
Abstract
Background
Atomic Solvation Parameters (ASP) model has been proven to be a very successful method of calculating the binding free energy of protein complexes. This suggests that incorporating it into docking algorithms should improve the accuracy of prediction. In this paper we propose an FFT-based algorithm to calculate ASP scores of protein complexes and develop an ASP-based protein-protein docking method (ASPDock).
Results
The ASPDock is first tested on the 21 complexes whose binding free energies have been determined experimentally. The results show that the calculated ASP scores have stronger correlation (r ≈ 0.69) with the binding free energies than the pure shape complementarity scores (r ≈ 0.48). The ASPDock is further tested on a large dataset, the benchmark 3.0, which contain 124 complexes and also shows better performance than pure shape complementarity method in docking prediction. Comparisons with other state-of-the-art docking algorithms showed that ASP score indeed gives higher success rate than the pure shape complementarity score of FTDock but lower success rate than Zdock3.0. We also developed a softly restricting method to add the information of predicted binding sites into our docking algorithm. The ASP-based docking method performed well in CAPRI rounds 18 and 19.
Conclusions
ASP may be more accurate and physical than the pure shape complementarity in describing the feature of protein docking.
Similar content being viewed by others

Background
Most proteins interact with other proteins to perform their biological functions in the form of protein complexes. During the past several decades, many docking programs have been developed to predict protein-protein complexes. Among them, the docking algorithms based on Fast Fourier Transform (FFT) are widely used and have made great success[1] because they can search 6D space in a very fast way. These programs include MolFit[2], 3D-Dock[3–5], GRAMM[6], ZDock[7, 8], DOT[9], BiGGER[10] and HEX[11]. The base of the original FFT-based docking method is shape complementarity between receptor and ligand. It is usually used as the first step of docking procedure and then other methods are used to refine or re-rank the docked structures [3, 12, 13]. Besides the FFT-based algorithms, there are other well-known docking algorithms that also consider flexibility of proteins during docking procedure, like RosettaDock[14], ICM-DISC[15], AutoDock[16], or HADDOCK[17]. Since the original FFT docking algorithm only used shape complementarity feature to solve bound docking problem[1], different scoring functions based on other physical features have been integrated into the original FFT-based docking method to improve the prediction ability. For examples, the 3D-DOCK[18] added electrostatic energy into the FFT-based docking method. ZDOCK[7] used atomic contact energy to calculate solvation energy. The hydrophobic docking method [19] combined hydrophobic complementarity with shape complementarity [20]. GRAMM used a long-distance potential[21] to calculate atom-atom van der Waals energy which has proved effective in detecting binding funnels.
Reliable scoring function is crucial to enhance success rate of prediction of protein-protein docking. Cheng and co-workers [22] analyzed the performance of different energy components in protein-protein interactions. They showed that the sum of solvation and electrostatic energies contributes more than 70% to the total binding free energy, while van der Waals energy only contributes less than 10%. Fernandez-Recio's work also showed that rather than electrostatic, van der Waals and hydrogen-bond energies, solvation energy[23] is the most important component in the total binding energy. Zhou et al. [24] found that the correlation coefficient between solvation energy and experimental binding energy is 0.83 with a root mean square deviation (RMSD) of 2.3 kcal/mol, and the most important is that the slope is close to 1 ( slope = 0.93 ).
ASP (Atomic solvation parameters) model is one of the best methods to calculate solvation energy. Due to its fast and efficient feature, ASP model [25–27] has made great success in free energy calculation[28, 29], structure prediction[30, 31], and scoring functions[22, 32]. This suggests that if we integrate ASP into the sampling stage of docking algorithms, it may enhance the success rates of docking. Up to now, several groups have constructed different ASP sets [25–27]. Among them, Zhou's set[24] is the most suitable one for calculating the solvation energy of protein complexes. This ASP set was extracted from 1023 mutation experiments and yielded an accurate prediction of free binding energy of complexes. In this paper, the ASP set from Zhou's work is used to develop an ASP-based protein-protein docking algorithm (ASPDock).
