
Abstract
Background
Large, population-based administrative healthcare databases can be used to identify patients with chronic kidney disease (CKD) when serum creatinine laboratory results are unavailable. We examined the validity of algorithms that used combined hospital encounter and physician claims database codes for the detection of CKD in Ontario, Canada.
Methods
We accrued 123,499 patients over the age of 65 from 2007 to 2010. All patients had a baseline serum creatinine value to estimate glomerular filtration rate (eGFR). We developed an algorithm of physician claims and hospital encounter codes to search administrative databases for the presence of CKD. We determined the sensitivity, specificity, positive and negative predictive values of this algorithm to detect our primary threshold of CKD, an eGFR <45 mL/min per 1.73 m2 (15.4% of patients). We also assessed serum creatinine and eGFR values in patients with and without CKD codes (algorithm positive and negative, respectively).
Results
Our algorithm required evidence of at least one of eleven CKD codes and 7.7% of patients were algorithm positive. The sensitivity was 32.7% [95% confidence interval: (95% CI): 32.0 to 33.3%]. Sensitivity was lower in women compared to men (25.7 vs. 43.7%; p <0.001) and in the oldest age category (over 80 vs. 66 to 80; 28.4 vs. 37.6 %; p < 0.001). All specificities were over 94%. The positive and negative predictive values were 65.4% (95% CI: 64.4 to 66.3%) and 88.8% (95% CI: 88.6 to 89.0%), respectively. In algorithm positive patients, the median [interquartile range (IQR)] baseline serum creatinine value was 135 μmol/L (106 to 179 μmol/L) compared to 82 μmol/L (69 to 98 μmol/L) for algorithm negative patients. Corresponding eGFR values were 38 mL/min per 1.73 m2 (26 to 51 mL/min per 1.73 m2) vs. 69 mL/min per 1.73 m2 (56 to 82 mL/min per 1.73 m2), respectively.
Conclusions
Patients with CKD as identified by our database algorithm had distinctly higher baseline serum creatinine values and lower eGFR values than those without such codes. However, because of limited sensitivity, the prevalence of CKD was underestimated.
Similar content being viewed by others
Background
Chronic kidney disease (CKD) is a permanent reduction in kidney function that can progress to end stage renal disease (ESRD) requiring either ongoing dialysis or a kidney transplant to maintain life. CKD also affects how many medications are eliminated from the body [1]. In routine practice a laboratory serum creatinine value is used to estimate kidney function by incorporating it into a formula to estimate the glomerular filtration rate and establish whether a patient has CKD. However, in some situations there is an interest in identifying CKD using healthcare database codes when laboratory values are not available. Codes in these databases have their limitations and knowledge of their validity guides their optimal use [2]. The purpose of the current study was to develop and examine the validity of algorithms using hospital encounter (International Classification of Diseases, 10th revision [ICD-10]) codes and physician claim codes for the detection of CKD assessed against a reference standard of estimated glomerular filtration rate (eGFR) determined with laboratory values. We hypothesized, based on validations done for other laboratory-based conditions by our research group, that our best performing algorithm would demonstrate limited sensitivity but excellent specificity for the identification of CKD [3–6]. As suggested in the literature, we also hypothesized that code sensitivity would be lower in women compared to men, and lowest in the oldest age category [7].
Methods
Study design
We conducted a retrospective, population-based validation study using linked administrative databases housed at the Institute for Clinical Evaluative Sciences (ICES). The province of Ontario, Canada has approximately 13 million residents, 14% of whom are 65 years of age or older [8]. Residents of Ontario have universal access to hospital care and physician services and those 65 years of age or older have universal prescription drug coverage. Due to the availability of laboratory data, this study was restricted to those individuals aged 65 and older in Southwestern Ontario, which consisted of 80,000 individuals in the year 2006 [9]. We gathered serum creatinine values from 12 regional hospitals in Southwestern Ontario as well as outpatient laboratories. We examined the validity of our primary database algorithm consisting of ICD-10 and physician claims diagnostic codes for detecting CKD by comparing it to eGFR (derived from serum creatinine laboratory values) as the reference standard. Codes of our primary database algorithm were finalized after testing several codes alone or in combination (described below). The reporting of this study follows guidelines for studies of diagnostic accuracy (Additional file 1) [10]. We conducted our study according to a pre-specified protocol that was approved by the institutional review board at Sunnybrook Health Sciences Centre (Toronto, Ontario).
