
Abstract
Background
Cognitive decline is a major threat to well being in later life. Change scores and regression based models have often been used for its investigation. Most methods used to describe cognitive decline assume individuals lose their cognitive abilities at a constant rate with time. The investigation of the parametric curve that best describes the process has been prevented by restrictions imposed by study design limitations and methodological considerations. We propose a comparison of parametric shapes that could be considered to describe the process of cognitive decline in late life.
Attrition plays a key role in the generation of missing observations in longitudinal studies of older persons. As ignoring missing observations will produce biased results and previous studies point to the important effect of the last observed cognitive score on the probability of dropout, we propose modelling both mechanisms jointly to account for these two considerations in the model likelihood.
Methods
Data from four interview waves of a population based longitudinal study of the older population, the Cambridge City over 75 Cohort Study were used. Within a selection model process, latent growth models combined with a logistic regression model for the missing data mechanism were fitted. To illustrate advantages of the model proposed, a sensitivity analysis of the missing data assumptions was conducted.
Results
Results showed that a quadratic curve describes cognitive decline best. Significant heterogeneity between individuals about mean curve parameters was identified. At all interviews, MMSE scores before dropout were significantly lower than those who remained in the study. Individuals with good functional ability were found to be less likely to dropout, as were women and younger persons in later stages of the study.
Conclusion
The combination of a latent growth model with a model for the missing data has permitted to make use of all available data and quantify the effect of significant predictors of dropout on the dropout and observational processes. Cognitive decline over time in older persons is often modelled as a linear process, though we have presented other parametric curves that may be considered.
Similar content being viewed by others

Background
Severe changes in the population pyramid have been acknowledged by international organisations such as the United Nations [1]. It has been estimated that the number of persons older than 60 years will be around 2 billion by the year 2050 [2]. They will represent more than a third of the total population in developed regions. In least developed regions, similar changes in society will still be seen though on a smaller scale [3]. These changes in the population present challenges for society and individuals. Countries need to plan and implement strategies to cope with the increase in the demand of health and social services from the older segments of the population [4].
At the individual level, the loss of physical and mental health are two main threats to the enjoyment of wellbeing in older ages and to the costs and health of carers. Age associated diseases such as dementia including Alzheimer's disease represent serious threats to healthy life of older persons and their carers. These diseases already affect over half a million people in England and Wales [5].
As a central feature of the ageing process, understanding and measuring changes in cognitive function has therefore become a key issue for society and researchers.
Many tests have been used to measure cognition, although the Mini Mental Status Examination [6] is the most widely used tool to assess global cognition. Many population based longitudinal studies of the older population have used this test to both identify individuals who are likely to have dementia cross sectionally and also to investigate decline, despite its origins as a screening instrument for dementia.
The MMSE can detect decline and correlates with biological and neuropathological markers associated with the dementias [7]. It takes integer values in the 0–30 interval, with higher values indicating good cognitive function.
Historically, change has been regarded as an incremental or as a continuous process [8]. When regarded as an incremental process, most authors have calculated change scores to quantify it [9–12] and then grouped individuals according to the magnitude of the change observed. When regarded as a continuous process, various forms of regression analysis, mixed effects models [13], generalised estimating equations [14] and unconditional latent growth analysis [15] have been used to investigate cognitive change.
There is large literature on age-based models fitted to examine change in specific cognitive abilities [16–23] that reported a non-linear decline. However, a review of the literature showed that often [24–28] change in global MMSE has been modelled fitting linear lines without further investigation of the trajectory shape that best describes the process. Yet, evidence suggests that the assumption of MMSE scores changing at a constant rate with time cannot be regarded as satisfactory. For instance, when semi parametric techniques were used to investigate cognitive decline before dementia diagnosis [29], it was found not to be linear. Several other studies have also identified an accelerated loss of cognition before death [30–33]. These findings suggest that further investigation of model shape is needed in order to understand whether rate of decline remains constant with time or not.
Limitations for further exploration of parametric curves that could fit the data were sometimes imposed by the study design. For instance, Backman et al. [24] reflect on the fact that as in the Kungsholmen study only two data waves were available, they could only fit a straight line model as it was the only model identifiable. Yet, they reckon that the issue of investigating other functions deserved further consideration. Korten et al. [27] and Christensen et al. [34] in the Canberra study, were in a similar position due to the lack of a sufficient number of interview waves to assure identification of higher order models.
