
Abstract
This study proposes a universal machine learning-based model to predict the adiabatic and condensing frictional pressure drop. For developing the proposed model, 11,411 data points of adiabatic and condensing flow inside micro, mini and macro channels are collected from 80 sources. The database consists of 24 working fluids, hydraulic diameters from 0.07 to 18 mm, mass velocities from 6.3 to 2000 Kg/m2s, and reduced pressures from 0.001 to 0.95. Using this database, four machine learning regression models, including “artificial neural network”, “support vector regression”, “gradient boosted regression”, and “random forest regression”, are developed and compared with each other. A wide range of dimensionless parameters as features, “two-phase friction factor” and “Chisholm parameter” are each considered separately as targets. Using search methods, the optimal values of important hyperparameters in each model are determined. The results showed that the “gradient boosted regression” model performs better than other models and predicts the frictional pressure drop with a mean absolute relative deviation of 3.24%. Examining the effectiveness of the new model showed that it predicts data with uniform accuracy over a vast range of variations of each flow parameter.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
High heat flux thermal management systems are used in various industries such as air conditioning, electronics, and automotive. Two-phase condensing flows are widely used in these systems. For this reason, researchers have paid much attention to estimating heat transfer and pressure drop in condensing flows.
Different models have been used to investigate the pressure drop in condensing and adiabatic flows. Most researchers have used the homogeneous model and the separated-flow model to predict the pressure drop, and some have used the least-squares fitting method. In the homogeneous model, it is assumed that the two phases are well mixed and move at the same velocity; therefore, they can be considered as a single-phase flow. This model works better near the critical point and the mass velocities of two-phase flow larger than 2000 Kg/m2s [1, 2]. In the separate-flow model, it is assumed that each phase has its own properties and velocity. In this model, the two-phase frictional pressure drop is related to the pressure drop of the individual flow of liquid or vapor in the channel [3].
The above methods have been used to develop correlations for two-phase frictional pressure drop. For example, Friedel [4] provided a correlation for frictional pressure drop during the two-phase flows of air-oil, air-water, and refrigerant R12 in channels with diameters larger than 4 mm using a database with 25,000 samples. Müller-Steinhagen and Heck [5] presented a simple frictional pressure drop correlation using 9300 data on two-phase flows of refrigerants, hydrocarbons, water, and air-water in channels with diameters in the range of 4–392 mm. Some researchers have attempted to provide correlations covering a vast range of working fluids, hydraulic diameters, and mass velocities. A universal frictional pressure drop correlation for condensing and adiabatic flows was developed by Kim and Mudawar [6]. The used database included 7115 samples, 17 working fluids, mass velocities in the range of 4–8528 kg/m2s, and hydraulic diameters in the range of 0.0695–6.22 mm.
Since the two-phase frictional pressure drop is a nonlinear function of various variables, new methods have been used based on machine learning to determine the correlation between these variables. Balcilar et al. [7] developed a correlation for predicting the frictional pressure drop during evaporation and condensation of different refrigerants in micro-fin and smooth tubes using artificial neural networks. The used database included 1485 samples, ten refrigerants, and tubes with diameters in the range of 4.39–11.1 mm, and the average error of the model was 7.09%. In another study, Balcilar et al. [8] employed artificial neural networks to estimate the pressure drop of refrigerant R134a during boiling and condensation in corrugated and smooth tubes. The used database included 1177 data points, mass velocities in the range of 200–700 Kg/m2s, tube diameters of 8.1 and 8.7 mm, pressures of 4.5,5.5,10 and 12 bar, and the relative error of the model was ±30%. In a study by Peng and Ling [9], the Colburn and friction factors in compact heat exchangers were predicted using artificial neural network and support vector regression (SVR) models. They used 48 data points for this purpose. The result showed that the SVR model provides better prediction performance with the mean squared errors of 2.64 × 10−4 and 1.251 × 10−3 for Colburn and friction factors, respectively. Zendehboudi and Li [10] used the universal intelligent models including Hybrid-ANFIS, GA-PLCIS, GA-LSSVM, and PSO-ANN to estimate the pressure drop of R134a during condensation in inclined smooth tubes. The database used included 649 data points, tube diameter of 8.38 mm, saturation temperatures of 30, 40, and 50 °C, and mass velocities in the range of 100–400 Kg/m2s. According to the results, GA-PLCIS, GA-LSSVM, and Hybrid-ANFIS models accurately predict the pressure drops. The GA-PLCIS model performs better than the other two models and predicts the pressure drop and frictional pressure drop with mean squared errors of 0.0140 and 0.0126, respectively. Lopez-Belchi et al. [11] used neuro-fuzzy logic neural networks and group method data handling (GMDH) to estimate heat transfer coefficient and pressure drop of condensing flow. They determined the minimum number of variables required to develop the most accurate models using the GMDH method. The database used to predict frictional pressure drop included 1824 data points, hydraulic diameters of 0.71 and 1.16 mm, mass velocities in the range of 175–800 Kg/m2s, and R32, R134a, R290, R410A, and R1234yf refrigerants. The frictional pressure drop was predicted with a MARD of 10.59%. Longo et al. [12] predicted the frictional pressure gradient inside the brazed plate heat exchanger during condensation and boiling using a gradient boosting machine model. The total number of data was 2549, and 16 refrigerants of different types were used. The frictional pressure gradient was predicted with a MARD of 6.6%. Najafi et al. [13] developed an optimal machine learning-based pipeline for two-phase air-water flow using 2021 experimental data points and optimization based on a genetic algorithm. This optimal pipeline, using selected features, estimates training and test sets with MARDs of 6.72% and 7.05%, respectively. Moradkhani et al. [14] presented a general frictional pressure drop correlation for condensing flow in micro, mini and macro channels using genetic programming. The used database included 4000 data points, 22 working fluids, hydraulic diameters in the range of 0.1–19 mm, reduced pressures in the range of 0.03–0.95, and mass fluxes in the range of 32.7–1400 Kg/m2s. The proposed correlation predicted the pressure drop with a MARD of 22.92%. Hughes et al. [15] proposed a universal model to estimate the condensing heat transfer coefficient and frictional pressure drop. The used database included 4000 samples, nine refrigerants, reduced pressures in the range of 0.03–0.96, mass fluxes in the range of 50–800 Kg/m2s, and hydraulic diameters in the range of 0.1–14.45 mm. They developed three machine learning models, including artificial neural networks, random forest, and support vector regression. The results indicated that the random forest model performs better than the other two models and can predict the condensing heat transfer coefficient and frictional pressure drop with a MARD of about 4%.
Many researchers have experimentally investigated the condensing frictional pressure drop for different fluids and a wide range of geometric and flow parameters. Therefore, today there is an acceptable number of databases for the development of universal models based on machine learning. These models are able to estimate the condensing frictional pressure drop with good accuracy. As seen, few studies [14, 15] have been conducted to develop universal models for estimating condensing frictional pressure drop using machine learning methods. Accordingly, this study is performed to develop an accurate and universal machine learning model for estimating the frictional pressure drop during condensing and adiabatic flow in micro, mini and macro channels. In this regard, a large database of 11,411 data points is collected from 80 sources. The database includes a vast range of diameters, working fluids, reduced pressures, and mass velocities. Using this database and taking into account the wide range of dimensionless parameters affecting the frictional pressure drop, important hyperparameters for each machine learning model are tuned. Finally, for the model with the best performance, by considering the trade-off between the model complexity (i.e., the number of used features) and the obtained accuracy, the final model with less complexity is presented.
