
Abstract
In this paper, we present a new type of extra-gradient method for generalized variational inequalities with multi-valued mapping in an infinite-dimensional Hilbert space. For this method, the generated sequence possesses an expansion property with respect to the initial point, and the existence of the solution to the problem can be verified through the behavior of the generated sequence. Furthermore, under mild conditions, we show that the generated sequence of the method strongly converges to the solution of the problem which is closest to the initial point.
MSC:90C30, 15A06.
Similar content being viewed by others

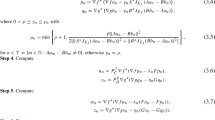
1 Introduction
Let F be a multi-valued mapping from ℋ into with nonempty values, where ℋ is a real Hilbert space. Let X be a nonempty, closed and convex subset of the Hilbert space ℋ. The generalized variational inequality problem, abbreviated as GVIP, is to find a vector such that there exists satisfying
where stands for the inner product of vectors in ℋ. If the multi-valued mapping F is a single-valued mapping from ℋ to ℋ, then the GVIP collapses to the classical variational inequality problem [1, 2].
The generalized variational inequalities find application in economics and transportation equilibrium, engineering sciences, etc. and have received much attention in the past decades [3–11]. It is well known that the extra-gradient method [5, 12] is a popular solution method, which has a contraction property, i.e., the generated sequence by the method satisfies
for any solution of the GVIP. It should be noted that the proximal point algorithm also possesses this property [13]. In this paper, inspired by the work in [14] for finding the zeros of maximal monotone operators in a real Hilbert space, we proposed a new type of extra-gradient solution method for the GVIP which has the following expansion property w.r.t. the initial point, i.e.,
Furthermore, we establish the strong convergence of the method in the case that the solution set is nonempty, and we show that the generated sequence diverges to infinity if the solution set is empty.
The rest of this paper is organized as follows. In Section 2, we give some related concepts and conclusions needed in the subsequent analysis. In Section 3, we present our designed algorithm and establish the convergence of the algorithm.
2 Preliminaries
Let and K be a nonempty, closed, and convex subset in ℋ. A point is said to be the orthogonal projection of x onto K if it is the closest point to x in K, i.e.,
and we denote by . The well-known properties of the projection operator are as follows.
Lemma 2.1 [15]
Let K be a nonempty, closed, and convex subset in ℋ. Then for any , and , the following statements hold:
-
(i)
;
-
(ii)
.
Remark 2.1 In fact, (i) in Lemma 2.1 also provides a sufficient condition for a vector u to be the projection of the vector x, i.e., if and only if
Definition 2.1 Let K be a nonempty subset of ℋ. The multi-valued mapping is said to be
-
(i)
monotone if and only if
-
(ii)
pseudo-monotone if and only if, for any , , ,
To proceed, we present the definition of maximal monotone multi-valued mapping F.
Definition 2.2 Let K be a nonempty subset of ℋ. The multi-valued mapping is said to be a maximal monotone operator if F is monotone and the graph
is not properly contained in the graph of any other monotone operator.
It is clear that a monotone multi-valued mapping F is maximal if and only if, for any such that , , then .
Definition 2.3 Let K be a nonempty, closed, and convex subset of the Hilbert space ℋ. A multi-valued mapping is said to be
-
(i)
upper semi-continuous at if for every open set V containing , there is an open set U containing x such that for all ;
-
(ii)
lower semi-continuous at if given any sequence converging to x and any , there exists a sequence that converges to y;
-
(iii)
continuous at if it is both upper semi-continuous and lower semi-continuous at x.
Throughout this paper, we assume that the multi-valued mapping is maximal monotone and continuous on X with nonempty compact convex values, where is a nonempty, closed, and convex set.
3 Main results
For any and , set
Then the projection residue can verify the solution set of problem (1.1).
Proposition 3.1 Point solves problem (1.1) if and only if i.e.,
Now, we give the description of the designed algorithm for problem (1.1), whose basic idea is as follows. At each step of the algorithm, compute the projection residue at iterate . If it is a zero vector for some , then stop with being a solution of problem (1.1); otherwise, find a trial point by a back-tracking search at along the residue , and the new iterate is obtained by projecting onto the intersection of X with two halfspaces, respectively, associated with and . Repeat this process until the projection residue is a zero vector.
Algorithm 3.1
Step 0: Choose , , .
Step 1: Given the current iterate , if for some , stop; else take any and compute
Take
where , with being the smallest non-negative integer m satisfying such that
Step 2: Let , where
Set and go to Step 1.
The following conclusion addresses the feasibility of the stepsize rule (3.1), i.e., the existence of point .
