
Abstract
Fuzzy inference systems have been commonly used for time series forecasting in the literature. Adaptive network fuzzy inference system, fuzzy time series approaches and fuzzy regression functions approaches are popular among fuzzy inference systems. In recent years, intuitionistic fuzzy sets have been preferred in the fuzzy modeling and new fuzzy inference systems have been proposed based on intuitionistic fuzzy sets. In this paper, a new intuitionistic fuzzy regression functions approach is proposed based on intuitionistic fuzzy sets for forecasting purpose. This new inference system is called an intuitionistic fuzzy time series functions approach. The contribution of the paper is proposing a new intuitionistic fuzzy inference system. To evaluate the performance of intuitionistic fuzzy time series functions, twenty-three real-world time series data sets are analyzed. The results obtained from the intuitionistic fuzzy time series functions approach are compared with some other methods according to a root mean square error and mean absolute percentage error criteria. The proposed method has superior forecasting performance among all methods.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Forecasting is very important for future planning in many technological areas. Forecasting techniques are attracted by managers and other decision-makers. Forecasting techniques can be based on probability theory, fuzzy set theory or computational techniques. Many of forecasting techniques use fuzzy sets in their algorithms. Fuzzy sets were proposed by Zadeh (1965). Chen (1996a, b) proposed a fuzzy reasoning approach. Chen (1998) proposed a fuzzy system for group decision-making. Bai and Chen (2008a, b) and proposed a method for creating automatically membership functions of fuzzy rules. Bai and Chen (2008a, b) proposed adaptive fuzzy system-based automatically determined concept maps. Fuzzy inference systems and fuzzy time series methods can be used for forecasting. Takagi and Sugeno (1985) system, adaptive network fuzzy inference system proposed by Jang (1993) and a fuzzy function approach proposed by Turksen (2008) are well-known fuzzy inference systems in the forecasting literature. Fuzzy time series methods are also popular methods in the forecasting literature. Song and Chissom (1993) were firstly defined fuzzy time series concept, and they proposed a fuzzy time series forecasting method. Chen and Wang (2010), Chen et al. (2012, 2013), Chen and Chen (2015), Chen and Phuong (2017) and Chen and Jian (2017) proposed forecasting methods based on fuzzy sets.
Recent years, many applications of classical fuzzy systems have been made in the literature. Zarandi et al. (2013) proposed a new fuzzy functions model tuned by hybridizing imperialist competitive algorithm and simulated annealing. Bezdek (2013) used fuzzy objective function algorithms for pattern recognition. Baykasoğlu and Maral (2014) proposed fuzzy functions approach via genetic programming. Baser and Apaydin (2015) proposed a hybrid fuzzy support vector regression analysis. Barak and Sadegh (2016) used ensemble ARIMA-ANFIS hybrid algorithm for forecasting of energy consumption. Goudarzi et al. (2016) proposed an interactively recurrent fuzzy function with multi-objective learning. Aladag et al. (2016) proposed a type 1 fuzzy time series function method based on binary particle swarm optimization. Tan et al. (2017) proposed a new adaptive network-based fuzzy inference system for forecasting. Yang et al. (2017) used linear fuzzy information granules and fuzzy inference system for long-term forecasting of time series. Son et al. (2017) proposed a new neuro-fuzzy inference system for insurance forecasting. Ranganayaki and Deepa (2017) proposed a support vector machine-based neuro-fuzzy model for short-term wing power forecasting. Tak et al. (2018) proposed a recurrent fuzzy function approach for forecasting. Pelka and Dudek (2018) proposed a neuro-fuzzy system for forecasting. Vanhoenshoven et al. (2018) proposed a fuzzy cognitive map employing ARIMA components for time series forecasting. Moreover, there are many fuzzy time series forecasting methods. The fuzzy time series concept was introduced by Song and Chissom (1993). Chen (1996a, b) proposed a fuzzy time series method based on fuzzy relation tables, and it constituted a base for many methods. In recent studies, Chen and Chang (2010), Chen and Chen (2011), Chen et al. (2012), Garg and Garg (2016), Singh (2016), Cagcag Yolcu et al. (2016), Kumar and Gangwar (2016), Kocak (2017), Bose and Mali (2018) and Chang and Yu (2019) proposed fuzzy time series methods. Wang (2018) used a fuzzy time series forecasting method for big data analysis. Bisht and Kumar (2019) used hesitant fuzzy sets based on the computational method for financial time series forecasting. Egrioglu et al. (2019) proposed a forecasting method for single-variable high-order intuitionistic fuzzy time series forecasting model. Gupta and Kumar (2019a) proposed a novel high-order fuzzy time series forecasting method based on probabilistic fuzzy sets. Gupta and Kumar (2019b) proposed a hesitant probabilistic fuzzy set-based time series forecasting method.
