
Abstract
In the cloud computing environment, the privacy of the electronic data is a serious issue that requires special considerations. We have presented a state-of-the-art review of the methodologies and approaches that are currently being used to cope with the significant issue of privacy. We have categorized the privacy-preserving approaches into four categories, i.e., privacy by cryptography, privacy by probability, privacy by anonymization and privacy by ranking. Moreover, we have developed taxonomy of the techniques that have been used to preserve the privacy of the governing data. We also presented a comprehensive comparison of the privacy-preserving approaches from the angle of the privacy-preserving requirements’ satisfaction. Therefore, it is highly desirable that the mechanisms should be developed to deploy efficient auditing and accountability mechanisms that anonymously monitor the utilization of data records and track the provenance to ensure the confidentiality of the data.
Similar content being viewed by others


Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
1 Introduction
In simple terms “the cloud” can be foreseen as a metaphor for the internet which is quite familiar cliché, but when it is combined to the term “computing,” its meaning gets bigger and hazy. Cloud computing proposes the opportunity to organizations that would merely connect to the cloud and use the available resources on a Pay Per use basis that avoids the company’s capital expenditure on supplementary of premises infrastructure resources. It promptly scales up and scales down rendering to business requirements. It consists of cloud client, services, application platform, storage and infrastructure measured services. Thus, the cloud computing is highly automated utility-based paradigm shift comprises of efficient and optimized framework that includes virtual desktops, servers and allocates services for computer network over the internet suggesting software applications and platform for easy and agile deployment of the secure data management.
The technology provides broad network access using resource pooling, on demand self-service with rapid elasticity. It results in continuous high availability, interoperability and standardized scalability for the hardware and software components providing data secrecy and ease for capital investment. Cloud storage is a system that allows users to store their sensitive and personal data in a secure way, making them able to access their data anywhere, at any time from any of the authorized devices. The cloud storage is usually dynamic in nature as it permits controlling the accessibility of the data by deleting/adding new users and devices. This idea is pursued to safeguard the users’ important data, where cloud storage plays the role of an access control. Veracity depicts that the data are encrypted, but in many cases cloud servers has the decryption key and manages the rights for user accessibility. It is sensed as a critical problem in the case of private sensitive data records, such as administrative documents (e.g., bills or pay sheets, ID cards) [1]. Also, increasing amount of storage and computing requirements of users is outsourced to remote, but generally are not necessarily trusted servers. These blow off several privacy issues regarding accessing data on such servers that can be defined as: sensitivity of (a) keywords sent in queries and (b) the retrieved data; both need to be hidden [2]. Hence, the security and privacy are entitled to be the most important issues. Particularly, the necessity and importance of privacy-preserving search techniques are still more pronounced in the cloud applications. The fact behind is the large companies that operate public clouds like Amazon Elastic Compute Cloud, Google Cloud Platform or Microsoft Live Mesh may access sensitive data such as access and search patterns. Also, hiding the query and the retrieved data has importance to ensure security and privacy for those using cloud services. Also, our research is based upon identifying privacy protection mechanisms processed over cloud standards, SaaS and DaaS, i.e., Software as a Service and Data as a Service, respectively, see Fig. 1. [There are mainly five standards represented by XaaS (“X” as a Service) where “X” can be varied, i.e., SaaS, PaaS, EaaS, DaaS, IaaS, depicted as Software, Platform, Education, Data and Infrastructure as a Service, respectively]. Furthermore, data are usually tackled by leveraging existing encryption cryptographic methods, such that only outsourced data are encrypted and are inaccessible by cloud servers that enable to protect the confidentiality of the data. These methods limit the flexibility of data retrieval and prevent the ciphertext holder from gaining access to the knowledge of the data [3].

Generalized view of privacy in the cloud
In [4] it is claimed that storing huge volumes of data records in third-party cloud is susceptible to leakage, loss or theft. Traditional network security and privacy mechanisms are not quite sufficient for data storage and outsourcing. Thus, integrity and confidentiality of the stored data records are initiated as one of the major challenges elevated by external storages.
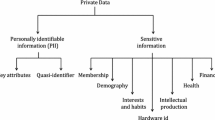
On the basis of Fig. 1, we can generalize the major factors responsible for comparing various approaches proposed to preserve privacy in the cloud. Conventionally, general privacy protection technologies are classified into three major categories, i.e., privacy by policy, privacy by statistical analysis, privacy by cryptography [4], but our study find that various architectural models should be divided into two major fields, i.e., cryptographic and non-cryptographic approaches. These are further segregated into subfields that can be referred from Fig. 2. Xiao et al. and Takabi et al. give overview about existing privacy and security issues in a cloud environment using contemporary privacy measures. Now, we are presenting a taxonomy of the approaches that have been used for preserving data privacy in the cloud.

Data privacy-preserving approaches
2 Preliminaries
2.1 Basic Hybrid Architecture for Data Utilization
As shown in Fig. 3, there are four entities defined as the foundation for each following comparative system approaches, that is, data users/owners, attribute authority, public cloud and private cloud.

Architecture for data utilization in cloud computing, including attack-prone areas
2.1.1 Attribute authority
It represents the key authority for attributes. Usually, it is in authority for generating private and public parameters for the system. Additionally, it is in charge of revoking, issuing and updating attribute private keys for various users.
2.1.2 Public cloud
This entity is responsible for a data outsourcing service. It assists in controlling the access from outside users to the stored data. It also works for the storage servers and providing corresponding content services via honestly executing the planned searching algorithm. In some cases, it is assumed that the public cloud is always online and has abundant computation power and storage capacity.
2.1.3 Data owners
This user node owns data files and bids to outsource them to the external storage server (i.e., the public or private cloud). It is responsible for enforcing and defining an access policy on its own files by encrypting them. Besides, the data owner also wants to delegate/finish the task of generating some searchable information for encrypted files in order to make efficient utilization of the outsourced encrypted data files.
2.1.4 Data users
This entity is the one who wishes to access an outsourced file. Such users are able to delegate the task of generating “trapdoors” for searching keywords. For example, on receiving searching results, if the user is initially authorized to embed in the encrypted file but later, mistakenly it is not revoked, such user will be able to decrypt the ciphertext and retrieve the file.