2 Databases
The database used in this study includes 11,411 data points of frictional pressure drop in condensing and adiabatic flows. These data are collected from 80 sources. Table 1 shows the operating conditions of individual databases. According to the classification proposed by Kandlikar [16], 507 data points concern micro-channels (Dh ≤ 0.2 mm), 6592 data points concern mini-channels (0.2 <Dh≤ 3 mm), and 4312 data points concern macro channels (Dh> 3 mm). The range of various parameters in this database is as follows:
-
Working fluid: R134, R410A, R744, R1234yf, R404A, R290, R32, R1234ze(E), R245fa, R50, R600a, R170, R22, R717, R152a, R601, R14, R407C, R1270, R728, R12, R236ea, R718, R125
-
Hydraulic diameter: 0.069 mm < Dh ≤ 18 mm
-
Mass velocity: 6.3 Kg/m2s < G ≤ 2000 Kg/m2s
-
Flow quality: 0 < x < 1
-
Reduced pressure: 0.001 < Pred < 0.95
3 Machine learning models
In this section, data preparation, scaling, and cross-validation are first described, followed by a brief introduction to artificial neural networks (ANN), support vector regression (SVR), gradient-boosted regression trees (GBR), and random forest regression (RFR).
3.1 Data preparation
During machine learning model development, the database is randomly divided into two parts. The part used to build the model is named the training set. The other part is used to evaluate how well the model works; this part is named the test set. In this study, 70% and 30% of the total data were used for training and testing each model, respectively.
The following dimensionless parameters are provided as features to the models:
-
Bo, Pred, Rel, Rev, Relo, Revo, X, Wel, Wev, Frl, Frv, Sul, Suv, DR, Ga, Cal, Cav
Furthermore, the two-phase friction factor and the Chisholm parameter are considered separately as the target. The two-phase friction factor is defined as [15]:
The relationship between the Chisholm parameter, the Lockhart-Martinelli parameter, the two-phase frictional multiplier, and the frictional pressure drop for each phase is as follows [97]:
The phase friction factors are calculated as follows:
It should be emphasized that the following equation is used for laminar flow in a rectangular channel [98]:
Where α∗ is the aspect ratio of a rectangular cross-section (α∗ ≤ 1). The equation proposed by Sparrow [99] is used for laminar flow in a triangular channel. In Eqs. (3) and (4), the subscript k indicates v or l for the vapor and liquid phase, respectively.
3.2 Scaling and cross-validation
Some models are sensitive to data scaling. In these models, all features must change on a similar scale. Therefore, the features are scaled so that the mean and variance of each feature are zero and unit, respectively. The statistical method k-fold cross-validation is used to assess the generalization performance of the models. In this method, the data is first randomly divided into k approximately equal-size parts, called fold. Then k model is trained. The k-th model is trained using the k-th fold as the test set, and the other folds are used as the training set. The mean of k accuracy values is considered as model accuracy. In this study, three-fold cross-validation was used.
When training set scaling and cross-validation are used together, the data partitioning during cross-validation should be done before scaling to prevent data leakage from the training folds to the validation fold. Therefore, a chain of different processes and models is built and used as a pipeline. The pipeline is generated using the Scikit-learn Python library [100].
3.3 Artificial neural networks (ANN)
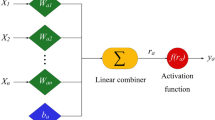
In artificial neural networks, all input variables (features) interact with each other in a complex way. This allows these networks to capture complex relationships in the database. An ANN involves the input layer, hidden layers, an output layer, and an activation function. The following recurrence relations are established between input vector \(\overline{x}\) and output vector \(\overline{y}\), for networks with k hidden layers, and activation function Φ [101]:
In Eq. (5), matrix W1 is the weight between the input and the first hidden layer, matrix Wp is the weight between pth hidden layer and (p + 1)th hidden layer, and matrix Wk + 1 is the weight between the last hidden layer and the output. The goal of network training is to find weight matrices that minimize the error (or loss) function. This process contains two forward and backward phases. In the forward phase, the output and the derivative of the loss function with respect to the output are determined using the current values of the weights. In the backward phase, the gradient of the loss function with respect to different weights is determined using the chain rule. The weights are updated using these gradients.
3.4 Support vector regression (SVR)
The search for function F so that the deviation of this function from target values yi for all training data is less than ε may not be feasible in some cases. Therefore, at some points, the deviation of F from yi is allowed to be ξi + ε. Assuming F is linear:
The problem can be written as an optimization problem [102]:
Where 〈∙, ∙〉 denotes the dot product, ‖w‖2 = 〈w, w〉, and C is constant. The solution to the above problem is shown as follows:
Where \({\hat{\alpha}}_i^{\ast }\) and \({\hat{\alpha}}_i\) are the solutions to the following optimization problem:
A subset of solutions \(\left({\hat{\alpha}}_i^{\ast }-{\hat{\alpha}}_i\right)\) is commonly nonzero, and the related data values are named the support vectors.
In the nonlinear case, the data is mapped into a higher-dimensional space. In this case:
The following similar results are obtained by repeating the steps in the linear case:
Where \({\hat{\alpha}}_i^{\ast }\) and \({\hat{\alpha}}_i\) are the solutions to the following optimization problem:
In the above equations, κ(xi, xj) is called the kernel. Various kernel functions such as linear, power, polynomial, sigmoid, and Gaussian radial basis are used in the support vector machine.
3.5 Gradient-boosted regression trees (GBR)
GBR is an ensemble method that combines a large number of simple models (weak learners) such as shallow trees to produce a robust model. In this method, the following equation is established between the estimate of function \({\hat{y}}_i\) and M simple models hm [100]:
This method is made in a greedy fashion, meaning that if a simple model such as hi is selected, the selection will not change, and only new models will be added. Therefore:
In the above equation, the recently added tree hm is fitted to minimize the total losses Lm of the earlier ensemble Fm-1:
In the above equation, L[yi, F(xi)] is a loss function. However:
Therefore, by removing the constants and denoting the gradient with gi:
The simple model is fitted to predict a value proportional to −gi to facilitate the solving of the above minimization problem. Various loss functions such as squared error, least absolute deviation, Huber loss function, and Quantile loss function are used in GBR. In addition, GBR is prone to overfitting, meaning that this method predicts the training set itself rather than the functional dependency between input and output. Regularization techniques such as subsampling, shrinkage, and early stopping prevent overfitting [103, 104].
3.6 Random forest regression (RFR)
Random forest regression is an ensemble method made from a combination of decision trees. Injecting randomness into the tree building reduces the variance and overfitting tendency of the forest estimator relative to the individual decision trees. Trees in the forest are randomized in two ways: by randomly selecting the data points used to build a tree and by randomly selecting the best split from a random subset of features. The average prediction of trees in the forest is considered the final prediction [105].
