
Abstract
Research Question
Can criminal recruiters be identified and ranked by crime harm levels in a London borough, and if so, how long is the predictive window of opportunity for targeting them with crime prevention efforts?
Data
This study deploys 5 years of Metropolitan Police Service crime data, relating to one of the 32 London boroughs in that time period. The data structure allowed identification of all suspects linked to the same crime report and all crime reports linked to the same suspects. Identification of linked suspects and their associated crime harm was undertaken using Structured Query Language (SQL) and ColdFusion Markup Language (CFML) via a web-based application.
Methods
All offenders were ranked by the number of co-offenders they acquired, as well as the total Cambridge crime harm index weight of the detected offences associated with them.
Findings
The highest harm recruiters are shown to be up to 137 times as harmful as the average offender, with one recruiter committing the same number of crimes as another but having 97 times more crime harm. Recruiter populations are highly dynamic, with few potential targets persisting from year to year over multiple years.
Conclusions
This study suggests that criminal recruiters are readily identifiable from police data, but police would only have a short window of opportunity to use deterrent or other preventive strategies with them once they are identified.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Targeting police resources can be achieved through a number of methods, using different units of analysis. Places, victims and offenders are the most prominent units, yet they may each feature different challenges for operational police purposes. One central challenge is to understand the causal links across crimes and criminals, especially in terms of the networks of co-offending that are detectable in police data. Such efforts can take police targeting strategies beyond the atomized individual offender and embed them in the relationships across offenders. This is especially important for offenders with high risk of causing high harm (Sherman et al. 2016). It is even more important for offenders who may recruit other offenders to enter a life of crime for their first criminal act, or to enlist them in repeated co-offending activity (Sarnecki 2001).
Interventions with high-risk offenders, in general, can be accomplished by a number of tactics, including Integrated Offender Management, Restorative Justice Conferences and more traditional “Prolific Priority Offender” programmes within police agencies. These tactics may disrupt and deter offenders through myriad police actions, including bail/curfew checks, warrant execution, GPS tagging and targeted stop and search. Yet the value of these activities in reducing crime harm may depend entirely on the capacity of targeting strategies to distinguish the offenders causing highest harm from the majority whose sum total of crime causes less harm than a potentially predictable highest harm “felonious few” (Sherman 2019).
This study examines a method of targeting offenders based on their relationship with other known offenders, as established based crime reports data. While this method has been used in California (Englefield and Ariel 2017), Sweden (Sarnecki 2001) and other countries, the present study appears to be the first to examine the method in London. The method identifies a small subset of prolific offenders who seem to recruit others into crime, as indicated by a higher than average number of co-offenders (each set defined as two or more persons appearing in the crime report in relation to the same offence) within a population of known offenders. Rather than identifying “prolific” offenders based solely on the number of crimes linked to them, this method starts with the number of co-offenders linked to each offender (Reiss 1988; Sarnecki 2001).
With the advent of the Cambridge crime harm index (Sherman 2007a, b; Sherman et al. 2016), targeting by identifying high levels of co-offending can now be refined by calculating CHI totals for each offender. Crimes linked to those recruiters and their recruits can be examined in terms of harm, rather than computing crime counts for each offender or network as if all crimes are created equal. As far as we are aware, no previous analysis has calculated the CHI values for co-offenders, their networks, or (crucially) the key “recruiters” into those networks. The enhancement of targeting that this study provides by applying CHI scores builds on the previous work done without calculating harm severity (including van Mastrigt and Farrington 2011; Sarnecki 2001; Englefield and Ariel 2017), with identification of the recruiters suggesting that targeting them will be an effective use of police resources (Ariel et al. 2019). Yet that conclusion may rest more on measures of harm than on measures of frequency, when both are distributed across populations of previously identified suspects.
This study examines the extent to which the application of a crime harm weighting to those identified recruiters can enhance the potential benefit of targeting police action, when it is designed to disrupt and deter these individuals both from committing crime themselves and from recruiting others into crime. It does that by using CHI to create a more sensitive measure of the different levels of harm associated with different recruiters and networks.
Targeting recruiters based on crime harm is still based on the assumption that those recruits who offend with the recruiters would not have started offending to the same extent unless they had been mentored into committing crime by the recruiter. Targeting these recruiters thus multiplies crime reductions, while targeting recruiters for crime harm can thus multiply harm reductions: in both cases the reduction in direct as well as vicarious harm attributable to them and their recruiting of others into crime. The analysis will examine how the rank ordering of these high harm offenders is altered by consideration of the crime harm attributable to them rather than just their crime counts, demonstrating that the high crime count recruiters are not the same as the high crime harm recruiters.