Data sources
We ascertained the presence of relevant comorbidities for exclusions and baseline characteristics using patient records from seven linked databases. The Ontario Drug Benefit (ODB) Plan database contains records of prescriptions for individuals 65 years or older from outpatient pharmacies. The dispensing of medications for patients aged 65 and older is accurately recorded in this database with an error rate of <1% [11]. The Canadian Institute for Health Information (CIHI) National Ambulatory Care Reporting System (NACRS) contains ambulatory care information on emergency room visits, outpatient procedures, and day surgeries. The CIHI Discharge Abstract Database (CIHI-DAD) captures procedures and diagnoses for hospitalized patients in Ontario. The Ontario Health Insurance Plan (OHIP) database contains all physician claims for medical services covered under the provincial health insurance plan. Lastly, the Registered Persons Database (RPDB) contains demographic information, such as birth date and sex, for all Ontario residents who have ever been covered by the provincial healthcare plan.
In addition to the administrative databases described above, we also used two laboratory datasets for baseline serum creatinine values. An electronic medical record, Cerner® (Kansas City, Missouri, USA), contains inpatient, outpatient, and emergency department laboratory values for 12 hospitals in Southwestern Ontario [12]. Additionally, Gamma Dynacare provided all outpatient serum creatinine values for patients serviced by this laboratory provider in Southwestern Ontario. We have successfully used these laboratory datasets linked to administrative data in previous studies [13–15].
Patients
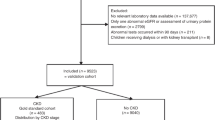
We accrued patients at the time of an outpatient prescription for any medication between July 1, 2007 and December 31, 2010. We focused on outpatient prescriptions based on the assumption that the outpatient setting is most likely to capture individuals at time of clinical stability. In addition, administrative data are often used for pharmacoepidemiologic studies, in which having a prescription is paramount. In Ontario, prescription drug coverage is a universal benefit for patients 65 years of age or older. Almost all older residents in Ontario were expected to have at least one prescription medication dispensed through the provincial drug plan over the accrual period. Patients with multiple prescriptions during the accrual period could only be selected once for cohort entry. To be included, patients must have had at least one serum creatinine laboratory test in the year prior to the prescription date from a laboratory in Southwestern Ontario. Serum creatinine testing amongst older adults is fairly ubiquitous in Ontario, with most individuals having at least one outpatient serum creatinine test in a given year [16]. We considered only patients 66 years of age or older in this study to allow for a minimum of one year of baseline prescription information from the provincial drug plan. We excluded laboratory tests where patients were hospitalized up to two days prior to their prescription date to ensure we captured prescriptions first initiated in the outpatient setting. As we were interested in detecting CKD prior to any treatment for kidney failure, we also excluded patients who received dialysis in the year prior or a kidney transplant in the five years prior to the prescription date.
CKD Database algorithm (Diagnostic test)
Diagnostic codes and their associated attributes are recorded in health administrative databases. For hospital encounters in Canada, trained coders follow specific rules and guidelines set out when assigning diagnostic codes based on a patient’s chart. They cannot interpret any diagnostic tests, such as x-rays or laboratory values, unless a diagnosis is specifically written by the physician in the medical chart [17]. For physician claims, typically clerical personnel employed by a physician submit billing and diagnosis codes for each patient seen in order for the physician to be paid for services provided.
To develop our algorithm to detect CKD two nephrologists reviewed all available ICD-10 and OHIP diagnostic database codes and identified 55 that were deemed potentially relevant (Additional file 1). An individual was classified as algorithm positive for CKD if a code appeared at least once in the five years prior to the outpatient prescription date. We finalized elements of our primary database algorithm using a process described below (see ‘Data Analysis’ section).
Kidney function laboratory values (Reference standard)
GFR was estimated from serum creatinine using the CKD-EPI equation [18, 19]. We chose the most recent serum creatinine value from any setting prior to the outpatient prescription as our test value. If this value was done while a patient was in hospital, this was the most recent value prior to discharge (which helps avoid temporary elevated serum creatinine values due to acute kidney injury where physicians wait for resolution prior to hospital discharge).
Although a recently revised staging system for CKD does exist its use in the elderly remains controversial [20]. Nonetheless, stage IIIb CKD or more is defined by an estimated glomerular filtration rate (eGFR) <45 mL/min per 1.73 m2 and is accepted as a clinically important reduction in kidney function in elderly patients [21]. Furthermore, when creatinine tests are repeated, eGFR values <45 mL/min per 1.73 m2 in the outpatient setting are more stable compared to higher eGFR values [22]. For these reasons we selected our primary threshold to define CKD as an eGFR <45 mL/min per 1.73 m2. However, in additional analyses we also examined thresholds of <60 and <30 mL/min per 1.73 m2. We used thresholds rather than mutually exclusive groups to mimic how inferences about the types of patients detected by the algorithm will be made in practice.
