
Abstract
Uncertainty research is one of the critical problems in artificial intelligence. In an uncertain environment, a large quantity of information is expressed in linguistic values. Aiming at the missing linguistic-valued information, we first propose incomplete fuzzy linguistic formal context and then discuss the fuzzy linguistic approximate concept. Our proposal can describe the attributes of objects from two aspects simultaneously. One is an object's essential attributes, and another includes the essential and possible attributes. As a result, more object-related information can be obtained to reduce information loss effectively. We design a similarity metric for correcting the errors caused by the initial complement operation. We then construct a corresponding fuzzy linguistic approximate concept lattice for the task of approximate information retrieval. Finally, we illustrate the applicability and feasibility of the proposed approach with concrete examples, which clearly show that our approach can better deal with the linguistic-valued information in an uncertain environment.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
Concept lattice [1] is widely used in many fields [2,3,4], such as information retrieval, software engineering, recommendation systems, and knowledge discovery. It has made some achievements in knowledge reduction [1, 5], rule extraction [6, 7], decision analysis [8, 9], and uncertainty reasoning [10, 11], among others [12,13,14]. Concept lattice can be used to discover implicit concepts and their relationships, which can visualize acquired information. Traditionally, concept lattice aims to study the deterministic relationships between objects and their attributes based on formal context. To improve conceptual representation, Burusco et al. [15] combined fuzzy sets with classical concept lattices and extended concept lattices from a classical aspect to a fuzzy one; Krupka et al. [16] proposed an approach to constructing fuzzy concept lattices for incomplete data. Based on an incomplete formal context, Li et al. [17] constructed an approximate concept lattice and proposed an approach to extracting non-redundant approximate decision rules from the incomplete decision context; Li et al. [18] presented K-medoids clustering to compress the approximate concept lattice and clustered the approximate concepts in an incomplete context. In addition, formal concept analysis can be extended to three-way concepts: Yao [19] constructed a framework of three-way concepts in an incomplete formal context, identifying four partially known concepts to study their relationships with existing concepts; Li et al. [20] constructed approximate concepts based on three-way decision and further presented attribute reduction; Wang et al. [21] presented four attribute reduction methods based on SE-ISI concept lattices of incomplete contexts.
When the available information is inaccurate and cannot be calculated with numbers, computing with words becomes necessary, as Zadeh [22] proposed in word computing based on fuzzy sets. However, the calculation method of fuzzy linguistics may lead to information loss, and the fusion results may lack accuracy. Herrera et al. [23] proposed a 2-tuple fuzzy linguistic representation model to overcome this limitation that has been extended in [33], which allows a continuous representation of linguistic information. For discrete and continuous cases, Liao et al. [24] proposed a variety of weighted distances, ordered weighted distances, and similarity measures between hesitant fuzzy linguistic term sets. Liu et al. [25] mainly presented an algorithm of rule extraction using incomplete the multi-expert fuzzy linguistic formal decision context and applied it to multimedia teaching evaluation. To better express comparable or incomparable information in linguistics, Diao et al. [26] proposed a group decision-making method based on LTVIFL. Zou et al. [7] proposed a rule extraction method of LVIFL to meet the needs of experts at different levels and to help people make reasonable decisions. Wang [27] designed a preference decision optimization algorithm with the InPLPR for solving practical problems under the conditions of time pressure and lack of knowledge. In solving the large-scale group decision-making multiple proposals have been done [34] such as in social network (LSGDM-SN), Lu et al. [28] introduced a method of estimating incomplete values in HFPRs, and developed a consensus management process for distrust behaviors. Xu et al. [29] studied the linguistic preference relations with self-confidence which considers the acceptable adjustment range of experts.
To empress incomplete linguistic value information, we introduce linguistic value into an incomplete context inspired by previous works on applying concept lattice to an incomplete formal context. Moreover, we propose both an incomplete fuzzy linguistic formal context and fuzzy linguistic approximation concept for constructing a fuzzy linguistic approximation concept lattice. Overall, our method can improve the representation of uncertain knowledge and better deal with the linguistic-valued information in an uncertain environment.
The rest of this paper is organized as follows. Section 2 briefly reviews some basic notions related to linguistic term set and incomplete context. Section 3 introduces linguistic values into an incomplete context and proposes the incomplete fuzzy linguistic formal context (IFLC). Using a fuzzy linguistic approximation concept (FLAC), we construct a fuzzy linguistic approximation concept lattice (FLAL). In Sect. 4, we design a similarity measure based on IFLC, followed by a practical example to illustrate the feasibility. Finally, Sect. 5 is the summary of this paper.
2 Preliminaries
In this section, we briefly review the concepts of linguistic term set, incomplete context, and approximate concept, as listed in the following definitions for more details.
Definition 1.
[30]. Let \(S=\{{s}_{\alpha }|\alpha =-\tau,\dots,-\mathrm{1,0},1,\dots \tau \}\) a finite ordered set consisting of an odd number of linguistic terms, which \(\tau\) is a positive integer, if S satisfies the following properties:
-
1.
Ordering, \({s}_{\alpha }\le {s}_{\beta }\iff \alpha \le \beta\).
-
2.
Reversibility, \(Neg({s}_{-\alpha })={s}_{\alpha }\), which \(-\alpha +\alpha =0\).
-
3.
Boundedness, \({s}_{-\tau }\) and \({s}_{\tau }\) are the lower and upper bounds of linguistic labels, respectively.
The mid linguistic label \({s}_{0}\) represents an assessment of 'indifference', and the rest are placed symmetrically around it. For example, the linguistic term set S can be represented as \(S = \left\{ {s_{{ - 2}} = {\text{low}},s_{{ - 1}} = {\text{somewhat~low}},s_{0} = {\text{medium}},s_{1} = s{\text{omewhat~high}},s_{2} = {\text{high}}} \right\}\).