Recent years, intuitionistic (hesitant) fuzzy sets have been commonly used in fuzzy techniques. In a fuzzy set, there are membership values for each member of the universal set. Non-membership values can be obtained from membership values by using a simple subtract operation. Atanassov (1983) introduced an intuitionistic fuzzy set. In an intuitionistic fuzzy set, non-membership values have different information than membership values have. Besides, hesitation degrees are obtained from the simple mathematical operation of membership and non-membership values. Atanassov (1986) and Atanassov (1999) gave the details of the theory and some applications for intuitionistic fuzzy sets. Bustince et al. (1995), Cornelis and Deschrijver (2001), Szmidt and Kacprzyk (2001), Marinov and Atanassov (2005), Own (2009) and Davarzani and Khorheh (2013) applied intuitionistic fuzzy sets on different implementations. Moreover, Zheng et al. (2013), Kumar and Gangwar (2016), Wang et al. (2016), Bisht and Kumar (2016) and Fan et al. (2017) proposed intuitionistic fuzzy time series method in their studies. Chen and Chang (2016), Chen et al. (2016a, b) and Liu et al. (2017) applied intuitionistic fuzzy sets in their proposed methods.
Castillo et al. (2007) proposed an intuitionistic fuzzy system for time series analysis. Olej and Hájek (2010a) proposed an intuitionistic fuzzy inference system design for prediction of ozone time series. Olej and Hájek (2010b) showed the possibilities of air quality modeling based on intuitionistic fuzzy set theory. Olej and Hájek (2011) compared of fuzzy operators for intuitionistic fuzzy inference system of Takagi–Sugeno type. Hájek and Olej (2012) used adaptive intuitionistic fuzzy inference system of Takagi–Sugeno type for regression problems. The parameters of the intuitionistic fuzzy inference system are determined by using particle swarm optimization in Angelov (2012), Maciel et al. (2012) and Henzgen et al. (2014). Bas et al. (2019) proposed a type 1 fuzzy function method based on ridge regression for forecasting. Kizilaslan et al. (2019) and Cagcag Yolcu et al. (2019) proposed intuitionistic fuzzy function approaches. Egrioglu et al.(2020) proposed picture fuzzy regression functions method based on picture fuzzy clustering.
The motivation of this paper is explained in the following sentences. Fuzzy inference systems are efficient tools for forecasting purposes. It is possible to create new fuzzy inference systems for obtaining more accurate forecasts. Especially, the intuitionistic fuzzy inference system is needed to improve by using different updated techniques. Because intuitionistic fuzzy inference systems employee non-membership values, they can give more accurate forecast results than classical fuzzy inference systems.
The main contribution of this paper can be expressed as proposing a new intuitionistic fuzzy inference system. In this new system, membership values and non-membership values in intuitionistic fuzzy sets and their nonlinear transformations are used as inputs. Thus, the dimension of the input matrix in type 1 fuzzy function approach is augmented by using non-membership values in intuitionistic fuzzy sets. In the new approach, the membership and non-membership values are obtained from intuitionistic fuzzy c-means as in Chaira (2011). The proposed intuitionistic systems do not need to determine the combination parameter of a dual system which are separately designed according to membership and non-membership. In the second section, the proposed method is summarized. The applications for real data sets are given in the third section. In the last section, conclusions and discussions are given.
2 Intuitionistic fuzzy time series functions approach
In the literature, many of fuzzy inference methods have been proposed. The fuzzy functions approach proposed by Turksen (2008) is fairly different from others because it does not have a rule base and it can use directly linear regression models. Although the fuzzy functions approach uses just fuzzy sets, it does not use intuitionistic fuzzy sets. In the fuzzy functions approach, Turksen (2008) showed that the augmentation of the input matrix’s elements by using nonlinear transformations of membership values can drastically improve prediction performance. In this paper, an intuitionistic fuzzy time series functions approach is proposed. In this approach, the input matrix contains nonlinear transformations of non-membership values as well as membership values. The proposed method is based on the ordinary least square estimation instead of ridge regression like in Kizilaslan et al. (2019). The proposed methods use membership and membership values in the same input matrices apart from Cagcag Yolcu et al. (2019). The proposed approach has the following advantages:
-
The proposed approach employs intuitionistic fuzzy c-means clustering. Creation of intuitionistic fuzzy sets is more realistic than creation fuzzy sets because of using hesitation margin.
-
The input matrix has a higher dimension in the proposed approach so that it uses more information compared with other fuzzy functions approaches.
-
The proposed approach has superior forecasting performance in many real-world time series applications.
