
Abstract
This paper is motivated by several interesting problems in statistics. We first define the concept of quasi-log concavity, and a conjecture involving quasi-log concavity is proposed. By means of analysis and inequality theories, several interesting results related to the conjecture are obtained; in particular, we prove that log concavity implies quasi-log concavity under proper hypotheses. As applications, we first prove that the probability density function of k-normal distribution is quasi-log concave. Next, we point out the significance of quasi-log concavity in the analysis of variance. Next, we prove that the generalized hierarchical teaching model is usually better than the generalized traditional teaching model. Finally, we demonstrate the applications of our results in the research of the allowance function in the generalized traditional teaching model.
MSC:26D15, 62J10.
Similar content being viewed by others


1 Introduction
Convexity and concavity are essential attributes of functions, their research and applications are important topics in mathematics (see [1–12]).
There are many types of convexity and concavity, one of them is log concavity which has many applications in statistics (see [2, 4, 7–12]). In [4], the authors apply the log concavity to study the Roy model, and some interesting results are obtained (see p.1128 in [4]), which include the following: If D is a log concave random variable, then
Recall the definitions of log-concave function (see [1–5]) and β-log-concave function (see [13]): If the function satisfies the inequality
then we say that the function is a β-log-concave function. 0-log-concave function is called a log-concave function. In other words, the function is a log-concave function if and only if the function logp is a concave function. If is a concave function, then we call the function a log-convex function. Here I is an interval (or high dimension interval).
For the log-concave function, we have the following results (see [5]). Let the function be differentiable, where I is an interval. Then the function p is a log-concave function if and only if the function is decreasing, i.e., if , , then we have
Let the function be twice differentiable. Then the function p is a log-concave function if and only if
Let for convenience that
It is well known that there is a wide range of applications of log concavity in probability and statistics theories (see [2, 4, 7–12]). However, quasi-log concavity also has fascinating significance in probability and statistics theories, see Section 4 and Section 5. The main object of this paper is to introduce the quasi-log concavity of a function and demonstrate its applications in the analysis of variance.
Now we introduce the definition of quasi-log concavity and quasi-log convexity as follows.
Definition 1.1 A differentiable function is said to be quasi-log concave if the following inequality
holds, here I is an interval. If inequality (1.5) is reversed, then the function is said to be quasi-log convex.
We remark here if the function is twice continuously differentiable, then inequality (1.5) can be rewritten as follows:
Now we show that for the twice continuously differentiable function, quasi-log concavity implies log concavity, and quasi-log convexity implies log convexity.
Indeed, suppose that is twice continuously differentiable and quasi-log concave. Then (1.6) holds. Hence
for all so that
Therefore, (1.4) holds and p is log concave on I. Similarly, we can prove that quasi-log convexity implies log convexity.
On the other hand, we can prove that for the twice continuously differentiable function log convexity implies quasi-log convexity.
Indeed, suppose that is twice continuously differentiable and log convex. Then (1.4) is reversed. Hence
that is, inequality (1.6) is reversed, here we used the Cauchy inequality
Therefore, p is quasi-log convex on I.
Unfortunately, we have not found the connection between quasi-log concavity and β-log concavity, where .
Based on the above analysis, we have reason to propose a conjecture (abbreviated as quasi-log concavity conjecture) as follows.
Conjecture 1.1 (Quasi-log concavity conjecture)
Suppose that the function is twice continuously differentiable. If p is log concave, then p is quasi-log concave. Here I is an interval.
We have done a lot of experiments with mathematical software to verify the correctness of Conjecture 1.1, but did not find a counter-example.
We remark that similar concepts may be defined for sequences . We first define
the sequence is called a log-concave sequence if
and is called quasi-log concave if
Set in (1.8). Then (1.8) can be rewritten as (1.7). Hence for the sequence , quasi-log concavity implies log concavity. Similarly, we can define a log-convex sequence and quasi-log convexity of a sequence. We expect inter-relations between these concepts but they will be dealt with elsewhere.
In this paper, we are concerned with Conjecture 1.1 and demonstrate the applications of our results in the analysis of variance and the generalized hierarchical teaching model with generalized traditional teaching model. Our motivation is to study several interesting problems in statistics.
In Section 2, we take up Conjecture 1.1. In Section 3, we give several illustrative examples. In Section 4, we prove that the probability density function of the k-normal distribution is quasi-log concave. In Section 5, we demonstrate the applications of these results, we show that the generalized hierarchical teaching model is normally better than the generalized traditional teaching model (see Remark 5.3), and we point out the significance of quasi-log concavity in the analysis of variance and the generalized traditional teaching model.
