
Abstract
Background
There has been no systematic evaluation of the association between genetic variants of type 2 receptor for TNFα (TNFR2) and type 2 diabetes, despite strong biological evidence for the role of this receptor in the pathogenesis of this complex disorder. In view of this, we performed a comprehensive association analysis of TNFRSF1B variants with type 2 diabetes in 4,200 Indo-European subjects from North India.
Methods
The initial phase evaluated association of seven SNPs viz. rs652625, rs496888, rs6697733, rs945439, rs235249, rs17883432 and rs17884213 with type 2 diabetes in 2,115 participants (1,073 type 2 diabetes patients and 1,042 control subjects). Further, we conducted replication analysis of three associated SNPs in 2,085 subjects (1,047 type 2 diabetes patients and 1,038 control subjects).
Results
We observed nominal association of rs945439, rs235249 and rs17884213 with type 2 diabetes (P < 0.05) in the initial phase. Haplotype CC of rs945439 and rs235249 conferred increased susceptibility for type 2 diabetes [OR = 1.19 (95%CI 1.03-1.37), P = 0.019/P perm = 0.076] whereas, TG haplotype of rs235249 and rs17884213 provided protection against type 2 diabetes [OR = 0.83 (95%CI 0.72-0.95, P = 7.2 × 10-3/P perm = 0.019]. We also observed suggestive association of rs496888 with plasma hsCRP levels [P = 0.042]. However, the association of rs945439, rs235249 and rs17884213 with type 2 diabetes was not replicated in the second study population. Meta-analysis of the two studies also failed to detect any association with type 2 diabetes.
Conclusions
Our two-stage association analysis suggests that TNFRSF1B variants are not the determinants of genetic risk of type 2 diabetes in North Indians.
Similar content being viewed by others

Background
Low-grade systemic inflammation plays a crucial role in the manifestation of type 2 diabetes [1]. Activation of TNF-TNFR axis in response to elevated Tumor Necrosis Factor α (TNFα) levels, a pro-inflammatory cytokine, can be speculated to contribute to the causation of type 2 diabetes. TNFα which is involved in varied processes such as inflammatory, immune and metabolic events, is over-expressed in adipose and muscle tissues of obese and type 2 diabetic subjects [2–4]. The metabolic activities of TNFα are mainly mediated through TNFR2 (type 2 receptor for TNFα), providing the inflammation-metabolic interface in type 2 diabetes.
Enhanced TNFR2 expression and soluble TNFR2 (sTNFR2) levels have been observed in obesity, insulin resistance and cardiovascular diseases [5–7]. While genetic variants of TNFRSF1B (TNFR2 gene) have been shown to be associated with various metabolic and inflammatory disorders [8–11], the investigations were limited to only two polymorphisms-M196R (rs1061622) and (CA)n repeat polymorphism. These two polymorphisms have not been analyzed extensively for their influence on the risk of type 2 diabetes. Only a solitary report suggested association of (CA)n repeat polymorphism of TNFRSF1B with diabetic neuropathy [9], while another study refuted its role in type 2 diabetes [12]. Moreover, the only study that investigated M196R failed to provide evidence for its association with type 2 diabetes [12]. Recently, we also investigated the association of these well-studied common polymorphisms along with 3'UTR rs3397 of TNFRSF1B with type 2 diabetes in North Indian population but did not find any significant association [13].
The inconsistent reports suggest that the role of TNFRSF1B variants in the pathogenesis of type 2 diabetes is not clear yet, necessitating comprehensive evaluation of TNFRSF1B variants. In view of this, we performed association analysis of seven SNPs of TNFRSF1B with type 2 diabetes in Indo-Europeans, followed by a replication analysis of three SNPs in an independent study population of Indo-European subjects from North India.