This study will look at two broad methods of identifying recruiters—through analysis of 5 years of data on each offender and their crimes on a calendar year basis, year by year. The first approach is that taken by previous authors (van Mastrigt and Farrington 2011; Englefield and Ariel 2017). The year-on-year analysis will seek to demonstrate whether targeting those recruiters would actually reduce harm in the ensuing years, by asking to what extent the recruiters identified continue to commit crime—a simple evaluation of the potential benefit of targeting recruiters over a longer time period. Yet even if the time period to target high harm recruiters is short, it may still be worthwhile to focus limited resources on them for short periods of time.
By identifying these exceptionally high harm offenders, the cost-benefit analysis of policing interventions should be high, allowing police leaders to show evidence of why they are deploying their officers to disrupt these offenders and not most others. To test this hypothesis, this study undertook an evaluation approach of the harm prevention potential of targeting co-offending recruiters, by ascertaining how much crime the recruiters were linked to in the calendar years subsequent to the year in which they were identified.
Surprisingly, the analysis suggests that the window of opportunity for targeting high harm crime recruiters is short. While the highest harm members of the “felonious few” (Sherman 2019) are very harmful in the calendar year in which they are identified, very few of them show up as high harmers in the subsequent years. Further research should consider the benefit of identifying recruiters on an ongoing basis, targeting them immediately once they have reached a threshold of crime harm.
Research Questions
The research procedure for this study was designed as a three-step process of confirming previous findings, undertaking new analyses of harm and then asking the question of “so what” for a multi-year period. These questions can be specified as follows:
-
1.
To what extent are “recruiters” of co-offending criminals identifiable in recorded crime datasets in this London borough?
-
2.
What are the levels of crime and crime harm associated with recruiters, relative to other offenders and each other?
-
3.
What is the feasibility of targeting recruiters over a multi-year period?
Data
The identification of co-offenders based on official records requires access to information about who is offending and with whom. This question could be answered by various datasets, with varying degrees of accuracy and usefulness.
Court Records
Perhaps the most reliable method would be to analyse court records for offenders found guilty of offences committed together. This method would identify co-offenders with a high degree of accuracy, given the evidentiary standard of “beyond all reasonable doubt” applied to criminal proceedings. The downsides to analysing court data, however, include the small number of criminal associations actually leading to prosecution and the difficulties associated with locating records.
Arrest Data
Previous attempts to identify police recruiters often used arrest data to identify recruiter-recruit relationships (see review in van Mastrigt and Carrington 2019). A dataset on co-arrests (i.e. individuals that were arrested by the police for the same offence) is the most approachable to police analysts and the most accurate police dataset prior to charging co-offenders for the same offence (on studies looking at co-offending data using charge records, see Frydensberg et al. 2019).
The most stubborn issue with using arrest data to identify co-offending relationships is understanding recruitment. Differentiating between crimes committed by a pair (or more) of offenders and crimes committed by offenders who have a recruiter-recruit relationship is not straightforward: the type of relationship is not evidentiary per se and therefore goes unrecorded in police data. Instead, research with police data applied a series of assumptions that, when met, increase the likelihood about recruitment relationships: when the recruiter is older and more prolific than the inexperienced and young co-offender (e.g. van Mastrigt and Farrington 2011). The construct validity of this approach is not unfounded, as it corresponds to recruitment patterns found in research using non-police records. For example, based on interviews with offenders in prison, Morselli et al. (2006, p. 27) reported that “on average, mentors were 11.4 years older than the protégés”.
Moreover, arrest data alone are insufficient when the geographic location in which the study takes place is small (so the total number of arrests is proportionally low). Recruiter-recruit relationships are rare (van Mastrigt and Farrington 2011) and arrest data from one police borough will produce a short target list.
Intelligence Records
At a far lower level of accuracy, but with greater value for policing, it would be possible to analyse intelligence records. One option is to analyse reports containing information about “sightings” of known offenders. These data could support conclusions about which people known offenders are associating with. However, non-offenders may be interacting socially with offenders (or organized crime group offenders interacting with offenders who are not associated with the group), but do not commit crimes together. These are weak intelligence products with which to ascertain social network linkages (Denley and Ariel 2019).