During a prediction procedure, correct auxiliary information (e.g., predicted binding sites) usually can increase the success rate significantly [33–36], but incorrect auxiliary information may mislead predictors and lead to worse predictions. However, we hardly distinguish whether the information is correct or not before the complex structure is experimentally solved. In this work, we present a softly restricting method of using biological information in which we constrain receptor and ligand partially within the predicted binding sites. Using our ASPDock algorithm with softly restricting method, we participated in two rounds of Critical Assessment of PRediction of Interactions (CAPRI)[37]. There are 3 targets (T40, T41, and T42) in rounds 18 and 19. We got high-quality hits for T40 and T41 and the best LRMSD were 2.35 Å and 1.41 Å, respectively.
Results and Discussion
Free Energy Calculation
The ASP used here is from Zhou and co-workers [24], which contain only six atom types. It proved to be successful in predicting binding free energy of complexes. ASP model assumes that the solvation energy of an atom or an atom-group is proportional to its solvent accessible surface area (ASA). Accurate calculation of ASA, which depends on the conformation of proteins or complexes, is a time consuming job. In order to meet the speed of the FFT-based docking method, we propose an approximate FFT method to calculate the ASA and so ASP values (see the section "Methods").
We first test our method on the 21 protein complexes[24], whose binding free energies have been measured experimentally. For each complex, we perform a bound docking and select the best structure close to the native state. Usually the LRMSD between the best structure and native structure is less than 0.5Å, and so we consider the ASP score of the best structure as that of the native structure. Using similar method we can calculate the shape complementarity score for each of the 21 complexes. Obviously, if we set all ASP values equal to one, what we calculated in our method is the shape complementarity score.
We compared the ASP and shape complementarity scores with the experimental binding free energy for each of the 21 complexes. The correlation coefficient between the ASP scores and experimental binding energies of the 21 complexes is 0.6868, and that between the shape complementarity scores and experimental binding energies is 0.4843 (Figure 1). In Zhou's work [24], the correlation coefficient between the ASP scores and experimental binding energies of the 21 complexes is 0.83 since they used a more accurate method to calculate the ASA than us. This shows that our approximate method can count most part of the binding free energy and is better than pure shape complementarity method. The later is easily understood because the shape complementarity is a reduced ASP model by taking all atoms as the same.

Correlation between experimental free binding energy and docking score. (A) Correlation between experimental free binding energy and shape complementarity score. (B) Correlation between experimental free binding energy and ASP score. Calculation of shape complementarity score and ASP score are both based on FFT method. Grid step is 1 Å here.
Benchmark Calculation
Our algorithm is further tested on the benchmark 3.0 [38] by using both the ASP and shape complementarity scores. There are 124 protein-protein complexes, which contain 24 antibody-antigen complexes, 35 enzyme-inhibitor complexes and 65 other complexes. In the docking sampling stage, we use 10 degree as a step for the rotational scanning. Success in top N predictions is defined as that at least one acceptable hit is found in top N predictions. Acceptable hits stand for those predicted complexes with ≤ 10Å LRMSD with respect to the native complex structure. LRMSD is the RMSD between the predicted and native ligand molecules after superposing predicted and native receptor molecules. No predicted and experimental information is used in the docking process. Result shows that ASP method enhances the success rate significantly (Figure 2) in comparison with shape complementarity score.

Success Rate on benchmark 3.0. (A) Success Rates of ASPDock method on antibody-antigen complexes, enzyme-inhibitor complexes, other complexes and total complexes, respectively. (B) Success Rates of ASPDock, GeoDock (Shape complementarity docking using ASPDock algorithm), FTDock and ZDock3.0 methods on the benchmark 3.0.
