
Abstract
Background
While occurring enzymatically in biological systems, O-linked glycosylation affects protein folding, localization and trafficking, protein solubility, antigenicity, biological activity, as well as cell-cell interactions on membrane proteins. Catalytic enzymes involve glycotransferases, sugar-transferring enzymes and glycosidases which trim specific monosaccharides from precursors to form intermediate structures. Due to the difficulty of experimental identification, several works have used computational methods to identify glycosylation sites.
Results
By investigating glycosylated sites that contain various motifs between Transmembrane (TM) and non-Transmembrane (non-TM) proteins, this work presents a novel method, GlycoRBF, that implements radial basis function (RBF) networks with significant amino acid pairs (SAAPs) for identifying O-linked glycosylated serine and threonine on TM proteins and non-TM proteins. Additionally, a membrane topology is considered for reducing the false positives on glycosylated TM proteins. Based on an evaluation using five-fold cross-validation, the consideration of a membrane topology can reduce 31.4% of the false positives when identifying O-linked glycosylation sites on TM proteins. Via an independent test, GlycoRBF outperforms previous O-linked glycosylation site prediction schemes.
Conclusion
A case study of Cyclic AMP-dependent transcription factor ATF-6 alpha was presented to demonstrate the effectiveness of GlycoRBF. Web-based GlycoRBF, which can be accessed at http://GlycoRBF.bioinfo.tw, can identify O-linked glycosylated serine and threonine effectively and efficiently. Moreover, the structural topology of Transmembrane (TM) proteins with glycosylation sites is provided to users. The stand-alone version of GlycoRBF is also available for high throughput data analysis.
Similar content being viewed by others

Background
Protein glycosylation adds an oligosaccharide (chain of sugars) to a polypeptide (chain of amino acids) in order to produce a glycoprotein. Many proteins in eukaryotic cells are glycoproteins since they contain oligosaccharide chains covalently linked to certain amino acids. Among the predominant sugars found in glycoproteins include xylose, fucose, galactose, glucose, mannose, N-acetylglucosamine, N-acetylgalactosamine, and N-acetylneuraminic acid [1]. Specific carbohydrate epitopes can serve as ligands for receptors that mediate recognition events [2]. Catalytic enzymes involve glycotransferases, sugar-transferring enzymes and glycosidases which trim specific monosaccharides from precursors to form intermediate structures [3]. As is well known, glycosylation affect protein folding, localization and trafficking, protein solubility, antigenicity, and biological activity, as well as cell-cell interactions on membrane proteins [4]. Protein glycosylation can be divided into four main categories mainly depending on the linkage between the amino acid and the sugar, including N-linked glycosylation, O-linked glycosylation, C-mannosylation and glycophosphatidlyinositol (GPI) anchor attachments [5].
Owing to the difficulty of experimental identification, several works have computationally identified glycosylation sites, which could be a feasible means of conducting preliminary analyses and significantly reducing the number of potential targets that require further in vivo or in vitro confirmation. Blom et al. [6] are the first group to propose a method for computationally identifying glycosylation sites. Gupta et al. [7] have proposed a web-based tool, named NetNGlyc, for identifying N-glycosylation sites in human proteins. Li et al. [8] applied support vector machine (SVM) for predicting O-glycosylation sites in mammalian proteins. Caragea et al. [9] have used the ensembles of SVM classifiers to predict glycosylation sites. Additionally, NetOglyc3.1 [2], CKSAAP [10], and GPP [11] are well-maintained O-linked glycosylation prediction web servers. Julenius et al. [2] combined sequence, surface accessibility, secondary structure, and distance constraints for building neural network glycosylation prediction model. Chen et al. [10] analyzed the k-spaced amino acid pairs of glycol-proteins and developed support vector machine based method to predict O-link glycosylation sites. Hamby and Hirst [11] adopted the random forests method, integrating frequencies of amino acids surrounding modified residue and significant pairwise patterns for predicting glycosylation site.
By investigating glycosylated sites that contain various motifs between transmembrane (TM) proteins and non-transmembrane (non-TM) proteins, this work presents a novel method, GlycoRBF, that implements radial basis function (RBF) networks for identifying O-linked glycosylated sites on TM proteins and non-TM proteins. Based on statistical measurement, the significant amino acid pairs (SAAPs) that surround O-linked glycosylation sites are adopted to improve the prediction performance. By combining the identified SAAPs with the sequence of amino acids, the predictive specificity for glycosylated TM proteins and non-TM proteins is greatly improved; this is based on an evaluation using five-fold cross validation. Additionally, a membrane topology is considered for reducing the false positives on glycosylated TM proteins. Via an independent test, GlycoRBF outperforms previously published glycosylation site prediction schemes. To investigate the characteristics of O-linked glycosylation sites in a comprehensive manner, 531 physicochemical properties, that were extracted from version 9.1 of AAindex [12], were evaluated for its ability to distinguish the glycosylation sites from the non-glycosylation sites. To demonstrate the performance of GlycoRBF, a case study of Cyclic AMP-dependent transcription factor ATF-6 alpha was presented. Web-based GlycoRBF, which can be accessed at http://GlycoRBF.bioinfo.tw, can identify O-linked glycosylated serine and threonine effectively and efficiently. Moreover, the membrane topology of TM proteins with glycosylation sites is provided to users. The stand-alone version of GlycoRBF is also available for high throughput data analysis.
