
Abstract
In contrast to classical data envelopment analysis (DEA), network DEA has attention to the internal structure of a production system and reveals the relationship between the efficiency of system and efficiencies of the processes. However, the flexibility of weights and the need for crisp input and output data in the evaluation process are two major shortcomings of classical network DEA models. This paper presents a common weights approach for a relational network DEA model in a fuzzy environment to measure the efficiencies of the system and the component processes. The proposed approach first finds upper bounds on input and output weights for a given cut level and then it determines a common set of weights (CSW) for all decision-making units (DMUs). Hence, the fuzzy efficiencies of all processes and systems for all DMUs are obtained based on the resulting CSW. The developed fuzzy relational network DEA and the proposed common weights approach are illustrated with a numerical example. The obtained results confirm that the fuzzy data affects over the efficiency scores and complete ranking of DMUs. The applicability of the proposed network model is illustrated by performance evaluation of gas refineries in Iran.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
Data envelopment analysis (DEA) is a well-known non-parametric technique for measuring the relative efficiency of a set of homogenous decision-making units (DMUs) with multiple inputs and outputs. DEA is a typical data-based mathematical programming approach that has been widely used for performance evaluations in many areas such as hospitals, universities, investment companies, banks, gas industry, and so on. The first DEA model, namely CCR was proposed by Charnes et al. [9] in 1978 in the case of Constant Return to Scale (CRS). Afterward, Banker et al. [8] proposed the BCC model for the case of Variable Return to Scale (VRS). The evaluation in DEA is done based on two different models, i.e., envelopment DEA models and multiplier DEA models. The multiplier DEA model is directly related to the weights assigned to input and output data which play an important role in evaluation. In the conventional multiplier DEA models, each DMU also selects suitable individual weights to maximize its efficiency. When there is freedom in the weight selection, the same input and output from the different DMUs may have different weights, which may not be rational or acceptable to the decision makers and managers. In fact, due to the possibility of multiple solutions in multiplier DEA models, the optimal weights of a DMU under evaluation may not have unique and it can differ from one DMU to others. To overcome this limitation, the idea of using a common set of weight (CSW) was proposed by Cook et al. [10] and Roll et al. [56] for the first time. In CSW models, there is no DMU under evaluation and the weights are obtained by solving a single optimization problem (see, e.g., Amin and Toloo [2], Hatami-Marbini et al. [35], Hosseinzadeh Lotfi et al. [41], Saati et al. [58]).
Moreover, in conventional DEA models, a production system has been seen as a black box without any attention to what is happening inside the system. A real-life system may involve several multi-step processes. Performance improvement of a complex system often requires observing the internal structure of the producing system to find the sources of inefficiencies. This type of view of the interdependencies among evaluated DMUs seeks alternative DEA models, are known as network DEA (NDEA), see Fare and Grosskopf [30]. The NDEA models report the influence of internal processes which are important in measuring the performance of DMUs. Attention to the internal processes leads to improve the efficiency of the entire system. In some cases, a system performs well, but some of its internal processes do not perform better than others. Thus, network DEA models have been attracted much interest in the recent DEA literature. One of the basic approaches in NDEA was developed by Kao and Hwangs [44] by considering the performance of the whole system as a product of the performance of each internal process. The network systems in practice include the series, parallel, and mixed (general) structures. An accurate study completely depends on the type of network structure, i.e. how the DMUs are considered, how the behavior of the system is, and how it can cover a real problem with internal complexities.