The effect of attrition is a major issue in longitudinal studies of the older population as individuals are more likely to die during the duration of the study or are too frail to be interviewed. If inferences about population decline are made without accounting for them results are likely to be biased towards less observed decline [35]. Methods previously used to investigate change either use the complete subsample only as in change scores, assume a missing completely at random mechanism without an explicit formulation of a missing data model as in generalised estimating equations [35], or a missing at random mechanism as in the parametric and semiparametric versions of random effects models [35].
In this paper, we fitted a linear, a quadratic and two piecewise latent growth models with the aim of investigating further possible functional shapes to describe cognitive decline in older age. These latent growth models included a model to describe the missing data mechanism and were parameterised within the selection models framework defined by Little and Rubin where the joint distribution of the complete data and a model for the missing data are factorised, conditional on the complete data model [35]. Latent growth models not only permit the estimation of latent variables that quantify marginal change but also individual's growth factors are estimated. Using them, it is possible to calculate model implied person specific trajectories and therefore, satisfy the need of investigating change at the individual level. Moreover, latent growth models allow for the latent variables to be regressed on relevant covariates known to be informative of the process of interest. Latent growth models are robust against a missing at random mechanism even so, the formulation of an explicit model for the missing data mechanism has several advantages. First, as theoretical considerations point to the last observed cognitive score as a strong predictor of dropout, the missing data model allows us to account for it within the model likelihood. Second, it permits the investigation of predictors of dropout at each time point of the study. Additionally, it allows for the possibility of conducting a sensitivity analysis under a range of possible assumptions about the dependence of dropout on unobserved scores [36].
All analyses were carried out in Mplus, Version 4 [36]. This software package uses maximum likelihood estimation techniques. The models fitted required numerical integration for the computations performed using Monte Carlo techniques.
Methods
The data
Data from the Cambridge City over 75 Cohort Study were used to perform the analysis proposed. The main aims of the study were to establish the incidence and prevalence of dementia. Initially, people aged at least 75 years old in 1985 who were registered at five primary care practices in the Cambridge City area were invited to participate in the Cambridge City over 75 Cohort study [37], then called Hughes Hall Project for Later Life. Those who agreed (95% response rate) were screened by trained interviewers in their homes at which socio- demographic information was collected.
This screening interview was followed by a more detailed clinical interview of all participants suspected of having dementia, identified by a cut point of 23 on the MMSE, and a third of those with scores of 24 and 25 points on the MMSE.
Further waves of interviews were carried out to establish incidence of dementia [38]. After baseline (T0), interviews were carried out an average of 2 (T2), 7 (T7) and 9 (T9) years later. Data from the first four interviews were examined here.
Characteristics of individuals at baseline are shown in Table 1.
A small number of participants did not take part in some study waves but rejoined the study later. Data from them were only considered up to their first dropout to produce a non intermittent data set. All participants were observed at baseline, but 43.4, 24.5 and 16.6% of the sample dropped out for the first time at T2, T7 and T9 respectively. These include drop out due to death.
Analysis
MMSE scores from the first four interview waves of the study were analysed using latent growth analysis where the latent variables (mean curve parameters) were adjusted for risk factors for cognitive decline such as education, gender and age cohort at baseline.
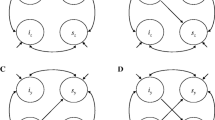
Four models were fitted: a linear, a quadratic and two piecewise models with change points at T2 and T7 respectively. The parameterisation of the models was such that the models' mean intercept represent mean cognitive status at baseline and the mean slope, average rate of change in cognition between T0 and T2. In the quadratic model, the quadratic term represents the rate of change in the linear term. In the piecewise models, the slope of the second piece represents the change in the linear term of the first piece after the change point. Correlations between latent variables were estimated unless fixed to zero to assure model fit. Figure 1 shows a diagram of the linear model fitted with equations in Appendix 1. Latent variables are represented within ellipses and observed variables such as MMSE scores, missing data indicators and risk factors for cognitive decline that were used to adjust the latent variables and the missing data model are represented within rectangles. Straight arrows show how variables are related whereas curved ones represent correlations between the latent variables.

Diagram representing the latent growth linear model fitted.
