
Abstract
Background
The giant panda (Ailuropoda melanoleuca) is one of the most endangered animals due to habitat fragmentation and loss. Although the captive breeding program for this species is now nearly two decades old, researches on the genetic background of such captive populations, especially on adaptive molecular polymorphism of major histocompatibility complex (MHC), are still limited. In this study, we characterized adaptive variation of the giant panda's MHC DQA gene by PCR amplification of its antigen-recognizing region (i.e. the exon 2) and subsequent single-strand conformational polymorphism (SSCP) and sequence analyses.
Results
The results revealed a low level of DQA exon 2 diversity in this rare animal, presenting 6 alleles from 61 giant panda individuals. The observed polymorphism was restricted to 9 amino acid substitutions, all of which occurred at and adjacent to positions forming the functionally important antigen-binding sites. All the samples were in Hardy-Weinberg proportions. A significantly higher rate of non-synonymous than synonymous substitutions at the antigen-binding sites indicated positive selection for diversity in the locus.
Conclusion
The DQA allelic diversity of giant pandas was low relative to other vertebrates. Nonetheless, the pandas exhibited more alleles in DQA than those in DRB, suggesting the alpha chain genes would play a leading role when coping with certain pathogens and thus should be included in conservation genetic investigation. The microsatellite and MHC loci might predict long-term persistence potential and short-term survival ability, respectively. Consequently, it is recommended to utilize multiple suites of microsatellite markers and multiple MHC loci to detect overall genetic variation in order to design unbiased conservation strategies.
Similar content being viewed by others

Background
Genes of the major histocompatability complex (MHC) are known to be involved intimately in the central control of the immune response, influencing host response to infectious disease challenge. These genes are highly polymorphic in vertebrates [1]. This genetic variation alters the peptide-binding site of the encoded proteins, enabling them to bind a variety of foreign peptides [2]. Many studies support the general hypothesis that allelic diversity at MHC genes is maintained by parasite-mediated balancing selection [3–7]. It has been suggested that species with low MHC polymorphism may be particularly vulnerable to infectious diseases [8, 9].
The giant panda (Ailuropoda melanoleuca) once had a wide distribution in southwest China, including Hunan, Hubei, Sichuan, Shaanxi and Gansu provinces in the 16–19th centuries. However, habitat destruction and fragmentation have extirpated it from most of its original range [10] and the population of giant panda has decreased sharply. In the 1980s the global population of giant pandas was estimated to be about 1000 [10]. Now giant pandas are restricted to the isolated Qinling, Minshan, Qionglai, Daxiangling, Xiaoxiangling and Liangshan mountains (Figure 1). The historical separation between the Qinling and other populations has yielded a new Qinling subspecies from the nominate Sichuan subspecies [12, 13]. A captive breeding program was initiated in 1980's. Now two biggest captive populations are bred in the Ya'an-Wolong and Chengdu breeding bases in Sichuan Province, containing 57 and 86 pandas, respectively [14]. The population size of wild giant pandas of Qinling subspecies was approximately 200 [10], having no captive populations but raising few rescued individuals in Louguantai base.

Current and historical distribution of the giantpanda [11]. Black areas, present distribution; White circle indicates fossil records in the Early Pleistocene and solid circle shows fossil records in the Mid and Late Pleistocene.
Pathological researches of captive giant pandas demonstrated that 44% of giant pandas had infected with pneumonia and tick-born disease and the mortality rate of ascariasis had attained to 66.67% [15, 16]. This showed that the giant pandas in captivity were particularly susceptible to infectious disease and parasites. Although different neutral DNA marker systems such as mitochondrial DNA [17], minisatellites [12] and microsatellites [18] were used to examine genetic background of giant pandas and revealed that the observed population reduction had a negative impact on genetic variation in the giant panda, neutral molecular markers can not reflect adaptive molecular polymorphism of MHC and thus fail to tell changes in fitness traits [19–21].
The MHC is divided into three classes of genes; one of these, the class II genes, encodes glycoproteins on the surface of cells [5]. Within this gene region, two subregions, DR and DQ, exhibit high levels of polymorphism [22]. Despite a wealth of references documenting allelic polymorphism in carnivore DQA genes [23–28], relatively little is known about their counterparts in the bears, especially in the giant panda.
Diversity of MHC DRB gene, the most polymorphic locus, has been studied for the giant panda in our laboratory [29]. As a result, in this study, we used the same techniques to investigate genetic variation of another polymorphic DQA locus in the giant panda using single-strand conformational polymorphism (SSCP) and sequence analyses. This study provided an insight into the level of giant panda MHC polymorphism and gave some possible implications for captive management of giant pandas.