4 Error analysis
The percentage of samples estimated with an accuracy of 20% (θ20) and 50% (θ50), mean absolute relative deviation (MARD), mean relative deviation (MRD), and R2 score with the following definitions are used to evaluate the accuracy of the models:
An R2 score of 1 corresponds to a perfect prediction, and an R2 score of 0 corresponds to a constant model that predicts only the mean of the data set.
5 Results and discussion
In this section, four universal models for frictional pressure drop in two-phase condensing and adiabatic flows in micro, mini and macro channels are developed and compared using ANN, SVR, GBR, and RFR algorithms and 11,411 data points.
5.1 Models performance comparison
There are hyperparameters in machine learning algorithms that should be tuned. In this study, these parameters are tuned using randomized search, Bayesian search, and grid search [100].
In the ANN model, the number of hidden layers and nodes in each hidden layer is considered important hyperparameters. The number of hidden layers is limited to four, with a maximum of 200 nodes per layer to avoid the over-complexity of the model as well as the high computational cost of searching for the optimal model. The parameters gamma and C in the SVR model, the parameters max-depth, learning-rate, and n-estimators in the GBR model, and the parameters max-features and n-estimators in the RFR model are the most important hyperparameters whose variations are considered. Table 2 shows the range of variation of these hyperparameters, their optimal values, and some other model parameters for predicting the Chisholm parameter (C) and the two-phase friction factor (fTP). Table 3 provides the results of predicting the Chisholm parameter, two-phase friction factor, and frictional pressure drop by four models with optimal parameters. The ANN model predicts the frictional pressure drop with a MARD value of 17.00% using the Chisholm parameter, which is better than the accuracy of conventional models with MARD of about 30%. The model, however, is not very successful in predicting the frictional pressure drop using the two-phase friction factor. The SVR model predicts the frictional pressure drop with a MARD value of 10.83% and a MARD value of 10.86%, respectively, using the Chisholm parameter and the two-phase friction factor. The GBR model predicts the frictional pressure drop with excellent accuracy with a MARD value of 3.09% using the Chisholm parameter. However, this model suffers from overfitting in predicting the two-phase friction factor. The RFR model predicts the frictional pressure drop with a MARD value of 6.93% and a MARD value of 6.16%, respectively, using the Chisholm parameter and the two-phase friction factor.
5.2 Sensitivity analysis
As mentioned in Section 5.1, with optimal parameters and 17 dimensionless features (mentioned in Section 3.1), the GBR model has the best performance in predicting the frictional pressure drop. However, the importance of these features in predicting frictional pressure drop varies as can be seen in Table 4. Investigation of the model performance with different numbers of features suggested that the frictional pressure drop can be predicted with a MARD value of 3.24% using six features X, Revo, Ga, Sul, Pred, and DR. In this way, as the number of features decreases from 17 to 6, the frictional pressure drop prediction error increases by only about 5%. The GBR model with these six features is considered the final model and will be used for further analysis.
5.3 Ascertaining the effectiveness of the present model
The performance of the present model is compared with a homogeneous model [106], three correlations presented for macro channels [4, 5, 107], and four correlations presented for micro, mini and macro channels [6, 14, 49, 108] in all individual databases. Table 5 shows the relative frequency distribution of MARD in predictions of individual databases. As can be seen in the table, the present model performs much better than other models and correlations. The present model predicts the frictional pressure drop in 85% of databases (68 databases) with a MARD value of less than 5%, in 13.75% of databases (11 databases) with a MARD in the range of 5–10%, and only in 1.25% of databases (1 database) with a MARD in the range of 15–20%. The maximum MARD obtained by the present model with a value of 18.78% belongs to the database of Bashar et al. [22]. A comparison of the performance of the present model with previous models and correlations is provided in Table 6 for a total of 11,411 data points. According to the table, the Müller-Steinhagen and Heck model with a MARD value of 29.57% has the best performance following the present model. To visualize the accuracy of the present model, the results are compared with the experimental data in Fig. 1.

Comparison of 11,411 experimental data points with predictions of the present model
Low overall values of MARD are not sufficient to ascertain the effectiveness and robustness of a new predictive approach. The predictive tool must predict data with uniform accuracy over a relatively wide range of variations of each flow parameter [6, 109]. In this regard, the distribution of MARD in the predictions of the present model and the Müller-Steinhagen and Heck model and the distribution of the number of data relative to working fluids, hydraulic diameters, mass velocities, qualities, and reduced pressures are investigated, and the results are provided in Figs. 2, 3, 4, 5 and 6. The standard deviations of MARD in the predictions of the present model for various working fluids, hydraulic diameters, mass velocities, qualities, and reduced pressures are 0.66%, 0.81%, 1.19%, 0.78%, and 0.58%, respectively, indicating the even distribution of MARD according to the average value of 3.24%. The results also show that the present model predicts the frictional pressure drop much more accurately than the Müller-Steinhagen and Heck model. However, the two models have almost the same accuracy in predicting the frictional pressure drop for a mass velocity range of 1500–1600 Kg/m2s.

Distribution of number of data points and MARD relative to working fluid

Distribution of number of data points and MARD relative to mass velocity

Distribution of number of data points and MARD relative to hydraulic diameter

Distribution of number of data points and MARD relative to quality

Distribution of number of data points and MARD relative to reduced pressure
The trend of changes in the frictional pressure drop predicted by the present model in terms of mass velocity, quality, saturation temperature, and working fluid is investigated. Figure 7 shows the effect of quality and mass velocity on frictional pressure drop for R134a at a saturation temperature of 31 °C and in a channel with a diameter of 1.1 mm. As the quality and mass velocity increase, the phase interactions and the frictional losses increase [110]. Figure 8 shows the influence of saturation temperature (41 and 31 °C) on the frictional pressure drop at a mass velocity of 500 Kg/m2s in a channel with a diameter of 1.1 mm. As the saturation temperature increases, the vapor density increases, and the liquid density decreases. This reduces the difference in phase velocities, interfacial shear, and frictional pressure drop. Figure 9 compares the frictional pressure drop for the R600a and R1234yf refrigerants at a mass velocity of 400 Kg/m2s and a saturation temperature of 31 °C. At this saturation temperature, the vapor and liquid densities of R1234yf refrigerant are about four and twice that of R600a refrigerant, respectively. Therefore, the difference in phase velocities in the R600a is more remarkable, resulting in higher shear stress between the phases and a more significant frictional pressure drop.

Comparison between experimental [86] and predicted frictional pressure drop by the present model for different mass velocities

Comparison between experimental [86] and predicted frictional pressure drop by the present model for different temperatures

Comparison between experimental [86] and predicted frictional pressure drop by the present model for different working fluids
In order to evaluate the performance of the present model in estimating the frictional pressure drop of a data set that has not been used before in the development of the model, Yang and Nalbandian data [111] is used. They investigated the condensing pressure drop of R134a and R1234yf at a saturation temperature of 15 °C and mass velocities of 200–1200 Kg/m2s. The present model predicts the frictional pressure drop measured by Yang and Nalbandian with a MARD value of 11.82%. Figure 10 shows the comparison between the measured frictional pressure drop and the predictions of the present model. As can be seen in this figure, there is good agreement between the experimental and predicted values, except for R134a data at a mass velocity of 800 Kg/m2s. However, machine learning methods do not perform as well as the data used in model development in predicting previously unseen data. It was recommended that more data be added to the database over time and that a more diverse database be developed to address this shortcoming [109].