Methods
Subjects
A total of 4,200 unrelated Indo-European subjects including 2,120 patients with type 2 diabetes and 2,080 non-diabetic controls from two independent study populations from North India participated in the study. For the initial association analysis, we recruited 2,115 subjects comprising 1,073 patients with type 2 diabetes and 1,042 non-diabetic controls. Replication was assessed in an independent study population of 2,085 individuals including 1,047 type 2 diabetes patients and 1,038 control subjects. The subjects in both the study populations were recruited according to the inclusion and exclusion criteria described previously [14]. Briefly, patients with type 2 diabetes diagnosed according to World Health Organization criteria [15]. The non-diabetic control samples were collected by organizing 'Diabetes Awareness Camps' in the urban regions in and around Delhi from North India. Subjects of ≥40 years of age with no family history of diabetes in first and/or second degree relatives who had glycated haemoglobin (HbA1c) level ≤6.0% and fasting glucose level <110 mg/dL were recruited as controls. All the participants provided written informed consent. The study was approved by the Ethics Committees of the participating institutions and was in accordance with the principles of the Helsinki Declaration.
Anthropometric and biochemical measurements
Anthropometric and biochemical parameters related to type 2 diabetes were measured in type 2 diabetic patients and control subjects. Height, weight, waist circumference and hip circumference were measured following standard guidelines. Body mass index (BMI) and waist-to-hip ratio (WHR) were calculated from these measurements. Levels of glucose, HbA1c, insulin, C-peptide, total cholesterol, triglycerides (TG), high-density lipoprotein cholesterol (HDL-C), low-density lipoprotein cholesterol (LDL-C), urea, uric acid and creatinine were measured as described earlier [14]. Levels of hsCRP were estimated using either ELISA (Biocheck Inc., CA, USA) or Cobas Integra 400 Plus (Roche Diagnostic, Mannheim, Germany). The homeostasis model assessment of insulin resistance (HOMA-IR) index was calculated as described earlier [16].
SNP selection and Genotyping
We first determined linkage disequilibrium (LD) pattern and tag SNPs for TNFRSF1B using European population data (HapMap 2). Four tag SNPs or their proxy SNPs (prioritized based on their locations in functionally significant region) that captured most of the SNPs in the gene (rs496888, rs6697733, rs945439 and rs235249) were selected. One tag SNP (rs3397) had already been genotyped in same sample set in our previous study [13]. Tag SNPs not capturing other SNPs were avoided; instead SNPs in functionally significant regions (promoter and coding regions) considering spacing between the SNPs to cover the entire gene were preferred (rs652625, rs17883432 and rs17884213). With the present seven SNPs and two SNPs (rs1061622 and rs3397) from our previous study, we captured 63% of all the variants reported in HapMap for Caucasian population. A pictorial representation of the selected SNPs along with gene structure and LD pattern around TNFRSF1B in GIH (Gujarati Indians in Houston, Texas) population from HapMap data is provided in Additional file 1.
We genotyped seven SNPs-rs652625 (5' flank), rs496888 (intron 1), rs6697733 (intron 1), rs945439 (exon 2), rs235249 (intron 8), rs17883432 (exon 9) and rs17884213 (intron 9) for the initial association analysis. Genotyping was performed using GoldenGate assay on Illumina platform (Illumina Inc., San Diego, CA, USA). The genotyping data obtained was subjected to extensive quality control as provided in detail earlier [17]. Two SNPs (rs235249 and rs17883432) failed in Illumina assay and were genotyped using iPLEX on a MassARRAY System (Sequenom, San Deigo, CA, USA). The SNPs that passed Illumina quality control had an average call rate of 99% with concordance of >99.9% in genotype calls in 7% duplicates. The average genotyping success rate for SNPs genotyped on Sequenom was >95% with 100% concordance rate in 4% duplicates. In the replication phase, genotyping of rs945439, rs235249 and rs17884213 was performed using iPLEX on a MassARRAY System (Sequenom). These SNPs had average call rate of 96% with 100% consistency of genotype calls in 5% duplicates.