Results
Sequence variation of DQA exon 2 was examined by SSCP, revealing 6 different alleles Aime-DQA1 ~ Aime-DQA6 (Figure 2). All sequences have been deposited in GenBank (Accession number: EF554075-EF4080). The Ya'an-Wolong and Chengdu populations of Sichuan subspecies presented 4 and 5 alleles, respectively, and shared 4 ones with each other (Table 2). The Louguantai population of Qinling subspecies showed 6 alleles, involving all of alleles from Sichuan subspecies (Table 2). The 6 Louguantai alleles showed relatively even frequencies, while alleles Aime-DQA1 ~ Aime-DQA5 were unevenly distributed in both Sichuan populations (Table 2). Table 2 indicated lower observed (H O ) than expected (H E ) heterozygosities in the studied populations but revealed no significant deviations from Hardy-Weinberg equilibrium in any groups.

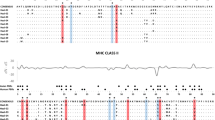
Comparison of exon 2 amino acid sequences of giant panda DQA alleles. Underlined indicates the upstream primer binding sites (the downstream primer was located on the intron 2 and thus excluded from amino acid sequences). A dot represents identity with the top sequence and a cross indicates putative sites involved in peptide binding as proposed for the human DQα molecules [29].
The polymorphism at class II loci occurs predominately in the exon 2, which encodes a majority of the peptide region [30]. The entire exon 2 translates into a sequence length of 87 amino acids with 21 possible binding sites for foreign peptide presentation [31]. Here the exon 2 region produce 76 amino acids with 20 ABS (Figure 2) if excluding the upstream primer binding sites. Alignments of nucleotide and amino acid sequences showed that the polymorphism was restricted to 11 nucleotide substitutions, together causing 9 amino acid substitutions (Figure 2). All the amino acid variation was found at ABS and adjacent to them (Figure 2). Of the 20 ABS, 5 (25%) were variable over the 6 alleles, whereas only 4 (7.1%) of the remaining 56 positions (those not thought to interact with ABS) were polymorphic. The giant panda DQA alleles obtained shared 95.7 to 99.1% nucleotide identity in the 234 bp exon 2 sequences (excluding the primer binding sequences), corresponding to 89.7 to 97.4% amino acid identity. The relative frequency of nonsynonymous substitutions (d N ) was significantly higher than that of synonymous ones (d S ) in the antigen-binding site for all three populations (Table 3), consistent with the proposed maintenance of high variation by diversifying selection.
Discussion
In the human DQα chain (DQA gene encoded), residues in the positions 7, 30, 65, 72, 75 and 76 are crucial for protein to form functional conformation and bind a foreign peptide [31]. The amino acid sequences of the giant panda showed identical residues or similar hydrophobic ones to those of human at these positions. None of the nucleotide sequences showed deletions, insertions, or stop codons. Moreover, in the functionally important antigen recognition and binding sites, the polymorphism over all alleles revealed a significantly higher rate of non-synonymous than synonymous substitutions (Table 3; P < 0.05), providing evidence for positive selection pressure on these gene loci. Consequently, all of these implied a functional role for these molecules in pathogen-specific immune responses.
The giant panda DQA allelic diversity was low compared with that of other vertebrates have been investigated. For instance, the number of alleles in ovin and horse were 24 and 18, respectively, and their numbers of variable amino acids were 37% and 46%, respectively [32, 33]. Differently, the giant panda only had 6 DQA alleles and 13.6% of variable amino acid positions, indicating that giant pandas had a limited capacity of recognizing diverse pathogens. Some studies showed that polymorphism was more extensive in class II beta chain genes than in the alpha chain genes [34, 35], implying that the DRB loci should have more alleles than DQA. However, our data seems to challenge this prediction. Although the Ya'an-Wolong population had more DRB alleles than DQA ones, both Chengdu and Louguantai populations had more DQA alleles and DRB ones (Table 4), suggesting that the alpha chain genes would play a leading role when coping with certain pathogens and thus should be included in genetic investigation when intending to design management strategies.
