
Abstract
Background
Numerous explanatory randomized trials support the efficacy of chronic disease interventions, including smoking cessation treatments. However, there is often inadequate adoption of these interventions for various reasons, one being the limitation of generalizability of the explanatory studies in real-world settings. Randomized controlled trials can be rated as more explanatory versus pragmatic along 10 dimensions. Pragmatic randomized clinical trials generate more realistic estimates of effectiveness with greater relevance to clinical practice and for health resource allocation decisions. However, there is no clear method to scale each dimension during the trial design phase to ensure that the design matches the intended purpose of the study.
Methods
We designed a pragmatic, randomized, controlled study to maximize external validity by addressing several barriers to smoking cessation therapy in ambulatory care. We analyzed our design and methods using the recently published ‘Pragmatic–Explanatory Continuum Indicatory Summary (PRECIS)’ tool, a qualitative method to assess trial design across 10 domains. We added a 20-point numerical rating scale and a modified Delphi process to improve consensus in rating these domains.
Results
After two rounds of review, there was consensus on all 10 domains of study design. No single domain was scored as either fully pragmatic or fully explanatory; but overall, the study scored high on pragmatism.
Conclusions
This addition to the PRECIS tool may assist other trial designers working with interdisciplinary co-investigators to rate their study design while building consensus.
Similar content being viewed by others

Background
Schwartz and Lellouch [1] first used the terms ‘pragmatic’ to describe trials designed to help choose between options for therapy, and ‘explanatory’ to describe trials designed to test causal research hypotheses – for example, whether a particular intervention causes a specific biological effect. Randomized, double-blind, placebo-controlled trials that are largely explanatory are necessary to establish the safety and efficacy of new interventions and to inform evidence-based guidelines [2]. However, explanatory trials for chronic diseases such as hypertension, diabetes, depression and addiction have a number of limitations [3, 4]. They are often conducted in tertiary centres, exclude people with comorbid conditions that cluster with the condition of interest, provide some incentive for participation, and mandate intensive follow-up visits and contact with research staff [5].
Explanatory studies, although highly internally valid, are often less generalizable to outpatient community settings. There has been a call for more real-world ‘practical’ or ‘pragmatic’ studies to enhance generalizability, but only rudimentary methods for distinguishing between efficacy (explanatory) and effectiveness (pragmatic) studies have been employed [1, 3, 4, 6–8]. The definition and design of pragmatic trials vary considerably, and are derived mainly from descriptive papers. These often describe observational studies that, in spite of limitations in internal validity and the ability to control for confounders, have frequently been used to influence clinical practice [9, 10]. Health policy makers have to make resource allocation decisions based on cost-effectiveness studies that may have excluded various populations of interest [3, 11]. Therefore, randomized clinical trials with inherent internal validity, but with greater ecological and external validity – pragmatic, randomized trials – are required in real-world settings after safety and efficacy have been established.
In Canada, there is limited drug plan coverage for smoking cessation treatments despite their proven efficacy [12–15], ostensibly due to the lack of pragmatic, randomized trials. The multicentre, community-based, pragmatic, randomized, controlled ACCESSATION Study (ClinicalTrials.gov Identifier NCT00818207) was designed to determine whether smoking cessation treatment insurance coverage is associated with improved outcomes in clinical practice. We addressed two key barriers to smoking cessation treatment: i) the lack of formulary coverage for smoking cessation treatment by most governments and private drug plans in Canada (excepting the province of Quebec at the time of the study), and ii) the cost of medications to patients. Based on existing study design elements that favoured a pragmatic study design, we developed the study protocol to make the design as pragmatic as possible. The basic study flow (Figure 1) resembles that of a traditional randomized, controlled trial. However, for each aspect of the trial, we attempted to simulate real-world conditions; this was based on discussion among the authors.

ACCESSATION study design.
