
Abstract
Background
Meta-analysis (MA) is widely used to pool genome-wide association studies (GWASes) in order to a) increase the power to detect strong or weak genotype effects or b) as a result verification method. As a consequence of differing SNP panels among genotyping chips, imputation is the method of choice within GWAS consortia to avoid losing too many SNPs in a MA. YAMAS (Yet Another Meta Analysis Software), however, enables cross-GWAS conclusions prior to finished and polished imputation runs, which eventually are time-consuming.
Results
Here we present a fast method to avoid forfeiting SNPs present in only a subset of studies, without relying on imputation. This is accomplished by using reference linkage disequilibrium data from 1,000 Genomes/HapMap projects to find proxy-SNPs together with in-phase alleles for SNPs missing in at least one study. MA is conducted by combining association effect estimates of a SNP and those of its proxy-SNPs. Our algorithm is implemented in the MA software YAMAS. Association results from GWAS analysis applications can be used as input files for MA, tremendously speeding up MA compared to the conventional imputation approach. We show that our proxy algorithm is well-powered and yields valuable ad hoc results, possibly providing an incentive for follow-up studies. We propose our method as a quick screening step prior to imputation-based MA, as well as an additional main approach for studies without available reference data matching the ethnicities of study participants. As a proof of principle, we analyzed six dbGaP Type II Diabetes GWAS and found that the proxy algorithm clearly outperforms naïve MA on the p-value level: for 17 out of 23 we observe an improvement on the p-value level by a factor of more than two, and a maximum improvement by a factor of 2127.
Conclusions
YAMAS is an efficient and fast meta-analysis program which offers various methods, including conventional MA as well as inserting proxy-SNPs for missing markers to avoid unnecessary power loss. MA with YAMAS can be readily conducted as YAMAS provides a generic parser for heterogeneous tabulated file formats within the GWAS field and avoids cumbersome setups. In this way, it supplements the meta-analysis process.
Similar content being viewed by others

Background
The ongoing GWAS era has led to 1,449 association findings for 237 complex traits by 6/2011 [1]. Typically small effect sizes, however, leave a large fraction of disease susceptibility unexplained, a phenomenon that has become famous as “the case of the missing heritability” [2–4]. Several potential explanations for the phenomenon were given, including over-estimation of the heritability, rare variants with larger effects, common variants with even smaller effects than observed so far, incomplete coverage of current GWAS marker panels, but also epigenetic effects [5] or interactions between genetic variants [6]. In order to address incomplete coverage and common variants with small effects, a most required method is an efficient combination of genome-wide association studies (GWAS) of the same objective. Meta-analysis (MA) is capable of improving the power of GWAS and to examine the heterogeneity between studies [7, 8]. Available tools [9, 10] for meta-analysis combine study data marker by marker. Markers which are not part of all included studies are underestimated in their contribution to the phenotype under investigation. Hence, such markers may be lost in further consideration, regardless of their actual disease association, simply due to misrepresented study power. Therefore, imputation is used to unify the available marker panels of GWAS and to avoid loss of SNPs that are present in one study but not in another. Conjunction of imputation and subsequent meta-analysis has become a standard technique for combination of GWAS data. Several imputation methods have been developed during the last years, including MaCH [11], IMPUTE [12, 13], BIMBAM [14], BEAGLE [15], or EMINIM [16] which are widely used. However, imputation is a time-consuming step with high computational performance requirements, which can be conducted in acceptable time only on high performance computer clusters. Furthermore, the imputation accuracy varies greatly from SNP to SNP, which is difficult to take into account for meta-analysis, and, may result in a loss of power [17]. Hence, great care has to be taken by each research group contributing to a meta-analysis effort. Here, we present a MA-approach that directly operates on GWAS association results and that can be run within about 1 hour with our YAMAS (Yet Another Meta Analysis Software) software. In particular, it is possible to carry out a first analysis without the need to impute. The idea of our algorithm is that for SNPs that are present in one study but not in another, substitute proxy SNPs are defined using reference data from the HAPMAP [18] or 1,000 Genomes projects [19]. In this way, all SNPs that are present in at least one of the experimental marker panels can be analyzed. We evaluate the performance of the proxy algorithm with data sets that were simulated using realistic linkage disequilibrium patterns obtained from the 1,000 Genomes project. Moreover, we successfully applied our approach to Type II diabetes (T2D) GWAS data derived from the database of Genotypes and Phenotypes (dbGaP). [20].