Microsatellites and MHC are neutral molecular markers and functional genes, respectively, but they both possess high variability and bi-parental genetic information, thus gradually becoming powerful tools in the examination of genetic diversity and population structure. The microsatellite heterozygosity showed that the three populations had similar level of genetic diversity while the heterozygosities of MHC loci indicated that the Louguantai population kept the most abundant genetic variation (Table 4). Regarding the Ya'an-Wolong and Chengdu populations, the DRB and DQA gave inconsistent results: the former had higher DRB heterozygosity but the latter exhibited higher DQA heterozygosity (Table 4). From an allelic perspective, comparisons among the number of alleles of different markers also revealed discordant results: average number of alleles for microsatellites was Ya'an-Wolong > Chengdu > Louguantai but that for DRB and DQA was Louguantai > Chengdu > Ya'an-Wolong (Table 4). The microsatellite-based and DRB-based Fst values disclosed that significant genetic differentiation existed between Ya'an-Wolong/Chengdu and Louguantai (Table 5), in good agreement with their gene sources, i.e. the Ya'an-Wolong and Chengdu populations were from the nominate Sichuan subspecies while the Louguantai population was from the new Qinling subspecies. On the contrary, the DQA-based Fst estimates revealed significant intra Sichuan subspecies rather than inter subspecies genetic divergence (Table 5).
The inconsistence in heterozygosity, allelic diversity and fixation index among microsatellites, DRB and DQA should be attributed to the differences in the driving mechanism of polymorphism for different markers and in the identity of individuals sampled in respective studies. The polymorphism of microsatellite loci results from DNA slippage during replication [38] whereas that of MHC genes is pathogen-driven. The neutral variation caused by replication slippage could be accumulated with the evolution of the species, thus predicting long-term evolutionary potential in the face of environmental change. The pathogen-driven MHC polymorphism is dynamic due to continual competition among pathogen variants and the host-pathogen co-evolution, thus being an indicator of ability to cope with short-term pathogen challenges. Scientific conservation plans should consider not only long-term persistence potential but also short-term survival ability. As a result, conservation geneticists should combine lots of microsatellite markers with multiple MHC loci to examine genetic diversity and population structure in order to obtain an overall result and give unbiased management advice. Despite available genetic data from microsatellite, DRB and DQA, it is a pity that these markers were conducted on different giant panda groups, making it infeasible to design conservation plans from the above-mentioned results at the current stage.
Conclusion
The DQA allelic diversity of giant pandas was low compared with that of other vertebrates have been investigated. Nonetheless, the giant pandas exhibited more alleles in DQA than those in DRB, suggesting the alpha chain genes would play a critical role when coping with certain pathogens and thus should be included in genetic investigation when intending to design conservation strategies. The microsatellites would accumulate neutral variation whereas the MHC loci could maintain high level of variability during the competition among pathogen variants and the co-evolution between host and pathogen. These two kinds of genetic markers might predict long-term persistence potential and short-term survival ability, respectively. As a result, it is recommended that conservation geneticists should combine the microsatellite markers with multiple MHC loci to examine genetic diversity and population structure in order to obtain an overall result and give unbiased management advice.
Methods
Sampling
A total of 61 giant pandas were sampled in this study (Table 1). The samples were obtained from the Ya'an-Wolong Breeding Center (n = 20) and Chengdu Breeding Research Base (n = 26) of Sichuan subspecies and from the Louguantai Saving Center of Rare Wild Animals (n = 15) of Qinling subspecies. Whole blood was collected in routine medical examination and stored at -20°C. Skin samples were collected from dead individuals over last decade and stored at -20°C until use. Faecal samples were collected within 24 hours post-defecation and dried at 65°C overnight. Each dried faecal samples was kept individually in paper bags with silica gel. Genomic DNA was isolated from the blood and skin samples by standard methods [39]. Genomic DNA was extracted from faeces as described by Wan et al. [29].
PCR amplification
Primers were designed to amplify the second exon of the giant panda DQA gene, which presumably encodes for the antigen-binding domain of the cell surface molecule [30]. Primers were designed based on DQA consensus regions derived from GenBank sequences (accession number: AY375882 - AY375895, AF343733 - AF343736, U47857 and AJ630363). Primers DQA- up (5'-GCT GAC CAT GTT GCT TAC TAT) and DQA-down (5'-AAG AGG CAG AGC ATT GGA CA) amplify 275 base pairs. The DQA up and down primers hybridize at nucleotide positions 13 to 33 of the exon 2 and 7 to 26 of the intron 2, respectively.