2.1.5 Private cloud
This entity facilitates a user’s secure usage of a cloud service. Specifically, the computing resources at the data user/owner side are restricted and the public cloud is less trusted in practice. A private cloud is capable to provide a data owner/user with an execution environment and infrastructure working as an interface between the public cloud and user. The interface offered by the private cloud allows users for submitting files and queries to be securely stored and computed, respectively.
Notice that Fig. 3 represents a novel architecture for the data utilization in cloud computing, which consists of the public cloud and a private cloud (i.e., twin cloud). Recently, such hybrid cloud setting has attracted lots of attention. On the other hand, the trusted private cloud could be a cluster of virtualized cryptographic co-processors. These might be offered as a service by a third party and offer the necessary hardware-based security types to implement a remote execution surroundings for privacy preserving by the users.
2.2 Adversary Model
Typically, it is assumed that the private cloud and public cloud are both “honest-but-curious” [5].
Precisely following approaches will follow the protocol, but try to find out as much secret information as possible based on their possessions that would help us detect the efficient approach. Fortunately, users would try to access data either within or out of the scope of their authorization. As foundation, one may assume that both keywords and files are sensitive. In this review paper, we suppose that all the files are sensitive and need to be fully protected against cloud environment, while keywords are semi-sensitive or quasi, and allowed to be known by the private cloud.
3 Cryptography-Oriented Privacy Measures
The cloud storage preserves data as if it is stacked in a locker, where the cloud storage acts the role of an access control to this locker. In reality, the data are encrypted, but usually the cloud server has the decryption key which manages the rights for each user to access the data. This is a critical problem in the case of private sensitive data such as administrative documents (e.g., bills, pay sheets or identity cards,) or, more generally, personal data. This is quite tricky in the case of confidential documents possessed by a business enterprise, i.e., shared between the collaborators or with trading partners. In fact, this problem can be effortlessly solved by merely encrypting the data before sending it to the cloud/safe. Different architectures were proposed to resolve this problem which work over two policies Trust-evaluation and predicate encryption, explained as follows.
3.1 Trust-evaluation/Authorized Encryption
The policy imposes to build users’ trust in the evaluation of reliable systems, especially against market-accepted criteria. In concern to user trust, a contract dealing with the use of a key management system should point out the jurisdiction whose laws relate to that system.
3.1.1 Using Fine-Grain Management of the Rights
An advanced cryptographic tool called as “proxy re-encryption” scheme is used in [1]. Taking it as foundation, Canard et al. modified this scheme in a way that customers could manage their shared documents dynamically in a tree-based structure. Unfortunately, these changes were not that sharp to cope with existing systems. Then they presented the first true implementation of such system that includes smartphones to upload, download and share client’s documents. It is focused on the fine-grain management of the rights, i.e., claiming and sharing the authorization of individuals on the basis of user priority.
Here, the problem is focused on the fine-grain management of the rights. Generally, the standard PRE scheme has a sharing property of “all or nothing.” If the re-encryption key is generated by client A, then the proxy can re-encrypt for client B any document initially encrypted to client A. But, there is no way for client A to restrict what the proxy can re-encrypt or not, except by trusting it. In such case, if the storage space is structured as a tree, client A may want to only share a specific folder F x , or any specific files f x,y , but not all the files. This problem can be resolved using the conditional PRE scheme. In concern, let a unique condition \( \omega_{{f_{2,1,1} }} \) that is defined during the encryption process is attached to each uploaded file \( f_{2,1,1} \). In order to obtain ciphertext encryption using client A public key (pk A ) will be (\( pk_{A} , f_{2,1,1} , \omega_{{f_{2,1,1} }} \)).
In other case, if client A wishes to share its right to client B for folder F 2, then the re-encryption key is computed from A to B under a condition related to F 2. That generated key is certainly denoted as \( rk_{{A \to B,F_{2} }} \), and further will be sent to the proxy that permits vertical transformation between users.
The third case needs more attention as there should be a particular path to traverse back to the root from the specific file location. To resolve this issue, after the vertical transformation a horizontal transformation is added inside the tree. It uses additional re-encryption keys such as \( rk_{{ F_{2,1} \to F_{2} ,A}} \) or \( rk_{{ f_{2,1,1} \to F_{2,1} ,A}} \) that are modified ciphertext attached conditions, as shown in Fig. 4.

Preferred tree-based structure to re-encrypt keys [1]
These steps look quite complicated, but precisely, it works upon a simple idea that is “for each couple (file, folder) or (folder, folder) in the path of the file to the root, client A needs to compute a re-encryption key (but only once for each link between folders).” This proxy re-encryption is resulted to be a good tool that has successfully maintained privacy by permitting the use of non-trusted platform for storing the sensitive documents. It can be further adapted to integrate additional features, e.g., de-duplication, indexation or some usual and unusual complex computations over encrypted data.
3.1.2 Using the Remote Data Auditing (RDA)
RDA technique falls in the cryptography category because it either provides a probabilistic or deterministic assurance for data intactness [6]. It embraces the properties like (a) Efficiency: data auditing with least possible computational complexity; (b) Public Verifiability: to allow data auditing process delegation to a trustworthy third-party auditor (TPA) and reducing the computational burden on the client’s side; (c) Detection Probability: to check potential data corruption detection probability. In concern to maintain privacy certainly a critical issue related to data auditing is required to resolve. This is the case, when digital certificate expires in the PKI system, then it is needed to update cloud users and authenticators associated with the key. Yannan et al. proposed an authenticator-evolving and key-updating mechanism with the zero-knowledge privacy of the stored files for security. It unites zero-knowledge proof systems, homomorphic linear authenticators and proxy re-signatures. It is a combination of five different algorithms, i.e., \( CrsGen, \,KeyGen, \,AuthGen,\, KeyUpdate \) and AuthUpdate along with an interactive proof system to get a proof between a Prover and a Verifier.