Comparison between experimental [111] and predicted frictional pressure drop by the present model for different working fluids and mass velocities
6 Conclusions
A new universal machine learning model is developed to predict frictional pressure drop in condensing and adiabatic two-phase flows within micro, mini and macro channels using a database of 11,411 samples from 80 sources. The significant findings are as follows:
-
ANN and GBR models are not very successful in predicting the frictional pressure drop using the two-phase friction factor compared to the Chisholm parameter. SVR and RFR models, however, predict the frictional pressure drop using the two-phase friction factor and the Chisholm parameter with almost equal accuracy.
-
Among the ANN, SVR, GBR, and RFR models, the GBR model has the best performance. This model predicts the frictional pressure drop with a MARD value of 3.09% and an MRD value of 0.81%, using the Chisholm parameter as the target and 17 dimensionless parameters as features.
-
Examination of the features importance suggests that the model can predict the frictional pressure drop with a MARD value of 3.24% and an MRD value of 0.58% using six features X, Revo, Ga, Sul, Pred, and DR.
-
According to the comparison of GBR model performance with several available models and correlations, the MARD value of this model predictions is lower than other models and correlations in all individual databases. The GBR model predicts the frictional pressure drop in 85% of databases with a MARD value of less than 5% and only 1.25% of databases with a MARD value of greater than 10%.
-
The GBR model predicts data with uniform accuracy over a relatively wide range of variations of each flow parameter.
-
The trend of changes in the frictional pressure drop predicted by the GBR model in terms of mass velocity, quality, saturation temperature, and working fluid is consistent with the trend observed in the experimental data.
-
The GBR model is less accurate in predicting the frictional pressure drop of data sets not previously used in model development.
7 Nomenclature
arg min argument of the minimum
Bo Bond number, \({B}_o=\frac{g{D_h}^2\left({\rho}_l-{\rho}_v\right)}{\sigma}\)
C Chisholm parameter
Cal liquid capillary number, \({Ca}_l=\frac{\mu_lG\left(1-x\right)}{\rho_l\sigma }\)
Cav vapor capillary number, \({Ca}_v=\frac{\mu_v Gx}{\rho_v\sigma }\)
Dh hydraulic diameter
DR density ratio, \({DR}=\frac{\rho_l}{\rho_v}\)
f friction factor
Frl liquid Froude number, \({Fr}_l=\frac{G^2{\left(1-x\right)}^2}{{\rho_l}^2g{D}_h}\)
Frv vapor Froude number, \({Fr}_v=\frac{G^2{x}^2}{{\rho_v}^2g{D}_h}\)
g gravitational acceleration
G mass velocity
Ga Galileo number, \(Ga=\frac{\rho_lg\left({\rho}_l-{\rho}_v\right){D_h}^3}{{\mu_l}^2}\)
MARD mean absolute relative deviation
MRD mean relative deviation
Pred reduced pressure
Rel liquid Reynolds number, \({\mathit{\operatorname{Re}}}_l=\frac{G\left(1-x\right){D}_h}{\mu_l}\)
Relo liquid-only Reynolds number, \({\mathit{\operatorname{Re}}}_{lo}=\frac{G{D}_h}{\mu_l}\)
Rev vapor Reynolds number, \({\mathit{\operatorname{Re}}}_v=\frac{G{xD}_h}{\mu_l}\)
Revo vapor-only Reynolds number, \({\mathit{\operatorname{Re}}}_{vo}=\frac{G{D}_h}{\mu_v}\)
Sul liquid Suratman number, \({Su}_l=\frac{\rho_l\sigma {D}_h}{{\mu_l}^2}\)
Suv vapor Suratman number, \({Su}_v=\frac{\rho_v\sigma {D}_h}{{\mu_v}^2}\)
Wel liquid Weber number, \({We}_l=\frac{G^2{\left(1-x\right)}^2{D}_h}{\rho_l\sigma }\)
Wev vapor Weber number, \({We}_v=\frac{G^2{x}^2{D}_h}{\rho_v\sigma }\)
X Lockhart-Martinelli parameter
7.1 Greek symbols
\({\upxi}_{\textrm{i}},{\upxi}_{\textrm{i}}^{\ast }\) slack variables
φ two-phase frictional multiplier
7.2 Subscripts
TP two-phase
l liquid
v vapor
Availability of data and materials
The datasets generated during and/or analyzed during the current study are available from the corresponding author on reasonable request.
References
Faghri, A., & Zhang, Y. (2006). Two-phase flow and heat transfer. In A. Faghri & Y. Zhang (Eds.), Transport phenomena in multiphase systems (pp. 853–949).
Rahman, M. M., Kariya, K., & Miyara, A. (2017). Comparison and development of new correlation for adiabatic two-phase pressure drop of refrigerant flowing inside a multiport minichannel with and without fins. International Journal of Refrigeration, 82, 119–129. https://doi.org/10.1016/j.ijrefrig.2017.06.001
Lockhart, R. W., & Martinelli, R. C. (1949). Proposed correlation of data for isothermal two-phase, two-component flow in pipes. Chemical Engineering Progress, 45(1), 39–48.
Friedel, L. (1979). Improved friction pressure drop correlation for horizontal and vertical two-phase pipe flow. In European two-phase group meeting, paper E2.