-
The proposed intuitionistic systems do not need to determine the combination parameter of a dual system which are separately designed according to membership and non-membership.
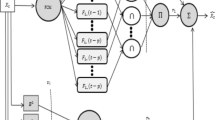
The proposes step-by-step algorithm for intuitionistic fuzzy time series functions algorithm is shown as follows, where its flowchart is given in Fig. 1.

Flowchart for the IFTSF approach
Algorithm 1. Intuitionistic Fuzzy Time Series Functions (IFTSF) Algorithm
-
Step 1 Parameters of the method are determined.
-
Parameters are the number of intuitionistic fuzzy clusters (cn), and inputs of the system are the number of lagged variables (p), hesitation margin \((\pi )\), alpha cut (\(\alpha - cut\)) and the length of the test set (ntest).
-
Step 2 Clustering the data.
-
The input and targets are constituted \(IO\) matrix. Intuitionistic fuzzy c-means clustering algorithm proposed by Chaira (2011) is used to obtain memberships and non-memberships.
$$IO = \left[ {\begin{array}{*{20}c} {x_{1} } & {x_{2} } & \cdots & {x_{p} } & {x_{p + 1} } \\ {x_{2} } & {x_{3} } & \cdots & {x_{p + 1} } & {x_{p + 2} } \\ . & . & \cdots & . & . \\ . & . & \cdots & . & . \\ . & . & \cdots & . & . \\ {x_{n - p} } & {x_{n - p + 1} } & \cdots & {x_{n - 1} } & {x_{n} } \\ \end{array} } \right]$$(1) -
The last element of cluster centers is excluded, and reduced cluster centers are obtained. Intuitionistic membership values \((\mu_{A} (x))\) and non-membership values \((\vartheta_{A} (x))\) are calculated according to reduced cluster centers. If the \(\mu_{A} \left( x \right) < \alpha - cut\), then \(\mu_{A} \left( x \right) = 0\). Similarly, if the \(\vartheta_{A} \left( x \right) < \alpha - cut\) then \(\vartheta_{A} \left( x \right) = 0\). After applying \(\alpha - cut\) operation, normalization applied to membership and non-membership values is shown \(u_{ij}\) and \(\mu_{ij}\).
-
Step 3 Fuzzy regression functions are obtained by using the least square method. The parameters of linear functions are estimated. Let \(n\) be the length of training time series data.
$$Input^{\left( i \right)} = \left[ {\begin{array}{*{20}c} 1 & {u_{i1} } & {u_{i1}^{2} } & {\exp (u_{i1} )} & {\mu_{i1} } & {\mu_{i1}^{2} } & {\exp (\mu_{i1}^{2} )} & {x_{1} } & {x_{2} } & \cdots & {x_{p} } \\ 1 & {u_{i2} } & {u_{i2}^{2} } & {\exp (u_{i2} )} & {\mu_{i2} } & {\mu_{i2}^{2} } & {\exp (\mu_{i2}^{2} )} & {x_{2} } & {x_{3} } & \cdots & {x_{p + 1} } \\ . & . & . & . & . & . & . & . & . & \cdots & . \\ . & . & . & . & . & . & . & . & . & \cdots & . \\ . & . & . & . & . & . & . & . & . & \cdots & . \\ 1 & {u_{in} } & {u_{in}^{2} } & {\exp (u_{in} )} & {\mu_{in} } & {\mu_{in}^{2} } & {\exp (\mu_{in}^{2} )} & {x_{n - p} } & {x_{n - p + 1} } & \cdots & {x_{n - 1} } \\ \end{array} } \right]$$(2)$$Target^{{\left( i \right){\prime }}} = \left[ {\begin{array}{*{20}c} {x_{p + 1} } & {x_{p + 2} } & \cdots & {x_{n} } \\ \end{array} } \right]$$(3)$$\hat{\theta }^{\left( i \right)} = ( Input^{{\left( i \right){\prime }}} Input^{\left( i \right)} )^{ - 1} Input^{{\left( i \right){\prime }}} Target^{\left( i \right)}$$(4) -
Step 4 Predictions are obtained for training data. Predictions for the training set are obtained by using Eq. (7) by combining outputs of linear functions.