After our study was initiated, an international consortium published the PRECIS (Pragmatic–Explanatory Continuum Indicator Summary) [16] model to help trialists assess the degree to which a study design falls along the pragmatic–explanatory continuum. The tool uses 10 key domains that qualitatively distinguish pragmatic (externally valid) from explanatory (internally valid) trials [16]. Although it has not been validated to predict outcomes post facto, no other instrument existed at the time and the consortium that developed this tool invites validation and enhancements to the process. Other limitations included the absence of a quantitative rating system that would increase precision, reproducibility and comparability of scores and of a formal process to reach consensus among investigators.
This paper describes the use of the PRECIS tool, coupled with the use of a numerical scale and a modified Delphi technique, to achieve consensus on the trial design, to characterize aspects of the study that determine whether it could be described as pragmatic.
Methods
The 50 participating sites of the ACCESSATION Study that could utilize a Central Ethics Committee were reviewed and approved by Institutional Review Board (IRB) Services (Suite 300, 372 Hollandview Trail, Aurora, ON L4G 0A5, Canada), and the seven remaining sites submitted to an IRB that reviewed and approved the study in the respective regions.
We analysed the ACCESSATION Study trial design elements on a continuum using the qualitative, multidimensional PRECIS tool. Table 1 provides an overview of the most important study design characteristics in relation to the 10 domains of the PRECIS tool, and was developed by the primary author.
Domain rating process
To simplify the rating process, we added a quantitative aspect to evaluations using the PRECIS tool by adding a visual 20-point numerical scale, where 1 represented ‘entirely explanatory’ and 20 represented ‘entirely pragmatic’. Six raters (five authors and one consultant: one academic family physician with an interest in smoking cessation; one cardiac rehabilitation physician with expertise in pharmacoeconomics; one addiction medicine physician and clinical scientist with a focus on tobacco dependence; one pharmacist with expertise in pharmacoeconomics; one pharmacologist with clinical research and medical affairs experience in the pharmaceutical industry; and one consultant physician with pharmacoeconomic and policy advice experience in Quebec) were requested to score the trial on each domain in Table 1 according to where they believed it fell on a pragmatic–explanatory trial continuum, and to provide an explanation for their decision. Raters were asked to review Table 1 and to read the manuscript: ‘A pragmatic–explanatory continuum indicator summary (PRECIS): a tool to help trial designers’ [16] as a guide to scoring the 10 domains of the ACCESSATION Study. A modified Delphi technique was then used to ensure a common understanding among the raters, given their multidisciplinary background (addiction medicine, family medicine, internal medicine, pharmacy, pharmacoeconomics):
-
1.
Initial group discussion among the raters regarding the study protocol and various elements classified by the 10 domains and criteria to justify their position, on a scale of 1 to 20 along the explanatory–pragmatic continuum.
-
2.
Round 1 scoring: raters independently scored each domain (see domain rating process below); an independent assistant collated the scores and developed descriptive statistics (median, mean, standard deviation [SD]). The results were anonymized before the face-to-face group discussion.
-
3.
A second face-to-face group discussion among the raters was held to clarify individual ratings, gain a better understanding of each domain and reach consensus.
-
4.
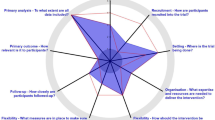
Round 2 scoring: raters did a second round of rating independently and submitted their scores. Scores were again collated in an anonymized manner to generate descriptive statistics (Figure 2A). The results of the first and second rounds of scoring were plotted in a spider graph as described by the PRECIS tool developers [16] (Figure 2B).

A. Author ratings for the ACCESSATION trial: median scores (min, max). B. Author ratings for the ACCESSATION trial using the pragmatic–explanatory continuum indicator summary (PRECIS).
Results
Table 1 results, developed prior to the group discussions and domain rating process, suggested that only the domain related to ‘Follow-up intensity’ was considered more explanatory than pragmatic. Domains related to ‘Primary trial outcome’, ‘Secondary trial outcome’ and ‘Practitioner adherence to study protocol’ were considered to have a balance of both pragmatic and explanatory elements. However, the descriptive statistics calculated after ratings and discussions had taken place (Figure 2A) indicated that all 10 domains scored higher than the midpoint of 10.5. This indicates that all the domains were more pragmatic than explanatory – albeit some were borderline. Descriptive statistics (Figure 2A) indicated that there was less variation in scores after the second round than after the first round of discussions for every domain. This suggests that the raters’ opinions converged, presumably as a result of reaching a common understanding of all aspects of the trial in relation to each of the PRECIS domains. The spider plot (Figure 2B) demonstrates the shift in opinions among the raters between the first to the second round of discussions, with the plot becoming larger – more pragmatic – after the second round of discussions.