A missing at random mechanism [35] was fitted using a simplified Diggle and Kenward's model [39]. That is, a logistic regression was fitted to model the probability of an individual missing an interview with the individual's previous score, education, gender, marital status, functional ability, social class and age cohort at baseline as covariates.
Numerical integration is needed to estimate maximum likelihood parameters in latent growth curve models with random effects and missing data. As standard fit indices are not appropriate for these types of models, in order to identify the model that best fits the data, a Bayesian Information Criteria (BIC) based selection was undertaken. As the BIC is a measure of fit that considers the likelihood with a penalisation for the number of parameters, the most parsimonious model would be the one with the lowest BIC and therefore, that model should be chosen as the one with best fit.
Sensitivity of models to normality assumption
Latent growth models require normality of residuals. On visual exploration of this assumption, some departure of normality was identified. To improve the normality of the data, MMSE scores were transformed using the transformation Y it = log(31-MMSE it ) previously applied in the literature [5] and models ran again. Some improvement in model fit was achieved. The quadratic model was the model with the lowest BIC value, and hence, the one with best fit in the transformed scale.
Figure 2 shows estimated mean curves obtained from fitting the models to transformed scores and the curves obtained after back- transforming these estimated curves.

The plot on the left shows the mean curve of scores obtained after applying the transformation Y it = log(31-MMSE it ) to MMSE scores and the mean estimated curves obtained from fitting a linear, a quadratic and two change point models to these transformed scores. On the right, the back-transformed curves are shown.
The results obtained from fitting the models to raw data are presented furtehr for two main reasons. First, the main aim of our investigation was to show a range of parametric models that can be used to model cognitive change taking into account the missing data. And second, the interpretation of the back transformed models is complex when non-linear or non-isometric transformations are applied in these models.
Results
Table 2 shows model parameters of the four models fitted. For the four models, parameters presented consist of the estimated mean initial score represented by the intercepts of the mean curves and rate of change represented by the slopes of the models. For the quadratic term, an estimate of the curvature of the mean curve was also estimated; whilst for the piecewise models, there is an estimate of the slope of the second piece.
In the linear and quadratic models, there was significant variability about the models' intercept and slope, an indication of heterogeneity of individuals about these parameters. The correlation between the intercept and slope in the linear model was estimated as 0.64 (st. error = 0.08), and in the quadratic, at -0.47 (1.79). The correlation of the quadratic term with the intercept was estimated at -0.11 (st. error = 0.07) in the quadratic model, and with the slope at -0.03 (st. error = 0.02). In the two piecewise models the variances of the two slopes were fixed at zero to achieve better model fit.
At all interviews, MMSE scores before dropout of those who dropped out were significantly lower than for those who remained in the study (t-tests, df = 1957, level 5%, p < 0.01 for all interviews).
All models consistently showed those with lower previous scores and lower functional ability as more likely to miss an interview. At the second and third interviews, women were less likely to dropout. Those in the youngest cohort interview were also found to be more likely to be observed in the fourth interview.
BIC values of the four models fitted were estimated at 27956.1, 27890.1, 28217.2 and 28179.3 for the linear, quadratic and the piecewise models with change points at T2 and T7 respectively. These BIC values identified the quadratic model as the model with best fit.
The same models were run without an explicit formulation of a model for the missing data. In all models, estimated slopes indicated less decline. For instance, in the case of the linear model, the mean slope was estimated at -0.7 (st. error = 0.09), a value that suggests a smoother decline when compared to the slope estimated by the linear model formulated within the selection modelling framework (estimate = -0.9, st error = 0.1). Factor scores were also estimated at different values, in particular, individual specific slopes were consistently estimated at higher values than the slopes estimated by the model with a formultation of the missing data model.
One of the main advantages of our proposed models is that they can be easily extended to model a non-ignorable missing data mechanism. This could be used to perform a sensitivity analysis of the missing data assumptions. We extended the work of Dufouil et al. [40], where a sensitivity analysis of the missing data assumptions was conducted by choosing a range of plausible values for the regression coefficients of the unobserved scores on the logistic regression used to model the missing data mechanism. In Dufouil et al. [40], a constant value was considered over time as the assumed coefficient for the unobserved MMSE score. In our example, under the hypothesis that the unobserved MMSE score has an increasing effect on the probability of the individuals missing an interview over time, we considered increasing coefficients for these unobserved scores.