Methods
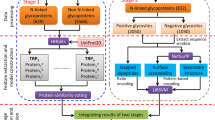
According to Figure 1, the analyzing flowchart consists of collecting and preprocessing data, extracting features, and learning and evaluating models. This work focuses on identifying O-linked glycosylation sites on Transmembrane (TM) and non-Transmembrane (non-TM) proteins. Following the model learning and evaluation, the selected models which contain the highest predictive accuracy are tested on an independent data set. All of the detailed processes are described as follows.

The analyzing flowchart of GlycoRBF.
Data collection and preprocessing
Release 15.0 of UniProt [13], which is the universal knowledge base of proteins, consists of 839 experimentally verified O-linked glycosylation sites in 239 glycoproteins. As shown in Table 1, 202 and 637 O-linked glycosylation sites are located on 40 TM proteins and 199 non-TM proteins, respectively. The O-linked glycosylation sites occurred mainly on residues of serine and threonine. In this work, all experimental O-linked glycosylated serine and threonine collected from UniProt are regarded as positive set of the original data. The amino acids of serine and threonine that have not been annotated as glycosylation sites on the experimental O-linked glycoproteins are regarded as negative set of the original data. Consequently, 2450 and 14234 non-glycosylation sites are located on TM proteins and non-TM proteins, respectively. The significant amino acid pairs (SAAPs) around the O-linked glycosylation sites are identified based on the original data. These SAAPs are then adopted to construct the radial basis function (RBF) networks for differentiating O-linked glycosylation sites from non-glycosylation sites on transmembrane and non-transmembrane proteins. To prevent overestimation of the predictive performance, homologous sequences are removed from the dataset by using a window size of 2n+1 for O-linked glycosylation sites. With reference to the reduction of the homology in the original dataset of MASA [14], two glycosylated protein sequences with more than 30% identity were defined as homologous sequences. Then, two homologous sequences were specified to re-align the fragment sequences using a window length of 2n+1, centered on the glycosylated sites using BL2SEQ [15]. For two fragment sequences with 100% identity, when the glycosylated sites in the two proteins are in the same positions, only one site was kept while the other was discarded. The non-homologous negative data were generated using the same approach as positive one.
As for classification, the prediction performance of the trained models may be overestimated owing to the over-fitting of a training set. The experimental O-linked glycosylation sites of HPRD release 8.0 [16], which were not included in UniProt [13], are regarded as the independent test set and are used to estimate the actual prediction performance. According to Table 1, 4 and 44 O-linked glycosylation sites are located on 9 TM proteins and 13 non-TM proteins, respectively. Similar to the extraction of a negative set of training data, a total of 1,238 and 662 non-glycosylated serines/threonines on TM proteins and non-TM proteins, respectively, are regarded as a negative set of independent test data. After the evaluation using k-fold cross-validation, the independent test set is evaluated by using the trained model with the highest accuracy. Independent test sets are utilized not only to demonstrate the effectiveness of the proposed method, but also to evaluate the performances of other previously proposed O-linked glycosylation prediction schemes.
Feature extraction
Fragments of amino acids are extracted from positive and negative training sets using a window of length 2n+1 that is centered on O-linked glycosylation sites. Different values of n are used to determine the optimal window length. BLOSUM62 matrix is adopted to represent the protein primary sequence information as the basic feature set for learning radial basis function networks. A matrix of (2n+ 1) × m elements is used to represent each residue of a training dataset, where 2n+ 1 stands for the window size and m consists of 21 elements including 20 types of amino acids and one for terminal signal. Each row of the normalized BLOSUM62 matrix is utilized to encode each type of 20 amino acids.
In order to make further investigation of substrate site specificity, the significant amino acid pairs between transmembrane (TM) and non-transmembrane (non-TM) glycoproteins are identified based on statistical measurement of F-score [17]. Each position surrounding glycosylation site is calculated a value of F-score. The F-score of the i th feature is defined as:
where , , and , denote the average value of the i th feature in whole, positive, and negative data sets, respectively; n+ denotes the number of positive data set and n- denotes the number of negative data set;
denotes the i th feature of the k th positive instance, and denotes the i th feature of the k th negative instance [17].