In this paper, we transform the 2-tuple representation model [23] of linguistic terms into a symmetric linguistic terms set.
Definition 2.
Let \(S=\{{s}_{\alpha }|\alpha =-\tau,\dots,-\mathrm{1,0},1,\dots \tau \}\) a finite ordered linguistic term set and \(\mu \in [-\tau,\tau ]\) a value representing the result of a symbolic aggregation operation, then the 2-tuple, which expresses the equivalent information to \(\mu\), is obtained with the following function:
\(\mathrm{round}(\cdot )\) is the usual round operation, \({s}_{\alpha }\) has the closest index label to \(\mu\), and \(\delta\) is the value of the symbolic translation.
Definition 3
[24]. Let \(S=\{{s}_{\alpha }|\alpha =-\tau,\dots,-\mathrm{1,0},1,\dots \tau \}\) a linguistic term set, the discrete linguistic term set S is extended to the continuous linguistic term set \(\overline{S} = \{ s_{\alpha } |\alpha \in \left[ { - q,q} \right]\}\), where \(q(q > \tau )\) is a sufficiently large positive integer. For any two linguistic terms \(s_{\alpha },s_{\beta } \in \overline{S}\), \(\lambda_{1},\lambda_{2},\lambda_{3} \in \left[ {0,1} \right]\), the following operational laws are introduced:
-
1.
\({s}_{\alpha }\oplus {s}_{\beta }={s}_{\alpha +\beta }\);
-
2.
\(\lambda {s}_{\alpha }={s}_{\lambda \alpha }\);
-
3.
\(({\lambda }_{1}+{\lambda }_{2}){s}_{\alpha }={\lambda }_{1}{s}_{\alpha }\oplus {\lambda }_{2}{s}_{\alpha }\);
-
4.
\(\lambda ({s}_{\alpha }\oplus {s}_{\beta })=\lambda {s}_{\alpha }\oplus \lambda {s}_{\beta }\).
Definition 4.
[32]. An incomplete context can be viewed as \((U,A,\{+,?,-\},I)\) consisting of a nonempty and finite set object U, a nonempty and finite attribute set A, the set \(\{+,?,-\}\) of values, and a mapping \(I:U\times A\to \{+,?,-\}\), where \(I(u,a)=+\) means that the object \(u\) has the attribute \(a\), \(I(u,a)=-\) means that the object \(u\) does not have the attribute \(a\), \(I\left(u,a\right)=?\) indicates that it is unknown whether or not the object \(u\) has the attribute \(a\).
Definition 5.
[17]. An incomplete context \((U,A,\{+,?,-\},I)\) with \(X\subseteq U\) is defined:
Definition 6.
[17]. Let \((U,A,\{+,?,-\},I)\) an incomplete context. For \(\forall X\in {2}^{U}\) and\((B,C)\in {2}^{A}\times {2}^{A}\), two operators \(\prec\): \({2}^{U}\to {2}^{A}\times {2}^{A}\) and \(\succ\): \({2}^{A}\times {2}^{A}\to {2}^{U}\) are respectively defined:
\(\underline {R} \left( X \right)\) is a pair \(\left( {\underline {R} \left( X \right),\overline{R}\left( X \right)} \right)\) with \(\overline{R}\left( X \right)\) containing precisely those attributes that are certain to be shared by all the objects in X and \(\overline{R}\left( X \right)\) containing those attributes that are possible to be shared by all the objects in X. \((B,C)^{ \succ }\) is the maximal set of the objects, featuring all the attributes in B with certainty and all the attributes in C with possibility.
Definition 7.
[17]. Let \((U,A,\{+,?,-\},I)\) an incomplete context. For \(\forall X\in {2}^{U}\) and \((B,C)\in {2}^{A}\times {2}^{A}\), if \({X}^{\prec }=(B,C)\) and \((B,C{)}^{\succ }=X\), we say that \((X,(B,C))\) is an approximate concept of \((U,A,\{+,?,-\},I)\). Here, X and \((B,C)\) are called the extension and the intention of the approximate concept \((X,(B,C))\), respectively.
3 Fuzzy Linguistic Approximate Concept Lattice Based on Incomplete Fuzzy Linguistic Formal Context
Based on incomplete context, this section further studies some related concepts of incomplete fuzzy linguistic formal context and constructs the fuzzy linguistic approximate concept lattice.
Definition 8.
Let \((U,A,\{S,\diamond \},{R}^{\diamond })\) an incomplete fuzzy linguistic formal context consisting of a nonempty and finite object set \(U=\{{u}_{i}|i\in \mathrm{1,2},\dots,n\}\), a nonempty and finite attribute set \(A=\{{a}_{j}|j\in \mathrm{1,2},\dots,m\}\),\(S=\{{s}_{\alpha }|\alpha =-\tau,\dots,-\mathrm{1,0},1,\dots,\tau \}\), and a mapping \({R}^{\diamond }:U\times A\to \{S,\diamond \}\). We denote the incomplete fuzzy linguistic formal context \((U,A,\{S,\diamond \},{R}^{\diamond })\) as \(IFLC(U,A,\{S,\diamond \},{R}^{\diamond })\).
Remark.
\(R^{\diamondsuit } \left( {u,a} \right) = \diamondsuit\)indicates that it is unknown whether the object u has the attribute a.\(A_{S}\) is the set of linguistic attribute values, which is the subset of U defined on A, where \(A_{S} = \left\{ {\frac{{s_{a} }}{a}{|}a \in A,s_{a} \in \left\{ {S,\diamondsuit } \right\}} \right\}\). If given a threshold value \(\lambda\), \(R^{\diamondsuit } \left( {u,a} \right) \ge \rlap{--} \lambda\) means that the object u has the attribute a, \(R^{\diamondsuit } \left( {u,a} \right) < \rlap{--} \lambda\) means that the object u does not have the attribute a.