A more accurate intelligence data source could be stop and search data, identifying who has been searched while in the company of others. Since a stop and search requires reasonable suspicion of the commission of an offence, these data can more precisely identify offender networks—possibly even more with the advents of body-worn cameras with facial recognition technologies (Almadan et al. 2020; Bromberg et al. 2020). The benefits of these large datasets are their size and the potential to locate latent relationships that arrest and court records do not show.
For this study, we built the network of co-offenders based on crime reports. These form part of the overall intelligence records as “products” of policing activities: they often contain names of accomplices that are discovered through investigation activities. For example, an offender may name his co-offenders in a police interview, or a person who identifies the two individuals that victimized him.
This study therefore examines co-offenders in the context of these crime reports, using all identified suspects, whether they are charged or not. The term “co-offender” could be replaced, in strictly legal terms, with a “co-identified suspect”. The results of this analysis should therefore considered to be an intelligence product for use by police agencies as a targeting method, rather than a way of definitively stating that those identified are responsible for the crimes which they are linked to.
Procedure
The study is based on more specific (and harm-coded) facts in the Met Police crime recording system, known as CRIS (Criminal Records Information System). CRIS records all allegations of crime as well as information about the suspects linked to each criminal offence. The suspect information in CRIS can range from a scant description up to a formally identified offender. The scant descriptions are inputted to the system when a victim can give no further details—perhaps having being attacked from behind, for example, and only being able to guess that the offender was taller than them but nothing else. There will also be several crime reports with no identified suspect, for example, burglaries where no offender is identified at all.
An export file of all crime data for 5 years for a London borough was obtained from the CRIS system. Reports are inputted to this system once it has been established by the police that a crime has been committed and is distinct from the “call for service” systems.
Where a suspect is identified to the level of detail of having their name and date of birth recorded, further internal Metropolitan Police Service (MPS) processes take place to assign a unique identifier to that offender. When a suspect is arrested in the MPS, their identity is confirmed against an internal unique ID in addition to any Police National Computer record. This unique identifier removes any substantial error that would have been encountered and had suspects been identified only by their name and date of birth. This MPS-assigned identifier removes the error attributable to misspelling of names, or incorrect entry of dates of birth. It also accounts for slightly different names being given at different times (nicknames, extra names, pseudonyms, etc.).
This export file resulted in 80,695 rows of data, with each row containing the unique suspect identifier, linked crime reference number and date of birth of offender. Suspects linked to multiple crimes would appear as multiple rows of data, so the number of crimes described in the data is 68,809.
To identify recruiters, MySQL database was used with the application written in ColdFusion Markup Language (CFML) and Structured Query Language (SQL). The data were first anonymised. The data were structured in such a way that one row was linked to each suspect for each crime, with columns for suspect id, crime reference number id, date of birth and crime type code. In this manner, for a crime with ten identified suspects, there would be ten rows of data.
This study, as in previous studies, developed its own algorithm to define the difference between offenders considered “recruiters” and those not considered to be recruiters. van Mastrigt and Farrington (2011) and Englefield and Ariel (2017) each adopted different thresholds to identify recruiters based on official statistics but used the same three variables (Table 1).
van Mastrigt and Farrington (2011) define an average of 3.33 offences a year as the threshold for a prolific offender. Since the present (London) study is examining 5 years of data, the corresponding count would be 16 offences over the 5 years. For ease of calculation on a year-by-year basis, this study will identify as prolific, any suspect linked in CRIS reports to a mean of three or more crimes per year.
Next, after identifying suspects linked to a mean of three or more offences per year over the 5-year dataset, we moved to identifying suspects linked to five or more accomplices, restricting this to the number of accomplices who were more than 1 year younger than the candidate for recruiter status by comparing dates of birth of the candidate to the apparent accomplice. These prolific suspects with a high rate of younger accomplices were then identified as recruiters.
Identifying Harm
MPS crimes are categorized into a wide variety of classifications, and due to the historical make-up of the crime recording system, there are multiple codes for the same crimes, as well as redundant crime classifications no longer used. A database of all crime codes found in the data was compiled and the corresponding crime harm value was recorded next to each crime classification to allow cross-referencing with the individual crimes. This allowed the analysis to assign crime harm values to suspects—for example, a suspect linked to two offences of domestic burglary without violence and one instance of assaulting a constable would be assigned a crime harm value of 15 + 15 + 1.5 = 31.5.