\( \varvec{CrsGen} \)(1k): It takes a security parameter k as input and outputs crs as a common reference string, which is an implicit input to all algorithms described below.
\( \varvec{KeyGen} \)(crs): to input crs, it generates a public key pk and a secret key sk for the cloud user. The user publishes pk and keeps sk secret.
\( \varvec{AuthGen } \)(\( sk, F \)): as input it takes the secret key sk and a file \( F = \left( {m_{1} ,m_{2} , \ldots ,m_{n} } \right) \) and outputs a set of authenticators {D i } for this file and a set of public verification parameter φ, which will be used for checking the data integrity in the proof phase.
\( \varvec{KeyUpdate} \)(\( sk, pk \)): On input the \( \left( {l - 1} \right) \) old key pairs \( (sk_{l - 1} ,pk_{l - 1} ) \), the algorithm outputs a new key pair \( (sk_{l} ,pk_{l} ) \).
\( \varvec{AuthUpdate} (sk_{l} ,pk_{l} ,ft_{l - 1} ,\varphi ) \): On input a new key pair (pk l , sk l ) the original file tag ft l−1 and the public verification parameter φ, it outputs a new file tag \( ft_{l} \) and the new update key β l that are valid under the new key pair.
Proof
(P, V) This interactive protocol between the Prover (P) and the Verifier \( \left( V \right) \) takes a common input to (P, V) which is the public key \( pk \) and the public verification parameter φ. P has additional input the file \( F = \left( {m_{1} ,m_{2} , \ldots ,m_{n} } \right) \) and a set of authenticators {D i } of this file. At the end of the protocol, V outputs a bit 1 or 0 to indicate whether the stored file is kept intact or not. For notational convenience, we use \( P \Leftrightarrow V\left( {pk, \varphi } \right) = 1 \) to indicate that V outputs 1 at the end of the interaction with \( P \). We omit the parameters \( \left( {pk, \varphi } \right) \) when the context is clear.
For the privacy-preserving public auditing scheme, author feels soundness, completeness and data privacy are three security requirements. Completeness means that when interacting with the cloud server who keeps the data unchanged, the interactive protocol proof will always result in \( P \Leftrightarrow V = 1 \) when the cloud server and the TPA follow the protocol honestly. Thus, the concept of zero-knowledge data privacy helps to capture that the TPA learns no knowledge about the processed content except publically available information-based random file name. This is further strengthen on the basis of evaluation properties and proved the security including soundness is efficient and can be used in practice.
3.1.3 Using BP-XOR Gates
LT codes, LDPC codes and digital fountain techniques have received considerable attention from both industry and academics in the past few years. BP-XOR gates works as a productive approach to get Trust-evaluation in the field of cryptography [7].
In order to employ the underlying ideas of competent belief propagation (BP) decoding process in LDPC and LT codes, the paper plans the BP-XOR codes and uses them to project three classes of secret sharing schemes called pseudo-BP-XOR secret sharing schemes, LDPC secret sharing schemes and BP-XOR secret sharing schemes. By inducing the equivalence between the edge-colored graph model and degree-two BP-XOR secret sharing schemes, authors designed novel and ideal 2-out-of-n BP-XOR secret sharing schemes.
By employing techniques from array code design, it is also able to design other \( \left( {n,k} \right) \) threshold LDPC secret sharing schemes. In the efficient LDPC or BP-XOR secret sharing schemes that it builds, only linear number of XOR (exclusive-or) operations on binary strings are necessary for both secret reconstruction phase and secret distribution phase.
For a comparison, one should note that Shamir secret sharing schemes need O(n 2) field operations for the secret reconstruction phase and \( O\left( {n\, log\, n} \right) \) field processes for the secret distribution phase. Additionally, author claims that such schemes attain the optimal update complexity for the secret sharing schemes. By update complexity for a secret sharing scheme, author meant that the average number of bits in the participant’s shares that needs to be revised when certain bit of the master secret is changed. It is also requested the efficient secret sharing schemes discussed in this paper considerably used for massive data storage in cloud environments for achieving reliability and privacy without employing encryption techniques. On the basis, various similar approaches are compared in Table 1.
3.2 Predicate Encryption
This predicate encryption is considered as a novel cryptographic primitive which provides a fine-grained control over the encrypted data accesses. It is usually used for the biometric matching and secure cloud storage.
3.2.1 Achieving Regular Language Search
“Regular language search” is concerned to languages in automata. It first defines a new notion called searchable deterministic finite automata-based functional encryption. The notion is a general notion for PEKS [3]. Next, it designs a concrete construction satisfying the notion. In its construction, any system user can describe a data to be shared with “regular language” in an encrypted form, where the language description can be arbitrary length (e.g., an English sentence, or a paragraph). A valid data receiver can generate and deliver a search token represented as a deterministic finite automata (DFA) to a cloud server, such that the cloud server can locate the corresponding ciphertexts and return them to the data receiver. In the search phase, the server knows nothing about the search contents and the underlying data. They further present extensive evaluation for the system to show its security, and the efficiency compared to two most related works [8, 9].
Regular language search is productively effective for this system. This makes the system be the first of its type, to the best of our knowledge. It is undeniable that SSE (e.g., [10]) usually enjoys better efficiency in data searching compared to the public key-based searchable encryption. However, this novel system can support any arbitrary alphabet/regular language search, so that it is more human-friendly readable for search keyword design. Besides, the system provides verifiable (data integrity) check for system users (due to public-key-based feature). Moreover, the system does not need to require a data owner to pick up some special keywords before constructing keyword index structures, e.g., least frequent keyword, but also it only leverages a DFA structure to embed flexible search expressiveness, e.g., “AND, OR, NOT,” unlike that of only limited in “a keyword AND (formula)” expression.
Author assumes, let BSetup be an algorithm that on input the security parameter n, outputs the parameters of a bilinear map as \( (p,g,\hat{g},G_{1} ,G_{2} ,G_{T} ,e) \), where \( G_{1} , G_{2} \) and G T are multiplicative cyclic groups of prime order p, where \( \left| p \right| = n, \) and g is a random generator of G 1, \( \hat{g} \) is a random generator of G 2.