After the calculation of the F-score value in each position around the glycosylated site, the significant position with highest F-score value is regarded as the starting point for extracting the significant amino acid pairs. As shown in Figure 1, the most frequent amino acids in significant position are determined and used to detect another frequent amino acid which is located on the other position. With the determination of one frequent amino acid on a specific position, another amino acid on a different position can be defined to generate the amino acid pair. After the detection of all amino acid pairs, each identified amino acid pair is calculated an F-score value, which indicates the significance of predicting glycosylation sites. To encode the amino acid pairs, a binary dimension in the features vector is set to 1 if a protein sequence contains the significant amino acid pair. Based on the results of the k-fold cross-validation, the ranked significant amino acid pairs can be added into the features vector one by one (forward feature selection) until the predictive performance is maximized.
Model learning and evaluation
In this work, we adopted the QuickRBF package [18] to construct radial basis function network (RBFN) classifiers. As presented in Additional file 1, Figure S1, a general RBFN consists of three layers, namely the input layer, the hidden layer, and the output layer. The input layer broadcasts the coordinates of the input vector to each of the nodes in the hidden layer. Each node in the hidden layer then produces an activation based on the associated radial basis kernel function. Finally, each node in the output layer computes a linear combination of the activations of the hidden nodes. The general mathematical form of the output nodes in RBFN is as follows:
where c j (x) denotes the function corresponding to the j-th output node and is a linear combination of k radial basis functions ?() with center µ i and bandwidth s i ; Also, w ji denotes the weight associated with the correlation between the j-th output node and the i-th hidden node. In this work, we adopted a fixed bandwidth (s) of 5, and used all input nodes as centers (k = n). With its several bioinformatics applications, classification based on radial basis function (RBF) network has been extensively adopted to predict factors such as the cleavage sites in proteins [19], inter-residue contacts [20], protein disorder [21], and discrimination of ß-barrel proteins [22].
Predictive performance of the constructed models is evaluated by performing five-fold cross validation. The five-fold cross validation has been performed with the sequence level. The 239 glycoproteins are divided into five approximately equal sized subgroups, about 48 sequences in each subgroup. In one round of cross-validation, a subgroup is regarded as the test set, and the remaining four subgroups are regarded as the training set. The RBFN classifier has been done for each fold separately using the data on training set and evaluated with the test set. The cross-validation process is repeated five rounds, with each of five subgroups used as the test set in turn. Then, the five results are combined to produce a single estimation. The advantage of five-fold cross-validation is that all original data are regarded as both training set and test set, and each data is used for test exactly once [23]. The following measures of predictive performance of the trained models are defined. Precision (Pr) = TP/(TP+FP), Sensitivity (Sn) = TP/(TP+FN), Specificity (Sp) = TN/(TN+FP), Accuracy (Acc) = (TP + TN)/(TP+FP+TN+FN), Balanced Accuracy (BAcc) = (Sn+Sp)/2, and
where TP, TN, FP and FN denote the number of true positives, true negatives, false positives and false negatives, respectively. Additionally, predictive models are constructed for an independent test by using the window size and features that yield the highest accuracy.
Results and discussions
Distribution of O-linked glycosylation sites on transmembrane proteins
Based on the annotation of a membrane topology in UniProt [13], the distribution of glycosylated sites on transmembrane (TM) proteins is investigated. Table 2 summarizes the statistics of structural topology on 40 TM proteins. Six structural topology types are Lumenal (L), Nucleoplasmic (N), Extracellular (E); Cytoplasmic (C), Transmembrane (TM), and Signal peptide (S). For instance, as a nuclear membrane protein, Lamin-B receptor contains eight transmembrane segments which cover 27.4% of the sequence length. Table 3 displays the distribution of O-linked glycosylation sites on TM proteins. It is observed that nearly all of the O-linked glycosylation sites are located in the extracellular region of cell membrane proteins (87.6%). Furthermore, several O-linked glycosylation sites are located in luminal and nucleoplasmic regions which are the structural topology of non cell membrane proteins. According to the statistics of our dataset, no glycosylation sites are located on transmembrane regions as these could not be enzymatically accessed by glycotransferases. Therefore, the transmembrane regions of a protein can be considered to reduce the false positive of glycosylation site prediction.