In total, 307 crime classifications were assigned crime harm counts. The CHI scores for each classification were taken from the Cambridge crime harm index (Weinborn et al. 2017). Although the process of matching those counts against MPS crime classifications was not straightforward given the significant differences between the classifications used in the CRIS system, the definitions were all provided by “starting point” sentence in the sentencing guidelines. In the majority of cases, this merely required the identification of corresponding classifications from the abbreviations used.
A number of CRIS classifications relate to “non-crime” classifications where the system is used to record investigations that do not amount to substantive offences. The largest category of these is the use of the CRIS system to record details of domestic arguments where no offences are committed, the so called “Non-Crime Domestic”. These categories were assigned a “0” value on the crime harm index.
The Cambridge crime harm index can be used to assign harm to individual suspects, and it allows a calculation to be made of how much harm that offender is suspect is linked to, as a percentage of all harm present in the data. However, this suggests that an offence of “domestic burglary without violence” involving five offenders has a crime harm index of 15 × 5 = 75, whereas a similar offence with only one suspect would have a crime harm index of only 15. This complexity is not considered when ascertaining the geographic spread of crime harm, as that data would consider purely crime counts multiplied by corresponding harm. It is only when considering offenders that this potential for crimes with multiple offenders to be weighted by the number of offenders becomes a concern.
This inconsistency is also apparent in the Home Office counting rules that dictate how UK police agencies record crimes (Home Office 2015). These state, for example, that where “two relatives of the householder who are staying overnight have property stolen when the house is burgled, one crime of burglary will be recorded” (p. 19).
The intention of the CHI is to better ascertain the associated harm of a crime. It can be argued that two people being subjected to a residential burglary implies that twice the harm has occurred compared to an offence with only one victim, since the CHI is by definition, partially an attempt to reflect the impact on the victim. If there are 5 suspects for that same burglary, how does this change the harm associated with it? The answer could be said to lie in the perspective being taken, since an offender-based perspective would identify offences with multiple suspects giving a greater opportunity to reduce the offending of those suspects. Since this study is aimed at identifying high harm offenders/suspects, it makes sense to count two suspects of one crime as amounting to twice the harm. For consistency, this is the approach taken with the calculations.
Findings
Five-Year Data Analysis
The 5-year data contained 68,809 crime reports and 51,632 unique suspects with a valid date of birth. Fully 75% of suspects were only linked with one crime report. Of the 25% linked to more than one crime report, the number linked to higher numbers of crimes reduces sharply as a proportion of the 51,632. There is a very steep curve of repeat suspects, with only 495 (0.96%) committing more than ten offences in the 5-year period. The most prolific suspect was linked to 65 crime reports—on average more than one a month for the entire 5-year period. This data also demonstrates that only 5051 (9.8%) of suspects were linked to three or more crimes.
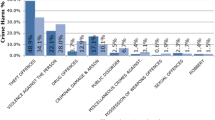
The first element of the recruiter identification is that it must be prolific, which this study defines prolific as being linked to 15 or more offences in the 5-year period. Applying those decision rules produced 229 prolific suspects. When comparing the prolific suspects’ crime breakdown against the general crime type breakdown, there appears to be one major difference between prolific suspects and the general suspect population, with prolific offenders committing about twice the amount of theft and handling offences (35% c/f 16%) as all non-prolific suspect combined and about half the violence offences as all offenders (18% c/f 35%).
This difference in crime types may reflect the difficulty in securing convictions for acquisitive offences, or it may demonstrate a difference in offence preference for recidivist offenders. It may also reflect the sentencing differences between acquisitive crimes and violent offences, with those offenders linked to a larger number of violent offences being more likely to receive a custodial sentence or other interventions.
Recruiter Identification
Having identified the prolific suspects, the next process identified those prolific suspects with more than five co-suspects. This calculation reduced the number of identified potential recruiters to just 114.
The next stage after this was to select those prolific suspects who were linked to five or more co-suspects who were younger than them. When initially calculated, this returned a number of suspects who were linked to a number of their peers and were identified as being the oldest of a group of similar aged suspects. In particular, this identified school-age suspects identified as suspects among a large group. This does not align with the theoretical basis for identifying recruiters (that a more experienced offender acts as a mentor to a younger offender). A buffer of a year was introduced to counter this challenge. In line with van Mastrigt and Farrington’s definition, more than 50% of these co-suspects were required to be more than a year younger than the recruiter. With this in place, 26 recruiters were identified from the 5-year data matching the definition:
-
Suspects for 15 or more offences (an average of three per year)
-
More than 5 co-suspects
-
More than 50% of co-suspects being more than a year younger than the recruiter
Of these recruiters, nine of the 26 were active in every year from 2011 to 2015. Ten were active in four out of the 5 years, three in 4 years and three in 2 years. There were no identified recruiters active in only 1 year.