$$\widehat{Output}_{j}^{\left( 1 \right)} = \frac{{\mathop \sum \nolimits_{i = 1}^{c} u_{ij} Input^{\left( i \right)} \hat{\theta }^{\left( i \right)} }}{{\mathop \sum \nolimits_{i = 1}^{c} u_{ij} }}\quad j = 1,2, \ldots ,n$$(5)$$\widehat{Output}_{j}^{\left( 2 \right)} = \frac{{\mathop \sum \nolimits_{i = 1}^{c} \mu_{ij} Input^{\left( i \right)} \hat{\theta }^{\left( i \right)} }}{{\mathop \sum \nolimits_{i = 1}^{c} \mu_{ij} }}\quad j = 1,2, \ldots ,n$$(6)$$\widehat{Output}_{j}^{\text{IFTSF}} = \pi \widehat{Output}_{j}^{\left( 1 \right)} + \left( {1 - \pi } \right)\widehat{Output}_{j}^{\left( 2 \right)}$$(7) -
\(\widehat{Output}_{j}^{\text{IFTSF}}\) is the prediction of intuitionistic fuzzy time series function (IFTSF) method for jth observation.
-
Step 5 Forecasts are obtained for test sets.
-
The design matrix \((Itest^{\left( i \right)} )\) is constituted for each intuitionistic fuzzy cluster and test set. The test set forecasts \((\widehat{Yt}^{\left( i \right)} )\) of each intuitionistic fuzzy regression functions are computed as follows.
$$Itest^{\left( i \right)} = \left[ {\begin{array}{*{20}c} 1 & {u_{i,n + 1} } & {u_{i,n + 1}^{2} } & {\exp (u_{i,n + 1} )} & {\mu_{i,n + 1} } & {\mu_{i,n + 1}^{2} } & {\exp (\mu_{i,n + 1}^{2} )} & {x_{n - p + 1} } & {x_{n - p + 2} } & \cdots & {x_{n} } \\ 1 & {u_{i,n + 2} } & {u_{i,n + 1}^{2} } & {\exp (u_{i,n + 2} )} & {\mu_{i,n + 2} } & {\mu_{i,n + 2}^{2} } & {\exp (\mu_{i,n + 2}^{2} )} & {x_{n - p + 2} } & {x_{n - p + 3} } & \cdots & {x_{n + 1} } \\ . & . & . & . & . & . & . & . & . & \cdots & . \\ . & . & . & . & . & . & . & . & . & \cdots & . \\ . & . & . & . & . & . & . & . & . & \cdots & . \\ 1 & {u_{i,n + ntest} } & {u_{i,n + ntest}^{2} } & {\exp (u_{i,n + ntest} )} & {\mu_{i,n + ntest} } & {\mu_{i,n + ntest}^{2} } & {\exp (\mu_{i,n + ntest}^{2} )} & {x_{n - p + ntest} } & {x_{n - p + ntest + 1} } & \cdots & {x_{n + ntest - 1} } \\ \end{array} } \right]$$(8)$$\widehat{Otest}_{j}^{\left( 1 \right)} = \frac{{\mathop \sum \nolimits_{i = 1}^{c} u_{ij} Itest^{\left( i \right)} \hat{\beta }^{\left( i \right)} }}{{\mathop \sum \nolimits_{i = 1}^{c} u_{ij} }}\quad j = n + 1,n + 2, \ldots ,n + ntest$$(9)$$\widehat{Otest}_{j}^{\left( 2 \right)} = \frac{{\mathop \sum \nolimits_{i = 1}^{c} \mu_{ij} Itest^{\left( i \right)} \hat{\beta }^{\left( i \right)} }}{{\mathop \sum \nolimits_{i = 1}^{c} \mu_{ij} }}\quad j = n + 1,n + 2, \ldots ,n + ntest$$(10)$$\widehat{Output}_{j}^{\text{IFTSF}} = \pi \widehat{Otest}_{j}^{\left( 1 \right)} + \left( {1 - \pi } \right)\widehat{Otest}_{j}^{\left( 2 \right)} \quad j = n + 1,n + 2, \ldots ,n + ntest$$(11) -
where \(u_{ij}\) and \(\mu_{ij}\) membership and non-membership values are computed by using reduced cluster centers which are obtained in Step 2.
3 Applications
The forecasting performance of the proposed method is investigated by using some real-world time series data sets. The list of time series and their features are given in Table 1. The first data set is daily BIST 100 (Borsa Istanbul 100) index computed for Istanbul Stock Exchange between the years 2009 and 2013 as totally five data sets. The time series were taken from the Turkish Central Bank official Web site. The second data set is the Taiwan Stock Exchange Capitalization Weighted Stock Index (TAIEX) data observed daily between the years 1999 and 2004. The TAIEX data sets were taken from Sarica et al. (2018). The third data set is daily Dow-Jones Industrial Average index between the years 2010 and 2014 as totally five time series. The first three data sets are stock exchange data sets. The last data are Turkey Electricity Consumption (TEC) data observed monthly between the first month of 2002 and last month of 2013. TEC data set was taken from Turkey Energy Ministry.