Characterization of O-linked glycosylation sites on transmembrane proteins and non-transmembrane proteins
This work focuses on analyzing O-linked glycosylated serine and threonine residues on TM proteins and non-TM proteins. Following the removal of homologous sequence of glycosylation sites, as shown in Table 4, flanking amino acids (-14 ~ +14) of the non-homologous glycosylated serine and threonine residues (glycosylation site centered on position 0) are graphically visualized as sequence logos. WebLogo [24, 25] is adopted to generate the graphical sequence logo for the relative frequency of the corresponding amino acid at each position around the glycosylated sites. The conservation of amino acids that surround the glycosylation sites can then be easily examined. Based on the sequence logo representation, no amino acids around the modified sites are obviously conserved. However, several motifs are slightly varied between glycosylated TM and non-TM proteins. Thus, the flanking regions of glycosylation sites are examined to understand that the significant amino acid pairs differ between TM proteins and non-TM proteins, based on the F-score measurement.
Table 5 displays the identified significant amino acid pairs (SAAPs) flanking the O-linked glycosylated serine and threonine residues on the transmembrane proteins and non-transmembrane proteins. Each SAAP has a corresponding F-score value, implying that a higher value of F-score has more significant conservation in a specific dataset. For instance, the pair (+3T, +9E or +9T) suggests that the threonine (T) on position +3 and the glutamic acid (E) or threonine (T) on position +9 are significant with F-score 0.071 that surround O-linked glycosylated serine on transmembrane proteins. For the glycosylated TM proteins, 16 SAAPs and 25 SAAPs surround the O-linked glycosylated serine and threonine residues, respectively. For non-TM proteins, 32 SAAPS and 13 SAAPS are identified for O-linked glycosylated serine and threonine residues, respectively. All of the identified SAAPs are combined with the sequence of amino acids (BLOSUM62) to increase the prediction accuracy of O-linked glycosylation sites.
Predictive performance of cross-validation
In this work, 29-mer (-14 ~ +14) is selected as the window length in the following evaluation and implementation. Initially, the sequence of amino acids around O-linked glycosylation sites is encoded using BlOSUM62 matrix and is evaluated in terms of predictive performance. Without the classification of TM proteins and non-TM proteins, the estimated sensitivity, specificity, accuracy, and balanced accuracy are 58.8%, 84.5%, 83.3%, and 71.6%, respectively. According to Table 6, the predictive sensitivity, specificity, accuracy, and balanced accuracy of glycosylated TM proteins are 65.3%, 81.1%, 79.9%, and 73.2% respectively. Notably, the negative set of training data is markedly larger than the positive one, thus, necessitating a consideration of the balanced accuracy for the skewed dataset. For O-linked glycosylated non-TM proteins, the predictive sensitivity, specificity, accuracy, and balanced accuracy are 56.7%, 85.1%, 83.9%, and 70.9%, respectively.
Combining the significant amino acid pairs with the sequence of amino acids increases the predictive specificity for glycosylated membrane proteins to 85.1%. The accuracy and balanced accuracy are improved without affecting the estimated sensitivity. For non-TM proteins, both predictive sensitivity and specificity increased to 60.3% and 86.4%, respectively. Consequently, according to the evaluation of the five-fold cross validation, the identified significant amino acid pairs can increase the predictive performance of GlycoRBF.
Effects of considering membrane topology on transmembrane proteins
This work also investigates the various motifs of O-linked glycosylation sites between TM proteins and non-TM proteins. For TM proteins, the membrane topology can be considered to further increase the prediction accuracy. As for statistics of O-linked glycosylation sites on TM proteins (Table 3), the transmembrane region is assumed to reduce the number of false positive predictions. As shown in Table 6, false positive predictions are reduced from 462 to 317, thereby reducing false positive data by 31.4% as compared to models that do not consider membrane topology. Since O-linked glycosylation sites must be identified from a novel protein sequence, an effective membrane topology prediction tool, MEMSAT-SVM [26], was firstly applied to discriminate between TM and non-TM proteins and annotate the structural topology on TM proteins.
Predictive performance of an independent test
Models are evaluated whether they are over-fitted to their training data or not. This is done by constructing and using independent sets of data concerning O-linked glycosylated sites on TM proteins and non-TM proteins to demonstrate the effectiveness of the RBF models, which have the highest prediction accuracy. As presented in Table 7, the balanced accuracies of the proposed method are 60.1% and 70.9% when it is applied to glycosylated TM proteins and non-TM proteins, respectively. With 14 O-linked glycosylation sites and 1238 non-glycosylation sites on TM proteins, the proposed model can achieve a sensitivity of 50.0% and a specificity of 70.2%. For non-TM proteins, there are 44 O-linked glycosylation sites and 662 non-glycosylation sites, and the proposed model can achieve a sensitivity of 61.4% and a specificity of 80.4%. This analysis reveals that the performance in an independent test is comparable to that of the cross-validation.