Results and discussion
Simulation Study
We conducted a power study based on 1,000 Genomes [19] data (August 2010 release), in order to obtain realistic linkage disequilibrium (LD) patterns. We used the chromosome 22 data of the 288 individuals of European descent (CEU sample) as a “master” data set M. In general, we simulated series of new data sets M i by random re-assignment of cases-control status, so that each M i consisted of 144 cases and 144 controls. For each data set, we conducted a single-marker analysis on M i and identified the smallest p-value obtained for any of the SNPs in M i . In case was smaller than 1×10−6, we kept the simulated data set for further analysis. We stopped the simulation process when 500 data sets with had been obtained. In order to compare the relative performance of the proxy algorithm and imputing we investigated to what degree could be retrieved in a meta-analysis. For this purpose, M i was split into two “studies” A i and B i , each involving only 144 individuals. In addition, for A i SNP information was kept only for SNPs from the Illumina® Human660WQuad v1 panel, and for B i , SNP information was kept only for Affymetrix® 6.0 chip content. Meta-analysis of A i and B i was then performed either using only the SNPs available in both panels (MA-intersection), or using the proxy algorithm (MA-proxy), or based on A i and B i imputed with the IMPUTE [13] software using the 1,000 Genomes data (MA-impute). The comparison of the three MA strategies was then based on their potential to recapture the association signal in the complete master sample. To meet this purpose, the p-values , and were defined by the smallest p-values obtained within the 100 kb window around the top signal of the master file. The window size was chosen since LD typically extends about 50 kb [18]. Therefore, we investigated the regions 50 kb upstream and downstream of the top signal. Nominal “power” was then evaluated based on the minP values: we counted the fraction of data sets for which minP was smaller than α ∈{0.01,0.001,..,1×10−6}. For comparison, we will show also the power values that would be obtained when both studies A and B had been genotyped for all SNPs of the 1,000 Genomes panel (LIMIT). That reflects the upper limit of what the meta-analysis approaches could have reached. Adjustment for the number of SNPs within the 100 kb window was not performed. In particular, min PMA−proxy and min PMA−impute were treated equally, even though more SNPs were considered with imputation-based MA. Thus, MA-imputed was favored in a way by our power definition. However, in practice a significance level of 5×10−8 is the consensus to establish genome-wide significance, irrespective of the number of SNPs actually tested. Therefore, it seems to be appropriate not to adjust for the varying amount of SNPs tested when comparing different MA strategies.
We tried to mimic different scenarios of potential reference panels, an “ideal”, an “incomplete” and a “mismatched” one. First, the “ideal” reference panel represents a perfect and complete match of the haplotype distribution between the study and the reference data. The “ideal” reference panel consisted of exactly the same haplotypes as the master file. In practice, the reference data will contain only a fraction of the haplotypes that are actually present in the study population, simple because of the limited size of the reference samples. Therefore, our “incomplete” reference consisted only of a third of the haplotypes present in the master file, in order to mimic a real data analysis situation. Third, the “mismatched” reference consisted only of the haplotypes of African descent (YRI sample) and was included to investigate the robustness against poorly fitting reference panels.
Running Time
Running time was evaluated on a cluster with 400 CPUs (2.4 Ghz, 2GB RAM). In Table 1, running time estimates (unix time command, real time) from analysis with YAMAS are listed. Analysis of the Type II Diabetes data (first line of Table 1, 6 studies) took 2 minutes and 5 seconds with the point-wise approach, and 92 minutes and 5 seconds with the proxy-algorithm, using a single CPU. In order to investigate running time in correlation with the number of studies, we increased the meta-analysis to 12 (24) studies by using each of the original dbGaP studies twice (four times). Running time of the point-wise algorithm is about proportional in the number of investigated studies: increasing the number of studies by a factor of 4 leads to an increase in running time from 2m5s to 6m56s, which corresponds to factor of 3.35. The running time of the proxy-algorithm grows only moderately with an increasing number of studies. For 24 studies, the running time is only about 8 minutes longer than with 6 studies. This is because most of the running time is needed for reading, indexing and storing the proxy reference file, which has to be done only once. We conclude that the proxy-algorithm can be run even with a large number of studies within less than two hours. In addition, several algorithms and data processing routines are parallelized, based upon the OpenMP project [21], such that the YAMAS running time can be further improved if required by the user.