To illustrate the method, results obtained from the quadratic model are presented in Tables 3 &4. These results show, for instance, that the non-ignorable model produced larger odds of missing an interview given the last observed score than the missing at random missing data model.
Discussion
Overall, we propose that the use of latent growth models to investigate cognitive decline at the marginal and individual level provides researchers with good opportunities that represent advancement with respect to methods previously used in the field. Change scores are known to be severely affected by reliability issues [41]. Furthermore, covariates that might be informative about the cognitive process cannot be included in most versions of change scores.
On the other hand, some regression based analysis are not suitable for the correlated measures that are observed in longitudinal data. Despite generalised estimating equations being more flexible in this regard, estimates of change at the individual level are not easily obtained. When mixed effects models are used, random effects are often not reported [42].
Latent growth analysis is flexible enough to estimate the full trajectory of change at the mean level also producing individual's growth factors that permit the reconstruction of individual's trajectories that are of interest to clinicians [43]. Distributional assumptions of latent growth models require normality of residuals.
To improve the fulfilment of this assumption, we transformed scores and ran all models using the resulting scores. Results obtained from transformed data showed some improvement in the satisfaction of the normality assumption and identified the quadratic as the model that fits the data best in the transformed scale. However, thoughtful consideration needs to be exercised in the interpretation of back-transformed results as parameter estimates apply to the transformed scale not the original MMSE scale. As the purpose of the paper is the illustration of the method proposed, and the interpretation of results is natural in the original MMSE scale, we opted for the presentation of all other results in the MMSE scale.
Our analysis of cognitive decline in older persons over a 9 year longitudinal has identified the quadratic curve as the one that best fits the data. The quadratic model suggests an initial drop followed by a deceleration in the rate of decline expressed by a positive quadratic term. A relatively small annualised rate of decline was estimated (around 1.14 points) in our study, a finding that agrees with other studies. For instance, Jacqmin-Gadda [26] found very small change after the first two interviews, in which an improvement in MMSE scores was detected. Similarly, Feskens [44] and Brayne [45] working with two waves of data have also identified a small change in the samples analysed. Also, although working with an expanded MMSE, researchers in the Canadian Study [11] found that 70.6% of the sample did not change between the first two interviews, another 62.5% exhibited little change between interviews two and three and almost 50% remained stable for the 10 years of the study. A similar non-linear decline has also been identified in studies where change in specific cognitive abilities [16–23] was examined. This behaviour may be a consequence of a survivor effect or could also be explained by the plateau described by Wernicke and Reischies [46], after which individuals do not decline any further.
Attrition has severe effects on studies of older people. In the literature different levels of analysis of the missing data mechanism present in the samples can be found. For instance, in studies where change scores were used to model change [47–50] individuals with missing observations were removed from the analysis sample. The main consequence of such practice is a bias in results towards less observed decline [35]. In Jacqmin-Gadda et al., Amieva et al., Korten et al. and Royall et al. [26, 27, 29, 51] where mixed random effect models and latent growth models were fitted, estimates that are robust against a missing at random mechanism were obtained but an explicit model for the missing data mechanism was not provided. Dufouil et al. [40] investigated marginal change accounting for the missing observations using inverse probability weighting to reduce the bias produced on observed data assuming an informative missing data mechanism. All other studies have relied on the robustness of the estimates against a missing at random mechanism.
Instead, we have opted for the actual modelling of the mechanism using Diggle and Kenward's logistic regression model. This was important as by explicitly modelling the missing data, we were able to quantify the effect of the last observed score on probability of dropout at each interview and to fully account for the effect of previous MMSE scores within the full model likelihood. We believe that the explicit formulation of a model for the missing data mechanism is a novel practise that is necessary to fully inform the measurement model in order to provide an accurate description of the cognitive change experimented by older individuals.
Furthermore, it raises further opportunities for conducting sensitivity analyses of the models with respect to the missing data as shown.
Our results agree with previous studies in which a missing at random mechanism was present in the data. Yet, we found that women are less likely to drop out than men at later interviews, as opposed to the findings by Van Beijsterveldt et al. [52]. Our findings regarding older individuals being more likely to drop out agree with theirs.