Other O-linked glycosylation predictors were tested based on independent test sets. According to the results, GPP [11] has a high estimated sensitivity in identifying O-linked glycosylation sites but has a low estimated specificity when applied to independent test sets of TM proteins. For non-TM proteins, GPP has a balanced performance between sensitivity and specificity. NetOglyc3.1 [2] and CKSAAP [10] have poor sensitivity in identifying O-linked glycosylation sites, but have high specificity. Owing to a large size of non-glycosylation site, NetOglyc3.1, which has high estimated specificity, outperforms other methods in terms of prediction accuracy. While considering balanced accuracy, this method which specifies the degree of significance outperforms other approaches in term of predicting O-linked glycosylation sites. Also, according to [27], we have performed paired t-test as our statistical significance test during different approaches. The p-value of paired t-test between our proposed method and other methods are 0.024, 0.036, and 0.035, respectively. The p-values show that our proposed method is statistically different than other methods.
Implementation of the prediction scheme
In utilizing time-consuming and laboratory-intensive experimental identification of protein glycosylation sites, although glycosylated proteins can be identified, precisely identifying the glycosylated sites on the substrate is difficult. Therefore, an effective prediction scheme should be developed to efficiently identify potential O-linked glycosylation sites. Following evaluation by cross-validation and an independent test, amino acid sequences (BLOSUM62) and the significant amino acid pairs are utilized to construct RBF models in order to predict the O-linked glycosylation of serine and threonine. As shown in Figure 2, users can submit their uncharacterized protein sequences and select a specific TM protein whose structural topology is considered. The system, named GlycoRBF, returns the predictions efficiently, including O-linked glycosylated position, the flanking amino acids, significant amino acid pairs, and the sequence logo. In particular, the system provides the structural topology when users select TM-specific models for predicting the O-linked glycosylation sites. The stand-alone version of GlycoRBF is also available for high throughput data analysis.

The user interface of web-based GlycoRBF.
To demonstrate the performance of GlycoRBF, a case study was presented. Cyclic AMP-dependent transcription factor ATF-6 alpha, which is located in the endoplasmic reticulum membrane, has been proposed that under ER stress the cleaved N-terminal cytoplasmic domain translocates into the nucleus [28]. As shown in Figure 3, cyclic AMP-dependent transcription factor ATF-6 alpha was experimentally confirmed that contains three O-linked glycosylation sites at 474T, 586T, and 645T [29]. With the annotation of structural topology, GlycoRBF could specifically reduce the false positives and accurately identify the true glycosylated threonine at position 474, 586, and 645. The conserved amino acids round 474T and 586T are colored in Figure 3, based on the sequence logo of experimentally verified O-linked glycosylation site of threonine. Moreover, the significant amino acid pair, that was used to identify O-linked glycosylated 645T, is also provided.

A case study of human cyclic AMP-dependent transcription factor ATF-6 alpha that contains three O-linked glycosylation sites at 474T, 586T, and 645T, based on the annotation of HPRD.
Evaluation of physicochemical properties around the glycosylation sites
Most predictive models are based on the features of amino acid sequences. However, previous work has utilized 31 informative physicochemical properties to identify protein ubiquitylation sites [30]. To investigate the characteristics of O-linked glycosylation sites in a comprehensive manner, 531 physicochemical properties extracted from version 9.1 of AAindex [12] are evaluated to distinguish the glycosylation sites from the non-glycosylation sites. Based on the measurement of F-score, Figure 4 indicates that eight physicochemical properties around O-linked glycosylation sites have significantly differential values at position -7, -1, +1, and +3 (glycosylation site centered on position 0), which have a similar significance to BLOSUM62-coded amino acids. For glycosylated TM proteins, the significant physicochemical properties include linker propensity index [31], weights for alpha-helix at the window position of 3 [32], relative preference value at N4 [33], propensity of amino acids within pi-helices [34], helix-coil equilibrium constant [35], weights for alpha-helix at the window position of 4 [32], and linker index [36]. Each significant physicochemical property is combined with the feature of amino acid sequences for evaluation of the predictive performance using five-fold cross-validation. As shown in Table S1 (Additional file 1), the predictive performance of integrating physicochemical properties is similar to the model that only uses the feature of amino acid sequences.

The F -score measurement of top eight physicochemical properties surrounding the O-linked glycosylation sites of transmembrane proteins.
In the case of glycosylated non-TM proteins, the significant physicochemical properties consist of the number of bonds in the longest chain [37], absolute entropy, volume [38], side chain volume [39], radius of gyration of side chain [40], average volume of buried residue [41], and residue volume [42, 43]. Table S2 (Additional file 1) shows that the combination of physicochemical property and amino acid sequence performs slightly worse than the model that is only trained with the feature of amino acid sequences. To further investigate the functions of O-linked glycosylated non-TM proteins, the functional annotations that are obtained from Gene Ontology [44] are listed in Table S3 (Additional file 1). Most of the glycosylated non-TM proteins are associated with blood coagulation, inflammatory response, immune response, cell adhesion, and transporter.