We wish to contrast the running time of the proxy-algorithm of 92m5s (6 studies) to that of imputation. Imputation was carried out in chunks using IMPUTEv2 [13]. We used 300 CPUs such that we were able to analyze each in one go. The average running time of a chunk was 20 hours. Since 6 studies had to be analyzed, 300 CPUs run 120 hours, each. In addition, association analysis ran 5 hours on average per chromosome, using PLINK [10], i.e., 22 CPUs were needed for 30 hours, in addition. In total, but ignoring extra running time for merging of chunks, imputation and association testing took 300 · 20 · 6 + 22 · 5 · 6 = 36,600 CPU-hours which is 23,921 more than what is needed with the proxy-approach. When one assumes that ample CPUs are available to impute all chunks of one study in parallel, the running time the user actually has to wait is 20 · 6 + 5 · 6 = 150 hours, ignoring overhead that is need to check and format the data for association testing. Thus, even when a cluster with hundreds of CPUs is available, running time improves by a factor of almost one hundred with the proxy-algorithm (150h/92m5s=98).
Results from Simulation Study
In Table 2 results from simulations under the null hypothesis are shown. None of the investigated methods exceeds the nominal level, of either α = 0.0 or α= 0.01, irrespective of the reference file that is chosen. In particular, there is no evidence for inflated type I error with the new proxy algorithm. This was also true when the r2-limit for a SNP and its proxy was relaxed from 0.80 to 0.50 (data not shown). We conclude that the proxy approach is a valid method. Of notice, all methods are too conservative when a random effects model is used. This is in concordance with a recent publication [22] in which is was shown that the random effects model tests an inappropriately strict null hypothesis.
The results from our power study are depicted in Figures 1, 2 and 3. The x-axis displays various α-levels on a logarithmic scale, moving from higher to lower levels. The y-axis displays power levels.

MA with “ideal” reference panel. Power levels are plotted over different nominal α levels (on the x-axis, with a negative logarithmic scale).

MA with “incomplete” reference panel. Power levels are plotted over different nominal α levels (on the x-axis, with a negative logarithmic scale).

MA with “mismatched” reference panel. Power levels are plotted over different nominal α levels (on the x-axis, with a negative logarithmic scale).
When an ideal reference panel is used (Figure 1), MA with imputing strongly outperforms naïve MA restricted to the joint marker panel (MA-intersection). Thus, imputing is highly recommendable. Nevertheless, the power level with MA-impute is considerably lower than power that can be achieved with a hypothetical sample that genotyped for all 1,000 Genomes SNPs (LIMIT). Thus, our simulation study also confirms the claim that imputing cannot replace complete genotyping or sequencing [23]. MA-proxy clearly outperforms MA-intersection, but is, as expected, less powerful than MA-impute. This is partly due to, first, the smaller marker panel that MA-proxy can analyze, and, second, that in case of incomplete LD the proxy marker will not necessarily reflect the true effect size.
In the presumably most realistic scenario (incomplete reference, Figure 2), we still see an impressive power gain with MA-impute when compared to MA-intersection. The performance of MA-proxy now comes much closer to that of MA-impute than with unrealistic “ideal” reference panel. We conclude that the proxy algorithm can yield valuable ad hoc results at an early analysis stage.
Thirdly, considering the mismatched reference panel (Figure 3), it is noteworthy, that MA-impute and MA-proxy still markedly outperform naïve MA. Obviously, even distant ethnical groups still share common LD patterns that can be useful in extending SNP information. Of note, there is no longer a measurable difference between the performance of MA-proxy and MA-impute. In summary, the difference between MA-impute and MA-proxy becomes smaller with reduced fit of the reference panel with the data. This is plausible: the imputing approach is the more sophisticated one, taking into account higher-order LD, whereas the proxy algorithm uses only pairwise LD information. Thus, the relative performance of the imputing approach will be the better the more closer its assumption “concordance of the study and reference haplotype set” is fulfilled. In contrast, the proxy algorithm uses a rougher metric, and, therefore, is more robust to peculiar mismatches in haplotype structure. As a consequence, the proxy algorithm can be recommended as an alternative main approach when a close-fitting reference panel is not available.