Perhaps one of the disadvantages of our study is the large amount of missing data after the second interview. This is common in most studies of the older population and the fact that a missing data model was implemented should smooth its consequences regarding parameter estimates. Our models could benefit from the inclusion of further variables such as the person's cardiovascular disease history, genetic data and social network, for instance. They would not only inform the measurement model, but also the missing data model. Another key variable that would benefit the understanding of the process is the reason for dropout. If information was available about the cause of drop out, then it would be plausible to perform a competing risk analysis or a multiple group analysis discriminating by reason for drop out. This is under investigation at the moment.
Another possible limitation of the study is the fact that we considered a growth model based on 'time in study' rather than on the individual's age at each interview, an approach that facilitated the fit of the missing data model based on fixed times of observation. The discussion about the most suitable temporal matrix to describe cognitive change is contentious [53–56] and when multiple cohorts are examined, age-based models are likely to provide a better description of age related cognitive decline. However, by adjusting our models by age defined cohorts, we compensated the impact of using a fixed time basis and were able to model the missing data process simultaneously.
Our research has proved that making parametric assumptions when investigating a process as complex as the loss of cognitive function as measured by the MMSE in older ages deserves thorough consideration.
Conclusion
Our study has showed that cognitive decline in older persons is not a linear process. The quadratic growth model, identified as the one with best fit, permitted the estimation of initial mean cognitive status, rate of decline and of its change. Estimates of person specific parameters were produced.
Significant heterogeneity between individuals in initial cognitive status and rate of decline was identified.
By fitting a latent growth model, we maximised the use of all data available to investigate cognitive change in older persons. Individuals with lower previous cognitive scores have been identified as more likely to drop out.
Appendix 1
The latent linear growth model represented in Figure 1 can be formulated in mathematical terms as:
MMSE it = λ 0t I i + λ 1t S i + e it
I i = α00 + α01 Z i + u 0i
S i = α10 + α11 Z i + u 1i
where i = 1...N, with N the number of individuals in the sample and t = 0,2,7,9 the number of years past after the initial interview.
λ0t and λ1t are factor loadings with λ0t fixed to one, and e it ; u 0i and u 1i normally distributed random errors such that E(e it ) = 0 for i = 1...N, t = 0,2,7,9; E(u 0i ) = 0 for i = 1...N, E(u 1i ) = 0 for i = 1...N;Cov(e it ,u 0i ) = 0 and Cov(e it ,u 1i ) = 0 for i = 1...N, t= 0,2,7,9; Cov(u 1j ,u 1i ) = 0 and Cov(u 0j ,u 0i ) = 0 for i ≠ j.
The missing data mechanism was modelled using a logistic regression model, where the probability of individual i being missing at time t, p it was modelled as:
log it(p it ) = γ it MMSE i(t-1) + Σδ iνi1 + ε1τ;
where ν i1 are model covariates and ε1τ are residuals that follow a logistic distribution.
Appendix 2
Basic Mplus code for linear model:
TITLE:
DATA: (data file location)
VARIABLE: NAMES ARE (name declaration);
CLASSES = c(1);
USEVARIABLES = sc1 sc2 sc3 sc4 married sclass mob
educ miss2 miss3 miss4 women young interm;
MISSING = ALL(-999);
CATEGORICAL ARE miss2 miss3 miss4;
ANALYSIS: TYPE = MIXTURE MISSING RANDOM;
algorithm = integration;
integration = montecarlo;
MODEL:
%OVERALL%
i s | sc1@0 sc2@2 sc3@7 sc4@9;
i s ON educ women young interm;
miss2 ON sc1 educ married sclass mob women young interm;
miss3 On sc2 educ married sclass mob women young interm;
miss4 On sc3 educ married sclass mob women young interm;
sc3; sc2;
%c#1%
i s ON educ women young interm;
OUTPUT: cinterval;
SAVEDATA:
RESULTS ARE (file location);
SAVE = FSCORES;
References
Population Division, United Nations Experts: Group meeting on social and economic implications of changing population age structure. Department of Economic Affairs.
Population Division, United Nations: Population Challenges and Development Goals. Department of Economic Affairs.
Population Division, United Nations: National trends in population, resources, environment and development 2005: country profiles. Department of Economic and Social Affairs.
Population Division, United Nations: UN world population policies. 2005
MRC CFAS: Cognitive function and dementia in six areas of England and Wales: the distribution of MMSE and prevalence of GMS organicity level in the MRC CFAS study. Psychol Med. 1998, 29 (2): 319-335.