Statistical Analysis
The statistical analyses were mainly performed using PLINK v. 1.07 [http://pngu.mgh.harvard.edu/~purcell/plink; [18]] or otherwise specified. Deviation from Hardy Weinberg Equilibrium (HWE) was tested using χ2 analysis. Association of SNPs with type 2 diabetes was assessed using logistic regression analysis adjusted for age, sex and BMI. Meta-analysis was performed by combining the summary estimates (OR and 95%CI) both under random and fixed effect models. Association between genotypes and quantitative traits were determined only in control subjects using Kruskal-Wallis test using SPSS version 17.0. Pairwise LD between the SNPs was determined using Haploview 4.0 and the haplotype blocks were defined using the method of Gabriel et al., 2002 as implemented in Haploview V4.0 [19]. Haplotype association analysis adjusted for age, sex and BMI were carried out at 10,000 permutations. A P value < 0.017 was considered significant after Bonferroni correction (P = 0.05/3) in the replication analysis. Statistical power of the study was determined using Quanto software (http://hydra.usc.edu/gxe/) assuming log additive model of inheritance and 10% prevalence of type 2 diabetes at α = 0.05. The initial and combined phase of the study had 82% and 98% power respectively to detect the association of a SNP with OR of 1.25 and allele frequency of 0.19 (the least allele frequency for the present study).
Results
The anthropometric and biochemical characteristics of patients with type 2 diabetes and control subjects in two study populations are provided in Table 1. Of the seven SNPs, rs652625 and rs17883432 had minor allele frequency (MAF) <5.0% and were excluded from subsequent association analysis. The genotypic distributions of the polymorphisms were in accordance with HWE both among type 2 diabetes patients and controls (all P > 0.047) (see Additional file 2).
In the initial phase, we observed nominal association of three SNPs- rs945439, rs235249 and rs17884213 with type 2 diabetes at P < 0.05 (Table 2). Stronger association was observed under recessive model for rs17884213 and rs235249. Individuals who were homozygous for minor allele of rs17884213 and rs235249 had OR of 1.80 (95%CI 1.25-2.60, P = 1.7 × 10-3) and 1.69 (95%CI 1.17-2.46, P = 5.7 × 10-3) respectively, under recessive model. Other genetic variants studied here-rs496888 and rs6697733 both in intron 1, did not show association with type 2 diabetes in the initial study population.
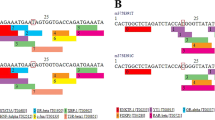
SNP rs945439 was found to be in LD with rs235249 (D' = 0.92 and r2 = 0.83) (Figure 1). The haplotype CC containing minor alleles of these two SNPs was associated with increased susceptibility for type 2 diabetes with OR of 1.19 (95%CI 1.03-1.37, P = 0.019/P perm = 0.076) (Table 3). We also observed some extent of LD between rs235249 and rs17884213 (D' = 0.83, r2 = 0.66). Haplotype TG encompassing major alleles of rs235249 and rs17884213 was associated with protection against type 2 diabetes with OR of 0.83 (95%CI 0.72-0.95, P = 7.2 × 10-3). The association remained significant after performing 10,000 permutations (P perm = 0.019).

Pairwise linkage disequilibrium between the selected SNPs in TNFRSF1B. (A) Plot with D' values; (B) Plot with r2values between the SNPs.
We then investigated the effect of TNFRSF1B polymorphisms on quantitative metabolic traits related to type 2 diabetes viz BMI, WHR, HbA1c, fasting glucose, insulin, C-peptide, total cholesterol, TG, HDL-C, LDL-C, urea, uric acid and creatinine (Table 4). For this, the clinical variables of only control subjects were compared across the genotypes of the SNPs. We observed suggestive association of rs496888 with plasma hsCRP levels (P = 0.042). No influence of other variants on any of the metabolic traits investigated was found.
Further, we attempted to replicate the associations of rs945439, rs235249 and rs17884213 in an independent study population of 2,085 Indo-European subjects. We did not find significant association of any of these SNPs with type 2 diabetes in the replication study population (P = 0.364, 0.440 and 0.289 respectively). We also performed meta-analysis of two studies that failed to identify any association with type 2 diabetes (Table 2).
Discussion
India has the largest number of individuals suffering from type 2 diabetes, with the prevalence likely to increase to approximately 80 million over the next two decades [20]. The factors contributing to such a high risk of type 2 diabetes in this part of world are not clearly understood yet. Previously, we demonstrated role of inflammation in the development of type 2 diabetes in Indo-European population [21]. Our group also showed association of TNF-LTA locus variants with type 2 diabetes in this population [22]. This suggests TNFRSF1B as an important biological candidate gene for type 2 diabetes in Indo-Europeans.