Data analysis
We calculated the sensitivity, specificity, positive predictive value, and negative predictive value of each coding algorithm for each eGFR threshold. We developed a two by two contingency table for each code to assess its validity for detecting CKD (see Additional file 1 for an example). We examined the validity of each code on its own or combined within an algorithm using the Boolean operator “OR”. For our final primary algorithm we combined codes to include those that either had a sensitivity of at least 3% or were conceptually similar to included codes. Because serum creatinine and eGFR are continuous variables, we also contrasted the mean, median, and interquartile ranges of serum creatinine and eGFR values for those who were CKD algorithm positive (i.e. presence of at least one of codes in our final algorithm) compared to those who were CKD algorithm negative (i.e. absence of all of the codes in our final algorithm). We performed additional analyses to further understand the attributes of the CKD algorithm. These included restricting to outpatient only laboratory values, assessing at least two codes in the look-back window, and applying different combinations of renal codes. We calculated 95% confidence intervals (CI) for single proportions using the Wilson Score method [22]. We expressed serum creatinine and eGFR values as medians with interquartile ranges (IQR). We performed all analyses using SAS version 9.2 (SAS Institute Incorporated, Cary, North Carolina, USA, 2008).
Results
Our study included 123,499 patients (patient selection presented in Additional file 1). Patient baseline characteristics are presented in Table 1. The median age was 75 years and 54% of the patients were women. Approximately 23% of our cohort had diabetes, while 40% had coronary artery disease. A total of 15.4% of patients had a measured eGFR study value of <45 mL/min per 1.73 m2. Seventy five percent of serum creatinine values used to estimate GFR were taken from an outpatient laboratory, with the remaining coming from a hospital setting. Of note, 52,081 (42.2%) patients also had an additional serum creatinine test in the 90 to 365 days prior to their study serum creatinine test (average 255 days). The absolute median (IQR) difference in eGFR between the study and prior test was minimal confirming stability of eGFR [5 mL/min per 1.73 m2 (2 to 11 mL/min per 1.73 m2)]. Our final CKD algorithm consisted of 11 codes (with the performance of individual codes and other algorithms presented in Table 2 and Additional file 1). This was an efficient algorithm, as the sensitivity decreased by less than 1.5% while there was an increase in both specificity and positive predictive value compared to the algorithm that used any one of the 55 codes (results of the algorithm of any 55 codes presented in Additional file 1). Using our final algorithm, a total of 9501 (7.7%) patients were classified positive for the CKD database algorithm. The sensitivity of the CKD algorithm for the detection of an eGFR <45 mL/min per 1.73 m2 was 32.7% (95% CI: 32.0 to 33.3%) and the specificity was 96.9% (95% CI: 96.7 to 97.0%). The positive predictive value was 65.4% (95% CI: 64.4 to 66.3%) and negative predictive value was 88.8% (95% CI: 88.6 to 89.0%). When the cohort was restricted to patients with an outpatient serum creatinine value only, we found the performance of the algorithm was not appreciably different (see Additional file 1). Additionally, when at least two codes were required in the look-back window, the sensitivity decreased by approximately 14%, however the positive predictive value increased compared to when at least one code was used.
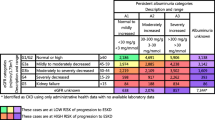
The validity of the algorithm for detection of the additional eGFR thresholds (<60 and <30 mL/min per 1.73 m2) is presented in Table 3. Algorithm sensitivity increased to 58.8% for the detection of more pronounced CKD (eGFR <30 mL/min per 1.73 m2).
Among patients who were positive for our final CKD coding algorithm the median (IQR) serum creatinine value was 135 μmol/L (106 to 179 μmol/L) and for those who were algorithm negative, the value was 82 μmol/L (69 to 98 μmol/L). Similar trends were seen with eGFR; algorithm positive patients had an eGFR of 38 ml/min per 1.73 m2 (26 to 51 ml/min per 1.73 m2) and algorithm negative patients had a value of 69 ml/min per 1.73 m2 (56 to 82 ml/min per 1.73 m2).