Analysis of Type II Diabetes dbGaP Data
We examined the performance of the proxy approach on the basis of six Type II Diabetes GWAS studies that were available from dbGaP [20], cf. Table 3. The six GWAS studies belong to three different projects.
There are two projects of the Northwestern NUgene Project Type 2 Diabetes from the National Human Genome Research Institute (NHGRI), each of which contributed 2 studies to our analysis. The “Project Health Research - Vanderbilt University” project provided two studies from different platforms. Data generated with the Illumina® Human660W-Quad v1 chip comprised 607 individuals and 499,350 markers. Another fraction of patients were examined with the Illumina® Human1M-Duo v3 array, for which 1384 individuals and 919,602 SNPs remained after quality control (QC). The same arrays were used for the second project, the “Northwestern NUgene Project”. Here, 1,239 individuals with 495,588 from the Human660W-Quad v1 array were available after QC, and, 267 individuals with 908,692 markers were available for Human1M-Duo v3. Finally the third project “GENEVA Diabetes Study”, comprised two further studies, the Nurses Health Study (NHS) and the Health Professionals Follow-up Study (HPFS). After provided quality control (QC), 3,435 individuals and 764,679 SNPs were available for NHS, and 2,606 individuals and 787,213 SNPs were available for HPFS. Both studies were performed on the Affymetrix® Human SNP Array 6.0. In total, data from three different platforms with different marker content were used in six GWAS studies.
The dbGaP data was analyzed with naïve MA (MA-intersection), i.e., conventional MA restricted to the joint marker panel, with the proxy algorithm (MA-proxy), and based on data imputed with IMPUTEv2 [16], using 1,000 Genomes reference data. We relied on the QC data available from dbGaP, since our focus was on the relative performance of the various MA approaches rather than on the detection of novel associations.
Only 141,105 SNPs were available in all six studies and 561,282 SNPs were available in at least four studies. The proxy approach enabled the analysis of 1,427,514 SNPs and SNP/SNP–proxy combinations, whereof 1,0464,482 were available in all six studies and 1,279,702 were available in at least four studies. More than 85% of the proxies had an r2 greater than 0.8 with the substituted SNP.
Our philosophy was to compare the performance of the methods on Type II Diabetes genes that the community considers to be “undoubtedly” confirmed. To this purpose, we used the catalog of published GWAS results provided by the American National Human Genome Research Institute [1]. The catalog lists 33 Type II Diabetes GWAS genes/LD regions (“gene regions”) with at least one SNP that meets the genome-wide significance criterion of 5×10−8. For each of these gene regions, we investigated the 100 kb up- and downstream region of the SNP reported to be most significant and computed min PMA−impute and min PMA−proxy for the six studies available for us. Of note, a considerable part of the 33 genes was identified by meta-analysis efforts and shows only moderate odds ratios [24, 25]. As a consequence, it cannot be expected that all the genes show measurable association effects within the smaller data sets we analyzed. In other words, not all the genes will be informative for the evaluation of the performance of the two meta-analysis approaches. Therefore, we restricted our comparison to gene regions that reached a significance level of 0.05 with at least one method.
In Table 4, 22 such gene regions are shown, together with the minimum p-values for all approaches. For 16 of the gene regions, MA-proxy yields a more significant result than MA-intersection. For TCF7L2 for instance, minP improves from 3.2×10−19 to 1.5×10−22, a change by a factor of 2127. In total, there are 6 gene regions with a p-value improvement of at least a factor of 10, including FTO, IRS1, JAZF1, KCNJ11, and KCNQ1. For KCNQ1, we observe p = 0.021 with MA-intersection and p = 0.00027 with MA-proxy,
an increase in significance by a factor of 78.6. For another 11 genes we observe an improvement with the proxy algorithm by a factor ranging from 2.18 (TSPAN8/LGR5) to 8.46 (JAZF1). There are also 5 gene regions for which no difference between MA-intersection and MA-proxy can be observed. In these cases, the most significant SNP is available in all 6 studies and, therefore, MA-intersection and MA-proxy coincide. Finally, for TSPAN8/LGR5, significance slightly decreases from 0.012 to 0.008. In summary, MA-proxy outperforms MA-intersection in the majority of cases and we observe an average (median) improvement of the level of significance of 107.1 (3.33), demonstrating the usefulness of proxy-SNPs.