Previously, we investigated association of three TNFRSF1B polymorphisms- rs1061622 (M196R; exon6), rs3397 (3'UTR) and (CA)n and demonstrated that these polymorphisms are not associated with type 2 diabetes or its complications in Indo-Europeans [13]. Here, we carried out a comprehensive association analysis of TNFRSF1B variants with type 2 diabetes in Indo-Europeans.
In the initial phase, we observed nominal association of rs235249 in intron 8 and rs17884213 in intron 9 with type 2 diabetes. Also, haplotype TG, harboring major alleles of these two SNPs was associated with protection against type 2 diabetes. SNP rs945439, a synonymous variation in exon 2 (K56K), also showed nominal association with type 2 diabetes in the initial phase. In spite of being a coding variation, this SNP had never been evaluated for its role in the manifestation of any metabolic disorder. SNPs rs496888 and rs6697733 both in intron 1, did not influence the susceptibility to type 2 diabetes in the study population.
The investigation of the association of genetic variants of TNFRSF1B with quantitative traits revealed only the nominal association of rs496888 with hsCRP levels. Hence, being a pro-inflammatory gene, we did observe a nominal association with inflammation. No association of other variants with any other metabolic traits suggests that either these associated SNPs have very small effect on the quantitative traits analyzed here or they might modulate the risk of type 2 diabetes by influencing some other biochemical traits not investigated here.
The observed differences in the results of initial and replication phases might reflect the heterogeneity in the population. However, subjects in both the study populations have been collected with great caution regarding ethnicity and geographical regions and form a homogenous cluster as reported by the Indian Genome Variation Consortium [23]. This strategy though cannot completely rule out but decreases the effects of population stratification. Importantly, a study by Rosenberg et al [24] has stated that false positives arising due to genetic heterogeneity in the diverse Indian population could be smaller than expected. It is pertinent to mention here that in our recent study we successfully replicated the association of top eight GWAS confirmed loci with type 2 diabetes in the same population [17].
Further, to determine the structure of our population, we performed a multidimensional scaling based on 608 unlinked markers genotyped in our initial study population which clearly shows that the study population belongs to one cluster (see Additional file 3). We have also adjusted the associations for principal components obtained from an ongoing genome wide association study on the same study population and found that the associations are not significant in either of the study population, merging the two study populations or after meta-analysis (data not presented). To take care of the difference in allele frequency of rs945439, we have meta-analyzed the data of the two study populations both under random and fixed effect models, instead of combining the two data sets.
Conclusion
The present two-stage association analysis did not detect any association between type 2 diabetes and TNFRSF1B genetic variants in Indo-Europeans from North India. The results are consistent with our earlier observation of no association of well-studied polymorphisms with type 2 diabetes in Indo-European population. Thus, we conclude, TNFESF1B is not a major genetic risk factor for type 2 diabetes in Indo-Europeans from North India.
References
Schmidt MI, Duncan BB, Sharrett AR, Lindberg G, Savage PJ, Offenbacher S, Azambuja MI, Tracy RP, Heiss G: Markers of inflammation and prediction of diabetes mellitus in adults (Atherosclerosis Risk in Communities study): a cohort study. Lancet. 1999, 353: 1649-1652. 10.1016/S0140-6736(99)01046-6.
Kern PA, Saphizadeh M, Ong JM, Bosch RJ, Deem R, Simsolo RB: The expression of tumor necrosis factor in human adipose tissue: Regulation by obesity, weight loss, and relationship to lipoprotein lipase. J Clin Invest. 1995, 95: 2111-2119. 10.1172/JCI117899.
Hotamisligi GS, Arner P, Caro JF, Atkinson RL, Spiegelman BM: Increased adipose tissue expression of tumor necrosis factor-alpha in human obesity and insulin resistance. J Clin Invest. 1995, 95: 2409-2415. 10.1172/JCI117936.
Saghizadeh M, Ong JM, Garvey WT, Henry RR, Kern PA: The expression of TNF alpha by human muscle: Relationship to insulin resitance. J Clin Invest. 1996, 97: 1111-1116. 10.1172/JCI118504.
Hotamisligil GS, Arner P, Atkinson RL, Spiegelman BM: Differential regulation of the p80 tumor necrosis factor receptor in human obesity and insulin resistance. Diabetes. 1997, 46: 451-455. 10.2337/diabetes.46.3.451.