The parameters of the proposed method (p, cn and ntest) are used like in Table 1 for the analysis of all data sets. Firstly, BIST100 data set is analyzed by using ARIMA (Box and Jenkins 1976), ANFIS (Jang 1993) and modified ANFIS (MANFIS) proposed by Egrioglu et al. (2014), fuzzy time series method (SC) proposed by Song and Chissom (1993), AR-ANFIS proposed by Sarica et al. (2018), type 1 fuzzy function (T1FF) proposed by Turksen (2008) and the proposed method in this paper (IFTSF). The root of mean square error (RMSE) and mean absolute percentage error (MAPE) values for test sets of BIST100 are given in Tables 2 and 3, respectively.
In Eqs. 12 and 13, \(y_{t}\) and \(\hat{y}_{t}\) are real observations and predicted values, respectively.
The proposed method produces the best forecasts for 50% of all results in BIST100 data set applications according to RMSE value. The similar results are obtained according to the MAPE criterion. Moreover, the proposed method produces the minimum mean of RMSE and MAPE values in Tables 2 and 3 when the proposed method is compared with other methods. When the length of the test set is 7, the success rate of the proposed method is 60%. For the length of the test set 15, the success rate of the proposed method is 40%. As a result of the analysis, IFTSF method can produce better forecasts for a small test set of BIST100 data set. The proposed method produces the competitive results for long test set lengths.
The analyzed results of the TAIEX data set are given in Table 4. In Table 4, it is seen that the proposed method has 83.33% succeeds of all results in TAIEX data set according to RMSE value. Besides this superior succeed performance, the proposed method is the best method for mean statistics of RMSE values among all other analytical methods for TAIEX data set.
Dow Jones data set is analyzed by ANFIS with the grid partition method (ANFISgrid), ANFIS with subtractive clustering (ANFISsub), MANFIS, T1FF and IFTSF. The results of the analysis for Dow Jones data set are given in Tables 5 and 6. The success rate of the IFTSF is 80% according to RMSE criterion, and it is 60% for MAPE criterion. For mean statistics, the proposed method is the best one according to both RMSE and MAPE criteria.
In the final application, the analyze results of TEC data are given in Table 7. TEC data are analyzed by multilayer perceptron artificial neural network (MLP-ANN), seasonal autoregressive integrated moving average model (SARIMA; Box–Jenkins 1976), single multiplicative neuron model artificial neural network (SMNM-ANN) proposed by Yadav et al. (2007), linear and nonlinear neural network introduced by Yolcu et al. (2013) and TIFF and IFTSF methods.
It is clearly seen that the proposed method has superior forecasting performance for both RMSE and MAPE criteria. Besides, the graph of real observations and forecasted values is given in Fig. 2.

Graph of real observations and proposed method forecasts for TEC data
The best parameter sets in IFTSF method for all analyzed time series are given in Table 8. An important remark in Table 8 is that while the number of clusters is generally obtained as 7, there is no a certain value for the number of lags that means the best results obtained in the different numbers of lags for the BIST 100. Moreover, there are no certain parameter values in other time series.
4 Conclusion
The main contribution of this paper can be stated that an intuitionistic fuzzy time series functions approach is proposed. The proposed method inspired by T1FF is an improved modification of T1FF with the use of hesitation margins and non-membership values. Non-memberships have different information to determine time series relations from membership values, unlike T1FF approach. The new inference system takes into consideration hesitation values, and it has an additional approach to uncertainty like type 2 fuzzy systems. Because of using second-order uncertainty, the system can define better relations between lagged variables of time series. In IFTSF, input matrix contains non-memberships and their transformations as well as lagged variables, memberships and transformations of memberships. Augmentation of the input matrix provides extra information to the inference mechanism.
The proposed method is compared with some well-known fuzzy inference, fuzzy time series methods, artificial neural networks and classical time series methods. According to analyzing results, it is clearly seen that IFTSF can produce better forecasting results than others for almost all of the time series. Moreover, it can be generally said that the proposed IFTSF has better forecasting performance for short-term or small test sets.
In future studies, the proposed method can be adapted to be working in a dual structure for memberships and non-memberships like other intuitionistic fuzzy inference systems. Input selection can be made by using artificial intelligence optimization techniques. Moreover, the fuzzy functions can be obtained by using artificial neural networks instead of the linear model.