As in other docking methods, the prediction of enzyme-inhibitor complexes has a higher success rate than antibody-antigen complexes and other complexes. That is mainly because enzyme-inhibitor complexes usually have better interface features than other types of complexes [39]. Success rate of antibody-antigen complexes is not as high as in some other methods [5, 7, 40]. However, complementarity determining regions (CDR) of antibodies can be predicted by sequence[41]. If we utilize this (CDR) information, success rate of antibody-antigen complexes should be enhanced dramatically. In general, ASP method can enhance the success rate significantly.
We also compared our results with the popular docking algorithms FTDock [5] and ZDock [7, 8] using the Benchmark 3.0 (Figure 2B and also Additional file 1). The former can be used to compare the performance of ASPDock relative to a pure shape complementarity method and the later can be used to judge the performance of a single ASP score relative to the best docking method integrating many important factors of protein interactions. The results show that the ASP score indeed gives higher success rate than the pure shape complementarity score of FTDock but lower success rate than ZDock. The former shows that "ASP complementarity" is more reasonable for describing the interface character of protein-protein interaction than pure shape complementarity. The later is expected because ASPDock is only to search a more physical model of pure shape complementarity for protein docking and needs integrating more important factors of protein interactions to get a higher success rate of prediction.
CAPRI Rounds 18-19
Using our ASPDock and softly restricting method, we participated in the CAPRI rounds18 and 19, which contain three targets, T40 in round 18 and T41, T42 in round 19. We got one high quality prediction for each of T40 and T41 (Figure 3), but no correct prediction for T42. During the docking procedure, we searched the structural space in 5 steps as follows: (1) Searching the binding site information of receptor and ligand from literature; (2) Scanning the six dimensional space by using ASPDock method with the amplified ASP valuesρi; (3) Picking out the top 2000 structures, clustering them and choosing the structures ranking first in each of the top 20 clusters. In this step, the structures are ranked directly according to their ASP values. (4) Refining the 20 structures using RosettaDock[14] and obtaining a set of new structures; (5) Re-ranking the structures using scoring function, clustering them, and then choosing the structures ranking first in each of the top 10 clusters. The scoring functions we used are RossettaDock[14] and DECK(Shiyong Liu and Ilya Vakser, submitted). The weight of RossettaDock and DECK scores is 1:1.

Native and predicted structures of T40 and T41 in CAPRI. Our submitted structures are represented by mass center model. Blue balls represent incorrect structures, yellow balls represent acceptable hits, magenta balls represent medium hits and red balls represent high quality hits.
The target T40 (Figure 4) is a complex between bovine trypsin (1BTY) and the double-headed arrowhead protease inhibitor API-A (bound). Some important information shared by Dr. Weng from Boston University shows that the two active sites of the inhibitor are Leu87 and Lys145 (Figure 4A). We incorporated this information into the ASP docking of T40 by using a softly restricting docking method with the amplification factor α being set as 3. For comparison, we also did a totally free docking without using any information of binding sites by shape complementarity method (Figure 4B) and by ASPDock method (Figure 4C). Although free docking can find some structures binding at the residues Leu87 and Lys145, softly restricting ASP docking can greatly enhance the sampling around them (Figure 4D). There is one high quality and six medium hits in our ten submitted structures. The best LRMSD between our hit and experimental measured structures is 2.35 Å.

Results of CAPRI T40 predicted by different methods. Top 3000 structures obtained by ASPDock with and without the information of predicted binding sites. Green protein is the double-headed arrowhead protease inhibitor (API-A). Orange residues are the key residues, Leu87 and Lys145. Small balls are mass centres of ligands. There are 3000 ligand-mass centres in each figure, representing top 3000 structures of ligands. The ASP scores are ranked form red to blue color. (A) Native structure of T40. (B) Top 3000 ligands generated by shape complementarity method. (C) Top 3000 ligands generated by ASPDock method. (D) Top 3000 ligands generated by softly restricting ASPDock method.