Müller-Steinhagen, H., & Heck, K. (1986). A simple friction pressure drop correlation for two-phase flow in pipes. Chemical Engineering and Processing: Process Intensification, 20(6), 297–308. https://doi.org/10.1016/0255-2701(86)80008-3
Kim, S. M., & Mudawar, I. (2012). Universal approach to predicting two-phase frictional pressure drop for adiabatic and condensing mini/micro-channel flows. International Journal of Heat and Mass Transfer, 55(11), 3246–3261. https://doi.org/10.1016/j.ijheatmasstransfer.2012.02.047
Balcilar, M., Dalkilic, A. S., Agra, O., Atayilmaz, S. O., & Wongwises, S. (2012). A correlation development for predicting the pressure drop of various refrigerants during condensation and evaporation in horizontal smooth and micro-fin tubes. International Communications in Heat and Mass Transfer, 39(7), 937–944. https://doi.org/10.1016/j.icheatmasstransfer.2012.05.005
Balcilar, M., Aroonrat, K., Dalkilic, A. S., & Wongwises, S. (2013). A generalized numerical correlation study for the determination of pressure drop during condensation and boiling of R134a inside smooth and corrugated tubes. International Communications in Heat and Mass Transfer, 49, 78–85. https://doi.org/10.1016/j.icheatmasstransfer.2013.08.010
Peng, H., & Ling, X. (2015). Predicting thermal–hydraulic performances in compact heat exchangers by support vector regression. International Journal of Heat and Mass Transfer, 84, 203–213. https://doi.org/10.1016/j.ijheatmasstransfer.2015.01.017
Zendehboudi, A., & Li, X. (2017). A robust predictive technique for the pressure drop during condensation in inclined smooth tubes. International Communications in Heat and Mass Transfer, 86, 166–173. https://doi.org/10.1016/j.icheatmasstransfer.2017.05.030
López-Belchí, A., Illán-Gómez, F., Cano-Izquierdo, J. M., & García-Cascales, J. R. (2018). GMDH ANN to optimise model development: Prediction of the Pressure drop and the heat transfer coefficient during condensation within mini-channels. Applied Thermal Engineering, 144, 321–330. https://doi.org/10.1016/j.applthermaleng.2018.07.140
Longo, G. A., Mancin, S., Righetti, G., Zilio, C., Ceccato, R., & Salmaso, L. (2020). Machine learning approach for predicting refrigerant two-phase pressure drop inside brazed plate heat exchangers (BPHE). International Journal of Heat and Mass Transfer, 163, 120450. https://doi.org/10.1016/j.ijheatmasstransfer.2020.120450
Najafi, B., Ardam, K., Hanušovský, A., Rinaldi, F., & Colombo, L. P. M. (2021). Machine learning based models for pressure drop estimation of two-phase adiabatic air-water flow in micro-finned tubes: Determination of the most promising dimensionless feature set. Chemical Engineering Research and Design, 167, 252–267. https://doi.org/10.1016/j.cherd.2021.01.002
Moradkhani, M. A., Hosseini, S. H., Valizadeh, M., Zendehboudi, A., & Ahmadi, G. (2020). A general correlation for the frictional pressure drop during condensation in mini/micro and macro channels. International Journal of Heat and Mass Transfer, 163, 120475. https://doi.org/10.1016/j.ijheatmasstransfer.2020.120475
Hughes, M. T., Fronk, B. M., & Garimella, S. (2021). Universal condensation heat transfer and pressure drop model and the role of machine learning techniques to improve predictive capabilities. International Journal of Heat and Mass Transfer, 179, 121712. https://doi.org/10.1016/j.ijheatmasstransfer.2021.121712
Kandlikar, S. G. (2002). Fundamental issues related to flow boiling in minichannels and microchannels. Experimental Thermal and Fluid Science, 26(2), 389–407. https://doi.org/10.1016/S0894-1777(02)00150-4
Adams, D. C., Hrnjak, P. S., & Newell, T. A. (2003). Pressure drop and void fraction in microchannels using carbon dioxide, ammonia, and R245fa as refrigerants. University of Illinois, Report.
Agarwal, A., & Garimella, S. (2010). Representative results for condensation measurements at hydraulic diameters ∼100 microns. Journal of Heat Transfer, 132(4). https://doi.org/10.1115/1.4000879
Ammar, S. M., Abbas, N., Abbas, S., Ali, H. M., Hussain, I., & Janjua, M. M. (2019). Experimental investigation of condensation pressure drop of R134a in smooth and grooved multiport flat tubes of automotive heat exchanger. International Journal of Heat and Mass Transfer, 130, 1087–1095. https://doi.org/10.1016/j.ijheatmasstransfer.2018.11.018
Andresen, U. C. (2007). Supercritical gas cooling and near-critical-pressure condensation of refrigerant blends in microchannels. Georgia Institute of Technology, PhD Thesis.
Aroonrat, K., & Wongwises, S. (2017). Experimental study on two-phase condensation heat transfer and pressure drop of R-134a flowing in a dimpled tube. International Journal of Heat and Mass Transfer, 106, 437–448. https://doi.org/10.1016/j.ijheatmasstransfer.2016.08.046
Bashar, M. K., Nakamura, K., Kariya, K., & Miyara, A. (2018). Experimental study of condensation heat transfer and pressure drop inside a small diameter microfin and smooth tube at low mass flux condition. Applied Sciences, 8(11), 2146. https://doi.org/10.3390/app8112146
Khairul Bashar, M., Nakamura, K., Kariya, K., & Miyara, A. (2020). Development of a correlation for pressure drop of two-phase flow inside horizontal small diameter smooth and microfin tubes. International Journal of Refrigeration, 119, 80–91. https://doi.org/10.1016/j.ijrefrig.2020.08.013
López-Belchí, A., Illán-Gómez, F., Vera-García, F., & García-Cascales, J. R. (2014). Experimental condensing two-phase frictional pressure drop inside mini-channels. Comparisons and new model development. International Journal of Heat and Mass Transfer, 75, 581–591. https://doi.org/10.1016/j.ijheatmasstransfer.2014.04.003
López-Belchí, A. (2014). Characterisation of heat transfer and pressre drop in condensation process within mini-channel tubes with last generation of refrigerant fluids. Polytechnic University of Cartagena, PhD Thesis.
López-Belchí, A., Illán-Gómez, F., García-Cascales, J. R., & Vera-García, F. (2016). Condensing two-phase pressure drop and heat transfer coefficient of propane in a horizontal multiport mini-channel tube: Experimental measurements. International Journal of Refrigeration, 68, 59–75. https://doi.org/10.1016/j.ijrefrig.2016.03.015
López-Belchí, A., Illán-Gómez, F., García Cascales, J. R., & Vera García, F. (2016). R32 and R410a condensation heat transfer coefficient and pressure drop within minichannel multiport tube. Experimental technique and measurements. Applied Thermal Engineering, 105, 118–131. https://doi.org/10.1016/j.applthermaleng.2016.05.143
López-Belchí, A. (2019). Assessment of a mini-channel condenser at high ambient temperatures based on experimental measurements working with R134a, R513a and R1234yf. Applied Thermal Engineering, 155, 341–353. https://doi.org/10.1016/j.applthermaleng.2019.04.003
Cavallini, A., Censi, G., Col, D. D., Doretti, L., Longo, G. A., & Rossetto, L. (2001). Experimental investigation on condensation heat transfer and pressure drop of new hfc refrigerants (R134a, R125, R32, R410a, R236ea) in a horizontal smooth tube. International Journal of Refrigeration, 24, 73–87. https://doi.org/10.1016/S0140-7007(00)00070-0
Cavallini, A., Del Col, D., Doretti, L., Matkovic, M., Rossetto, L., & Zilio, C. (2005). Two-phase frictional pressure gradient of R236ea, R134a and R410a inside multi-port mini-Channels. Experimental Thermal and Fluid Science, 29(7), 861–870. https://doi.org/10.1016/j.expthermflusci.2005.03.012
Cavallini, A., Del Col, D., Doretti, L., Matkovic, M., Rossetto, L., & Zilio, C. (2005). Condensation heat transfer and pressure gradient inside multiport minichannels. Heat Transfer Engineering, 26(3), 45–55. https://doi.org/10.1080/01457630590907194
Charnay, R., Revellin, R., & Bonjour, J. (2015). Discussion on the validity of prediction tools for two-phase flow pressure drops from experimental data obtained at high saturation temperatures. International Journal of Refrigeration, 54, 98–125. https://doi.org/10.1016/j.ijrefrig.2015.02.014
Chen, I. Y., Won, C. L., & Wang, C. C. (2005). Influence of oil on R-410a two-phase frictional pressure drop in a small U-type wavy tube. International Communications in Heat and Mass Transfer, 32(6), 797–808. https://doi.org/10.1016/j.icheatmasstransfer.2004.10.008
Coleman, J. W. (2000). Flow visualization and pressure drop for refrigerant phase change and air-water flow in small hydraulic diameter geometries. Iowa State University, PhD Thesis.