2 Study of Conjecture 1.1
For Conjecture 1.1, we have the following five theorems.
Theorem 2.1 Let the function be twice continuously differentiable, log concave and monotone. If
then p is quasi-log concave.
Proof Since the function p is log concave, we have
so inequality (2.1) is well defined.
Without loss of generality, we may assume that
Note that for any positive real number λ and any real numbers x, y, we have the inequality
the equality holds if and only if .
According to inequality (2.1), there exists a positive real number λ such that
From (2.3) we know that for the positive real number λ, we have
and
Indeed, since
inequality (2.4) is equivalent to the inequalities
and inequality (2.5) is equivalent to the inequalities
or
Hence if inequalities (2.3) hold, then both inequality (2.4) and inequality (2.5) hold. That is to say, inequalities (2.4) and (2.5) are equivalent to inequalities (2.3).
Since is monotonic, we obtain that
Combining with (2.2), (2.4), (2.5) and (2.10), we get
This means that inequality (1.6) holds.
The proof of Theorem 2.1 is completed. □
Corollary 2.1 Let the function be thrice continuously differentiable and log concave. If
then the function is quasi-log concave.
Proof Let
From (2.11), we have
and
hence
By Theorem 2.1, the function is quasi-log concave. This ends the proof. □
Theorem 2.2 Let the function be twice continuously differentiable and log concave. If
then is quasi-log concave.
Proof Now we prove that (1.6) holds as follows.
Without loss of generality, we assume that and . Note that
and
According to Lagrange mean value theorem, there are two real numbers , ,
such that
and
hence
From (2.6) and the Lagrange mean value theorem, we get
i.e.,
where
Combining with (2.13), (2.14) and (2.15), we get inequality (1.6).
This completes the proof of Theorem 2.2. □
Theorem 2.3 Let the function be thrice continuously differentiable. If
then the function
is quasi-log concave.
Proof Let
We just need to show that
Since
without loss of generality, we can assume that
and a is a fixed constant.
Note that
and
Hence
and
From
(2.19) and (2.20), we may see that
Let
Then
i.e.,
Based on assumption (2.16), and (2.23), we have
From (2.24), (2.18) and (2.22), we have
By (2.25) and (2.18), we get
That is to say, inequality (2.17) holds.
We remark that the equality in (2.17) holds if and only if .
The proof of Theorem 2.3 is completed. □
Theorem 2.4 Let the function be four times continuously differentiable. If
and
then the function
is quasi-log concave, where c is a constant.
In order to prove Theorem 2.4, we need the following lemma.
Lemma 2.1 Under the assumptions of Theorem 2.4, if
then we have
Proof Without loss of generality, we can assume that and a is a fixed constant.
We continue to use the proof of Theorem 2.3. Note that equation (2.23) can be rewritten as
where
Based on assumption (2.27), and (2.32), we have
which means that is strictly increasing for the variable .
From (2.32), we may see that
We prove inequality (2.30) in two cases (A) and (B).
-
(A)
Assume that
(2.35)
By (2.34), (2.35) and the intermediate value theorem, there exists only one number such that
From (2.33) and (2.31), we get
and
hence is strictly decreasing if and strictly increasing if .
If , since , we have
and
This means that inequality (2.30) holds.
Now we assume that
Note that is strictly decreasing if , we have
By (2.37), (2.38), is strictly increasing if and the continuity, we know that there exists a unique real number such that
Since
and
we know that is strictly decreasing if and strictly increasing if , so that
This means that inequality (2.30) also holds.
-
(B)
Assume that
(2.41)
Since is strictly increasing for the variable , we have
and
That is to say, inequality (2.30) still holds.
The proof of Lemma 2.1 is completed. □
The proof of Theorem 2.4 is now relatively easy.
Proof of Theorem 2.4 We just need to show that (2.17) holds. Without loss of generality, we assume that
Let such that
By Lemma 2.1, inequality (2.30) holds.
We define the auxiliary function as follows:
Then, by (2.27), we have
and
According to Lemma 2.1 and
we get
Since
we have
and inequality (2.44) can be rewritten as
Combining with inequalities (2.30) and (2.45), we get
In (2.46), set , , we get
According to conditions (2.28) and (2.47), inequality (2.17) holds.