Performance of the CKD algorithm stratified by age and sex is presented in Table 4. Algorithm sensitivity was lower in women compared to men (25.7 vs. 43.7%; p <0.001) and in the oldest patients (over 80 vs. 66 to 80; 28.4 vs. 37.6%; p <0.001). Men who were algorithm positive had a median (IQR) eGFR similar to algorithm positive women [40 (28 to 53) vs. 36 (25 to 49) mL/min per 1.73 m2]. Patients in the oldest age category (>80 years) who were positive for the CKD algorithm had a median (IQR) eGFR of 34 mL/min per 1.73 m2 (25 to 45 mL/min per 1.73 m2) compared to 41 ml/min per 1.73 m2 (29 to 55 mL/min per 1.73 m2) in algorithm positive patients in the second oldest age category (66 to 80 years).
Discussion
We developed and assessed the accuracy and validity of algorithms that used hospital encounter and physician claim codes from population-based administrative data in Ontario, Canada to detect CKD. Older patients identified as having CKD by the final database algorithm had higher serum creatinine values and lower eGFR values than those without such codes. Similar to previous studies, our final algorithm demonstrated a high specificity and negative predictive value [6, 7]. For example, the specificity was high (>92%) for all eGFR thresholds and stratified analyses. The high negative predictive value (88.8% for the main eGFR threshold) provides confidence that individuals who are algorithm negative most likely do not have CKD.
The range of sensitivities reported in other CKD validation studies has been broad [6, 7]. Our algorithm demonstrated 33% sensitivity for detecting an eGFR <45 mL/min pre 1.73 m2, and resulted in an appreciable underestimation of disease. In both the current study and a recent study done in Alberta, Canada sensitivity was lowest for detecting milder forms of CKD and improved with disease severity [7]. As coding relies on recorded diagnoses, physicians may be less likely to recognize or act on mild CKD. As well, in both studies algorithm sensitivity was lower in women compared to men, and in older compared to younger elderly patients. These are segments of the population where CKD has traditionally been unrecognized [23]. Differences in code validity by age and sex may lead to biased estimates when assessing CKD risk in certain populations using the database algorithm. In general, the algorithm seems most useful when assessing CKD as a baseline characteristic and when it is not a main variable in an analysis. Given limits in sensitivity, the CKD coding algorithm is also less useful as an outcome measure.
We recently published a systematic review of 19 studies on the validity of algorithms of healthcare administrative database codes to detect CKD [6]. Across the studies, patients were accrued from 1984 to 2004 and some studies included CKD defined by the receipt of dialysis. Most of the studies used an ICD-9 version of the codes. The four studies validating ICD-10 codes for CKD used the reference standard of chart review. This differs from the current study where the preferred reference standard of laboratory values was employed.
Our study has other strengths. The validation follows guidelines set out for studies of diagnostic accuracy [10]. As well, all individuals in Canada receive universal health care. This provided us with access to information from a large number of patients which resulted in estimates with good precision.
Our study does have some limitations. We used a pragmatic approach to algorithm development and only combined codes using the Boolean operator “OR”. We also only defined codes as absent or present based on a fixed window of being present at least once in the prior five years. While we did also assess our main algorithm looking for two codes in the look-back, we found that the loss in sensitivity was not worth the small gain in positive predictive value. Additional efforts could consider more refined methods of combining codes, and or different algorithms focused on maximizing a single performance measure such as specificity. Combining codes could also be done with machine learning which takes information from a variety of sources in an automated fashion to compile the most efficient algorithms [24].
We were interested in developing an algorithm to detect a reduced eGFR. Estimated GFR is the most important parameter of CKD. In clinical practice, two measurements separated by at least three months are required to confirm its presence, while in this study we assessed eGFR at a single point in time (although the single value was stable in the subset of patients with another baseline measurement). It might be useful in the future to develop different algorithms for different levels of low eGFR. As well, the algorithm may not be useful for detecting CKD defined by proteinuria in the absence of low eGFR.
We did not split our sample into derivation and validation subsets. Rather, to confirm similar performance our final CKD algorithm should be tested in other regions and be re-examined in our region at a future time. It is possible that similar physician claim codes included in the algorithm will not operate well in other regions, particularly in jurisdictions without universal health care or without a fee-for-service model. The algorithm should also be validated in younger patients where CKD is less prevalent and serum creatinine testing is less common [25–27].
Finally, it must be recognized that any algorithm will fail to capture individuals who have CKD but do not have a laboratory test to identify its presence in routine care.