Imputation-based MA outperforms MA-proxy in 19 out of 22 cases and we observe an average (median) improvement of the level of significance of 19.1 (2.79). In two cases, imputing outperforms the proxy-algorithm by a factor of more than 100, SLC30A8 (193) and HMGA2 (149.8), and in another case by a factor of 21.7 (SPRY2) which demonstrates the usefulness of long-range LD for association analysis. For 16 genes, the loss of significance with the proxy-algorithm is moderate with a factor of less than 10, of which for 11 genes we observe a factor of less than 4. For three genes, FTO, KCNQ1 and RBSM1/ITGB6, the proxy-algorithm even performs slightly better than MA-impute. In summary, one can say that the proxy algorithm yields good approximations of the actual level of significance in the majority of cases and that it is a potentially useful screening algorithm.
Table 5 contains a detailed example that explains the idea of proxy-SNPs for rs7903146 which is located within the gene of transcription factor TCF7L2, which has an essential function in the Wnt signaling pathway. This SNP is described in several GWAS to be significantly associated with the risk of Type II Diabetes. P-values up to 2×10−51 are reported [25]. In our dbGaP analysis, rs7903146(A/G) is present in studies 1-4, but not in studies 5 and 6. However, those studies contain rs4506565(T/A) which, according to 1,000 Genomes [19] data, has an r2 of 0.945 with rs7903146 and which is located only 2.3 kb downstream. Moreover, the A-T haplotype has a frequency of 0.668, while under linkage equilibrium a frequency of only 0.454 would be expected, based on the allele frequencies of 0.68 for rs7903146-A and 0.668 for rs4506565-T. Thus, rs7903146-A and rs4506565-T are “in-phase” alleles and proxy meta-analysis can combine the respective effect estimates and standard errors. Since in all 6 studies the effect estimates for rs7903146-A or rs4506565-T, respectively, are positive, joint meta-analysis becomes highly significant with a p-value of 1.5×10−22. Of course, rs7903146 also is indicated by conventional meta-analysis with a p-value of 3.3×10−19, but in this case only 4 GWAS studies can be used and the additional evidence coming from studies 5 and 6 is lost. We note that the proxy-SNPs that YAMAS uses may differ from study to study. In the example, the same proxy SNP was used for both study 5 and 6. In general, however, the proxy algorithm identifies for each study independently the SNP with the highest r2 with the SNP that shall be substituted.
Conclusion
Via real data analysis we were able to show that the proxy algorithm is not only fast and quickly employed, but also powerful. It clearly outperformed naïve SNP-by-SNP meta-analysis on real genotype data, when applied to a set of established Type 2 Diabetes regions. Moreover, our simulation study indicates that the proxy algorithm is very robust in terms of power with respect to a ethnically poorly matched reference panel. Thus, it is worth considering it as an alternative MA approach for studies on ethnical groups that are not directly represented in the 1,000 Genomes, for instance studies carried out in population isolates.
It is a known phenomenon that the catalogue of confirmed GWAS findings [1] is strikingly sparse for the X chromosome. At the moment, it is unclear if this phenomenon reflects the “true genetics” of human diseases or whether it is a detection bias. One might indeed speculate that the X chromosome is often ignored in MA efforts since it requires additional efforts to be imputed [26]. In this context, YAMAS may be particular helpful since no special analysis steps are necessary for the X chromosome.
Another notable feature of YAMAS is that it can be combined with imputed data. In practice, it may happen that studies are imputed with different reference panels. Moreover, particular SNPs might pass imputing-QC in some studies but not in others. In these situations, the analysis panel can be completed with the proxy-algorithm. In this context we wish to emphasize that our goal is not to compete with imputing as the standard approach for meta-analysis. Indeed, our own simulation study demonstrates a power advantage of imputation-based MA in a standard setting. Our aim is rather to speed up and give impetus to meta-analysis efforts. Even though the required analysis time for genome-wide imputing is meanwhile limited to a few weeks for experienced and well-equipped groups, joint projects are frequently long-lasting. Everyone who has worked in a meta-analysis project has either experienced or can imagine that it can easily take one year until all participating groups have provided their imputing results, either because some of the participating groups are less experienced in imputing analysis than others or either because they are involved in projects which they assign higher priority to. In particular, the priorities the participants have will sometimes be heterogeneous, causing delay for those who have the primary interest in the joint effort. Therefore, we believe that a method that facilitates MA and yields ad hoc, but still interpretable and meaningful results, is highly warranted. The proxy algorithm we have introduced fulfills these criteria: it directly operates on GWAS analysis results and can be run in a few hours even when the meta-analysis comprises many groups, and has descent power since it can analyze all SNPs that were genotyped in at least one of the participating studies.