This further defines the complexity assumptions that determine the base of the work. Considering the (Asymmetric) l-Expanded BDHE Assumption: It depicts that an algorithm A has advantage \( Adv _{A}^{A - l - BDHE } \) in solving the asymmetric l-Expanded BDHE problem in \( \left( {G_{1} , G_{2} } \right) \) if \( |\Pr \left[ {A\left( {\hat{X}, e\left( {g,\hat{g}} \right)^{{a^{l + 1} bs}} } \right) = 0} \right] - \Pr [A\left( {\hat{X},T} \right) = 0|\, \ge \, \in \), where the probability is over the random choice of generators \( g \in G_{1} , \hat{g} \in G_{2} \), the random choice of exponents \( a,b,c_{0} , \ldots , c_{l + 1} ,d \in Z_{p}^{*} , T \in_{R} G_{T} \), the random bits used by \( A \), and \( \hat{X} \) is a set of the following elements:
It says the asymmetric l-Expanded BDHE assumption holds in (G 1, G 2) if no PPT algorithm has advantage ∊ in solving the asymmetric l-Expanded BDHE problem in \( \left( {G_{1} ,G_{2} } \right) \). It shows that the above extended complexity assumption still holds in the generic group model by employing the same proof technology introduced in [11]. Specifically, one can see from the set \( \hat{X} \) that there are five elements in G 1 including \( g,g^{b/d} ,g^{a} ,g^{ab/d} ,g^{{a^{i} s}} ,g^{{a^{i} bs/C_{j} }} ,g^{{a^{i} b/c_{i} }} \).
Here, it shows that these elements cannot help an adversary to compute an exponent value a l+1 bs. For the element \( g \), it is easy to see that there does not exist a \( \hat{X}^{{a^{l + 1} bs}} \) in \( \hat{X} \). Similarly, it needs the G 2 elements \( \hat{g}^{{a^{l + 1} ds}} ,\hat{g}^{{a^{l} ds}} ,\hat{g}^{{a^{l} bs}} , \hat{g}^{{a^{z} s}} , \hat{g}^{{a^{z} c_{j} }} \,\, {\text{and}}\,\,\hat{g}^{{a^{z} sc_{i} }} \) for the G 1 elements \( g^{b/d} ,g^{a} ,g^{ab/d} ,g^{{a^{i} s}} ,g^{{a^{i} bs/C_{j} }} ,g^{{a^{i} b/c_{i} }} \), respectively, where \( i + z = l + 1. \) It is not difficult to see that the above \( G_{2} \) elements cannot be provided by the set \( \hat{X} \). However, the structure and the pattern is the premise of allowing users to achieve regular language search. Though, the premise sustains a shortage in the search token storage cost.
3.2.2 Using Key Encryption
Over encrypted cloud storage services such current privacy-preserving search schemes do not provide effective revocation for search privileges [12]. Targeting at symmetric predicate encryptions and cloud storage requirements, in this paper author proposed controllable privacy-preserving search in cloud storage. This scheme is based on Private-key hidden vector encryption with key confidentiality. Although, its efficiency is much better than approach present in [13]. In [13] author presented a symmetric-key predicate encryption scheme in support of inner product queries that considers predicate encryption in the symmetric-key setting.
In contrast, the controllable privacy-preserving search scheme has two new features. One is revocable delegated search that helps secret key owner to control the lifetime of the delegation. But, the other is undecryptable delegated search. Due to this feature, a delegated person cannot decrypt the returned matched ciphertexts even though one has the delegated privilege of search. Here, in Table 2, various predicate encryption-based approaches are compared to highlight the concepts.
Viewpoint: The category “privacy by cryptography” considers the original sensitive data and then is perturbed. This perturbation makes the data less sensitive which increases the integrity simultaneously. It surely helps in storing and sharing sensitive data in the cloud environment safely where storage-based computing resources are provided by a third-party service provider. But, this communication raises serious concern for the adoption of advanced computing technologies to cope with individual privacy. These issues can be resolved by the following privacy categories.
4 Probability-Oriented Privacy Measures
Traditionally, watermarking was preferred to preserve the data privacy. It works on serving to the agents after performing data modifications. If the data are discovered in the hands of an unauthorized agent (who is a malicious recipient), then the watermarks can be destroyed. Thus, in support of privacy by probability some best approaches are presented here, as follows:
4.1 Effective Solution for Data Leakage
In [16] author deliberates the following problem: “A data distributor gives sensitive data to a set of allegedly trusted agents (third parties). Some of the leaked data are found in an unauthorized place (e.g., on somebody’s laptop or on the web). The distributor must weigh the outlook that the leaked data came from one or more agents, as opposed to having been independently gathered by other unauthorized means.” In concern to agents, author has proposed data allocation strategies that improve the probability of identifying leakages. Such methods do not depend on alterations of the released data (e.g., watermarks). In some cases, author also injects “realistic but fake” data records to further improve the chances of detecting leakage and identifying the guilty agent or party.
It considers basic entities and agents to build guilty agent detection system. Following the impression that has a distributor who owns a set \( T = \left\{ {t_{1} , t_{2} , \ldots ,t_{p} } \right\} \) of valuable data objects.
The distributor desires to share some of the objects with a set of agents \( U, U_{2} , \ldots ,U_{q} \), which do not wish the objects be leaked to other third parties. The objects in T might be of any type and size, for example, it could be tuples in a relation, or relations in a database.
An agent U i receives a subset of objects \( R_{i} \subseteq T \), that is, determined either by an explicit request or sample request:
-
\( {\text{Sample}}\,\, {\text{request}}\,\,R_{i} = {\text{SAMPLE}}\left( {T,m_{i} } \right) \): Any subset of m i records from T can be given to U i .
-
\( {\text{Explicit}}\,\, {\text{request}}\,\,R_{i} = {\text{EXPLICIT}}\left( {T,{\text{cond}}_{i} } \right) \): Agent U i receives all T objects that satisfy cond i .