Folstein MF, Folstein SE, McHugh PR: Mini-Mental State: a practical method for grading the state of patients for the clinician. J Psych Res. 1975, 12: 189-198. 10.1016/0022-3956(75)90026-6.
Xuereb J, Brayne C, Dufouil C, Gertz H, Wischik C, Harrington C, Mukaetova-Ladinska E, McGee MA, O'Sullivan A, O'Connor D, Paykel ES, Huppert FA: Neuropathological findings in the very old: results from the first 101 brains of a population based longitudinal study of dementing disorders. Ann NY Acad Sci. 2000, 903 (Suppl): 490-496. 10.1111/j.1749-6632.2000.tb06404.x.
Francis DJ, Fletcher JM, Stuebing KK, Davidson CK, Thompson NM: Analysis of change: modeling individual growth. J Consult Clin Psychol. 1991, 59 (1): 27-37. 10.1037/0022-006X.59.1.27.
Ganguli M, Seaberg E, Ratcliff G, Belle S, Dekosky S: Cognitive stability over 2 years in a rural elderly population: the MoVIES project. Neuroepidemiology. 1996, 15: 42-50. 10.1159/000109888.
Kliegel M, Sliwinski M: MMSE cross domain validity predicts cognitive decline in centenarians. Gerontology. 2004, 50 (1): 39-43. 10.1159/000074388.
McDowell I, Xi G, Lindsay L, Tuokko H: Canadian Study of Health and Aging: study description and patterns of early cognitive decline. Aging Neuropsychol Cog. 2004, 11 (2–3): 149-168.
Dik M, Pluijm S, Jonker C, Deeg D, Lomecky M, Lips P: Insulin-like growth factor I (IGF-I) and cognitive decline in older persons. Neurobiol Aging. 2003, 25 (2): 573-581. 10.1016/S0197-4580(02)00136-7.
Laird NM, Ware JH: Random effects models for longitudinal data. Biometrics. 1982, 38: 963-974. 10.2307/2529876.
Liang KJ, Zeger SL: Longitudinal data analysis using generalized linear models. Biometrika. 1986, 73: 13-22. 10.1093/biomet/73.1.13.
Meredith W, Tisak J: On "Tuckerizing" curves. 1984, Presented at the annual meeting of the Psychometric Society, Santa Barbara, California
Finkel D, Reynolds CA, Mc Ardle JJ, Gatz M, Pedersen NL: Latent growth curve analyses of accelerating decline in cognitive abilities in late adulthood. Dev Psychol. 2003, 33 (3): 535-550. 10.1037/0012-1649.39.3.535.
Finkel D, Reynolds CA, Mc Ardle JJ, Gatz M, Pedersen NL: Age changes in processing speed as a leading indicator of cognitive aging. Psychol Aging. 2007, 22 (3): 558-568. 10.1037/0882-7974.22.3.558.
Ghisletta P, Ribaupierre A: A dynamic investigation of cognitive dedifferentiation with control for retest: evidence from the Swiss Interdisciplinary Longitudinal Study of the oldest old. Psych Aging. 2007, 20 (4): 671-682. 10.1037/0882-7974.20.4.671.
Ghisletta P, Linderberger U: Age based structural dynamics between perceptual speed and knowledge in the Berlin Aging Study: direct evidence for ability dedifferentiation in old age. Psychol Aging. 2003, 18 (4): 696-713. 10.1037/0882-7974.18.4.696.
McArdle JJ, Ferrer-Caja E, Hamagami F, Woodcock RW: Comparative longitudinal structural analyses of the growth and decline of multiple intellectual abilities over the life span. Dev Psychol. 2002, 38 (1): 115-142.
Reynolds CA, Finkel D, Gatz M, Pedersen NL: Sources of influence on rate of cognitive change over time in Swedish twins: an application of latent growth models. Exp Aging Res. 2002, 28 (4): 407-433. 10.1080/03610730290103104.
Sliwinski MJ, Stawski RB, Hall CB, Katz M, Verghese J, Lipton RB: Distinguishing pre-terminal and terminal cognitive decline. European Psychol. 2006, 11 (3): 172-181. 10.1027/1016-9040.11.3.172.
Dominicus A, Ripatti S, Pedersen N, Palmgren J: Modelling variability in longitudinal data using random change point models. Research reports in mathematical statistics. 2006, University of Stockholm
Backman L, Jones S, Small B, Aguero-Torres H, Fratiglioni L: Rate of cognitive decline in preclinical Alzheimer's disease: the role of comorbidity. J Gerontol B Psychol Sci Soc Sci. 2003, 58B (4): 228-236.