T41 is the DNase domain of colicin E9 (G95C mutant) in complex with the Im2 immunity protein (C23A/E31C mutant). The unbound coordinates provided are: E9 DNase domain (1FSJ) and Im2 from the NMR ensemble (2NO8). We got one high quality hit and eight acceptable hits in our ten submitted structures. The best LRMSD is 1.41 Å (Figure 3).
T42 is a symmetric homodimer and designed based on Lynn Regan's idealized TPR (1NA3). Residues 1-4 and 108-125 are disordered. We didn't get any acceptable hits of this target (in fact there were only few hits in all predictions from the groups that participated in this CAPRI round).
Conclusions
We proposed an easy way to incorporate ASP model into FFT protein-protein docking method, which can calculate the solvation energy approximately but quickly. This ASPDock method is reduced the FFT docking method of pure shape complementarity when the ASP values of all atoms are set to be 1. The scores of ASPDock reflect solvation energy, which has proved to be the most significant energy among all kinds of energies in binding free energy. On the contrast, pure shape complementarity has no clear physical meaning. Our results indicate that the ASPDock method can enhance the prediction accuracy significantly in comparison with the pure shape complementarity method.
A softly restricting method was also proposed to incorporate the predicted binding sites into the ASPDock method. This method is more reasonable than the strictly restricting method, which will definitely miss the correct complex structure when the information is incorrect.
Methods
ΔG Calculation using ASP
Solvation energy of a complex is strongly correlated to its binding free energy. ASP model, first proposed by Eisenberg and McLachlan1[25] in 1986, is one of the most successful models for solvation energy calculation. ASP model assumes that the solvation energy of an atom or an atom-group is proportional to the area of its solvent accessible surface and so the total solvation energy of a molecule is
where Ai is the solvent-accessible surface area (ASA) of atom i and σ i is the ASP value of atom i, which can be determined experimentally. Although both analytical [42–45] and numerical [46–48] methods have been developed, accurate calculation of the ASA, which depends on the conformations of proteins or complexes, is still a time consuming job. In this work we propose alternative approach to estimate the ASA quickly and approximately in order to meet the speed of the FFT-based docking method.
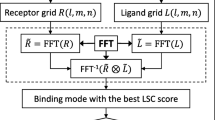
In FFT-based docking method, proteins are projected onto three dimensional grids (Figure 5). We define the space between molecular surface and accessible surface as a shell. The thickness of this shell is the radius of a solvent molecule, which is 1.7Å for water. We assume that the ASA Ai is proportional to the number Ni of the grids occupied by the shell of atom i. If the ASP value of these grids is σ i , we have

Calculation of ASP scores using grids. (A) a, b and c represent different atoms or atom groups, P is the probe molecule, dashed line shows the solvent accessible surface, different colors stand for different ASP values. (B) Projecting these atom groups onto grids, we can calculate accessible surface area approximately by counting grids occupied by the shells of atoms or atom groups.
Obviously represents not an absolute but a relative value of ΔG, and the accuracy could be controlled by the grid size. Smaller grid size leads to a higher accuracy. Using this approximation, we can quickly evaluate ΔG of proteins.
ΔΔG calculation using ASP
In order to evaluate stability of a protein complex, we need to calculate the binding energy of complexes ΔΔG,
where ΔGReceptor, ΔGLigand and ΔGComplex are the solvation energy of receptor, ligand and complex, respectively.
For rigid docking problem, the receptor and ligand have no conformational changes during the formation of complex and the calculation of ΔΔG is much simpler (Figure 6). We only need to calculate the ASP values of atoms on the buried surface, i.e.,

Schematic of ΔΔ G calculation. Unburied surface keeps unchanged during association in rigid body docking and we can evaluate ΔΔG by only calculating ASP values of the atoms on the buried surface.
Here TS, BS and US denote the total surface, buried surface and unburied surface, respectively. In this work, we use FFT method to calculate . It is noted that describes the pure shape complementarity if σ i is set to be 1 for all atoms.