Discussion
This paper describes the use of the PRECIS tool for the multidimensional evaluation of the ACCESSATION Study, and provides a thorough exploration of the study design that impacts its pragmatic/explanatory nature. Use of the tool highlighted study design features for which discrepancy of opinion existed among the authors regarding the degree of pragmatism within the trial, and provided a basis for discussing those areas more explicitly. However, this occurred after the study was initiated, but before data collection was completed. The high variability in ratings at the first scoring round was primarily due to differences in interpretation of the criteria described in the PRECIS tool and of how the design elements of the study fitted these dimensions. The dimensions were discussed and ratings were clarified based on the PRECIS tool. Therefore, it appears that deliberate discussion about each dimension is necessary, especially when there is considerable variability between raters. Use of a Delphi method is appropriate to reach consensus on such complex and subjective material.
If we were to design the study to be more pragmatic, we would reduce the frequency of visits for assessments and use a patient- and physician-defined primary outcome measure. For example, we would ask patients if they had quit or not, as opposed to using a validated scale. To make the study completely pragmatic on the primary outcome measure, we would use an administrative database to see if there was reduction in healthcare utilization in those who received coverage versus the control group.
Developers of the PRECIS tool [16] considered it to be an initial attempt to identify and quantify trial characteristics that distinguish between pragmatic and explanatory trials, and requested suggestions for its further development. Since 2010, five papers describing modifications to the PRECIS tool have been published, all of which employ quantification of the ratings on each dimension [17–21]. Each paper is summarized in Table 2.
In a similar analysis to ours, Riddle et al. used the PRECIS tool to design a randomized, controlled trial of pain-coping skills [17]. The authors also used the PRECIS tool to assist with face-to-face meetings and found the approach helpful, for similar reasons. They, too, added a semi-quantitative scale, but of 4 cm in length, and had three rounds of discussions. Their final evaluation led to greater agreement on all dimensions, whereby they increased the explanatory scores of each domain. The timing of their exercise prompted the authors to make revisions to the design of their randomized trial prior to submission for funding [17].
Tosh et al. [19] had three reviewers (co-authors) use a 1- to 5-point scale to review published trials in mental health; they referred to this as the Pragmascope. If a dimension could not be rated, it received a score of 0. Each trial could be allocated a total possible score of 50, with a range of 0 to 30 indicating an explanatory trial, 31 to 39 indicating a balanced trial and any score >35 indicating a pragmatic trial. However, in Figures 2 and 3, Tosh et al use ranges of 0 to 16 to describe explanatory trials and 16 to 35 to describe an interim trial that is balanced. They had independent ratings and averaging of scores, but did not describe an explicit process to be used to reach consensus.
Several limitations are associated with the use of the Pragmascope at this time. For example, if the dimension could not be rated, the dimension would receive a score of 0 and as such, bias ratings towards the study being explanatory. Moreover, the use of cut-offs for the total scores categorizing trials reverts to the problem of looking at trial design as purely explanatory or pragmatic [8, 16]. Moreover, the reason for the cut-offs used is not specified. It is not clear why they did not choose 25 (the midpoint) to indicate a balanced trial and any score less than that would favour an explanatory study, while any score greater than 25 would favour a pragmatic study. Moreover, we agree with Glasgow et al. [5] and Spigt and Kotz [22] that composite scores should be avoided because widely disparate trials can receive the same score and defeat the purpose of having a dimensional approach to the rating.