This completes the proof of Theorem 2.4. □
Theorem 2.5 Let the function be four times continuously differentiable. If
and (2.27) holds, then the function
is quasi-log concave.
Proof We just need to show that (2.17) holds. Without loss of generality, we assume that
Set in Lemma 2.1, we have
To complete the proof of inequality (2.17), by (2.50), we just need to show that
Now, we believe that the real number a is variable. By condition (2.48), we have
and
i.e.,
where
If , then , (2.51) holds by (2.52). Here we assume that .
Note that
Since
the limit
exists.
If
from , we have
and
If
then, by (2.54), (2.48) and L’Hospital’s rule, we have
that is to say, (2.55) also holds. Hence
By (2.52), inequality (2.51) holds.
The proof of Theorem 2.5 is completed. □
3 Four illustrative examples
In order to illustrate the connotation of quasi-log concavity, we give four examples as follows.
Example 3.1 The function
is quasi-log concave.
Proof Indeed, if
then is twice continuous differentiable and log concave with monotonous function, and
hence
By Theorem 2.1, the function is quasi-log concave. That is to say, for any , inequality (1.5) holds.
Let
Since
inequality (1.5) still holds. The proof is completed. □
Example 3.2 The function
is quasi-log concave, where
is the root of the equation
Proof Indeed, in Theorem 2.4, set , then
By means of Mathematica software, we get
the equation holds if and only if .
Since
and
so (2.27) and (2.28) hold. By Theorem 2.4, the function is quasi-log concave. This ends the proof. □
Example 3.3 The function
is quasi-log concave, where .
Proof Note that inequality (1.6) can be rewritten as
If , then
inequality (3.2) holds. Let . Then
Since
and
we have
that is to say, inequality (3.2) still holds. The proof is completed. □
Example 3.4 The function
is quasi-log concave.
Proof Indeed,
and
hence equations in (2.48) hold. Since
and
inequalities in (2.27) hold. By Theorem 2.5, the function p is quasi-log concave. This ends the proof. □
In the next section, we demonstrate the applications of Theorem 2.3 and Theorem 2.5 in the theory of k-normal distribution.
4 Quasi-log concavity of pdf of k-normal distribution
The normal distribution (see [14–16]) is considered as the most prominent probability distribution in statistics. Besides the important central limit theorem that says the mean of a large number of random variables drawn from a common distribution, under mild conditions, is distributed approximately normally, the normal distribution is also tractable in the sense that a large number of related results can be derived explicitly and that many qualitative properties may be stated in terms of various inequalities.
But perhaps one of the main practical uses of the normal distribution is to model empirical distributions of many different random variables encountered in practice. In such a case, a possible generalization would be families of distributions having more than two parameters (namely the mean and the standard variation) which may be used to fit empirical distributions more accurately. Examples of such generalizations are the normal-exponential-gamma distribution which contains three parameters and the Pearson distribution which contains four parameters for simulating different skewness and kurtosis values.
In this section, we first introduce another generalization of the normal distribution as follows: If the probability density function of the random variable X is
then we say that the random variable X follows the k-normal distribution or generalized normal distribution (see [17] or [18]), denoted by , where
and is the well-known gamma function.
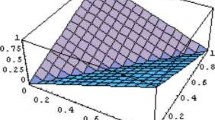
For the probability density function of k-normal distribution, the graphs of the functions , and are depicted in Figure 1 and is depicted in Figure 2.

The graphs of the functions , and , where .

The graph of the function , where , .
Clearly, when , is just the standard normal distribution with mean μ and standard deviation σ, and it is easily checked that is symmetric about 0 and that
According to (4.1), we get (see (2) in [17])
According to the results of [17], we may easily show that (see [17], p.688)
and
Here μ, and σ are the mathematical expectation, k-order absolute central moment and k-order mean absolute central moment of the random variable X, respectively.
We remark here if
then
and
where is the probability density function of a Weibull distribution. Therefore, there are close relationships between the k-normal distribution and the Weibull distribution.
Next, we study the quasi-log concavity of the probability density function of k-normal distribution.
Theorem 4.1 The probability density function of the k-normal distribution is quasi-log concave on for all , and .
Proof In view of (4.2), we may assume that
Let for convenience that
where
Then
where the last equality holds because p is even.
Now we show that
in two steps (A) and (B).
-
(A)
We first consider the case where .