Two identified recruiters had a huge number of co-suspects. Examination of the relevant crime reports shows that these reports relate to the August 2011 riots in London. The number of co-suspects is so high because the reports relate to looting of shops with more than fifty named suspects. As such, this does not match the theoretical basis of the recruiter, whereby there is social or other exchange between the mentor recruiter and the recruit. Rather, this appears to be a data anomaly caused by an extremely unusual series of crimes during the civil unrest.
Crime Harm Linked to Recruiters
With the 26 recruiters identified as above, the harm associated with each can be calculated by multiplying each of their linked crimes with the crime harm value for that crime type. The red line shows the offence counts, with suspect 1 having the highest number of offences.
Figure 1 clearly demonstrates the impact of applying a crime harm index to these suspects. Recruiters 18 and 19 have the same number of offences linked to them but a twenty times difference in crime harm. Recruiter 19 would clearly be a more appropriate target for police resources, since the amount of harm caused by them is so much greater.

Recruiter direct crime harm total by offence count over 5 years
Of particular note in Fig. 1 is that recruiter 26 is linked to the least number of crimes (15) yet has the highest attributable crime harm (8220 days). Recruiters 26 and 8 both match our definition of recruiters yet are linked to crimes with crime harm of 8220 and 84, respectively. This represents a difference of 97 times. Thus using the Cambridge crime harm index has revealed that targeting recruiter 26 would reduce the harm to society by 97 more times than recruiter 8, yet a pure crime count analysis would suggest that recruiter 8 would actually be a more appropriate target.
Expanding the analysis to include the crime counts and crime harm linked to the recruiter’s co-offenders shows the significant potential benefits of targeting the recruiters. Recruiter 26 is now linked to crime harm amounting to 13,700 days, resulting from 25 offences, an average of 548 days of crime harm per offence. Recruiter 8 is linked to 26 offences, more than recruiter 26, but with a total crime harm of 102—an average of 4 days per offence. The rationale to target recruiter 26 instead of recruiter 8 is clear (Fig. 2).

Total harm by recruiters and their recruits vs. all offence counts
Total harm present in the dataset is 6,978,508. The top 5 recruiters (0.006% of suspects) account for 0.84% of all crime harm in Southwark, but only 256 crimes out of a total of 67,792 (0.38%). These suspects are thus twice as harmful as the crime counts alone would suggest.
The data analysis so far has focussed on the identification of recruiters in a 5-year dataset. A core question of this study is how useful the identification of recruiters could be operationally. While the analysis of 5 years of data undoubtedly identifies high harm suspects, what is the best way to operationalize this work, in order to target recruiters at the right time?
In order to understand this, the data was reviewed based on individual and calendar years of data, to understand the persistence of recruiters in the data. The algorithm used to identify recruiters was altered to identify a recruiter as a prolific suspect having committed three or more offences in the year. The requirement for the recruiter to be linked to five or more younger suspects was not altered.
Table 2 presents the year-on-year data for identified recruiter numbers.
Only twelve recruiters were identified as recruiters in two different years, and no recruiters were identified in three or more years’ worth of data. As detailed in Table 2 above, a small number of the recruiters identified in the 5-year data were also identified in any of the individual years, and only five recruiters in the 5-year data were identified in two different years, and none in three or more.
The year-on-year data analysis identified varying numbers of recruiters for each year, with the year 2011 having significantly more recruiters, as a result of the large number of multiple offender crime reports linked to the August 2011 riots. Because this year is so affected by those reports, the following analysis is restricted to the 4 years of 2012–2015 which are more typical years.
Summary of Individual Years Data Analysis
From 2012 to 2015, it is clear that a small number of the recruiters are responsible for a significant percentage of all the crime harm attributable to recruiters and their recruits. To demonstrate just how concentrated the harm is among a small “felonious few”, the number of recruiters linked to approximately two thirds of the recruiters’ crime harm was calculated for each year, reducing the number of recruiters down to the most harmful. The exact percentage of crime harm attributable to this number was then calculated. This value is expressed as a percentage of the crime harm in all the crimes for that year, to show how much of the total harm in the year was attributable to those high harm recruiters. Table 3 displays the results.