Conclusions
O-linked glycosylation prediction methods in previous studies, including NetOglyc3.1 [2], CKSAAP [10], and GPP [11], do not consider glycosylated protein types. However, the proposed scheme incorporates significant amino acid pairs (SAAPs) to increase the prediction accuracy of O-linked glycosylated sites on transmembrane and non-transmembrane proteins. Based on the method of RBF networks, the cross-validation accuracies of O-linked glycosylated sites on TM proteins and non-TM proteins are 83.6% and 85.1%, respectively. When the structural topology on glycosylated TM proteins is considered, the prediction accuracy can reach 85.4%, subsequently reducing false positives by 31.4%. Comparison of the performance of the proposed approach with that of previous methods reveals that GlycoRBF has the significantly higher prediction accuracy according to independent testing. Additionally, GlycoRBF is implemented as an effective web server for predicting the O-linked glycosylation sites on TM proteins and non-TM proteins. A case study of Cyclic AMP-dependent transcription factor ATF-6 alpha was presented to demonstrate the effectiveness of GlycoRBF. The stand-alone version of GlycoRBF is also available for high throughput data analysis.
Although the proposed method can perform accurately and robustly, based on the results of independent tests, some issues must still be addressed in future work. First, there are numerous sugars found in glycoproteins including xylose, fucose, galactose, glucose, mannose, N-acetylglucosamine, N-acetylgalactosamine, and N-acetylneuraminic acid [1]. Various catalytic enzymes involve glycotransferases, sugar-transferring enzymes and glycosidases, which trim specific monosaccharides from precursors to form intermediate structures [3]. Therefore, future research should further investigate the characteristics of O-linked glycosylation sites according to the sugar types attached on glycosylated sites. Second, future research should examine the structural preferences of glycosylated sites in greater detail, especially in O-linked glycosylated serine and threonine, whose flanking residues are not conserved. In addition to the solvent accessible surface area, secondary structure, B-factor, intrinsic disordered region, protein linker region, and other factors at experimental O-linked glycosylation sites that are located in the protein regions with PDB entries, should be studied. Finally, the independent test sets that are proposed herein are blind to the trained model during cross-validation, but may not be to previously proposed predictors. Hence, developing a benchmark for constructing test sets that are truly independent of each predictor is a worthwhile task.
Availability
GlycoRBF can be accessed via a web interface, and is freely available to all interested users at http://GlycoRBF.bioinfo.tw. The stand-alone version of GlycoRBF is also available for high throughput data analysis. All of the data set that is used in this work is also available.
References
Hart GW: Glycosylation. Curr Opin Cell Biol 1992, 4(6):1017–1023. 10.1016/0955-0674(92)90134-X
Julenius K, Molgaard A, Gupta R, Brunak S: Prediction, conservation analysis, and structural characterization of mammalian mucin-type O-glycosylation sites. Glycobiology 2005, 15(2):153–164. 10.1093/glycob/cwh151
Lehninger AL ND, Cox MM: Lehninger Principles of Biochemistry. Fourth edition. W.H. Freeman; 2005.
Varki A: Biological roles of oligosaccharides: all of the theories are correct. Glycobiology 1993, 3(2):97–130. 10.1093/glycob/3.2.97
Farriol-Mathis N, Garavelli JS, Boeckmann B, Duvaud S, Gasteiger E, Gateau A, Veuthey AL, Bairoch A: Annotation of post-translational modifications in the Swiss-Prot knowledge base. Proteomics 2004, 4(6):1537–1550. 10.1002/pmic.200300764
Blom N, Sicheritz-Ponten T, Gupta R, Gammeltoft S, Brunak S: Prediction of post-translational glycosylation and phosphorylation of proteins from the amino acid sequence. Proteomics 2004, 4(6):1633–1649. 10.1002/pmic.200300771
Gupta R, Jung E: NetNGlyc: Prediction of N-glycosylation sites in human proteins. software 2005. [http://www.cbs.dtu.dk/services/NetNGlyc/]
Li S, Liu B, Zeng R, Cai Y, Li Y: Predicting O-glycosylation sites in mammalian proteins by using SVMs. Comput Biol Chem 2006, 30(3):203–208. 10.1016/j.compbiolchem.2006.02.002
Caragea C, Sinapov J, Silvescu A, Dobbs D, Honavar V: Glycosylation site prediction using ensembles of Support Vector Machine classifiers. BMC Bioinformatics 2007, 8: 438. 10.1186/1471-2105-8-438
Chen YZ, Tang YR, Sheng ZY, Zhang Z: Prediction of mucin-type O-glycosylation sites in mammalian proteins using the composition of k-spaced amino acid pairs. BMC Bioinformatics 2008, 9: 101. 10.1186/1471-2105-9-101
Hamby SE, Hirst JD: Prediction of glycosylation sites using random forests. BMC Bioinformatics 2008, 9: 500. 10.1186/1471-2105-9-500
Kawashima S, Pokarowski P, Pokarowska M, Kolinski A, Katayama T, Kanehisa M: AAindex: amino acid index database, progress report 2008. Nucleic Acids Res 2008, (36 Database):D202–205.