By (4.8) and continuity, without loss of generality, we may assume that either
We first consider the case (i): .
By (4.4), we have
Since
and
equations in (2.48) hold. Since
and
inequalities in (2.27) hold. By Theorem 2.5, inequality (4.9) holds.
Next, we consider the case (ii): .
Since
we have
that is, inequality (4.9) still holds.
-
(B)
Next we assume that .
Since
and
inequalities in (2.16) hold. By Theorem 2.3, inequality (4.9) holds.
Based on the above analysis, inequality (4.9) is proved.
The proof of Theorem 4.1 is completed. □
In the next section, we demonstrate the applications of Theorem 4.1 in the generalized hierarchical teaching model and the generalized traditional teaching model.
5 Applications in statistics
5.1 Hierarchical teaching model and truncated random variable
We first introduce the hierarchical teaching model as follows.
The usual teaching model assumes that the math scores of each student in a class are treated as a continuous random variable, written as , which takes on some value in the real interval , and its probability density function is continuous. Suppose we now divide the students into m classes, written as
where
and
are the lowest and the highest allowable scores of the students of , respectively. We introduce a set
called a hierarchical teaching model (see [19–22]) such that the traditional teaching model, denoted by , is just a special , where .
If and , then and are called generalized hierarchical teaching model and generalized traditional teaching model, respectively.
In order to study the hierarchical teaching model and the traditional teaching model from the angle of the analysis of variance, we need to recall the definition of truncated random variable.
Definition 5.1 Let be a continuous random variable with continuous probability density function . If is also a continuous random variable and its probability density function is
then we call the random variable a truncated random variable of the random variable , written as . If and , then we call the random variable a proper truncated random variable of the random variable , written as . Here I and J are high dimensional intervals.
We point out that a basic property of the truncated random variable is as follows: Let be a continuous random variable with continuous probability density function . If
then . If
then .
Indeed, by Definition 5.1, the probability density functions of the truncated random variables , are
respectively. Thus, the probability density function of can be rewritten as
Hence
According to the definitions of the mathematical expectation and the variance with Definition 5.1, we easily get
and
where , and the function of the random variable is continuous.
In the generalized hierarchical teaching model , the math scores of each student in is also a random variable, written as . Since
so is a truncated random variable of the random variable . Assume that the classes, i.e.,
are merged into one, written as . Since , we know that is a truncated random variable of the random variable , where . In general, we have
In the generalized hierarchical teaching model , we are concerned with the relationship between the variance and the variance , where , so as to decide the superiority and inferiority of the hierarchical and the traditional teaching models.
If
then in view of the usual meaning of the variance, we tend to think that this generalized hierarchical teaching model is better than the generalized traditional teaching model. Otherwise, this generalized hierarchical teaching model is probably not worth promoting, where .
In this section, one of our purposes is to study the generalized hierarchical teaching model and the generalized traditional teaching model from the angle of the analysis of variance so as to decide the superiority and inferiority of the generalized hierarchical and the generalized traditional teaching models. In particular, we will study the conditions such that inequality (5.4) holds (see Theorem 5.2).
In the generalized hierarchical teaching model , we can choose the parameters such that the ‘variance’
of
is the minimal by means of mathematical software, its purpose is to make the scores of the classes
stable, where and .
Remark 5.1 We remark here if is a continuous random variable with continuous probability density function , then the integration converges (see [23]), and it satisfies the following conditions:
We call the function a probability distribution function of the random variable , where is the probability of the random event ‘’, and I is an interval.
5.2 Applications in the analysis of variance
The analysis of variance is one of the central topics in statistics. Recently, the authors [24] have expanded the connotation of analysis of variance and obtained some interesting results.
In this section, we point out the significance of quasi-log concavity in the analysis of variance as follows.
Theorem 5.1 Let be a continuous random variable and its probability density function be twice continuously differentiable. Then the function is quasi-log concave if and only if
where is a truncated random variable of the random variable .
Proof By identities (2.6) and (5.1) with (5.2), we get
i.e.,
According to identity (5.8), we know that inequality (1.6) can be rewritten as (5.7).
This completes the proof of Theorem 5.1. □
Remark 5.2 According to Theorem 5.1, quasi-log concavity is of great significance in the analysis of variance.
5.3 Applications in the generalized hierarchical teaching model
Now we demonstrate the application of Theorem 4.1 in the generalized hierarchical teaching model.