Fernández-Real JM, Broch M, Ricart W, Casamitjana R, Gutierrez C, Vendrell J, Richart C: Plasma levels of the soluble fraction of tumor necrosis factor receptor 2 and insulin resistance. Diabetes. 1998, 47: 1757-1762. 10.2337/diabetes.47.11.1757.
Shai I, Schulze MB, Manson JE, Rexrode KM, Stampfer MJ, Mantzoros C, Hu FB: A prospective study of soluble tumor necrosis factor-alpha receptor II (sTNF-RII) and risk of coronary heart disease among women with type 2 diabetes. Diabetes Care. 2005, 28: 1376-1382. 10.2337/diacare.28.6.1376.
Glenn CL, Wang WY, Benjafield AV, Morris BJ: Linkage and association of tumor necrosis factor receptor 2 locus with hypertension, hypercholesterolemia and plasma shed receptor. Hum Mol Genet. 2000, 9: 1943-1949. 10.1093/hmg/9.13.1943.
Benjafield AV, Glenn CL, Wang XL, Colagiuri S, Morris BJ: TNFRSF1B in genetic predisposition to clinical neuropathy and effect on HDL cholesterol and glycosylated hemoglobin in type 2 diabetes. Diabetes Care. 2001, 24: 753-757. 10.2337/diacare.24.4.753.
Geurts JM, Janssen RG, van Greevenbroek MM, van der Kallen CJ, Cantor RM, Bu X, Aouizerat BE, Allayee H, Rotter JI, de Bruin TW: Identification of TNFRSF1B as a novel modifier gene in familial combined hyperlipidemia. Hum Mol Genet. 2000, 9: 2067-2074. 10.1093/hmg/9.14.2067.
Benjafield AV, Wang XL, Morris BJ: Tumor necrosis factor receptor 2 gene (TNFRSF1B) in genetic basis of coronary artery disease. J Mol Med. 2001, 79: 109-115. 10.1007/s001090000168.
Vendrell J, Broch M, Fernandez-Real JM, Gutiérrez C, Simón I, Megia A, Gallart L, Ricart W, Richart C: Tumour necrosis factor receptors (TNFRs) in Type 2 diabetes. Analysis of soluble plasma fractions and genetic variations of TNFR2 gene in a case-control study. Diabet Med. 2005, 22: 387-392. 10.1111/j.1464-5491.2004.01392.x.
Tabassum R, Chavali S, Mahajan A, Ghosh S, Madhu SV, Bharadwaj D: Association analysis of TNFRSF1B polymorphisms with type 2 diabetes and its related traits in North India. Genomic Med. 2008, 2: 93-100. 10.1007/s11568-009-9031-7.
Tabassum R, Chavali S, Dwivedi OP, Tandon N, Bharadwaj D: Genetic variants of FOXA2: risk of type 2 diabetes and effect on metabolic traits in North Indians. J Hum Genet. 2008, 53: 957-965. 10.1007/s10038-008-0335-6.
Expert committee on the diagnosis and classification of diabetes mellitus: Report of the expert committee on the diagnosis and classification of diabetes mellitus. Diabetes Care. 2003, 26: S5-S20.
Matthews DR, Hosker JP, Rudenski AS, Naylor BA, Treacher DF, Turner RC: Homeostasis model assessment: insulin resistance and beta-cell function from fasting plasma glucose and insulin concentrations in man. Diabetologia. 1985, 28: 412-419. 10.1007/BF00280883.
Chauhan G, Spurgeon CJ, Tabassum R, Bhaskar S, Kulkarni SR, Mahajan A, Chavali S, Kumar MV, Prakash S, Dwivedi OP, Ghosh S, Yajnik CS, Tandon N, Bharadwaj D, Chandak GR: Impact of common variants of PPARG, KCNJ11, TCF7L2, SLC30A8, HHEX, CDKN2A, IGF2BP2 and CDKAL1 on the risk of type 2 diabetes in 5164 Indians. Diabetes. 2010, 59: 2068-2072. 10.2337/db09-1386.
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, Maller J, Sklar P, de Bakker PI, Daly MJ, Sham PC: PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007, 81: 559-575. 10.1086/519795.