Apweiler R, Bairoch A, Wu CH, Barker WC, Boeckmann B, Ferro S, Gasteiger E, Huang H, Lopez R, Magrane M, et al.: UniProt: the Universal Protein knowledgebase. Nucleic Acids Res 2004, (32 Database):D115–119. 10.1093/nar/gkh131
Shien DM, Lee TY, Chang WC, Hsu JB, Horng JT, Hsu PC, Wang TY, Huang HD: Incorporating structural characteristics for identification of protein methylation sites. J Comput Chem 2009, 30(9):1532–1543. 10.1002/jcc.21232
Tatusova TA, Madden TL: BLAST 2 Sequences, a new tool for comparing protein and nucleotide sequences. FEMS Microbiol Lett 1999, 174(2):247–250. 10.1111/j.1574-6968.1999.tb13575.x
Peri S, Navarro JD, Kristiansen TZ, Amanchy R, Surendranath V, Muthusamy B, Gandhi TK, Chandrika KN, Deshpande N, Suresh S, et al.: Human protein reference database as a discovery resource for proteomics. Nucleic Acids Res 2004, (32 Database):D497–501. 10.1093/nar/gkh070
Lin C-J, Chen Y-W: Combining SVMs with various feature selection strategies. NIPS 2003 feature selection challenge 2003, 1–10.
Ou Y-Y: QuickRBF: an efficient RBFN package. software [http://csie.org/~yien/quickrbf/]
Yang ZR, Thomson R: Bio-basis function neural network for prediction of protease cleavage sites in proteins. IEEE Transactions on Neural Networks 2005, 16(1):263–274. 10.1109/TNN.2004.836196
Zhang GZ, Huang DS: Prediction of inter-residue contacts map based on genetic algorithm optimized radial basis function neural network and binary input encoding scheme. Journal of Computer-Aided Molecular Design 2004, 18(12):797–810. 10.1007/s10822-005-0578-7
Su CT, Chen CY, Ou YY: Protein disorder prediction by condensed PSSM considering propensity for order or disorder. Bmc Bioinformatics 2006., 7: 10.1186/1471-2105-7-319
Ou YY, Gromiha MM, Chen SA, Suwa M: TMBETADISC-RBF: Discrimination of beta-barrel membrane proteins using RBF networks and PSSM profiles. Computational Biology and Chemistry 2008, 32(3):227–231. 10.1016/j.compbiolchem.2008.03.002
Ron K: A study of cross-validation and bootstrap for accuracy estimation and model selection. Proceedings of the Fourteenth International Joint Conference on Artificial Intelligence 1995, 2(12):1137–1143.