This recruits a procedure which presumes that after sending objects to agents, the distributor notices a set S ⊆ T has leaked. This means that some third party, called the target, is caught in possession of S. For example, the target might be displaying S on its website, or perhaps as part of a legal discovery process, the target turned over S to the distributor.
Since the agents \( U, U_{2} , \ldots ,U_{q} \) have some of the data, it is reasonable to suspect them leaking the data. However, the agents can argue that they are innocent and that the S data were obtained by the target through other means. For example, assume that one of the objects in S represents a customer X. Perhaps X is also a customer referred to some other company which provides the data to the target agent. It is also possible that X can be reconstructed from several publicly available sources on the web. The goal is to guess the precise likelihood that the leaked data came from the agents as opposed to other sources. Instinctively, the more data in S, the harder it is for the agents to argue they did not leak anything.
The process of consideration and evaluation can compute the probability \( \Pr \left\{ {G_{i} |S} \right\} \) that agent U i is guilty
Here, p is the probability of the event occurred and V t stands for the set of agents.
Authors [16] proposed an algorithm that finds agents which are eligible to receiving fake objects in O(n) time. Then, in the main loop the algorithm creates one fake object in every iteration and allocates it to random agent. The main loop takes O(B) time, where B refers to Fake object creation. Hence, the running time of the algorithm is determined to be \( O\left( {n + B} \right) \).
In spite of any difficulty, authors have worked on predicting that it is possible to assess the likelihood that an agent is responsible for a leak, established on the data overlapping with the leaked data and the data of other agents. It is based on the probability that objects can be “guessed” by other means. The model is moderately simple, but it is believed that it seizures the essential trade-offs. The algorithms described here implement a diversity of data distribution strategies that can improve the distributor’s chances to identify a leaker. Authors represented that distributing objects cautiously makes a significant difference in identifying guilty agents, particularly in the case where agents must receive large overlap in the data.
The future work includes the investigation of agent guilt models that capture leakage scenarios, for example, determining the suitable model for cases where various agents can collude and identify fake tuples. An initial discussion of such a model is available in [17]. Another open problem is the extension of the allocation strategies so that they can handle agent requests in an online fashion (the presented strategies assume that there is a fixed set of agents with requests known in advance).
5 Using Probabilistic Hybrid Logics
In [18], Hsu et al. proposed a combination of basic hybrid logic and quantitative uncertainty logic with a satisfaction operator. This technique is highlighted individually in comparison with the other approach due to its special features.
The logic is expressive and flexible enough to represent many existing privacy criteria, such as k-anonymity, logical safety, l-diversity, t-closeness, and δ-disclosure. The main contribution of the logic is twofold. On the one hand, the uniformity of the framework explicates the common principle behind a variety of privacy requirements and highlights their differences. For example, the difference between syntactic and semantic privacy criteria is easily observed by using the logical specifications. On the other hand, the generality of the framework extends the scope of privacy specifications.
In particular, one can specify heterogeneous requirements between different individuals, so it is possible to achieve personalized privacy specification. For example, one can use \( @_{i} \neg \left[ {a_{1} } \right]\emptyset \wedge @_{j} \neg \left[ {a_{1} } \right]\psi \) to express different privacy requirements of individuals i and j. Moreover, the logic allows arbitrary combinations of existing privacy requirements, so we can express compound privacy criteria. For example, we can use \( @_{i} \neg \left[ {a_{1} } \right]\emptyset \wedge l_{{a_{1} }} \left( i \right) \le \frac{1}{k} \) to express that both logical safety and k-anonymity are required for the individual i. Since unexpected attacks may occur occasionally, existing criteria may be inadequate; hence, it may be necessary to specify new criteria. For example, the logical safety criterion may be combined with δ-disclosure to require formulas in Sec(i), instead of simply f-atoms, to satisfy the δ-disclosure privacy criterion. In addition, it is possible to consider the weight of a secret in order to measures the seriousness of revealing the secret. Thus, \( W\,\sec : U \times\Gamma \to \left[ {0, 1} \right] \) is defined as the weight function for each individual and secret. Then, we can combine the weight with existing privacy criteria to obtain new privacy protection models. This may facilitate a more effective trade-off between privacy protection and data utility. The logic language provides a uniform framework to meet the specification needs of such new criteria as well as existing ones. See Table 3 for various similar approaches proposed earlier.
6 Anonymization-Oriented Privacy Measures
This category of privacy perseverance comprises subset generations of well-known method, “anonymization.” Based on secured multiparty computation, collaborative privacy-preserving data mining sustains high computational cost and communication. Data anonymization is an encouraging technique in the field of privacy-preserving data mining castoff to protect the data against identity disclosure. Common attacks and information loss possible on the anonymized data are intense challenges of anonymization. Lately, data anonymization using data mining techniques has showed noteworthy enhancement in data utility. Still the prevailing techniques lack in effective handling of attacks. Out of numerous proposed methods, the following privacy approach based on anonymization sounds appealing in a few comparative terms with other categories.
7 For Utility Preserving Data Clustering
In this paper [20], an anonymization algorithm established on clustering and resilient to similarity attack and probabilistic inference attack is proposed. The anonymized data are dispersed on hadoop distributed file system. The method attains a better trade-off between privacy and utility. In this work, the data utility is measured in terms of accuracy and F measure with respect to different classifiers.
Nayahi and Kavitha [20] proposed a \( {\text{KNN}}\left( {G,S} \right) \) clustering algorithm to achieve anonymized clusters each with uniform distribution of sensitive values. The \( \left( {G,S} \right) \) clustering algorithm [21] governs the single best neighbor of each cluster and allocates one instance at a time to the existing cluster. The authors have modified the algorithm to overcome the skew in the sensitive value distribution of the resultant clusters using the K-nearest neighbor technique. The KNN-(G,S) clustering algorithm determines the KN nearest neighbors using the following equation from each sensitive value group and adds the KN records to the clusters at a time.
where |D i | is the number of instances in each sensitive value subgroup \( \left( {D_{i} } \right) \); and NOB is the number of clusters. This formula divides the records equally among all the clusters. Hence, there will be an evenly spread distribution of sensitive values in the formed clusters with original data set. The given data set D is sorted with respect to the sensitive attribute value SA. After sorting, the input data set is divided into D 1, D 2,…, D n subgroups. Each subgroup would contain identical values for SA. All the remaining subgroups other than D min (i.e., the cardinality of the least frequent value in SA or smallest group) are considered as D rem. Based on the values of k and S, the algorithm works in two cases. In Case 1 the k value is less than or equal to S (k ≤ S), and in Case 2 the k value is greater than S (k > S). It claims that it has reduced the complexity also as compared to other similar approaches.