In the generalized hierarchical teaching model , the math scores of each student are treated as a random variable , where . By using the central limit theorem (see [25]), we may think that the random variable follows a normal distribution, that is, , where μ is the average score of the students and σ is the mean square deviation of the score. Hence
We remark here that if the math scores of each student satisfies
then, by (5.9), we have
Hence we can use the generalized hierarchical teaching model instead of the hierarchical teaching model, approximately.
Based on the above analysis and Theorem 4.1, we have the following theorem.
Theorem 5.2 In the generalized hierarchical teaching model , assume that . Then we have the following inequality:
Proof Note that
is quasi-log concave by Theorem 4.1, hence inequality (5.7) holds by Theorem 5.1, so we obtain that
Note that
where C is a constant. By (5.11), we have
that is to say, inequality (5.10) holds.
This completes the proof of Theorem 5.2. □
Remark 5.3 According to Theorem 5.2, we may conclude that the generalized hierarchical teaching model is normally better than the generalized traditional teaching model.
5.4 Applications in the generalized traditional teaching model
Next, we demonstrate the applications of Theorem 4.1 in the generalized traditional teaching model as follows.
In the generalized traditional teaching model , the math scores of each student are treated as a random variable , where . By using the central limit theorem (see [25]), we may think that the random variable ξ follows a normal distribution, that is, , where μ is the average score of the students and σ is the mean square deviation of the score. If the top and bottom students are insignificant, that is to say, the variance of the random variable is close to 0, according to Figure 1 and Figure 2 with formula (4.7), we may think that there is a real number such that . Otherwise, we may think that there is a real number such that . We can estimate the number k by means of a sampling procedure.
In the generalized traditional teaching model , we may assume that
where , and is the average math score of the students and σ is the k-order mean absolute central moment of the score. Then the probability density function of is that
In the generalized traditional teaching model , suppose that the math score of the student is . In order to stimulate the learning enthusiasm of students, we may want to give each student a bonus payment . The function
may be regarded as an allowance function.
In the generalized traditional teaching model , we define the allowance function as follows:
For the above allowance function (5.12), we have the following theorem.
Theorem 5.3 In the generalized traditional teaching model , assume that
Then we have the following inequalities:
Here the allowance function is defined by (5.12).
Proof By Theorem 4.1, the function is quasi-log concave on J. Hence inequalities (5.7) hold by Theorem 5.1. Note that
and
where C is a constant. By inequalities (5.7), we get
and
That is to say, inequalities (5.13) hold.
This completes the proof of Theorem 5.3. □
Remark 5.4 A large number of inequality analysis and statistical theories are used in this paper. Some theories in the proofs of our results are used in the references [5, 23, 24, 26–34].
References
Tong Y: An adaptive solution to ranking and selection problems. Ann. Stat. 1978,6(3):658-672. 10.1214/aos/1176344210
Bagnoli, M, Bergstrom, T: Log-concave probability and its applications. Mimeo (1991)
Patel JK, Read CB: Handbook of the Normal Distribution. 2nd edition. CRC Press, Boca Raton; 1996.
Heckman JJ, Honor BE: The empirical content of the Roy model. Econometrica 1990,58(5):1121-1149. 10.2307/2938303
Wang WL: Approaches to Prove Inequalities. Harbin Institute of Technology Press, Harbin; 2011.(in Chinese) (in Chinese)
Wen JJ, Gao CB, Wang WL: Inequalities of J-P-S-F type. J. Math. Inequal. 2013,7(2):213-225.
Mohtashami Borzadaran GR, Mohtashami Borzadaran HA: Log concavity property for some well-known distributions. Surv. Math. Appl. 2011, 6: 203-219.
An, MY: Log-concave probability distributions: theory and statistical testing. Working paper, Duke University (1995)
An, MY: Log-concavity and statistical inference of linear index modes. Manuscript, Duke University (1997)
Finner H, Roters M: Log-concavity and inequalities for Chi-square, F and Beta distributions with applications in multiple comparisons. Stat. Sin. 1997, 7: 771-787.
Miravete EJ: Preserving log-concavity under convolution: Comment. Econometrica 2002,70(3):1253-1254. 10.1111/1468-0262.00327
Al-Zahrani B, Stoyanov J: On some properties of life distributions with increasing elasticity and log-concavity. Appl. Math. Sci. 2008,2(48):2349-2361.
Caramanis C, Mannor S: An inequality for nearly log-concave distributions with applications to learning. IEEE Trans. Inf. Theory 2007,53(3):1043-1057.