Crooks GE, Hon G, Chandonia JM, Brenner SE: WebLogo: a sequence logo generator. Genome Res 2004, 14(6):1188–1190. 10.1101/gr.849004
Schneider TD, Stephens RM: Sequence logos: a new way to display consensus sequences. Nucleic Acids Res 1990, 18(20):6097–6100. 10.1093/nar/18.20.6097
Nugent T, Jones DT: Transmembrane protein topology prediction using support vector machines. BMC Bioinformatics 2009, 10: 159. 10.1186/1471-2105-10-159
Dietterich T: Approximate statistical tests for comparing supervised classification learning algorithms. Neural computation 1998, 10(7):1895–1923. 10.1162/089976698300017197
Okada T, Haze K, Nadanaka S, Yoshida H, Seidah NG, Hirano Y, Sato R, Negishi M, Mori K: A serine protease inhibitor prevents endoplasmic reticulum stress-induced cleavage but not transport of the membrane-bound transcription factor ATF6. J Biol Chem 2003, 278(33):31024–31032. 10.1074/jbc.M300923200
Hong M, Luo S, Baumeister P, Huang JM, Gogia RK, Li M, Lee AS: Underglycosylation of ATF6 as a novel sensing mechanism for activation of the unfolded protein response. J Biol Chem 2004, 279(12):11354–11363. 10.1074/jbc.M309804200
Tung CW, Ho SY: Computational identification of ubiquitylation sites from protein sequences. BMC Bioinformatics 2008, 9: 310. 10.1186/1471-2105-9-310
Suyama M, Ohara O: DomCut: prediction of inter-domain linker regions in amino acid sequences. Bioinformatics 2003, 19(5):673–674. 10.1093/bioinformatics/btg031
Qian N, Sejnowski TJ: Predicting the secondary structure of globular proteins using neural network models. J Mol Biol 1988, 202(4):865–884. 10.1016/0022-2836(88)90564-5
Richardson JS, Richardson DC: Amino acid preferences for specific locations at the ends of alpha helices. Science 1988, 240(4859):1648–1652. 10.1126/science.3381086
Fodje MN, Al-Karadaghi S: Occurrence, conformational features and amino acid propensities for the pi-helix. Protein Eng 2002, 15(5):353–358. 10.1093/protein/15.5.353
Finkelstein AV, Ptitsyn OB, Kozitsyn SA: Theory of protein molecule self-organization. II. A comparison of calculated thermodynamic parameters of local secondary structures with experiments. Biopolymers 1977, 16(3):497–524. 10.1002/bip.1977.360160303
Bae K, Mallick BK, Elsik CG: Prediction of protein interdomain linker regions by a hidden Markov model. Bioinformatics 2005, 21(10):2264–2270. 10.1093/bioinformatics/bti363
Charton M, Charton BI: The dependence of the Chou-Fasman parameters on amino acid side chain structure. J Theor Biol 1983, 102(1):121–134. 10.1016/0022-5193(83)90265-5
Grantham R: Amino acid difference formula to help explain protein evolution. Science 1974, 185(4154):862–864. 10.1126/science.185.4154.862
Krigbaum WR, Komoriya A: Local interactions as a structure determinant for protein molecules: II. Biochim Biophys Acta 1979, 576(1):204–248.
Levitt M: A simplified representation of protein conformations for rapid simulation of protein folding. J Mol Biol 1976, 104(1):59–107. 10.1016/0022-2836(76)90004-8
Chothia C: Structural invariants in protein folding. Nature 1975, 254(5498):304–308. 10.1038/254304a0
Bigelow CC: On the average hydrophobicity of proteins and the relation between it and protein structure. J Theor Biol 1967, 16(2):187–211. 10.1016/0022-5193(67)90004-5
Goldsack DE, Chalifoux RC: Contribution of the free energy of mixing of hydrophobic side chains to the stability of the tertiary structure of proteins. J Theor Biol 1973, 39(3):645–651. 10.1016/0022-5193(73)90075-1
Ashburner M, Ball CA, Blake JA, Botstein D, Butler H, Cherry JM, Davis AP, Dolinski K, Dwight SS, Eppig JT, et al.: Gene ontology: tool for the unification of biology. The Gene Ontology Consortium. Nat Genet 2000, 25(1):25–29. 10.1038/75556
Acknowledgements
This work was partially supported by National Science Council (NSC) of Taiwan, NSC99-2320-B155-001 to TYL, and NSC99-2221-E155-073 to YYO. We thank the reviewers for their constructive comments, which improved the quality of this manuscript.
Author information
Authors and Affiliations
Corresponding author
Additional information
Authors' contributions
TYL and YYO conceived and supervised the project. SAC was responsible for the design, computational analyses, implemented the web-based tool, and draft the manuscript with revisions provided by TYL and YYO. All authors read and approved the final manuscript.
Shu-An Chen, Tzong-Yi Lee contributed equally to this work.
Electronic supplementary material
12859_2010_4119_MOESM1_ESM.DOC
Additional file 1: Figure S1. The general architecture of RBFN consisting of input layer, hidden layer, and output layer. Table S1. The predictive performance of significant physicochemical properties in glycosylated transmembrane proteins. Table S2. The predictive performance of significant physicochemical properties in glycosylated non-transmembrane proteins. Table S3. Functional analysis of glycosylated non-transmembrane proteins. Table S4. Independent dataset of transmembrane protein. Table S5. The distribution of O-linked glycosylation sites on transmembrane proteins of independent test set. (DOC 514 KB)
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
{kind=link}
Rights and permissions
Open Access This article is published under license to BioMed Central Ltd. This is an Open Access article is distributed under the terms of the Creative Commons Attribution License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article
Cite this article
Chen, SA., Lee, TY. & Ou, YY. Incorporating significant amino acid pairs to identify O-linked glycosylation sites on transmembrane proteins and non-transmembrane proteins. BMC Bioinformatics 11, 536 (2010). https://doi.org/10.1186/1471-2105-11-536
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1471-2105-11-536