Fast Fourier Transform
In FFT docking method, receptor and ligand are mapped to three dimensional grids of N × N × N nodes, respectively. The grids occupied by receptor surface, inside receptor, and outside receptor are set as a value of 1, -15, and 0, respectively. The grids occupied by ligand and outside ligand are set as 1 and 0, respectively.
In our ASPDock, receptor and ligand are described by two discrete functions in the same way as follows:
where (l,m,n) is the grid node coordinates. ASP value used is from Zhou's work[24], which is simple and effective. The value of ρ is a penalty for protein overlap, setting from -20 to -40 that doesn't change the results significantly. is the imaginary unit.
If ΔASP is defined as the change of ASP values by docking,
the score of ΔASP can be calculated using the correlation function:
where Im [ ] denotes the imaginary part of a complex function. α, β, γ are the numbers of grid steps by which ligand L is shifted with respect to receptor R in each dimension. SASP is positive, zero or negative depending on if there is contact, no contact or overlap between the receptor and ligand after shift. The tolerance of overlap is controlled by the penalty factor ρ.
Calculating correlation of two functions directly is a lengthy procedure, which needs N3 multiplications and additions for each of the N3 possible shifts, and results in totally N6 calculations. We use FFT method to accelerate this stage, as in other works.
Here the Discrete Fourier Transform (DFT) and Inverse Fourier Transform (IFT) can be calculated rapidly by using fftw library. Before translational scan, the ligand should be rotated in 360 × 180 × 360 degree. Here we use Lattman's method to delete the redundant angles[5, 49], which enhances the efficiency significantly.
After the total scan of transition and rotation, we rank the complexes by their ASP scores in two steps. Firstly, we rank the complexes in each orientation and pick the top N out. Secondly, we rank all the top N complexes together. N could be set from 1 to 10. If N is larger than 10, there will be many similar complexes, which may have no benefit in enhancing success rate of prediction and sometimes even make correct complexes rank worse.
DECK (Distance and environment-dependent coarse-grained) Scoring Function
Based on Dockground (http://dockground.bioinformatics.ku.edu/), Liu and Vakser developed a low-resolution scoring function for protein-protein docking (Shiyong Liu and Ilya Vakser, submitted). Each residue is represented as one pseudo-atom, the "centroid"of the side chain. The optimal reference state was selected according to the success rate of testing on a public available decoy set (http://dockground.bioinformatics.ku.edu/UNBOUND/decoy/decoy.php).
Softly Restricting Method
Predicted binding sites can be used to restrict the range of docking sampling and enhance success rate of prediction. This has been done in two ways, using as a post scan filter[3, 18, 50–52] and integrating into the scanning stage[33, 53]. However, the predicted binding sites may be incorrect. This will make the docking prediction completely wrong and much worse than without using the predicted information.
To avoid this problem, we use a softly restricting method to use the predicted information. We amplify the ASP values of the residues belong to the predicted binding sites by a factor α and keep the values of other residues unchanged. The ASP values amplified ρ i are represented as
If α is set as infinity, the docking sampling will be completely restricted to the range of the predicted binding sites. However, if the value of α is finite, the sampling is still allowed around the whole surface of the molecules. Thus, even if the predicted binding sites are wrong, we still have the chance to find the correct docking conformations and the success rate will not decrease significantly.
References
Katchalski-Katzir E, Shariv I, Eisenstein M, Friesem A, Aflalo C, Vakser I: Molecular surface recognition: determination of geometric fit between proteins and their ligands by correlation techniques. Proc Natl Acad Sci USA 1992, 89(6):2195–2199. 10.1073/pnas.89.6.2195
Heifetz A, Katchalski-Katzir E, Eisenstein M: Electrostatics in protein-protein docking. Protein Sci 2002, 11(3):571–587. 10.1110/ps.26002
Jackson RM, Gabb HA, Sternberg MJE: Rapid refinement of protein interfaces incorporating solvation: application to the docking problem. J Mol Biol 1998, 276(1):265–285. 10.1006/jmbi.1997.1519
Moont G, Gabb HA, Sternberg MJE: Use of pair potentials across protein interfaces in screening predicted docked complexes. Proteins 1999, 35(3):364–373. 10.1002/(SICI)1097-0134(19990515)35:3<364::AID-PROT11>3.0.CO;2-4
Henry GabbA, RMJaMJES : Modelling Protein Docking using Shape Complementarity, Electrostatics and Biochemical Information. J Mol Biol 1997, (272):106–120.