Del Col, D., Bisetto, A., Bortolato, M., Torresin, D., & Rossetto, L. (2013). Experiments and updated model for two phase frictional pressure drop inside minichannels. International Journal of Heat and Mass Transfer, 67, 326–337. https://doi.org/10.1016/j.ijheatmasstransfer.2013.07.093
Del Col, D., Bortolato, M., Azzolin, M., & Bortolin, S. (2015). Condensation heat transfer and two-phase frictional pressure drop in a single minichannel with R1234ze(E) and other refrigerants. International Journal of Refrigeration, 50, 87–103. https://doi.org/10.1016/j.ijrefrig.2014.10.022
Ducoulombier, M., Colasson, S., Bonjour, J., & Haberschill, P. (2011). Carbon dioxide flow boiling in a single microchannel – part I: Pressure drops. Experimental Thermal and Fluid Science, 35(4), 581–596. https://doi.org/10.1016/j.expthermflusci.2010.12.010
Field, B. S., & Hrnjak, P. S. (2007). Two-phase pressure drop and flow regime of refrigerants and refrigerant-oil mixtures in small channels. University of Illinois, Report.
Fronk, B. M., & Garimella, S. (2012). Heat transfer and pressure drop during condensation of ammonia in microchannels. In ASME third international conference on micro/nanoscale heat and mass transfer (pp. 399–409).
Fronk, B. M., & Garimella, S. (2016). Condensation of carbon dioxide in microchannels. International Journal of Heat and Mass Transfer, 100, 150–164. https://doi.org/10.1016/j.ijheatmasstransfer.2016.03.083
Heo, J., Park, H., & Yun, R. (2013). Condensation heat transfer and pressure drop characteristics of Co2 in a microchannel. International Journal of Refrigeration, 36(6), 1657–1668. https://doi.org/10.1016/j.ijrefrig.2013.05.008
Heo, J., Park, H., & Yun, R. (2013). Comparison of condensation heat transfer and pressure drop of Co2 in rectangular microchannels. International Journal of Heat and Mass Transfer, 65, 719–726. https://doi.org/10.1016/j.ijheatmasstransfer.2013.06.064
Hinde, D. K., Dobson, M. K., Chato, J. C., Mainland, M. E., & Rhines, N. (1992). Condensation of refrigerants 12 and 134a in horizontal tubes with and without oil. University of Illinois, Report.
Hirose, M., Ichinose, J., & Inoue, N. (2018). Development of the general correlation for condensation heat transfer and pressure drop inside horizontal 4 mm small-diameter smooth and microfin tubes. International Journal of Refrigeration, 90, 238–248. https://doi.org/10.1016/j.ijrefrig.2018.04.014
Hossain, M. A., Onaka, Y., & Miyara, A. (2012). Experimental study on condensation heat transfer and pressure drop in horizontal smooth tube for R1234ze(E), R32 and R410a. International Journal of Refrigeration, 35(4), 927–938. https://doi.org/10.1016/j.ijrefrig.2012.01.002
Huang, X., Ding, G., Hu, H., Zhu, Y., Gao, Y., & Deng, B. (2010). Two-phase frictional pressure drop characteristics of R410a-oil mixture flow condensation inside 4.18 mm and 1.6 mm I.D. horizontal smooth tubes. HVAC&R Research, 16(4), 453–470. https://doi.org/10.1080/10789669.2010.10390915
Jang, J., & Hrnjak, P. S. (2004). Condensation of Co2 at low temperatures. University of Illinois, Report.
Jiang, Y. (2004). Heat transfer and pressure drop of refrigerant R404a at near-critical and supercritical pressures. Iowa State University, PhD Thesis.
Jige, D., Inoue, N., & Koyama, S. (2016). Condensation of refrigerants in a multiport tube with rectangular minichannels. International Journal of Refrigeration, 67, 202–213. https://doi.org/10.1016/j.ijrefrig.2016.03.020
Jige, D., Mikajiri, N., Kikuchi, S., & Inoue, N. (2020). Condensation heat transfer and pressure drop of R32/R1123 inside horizontal multiport extruded tubes. International Journal of Refrigeration, 120, 200–208. https://doi.org/10.1016/j.ijrefrig.2020.08.029
Kang, P., Heo, J., & Yun, R. (2013). Condensation heat transfer characteristics of Co2 in a horizontal smooth tube. International Journal of Refrigeration, 36(3), 1090–1097. https://doi.org/10.1016/j.ijrefrig.2012.10.005
Keinath, B. L. (2012). Void fraction, pressure drop, and heat transfer in high pressure condensing flows through microchannels. Georgia Institute of Technology, PhD Thesis.
Knipper, P., Arnsberg, J., Bertsche, D., Gneiting, R., & Wetzel, T. (2020). Modelling of condensation pressure drop for R134a and R134a-lubricant-mixtures in multiport flat tubes. International Journal of Refrigeration, 113, 239–248. https://doi.org/10.1016/j.ijrefrig.2020.01.007
Komandiwirya, H. B., Hrnjak, P. S., & Newell, T. A. (2005). An experimental investigation of pressure drop and heat transfer in an in-tube condensation system of ammonia with and without miscible oil in smooth and enhanced tubes. University of Illinois, Report.
Liu, N., Li, J. M., Sun, J., & Wang, H. S. (2013). Heat transfer and pressure drop during condensation of R152a in circular and square microchannels. Experimental Thermal and Fluid Science, 47, 60–67. https://doi.org/10.1016/j.expthermflusci.2013.01.002
Liu, N., Xiao, H., & Li, J. (2016). Experimental investigation of condensation heat transfer and pressure drop of propane, R1234ze(E) and R22 in minichannels. Applied Thermal Engineering, 102, 63–72. https://doi.org/10.1016/j.applthermaleng.2016.03.073
Liu, N., & Li, J. (2016). Experimental study on pressure drop of R32, R152a and R22 during condensation in horizontal minichannels. Experimental Thermal and Fluid Science, 71, 14–24. https://doi.org/10.1016/j.expthermflusci.2015.10.013
Longo, G. A., Mancin, S., Righetti, G., & Zilio, C. (2017). Saturated vapour condensation of HFC404A inside a 4mm ID horizontal smooth tube: Comparison with the long-term low GWP substitutes HC290 (propane) and HC1270 (propylene). International Journal of Heat and Mass Transfer, 108, 2088–2099. https://doi.org/10.1016/j.ijheatmasstransfer.2016.12.087
Longo, G. A., Mancin, S., Righetti, G., & Zilio, C. (2018). Saturated vapour condensation of R410A inside a 4 mm ID horizontal smooth tube: Comparison with the low GWP substitute R32. International Journal of Heat and Mass Transfer, 125, 702–709. https://doi.org/10.1016/j.ijheatmasstransfer.2018.04.109
Longo, G. A., Mancin, S., Righetti, G., & Zilio, C. (2019). Saturated vapour condensation of R134a inside a 4 mm ID horizontal smooth tube: Comparison with the low GWP substitutes R152a, R1234yf and R1234ze(E). International Journal of Heat and Mass Transfer, 133, 461–473. https://doi.org/10.1016/j.ijheatmasstransfer.2018.12.115
Lu, M.-C., Tong, J.-R., & Wang, C.-C. (2013). Investigation of the two-phase convective boiling of HFO-1234yf in a 3.9 mm diameter tube. International Journal of Heat and Mass Transfer, 65, 545–551. https://doi.org/10.1016/j.ijheatmasstransfer.2013.06.004
MacDonald, M. (2015). Condensation of pure hydrocarbons and zeotropic mixtures in smooth horizontal tubes. Georgia Institute of Technology, PhD Thesis.