Barrett JC, Fry B, Maller J, Daly MJ: Haploview: analysis and visualization of LD and haplotype maps. Bioinformatics. 2005, 21: 263-265. 10.1093/bioinformatics/bth457.
Wild S, Roglic G, Green A, Sicree R, King H: Global prevalence of diabetes: estimates for the year 2000 and projections for 2030. Diabetes Care. 2004, 27: 1047-1053. 10.2337/diacare.27.5.1047.
Mahajan A, Tabassum R, Chavali S, Dwivedi OP, Bharadwaj M, Tandon N, Bharadwaj D: High-sensitivity C-reactive protein levels and Type 2 Diabetes in urban North Indians. J Clin Endocrinol Metab. 2009, 94: 2123-2127. 10.1210/jc.2008-2754.
Mahajan A, Tabassum R, Chavali S, Dwivedi OP, Chauhan G, Tandon N, Bharadwaj D: Obesity-dependent association of TNF-LTA locus with type 2 diabetes in North Indians. J Mol Med. 2010, 88: 515-522. 10.1007/s00109-010-0594-5.
Indian Genome Variation Consortium: Genetic landscape of the people of India: a canvas for disease gene exploration. J Genet. 2008, 87: 3-20.
Rosenberg NA, Mahajan S, Gonzalez-Quevedo C, Blum MG, Nino-Rosales L, Ninis V, Das P, Hegde M, Molinari L, Zapata G, Weber JL, Belmont JW, Patel PI: Low levels of genetic divergence across geographically and linguistically diverse populations from India. PLoS Genet. 2006, 2: e215-10.1371/journal.pgen.0020215.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2350/12/110/prepub
Acknowledgements
We thank all the participants of the study. We also thank Mr. A.K. Sharma for his technical assistance in sample recruitment. This study was supported by 'Diabetes mellitus-New drug discovery R&D, molecular mechanisms and genetic & epidemiological factors' (NWP0032-7) funded by Council of Scientific and Industrial Research (CSIR), Government of India. We thank Dr. Abhay Sharma (CSIR-Institute of Genomics and Integrative Biology) for the critical evaluation of the manuscript.
We report no conflicts of interest.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors' contributions
RT designed and processed the study, interpreted the data and wrote the first draft of the manuscript. AM contributed in the data interpretation and manuscript writing. OPD and GC contributed in genotyping and manuscript writing. VS and BK did sample management and DNA purification. SG helped in the statistical analysis of the data. DB and NT conceived and supervised the study and critically evaluated the study and manuscript. All the authors read and approved the final manuscript.
Electronic supplementary material
12881_2011_847_MOESM1_ESM.TIFF
Additional file 1: Schematic presentation of selection of SNPs for the study and linkage disequilibrium pattern around TNFRSF1B gene in GIH population. A figure described the linkage disequllibrium between the SNPs, drawn using the GIH population data from HapMap 3. The arrow above the SNPs in LD plot shows the SNPs that have been genotyped. * These SNPs were genotyped in our previous study (Ref). Arrows with dotted pattern lines shows the SNPs not presented in LD plot as these were not available in HapMap 3. (TIFF 905 KB)
12881_2011_847_MOESM2_ESM.DOC
Additional file 2: Hardy Weinberg Equilibrium in cases and control subjects in initial phase and replication phase for all the SNPs. A table summarized the minor allele frequencies and Hardy Weinberg Equilibrium of the SNPs in cases and control subjects. MAF: Minor allele frequency; P_HWE: P value for Hardy Weinberg Equilibrium; NA: Not genotyped in replication phase. (DOC 32 KB)
12881_2011_847_MOESM3_ESM.TIFF
Additional file 3: ³Multidimensional scaling based on markers genotyped in our initial study². A figure presented the multidimensional scaling based on 608 unlinked markers (r2 < 0.20) that were used to obtain the positions on the first and second dimensions using PLINK for the samples of the initial phase. (TIFF 194 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Tabassum, R., Mahajan, A., Chauhan, G. et al. No association of TNFRSF1B variants with type 2 diabetes in Indians of Indo-European origin. BMC Med Genet 12, 110 (2011). https://doi.org/10.1186/1471-2350-12-110
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2350-12-110