References
Aladag CH, Yolcu U, Egrioglu E, Turksen IB (2016) Type-1 fuzzy time series function method based on binary particle swarm optimization. Int J Data Anal Tech Strateg 8(1):2–13
Angelov P (2012) Evolving fuzzy systems. Computational complexity: theory, techniques, and applications. Springer, Berlin
Atanassov K (1983) Intuitionistic fuzzy sets. In: Proceedings of VII ITKR’s Session. Sofia, Bulgaria, pp 1684–1697
Atanassov K (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20:87–96
Atanassov K (1999) Intuitionistic fuzzy sets: theory and applications. Physica-Verlag, Heidelberg
Bai S-M, Chen S-M (2008a) Automatically constructing grade membership functions of fuzzy rules for students’ evaluation. Expert Syst Appl 35(3):1408–1414
Bai S-M, Chen S-M (2008b) Automatically constructing concept maps based on fuzzy rules for adapting learning systems. Expert Syst Appl 35(1–2):41–49
Barak S, Sadegh SS (2016) Forecasting energy consumption using ensemble ARIMA-ANFIS hybrid algorithm. Int J Electr Power Energy Syst 82:92–104
Bas E, Egrioglu E, Yolcu U, Grosan C (2019) Type 1 fuzzy function approach based on ridge regression for forecasting. Granul Comput 4(4):629–637
Baser F, Apaydin A (2015) Hybrid fuzzy support vector regression analysis. J Intell Fuzzy Syst 28(5):2037–2045
Baykasoğlu A, Maral S (2014) Fuzzy functions via genetic programming. J Intell Fuzzy Syst 27(5):2355–2364
Bezdek C (2013) Pattern recognition with fuzzy objective function algorithms. Springer, Berlin
Bisht K, Kumar S (2016) Fuzzy time series forecasting method based on hesitant fuzzy sets. Expert Syst Appl 64:557–568
Bisht K, Kumar S (2019) Hesitant fuzzy set based computational method for financial time series forecasting. Granul Comput 4:655–669
Bose M, Mali K (2018) A novel data partitioning and rule selection technique for modelling high-order fuzzy time series. Appl Soft Comput J 63:87–96
Box GEP, Jenkins GM (1976) Time series analysis: forecasting and control. Holdan-Day, San Francisco
Bustince H, Burillo P, Mohedano V (1995) A method for inference in approximate reasoning based on normal intuitionistic fuzzy sets. Notes Intuit Fuzzy Sets 1(1):51–55
Cagcag Yolcu O, Yolcu U, Egrioglu E, Aladag CH (2016) High order fuzzy time series forecasting method based on an intersection operation. Appl Math Model 40(19–20):8750–8765
Cagcag Yolcu O, Bas E, Egrioglu E, Yolcu U (2019) A new intuitionistic fuzzy functions approach based on hesitation margin for time-series prediction. Soft Comput. https://doi.org/10.1007/s00500-019-04432-2
Castillo O, Alanis A, Garcia M, Arias H (2007) An intuitionistic fuzzy system for time series analysis in plant monitoring and diagnosis. Appl Soft Comput 7(4):1227–1233
Chaira T (2011) A novel intuitionistic fuzzy C means clustering algorithm and its application to medical images. Appl Soft Comput 11:1711–1717
Chang J, Yu P (2019) Weighted-fuzzy-relations time series for forecasting information technology maintenance cost. Granul Comput 4:687–697
Chen SM (1996a) Forecasting enrollments based on fuzzy time-series. Fuzzy Sets Syst 81:311–319
Chen S-M (1996b) A fuzzy reasoning approach for rule-based systems based on fuzzy logics. IEEE Trans Syst Man Cybern Part B (Cybern) 26(5):769–778
Chen S-M (1998) Aggregating fuzzy opinions in the group decision-making environment. Cybern Syst 29(4):363–376
Chen SM, Chang YC (2010) Multi-variable fuzzy forecasting based on fuzzy clustering and fuzzy rule interpolation techniques. Inf Sci 180(24):4772–4783
Chen S-M, Chang C-H (2016) Fuzzy multi attribute decision making based on transformation techniques of intuitionistic fuzzy values and intuitionistic fuzzy geometric averaging operators. Inf Sci 352–353:133–149
Chen SM, Chen CD (2011) TAIEX forecasting based on fuzzy time series and fuzzy variation groups. IEEE Trans Fuzzy Syst 19(1):1–12
Chen S, Chen S (2015) Fuzzy forecasting based on two-factors second-order fuzzy-trend logical relationship groups and the probabilities of trends of fuzzy logical relationships. IEEE Trans Cybern 45(3):391–403
Chen S-M, Jian W-S (2017) Fuzzy forecasting based on two-factors second-order fuzzy-trend logical relationship groups, similarity measures and PSO techniques. Inf Sci 391–392:65–79