Baker DW, Gazmararian JA, Sudano J, Patterson M, Parker RM, Williams MV: Health literacy and performance on the Mini Mental State Examination. Aging Ment Health. 2002, 6 (1): 22-29. 10.1080/13607860120101121.
Jacqmin-Gadda H, Fabrigoule C, Commenges D, Dartigues JF: A 5-year longitudinal study of the Mini Mental State Examination in normal aging. Am J Epidemiol. 1997, 145 (6): 498-506.
Korten AE, Henderson AS, Christensen H, Jorm AF, Rodgers B, Jacomb P, Mackinnon AJ: A prospective study of cognitive function in the elderly. Psychol Med. 1997, 27: 919-930. 10.1017/S0033291797005217.
Kliegel M, Moor C, Rott C: Cognitive status and development in the oldest old: a longitudinal analysis from the Heidelberg Centenarian Study. Arch Gerontol Geriatr. 2004, 39 (2): 143-56. 10.1016/j.archger.2004.02.004.
Amieva H, Jacqmin-Gadda H, Orgogozo JM, Le Carret N, Helmer C, Barberger Gateau P, Fabrigoule C, Dartigues JF: The 9 year cognitive decline before dementia of the Alzheimer type: a prospective population based study. Brain. 2005, 128: 1093-1101. 10.1093/brain/awh451.
Kliegel M, Moor C, Rott C: Cognitive status and development in the oldest old: a longitudinal analysis from the Heidelberg Centenarian Study. Arch Gerontol Geriatr. 2004, 39 (2): 143-56. 10.1016/j.archger.2004.02.004.
Rabbitt P, Watson P, Donlan C, Mc Innes L, Horan M, Pendleton N, Clague J: Effects of death within 11 years on cognitive performance in old age. Psychol Aging. 2002, 17 (3): 468-81. 10.1037/0882-7974.17.3.468.
Wilson RS, Beck TL, Bienas JL, Bennett DA: Terminal cognitive decline: accelerated loss of cognition in the last years of life. Psychosom Med. 2007, 69 (2): 131-137. 10.1097/PSY.0b013e31803130ae.
Wilson RS, Beck TL, Evans DA, Bienas JL, Bennett DA: Terminal decline in cognitive function. Neurology. 2003, 60 (11): 1781-1787.
Christensen H, Hofer S, Mackinnon AJ, Korten AE, Jorm AF, Henderson AS: Age is no kinder to the better educated: absence of an association investigated using latent growth techniques in a community sample. Psychol Med. 2001, 31: 15-28. 10.1017/S0033291799002834.
Little R, Rubin D: Statistical data analysis with missing data. 1987, John Wiley and Sons, College Station, Texas
Muthen LK, Muthen BO: Mplus User's Guide. Los Angeles, CA: Muthen & Muthen, 1998–2004, 3
Brayne C, Huppert F, Paykel E, Gill C: The Cambridge Project for Later Life: Design and preliminary results. Neuroepidemiology. 1992, 11 (Suppl 1): 71-75. 10.1159/000110983.
Paykel ES, Brayne C, Huppert FA, Gill C, Barkely C, Gehlaar E, Beardsall L, Girling DM, Pollitt P, O' Connor D: Incidence of dementia in a population older than 75 years in the United Kingdom. Arch Gen Psychiatry. 1994, 51: 325-332.
Diggle P, Kenward MG: Informative dropout in longitudinal data analysis. J Appl Stat. 1994, 43: 49-93. 10.2307/2986113.
Dufouil C, Brayne C, Clayton D: Analysis of longitudinal studies with death and drop out: a case study. Stat Med. 2004, 23: 2218-2226. 10.1002/sim.1821.
Zimmerman DW, Williams RH: Gain scores in research can be highly reliable. J Educ Meas. 1982, 19: 149-154. 10.1111/j.1745-3984.1982.tb00124.x.
Wallace D, Green S: Analysis of repeated measures designs with linear mixed models. modelling intraindividual variability with repeated measures data: methods and applications. Edited by: Moskowitz DS, Hershberger, S. 2002, Lawrence Erlbaum Ass. NJ
Martin M, Hofer S: Intraindividual variability, change, and ageing: conceptual and analytical issues. Gerontology. 2004, 50: 7-11. 10.1159/000074382.