Though, the worst case analysis on the computational cost of the KNN-(G, S) clustering algorithm is figured and represented using big O notation. On the other side, the worst case storage cost of proposed algorithm is given by \( S_{1} \left( n \right) \). The given data set is divided into sub-groups and stored separately incurring an additional storage cost shown in \( S_{3} \left( n \right) \). The storage cost of the clusters formed in either Case 1 or Case 2 of the algorithm is given by \( S_{5,6} \left( n \right) \). The total size of all the clusters would be equal to the size of the original data set. The total storage cost of algorithm is given by S(n). After simplifying the storage cost of the KNN-(G,S) clustering algorithm is O(n)
One of the best features of this approach is that it overcomes the possibility of probabilistic inference attack easily. The possibility is compared to the other techniques based on t-closeness [22, 23].
The existing techniques on data anonymization do not show such comparison. Specifically, most of the existing techniques assess the performance using traditional metrics only. Unlike those, the information loss is measured in terms of traditional metrics such as global certainty penalty [4, 24], non-uniform entropy metric [25], normalized information loss [26, 27], normalized certainty penalty [4], query error [11, 28], sum of squared errors [29]. But, in proposed approach, Nayahi and Kavitha worked best to succeed in the anonymization using centroid-based replacement of QID values that is computationally superior to suppression in terms of information loss and less expensive than generalization.
After studying this work, we could judge the effectively summarized facts and the need to include in our review work especially in this particular privacy category. Hence, Table 4 gives an overview of similar comparative approaches.
8 Ranking-Oriented Privacy Measures
For privacy apprehensions, secure searches over encrypted cloud data have encouraged numerous research works under the single-owner model. Basics of “Ranking” is precisely explained by [14, 31] On the contrary, most cloud servers in cutting-edge practice not only serve one owner; instead, they support multiple owners to segment the profits brought by cloud computing. Thus, we classify several approaches in two, i.e., (a) for single owner, (b) for the multi-owner cloud environment. Out of various classified approaches, we are reviewing best one for the individual sub-categories.
9 Common Considerations
In order to present the variation for both of the review approaches on a common platform, following terms are considered.
The policy is based upon bilinear map which assumes two cyclic groups G 1 and G 2 of prime order p 1 and G 1 generated by g 1 (known as generator). Thus, bilinear mapping \( e : G_{1} \times G_{1} \to G_{2} \) must satisfy the following:
-
Bi-linearity property: for all y, z ∊ G 1 and \( a,b \in Z_{p} \), where \( Z_{{p_{1} }} = \left\{ {0,1,2, \ldots ,p_{1} - 1} \right\}, \) we are having e(y a, z b) = e(y, z)ab.
-
Computability property: for any, \( y,z \in G_{1} \) there is a polynomial time algorithm to compute the mapping e(y, z) ∊ G 2.
-
Non-degeneracy property, \( e\left( {g1,g1} \right) \ne 1 \).
10 Based on Single-Owner Cloud Environment
In the paper [5], author has aimed at efficiently solving the problem of fine-grained access control on searchable encrypted data for the single-owner cloud system. It considers a hybrid architecture in which a private cloud is introduced as an access interface between the public cloud and user. Under the hybrid architecture, it has considered a practical keyword search scheme which concurrently supports fine-grained access control over encrypted data. Further, the exact keyword search, it grants an advanced scheme under this new architecture to capably achieve fuzzy keyword search. Lastly, based on the scrutiny in both of the schemes that the main computational cost at user side is the ABE scheme, such that author discusses the issue of outsourcing ABE to private cloud to further relieve the computational cost at user side.
In concern, the work examines the problem of privacy-preserving data utilization in cloud computing and intends the data utilization system supporting for the following three:
-
Fine-Grained Access Control The data owner is permitted to impose an access policy on each file to be uploaded that precisely entitles the set of data users allowed to access. The public cloud is also prohibited from learning the plaintexts of data files.
-
Authorization/Revocation Each authorized user is capable to get their individual private key to execute search and decryption. When a user’s key has been retracted, the user will no longer be able to search and read the outsourced files.
-
Keyword-Based Query An authorized user is capable to use individual private key for generating a query for assured keywords. Though the public cloud implements a “search” directly on the encrypted data and proceeds the matched files.
11 Using Multi-owner Cloud Environment
The paper [14] offers schemes to deal with privacy-preserving ranked multi-keyword search in a multi-owner model (PRMSM). To empower cloud servers to achieve secure search without knowing the actual data of both keywords and trapdoors, one methodically constructs a novel secure search protocol. To rank the explored results and preserve the privacy of relevance scores between files and keywords, author has proposed a novel additive instruction and privacy-preserving function family. To prevent the attackers from pretending to be legal data users submitting searches and from eavesdropping secret keys, author proposed a novel dynamic secret key generation protocol. PRMSM also works as a data user authentication protocol which supports efficient data user revocation. All-encompassing experiments on real-world datasets endorse the effectiveness and efficiency of PRMSM (Fig. 5).

Architecture of privacy-preserving keyword search in a multi-owner and multi-user cloud model
Individually this multi-owner environment works on the foundation of these two considerations.
Consideration-1 Given a probabilistic polynomial time adversary A, he asks the challenger B for the cipher-text of his submitted keywords for polynomial times. Then A sends two keywords w 0 and w 1 which are not challenged before, to B. B randomly sets \( \mu \in \left\{ {0,1} \right\} \) and returns an encrypted keyword \( \hat{w}_{\mu } \) to A. A continues to ask B for the cipher-text of keyword w, the only restriction is that w is not w 0 or \( w_{1} \). Finally, A outputs its guess μ′ for \( \mu \). We define the advantage that A breaks PRMSM as \( {\text{Adv}}_{A} = \left| {\Pr } \right|\mu = \mu^{\prime}\left| { - \frac{1}{2}} \right| \). If Adv A is negligible, we say that PRMSM is semantically secure against the chosen keyword attack.