Methods
Standard Meta-Analysis
YAMAS either combines allelic odds ratios (ORs) or estimates of the allelic effects (“betas”) as obtained in regression models. In case of ORs, the effect becomes E=ln(OR), else it stays un-transformed. Effects are merged across studies with the weighted average,
, where k is the number of studies and w i is a weight given by the standard error (S E i ) for the ith study: . The standard error of Ē is computed as
and the combined two-tailed p-value becomes , with being the standard normal cumulative density distribution function. The meta-analysis follows the standards exemplified [8] and is also equipped to consider the between-study variance of markers by calculating so called random effect sizes [27, 28]. Taking Cochran’s Q-value [29],
, as an indicator for the total between-study variance, we are able to replace w with w∗ = (S E2 + τ2)−1 and use this weight to reflect heterogeneity, τ2 being the between-study variance:
if Q−(k−1) > 0, else τ2 = 0. Q itself follows a χ2-distribution with k − 1 degrees of freedom [30]. We note that it has recently been shown [22] that the classical random-effects model tests a too strict null hypothesis and although intended for effects that vary between studies, ironically enough leads to a conservative procedure in the presence of heterogeneity. However, since the random-effects model is still often requested by reviewers, we still feature it in our software.
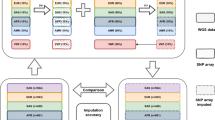
The Proxy Algorithm
We assume that association results (effect estimates and standard errors) are available for the real genotype data of each participating study. In order to enable MA on the complete marker panel missing markers can be filled with “proxy markers”. For this purpose, a sample reference file based on 1,000 Genomes [19] SNP content is provided for download on the YAMAS web site. As an alternative, own reference files can be produced using genotype data in PLINK-format [10] with the current version of INTERSNP [31]. The reference file tabulates pairs of SNPs with marker IDs, each marker’s alleles, the chromosome the markers are on, their absolute physical distance in base pairs, r2 as a linkage disequilibrium indicator [32] and a boolean flag to define the proxy alleles (see below). We provide proxy files for CEU, YRI and JPT+HCN samples. In general, pairs of SNPs no more than 200kb apart and with an r2 ≥ 0.5 are listed. For the X chromosome and the MHC region, we choose a distance limit of 5 Mb. If the algorithm would encounter a situation where one marker is present in one of the studies, but missing in one or more of the other studies, it will try to find a proxy marker in those studies, compare Figure 4. Proxy markers are ranked by their mutual r2 (higher r2 ranks higher). This sorted list of markers is tried for the presence in the data set. The first present SNP, i.e., the SNP with the highest LD with the missing SNP, is chosen to be the proxy-SNP and will subsequently be used for MA, see also Figure 4. To account for the effect direction the proxy marker also carries the information for a proxy allele: the reference file designates the allele as the proxy allele for which the observed haplotype frequency is greater than the expected haplotype frequency under linkage equilibrium. In other words, the “in-phase” alleles of a SNP and its proxy define mutual proxy alleles (cf. also the section “Analysis of dbGaP data” for an example). A boolean indicator for the proxy alleles is part of the reference file. In summary, meta-analysis is always based on the established formula
from the previous section. In contrast to “standard” meta-analysis the effect estimates that are combined do not always refer to the same SNP (rsNumber) in each study, but to a SNP from one study and its proxy-SNPs in other studies. In order to select a SNP as a proxy, we require a minimum r2 of 0.50.

Proxy meta-analysis schematic example. Schematic example of a meta-analysis with proxy markers. For simplicity we consider only two studies with four markers each (1-4). Common MA is applied on markers 1 and 4 (as they are present in both marker sets), yet when YAMAS hits marker 3, which is missing in the second study (3 – gray box), it selects marker 2 in study 2 as its proxy marker, based on the r2 indicator. Dashed arrows indicate non-chosen potential proxy markers. The case of the missing marker 2 in study 1 is omitted for better readability.