Vakser I, Conformation P, Glycoproteins H, Virus-immunology I: Evaluation of GRAMM low-resolution docking methodology on the hemagglutinin-antibody complex. Proteins 1997, 29(S1):226–230. 10.1002/(SICI)1097-0134(1997)1+<226::AID-PROT31>3.0.CO;2-O
Chen R, Li L, Weng Z: ZDOCK: an initial-stage protein-docking algorithm. Proteins 2003, 52(1):80–87. 10.1002/prot.10389
Mintseris J, Pierce B, Wiehe K, Anderson R, Chen R, Weng Z: Integrating statistical pair potentials into protein complex prediction. Proteins 2007, 69(3):511–520. 10.1002/prot.21502
Mandell J, Roberts V, Pique M, Kotlovyi V, Mitchell J, Nelson E, Tsigelny I, Ten Eyck L: Protein docking using continuum electrostatics and geometric fit. Protein Eng Des Sel 2001, 14(2):105–113. 10.1093/protein/14.2.105
Palma P, Krippahl L, Wampler J, Moura J: BiGGER: a new (soft) docking algorithm for predicting protein interactions. Proteins 2000, 39: 372–384. 10.1002/(SICI)1097-0134(20000601)39:4<372::AID-PROT100>3.0.CO;2-Q
Ritchie D, Kemp G: Protein docking using spherical polar Fourier correlations. Proteins 2000, 39(2):178–194. 10.1002/(SICI)1097-0134(20000501)39:2<178::AID-PROT8>3.0.CO;2-6
Pierce B, Weng Z: ZRANK: reranking protein docking predictions with an optimized energy function. Proteins 2007, 67(4):1078–1086. 10.1002/prot.21373
Huang S, Zou X: An iterative knowledge-based scoring function for protein-protein recognition. Proteins 2008, 72(2):557. 10.1002/prot.21949
Gray J, Moughon S, Wang C, Schueler-Furman O, Kuhlman B, Rohl C, Baker D: Protein-protein docking with simultaneous optimization of rigid-body displacement and side-chain conformations. J Mol Biol 2003, 331(1):281–299. 10.1016/S0022-2836(03)00670-3
Fernández-Recio J, Totrov M, Abagyan R: Soft protein-protein docking in internal coordinates. Protein Sci 2002, 11(2):280–291.
Harris R, Olson A, Goodsell D: Automated prediction of ligand-binding sites in proteins. Proteins 2008, 70(4):1506–1517. 10.1002/prot.21645
Dominguez C, Boelens R, Bonvin AMJJ: HADDOCK: a protein-protein docking approach based on biochemical or biophysical data. J Am Chem Soc 2003, 125(7):1731–1737. 10.1021/ja026939x
Gabb HA, Jackson RM, Sternberg MJE: Modelling Protein Docking using Shape Complementarity, Electrostatics and Biochemical Information. J Comput Chem 1997, 272(1):106–120.
Vakser I, Alfano C: Hydrophobic docking: a proposed enhancement to molecular recognition techniques. Proteins 1994, 20: 320–329. 10.1002/prot.340200405
Berchanski A, Shapira B, Eisenstein M: Hydrophobic complementarity in protein-protein docking. Proteins 2004, 56(1):130–142. 10.1002/prot.20145
Vakser I: Long-distance potentials: an approach to the multiple-minima problem in ligand-receptor interaction. Protein Eng Des Sel 1996, 9(1):37–41. 10.1093/protein/9.1.37
Cheng T, Blundell T, Fernandez-Recio J: pyDock: electrostatics and desolvation for effective scoring of rigid-body protein-protein docking. Proteins 2007, 68(2):503–515. 10.1002/prot.21419
Fernández-Recio J, Totrov M, Abagyan R: Identification of protein-protein interaction sites from docking energy landscapes. J Mol Biol 2004, 335(3):843–865.