Consideration-2 Given a probabilistic polynomial time adversary A, he asks the challenger B for the cipher-text of his queried keywords for t times. Then B randomly chooses a keyword \( w^{*} \), encrypts it to \( \hat{w}^{*} \) and sends \( \hat{w}^{*} \) to A. A outputs its guess w′ for \( w^{*} \), and wins if \( w^{\prime} = w^{*} \). We define the probability that A breaks keyword secrecy as \( {\text{Adv}}_{A} = { \Pr }\left| {w^{\prime} = w^{*} } \right| \). We say that PRMSM achieves keyword secrecy if \( {\text{Adv}}_{A} = \frac{1}{u - t} + \in \), where ∊ is a negligible parameter, t denotes the number of keywords that A has known, and u denotes the size of keyword dictionary.
This work preserves privacy as well as security that means it first requires to manipulate the data to preserve data privacy. Then, it needs to lock the data using key-based encryption to provide security. In progress, it starts with the user authentication process that follows the following format.
Request counter | Last request time | Personally identifiable data | Random number | CRC |
Here, the significant fact of a successful authentication is to offer both the dynamically changing secret keys and the historical data of the equivalent data user.
An example has been illustrated to get the main idea of the keywords matching protocol (the detailed protocol is elaborated in the following sections). Assume Alice wants to use the cloud to store her file F; she first encrypts her file F and gets the ciphertext C. To enable other users to perform secure searches on C, Alice extracts a keyword w i,h and sends the encrypted keyword \( \hat{w}_{i,h} = \left( {E_{{a^{\prime}}} ,E_{o} } \right) \) to the administration server. The administration server further re-encrypts \( E_{{a^{\prime}}} \) to \( E_{a} \) and submits \( \hat{w}_{i,h} = \left( {E_{a} ,E_{o} } \right) \) to the cloud server. Now Bob wants to search a keyword \( w_{{h^{\prime}}} \); he first generates the trapdoor \( T_{{w_{{h^{\prime}}} }}^{{\prime }} \) and submits it to the administration server. The administration server re-encrypts \( T_{{w_{{h^{\prime}}} }}^{{\prime }} \) to \( T_{{w_{{h^{\prime}}} }} = \left( {T_{1} ,T_{2} ,T_{3} } \right) \), generates a secret data \( S_{a} \), and submits \( T_{{w_{{h^{\prime}}} }} \), S a to the cloud server. The cloud server will judge whether Bob’s search request matches Alice’s encrypted keyword by checking whether \( \hat{e}\left( {E_{a} ,T_{3} } \right) = \hat{e}\left( {E_{a} ,T_{1} } \right) \cdot \hat{e}\left( {S_{a} ,T_{2} } \right) \) holds.
The keywords encryption benefits in two ways; First, losing the key of one data owner would not lead to the disclosure of other owners’ data. Second, the cloud server cannot see any relationship among encrypted keywords. This follows the proposal of Trapdoor construction formula and is constructed in a ways that the privacy of trapdoor is protected as long as the discrete logarithm problem is hard.
And it is constructed in a way that the privacy of trapdoor is protected as long as the discrete logarithm problem is hard.
Different from prior works, this approach supports authenticated data users to attain efficient, secure and convenient searches over multiple data owners’ data. To proficiently authenticate data users and detect attackers who steal the secret key and execute illegal searches, author has proposed a novel dynamic secret key generation protocol and a new data user authentication protocol. To enable the cloud server to perform secure search among multiple owners’ data encrypted with different secret keys, they systematically construct a novel secure search protocol. Moreover, the work shows that the approach is computationally efficient, even for large data and keyword sets. See Table 5 for similar approaches based on Ranking.
12 Evaluation and Analysis
A detailed comparison of the presented approaches in terms of the privacy requirements is provided in Table 6. In Table 6, “×” and “√” symbols indicate whether a specific privacy-preserving check is fulfilled or not, respectively, whereas “–” represents that a particular requirement is not discussed. As can be observed that majority of the presented techniques fulfill the privacy-preserving requirements, such as integrity, accessibility and confidentiality. However, the requirements, such as data utility and data minimization, are met by only few techniques. There appears an important relationship between the data utility and data minimization and most of the presented approaches maintain unlinkability through data minimization. Another important observation is particular to the probability and multi-keyword ranking approaches. These approaches may propagate the keys to the unwanted users having attributes similar to the legitimate users. Nonetheless, the probability and multi-keyword ranking approaches have been quite effectively utilized to achieve a desired level of privacy. We also observe that most of the presented cryptographic techniques have successfully been able to minimize the key management overheads despite of their inherent complexities. For instance, the anonymization is considered as less efficient in terms of computation, whereas the multi-keyword ranking has a standing of costly privacy primitive because of bilinear computations. However, the presented schemes in this survey based on the aforementioned probability and cryptographic schemes sufficiently minimized the privacy preserving overhead. The higher data utility-based approaches can never be truly safe in public clouds because they are susceptible to information disclosure by some insiders or the other hackers.
However, higher data utility-based approaches when used only in private clouds preserve the privacy to a desired level because the infrastructure in such cases is trusted. Therefore, for systems operating in public or hybrid clouds, using reasonably strong privacy-preserving idea is highly important that can be depicted in Table 7.
13 Conclusion
In this age of cloud computing and big data, privacy protection is becoming an unavoidable stumbling block in front of us. Encouraged by this, we plotted the major milestones in privacy study and kept up to date from different perspectives. It aims to pave a consistent ground for concerned readers to explore this promising and emerging field. We summarized the privacy study upshots in different research principles and communities. Specifically, we presented the mathematical efforts announced by the related privacy frameworks and models.