Maråk, K. A. (2009). Condensation heat transfer and pressure drop for methane and binary methane fluids in small channels. Norwegian University of Science and Technology, PhD Thesis.
Milkie, J. A. (2014). Condensation of hydrocarbon and zeotropic hydrocarbon/refrigerant mixtures in horizontal tubes. Georgia Institute of Technology, PhD Thesis.
Mitra, B. (2005). Supercritical gas cooling and condensation of refrigerant R410a at near-critical pressures. Georgia Institute of Technology, PhD Thesis.
Monroe, C. A., Newell, T. A., & Chato, J. C. (2003). An experimental investigation of pressure drop and heat transfer in internally enhanced aluminum microchannels. University of Illinois, Report.
Murphy, D. (2014). Condensation heat transfer and pressure drop of propane in vertical minichannels. Georgia Institute of Technology, MSc Thesis.
Nino, V. G., Hrnjak, P. S., & Newell, T. A. (2002). Characterization of two-phase flow in microchannels. University of Illinois, Report.
Garcia Pabon, J., Khosravi, A., Nunes, R., & Machado, L. (2019). Experimental investigation of pressure drop during two-phase flow of R1234yf in smooth horizontal tubes with internal diameters of 3.2 mm to 8.0 mm. International Journal of Refrigeration, 104, 426–436. https://doi.org/10.1016/j.ijrefrig.2019.05.019
Padilla, M., Revellin, R., Haberschill, P., Bensafi, A., & Bonjour, J. (2011). Flow regimes and two-phase pressure gradient in horizontal straight tubes: Experimental results for HFO-1234yf, R-134a and R-410A. Experimental Thermal and Fluid Science, 35(6), 1113–1126. https://doi.org/10.1016/j.expthermflusci.2011.03.006
Park, C. Y., & Hrnjak, P. S. (2007). Carbon dioxide and R410A flow boiling heat transfer, pressure drop, and flow pattern in horizontal tubes at low temperatures. University of Illinois, Report.
Park, C. Y., & Hrnjak, P. S. (2009). Co2 flow condensation heat transfer and pressure drop in multi-port microchannels at low temperatures. International Journal of Refrigeration, 32(6), 1129–1139. https://doi.org/10.1016/j.ijrefrig.2009.01.030
Patel, T., Parekh, A. D., & Tailor, P. R. (2020). Experimental analysis of condensation heat transfer and frictional pressure drop in a horizontal circular mini channel. Heat and Mass Transfer, 56(5), 1579–1600. https://doi.org/10.1007/s00231-019-02798-5
Pham, Q. V., Choi, K.-I., & Oh, J.-T. (2019). Condensation heat transfer characteristics and pressure drops of R410A, R22, R32, and R290 in a multiport rectangular channel. Science and Technology for the Built Environment, 25(10), 1325–1336. https://doi.org/10.1080/23744731.2019.1665447
Qi, C., Chen, X., Wang, W., Miao, J., & Zhang, H. (2019). Experimental investigation on flow condensation heat transfer and pressure drop of nitrogen in horizontal tubes. International Journal of Heat and Mass Transfer, 132, 985–996. https://doi.org/10.1016/j.ijheatmasstransfer.2018.11.092
Rahman, M. M., Kariya, K., & Miyara, A. (2017). Experimental investigation of condensation heat transfer and adiabatic pressure drop characteristics inside a microfin and smooth tube. International Journal of Air-Conditioning and Refrigeration, 25(03), 1750027. https://doi.org/10.1142/S2010132517500274
Revellin, R., & Thome, J. R. (2007). Adiabatic two-phase frictional pressure drops in microchannels. Experimental Thermal and Fluid Science, 31(7), 673–685. https://doi.org/10.1016/j.expthermflusci.2006.07.001
Rossato, M., Da Silva, J. D., Ribatski, G., & Del Col, D. (2017). Heat transfer and pressure drop during condensation of low-GWP refrigerants inside bar-and-plate heat exchangers. International Journal of Heat and Mass Transfer, 114, 363–379. https://doi.org/10.1016/j.ijheatmasstransfer.2017.06.011
Sakamatapan, K., & Wongwises, S. (2014). Pressure drop during condensation of R134a flowing inside a multiport minichannel. International Journal of Heat and Mass Transfer, 75, 31–39. https://doi.org/10.1016/j.ijheatmasstransfer.2014.02.071
Sarmadian, A., Shafaee, M., Mashouf, H., & Mohseni, S. G. (2017). Condensation heat transfer and pressure drop characteristics of R-600a in horizontal smooth and helically dimpled tubes. Experimental Thermal and Fluid Science, 86, 54–62. https://doi.org/10.1016/j.expthermflusci.2017.04.001
Shin, J. S., & Kim, M. H. (2004). An experimental study of condensation heat transfer inside a mini-channel with a new measurement technique. International Journal of Multiphase Flow, 30(3), 311–325. https://doi.org/10.1016/j.ijmultiphaseflow.2003.11.012
Shin, J. S., & Kim, M. H. (2004). An experimental study of condensation heat transfer in sub-millimeter rectangular tubes. Journal of Thermal Science, 13(4), 350–357. https://doi.org/10.1007/s11630-004-0054-z
Singh, S., & Kukreja, R. (2018). Experimental heat transfer coefficient and pressure drop during condensation of R-134a and R-410A in horizontal micro-fin tubes. International Journal of Air-Conditioning and Refrigeration, 26(03), 1850022. https://doi.org/10.1142/S2010132518500220
Son, C.-H., & Oh, H.-K. (2012). Condensation pressure drop of R22, R134a and R410a in a single circular microtube. Heat and Mass Transfer, 48(8), 1437–1450. https://doi.org/10.1007/s00231-012-0990-1
Song, Q., Chen, G., Guo, H., Shen, J., & Gong, M. (2019). Two-phase flow condensation pressure drop of R14 in a horizontal tube: Experimental investigation and correlation development. International Journal of Heat and Mass Transfer, 139, 330–342. https://doi.org/10.1016/j.ijheatmasstransfer.2019.05.023
Sempértegui-Tapia, D. F., & Ribatski, G. (2017). Two-phase frictional pressure drop in horizontal micro-scale channels: Experimental data analysis and prediction method development. International Journal of Refrigeration, 79, 143–163. https://doi.org/10.1016/j.ijrefrig.2017.03.024
Tibiriçá, C. B., & Ribatski, G. (2011). Two-phase frictional pressure drop and flow boiling heat transfer for R245fa in a 2.32 mm tube. Heat Transfer Engineering, 32(13-14), 1139–1149. https://doi.org/10.1080/01457632.2011.562725
Tu, X., & Hrnjak, P. S. (2007). Flow and heat transfer in microchannels 30 to 300 microns in hydraulic diameter. University of Illinois, Report.