Zhou H, Zhou Y: Stability scale and atomic solvation parameters extracted from 1023 mutation experiments. Proteins 2002, 49(4):483–492. 10.1002/prot.10241
Eisenberg D, McLachlan A: Solvation energy in protein folding and binding. nature 1986.
Ooi T, Oobatake M, Nemethy G, Scheraga H: Accessible surface areas as a measure of the thermodynamic parameters of hydration of peptides. Proc Natl Acad Sci USA 1987, 84(10):3086–3090. 10.1073/pnas.84.10.3086
Eisenberg D, McLachlan AD: Solvation energy in protein folding and binding. Nature 1986, 319(6050):199–203. 10.1038/319199a0
Wesson L, Eisenberg D: Atomic solvation parameters applied to molecular dynamics of proteins in solution. Protein Sci 1992, 1(2):227–235. 10.1002/pro.5560010204
am Busch M, Lopes A, Amara N, Bathelt C, Simonson T: Testing the Coulomb/Accessible Surface Area solvent model for protein stability, ligand binding, and protein design. BMC Bioinformatics 2008, 9(1):148. 10.1186/1471-2105-9-148
Eisenmenger F, Hansmann U, Hayryan S, Hu C: [SMMP] A modern package for simulation of proteins. Comput Phys Commun 2001, 138(2):192–212. 10.1016/S0010-4655(01)00197-7
Nicosia G, Stracquadanio G: Generalized pattern search algorithm for peptide structure prediction. Biophys J 2008, 95(10):4988–4999. 10.1529/biophysj.107.124016
Pei J, Wang Q, Liu Z, Li Q, Yang K, Lai L: PSI-DOCK: towards highly efficient and accurate flexible ligand docking. Proteins 2006., 62(4): 10.1002/prot.20790
Ben-Zeev E, Eisenstein M: Weighted geometric docking: incorporating external information in the rotation-translation scan. Proteins 2003, 52(1):24–27. 10.1002/prot.10391
de Vries SJ, Melquiond ASJ, Kastritis PL, Karaca E, Bordogna A, van Dijk M, Rodrigues JPGLM, Bonvin AMJJ: Strengths and weaknesses of data-driven docking in critical assessment of prediction of interactions. Proteins 2010, 78(15):3242–3249. 10.1002/prot.22814
Luo L, Zhang Sw, Chen W, Pan Q: Predicting protein-protein interaction based on the sequence-segmented amino acid composition. Acta Biophys Sin 2009, 25(4):282–286.
Cai L, Pei Z, Chen S: Study on Law of Protein-protein Interactions Based on Structural Information. Acta Biophys Sin 2009, 25(1):65–71.