Definition 9.
Let \(IFLC(U,A,\{S,\diamond \},{R}^{\diamond })\) and \(X\subseteq U\). The operators \(^{\prime }\), \(^{\prime \prime }\), \(^{\prime \square }\) and \(^{\prime \prime *}\) are defined as follows:
Remark.
If \({R}^{\diamond }(u,a)\) is incomparable to the threshold value \(\rlap{--} \lambda\), that is, \({R}^{\diamond }(u,a)=\diamond\), denoted as \(R^{\diamondsuit } \left( {u,a} \right)\parallel \rlap{--} \lambda\), all the corresponding attribute linguistic values are retained.
Definition 10.
Let \(IFLC(U,A,\{S,\diamond \},{R}^{\diamond })\) and \(X\subseteq U\), \(B,C\subseteq {A}_{S}\). Two operators are defined:
where \(X^{\prime \square }\) is the intersection set of the linguistic values of attributes that are certain to be shared by all the objects, \(X^{\prime \prime * }\) is the intersection set of the linguistic values of attributes that they have or may have, \((B,C{)}^{\nabla }\) is the intersection set of objects satisfied by the corresponding linguistic values of each attribute.
Definition 11.
Let \(IFLC(U,A,\{S,\diamond \},{R}^{\diamond })\) and \(X\subseteq U\), \(B,C\subseteq {A}_{S}\). If \({X}^{\Delta }=(B,C)\), \({X}^{\Delta }=(B,C)\) and \((B,C{)}^{\nabla }=X\), we say that \((X,(B,C))\) is a fuzzy linguistic approximate concept of \((U,A,\{S,\diamond \},{R}^{\diamond })\). Here, \(X\) and \((B,C)\) are called the extension and the intention of the fuzzy linguistic approximate concept \((X,(B,C))\), respectively.
\(FLAC(U,A,\{S,\diamond \},{R}^{\diamond })\) is used to represent the set of all fuzzy linguistic approximation concepts of \((U,A,\{S,\diamond \},{R}^{\diamond })\). For \(({X}_{1},({B}_{1},{C}_{1}))\), \(({X}_{2},({B}_{2},{C}_{2}))\in FLAL(U,A,\{S,\diamond \},{R}^{\diamond })\), the partial order relation “\(\le\)” can be defined:
Proposition 1.
Let \(IFLC(U,A,\{S,\diamond \},{R}^{\diamond })\) and \(X\subseteq U\), \(B,C\subseteq {A}_{S}\), then.
-
1.
\(X\subseteq {X}^{\Delta \nabla },(B,C)\subseteq (B,C{)}^{\nabla\Delta }.\)
-
2.
\({X}^{\Delta }={X}^{\Delta \nabla\Delta },(B,C{)}^{\nabla }=(B,C{)}^{\nabla\Delta \nabla }.\)
-
3.
\(X\subseteq (B,C{)}^{\nabla }\iff (B,C)\subseteq {X}^{\Delta }.\)
Proof.
It is easily obtained by Definition 10 and the proof is omitted.
Proposition 2.
Let \(IFLC(U,A,\{S,\diamond \},\diamond )\) and \(\forall {X}_{1},{X}_{2}\subseteq U\), \({B}_{1},{B}_{2},{C}_{1},{C}_{2}\subseteq {A}_{S}\), then.
-
\(({X}_{1}\cup {X}_{2}{)}^{\Delta }={{X}_{1}}^{\Delta }\cap {{X}_{2}}^{\Delta },(({B}_{1},{C}_{1})\cup ({B}_{2},{C}_{2}){)}^{\nabla }=({B}_{1},{C}_{1}{)}^{\nabla }\cap ({B}_{2},{C}_{2}{)}^{\nabla }.\)
-
\({{X}_{1}}^{\Delta }\cup {{X}_{2}}^{\Delta }\subseteq ({X}_{1}\cap {X}_{2}{)}^{\Delta },({B}_{1},{C}_{1}{)}^{\nabla }\cup ({B}_{2},{C}_{2}{)}^{\nabla }=(({B}_{1},{C}_{1})\cap ({B}_{2},{C}_{2}){)}^{\nabla }.\)
-
\({X}_{1}\subseteq {X}_{2}\Rightarrow {{X}_{2}}^{\Delta }\subseteq {{X}_{1}}^{\Delta },({B}_{1},{C}_{1})\subseteq ({B}_{2},{C}_{2})\Rightarrow ({B}_{2},{C}_{2}{)}^{\nabla }\subseteq ({B}_{1},{C}_{1}{)}^{\nabla }.\)
Proof.
It is easily obtained by Definition 10 and the proof is omitted.
Definition 12.
Let \(IFLC(U,A,\{S,\diamond \},{R}^{\diamond })\) and \(\forall {X}_{1},{X}_{2}\subseteq U\), \({B}_{1},{B}_{2},{C}_{1},{C}_{2}\subseteq {A}_{S}\), the infimum and supremum can be defined respectively:
4 A Similarity Completion Approach Based on Incomplete Fuzzy Linguistic Formal Context
Nowadays, the scale of data collected from real-world applications is enormous, and sometimes data are missing. The incompleteness of data brings specific difficulties to evaluation, interpretation and knowledge discovery. In order to solve this problem, we study a similarity complement approach based on incomplete fuzzy linguistic formal context.
4.1 A Similarity Completion Approach
Definition 13.