Lemma 3.1 If is not a solution of problem (1.1), then there exists a smallest non-negative integer m satisfying (3.1).
Proof By the definition of and Lemma 2.1, it follows that
which implies
Since , we get
Combining this with the fact that F is continuous, we know that there exists such that
hence, by (3.2), one has
This completes the proof. □
Lemma 3.2 Suppose the solution set is nonempty, then the halfspace in Algorithm 3.1 separates the point from the set . Moreover,
Proof By the definition of and Algorithm 3.1, we have
which can be written as
Then, by this and (3.1), one has
where is a vector in . So, by the definition of and (3.3) it follows that .
On the other way, for any and , we have
Since F is monotone on X, one has
Let in (3.4). Then for any ,
which implies . Moreover, since
the desired result follows. □
Regarding the projection step, we shall prove that the set is always nonempty, even when the solution set is empty. Therefore the whole algorithm is well defined in the sense that it generates an infinite sequence .
Lemma 3.3 If the solution set , then for all .
Proof From the analysis in Lemma 3.2, it is sufficient to prove that for all . The proof will be given by induction. Obviously, if ,
Now, suppose that
holds for . Then
For any , by Lemma 2.1 and the fact that
we have
Thus . This shows that for all and the desired result follows. □
Lemma 3.4 Suppose that , then for all .
Proof On the contrary, suppose is the smallest non-negative number such that
Then , , are defined for , and there exists a positive number M such that
and
where
Set
Then is a lower semi-continuous proper convex function. By the definition of subgradient, we have
So, and
are all maximal monotone mappings [16]. Furthermore,
and , , for also satisfy the conditions of Algorithm 3.1. Since the domain of is bounded, by the proof of Theorem 2 in [14], we know that has a zero point i.e., there exists a point such that
which implies that the solution set is nonempty. We arrive at a contradiction and the desired result follows. □
In order to establish the convergence of the algorithm, we first show the expansion property of the algorithm w.r.t. the initial point.
Lemma 3.5 Suppose Algorithm 3.1 reaches an iteration . Then
Proof By the iterative process of Algorithm 3.1, one has
So and
From the definition of , it follows that
Thus, from Remark 2.1. Then, from Lemma 2.1, we have
which can be written as
i.e.,
and the proof is completed. □
From Lemma 3.4, Algorithm 3.1 generates an infinite sequence if the solution set of problem (1.1) is empty. More precisely, we have the following conclusion.
Theorem 3.1 Suppose Algorithm 3.1 generates an infinite sequence . Assume the sequence is bounded away from zero. Then the generated sequence is bounded and its each weak accumulation point is a solution of problem (1.1) if the solution set is nonempty. Otherwise
if the solution set is empty.
Proof For the case that , by Lemma 3.3 and
we know that
for any . So, is a bounded sequence.
Then, by Lemma 3.5, we know the sequence is nondecreasing and bounded, which implies that
On the other hand, by the fact that , we have
where can be chosen as (3.1). Since
by (3.6), one has
which can be written as
Using the Cauchy-Schwarz inequality and (3.1), we obtain
Since F is continuous with compact values, Proposition 3.11 in [17] implies that is a bounded set, and hence the sequence is bounded. Thus, by (3.5) and (3.7), it follows that
By assumption that is bounded away from zero, we have
Since the sequence is bounded, it has weak accumulation points. Without loss of generality, assume that the subsequence weakly converges to , i.e.,
Since is a continuous and single valued operator, from Theorem 2 of [18], we know that is a weak continuous operator. Thus,
for some and is a solution of problem (1.1).
Now, consider the case that the solution set is empty. For this case, the inequality
and (3.5) still hold. Thus, the sequence is also nondecreasing. Now, we claim that
Otherwise, a similar argument to the one above leads to the conclusion that any weak accumulation point of is a solution of problem (1.1), which contradicts the emptiness of the solution set, and the conclusion follows. □
We are in a position to prove strong convergence of Algorithm 3.1.
Theorem 3.2 Suppose Algorithm 3.1 generates an infinite sequence . If the solution set is nonempty and the sequence is bounded away from zero, then the sequence converges strongly to a solution such that ; otherwise, . That is, the solution set of problem (1.1) is empty if and only if the sequence generated by Algorithm 3.1 diverges to infinity.
Proof For the case that the solution set is nonempty, from Theorem 3.1, we know that the sequence is bounded and that every weak accumulate point of is a solution of problem (1.1). Let be a weakly convergent subsequence of , and let be its weak limit. Let . Then by Lemma 3.3,
for all j. So, from the iterative procedure of Algorithm 3.1,
one has
Thus,
where the inequality follows from (3.9). Letting , it follows that
Due to Lemma 2.1 and the fact that and , we have
Combing this with (3.10) and the fact that is a weak limit of , we conclude that the sequence strongly converges to and
Since was taken as an arbitrary weak accumulation point of , it follows that is the unique weak accumulation point of this sequence. Since is bounded, the whole sequence weakly converges to . On the other hand, we have shown that every weakly convergent subsequence of converges strongly to . Hence, the whole sequence converges strongly to .
