ME, Tan D: Proteomic analysis of human tears: defensin expression after ocular surface surgery. J Proteome Res. 2004, 3 (3): 410-416.
Csosz E, Boross P, Csutak A, Berta A, Toth F, Poliska S, Torok Z, Tozser J: Quantitative analysis of proteins in the tear fluid of patients with diabetic retinopathy. J Proteomics. 2012, 75 (7): 2196-2204.
Berta A: Standardization of tear protein determinstions: the effects of sampling, flow rate, and vascular permeability. The preocular tear film in health, disease, and contact lens wear. Edited by: Holly FJ. 1986, Lubbock: Dry Eye Institute, 418-435.
Karatzoglou A, Hornik K, Smola A, Zeileis A: Kernlab–An S4 Package for Kernel Methods in R. J Stat Softw. 2004, 11: 9-
R: A language and environment for statistical computing: http://www.r-project.org/,
White FM: The potential cost of high-throughput proteomics. Sci Signal. 2011, 4 (160): pe8-
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2415/13/40/prepub
Acknowledgements
This work was supported in part by the Baross Gábor grant, EA_SPIN_06-DIABDIAG, “Proteomic platform for diabetic retinopathy”, TAMOP-4.2.2.A-11/1/KONYV-2012-0045 grant and the TECH08-2 project DRSCREEN, “Developing a computer based image processing system for diabetic retinopathy screening” of the National Office for Research and Technology, Hungary and by the KMA 0149/3.0 grant from the Research Fund Management and Research Exploitation and the Bioincubator House project. This work was supported in part by the project TAMOP-4.2.2.C-11/1/KONV-2012-0001 supported by the European Union, co-financed by the European Social Fund, and by the OTKA grant NK101680. The authors thank Katalin Szabo and Szilvia Peto for their technical assistance. Tunde Peto was supported by NIHR Biomedical Research Centre for Ophthalmology, at Moorfields Eye Hospital NHS Foundation Trust and UCL Institute of Ophthalmology. The authors gratefully acknowledge the support of Peterborough KM Hunter Charitable Foundation, The Canadian Institutes for Health Research Grant #96566, and the Ontario Ministry of Health and Long-Term Care. The views expressed in this publication are the views of the authors and do not necessarily reflect the views of the Ontario Ministry of Health and Long-Term Care.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
ZST carried out the initiation of the research, management and manuscript writing. TP took part in the patient stratification and manuscript writing. JT and ECS participated in the tear sample processing and proteomics experiments. ET carried out the statistics, the data analysis and the mathematical model development. AMM partook in the evaluation of the validity of screening and manuscript writing. ZSMSZ participated in manuscript writing, clinical data collection and in its integration. AB and VN helped in carrying out the patient examination, the diagnosis, the tear sample collection and photodocumentation. AH performed the mathematical model development. BD carried out the programming, the data analysis and visualisation, the machine learning and mathematical model development. ACS acted as supervisor, took part in project management, helped in patient examination, diagnosis, tear sample collection and photodocumentation. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Torok, Z., Peto, T., Csosz, E. et al. Tear fluid proteomics multimarkers for diabetic retinopathy screening. BMC Ophthalmol 13, 40 (2013). https://doi.org/10.1186/1471-2415-13-40
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2415-13-40