The PRECIS Review (PR) tool was developed by Koppenaal et al. [21] to evaluate systematic reviews and the randomized controlled trials used in the review to help policy makers decide on applicable trials to inform their work. Like us, they quickly realised that a Visual Analog Scale (VAS) scale of 0 to 10 was arbitrary and so converted it to a Likert-type scale of 1 to 5, also including a percentage score. They used two reviewers and an additional reviewer to rate the score when consensus could not be reached. The scoring scale appeared to be valid for the stated purpose and they acknowledged the limitations of broader applicability. Again, given the purpose behind the PRECIS tool to introduce multidimensionality to the evaluation of a study design, scores are important to initiate and guide discussion, but broader consensus on the rating is still required to inform decision making.
Glasgow et al. [20] also used a 5-point (0 to 4) scale to rate three interrelated, yet separate studies by investigators from three separate institutions. They describe a similar process of training reviewers and noted that investigators tended to rate their own papers as being pragmatic. The scoring revealed moderate levels of variability with most variability within 1 point on the 5-point scale. However, several telephone calls were required to develop consensus on the meaning of each score. It is possible that the scale was not sufficiently sensitive to detect a difference, which would be important if the group was interested in achieving consensus, but less so if trying to evaluate the study per se and categorize the protocol dichotomously.
Our proposed refinement also identified the need for a rating scale, but included a modified Delphi technique to reach consensus [23]. We chose a 20-point numerical scale to approximate a continuous scale. This permitted easier, more accurate and more stable coding of the response using e-mail. A VAS with measurement is appropriate when standardized in pen and paper format rather than e-mail, which distorts the dimensions. We also used extreme anchor points, 1 to 20, to discourage rating the domains beyond the numbers provided. Moreover, Likert scales have increased reliability with up to 11 steps, 7 steps being the minimum. Therefore, the scale we used was most sensitive to capture inter-individual differences to better target our discussions. This may be one reason why the spider graphs do not reach the extremes, but it is also possible that the raters appreciated that elements existed in each dimension to prevent an extreme rating. Use of the iterative technique provided a sound basis for discussing the intricacies of the trial design and allowed individuals to provide viewpoints anonymously and then offer their opinions during face-to-face meetings.
Taken together, these examples demonstrate that depending on the purpose of the application of the PRECIS tool (study evaluation versus study design), different scales and methods may need to be used to rate studies. However, our method may be particularly helpful to trialists to ensure common understanding of a study design when working in teams with disparate expertise. Therefore, other investigative teams may find these approaches helpful.
The multidimensional PRECIS tool can be implemented easily by investigators and represents a major advance in the design and evaluation of clinical trials that inform practice, as demonstrated by our own experience and that of others. All clinical trialists need to make compromises in their design due to a variety of practical factors that affect the conduct of a large study. Collaborative research by a team requires consensus on study design to ensure the methods are appropriate to answer the study question. Methods to evaluate study design and reach consensus are needed to ensure that disparate views and perspectives can be reconciled so that the best possible course of action is adopted.
Although most agree that the 10 dimensions are necessary to understand the explanatory–pragmatic continuum, numerical scales run the risk of dichotomously classifying the study and we did not provide a composite score for the study. This required a qualitative approach. Therefore, a more structured process using the Delphi technique that we employed, or a similar nominal group technique used by Riddle et al. [17], allowed a more democratic process of consensus among the investigators, who hailed from different disciplines and institutions. This process may be helpful to investigators during the design stage of a multicentre collaborative study to resolve disagreements and assist in reaching a common understanding of the design of the study.
Conclusions
The PRECIS tool may be applicable across a variety of health-related studies to help investigators design trials most appropriate to their study question and hypothesis. Moreover, clinicians, study reviewers, policy makers and the so-called post-regulatory decision-makers can use this tool to determine if a study has generalizability to the populations of interest and the level of reasonable effectiveness that can be expected in different ecological settings versus those in explanatory trials. In these situations, simpler rating systems as described by others might be adequate to achieve the desired outcome.
Abbreviations
- IRB:
-
Institutional Review Board
- PR:
-
PRECIS Review
- PRECIS:
-
Pragmatic–Explanatory Continuum Indicatory Summary
- SD:
-
Standard deviation
- VAS:
-
Visual Analog Scale.