The 20 μL reactions contained 10–100 ng of genomic DNA, 10 × ExTaq buffer (Mg2+ plus) (Takara, Shanghai), 0.2 mM of each dNTP, 0.4 μM of forward and reverse primers, 1 unit of ExTaq (Takarak Shanghai) and 200 μg/mL of bovine serum albumin (Takara, Shanghai) for genomic DNA from faeces. The cycle conditions consisted of an initial denaturation at 95°C for 5 minutes followed by 35 rounds of denaturetion at 95°C for 45 seconds, annealing at 56°C for 45 seconds and extension at 72°C for 45 seconds, with a final extension at 72°C for 10 minutes using a PTC-200 Peltier thermal cycler (M.J. Research Inc. Watertown, MA).Purified PCR product (5 μL) was added to 5 μL 2 × gel loading dye buffer containing 95% formamide, 20 μM DETA, 0.05% bromophenol blue, and 0.05% xylene cyanol and run in 0.5 × TBE (4.5 M TRIS, 4.5 M boric acid, 1 mM EDTA) for 15–18 hours at 8°C. The SSCP bands were visualized by silver staining. The PCR-SSCP analysis was conducted three times for each DNA sample and the results were compared to each other.
Cloning and sequence analysisAt least three examples of each allele were cut separately from the gel with a scalpel knife. The DNA was extracted from these gel strips using acrylamaide gel DNA purification kit (Tianwei, Shanghai), and 2 μL was used in PCR re-amplification. PCR products were separated on a 1.5% agarose gel, recovered using the Agarose Gel Extraction Kit (Takara, Shanghai) and then ligated into pUC18 vector. The inserts of positive clones were verified by SSCP and clones with SSCP patterns identical to the genomic band profile were chosen for sequencing. Nine clones for each allele (from three individuals) were sequenced in both directions, using an ABI 3730 sequencer (Applied Biosystems).
Data analysis
All nucleotide and amino acid sequences were aligned using ClustalW. MEGA2.1 version was used to estimate the number of synonymous nucleotide substitutions per synonymous site (d S ) and the number of nonsynonymous nucleotide substitutions per nonsynonymous site (d N ) using the Nei and Gojobori method with a Jukes-Cantor correction [40]. These calculations were performed independently for the nucleotides within and outside the antigen-binding-sites (ABS) [41]). The ABS and non-ABS of these sequences were assigned after Paliakasis et al. [30] in accordance with human HLA DQA molecule. Expected heterozygosity was calculated after Nei [42] with the small sample size correction and deviation from the Hardy-Weinberg equilibrium was tested using Markov chain permutation test of 100 000 steps in GENEPOP version 3.4 [43]. ARLEQUIN version 2.0 [44] was utilized to calculate Fst indices and the significance was tested using 1000 permutations.
References
Bernatchez L, Landry C: MHC studies in nonmodel vertebrates: what have we learned about natural selection in 15 years?. J Evol Biol. 2003, 16: 363-377. 10.1046/j.1420-9101.2003.00531.x.
Janeway CA, Travers P, Walport M, Capra JD: Immunobiology: the immune system in health and disease. 1999, London: Current Biology Publication, 4
Apanius V, Penn DJ, Slev PR, Ruff LR, Potts WK: The nature of selection on the major histocompatibility complex. Crit Rev Immunol. 1997, 17: 179-224.
Edwards SV, Hedrick PW: Evolution and ecology of MHC molecules: from genomics to sexual selection. Tree. 1998, 13: 305-311.
Hughes AL, Yeager M: Natural selection at major histocompatibility complex loci of vertebrates. Annu Rev Genet. 1998, 32: 415-435. 10.1146/annurev.genet.32.1.415.
Hess CM, Edwards SV: The evolution of the major histocompatibility complex in birds. Bioscience. 2002, 52: 423-431. 10.1641/0006-3568(2002)052[0423:TEOTMH]2.0.CO;2.
Penn DJ, Damjanovich K, Potts WK: MHC heterozygosity confers a selective advantage against multiple-strain infections. Proc Natl Acad Sci USA. 2002, 99: 11260-11264. 10.1073/pnas.162006499.
O'Brien SJ, Roelke ME, Marker L, Newman A, Winkler CA, Meltzer D, Colly L, Evermann JF, Bush M, Wildt DE: Genetic basis for species vulnerability in the Cheetah. Science. 1985, 227: 1428-1434. 10.1126/science.2983425.
Watkins D, Garber TL, Chen ZW, Toukatly G, Hughes AL, Letvin NL: Unusually limited nucleotide equence variation of the expressed major histocompatibility complex class I genes of a New World primate species (Saguinus oedipus). Immunogenetics. 1991, 33: 79-89.