Table 3 suggests that in 2013, just 3 suspects were linked, directly and through their recruits, to 4.47% of all crime harm committed in a London borough of 300,000 residents. In this year, 9220 offenders were identified for the same policing area, which suggests that these recruiters are responsible for 137 times as much harm as the average suspect. This is an extremely powerful demonstration of Sherman’s (2007a, b; 2019) “felonious few” hypothesis. It suggests that these suspects could be cost-effectively targeted by any policing agency, as the amount of harm they cause is so very much more than the average suspect.
Moving Targets: Activity of “Year-on-Year Recruiters in the Following Years
While only twelve of the recruiters are identified as recruiters in more than 1 year, and none in more than 2 years, the data were analysed to understand whether the recruiters were linked to any crime at all in the years after they were identified. There is no lower threshold for the number of crimes committed. This analysis instead simply shows whether they were linked to any crime reports at all in the following years after initial identification. Of the 16 recruiters identified in 2012, only 7 were linked to any crime at all in 2013.
Two-Year Recruiter Identification
To ascertain if recruiters were more active in more than the first following year, the data was re-computed using 2 years’ worth of data at a time. First, we examine 2012 and 2013 and then 2013 and 2014. For the first pair of years, the presence of those identified recruiters in the following single years (2014 and 2015) identified recruiters was ascertained. In addition, the recruiters’ presence in the 5-year recruiters was identified, and finally, those 2012/2013 recruiters who were linked to any crime in the following individual years were identified. Of the 21 recruiters identified from 2012/2013 data, only 1 was a recruiter in 2014 and none in 2015.
Three-Year Recruiter Identification
The data from 2012 to 2014 inclusive was analysed to identify recruiters matching the definition of three offences per year (nine in total) as well as five or more younger co-suspects. None were identified as recruiters in the 2015 data.
In summary, the 4 years’ worth of data was analysed a year at a time, 2 years at a time and 3 years at a time. The analysis tried to ascertain any amount of data most reliably identified recruiters who continued to offend in the ensuing years. The data above suggests strongly that none of these time periods of analysis usefully identified recruiters that should be targeted. Instead, it seems sensible for future research to consider identifying recruiters immediately as soon as they reach a threshold of harm, rather than on a calendar year basis.
Conclusions
This study has successfully identified recruiters in a London borough according to the definitions used by previous authors. The subset of prolific offenders that are linked to a large number of younger co-offenders is identified on a similar scale as in previous studies and appears to be a fruitful target for police intervention based on this.
The application of the Cambridge crime harm index alters our understanding of which suspects are high “value” targets considerably. Using CHI rather than crime counts reveals that some of the identified recruiters account for less crime harm over a 5-year period than many offenders do in a single crime. This advances the methodology of high harm offender targeting significantly, suggesting that police resources be targeted to the highest harm recruiters who are linked to a very significant amount of harm, making them in some cases up to 137 times as harmful as the average offender.
The recruiters do not appear to be persistent from year to year, either on a 1-, 2- or 3-year analysis, at least based on recorded offences. There is an argument to be made that these suspects have been identified as recruiters and therefore are likely to continue offending even if they are not identified through the data as such. It may also be that police resources are naturally targeted at these recruiters as they are a subset of prolific offenders; they may therefore have disappeared from the data due to the application of the criminal justice process.
The key to targeting recruiters may be to consider a continuous process of identification, with police interventions focussed on those offenders who reach a threshold, immediately as soon as they reach that threshold. The justification for such intensive tracking, perhaps with an algorithmic digital tracking system, is especially justified for those recruiters who are linked (through accomplices) to substantial amounts of crime harm. Targeting these high-total (direct and indirect) harm recruiters, as well as their linked offenders, has clear potential for substantial benefit, as long as they can be identified early enough.
The requirement to effectively target police resources is central tenet of the drive to become more evidence-based in policing (Sherman 2013). The identification of recruiters appears to be a promising method of targeting and has previously resisted more detailed exploration due to the analytic difficulties of identifying recruiters. This has meant that previous studies have identified recruiters in a dataset but have been unable to re-compute partial datasets multiple times to ascertain the continuing offending of those recruits.