References
Schwartz D, Lellouch J: Explanatory and pragmatic attitudes in therapeutical trials. J Chronic Dis. 1967, 20: 637-648. 10.1016/0021-9681(67)90041-0.
Guyatt GH, Sackett DL, Cook DJ: Users’ guides to the medical literature. II. How to use an article about therapy or prevention. B. What were the results and will they help me in caring for my patients? Evidence-Based Medicine Working Group. JAMA. 1994, 271: 59-63. 10.1001/jama.1994.03510250075039.
Tunis SR, Stryer DB, Clancy CM: Practical clinical trials: increasing the value of clinical research for decision making in clinical and health policy. JAMA. 2003, 290: 1624-1632. 10.1001/jama.290.12.1624.
March JS, Silva SG, Compton S, Shapiro M, Califf R, Krishnan R: The case for practical clinical trials in psychiatry. Am J Psychiatry. 2005, 162: 836-846. 10.1176/appi.ajp.162.5.836.
Glasgow RE, Emmons KM: How can we increase translation of research into practice? Types of evidence needed. Annu Rev Public Health. 2007, 28: 413-433. 10.1146/annurev.publhealth.28.021406.144145.
Liberati A: The relationship between clinical trials and clinical practice: the risks of underestimating its complexity. Stat Med. 1994, 13: 1485-1491. 10.1002/sim.4780131326.
Glasgow RE, Magid DJ, Beck A, Ritzwoller D, Estabrooks PA: Practical clinical trials for translating research to practice: design and measurement recommendations. Med Care. 2005, 43: 551-557. 10.1097/01.mlr.0000163645.41407.09.
Gartlehner G, Hansen RA, Nissman D, Lohr KN, Carey TS: A simple and valid tool distinguished efficacy from effectiveness studies. J Clin Epidemiol. 2006, 59: 1040-1048. 10.1016/j.jclinepi.2006.01.011.
Jepsen P, Johnsen SP, Gillman MW, Sørensen HT: Interpretation of observational studies. Heart. 2004, 90: 956-960. 10.1136/hrt.2003.017269.
Hannan EL: Randomized clinical trials and observational studies: guidelines for assessing respective strengths and limitations. JACC Cardiovasc Interv. 2008, 1: 211-217. 10.1016/j.jcin.2008.01.008.
Mullins CD, Whicher D, Reese ES, Tunis S: Generating evidence for comparative effectiveness research using more pragmatic randomized controlled trials. Pharmacoeconomics. 2010, 28: 969-976. 10.2165/11536160-000000000-00000.
2008 PHS Guideline Update Panel, Liaisons, and Staff: Treating tobacco use and dependence: 2008 update U.S. Public Health Service Clinical Practice Guideline executive summary. Respir Care. 2008, 53: 1217-1222.
Cahill K, Stead LF, Lancaster T: Nicotine receptor partial agonists for smoking cessation. Cochrane Database Syst Rev. 2010, 12: CD006103-
Hughes JR, Stead LF, Lancaster T: Antidepressants for smoking cessation. Cochrane Database Syst Rev. 2007, 1: CD000031-
Stead LF, Perera R, Bullen C, Mant D, Lancaster T: Nicotine replacement therapy for smoking cessation. Cochrane Database Syst Rev. 2008, 1: CD000146-
Thorpe KE, Zwarenstein M, Oxman AD, Treweek S, Furberg CD, Altman DG, Tunis S, Bergel E, Harvey I, Magid DJ, Chalkidou K: A pragmatic-explanatory continuum indicator summary (PRECIS): a tool to help trial designers. J Clin Epidemiol. 2009, 62: 464-475. 10.1016/j.jclinepi.2008.12.011.
Riddle DL, Johnson RE, Jensen MP, Keefe FJ, Kroenke K, Bair MJ, Ang DC: The Pragmatic-Explanatory Continuum Indicator Summary (PRECIS) instrument was useful for refining a randomized trial design: experiences from an investigative team. J Clin Epidemiol. 2010, 63: 1271-1275. 10.1016/j.jclinepi.2010.03.006.