WWF MOF: A Comprehensive Survey Report on China's Giant Panda and its Habitat. 1989, China Alliance Press & Hong Kong
Hu JC, Schaller GB: The giant panda of Wolong. Sichuan Scientific and Technological Publishing House, Chengdu (in Chinese). 1985
Wan QH, Fang SG, Wu H, Fujihara T: Genetic differentiation and subspecies development of the giant panda as revealed by DNA fingerprinting. Electrophoresis. 2003, 24: 1353-1359. 10.1002/elps.200390174.
Wan QH, Wu H, Fang SG: A new subspecies of giant panda (Ailuropoda melanoleuca) from Shaanxi, China. J Mammal. 2005, 86: 397-402. 10.1644/BRB-226.1.
Xie Z, Gipps J: The 2004 international studbook for giant panda (Ailuropoda melanoleuca). 2004, Beijing: Chinese Association of Zoological Garden
Feng WH, Wang RL, Zhong SM, Ye ZY, Cui XZ, Zeng JH: Analysis on the dead cause of the anatomical carcass of giant panda (Ailuropoda melanoleuca). A study on breeding and disease of the giant panda. Edited by: Feng WH, Zhang AJ. 1991, Chengdu, Sichuan Scientific and Technical Publishers, 244-248.
Ye ZY: The control of the diseases of giant panda in field: report of 50 cases. A study on breeding and disease of the giant panda. Edited by: Feng WH, Zhang AJ. 1991, Chengdu, Sichuan Scientific and Technical Publishers, 313-315.
Zhang YP, Ryder OA, Fang Z, Zhang H, He T, He G, Zhang A, Fei L, Zhang S, Chen H, Zhang C, Yang M, Zhu F, Peng Z, Pu T, Chen Y, Yao M, Gu W: A study on sequence variation and genetic diversity of the giant panda. Sci in China Ser C. 1997, 27: 139-144.
Lü Z, Johnson WE, Menotti-Raymond M, Yuhki N, Martenson JS, Mainka S, Huang SQ, Zheng Z, Li GH, Pan WS, Mao XR, O'Brien SJ: Patterns of genetic diversity in remaining Giant Panda populations. Conserv Biol. 2001, 15: 1596-1607. 10.1046/j.1523-1739.2001.00086.x.
Einum S, Fleming IA: Genetic divergence and interactions in the wild among native, farmed and hybrid Atlantic salmon. J Fish Biol. 1997, 50: 634-651. 10.1111/j.1095-8649.1997.tb01955.x.
Fleming IA, Einum S: Experimental test of genetic divergence of farmed from wild Atlantic salmon due to domestication. ICES J Mar Sci. 1997, 54: 1051-1063.
Kallio-Nyberg I, Koljonen M-L: The genetic consequence of hatchery rearing on life-history traits of the Atlantic salmon (Salmo salar L.): A comparative analysis of sea-ranched salmon with wild and reared parents. Aquaculture. 1997, 153: 207-224. 10.1016/S0044-8486(97)00023-9.
Amills M, Ramiya V, Norimine J, Lewin HA: The major histocompatibility complex of ruminants. Rev Sci Tech. 1998, 17: 108-120.
Bowen L, Aldridge BM, Gulland F, Woo J, Van Bonn W, DeLong R, Stott JL, Johnson ML: Molecular characterization of expressed DQA and DQB genes in the California sea lion (Zalophus californianus). Immunogenetics. 2002, 54: 332-347. 10.1007/s00251-002-0472-6.
Kennedy LJ, Hall LS, Carter SD, Barnes A, Bell S, Bennett D, Ollier B, Thomson W: Identification of further DLA-DRB1 and DQA1 alleles in the dog. Eur J Immunogenet. 2000, 27: 25-28. 10.1046/j.1365-2370.2000.00189.x.
Lehman N, Decker DJ, Stewart BS: Divergent patterns of variation in major histocompatibility complex class II alleles among Antarctic phocid pinnipeds. J Mammal. 2004, 85: 1215-1224. 10.1644/BDW-010.1.
Polvi A, Garden OA, Elwood CM, Sorensen SH, Batt RM, Maki M, Partanen J: Canine major histocompatibility complex genes DQA and DQB in Irish setter dogs. Tissue Antigens. 1997, 49: 236-243.
Vage DI, Olsaker I, Ronningen K, Lie O: Partial sequence of an expressed major histocompatibility complex gene (DQA) from artic fox (Alopex lagopus). Anim Biotechnol. 1994, 5: 65-68.