Conclusion
We have described the diagnostic properties of an algorithm to detect CKD in the large healthcare administrative databases of Ontario, Canada. This algorithm can be used for health services research and population disease surveillance when serum creatinine results are unavailable. However, the algorithm should be used judiciously given its limited sensitivity.
References
Erler A, Beyer M, Petersen JJ, Saal K, Rath T, Rochon J: How to improve drug dosing for patients with renal impairment in primary care - a cluster-randomized controlled trial. BMC Fam Pract. 2012, 13: 91-10.1186/1471-2296-13-91.
Elixhauser A, Steiner C, Harris DR, Coffey RM: Comorbidity measures for use with administrative data. Med Care. 1998, 36: 8-27. 10.1097/00005650-199801000-00004.
Fleet JL, Shariff SZ, Gandhi S, Weir MA, Jain AK, Garg AX: Validity of the International Classification of Diseases 10th revision code for hyperkalaemia in elderly patients at presentation to an emergency department and at hospital admission. BMJ Open. 2012, 2: e002011-10.1136/bmjopen-2012-002011.
Gandhi S, Shariff SZ, Fleet JL, Weir MA, Jain AK, Garg AX: Validity of the International Classification of Diseases 10th revision code for hospitalisation with hyponatraemia in elderly patients. BMJ Open. 2012, 2: e001727-10.1136/bmjopen-2012-001727
Hwang YJ, Shariff SZ, Gandhi S, Wald R, Clark E, Fleet JL: Validity of the International Classification of Diseases, Tenth Revision code for acute kidney injury in elderly patients at presentation to the emergency department and at hospital admission. BMJ Open. 2012, 2: e001821-10.1136/bmjopen-2012-001821. 10.1136/bmjopen-2012-001821
Vlasschaert ME, Bejaimal SA, Hackam DG, Quinn R, Cuerden MS, Oliver MJ: Validity of administrative database coding for kidney disease: a systematic review. Am J Kidney Dis. 2011, 57: 29-43. 10.1053/j.ajkd.2010.08.031.
Ronksley PE, Tonelli M, Quan H, Manns BJ, James MT, Clement FM: Validating a case definition for chronic kidney disease using administrative data. Nephrol Dial Transplant. 2012, 27: 1826-1831. 10.1093/ndt/gfr598.
Statscan: age and sex, 2006 counts for both sexes, for Canada, provinces and territories, and census divisions. 2010, http://www12.statcan.ca/census-recensement/2006/dp-pd/hlt/97-551/index.cfm?Lang=E. Ref Type: Electronic Citation
Gandhi S, Shariff SZ, Beyea MM, Weir MA, Hands T, Kearns G: Identifying geographical regions serviced by hospitals to assess laboratory-based outcomes. BMJ Open. 2013, 3:
STAndards for the Reporting of Diagnostic accuracy studies checklist. 2003, http://www.stard-statement.org/. 2003. Ref Type: Electronic Citation
Levy AR, O'Brien BJ, Sellors C, Grootendorst P, Willison D: Coding accuracy of administrative drug claims in the Ontario Drug Benefit database. Can J Clin Pharmacol. 2003, 10: 67-71.
Cerner. 2012, http://www.cerner.com/solutions/Hospitals_and_Health_Systems/Laboratory/. 2012. Ref Type: Electronic Citation
Jain AK, Cuerden MS, McLeod I, Hemmelgarn B, Akbari A, Tonelli M: Reporting of the estimated glomerular filtration rate was associated with increased use of angiotensin-converting enzyme inhibitors and angiotensin-II receptor blockers in CKD. Kidney Int. 2012, 81: 1248-1253. 10.1038/ki.2012.18.
Weir MA, Gomes T, Mamdani M, Juurlink DN, Hackam DG, Mahon JL: Impaired renal function modifies the risk of severe hypoglycaemia among users of insulin but not glyburide: a population-based nested case–control study. Nephrol Dial Transplant. 2011, 26: 1888-1894. 10.1093/ndt/gfq649.
Zhao YY, Weir MA, Manno M, Cordy P, Gomes T, Hackam DG: New fibrate use and acute renal outcomes in elderly adults: a population-based study. Ann Intern Med. 2012, 156: 560-569. 10.7326/0003-4819-156-8-201204170-00401.
Garg AX, Mamdani M, Juurlink DN, van WC: Identifying individuals with a reduced GFR using ambulatory laboratory database surveillance. J Am Soc Nephrol. 2005, 16: 1433-1439. 10.1681/ASN.2004080697.