Chen S-M, Phuong BDH (2017) Fuzzy time series forecasting based on optimal partitions of intervals and optimal weighting vectors. Knowl Based Syst 118:204–216
Chen S, Wang N (2010) Fuzzy forecasting based on fuzzy-trend logical relationship groups. IEEE Trans Syst Man Cybern Part B (Cybern) 40(5):1343–1358
Chen S, Chu H, Sheu T (2012) TAIEX forecasting using fuzzy time series and automatically generated weights of multiple factors. IEEE Trans Syst Man Cybern Part A Syst Hum 42(6):1485–1495
Chen S-M, Manalu GMT, Pan J-S, Liu H-C (2013) Fuzzy forecasting based on two-factors second-order fuzzy-trend logical relationship groups and particle swarm optimization techniques. IEEE Trans Cybern 43(3):1102–1117
Chen S-M, Cheng S-H, Lan T-C (2016a) A novel similarity measure between intuitionistic fuzzy sets based on the centroid points of transformed fuzzy numbers with applications to pattern recognition. Inf Sci 343–344:15–40
Chen S-M, Cheng S-H, Lan T-C (2016b) Multicriteria decision making based on the TOPSIS method and similarity measures between intuitionistic fuzzy values. Inf Sci 367–368:279–295
Cornelis C, Deschrijver G (2001) The compositional rule of inference in an intuitionistic fuzzy logic setting. In: Proceedimg of ESSLLI, pp 83–94
Davarzani H, Khorheh MA (2013) A novel application of intuitionistic fuzzy sets theory in medical science: Bacillus colonies recognition. Artif Intell Res 2(2):1–17
Egrioglu E, Aladag CH, Yolcu U, Bas E (2014) A new adaptive network-based fuzzy inference system for time series forecasting. Aloy J Soft Comput Appl 2(1):25–32
Egrioglu E, Yolcu U, Bas E (2019) Intuitionistic high-order fuzzy time series forecasting method based on pi-sigma artificial neural networks trained by artificial bee colony. Granul Comput 4(4):639–654
Egrioglu E, Bas E, Yolcu U, Chen M-Y (2020) Picture fuzzy time series: defining, modelling and creating a new forecasting method. Eng Appl Artif Intell. https://doi.org/10.1016/j.engappai.2019.103367
Fan X, Lei Y, Wang Y (2017) Adaptive partition intuitionistic fuzzy time series forecasting model. J Syst Eng Electron 28(3):585–596
Garg B, Garg R (2016) Enhanced accuracy of fuzzy time series model using ordered weighted aggregation. Appl Soft Comput 48:265–280
Goudarzi S, Khodabakhshi MB, Moradi MH (2016) Interactively recurrent fuzzy functions with multi-objective learning and its application to chaotic time series prediction. J Intell Fuzzy Syst 30(2):1157–1168
Gupta KK, Kumar S (2019) A novel high-order fuzzy time series forecasting method based on probabilistic fuzzy sets. Granul Comput 4:699–713
Hájek P, Olej V (2012) Adaptive intuitionistic fuzzy inference systems of Takagi–Sugeno type for regression problems. In: Artificial intelligence applications and innovations, part I, L.S. Springer, pp 206–216
Henzgen S, Strickert M, Hüllermeier E (2014) Visualization of evolving fuzzy rule-based systems. Evol Syst 5(3):175–191
Jang JS (1993) ANFIS: adaptive network based fuzzy inference systems. IEEE Trans Syst Man Cybern 23:665–685
Kizilaslan B, Egrioglu E, Evren AA (2019) Intuitionistic fuzzy ridge regression functions. Commun Stat Simul Comput. https://doi.org/10.1080/03610918.2019.1626887
Kocak C (2017) ARMA(p, q) type high order fuzzy time series forecast method based on fuzzy logic relations. Appl Soft Comput 58:92–103
Kumar S, Gangwar SS (2016) Intuitionistic fuzzy time series: an approach for handling nondeterminism in time series forecasting. IEEE Trans Fuzzy Syst 24(6):1270–1281
Liu P, Chen S-M, Liu J (2017) Multiple attribute group decision making based on intuitionistic fuzzy interaction partitioned Bonferroni mean operators. Inf Sci 411:98–121
Maciel L, Lemos A, Gomide F, Ballini R (2012) Evolving fuzzy systems for pricing fixed income options. Evol Syst 3(1):5–18
Marinov M, Atanassov K (2005) A method and electronic circuit for intuitionistic fuzzy inference. Notes Intuit Fuzzy Sets 11(1):28–32
Olej V, Hájek P (2010) IF-inference systems design for prediction of ozone time series: the case of Pardubice micro-region. In: Diamantaras K, Duch W, Iliadis LS (eds) ICANN 2010, part I. LNCS, vol 6352. Springer, Heidelberg, pp 1–11