An initially filling in \(IFLC(U,A,\{S,\diamond \},{R}^{\diamond })\) with the mean value is:
\({\alpha }^{\diamond }=\mathrm{round}(.)\) is the usual round operation. \({A}_{c}\) represents the non-missing attribute set of object \({u}_{i}\), \({S}_{{A}_{c}}\) is the linguistic value set defined by U on \({A}_{c}\), \({S}_{{A}_{c}}=\{{s}_{{a}_{j}}\in S|{s}_{{a}_{1}},{s}_{{a}_{2}},\dots,{s}_{{a}_{m}}\}\), and \(\overline{S}_{{A_{c} }}^{{u_{i} }}\) is the mean value of the linguistic value set of the object \({u}_{i}\) on \({A}_{c}\).
Definition 14.
Let \((U,A,{S}^{*},{R}^{*})\) a fuzzy linguistic formal context after the initial complement consisting of \(U=\{{u}_{i}|i\in \mathrm{1,2},\dots,n\}\) and \(A=\{{a}_{j}|j\in \mathrm{1,2},\dots,m\}\). A mapping \({R}^{*}:U\times A\to {S}^{*}\), \({S}^{*}\) is a linguistic value set. \(FLC\left(U,A,{S}^{*},{R}^{*}\right)\) is used to denote the fuzzy linguistic formal context after the initial complement.
Definition 15.
\({S}_{A}^{*}\) is the linguistic value set of U defined on A in \(FLC\left(U,A,{S}^{*},{R}^{*}\right)\), \({S}_{A}^{*}=\{{s}_{{a}_{j}}\in {S}^{*}|{s}_{{a}_{1}},{s}_{{a}_{2}},\dots,{s}_{{a}_{m}}\}\). For \(\forall {u}_{p},{u}_{q}\in U\), the linguistic value sets are \({S}_{A}^{*{u}_{p}}\) and \({S}_{A}^{*{u}_{q}}\), respectively. The fuzzy linguistic similarity is defined by
\({\sum }_{j=1}^{m}\left|{S}_{{a}_{j}}^{*{u}_{p}}\cap {S}_{{a}_{j}}^{*{u}_{q}}\right|\) is the number of intersection elements of the linguistic value set between the objects \({u}_{p}\) and \({u}_{q}\). \({\sum }_{j=1}^{m}\left|{S}_{{a}_{j}}^{*{u}_{p}}\cup {S}_{{a}_{j}}^{*{u}_{q}}\right|\) is the number of union elements in a linguistic value set. \({\alpha }_{{a}_{j}}^{{u}_{p}}\) and \({\alpha }_{{a}_{j}}^{{u}_{q}}\) represent the linguistic value subscripts of attribute \({a}_{j}\) of the objects \({u}_{p}\) and \({u}_{q}\), respectively. \(\overline{\alpha }_{A}^{{u_{p} }}\) and \(\overline{\alpha }_{A}^{{u_{q} }}\) are the mean values of the linguistic value subscripts of attribute \({a}_{j}\) of the objects \({u}_{p}\) and \({u}_{q}\), respectively.
Proposition 3.
For \(\forall {u}_{p},{u}_{q}\in U\) in \(FLC\left(U,A,{S}^{*},{R}^{*}\right)\), the similarity between the linguistic value sets of \({u}_{p}\) and \({u}_{q}\) satisfies the following properties:
-
1.
\(0\le Si{m}^{Mixfl}({S}_{A}^{*{u}_{p}},{S}_{A}^{*{u}_{q}})\le 1\).
-
2.
\(Si{m}^{Mixfl}({S}_{A}^{*{u}_{p}},{S}_{A}^{*{u}_{q}})=Si{m}^{Mixfl}({S}_{A}^{*{u}_{q}},{S}_{A}^{*{u}_{p}})\).
-
3.
\(Si{m}^{Mixfl}({S}_{A}^{*{u}_{p}},{S}_{A}^{*{u}_{q}})=1\) iff \({S}_{A}^{*{u}_{p}}={S}_{A}^{*{u}_{q}}\).
Proof.
The proof can be completed according to Definition 15.
-
(1)
Since
$$0 \le \frac{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{p} }} \cap S_{{a_{j} }}^{{*u_{q} }} } \right|}}{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{p} }} \cup S_{{a_{j} }}^{{*u_{q} }} } \right|}} \le 1,\quad - 1 \le \frac{{\mathop \sum \nolimits_{j = 1}^{m} \left( {\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} } \right)\left( {\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} } \right)}}{{\sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} )^{2} } \sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} )^{2} } }} \le 1,$$we can easily get.
$$0 \le \frac{1}{2}\left( {\frac{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{p} }} \cap S_{{a_{j} }}^{{*u_{q} }} } \right|}}{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{p} }} \cup S_{{a_{j} }}^{{*u_{q} }} } \right|}}} \right) + \frac{1}{2}\left( {\frac{{\mathop \sum \nolimits_{j = 1}^{m} \left( {\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} } \right)\left( {\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} } \right)}}{{\sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} )^{2} } \sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} )^{2} } }} + 1} \right) \le 1.$$So we can get \(0\le Si{m}^{Mixfl}({S}_{A}^{*{u}_{p}},{S}_{A}^{*{u}_{q}})\le 1\).