URLs
YAMAS, Yet Another Meta-Analysis Software; http://yamas.meb.uni-bonn.de/ The OpenMP API specification for parallel programming, http://openmp.org/wp
Author’s contributions
CM and TB developed the proxy algorithm and are responsible for the software design. CM programmed the major part of YAMAS. ML and TB prepared the manuscript. ML is responsible for the programming of additional features and software maintenance. MA performed parts of the T2D analysis. CH, MM, DD and AL provided significant input to the work and the manuscript. All authors read and approved the final manuscript.
References
Hindorff LA, Wise A, Junkins HA, Hall PN, Klemm AK, Manolio TA, MacArthur J (European Bioinformatics Institute): A Catalog of Published Genome-Wide Association Studies. [www.genome.gov/gwastudies]. Accessed 10/10/2011
Maher B: Personal genomes: The case of the missing heritability. Nature. 2008, 456: 18-21.
Manolio TA, Collins FS, Cox NJ, Goldstein DB, Hindorff LA, Hunter DJ, McCarthy MI, Ramos EM, Cardon LR, Chakravarti A, et al: Finding the missing heritability of complex diseases. Nature. 2009, 461: 747-753. 10.1038/nature08494.
Yang J, Benyamin B, McEvoy BP, Gordon S, Hendres AK, Nyholt DR, Madden PA, Heath AC, Martin NG, Montgomerey GW, et al: Common SNPs explain a large porportion of the heritability for human height. Nat Genet. 2010, 462: 565-571.
Slatkin M: Epigenetic inheritance and the missing heritability problem. Genetics. 2009, 182: 845-850. 10.1534/genetics.109.102798.
Heard E, Tishkoff S, Todd JA, Vidal M, Wagner GP, Wang J, Weigel D, Young R: Ten years of genetics and genomics: what have we achieved and where are we heading?. Nat Rev Genetics. 2010, 11: 723-733. 10.1038/nrg2878.
Evangelou E, Maraganore DM, Ioannidis JP: Meta-analysis in genome-wide association datasets: strategies and application in Parkinson disease. PLoS One. 2007, 2: e196-10.1371/journal.pone.0000196.
de Bakker PIW, Ferreira MA, Jia X, Neale BM, Raychaudhuri S, Voight BF: Practical aspects of imputation-driven meta-analysis of genome-wide association studies. Hum Mol Genet. 2008, 17: R122-R128. 10.1093/hmg/ddn288.
Willer CJ, Li Y, Abecasis GR: METAL: fast and efficient meta-analysis of genomewide association scans. Bioinformatics. 2010, 26: 2190-2191. 10.1093/bioinformatics/btq340.
Purcell S, Neale B, Todd-Brown K, Thomas L, Ferreira MA, Bender D, Maller J, Sklar P, de Bakker PI, Daly MJ, Sham PC: PLINK: a tool set for whole-genome association and population-based linkage analyses. Am J Hum Genet. 2007, 81: 559-575. 10.1086/519795.
Li Y, Willer CJ, Ding J, Scheet P, Abecasis GR: MaCH: using sequence and genotype data to estimate haplotypes and unobserved genotypes. Genet Epidemiol. 2010, 34: 816-834. 10.1002/gepi.20533.
Marchini J, Howie B, Myers S, McVean G, Donnelly P: A new multipoint method for genome-wide association studies by imputation of genotypes. Nat Genet. 2007, 39: 906-913. 10.1038/ng2088.
Howie B, Donnelly P, Marchini J: Imputation Method for the Next Generation of Genome-Wide Association Studies. PLoS Genetics. 2009, 5: e1000529-10.1371/journal.pgen.1000529.
Servin B, Stephens M: Imputation-based analysis of association studies: candidate regions and quantitative traits. PLoS Genet. 2007, 3: e114-10.1371/journal.pgen.0030114.
Browning BL, Browning SR: A unified approach to genotype imputation and haplotype phase inference for large data sets of trios and unrelated individuals. Am J Hum Genet. 2009, 84: 210-223. 10.1016/j.ajhg.2009.01.005.