For the case that the solution set is empty, the conclusion can be obtained directly from Theorem 3.1. □
References
Harker PT, Pang JS: Finite-dimensional variational inequality and nonlinear complementarity problems: a survey of theory, algorithms and applications. Math. Program. 1990, 48: 161–220. 10.1007/BF01582255
Wang YJ, Xiu NH, Zhang JZ: Modified extragradient method for variational inequalities and verification of solution existence. J. Optim. Theory Appl. 2003, 119: 167–183.
Auslender A, Teboulle M: Lagrangian duality and related multiplier methods for variational inequality problems. SIAM J. Optim. 2000, 10: 1097–1115. 10.1137/S1052623499352656
Ben-Tal A, Nemirovski A: Robust convex optimization. Math. Oper. Res. 1998, 23: 769–805. 10.1287/moor.23.4.769
Censor Y, Gibali A, Reich S: The subgradient extragradient method for solving variational inequalities in Hilbert space. J. Optim. Theory Appl. 2011, 148: 318–335. 10.1007/s10957-010-9757-3
Fang SC, Peterson EL: Generalized variational inequalities. J. Optim. Theory Appl. 1982, 38: 363–383. 10.1007/BF00935344
Fang CJ, He Y: A double projection algorithm for multi-valued variational inequalities and a unified framework of the method. Appl. Math. Comput. 2011, 217: 9543–9551. 10.1016/j.amc.2011.04.009
He Y: Stable pseudomonotone variational inequality in reflexive Banach spaces. J. Math. Anal. Appl. 2007, 330: 352–363. 10.1016/j.jmaa.2006.07.063
Huang NJ: Generalized nonlinear variational inclusions with noncompact valued mappings. Appl. Math. Lett. 1996,9(3):25–29. 10.1016/0893-9659(96)00026-2
Li S, Chen G: On relations between multiclass, multicriteria traffic network equilibrium models and vector variational inequalities. J. Syst. Sci. Syst. Eng. 2006,15(3):284–297. 10.1007/s11518-006-5012-8
Saigal R: Extension of the generalized complementarity problem. Math. Oper. Res. 1976, 1: 260–266. 10.1287/moor.1.3.260
Korpelevich GM: The extragradient method for finding saddle points and other problems. Matecon 1976, 12: 747–756.
Allevi E, Gnudi A, Konnov IV: The proximal point method for nonmonotone variational inequalities. Math. Methods Oper. Res. 2006, 63: 553–565. 10.1007/s00186-005-0052-2
Solodov MV, Svaiter BF: Forcing strong convergence of proximal point iterations in a Hilbert space. Math. Program. 2000, 87: 189–202.
Polyak BT: Introduction to Optimization. Optimization Software Incorporation, Publications Division, New York; 1987.
Rockafellar RT: On the maximality of sums of nonlinear monotone operators. Trans. Am. Math. Soc. 1970, 149: 75–78. 10.1090/S0002-9947-1970-0282272-5
Aubin JP, Ekeland I: Applied Nonlinear Analysis. Wiley, New York; 1984.
Levine N: A decomposition of continuity in topological spaces. Am. Math. Mon. 1961,68(1):44–46. 10.2307/2311363
Acknowledgements
This work was supported by the Natural Science Foundation of China (Grant Nos. 11171180, 11101303), and the Specialized Research Fund for the Doctoral Program of Chinese Higher Education (20113705110002). The authors would like to thank the reviewers for their careful reading, insightful comments, and constructive suggestions, which helped improve the presentation of the paper.
Author information
Authors and Affiliations
Corresponding author
Additional information
Competing interests
The authors declare that they have no competing interests.
Authors’ contributions
All authors contributed equally to the writing of this paper. All authors read and approved the final manuscript.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 2.0 International License (https://creativecommons.org/licenses/by/2.0), which permits unrestricted use, distribution, and reproduction in any medium, provided the original work is properly cited.
About this article

Cite this article
Chen, H., Wang, Y. & Wang, G. Strong convergence of extragradient method for generalized variational inequalities in Hilbert space. J Inequal Appl 2014, 223 (2014). https://doi.org/10.1186/1029-242X-2014-223
Received:
Accepted:
Published:
DOI: https://doi.org/10.1186/1029-242X-2014-223