This study, having built a database application to accomplish this data analysis, was able to re-compute the data more than ten times to better understand the potential impacts of targeting recruiters identified in different time periods. This analysis was conducted in 2016, and since then, the potential for rapid analysis of large datasets in this way has improved significantly. The advent of cloud-based platforms where researchers may purchase large amounts of computing power for short periods of time has been helpful, as would programming of digital tracking of reported harm levels by recruiters and their recruits. Revisiting these methods with large datasets may prove increasingly useful as Police IT systems improve, with work done now potentially informing operational decision-making as those IT systems advance.
Change history
15 March 2021
A Correction to this paper has been published: https://doi.org/10.1007/s41887-021-00062-7
References
Almadan, A., Krishnan, A., & Rattani, A. (2020). BWCFace: Open-set face recognition using body-worn camera. arXiv preprint arXiv:2009.11458.
Ariel, B., Englefield, A., & Denley, J. (2019). A randomized controlled trial on the direct and vicarious effects of preventative specific deterrence initiatives in criminal networks. The Journal of Criminal Law and Criminology, 109(4), 819–867.
Bromberg, D. E., Charbonneau, É., & Smith, A. (2020). Public support for facial recognition via police body-worn cameras: Findings from a list experiment. Government Information Quarterly, 37(1), 101415.
Denley, J., & Ariel, B. (2019). Whom should we target to prevent? Analysis of organized crime in England using intelligence records. European journal of crime, criminal law and criminal justice, 27(1), 13–44.
Englefield, A., & Ariel, B. (2017). Searching for influencing actors in co-offending networks: The recruiter. International Journal of Social Science Studies, 5, 24.
Frydensberg, C., Ariel, B., & Bland, M. (2019). Targeting the most harmful co-offenders in Denmark: A social network analysis approach. Cambridge Journal of Evidence-Based Policing, 3(1–2), 21–36.
Home Office Counting Rules For Recorded Crime, April 2015.
Morselli, C., Tremblay, P., & McCarthy, B. (2006). Mentors and criminal achievement. Criminology, 44(1), 17–43.
Reiss, A. J. J. (1988). Co-offending and criminal careers. Crime and Justice, 10, 117–170.
Sarnecki, J. (2001). Delinquent networks youth co-offending in Stockholm.
Sherman, L. W. (2007a). The power few hypothesis: Experimental criminology and the reduction of harm. Journal of Experimental Criminology, 3, 299–321.
Sherman, L. W. (2007b). The power few: Experimental criminology and the reduction of harm. Journal of Experimental Criminology, 3, 299–321.
Sherman, L. W. (2013). The rise of evidence-based policing: Targeting, testing, and tracking. In M. Tonry (Ed.), Crime and Justice in America, 1975-2025 (pp. 377–452).
Sherman, L. W. (2019). Burying the ‘power few’: Language and resistance to evidence-based policing. Cambridge Journal of Evidence-Based Policing, 3, 1–7.
Sherman, L., Neyroud, P. W., & Neyroud, E. (2016). The Cambridge crime harm index: Measuring total harm from crime based on sentencing guidelines. Policing: A Journal of Policy and Practice, 10(3), 171–183.
van Mastrigt, S. B., & Carrington, P. J. (2019). Co-offending. In The Oxford Handbook of Developmental and Life-Course Criminology. In D. P. Farrington, L. Kazemian, A. & Piquero (Eds.), (2018). The Oxford handbook of developmental and life-course criminology. Oxford Handbooks.
van Mastrigt, S. B., & Farrington, D. P. (2011). Prevalence and characteristics of co- offending recruiters. Justice Quarterly, 28(2), 325–359.
Weinborn, C., Ariel, B., Sherman, L. W., & O'Dwyer, E. (2017). Hotspots vs. harmspots: Shifting the focus from counts to harm in the criminology of place. Applied Geography, 86, 226–244.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
The original version of this article was revised: Author affiliations were not assigned correctly in this article as originally published. The following shows the authors’ correct affiliations: Benedict Linton1,2 & Barak Ariel2,3 1 Metropolitan Police Service, University of Cambridge, London, UK 2 Institute of Criminology, University of Cambridge, Cambridge, UK 3 Institute of Criminology, Hebrew University, Jerusalem, Israel
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Linton, B., Ariel, B. Highest Harm Crime “Recruiters” in a London Borough: a Case of Moving Targets. Camb J Evid Based Polic 4, 260–273 (2020). https://doi.org/10.1007/s41887-020-00060-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41887-020-00060-1