Wang, C. C., Chiang, S. K., Chang, Y. J., & Chung, T. W. (2001). Two-phase flow resistance of refrigerants R-22, R-410A and R-407C in small diameter tubes. Transactions of the American Institute of Chemical Engineers, 79, Part A, 553–559.
Wang, Y., Shen, S., & Yuan, D. (2017). Frictional pressure drop during steam stratified condensation flow in vacuum horizontal tube. International Journal of Heat and Mass Transfer, 115, 979–990. https://doi.org/10.1016/j.ijheatmasstransfer.2017.08.088
Yang, C. Y., & Webb, R. L. (1996). Friction pressure drop of R-12 in small hydraulic diameter extruded aluminum tubes with and without micro-fins. International Journal of Heat and Mass Transfer, 39(4), 801–809. https://doi.org/10.1016/0017-9310(95)00151-4
Yun, R., Hyeok Heo, J., & Kim, Y. (2006). Evaporative heat transfer and pressure drop of R410A in microchannels. International Journal of Refrigeration, 29(1), 92–100. https://doi.org/10.1016/j.ijrefrig.2005.08.005
Zhang, M., & Webb, R. L. (2001). Correlation of two-phase friction for refrigerants in small-diameter tubes. Experimental Thermal and Fluid Science, 25(3), 131–139. https://doi.org/10.1016/S0894-1777(01)00066-8
Zhang, Z., Weng, Z. L., Li, T. X., Huang, Z. C., Sun, X. H., He, Z. H., van Es, J., Pauw, A., Laudi, E., & Battiston, R. (2013). CO2 condensation heat transfer coefficient and pressure drop in a mini-channel space condenser. Experimental Thermal and Fluid Science, 44, 356–363. https://doi.org/10.1016/j.expthermflusci.2012.07.007
Zhuang, X. R., Gong, M. Q., Zou, X., Chen, G. F., & Wu, J. F. (2016). Experimental investigation on flow condensation heat transfer and pressure drop of R170 in a horizontal tube. International Journal of Refrigeration, 66, 105–120. https://doi.org/10.1016/j.ijrefrig.2016.02.010
Zhuang, X. R., Chen, G. F., Zou, X., Song, Q. L., & Gong, M. Q. (2017). Experimental investigation on flow condensation of methane in a horizontal smooth tube. International Journal of Refrigeration, 78, 193–214. https://doi.org/10.1016/j.ijrefrig.2017.03.021
Chisholm, D. (1967). A theoretical basis for the Lockhart-Martinelli correlation for two-phase flow. International Journal of Heat and Mass Transfer, 10(12), 1767–1778. https://doi.org/10.1016/0017-9310(67)90047-6
Shah, R. K., & London, A. L. (2014). Laminar flow forced convection in ducts: A source book for compact heat exchanger analytical data. Academic.
Sparrow, E. M. (1962). Laminar flow in isosceles triangular ducts. AIChE Journal, 8(5), 599–604. https://doi.org/10.1002/aic.690080507
Pedregosa, F., Varoquaux, G., Gramfort, A., Michel, V., Thirion, B., Grisel, O., Blondel, M., Prettenhofer, P., Weiss, R., Dubourg, V., Vanderplas, J., Passos, A., Cournapeau, D., Brucher, M., Perrot, M., & Duchesnay, E. (2011). Scikit-Learn: Machine learning in python. Journal of Machine Learning Research, 12, 2825–2830.
Aggarwal, C. C. (2018). Neural networks and deep learning. Springer. https://doi.org/10.1007/978-3-319-94463-0
Smola, A. J., & Schölkopf, B. (2004). A tutorial on support vector regression. Statistics and Computing, 14(3), 199–222. https://doi.org/10.1023/B:STCO.0000035301.49549.88
Natekin, A., & Knoll, A. (2013). Gradient boosting machines, a tutorial. Frontiers in Neurorobotics, 710. https://doi.org/10.3389/fnbot.2013.00021
Friedman, J. H. (2001). Greedy function approximation: A gradient boosting machine. Annals of Statistics, 29(5), 1189–1232.
Breiman, L. (2001). Random forests. Machine Learning, 45(1), 5–32. https://doi.org/10.1023/A:1010933404324
Akers, W. W., Deans, H. A., & Crosser, O. K. (1958). Condensing heat transfer within horizontal tubes. Chemical Engineering Progress, 54, 89–90.
Wang, C.-C., Chiang, C.-S., & Lu, D.-C. (1997). Visual observation of two-phase flow pattern of R-22, R-134a, and R-407C in a 6.5 mm smooth tube. Experimental Thermal and Fluid Science, 15(4), 395–405. https://doi.org/10.1016/S0894-1777(97)00007-1
Sun, L., & Mishima, K. (2009). Evaluation analysis of prediction methods for two-phase flow pressure drop in mini-channels. International Journal of Multiphase Flow, 35(1), 47–54. https://doi.org/10.1016/j.ijmultiphaseflow.2008.08.003
Zhou, L., Garg, D., Qiu, Y., Kim, S.-M., Mudawar, I., & Kharangate, C. R. (2020). Machine learning algorithms to predict flow condensation heat transfer coefficient in mini/micro-channel utilizing universal data. International Journal of Heat and Mass Transfer, 162120351. https://doi.org/10.1016/j.ijheatmasstransfer.2020.120351
Macdonald, M., & Garimella, S. (2016). Hydrocarbon condensation in horizontal smooth tubes: Part II – Heat transfer coefficient and pressure drop modeling. International Journal of Heat and Mass Transfer, 93, 1248–1261. https://doi.org/10.1016/j.ijheatmasstransfer.2015.09.019
Yang, C.-Y., & Nalbandian, H. (2018). Condensation heat transfer and pressure drop of refrigerants HFO-1234yf and HFC-134a in small circular tube. International Journal of Heat and Mass Transfer, 127, 218–227. https://doi.org/10.1016/j.ijheatmasstransfer.2018.07.093
Funding
The authors did not receive support from any organization for the submitted work.
Author information
Authors and Affiliations
Contributions
Both authors have contributed equally to the work. The author(s) read and approved the final manuscript.
Corresponding author
Ethics declarations
Competing interests
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Shourehdeli, S.A., Mobini, K. Machine learning-based models for frictional pressure drop prediction of condensing and adiabatic flow in micro, mini and macro channels utilizing universal data. Int. J. Air-Cond. Ref. 31, 8 (2023). https://doi.org/10.1007/s44189-023-00025-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s44189-023-00025-9