Janin J, Henrick K, Moult J, Eyck LT, Sternberg MJE, Vajda S, Vakser I, Wodak SJ: CAPRI: A Critical Assessment of PRedicted Interactions. Proteins 2003, 52(1):2–9. 10.1002/prot.10381
Hwang H, Pierce B, Mintseris J, Janin J, Weng Z: Protein-protein docking benchmark version 3.0. Proteins 2008, 73(3):705–709. 10.1002/prot.22106
Liang S, Zhang C, Liu S, Zhou Y: Protein binding site prediction using an empirical scoring function. Nucleic Acids Res 2006, 34(13):3698. 10.1093/nar/gkl454
Chen R, Weng Z: Docking Unbound Proteins Using Shape Complementarity, Desolvation, and Electrostatics. proteins 2002, (47):281–294. 10.1002/prot.10092
Al-Lazikani B, Lesk A, Chothia C: Standard conformations for the canonical structures of immunoglobulins. J Mol Biol 1997, 273(4):927–948. 10.1006/jmbi.1997.1354
Connolly ML: The molecular surface package. J Mol Graphics 1993, 11(2):139–141. 10.1016/0263-7855(93)87010-3
Hayryan S, Hu C, Skrivanek J, Hayryane E, Pokorny I: A new analytical method for computing solvent-accessible surface area of macromolecules and its gradients. J Comput Chem 2005, 26(4):334–343. 10.1002/jcc.20125
Fraczkiewicz R, Braun W: Exact and efficient analytical calculation of the accessible surface areas and their gradients for macromolecules. J Comput Chem 1998, 19(3):319–333. 10.1002/(SICI)1096-987X(199802)19:3<319::AID-JCC6>3.0.CO;2-W
Eisenhaber F, Argos P: Improved strategy in analytic surface calculation for molecular systems: Handling of singularities and computational efficiency. J Comput Chem 1993, 14(11):1272–1280. 10.1002/jcc.540141103
Still WC, Tempczyk A, Hawley RC, Hendrickson T: Semianalytical treatment of solvation for molecular mechanics and dynamics. J Am Chem Soc 1990, 112(16):6127–6129. 10.1021/ja00172a038
Eisenhaber F, Lijnzaad P, Argos P, Sander C, Scharf M: The double cubic lattice method: Efficient approaches to numerical integration of surface area and volume and to dot surface contouring of molecular assemblies. J Comput Chem 1995, 16(3):273–284. 10.1002/jcc.540160303
Masuya M, Doi J: Detection and geometric modeling of molecular surfaces and cavities using digital mathematical morphological operations. J Mol Graphics 1995, 13(6):331–336. 10.1016/0263-7855(95)00071-2
Lattman E: Optimal sampling of the rotation function. Acta Crys B 1972, 28(4):1065–1068. 10.1107/S0567740872003723
Jiang F, Kim SH: "Soft docking": Matching of molecular surface cubes. J Mol Biol 1991, 219(1):79–102. 10.1016/0022-2836(91)90859-5
Krippahl L, Moura J, Palma P: Modeling protein complexes with BiGGER. Proteins 2003, 52(1):19–23. 10.1002/prot.10387
Law DS, Eyck LFT, Katzenelson O, Tsigelny I, Roberts VA, Pique ME, Mitchell JC: Finding needles in haystacks: Reranking DOT results by using shape complementarity, cluster analysis, and biological information. Proteins 2003, 52(1):33–40. 10.1002/prot.10395
Ma X, Li C, Shen L, Gong X, Chen W, Wang C: Biologically enhanced sampling geometric docking and backbone flexibility treatment with multiconformational superposition. Proteins 2005, 60(2):319–323. 10.1002/prot.20577
Acknowledgements
This work is supported by the NSFC under Grant No. 11074084 and 30525037.
Author information
Authors and Affiliations
Corresponding authors
Additional information
Authors' contributions
LL participated in the design of the study, performed computation and analysis, and drafted the manuscript. DG and YH participated in prediction work of CAPRI rounds 18-19. SL helped to improve the programs and draft the manuscript. YX designed and finally wrote the manuscript. All authors read and approved the final manuscript.
Electronic supplementary material
12859_2010_4351_MOESM1_ESM.XLS
Additional file 1:Docking performance of different programs. The additional file 1 is a table that contains the detailed data of Figure 4B, i.e., the success rates of ASPDock, GeoDock (Shape complementarity docking using ASPDock algorithm), FTDock and ZDock3.0 methods on the benchmark 3.0. (XLS 38 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Li, L., Guo, D., Huang, Y. et al. ASPDock: protein-protein docking algorithm using atomic solvation parameters model. BMC Bioinformatics 12, 36 (2011). https://doi.org/10.1186/1471-2105-12-36
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2105-12-36