-
(2)
\(Si{m}^{Mixfl}({S}_{A}^{*{u}_{p}},{S}_{A}^{*{u}_{q}})\)
$$= \frac{1}{2}\left( {\frac{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{p} }} \cap S_{{a_{j} }}^{{*u_{q} }} } \right|}}{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{p} }} \cup S_{{a_{j} }}^{{*u_{q} }} } \right|}} + \frac{1}{2}\left( {\frac{{\mathop \sum \nolimits_{j = 1}^{m} \left( {\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} } \right)\left( {\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} } \right)}}{{\sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} )^{2} } \sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} )^{2} } }} + 1} \right)} \right)$$$$= \frac{1}{2}\left( {\frac{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{q} }} \cap S_{{a_{j} }}^{{*u_{p} }} } \right|}}{{\mathop \sum \nolimits_{j = 1}^{m} \left| {S_{{a_{j} }}^{{*u_{q} }} \cup S_{{a_{j} }}^{{*u_{p} }} } \right|}} + \frac{1}{2}\left( {\frac{{\mathop \sum \nolimits_{j = 1}^{m} \left( {\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} } \right)\left( {\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} } \right)}}{{\sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{q} }} - \overline{\alpha }_{A}^{{u_{q} }} )^{2} } \sqrt {\mathop \sum \nolimits_{j = 1}^{m} (\alpha_{{a_{j} }}^{{u_{p} }} - \overline{\alpha }_{A}^{{u_{p} }} )^{2} } }} + 1} \right)} \right)$$$$= Sim^{Mixfl} \left( {S_{A}^{{{*}u_{q} }},S_{A}^{{{*}u_{p} }} } \right).$$ -
(3)
If \({S}_{A}^{*{u}_{p}}={S}_{A}^{*{u}_{q}}\).
We can get
So that
It means that \(Si{m}^{Mixfl}({S}_{A}^{*{u}_{p}},{S}_{A}^{*{u}_{q}})=1\).
Based on the above discussions, to solve the problem of missing linguistic values in an incomplete fuzzy linguistic formal context, we propose a similarity completion algorithm, which can be described as follows:

Example 1.
Table 1 shows an incomplete fuzzy linguistic formal context \((U,A,\{S,\diamond \},{R}^{\diamond })\), where \(U=\{{u}_{1},{u}_{2},{u}_{3}\}\),\(A=\{{a}_{1},{a}_{2},{a}_{3}\}\) and \(S=\{{s}_{-2}=\mathrm{low},{s}_{-1}=\mathrm{somewhat low},{s}_{0}=\mathrm{medium},{s}_{1}=\mathrm{somewhat high}, {s}_{2}=\mathrm{high}\}\). Given a threshold value \(\rlap{--} \lambda = s_{0}\), it can be seen from Table 1 that if \(R^{\diamondsuit } \left( {u_{1},a_{1} } \right) = s_{1} > \rlap{--} \lambda\), the object \(u_{1}\) has attribute \(a_{1}\), and the degree is somewhat high. If \(R^{\diamondsuit } \left( {u_{1},a_{2} } \right) = \diamondsuit_{1}\), it is unknown whether the object \(u_{1}\) has the attribute \(a_{2}\). If \(R^{\diamondsuit } \left( {u_{3},a_{1} } \right) = s_{ - 1} < \rlap{--} \lambda\), the object \(u_{3}\) does not have attribute \(a_{1}\).
Remark.
\({\diamond }_{1}\)is the missing linguistic value of the object \({u}_{1}\), \({\diamond }_{2}\) is the missing linguistic value of the object \({u}_{2}\).
In Definition 13, the mean values are used to complement the formal context, as shown in Table 2. (The linguistic 2-tuple in bold represents the filling value).
In Definition 15, the similarity between each object’s linguistic value sets is computed after the initial complement. The similarity between \({u}_{1}\) and \({u}_{2}\) is \(Si{m}^{Mixfl}({S}_{A}^{*{u}_{1}},{S}_{A}^{*{u}_{2}})\).
Then, we can get the fuzzy linguistic similarity matrix:
We can obtain that \({u}_{1}\), \({u}_{2}\) are the most similar to \({u}_{2}\), \({u}_{3}\) respectively. So, the filling values are \({s}_{2}\), \({s}_{0}\), We then get \(FLC\left(U,A,S,R\right)\) as shown in Table 3. (The linguistic value in bold represents the filling value).
4.2 Scenario Analysis
People often need to rent a house when they work or study outside, so how to quickly find a good house and reduce the frequent relocation is a critical issue. Table 4 shows an \(IFLC\left(U,A,\left\{S,\diamond \right\},{R}^{\diamond }\right)\), where \(U=\left\{{u}_{1},{u}_{2},{u}_{3},{u}_{4},{u}_{5}\right\}\) represents five houses, \(A=\left\{{a}_{1},{a}_{2},{a}_{3},{a}_{4},{a}_{5},{a}_{6}\right\}\) represents six attributes: \({a}_{1}\) is "favorable price"; \({a}_{2}\) is "transparent apartment layout"; \({a}_{3}\) is "convenient transportation"; \({a}_{4}\) is "complete facilities"; \({a}_{5}\) is "clean surrounding environment"; \({a}_{6}\) is "convenient shopping". \(S=\{{s}_{-3}=\mathrm{very low},{s}_{-2}=\mathrm{low},{s}_{-1}=\mathrm{somewhat low},{s}_{0}=\mathrm{medium},{s}_{1}=\mathrm{somewhat high},{s}_{2}=\mathrm{high},{s}_{3}=\mathrm{very high}\}\).
According to Definition 13, the mean values are used to initially complement the formal context, as shown in Table 5.
After the initial complement, the similarity between each object's linguistic value sets is computed in Definition 15. The similarity between \({u}_{1}\) and \({u}_{2}\) is \(Si{m}^{Mixfl}({S}_{A}^{*{u}_{1}},{S}_{A}^{*{u}_{2}})\).
Then, we can get the fuzzy linguistic similarity matrix:
We can observe that \({u}_{2}\), \({u}_{3}\), \({u}_{5}\) are the most similar options to \({u}_{1}\), \({u}_{4}\), \({u}_{4}\), respectively. So, the filling values are \({s}_{2}\), \({s}_{1}\), \({s}_{2}\). We then get \(FLC\left(U,A,S,R\right)\), as shown in Table 6.