Wlodzimierz B: The Normal Distribution: Characterizations with Applications. Springer, Berlin; 1995.
Spiegel MR: Theory and Problems of Probability and Statistics. McGraw-Hill, New York; 1992:109-111.
Whittaker ET, Robinson G: The Calculus of Observations: A Treatise on Numerical Mathematics. 4th edition. Dover, New York; 1967:164-208.
Nadarajah S: A generalized normal distribution. J. Appl. Stat. 2005,32(7):685-694. 10.1080/02664760500079464
Varanasi MK, Aazhang B: Parametric generalized Gaussian density estimation. J. Acoust. Soc. Am. 1989,86(4):1404-1415. 10.1121/1.398700
Hawkins GE, Brown SD, Steyvers M, Wagenmakers EJ: Context effects in multi-alternative decision making: empirical data and a Bayesian model. Cogn. Sci. 2012, 36: 498-516. 10.1111/j.1551-6709.2011.01221.x
Yang CF, Pu YJ: Bayes analysis of hierarchical teaching. Math. Pract. Theory 2004(in Chinese),34(9):107-113. (in Chinese)
de Valpine P: Shared challenges and common ground for Bayesian and classical analysis of hierarchical models. Ecol. Appl. 2009, 19: 584-588. 10.1890/08-0562.1
Carlin BP, Gelfand AE, Smith AFM: Hierarchical Bayesian analysis of change point problem. Appl. Stat. 1992,41(2):389-405. 10.2307/2347570
Wen JJ, Han TY, Gao CB: Convergence tests on constant Dirichlet series. Comput. Math. Appl. 2011,62(9):3472-3489. 10.1016/j.camwa.2011.08.064
Wen JJ, Han TY, Cheng SS: Inequalities involving Dresher variance mean. J. Inequal. Appl. 2013.Article ID 366, 2013: Article ID 366
Johnson OT: Information Theory and the Central Limit Theorem. Imperial College Press, London; 2004:88.
Wen JJ, Zhang ZH: Jensen type inequalities involving homogeneous polynomials. J. Inequal. Appl. 2010. Article ID 850215, 2010: Article ID 850215
Wen JJ, Cheng SS: Optimal sublinear inequalities involving geometric and power means. Math. Bohem. 2009,2009(2):133-149.
Peĉarić JE, Wen JJ, Wang WL, Tao L: A generalization of Maclaurin’s inequalities and its applications. Math. Inequal. Appl. 2005,8(4):583-598.
Gao CB, Wen JJ: Theory of surround system and associated inequalities. Comput. Math. Appl. 2012, 63: 1621-1640. 10.1016/j.camwa.2012.03.037
Wen JJ, Wang WL: Inequalities involving generalized interpolation polynomial. Comput. Math. Appl. 2008,56(4):1045-1058. 10.1016/j.camwa.2008.01.032
Wen JJ, Wang WL: Chebyshev type inequalities involving permanents and their applications. Linear Algebra Appl. 2007,422(1):295-303. 10.1016/j.laa.2006.10.014
Wen JJ, Cheng SS: Closed balls for interpolating quasi-polynomials. Comput. Appl. Math. 2011,30(3):545-570.
Wen JJ, Wu SH, Gao CB: Sharp lower bounds involving circuit layout system. J. Inequal. Appl. 2013.Article ID 592, 2013: Article ID 592
Wen JJ, Wu SH, Tian YH: Minkowski-type inequalities involving Hardy function and symmetric functions. J. Inequal. Appl. 2014. Article ID 186, 2014: Article ID 186
Acknowledgements
This work was supported in part by the Natural Science Foundation of China (No. 61309015) and the Natural Science Foundation of Sichuan Province Education Department (No. 07ZA207). The authors are indebted to several unknown referees for many useful comments and keen observations which led to the present improved version of the paper as it stands.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
All authors contributed equally and significantly in this paper. All authors read and approved the final manuscript.
Authors’ original submitted files for images
Below are the links to the authors’ original submitted files for images.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License ( https://creativecommons.org/licenses/by/2.0 ), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article

{kind=link}
{kind=link}
Cite this article
Wen, J.J., Han, T.Y. & Cheng, S.S. Quasi-log concavity conjecture and its applications in statistics. J Inequal Appl 2014, 339 (2014). https://doi.org/10.1186/1029-242X-2014-339
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1029-242X-2014-339