Kang HM, Zaitlen NA, Eskin E: EMINIM: an adaptive and memory-efficient algorithm for genotype imputation. J Comput Biol. 2010, 3: 547-560.
Zaitlen N, Eskin E: Imputation aware meta-analysis of genome-wide association studies. Genet Epidemiol. 2010, 34: 537-42. 10.1002/gepi.20507.
The International HapMap Consortium ea: The International HapMap Consortium. Nature. 2007, 449: 851-861. 10.1038/nature06258.
1000 Genomes Project Consortium ea: A map of human genome variation from population-scale sequencing. Nature. 2010, 467: 1061-1073. 10.1038/nature09534.
Mailman MD, Feolo M, Jin Y, Kimura M, Tryka K, Bagoutdinov R, Hao L, Kiang A, Paschall J, Phan L: The NCBI dbGaP Database of Genotypes and Phenotypes. Nat Genet. 2007, 39: 1181-6.
Ayguade E, Copty N, Duran A, Hoeflinger J, Massaioli YL, Teruel X, Unnikrishnan P, Zhang G: The design of OpenMP tasks. IEEE Transactions on Parallel and Distributed Systems. 2009, 20: 404-418.
Han B, Eskin E: Random-effects model aimed at discovering associations in meta-analysis of genome-wide association studies. Am J Hum Genet. 2011, 88: 586-98. 10.1016/j.ajhg.2011.04.014.
Shea J, Agarwala V, Philippakis AA, Maguire J, Banks E, Depristo M, Thomson B, Guiducci C, Onofrio RC, Kathiresan S, Gabriel S, et al: Comparing strategies to fine-map the association of common SNPs at chromosome 9p21 with type 2 diabetes and myocardial infarction. Nat Genet. 2011, 43: 801-5. 10.1038/ng.871.
Zeggini E, Scott LJ, Saxena R, Voight BF, Marchini JL, Hu T, de Bakker PI, Abecasis GR, Almgren P, Andersen G, et al: Meta-analysis of genome-wide association data and large-scale replication identifies additional susceptibility loci for type 2 diabetes. Nat Genet. 2008, 40: 638-43. 10.1038/ng.120.
Voight BF, Scott LJ, Steinthorsdottir V, Morris AP, Dina C, Welch RP, Zeggini E, Huth C, Aulchenko YS, Thorleifsson G, et al: Twelve type 2 diabetes susceptibility loci identified through large-scale association analysis. Nat Genet. 2010, 42: 579-89. 10.1038/ng.609.
Marchini J, Howie B: Genotype imputation for genome-wide association studies. Nat Rev Genetics. 2010, 2010: 499-511.
Higgins JPT, Thompson SG, Deeks JJ, Altman DG: Measuring inconsistency in meta-analyses. BMJ. 2003, 327: 557-560. 10.1136/bmj.327.7414.557.
Huedo-Medina TB, Sanchez-Meca J, Marin-Martinez F, Botella J: Assessing heterogeneity in meta-analysis: Q statistic or I2 index?. Psychol Methods. 2006, 11: 193-206.
Cochran WG: The combination of estimates from different experiments. Biometrics. 1954, 10: 101-129. 10.2307/3001666.
Gavaghan DJ, Moore RA, McQuay HJ: An evaluation of homogeneity tests in meta-analyses in pain using simulations of individual patient data. Pain. 2000, 85: 415-424. 10.1016/S0304-3959(99)00302-4.
Herold C, Steffens M, Brockschmidt FF, Baur MP, Becker T: INTERSNP: genome-wide interaction analysis guided by a priori information. Bioinformatics. 2009, 25: 3275-3281. 10.1093/bioinformatics/btp596.
Devlin B, Risch N: A comparison of linkage disequilibrium measures for fine-scale mapping. Genomics. 1995, 29: 311-322. 10.1006/geno.1995.9003.
Acknowledgements
The work was supported by grant BE 3828/4-1 from the Deutsche Forschungsgemeinschaft.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Christian Meesters, Markus Leber contributed equally to this work.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Meesters, C., Leber, M., Herold, C. et al. Quick, “Imputation-free” meta-analysis with proxy-SNPs. BMC Bioinformatics 13, 231 (2012). https://doi.org/10.1186/1471-2105-13-231
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2105-13-231