Wagner JL, Burnett RC, DeRose SA, Storb R: Molecular analysis and polymorphism of the DLA-DQA gene. Tissue Antigens. 1996, 48: 199-204.
Wan QH, Zhu L, Wu H, Fang SG: Major histocompatibility complex class II variation in the giant panda (Ailuropoda melanoleuca). Mol Ecol. 2006, 15: 2441-2450. 10.1111/j.1365-294X.2006.02966.x.
Paliakasis K, Routsias J, Petratos K, Ouzounis C, Kokkinidis M, Papadopoulos GK: Novel structural features of the human histocompatibility molecules HLA-DQ as revealed by modeling based on the published structure of the related molecule HLA-DR. J Struct Biol. 1996, 117: 145-163. 10.1006/jsbi.1996.0079.
Brown JH, Jardetzky TS, Gorga JC, Stern LJ, Urban RG, Strominger JL, Wiley DC: Three-dimensional structure of the human class II histocompatibility antigen. Nature. 1993, 364: 33-39. 10.1038/364033a0.
Zhou H, Hickford JG: Allelic polymorphism in the ovine DQA1 gene. J Anim Sci. 2004, 82: 8-16.
Fraser DG, Bailey E: Polymorphism and multiple loci for the horse DQA gene. Immunogenetics. 1998, 47: 487-490. 10.1007/s002510050387.
DeFransco AL, Locksley RM, Robertson M: The MHC and polymorphism of MHC molecules. Immunity: The Immune Response in Infectious and Inflammatory Disease. 2007, Published online, New Science Press Ltd
Hugh M: Evolution of MHC class II allelic diversity. Immunol Rev. 1995, 143: 113-122. 10.1111/j.1600-065X.1995.tb00672.x.
Yan L, Huang Y, Zhang BW, Zhang SN, Zhang HM, Wei FW, Wang PY, Li M: Status and prognosis of genetic diversity in captive giant pandas(Ailuropoda mela noleuca)in Wolong. Acta Theriologica Sinica. 2006, 26: 317-324. 10.1016/S1872-2032(06)60007-3. (in Chinese)
Zhang ZH, Shen FJ, Sun S, Davil VA, Zhang AJ, O'Brien SJ: Paternity Assignment of Giant Pan da by M icrosatellite Genotyping. Hereditas. 2003, 25: 504-510. (in Chinese)
Levinson G, Gutman GA: Slipped-strand mispairing: a major mechanism for DNA sequence evolution. Mol Biol Evol. 1987, 4: 203-221.
Sambrook J, Russell DW: Molecular cloning: a laboratory manual, 3rd edn. 2001, Cold Spring Harbor Laboratory Press, New York, NY
Kumar S, Tamura K, Jakobsen IB, Nei M: Mega2: molecular evolutionary genetics analysis software. Bioinformatics. 2001, 17: 1244-1245. 10.1093/bioinformatics/17.12.1244.
Hughes AL, Nei M: Pattern of nucleotide substitution at major histocompatibility complex class I loci reveals overdominant selection. Nature. 1988, 335: 167-170. 10.1038/335167a0.
Nei M: Molecular Evolutionary Genetics. 1987, New York: Columbia University Press
Raymond M, Rousset F: GENEPOP (version 1.2): Population genetics software for exact tests and ecumenicism. J Heredity. 1995, 86: 248-249.
Schneider S, Roessli D, Excoffier L: Arlequin, Version 2.000: A Software for Population Genetic Data Analysis. Genetics and Biometry Laboratory. 2000, University of Geneva, Switzerland, 91: 3166-3170.
Acknowledgements
This work was supported by two grants from the National Nature Science Foundation of People's Republic China (No. 30325009, to Fang SG; No. 30540054, to Wan QH) and a special grant (No. wh0418, to Wan QH) for the giant panda from the China State Forestry Administration.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Authors' contributions
LZ and YFG performed the experiments and LZ drafted the first version of the manuscript. XDR collected the samples and drafted the second version of the manuscript. QHW and SGF provided supervision and revised the manuscript. All authors read and approved the final manuscript.
Liang Zhu, Xiang-Dong Ruan contributed equally to this work.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Zhu, L., Ruan, XD., Ge, YF. et al. Low major histocompatibility complex class II DQA diversity in the Giant Panda (Ailuropoda melanoleuca). BMC Genet 8, 29 (2007). https://doi.org/10.1186/1471-2156-8-29
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2156-8-29