Bratton DJ, Nunn AJ: Alternative approaches to tuberculosis treatment evaluation: the role of pragmatic trials. Int J Tuberc Lung Dis. 2011, 15: 440-446. 10.5588/ijtld.10.0732.
Tosh G, Soares-Weiser K, Adams CE: Pragmatic vs explanatory trials: the pragmascope tool to help measure differences in protocols of mental health randomized controlled trials. Dialogues Clin Neurosci. 2011, 13: 209-215.
Glasgow RE, Gaglio B, Bennett G, Jerome GJ, Yeh HC, Sarwer DB, Appel L, Colditz G, Wadden TA, Wells B: Applying the PRECIS criteria to describe three effectiveness trials of weight loss in obese patients with comorbid conditions. Health Serv Res. 2011, 10.1111/j.1475-6773.2011.01347.x.. [Epub ahead of print] Nov 2
Koppenaal T, Linmans J, Knottnerus JA, Spigt M: Pragmatic vs. explanatory: an adaptation of the PRECIS tool helps to judge the applicability of systematic reviews for daily practice. J Clin Epidemiol. 2011, 64: 1095-1101. 10.1016/j.jclinepi.2010.11.020.
Spigt MG, Kotz D: Comment on: ‘a simple and valid tool distinguished efficacy from effectiveness studies’. J Clin Epidemiol. 2007, 60: 753-755.
Mullen PM: Delphi: myths and reality. J Health Organ Manag. 2003, 17: 37-52. 10.1108/14777260310469319.
Pre-publication history
The pre-publication history for this paper can be accessed here:http://www.biomedcentral.com/1471-2288/12/101/prepub
Acknowledgements
The ACCESSATION Study was sponsored by Pfizer Inc. Jacques Le Lorier, Professor in the Departments of Medicine and Pharmacology at the University of Montreal and Chief of Pharmacoepidemiology and Pharmacoeconomics at the Research Centre of the University of Montreal Hospital Centre, kindly provided elaboration of the initial concept, the semi-quantitative scoring, contributed to the protocol design and discussion of the statistical analysis plan. Susan Bondy, PhD, University of Toronto Dalla Lana School of Public Health, provided advice regarding the use of Visual Analog Scales. Editorial assistance in the form of proofreading, collation of review comments, formatting the manuscript for submission, preparation of figures and formatting of references was provided by Alexandra Bruce, Tina Morley and Helen Jones of UBC Scientific Solutions and was funded by Pfizer Inc. Rebecca Cowan from Med Plan Inc. provided administrative assistance and was funded by Pfizer Inc.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
All authors have completed the Unified Competing Interest form at http://www.icmje.org/coi_disclosure.pdf (available on request from the corresponding author). All non-Pfizer authors declare financial compensation from Pfizer Inc. for professional services, including protocol and clinical trial materials development, initial start-up and end-of-study activities such as Case Report Form review, Statistical Analysis Plan review, preparation, participation and presentation at the Investigator Meeting, and Clinical Study Report review. No payments were made by Pfizer Inc. to PS, GB or PO for authorship and/or authorship-related activities of this paper. Travel expenses such as airfare, hotel accommodation, meals and ground transportation were reimbursed by Pfizer Inc. when appropriate. During the conduct of the study, PS and GB received research funding from their respective employers.
Authors’ contributions
PS conceptualized the idea for the paper, the addition of the Delphi Panel and the semi-quantitative scale for each dimension. He also prepared Table 1 for discussion and prepared the first draft. All authors participated in and made a substantial contribution to the discussions of the conception and design, and acquisition analysis and interpretation of data. They also revised the article critically for intellectual content and gave final approval of the version submitted for publication. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
Rights and permissions
This article is published under license to BioMed Central Ltd. This is an Open Access article distributed under the terms of the Creative Commons Attribution License (http://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Selby, P., Brosky, G., Oh, P.I. et al. How pragmatic or explanatory is the randomized, controlled trial? The application and enhancement of the PRECIS tool to the evaluation of a smoking cessation trial. BMC Med Res Methodol 12, 101 (2012). https://doi.org/10.1186/1471-2288-12-101
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2288-12-101