Given a threshold value \(\uplambda ={s}_{0}\). According to Table 6, we can get 26 FLACs as follows (The linguistic 2-tuple in red bold represents the filling value):
1#\(({u}_{1}{u}_{2}{u}_{3}{u}_{4}{u}_{5},((\varnothing ),(\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}}))),\)
2#\(({u}_{1}{u}_{2}{u}_{3}{u}_{5},((\frac{{s}_{0}}{{a}_{2}}),(\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}})))\),
3#\(({u}_{1}{u}_{2}{u}_{4}{u}_{5},((\frac{{s}_{1}}{{a}_{4}}),(\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}}))),\)
4#\(({u}_{1}{u}_{3}{u}_{4}{u}_{5},((\frac{{s}_{0}}{{a}_{1}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}}))),\)
5#\(({u}_{2}{u}_{3}{u}_{4}{u}_{5},((\frac{{s}_{2}}{{a}_{5}}),(\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}))),\)
6#\(({u}_{1}{u}_{2}{u}_{5},((\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{2}}{{a}_{4}}),(\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{2}}{{a}_{4}}))),\)
7#\(({u}_{1}{u}_{3}{u}_{4},((\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{3}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}}))),\)
8#\(({u}_{1}{u}_{3}{u}_{5},((\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}}))),\)
9#\(({u}_{1}{u}_{4}{u}_{5},((\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{1}}{{a}_{4}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}}))),\)
10#\(({u}_{2}{u}_{3}{u}_{5},((\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{2}}{{a}_{5}}),(\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}))),\)
11#\(({u}_{3}{u}_{4}{u}_{5},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
12#\(({u}_{1}{u}_{2},((\frac{{s}_{2}}{{a}_{2}},\frac{{s}_{3}}{{a}_{4}}),(\frac{{s}_{2}}{{a}_{2}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{3}}{{a}_{4}}))),\)
13#\(({u}_{1}{u}_{3},((\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{0}}{{a}_{3}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}}))),\)
14#\(({u}_{1}{u}_{4},((\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}}))),\)
15#\(({u}_{1}{u}_{5},((\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{2}}{{a}_{4}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{2}}{{a}_{4}}))),\)
16#\(({u}_{2}{u}_{4},((\frac{{s}_{1}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}),(\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}))),\)
17#\(({u}_{2}{u}_{5},((\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{2}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}),(\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{2}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}))),\)
18#\(({u}_{3}{u}_{4},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{3}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
19#\(({u}_{3}{u}_{5},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
20#\(({u}_{4}{u}_{5},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
21#\(({u}_{1},((\frac{{s}_{0}}{{a}_{1}},\frac{{s}_{2}}{{a}_{2}},\frac{{s}_{2}}{{a}_{3}},\frac{{s}_{3}}{{a}_{4}}),(\frac{{s}_{0}}{{a}_{1}},\frac{{{\varvec{s}}}_{2}}{{a}_{2}},\frac{{s}_{2}}{{a}_{3}},\frac{{s}_{3}}{{a}_{4}}))),\)
22#\(({u}_{2},((\frac{{s}_{3}}{{a}_{2}},\frac{{s}_{3}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}),(\frac{{s}_{3}}{{a}_{2}},\frac{{s}_{2}}{{a}_{3}},\frac{{s}_{3}}{{a}_{4}},\frac{{s}_{2}}{{a}_{5}}))),\)
23#\(({u}_{3},((\frac{{s}_{3}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{0}}{{a}_{3}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{3}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
24#\(({u}_{4},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{2}}{{a}_{3}},\frac{{s}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
25#\(({u}_{5},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{2}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{2}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{2}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{2}}{{a}_{6}}))),\)
26#\(\left(\emptyset,\left(\left(\frac{{s}_{3}}{{a}_{1}},\frac{{s}_{3}}{{a}_{2}},\frac{{s}_{3}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{2}}{{a}_{6}}\right),\left(\frac{{s}_{3}}{{a}_{1}},\frac{{s}_{3}}{{a}_{2}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{3}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{2}}{{a}_{6}}\right)\right)\right).\)
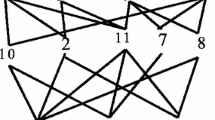
The Hasse diagram of FLAL is depicted in Fig. 1.

FLAL
Suppose that a tenant is looking for houses with favorable prices, convenient transportation and a clean surrounding environment, that is, looking for the objects with attributes \({a}_{1}\), \({a}_{2}\) and \({a}_{5}\). After completion, the query is represented by attributes in FLAL as follows:
The FLACs, which meet the conditions, are as follows:
19#\(({u}_{3}{u}_{5},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
23#\(({u}_{3},((\frac{{s}_{3}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{0}}{{a}_{3}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}),(\frac{{s}_{3}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{0}}{{a}_{3}},\frac{{{\varvec{s}}}_{1}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{1}}{{a}_{6}}))),\)
25#\(({u}_{5},((\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{s}_{2}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{2}}{{a}_{6}}),(\frac{{s}_{2}}{{a}_{1}},\frac{{s}_{0}}{{a}_{2}},\frac{{{\varvec{s}}}_{2}}{{a}_{3}},\frac{{s}_{2}}{{a}_{4}},\frac{{s}_{3}}{{a}_{5}},\frac{{s}_{2}}{{a}_{6}}))).\)
It can be seen from concept 19# that \({u}_{3}\) and \({u}_{5}\) meet the conditions. The tenant can choose a more appropriate house within all the FLACs that satisfy the conditions. It can be seen from concepts 23# and 25# that if the tenant pays more attention to favorable prices, the tenant can select \({u}_{3}\). And if the tenant has high requirements in all attributes, then he can select \({u}_{5}\).