Feskens EJ, Havek LM, Kalmijn S, Knijff PD, Launer LJ, Kromhout D: Apolipoprotein ε-4 allele and cognitive decline in elderly men. Br Med J. 1994, 309: 1202-1206.
Brayne C, Gill C, Paykel ES, Huppert F, O'Connor DW: Cognitive decline in an elderly population-a two wave study of change. Psychol Med. 1995, 25 (4): 673-683.
Wernicke TF, Reischies FM: Prevalence of dementia in old age: clinical diagnosis in subjects aged 95 years and older. Neurology. 1994, 44: 250-253.
Eslinger PJ, Swan GE, Carmelli D: Changes in MMSE in community dwelling older persons over 6 years: relationship to health and neuropsychological measures. Neuroepidemiology. 2003, 22 (1): 23-30. 10.1159/000067113.
Frerichs RJ, Tuokko HA: A comparison of methods for measuring cognitive change in older adults. Arch Clin Neuropsychol. 2005, 20: 321-333. 10.1016/j.acn.2004.08.002.
Tombaugh T: Test-retest reliable coefficients and 5 year change scores for the MMSE and 3MS. Arch Clin Neuropsychol. 2005, 20: 485-503. 10.1016/j.acn.2004.11.004.
Kliegel M, Sliwinski M: MMSE cross domain validity predicts cognitive decline in centenarians. Gerontology. 2004, 50 (1): 39-43. 10.1159/000074388.
Royall D, Palmer R, Chiodo L, Polk M: Normal rates of cognitive change in successful aging: the Freedom House study. J Int Neuropsychol Soc. 2005, 11 (7): 899-909. 10.1017/S135561770505109X.
Van Beijsterveldt CEM, van Boxtel MPJ, Bosma H, Houx PJ, Buntix F, Jolles J: Predictors of attrition in a longitudinal cognitive aging study: The Maastricht Aging Study (MAAS). J Clin Epidemiol. 2002, 55 (3): 16-223. 10.1016/S0895-4356(01)00473-5.
Hofer S, Sliwinski M: Understanding Ageing. An evaluation of research designs for assessing the interdependence of ageing-related changes. Gerontology. 2001, 47: 341-352. 10.1159/000052825.
Sliwinski M, Buschke H: Modeling intraindividual cognitive change in aging adults: results from the Einstein Aging Studies. Aging Neuropsychology Cog. 2004, 11 (2–3): 196-211. 10.1080/13825580490511080.
Hertzog C, Dixon R, Hultsch D, MacDonald S: Latent change models of adult cognition: are changes in processing speed and working memory associated with changes in episodic memory?. Psychol Aging. 2003, 18 (4): 755-769. 10.1037/0882-7974.18.4.755.
Mendes de Leon , Carlos F: Aging and the effect of time: a comment on the analysis of change. J of Gerontology, Social Sciences. 2007, 62B (3): S198-S202.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2377/8/16/prepub
Acknowledgements
We thank all study participants, their relatives and carers for their invaluable help. We also thank all our past sponsors for financial support spanning two decades (project grants from the Charles Wolfson Charitable Trust, Medical Research Council, Leopold Muller Foundation, East Anglian Regional Health Authority, Anglia and Oxford Regional Health Authority, British Council Joint Research Programme in Progressive Degenerative Diseases, Edward Storey Foundation, Research into Ageing and Addenbrooke's Hospital Alzheimer's Disease Research Fund and fellowship awards including Wellcome Trust Prize PhD Studentship, Isaac Newton Trust Research Fellowship, Taiwan Government PhD Studentship, Anglia and Oxford Regional Health Authority Training Fellowship and the National Health Service Executive Research and Development Unit Health Services Research Fellowships) and are grateful to the BUPA Foundation for ensuring the study continues today. FM is fundeed by MRC. U. 1052.00.004
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
GM ran the analysis and produced the manuscript, FM contributed with comments on analysis and manuscript and CB contributed with comments on the manuscript. CB is a principal investigator of the CC75C study. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Muniz Terrera, G., Matthews, F. & Brayne, C. A comparison of parametric models for the investigation of the shape of cognitive change in the older population. BMC Neurol 8, 16 (2008). https://doi.org/10.1186/1471-2377-8-16
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2377-8-16