The methodologies are well classified into four classifications and prepare section-wise tables governing their characteristics. Furthermore, the optimum solution for a type of cloud privacy-preserving model is highlighted section-wise as well as when all taken together for better understanding and clarification to new researchers in this area. It is believed that such effort in privacy is essential and highly demanded in problem solving in the cloud environment, and it is undeniably worthwhile to invest our energy and passion to look forward to the best approach on the basis of data utility and privacy accessibility.
References
Canard S, Devigne J (2016) Highly privacy-protecting data sharing in a tree structure. Future Gener Comput Syst 62:119–127
Örencik C, Savaş E (2014) An efficient privacy-preserving multi-keyword search over encrypted cloud data with ranking. Distrib Parallel Database 32(1):119–160
Liang K, Huang X, Guo F, Liu JK (2016) Privacy-preserving and regular language search over encrypted cloud data. IEEE Trans Inf Forensics Secur 11(10):2365–2376
Yang JJ et al (2015) A hybrid solution for privacy preserving medical data sharing in the cloud environment. Future Gener Comput Syst 43–44:74–86
Li J et al (2014) Privacy-preserving data utilization in hybrid clouds. Future Gener Comput Syst 30(1):98–106
Li Y et al (2016) Privacy preserving cloud data auditing with efficient key update. Future Gener Comput Syst 78:789–798
Wang Y (2015) Privacy-preserving data storage in cloud using array BP-XOR codes. IEEE Trans Cloud Comput 3(4):425–436
Waters B et al (2007) Conjunctive, subset, and range queries on encrypted data. Theory Cryptogr 4392:535–545
Zheng Q et al (2014) VABKS: verifiable attribute-based keyword search over outsourced encrypted data. In: IEEE conference computer communication (INFOCOM)
Cash D et al (2013) Highly-scalable searchable symmetric encryption with support for Boolean queries. In: Advances in cryptology—CRYPTO, Berlin, Germany
Komishani EG et al (2016) PPTD: preserving personalized privacy in trajectory data publishing by sensitive attribute generalization and trajectory local suppression. Knowl Based Syst 94:43–59
Chun-I Fan S-YH (2013) Controllable privacy preserving search based on symmetric predicate encryption in cloud storage. Future Gener Comput Syst 29:1716–1724
Shen E et al (2009) Predicate privacy in encryption systems. In: The 6th theory of cryptography conference, TCC, Verlag
Zhang W et al (2016) Privacy preserving ranked multi-keyword search for multiple data owners in cloud computing. IEEE Trans Comput 65(5):1566–1578
Yan Z et al (2016) Two schemes of privacy-preserving trust evaluation. Future Gener Comput Syst 62:175–189
Garcia-Molina H et al (2011) Data leakage detection. IEEE Trans Knowl Data Eng 23(1):51–63
Garcia-Molina H, Papadimitriou P (2010) Data leakage detection. IEEE Trans Knowl Data Eng 51–63. https://doi.org/10.1109/TKDE.2010.100
Hsu T-S, Liau C-J, Wang D-W (2012) Logic, probability, and privacy: a framework. In: Turing-100, pp 157–167
Zhang G et al (2012) A historical probability based noise generation strategy for privacy protection in cloud computing. J Comput Syst Sci 78:1374–1381
Jesu Vedha Nayahi J, Kavitha V (2016) Privacy and utility preserving data clustering for data anonymization and distribution on Hadoop. Future Gener Comput Syst. https://doi.org/10.1016/j.future.2016.10.022
Jesu Vedha Nayahi J, Kavitha V (2015) An efficient clustering for anonymizing data and protecting sensitive labels. Int J Uncert Fuzziness Knowl Based Syst 23:685–714
Li N et al (2007) T-closeness: privacy beyond k-anonymity and l-diversity. In: IEEE international conference on data engineering
Rebollo-Monedero D et al (2010) From t-closeness-like privacy to postrandomization via information theory. IEEE Trans Knowl Data Eng 22:1623–1636
Amiri F et al (2015) Hierarchical anonymization algorithms against background knowledge attack in data releasing. Knowl-Based Syst 101:71–89
Kohlmayer F et al (2014) A flexible approach to distributed data anonymization. J Biomed Inform 50:62–76
Zhang X et al (2015) Proximity-aware local recoding anonymization with mapreduce for scalable big data privacy preservation in cloud. IEEE Trans Comput 64(8):2293–2307
Wen-Yang L et al (2015) Privacy preserving data anonymization of spontaneous ADE reporting system dataset. BMC Med Inform Decis Mak 16:58
Goryczka S et al. (2014) m-Privacy for collaborative data publishing. IEEE Trans Knowl Data Eng 26(10)
Soria-Comas J et al (2015) t-Closeness through microaggregation: strict privacy with enhanced utility preservation. IEEE Trans Knowl Data Eng 27(11):3098–3110
Rao YS (2017) A secure and efficient ciphertext-policy attribute-based signcryption for personal health records sharing in cloud computing. Future Gener Comput Syst 67:133–151
Rena SQ et al (2016) Secure searching on cloud storage enhanced by homographic indexing. Future Gener Comput Syst 65:102–110
Örencik C et al (2014) An efficient privacy-preserving multi-keyword search over encrypted cloud data with ranking. Distrib Parallel Datab 32:119–160
Cao N et al (2011) Privacy-preserving multi-keyword ranked search over encrypted cloud data. In: INFOCOM
Elger BS et al (2010) Strategies for health data exchange for secondary, cross-institutional clinical research. Comput Methods Prog Biomed 99:1–21
Ardagna CA et al (2010) Access control for smarter healthcare using policy spaces. J Comput Secur 29(8):848–858
Ni Q et al (2009) Privacy-aware role-based access control. IEEE Secur Privacy 7(4):35–43
Jin J et al (2011) Patient-centric authorization framework for electronic healthcare services. Comput Secur 30(2–3):116–127
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Singh, N., Singh, A.K. Data Privacy Protection Mechanisms in Cloud. Data Sci. Eng. 3, 24–39 (2018). https://doi.org/10.1007/s41019-017-0046-0
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s41019-017-0046-0