4.3 Comparative Analysis
Ganter et al. [31] introduced the notion of formal context and concept lattice. The formal concept is defined to be a pair \((X,B)\), where \(X\) and \(B\) are called extension and intension respectively. The family of all the formal concepts forms a complete lattice that is named as the concept lattice of \((U,A,I)\) and is denoted by \(L(U,A,I)\). In the classical formal context, we can definitely infer whether an object has an attribute or not via the relation value. However, uncertainty is full of our life, for which \(L(U,A,I)\) is unable to solve. By contrast, our FLAL is fully capable in representing the uncertainty information (Table 7).
To improve \(L(U,A,I)\), Li. et al. [17] proposed AL, a novel method to construct the approximate concept lattice of an incomplete context. In comparison with AL, we introduced linguistic values into concept representation and the fuzzy linguistic approximate concept, which can better interpret the qualitative attributes of a concept.
Liu et al. [25] proposed FLL, the fuzzy linguistic concept lattice, through combining with fuzzy linguistic information for an uncertain linguistic environment. FLAL can improve FLL in many aspects. First, FLAL makes twice complements to avoid information loss caused by only one complement, using the incomplete fuzzy linguistic formal context. It can effectively promote knowledge acquisition. Second, FLAL contains description of attributes. FLAL describes an object from two aspects: one is the essential attribute set; and the other is the nonessential attribute set that the object may have. In an uncertain environment, FLAL may well reduce the information loss caused by uncertain factors. Moreover, it includes a new fuzzy linguistic similarity method to calculate object similarity, which can clearly improve the comparison fairness among different methods. Finally, it can retrieve approximate information, which can greatly increase searching scope and reduce calculation complexity.
5 Conclusions
The problems of uncertainty and incomplete information in real life are difficult to be represented by a certainty concept or relationship. In cognition, decision-making, and implementation, we prefer to use linguistic values to obtain information or knowledge, which can better express qualitative concepts. In this paper, we propose the incomplete fuzzy linguistic formal context and the fuzzy linguistic approximation concept to deal with the incomplete context with linguistic values. The FLAC contains more information and describes the object from two aspects simultaneously. One is an object's essential attributes, and another includes its essential and possible attributes. We constructed the fuzzy linguistic approximate concept lattice. For the problem of missing values in IFLC, a proposed similarity approach can effectively complete the information. After that, we constructed the fuzzy linguistic approximate concept lattice to reduce the loss of missing information, the number of concepts, and the search range. Given the advantages of FLAL, we will continue to study attribute reduction and rule extraction algorithms in the future.
Availability of Data and Materials
Data sharing is not applicable to this article as no datasets were generated or analyzed during the current study.
Abbreviations
- IFLC:
-
Incomplete fuzzy linguistic formal context
- FLC:
-
Fuzzy linguistic formal context
- FLAC:
-
Fuzzy linguistic approximation concept
- FLAL:
-
Fuzzy linguistic approximate concept lattice
- FLL:
-
Fuzzy linguistic concept lattice
- AL:
-
Approximate concept lattice
References
Shao, M., Wu, W., Wang, X., Wang, C.: Knowledge reduction methods of covering approximate spaces based on concept lattice. Knowl. Based Syst. (2019). https://doi.org/10.1016/j.knosys.2019.15269
Zou, C., Zhang, D., Wan, J., Hassan, M., Lloret, J.: Using concept lattice for personalized recommendation system design. IEEE Syst. J. 11(1), 305–314 (2015)
Shemis, E., Mohammed, A.: A comprehensive review on updating concept lattices and its application in updating association rules. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 11(2), 1401–1426 (2021)
Mohapatro, A., Mahendran, S., Das, T.: A knowledge elicitation framework in ranking healthcare providers using rough set with formal concept analysis. Int. J. Comput. Sci. Eng. 23(4), 396–407 (2020)
Li, L., Zhang, D.: 0–1 linear integer programming method for granule knowledge reduction and attribute reduction in concept lattices. Soft Comput. 23(2), 383–391 (2019)
Zou, L., Kang, N., Che, L., Liu, X.: Linguistic-valued layered concept lattice and its rule extraction. Int. J. Mach. Learn. Cybern. 13(1), 83–98 (2022)
Zou, L., Lin, H., Song, X., Feng, K., Liu, X.: Rule extraction based on linguistic-valued intuitionistic fuzzy layered concept lattice. Int. J. Approx. Reason. 133, 1–16 (2021)
Yao, J., Medina, J., Zhang, Y., Ślęzak, D.: Formal concept analysis, rough sets, and three-way decisions. Int. J. Approx. Reason. 140, 1–6 (2022)
Shen, Q., Lou, J., Liu, Y., Jiang, Y.: Hesitant fuzzy multi-attribute decision making based on binary connection number of set pair analysis. Soft Comput. 25(23), 14797–14807 (2021)
Cui, H., Yue, G., Zou, L., Liu, X., Deng, A.: Multiple multidimensional linguistic reasoning algorithm based on property-oriented linguistic concept lattice. Int. J. Approx. Reason. 131, 80–92 (2021)
Fang, R., Liao, H.: A prospect theory-based evidential reasoning approach for multi-expert multi-criteria decision-making with uncertainty considering the psychological cognition of experts. Int. J. Fuzzy Syst. 23(2), 584–598 (2021)