Olej V, Hájek P (2010b) Possibilities of air quality modelling based on IF-sets theory. In: Mastorakis N, Demiralp N, Mladenov M (eds) Computers and simulation in modern science. Selected papers from WSEAS conferences. WSEAS Press, pp 90–100
Olej V, Hájek P (2011) Comparison of fuzzy operators for if-inference systems of Takagi–Sugeno type in ozone prediction. In: Iliadis L, Maglogiannis I, Papadopoulos H (eds) EANN/AIAI 2011, part II. IFIP AICT, vol 364. Springer, Heidelberg, pp 92–97
Own CM (2009) Switching between type-2 fuzzy sets and intuitionistic fuzzy sets: an application in medical diagnosis. Appl Intell 31(3):283–291
Pełka P, Dudek G (2018) Neuro-fuzzy system for medium-term electric energy demand forecasting. Adv Intell Syst Comput 655:38–47
Ranganayaki V, Deepa SN (2017) SVM based neuro-fuzzy model for short term wind power forecasting. Natl Acad Sci Lett 40(2):131–134
Rumelhart DE, Geoffrey EH, Williams RJ (1986) Learning internal representations by error propagation. In: Rumelhart DE, McClelland JL, PDP research group (eds) Parallel distributed processing: explorations in the microstructure of cognition. Foundation, vol 1. MIT Press, Cambridge
Sarıca B, Egrioglu E, Aşıkgil B (2018) A new hybrid method for time series forecasting: AR–ANFIS. Neural Comput Appl 29:749–760
Singh P (2016) An efficient method for forecasting using fuzzy time series. Emerging research on applied fuzzy sets and intuitionistic fuzzy matrices, pp 287–304
Son LH, Khuong MN, Tuan TM (2017) A new neuro-fuzzy inference system for insurance forecasting. Adv Intell Syst Comput 538:63–72
Song Q, Chissom BS (1993) Forecasting enrollments with fuzzy time series—part I. Fuzzy Sets Syst 54:1–10
Szmidt E, Kacprzyk J (2001) Intuitionistic fuzzy sets in some medical applications in computational intelligence. Theory and applications. Springer, Berlin, pp 148–151
Tak N, Evren AA, Tez M, Egrioglu E (2018) Recurrent type-1 fuzzy functions approach for time series forecasting. Appl Intell 48:68–77
Takagi T, Sugeno M (1985) Fuzzy identification of systems and its applications to modelling and control. IEEE Trans Syst Man Cybern 15(1):116–132
Tan L, Wang S, Wang K (2017) A new adaptive network-based fuzzy inference system with adaptive adjustment rules for stock market volatility forecasting. Inf Process Lett 127:32–36
Turksen IB (2008) Fuzzy function with LSE. Appl Soft Comput 8:1178–1188
Vanhoenshoven F, Nápoles G, Bielen S, Vanhoof K (2018) Fuzzy cognitive maps employing ARIMA components for time series forecasting. Smart Innov Syst Technol 72:255–264
Wang W (2018) A big data framework for stock price forecasting using fuzzy time series. Multimed Tools Appl 77:10123–10134
Wang Y, Lei Y, Lei Y, Fan X (2016) Multi-factor high-order intuitionistic fuzzy time series forecasting model. J Syst Eng Electron 27(5):1054–1062
Yadav RN, Kalra PK, John J (2007) Time series prediction with a single multiplicative neuron model. Appl Soft Comput 7:1157–1163
Yang X, Yu F, Pedrycz W (2017) Long-term forecasting of time series based on linear fuzzy information granules and fuzzy inference system. Int J Approx Reason 81:1–27
Yolcu U, Aladag CH, Egrioglu E (2013) A new linear & nonlinear artificial neural network model for time series forecasting. Decis Support Syst J 54:1340–1347
Zadeh LA (1965) Fuzzy sets. Inf Control 8:338–353
Zarandi MHF, Zarinbal M, Ghanbari N, Turksen IB (2013) A new fuzzy functions model tuned by hybridizing imperialist competitive algorithm and simulated annealing. application: stock price prediction. Inf Sci 222:213–228
Zheng KQ, Lei YJ, Wang R, Wang YF (2013) Modeling and application of IFTS. Control Decis 28(10):1525–1530
Acknowledgements
This study is partly supported by “The Scientific and Technological Research Council of Turkey” with Award Number: 1059B191800872, Recipient: Erol Egrioglu.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bas, E., Yolcu, U. & Egrioglu, E. Intuitionistic fuzzy time series functions approach for time series forecasting. Granul. Comput. 6, 619–629 (2021). https://doi.org/10.1007/s41066-020-00220-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41066-020-00220-8