Canadian coding standards for Version 2012 ICD-10-CA and CCI. 2012, https://secure.cihi.ca/free_products/canadian_coding_standards_2012_e.pdf. 2012. Ref Type: Electronic Citation
Kilbride HS, Stevens PE, Eaglestone G, Knight S, Carter JL, Delaney MP: Accuracy of the MDRD (Modification of Diet in Renal Disease) Study and CKD-EPI (CKD Epidemiology Collaboration) Equations for Estimation of GFR in the Elderly. Am J Kidney Dis. 2012, 61: 57-66.
Matsushita K, Mahmoodi BK, Woodward M, Emberson JR, Jafar TH, Jee SH: Comparison of risk prediction using the CKD-EPI equation and the MDRD study equation for estimated glomerular filtration rate. JAMA. 2012, 307: 1941-1951. 10.1001/jama.2012.3954.
Polkinghorne KR: Controversies in chronic kidney disease staging. Clin Biochem Rev. 2011, 32: 55-59.
Levey AS, Coresh J: Chronic kidney disease. Lancet. 2012, 379: 165-180. 10.1016/S0140-6736(11)60178-5.
Newcombe RG: Two-sided confidence intervals for the single proportion: comparison of seven methods. Stat Med. 1998, 17: 857-872. 10.1002/(SICI)1097-0258(19980430)17:8<857::AID-SIM777>3.0.CO;2-E.
Jain AK, McLeod I, Huo C, Cuerden MS, Akbari A, Tonelli M: When laboratories report estimated glomerular filtration rates in addition to serum creatinines, nephrology consults increase. Kidney Int. 2009, 76: 318-323. 10.1038/ki.2009.158.
Meyfroidt G, Guiza F, Ramon J, Bruynooghe M: Machine learning techniques to examine large patient databases. Best Pract Res Clin Anaesthesiol. 2009, 23: 127-143.
Hanlon JT, Wang X, Handler SM, Weisbord S, Pugh MJ, Semla T: Potentially inappropriate prescribing of primarily renally cleared medications for older veterans affairs nursing home patients. J Am Med Dir Assoc. 2011, 12: 377-383. 10.1016/j.jamda.2010.04.008.
McClellan WM, Resnick B, Lei L, Bradbury BD, Sciarra A, Kewalramani R: Prevalence and severity of chronic kidney disease and anemia in the nursing home population. J Am Med Dir Assoc. 2010, 11: 33-41. 10.1016/j.jamda.2009.07.003.
Stevens LA, Coresh J, Greene T, Levey AS: Assessing kidney function–measured and estimated glomerular filtration rate. N Engl J Med. 2006, 354: 2473-2483. 10.1056/NEJMra054415.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2369/14/81/prepub
Acknowledgements
We thank Barbara Jones, Jeff Lamond, and the late Milton Haines for their help in providing access to Gamma-Dynacare laboratory data. We thank the team at London Health Sciences Centre, St. Joseph's Health Care, and the Thames Valley Hospitals for providing access to the Cerner laboratory data.
Funding
This study was conducted at the Institute for Clinical Evaluative Sciences (ICES), which is funded by an annual grant from the Ontario Ministry of Health and Long-Term Care (MOHLTC). The opinions, results, and conclusions reported in this paper are those of the authors and are independent from the funding sources. No endorsement by ICES or the Ontario MOHLTC is intended or should be inferred.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
JLF participated in the coordination of the study, study design, provided interpretation of study results, and drafted the manuscript. SND participated in the study design, performed the analysis and provided interpretation of study results. SZS contributed to the study design and interpretation of study results. DMN, RRQ, and ZH contributed to the study design and provided feedback on the manuscript. AXG conceived of the study, participated in its design and interpretation, helped draft the manuscript and provided feedback on the manuscript. All authors read and approved the final manuscript.
Electronic supplementary material
12882_2012_512_MOESM1_ESM.doc
Additional file 1: Table S1: Standards for the reporting of diagnostic accuracy studies checklist. Table S2. List of all 55 potential chronic kidney disease codes and performance in detecting an estimated glomerular filtration rate of < 45 mL/min per 1.73 m2. All potential codes were reviewed by two nephrologists to identify any potentially relevant renal codes. The final list consisted of 11 of these codes. (DOC 140 KB)
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Fleet, J.L., Dixon, S.N., Shariff, S.Z. et al. Detecting chronic kidney disease in population-based administrative databases using an algorithm of hospital encounter and physician claim codes. BMC Nephrol 14, 81 (2013). https://doi.org/10.1186/1471-2369-14-81
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2369-14-81