Yang, H., Qin, K.: Neutrosophic three-way concept lattice and its application in conflict analysis. J. Intell. Fuzzy Syst. 41(2), 3219–3236 (2021)
Hao, F., Yang, Y., Min, G., Loia, V.: Incremental construction of three-way concept lattice for knowledge discovery in social networks. Inf. Sci. 578, 257–280 (2021)
Zhang, C., Li, J., Lin, Y.: Matrix-based reduction approach for one-sided fuzzy three-way concept lattices. J. Intell. Fuzzy Syst. 40(6), 11393–11410 (2021)
Juandeaburre, A.B., Fuentes-González, R.: The study of the L-fuzzy concept lattice. Mathw. Soft Comput. 1(3), 209–218 (1994)
Krupka, M., Laštovička, J.: Fuzzy concept lattices with incomplete knowledge. In: Greco, S., Bouchon-Meunier, B., Coletti, G., Fedrizzi, M., Matarazzo, B., Yager, R.R. (eds.) Advances in computational intelligence. IPMU 2012. Communications in computer and information science, pp. 171–180. Springer, Heidelberg (2012)
Li, J., Mei, C., Lv, Y.: Incomplete decision contexts: approximate concept construction, rule acquisition and knowledge reduction. Int. J. Approx. Reason. 54(1), 149–165 (2013)
Li, C., Li, J., He, M.: Concept lattice compression in incomplete contexts based on K-medoids clustering. Int. J. Mach. Learn. Cybern. 7(4), 539–552 (2016)
Yao, Y.: Interval sets and three-way concept analysis in incomplete contexts. Int. J. Mach. Learn. Cybern. 8(1), 3–20 (2017)
Li, M., Wang, G.: Approximate concept construction with three-way decisions and attribute reduction in incomplete contexts. Knowl.-Based Syst. 91, 165–178 (2016)
Wang, Z., Wei, L., Qi, J., Qian, T.: Attribute reduction of SE-ISI concept lattices for incomplete contexts. Soft Comput. 24(20), 15143–15158 (2020)
Zadeh, L.A.: Fuzzy logic = computing with words. IEEE Trans. Fuzzy Syst. 4(2), 103–111 (1996)
Herrera, F., Martínez, L.: A 2-tuple fuzzy linguistic representation model for computing with words. IEEE Trans. fuzzy Syst. 8(6), 746–752 (2000)
Liao, H., Xu, Z., Zeng, X.-J.: Distance and similarity measures for hesitant fuzzy linguistic term sets and their application in multi-criteria decision making. Inf. Sci. 271, 125–142 (2014)
Liu, P., Cui, H., Cao, Y., Hou, X., Zou, L.: A method of multimedia teaching evaluation based on fuzzy linguistic concept lattice. Multimed. Tools Appl. 78(21), 30975–31001 (2019)
Diao, H., Cao, Y., Xu, Y., Zou, L., Deng, A.: Approach for group decision making based on linguistic truth-valued intuitionistic fuzzy lattice. J. Intell. Fuzzy Syst. 38(1), 895–904 (2020)
Wang, P., Liu, P., Chiclana, F.: Multi-stage consistency optimization algorithm for decision making with incomplete probabilistic linguistic preference relation. Inf. Sci. 556, 361–388 (2021)
Lu, Y., Xu, Y., Huang, J., Wei, J., Herrera-Viedma, E.: Social network clustering and consensus-based distrust behaviors management for large-scale group decision-making with incomplete hesitant fuzzy preference relations. Appl. Soft Comput. (2022). https://doi.org/10.1016/j.asoc.2021.108373
Xu, Y., Zhu, S., Liu, X., Huang, J., Herrera-Viedma, E.: Additive consistency exploration of linguistic preference relations with self-confidence. Artif. Intell. Rev. (2022). https://doi.org/10.1007/s10462-022-10172-x
Herrera, F., Herrera-Viedma, E.: A model of consensus in group decision making under linguistic assessments. Fuzzy Sets Syst. 78(1), 73–87 (1996)
Ganter, B., Wille, R.: Formal concept analysis: mathematical foundations. Springer, New York (1999)
Burmeister, P., Holzer, R.: On the treatment of incomplete knowledge in formal concept analysis. In: Ganter, B., Mineau, G.W. (eds.) Conceptual structures: logical, linguistic, and computational issues. ICCS 2000. Lecture notes in computer science, pp. 385–398. Springer, Heidelberg (2000)
Labella, A., Rodriguez, R., Martinez, L.: Computing with comparative linguistic expressions and symbolic translation for decision making: ELICIT information. IEEE Trans. Fuzzy Syst. 28(10), 2510–2522 (2020)
García-Zamora, D., Labella, A., Ding, W., Rodríguez, R.M., Martinez, L.: Large-scale group decision making: a systematic review and a critical analysis. IEEE/CAA J. Autom. Sin. 9(6), 949–966 (2022)
Funding
This work has been supported by National Social Science Foundation (China) (17BYY119).
Author information
Authors and Affiliations
Contributions
DY conceived of the study and helped to review the manuscript. XY drafted the manuscript, studied fuzzy linguistic approximate concept lattice based on incomplete fuzzy linguistic formal context and realized its application. HJ proved the theorems and properties in the manuscript. LX and JG consulted relevant literature and research status at home and abroad. All authors read and approved the final manuscript.
Corresponding authors
Ethics declarations
Conflict of Interest
Authors have no conflict of interest to declare.
Ethics Approval and Consent to Participate
Not applicable.
Consent for Publication
I would like to declare on behalf of my co-authors that the work described was original research that has not been published previously, and is not under consideration for publication elsewhere, in whole or in part. All the authors listed have approved the manuscript that is enclosed.
Additional information
Publisher's Note
Publisher's Note Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, D., Yang, X., Jia, H. et al. Construction of Fuzzy Linguistic Approximate Concept Lattice in an Incomplete Fuzzy Linguistic Formal Context. Int J Comput Intell Syst 15, 70 (2022). https://doi.org/10.1007/s44196-022-00125-1
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44196-022-00125-1