For example, Lovell et al. [48] examined the American school network system where each internal process in that study operated separately and independently. Fare et al. [31] proposed the DEA network model to analyze the health economics of Swedish institutions. Noulas et al. [51] applied NDEA models to investigate IT technology and life insurance companies. Chen and Zhu [14] evaluated the bank network systems to identify some factors that are affected by efficiency or inefficiency scores. Many network systems are neither completely parallel nor completely series. Zhao et al. [73] evaluated transportation services by considering a three-stage network system. Adler et al. [1] appraised the performance of two-stage independent network systems for 43 airports in 13 European countries. In that study, the first stage with one process was linked to the second stage with two parallel sub-processes. Ebrahimnejad et al. [22] calculated the efficiency of three-stage DEA model with two independent parallel stages linking to a third final stage by considering a series of intermediate measures and constraints. An et al. [3] proposed a new dynamic two-stage data envelopment analysis approach to measure the efficiency of network system with a two-stage structure and shared outputs. Yu et al. [71] developed an improved matrix-type NDEA model with undesirable output was developed to evaluate the eco-efficiency of China’s 30 provinces. Yu et al. [72] proposed a two-system slacks-based measure dynamic NDEA model which allows the linking activities between processes and the carry-over activities between two consecutive terms.
In evaluating the processes, both in DEA and NDEA, the type of data plays a key role. Making exact decisions needs accurate information to reflect reality without speculation. The data used in real life are not always definitively available. Fuzzy theory proposed by Zadeh [74] is an appropriate approach to deal with such descriptive and inaccurate data. It was an attitude to connect the real-life with mathematical logic. Fuzzy logic uses vague data to report logical results based on reality. Hence, fuzzy DEA (FDEA) and fuzzy NDEA models are important in such situations.
Literature review
The development and capability of fuzzy set theory have been considered by many researchers in various fields. For example, Zhang et al. [75] investigated the fault detection filter design problem [11] for a class of nonhomogeneous higher level Markov jump systems with interval type-2 fuzzy transition probabilities. Moreover, Cheng et al. [12] addresses the design issue of fuzzy asynchronous fault detection filter for a class of nonlinear Markov jump systems by an event-triggered scheme. Das [15] investigated a fully fuzzy triangular linear fractional programming problem under the condition that all the parameters and decision variables are characterized by triangular fuzzy numbers. Sun et al. [61] investigated a green road–rail intermodal routing problem with improved pickup and delivery services under uncertainty. Chen and Wang [13] proposed a fuzzy mid-term capacity and production planning model for a manufacturer with cloud-based capacity.
New DEA and NDEA approaches with fuzzy data also are used in many applications in the last decades. In a comprehensive review of FDEA, Emrouznejad et al. [27] and Hatami-Marbini et al. [36] divided these approaches into four categories. (1) Tolerance approach: considering uncertainty based on determining a tolerance level for constraints. (2) The α-cut based approach: converting the fuzzy DEA model into a pair of parametric models to find the upper and lower bounds of efficiency. (3) Ranking approach: using a ranking function for converting fuzzy DEA model into crisp one. (4) The possibility approach: considering each fuzzy constraint in DEA model as a fuzzy event and using the fuzzy event possibility measure.
Many DEA models have been developed in fuzzy environments. Kao and Liu [45] presented a model for measuring the efficiency of DMUs with fuzzy data. The main idea was to transfer an FDEA model to a family of conventional DEA models using the α-cut method. Entani et al. [29] proposed a DEA model based on optimistic and pessimistic perspectives and considered the efficiency measures as an interval. Kao and Liu [46] provided a way to rank DMUs without considering the exact amount of their membership. Zhu [76] conducted a very good review of inaccurate DEA models. Hatami-marbini et al. [37] proposed a novel fully fuzzified DEA approach where, in addition to input and output data, all the variables are considered fuzzy, including the resulting efficiency scores. Tavana et al. [62] evaluated the technical and environmental efficiency of Iranian refineries with fuzzy DEA models. They used the α-cut approach and obtained a CSW for all inputs and outputs. Kachouei et al. [42] developed the fuzzy arithmetic approach for finding the common set of weights (CSW) in fuzzy DEA model with undesirable outputs. Ebrahimnejad and Amani [25] have used the fuzzy arithmetic approach for solving fuzzy DEA models in the presence of undesirable outputs by the help of fuzzy ideal DMUs. Arana-Jiménez et al. [4] considered a fuzzy extension of the measure of inefficiency proportions, a well-known slacks-based additive inefficiency measure.
Yu and Lin [69] evaluated the performance of 20 railway companies worldwide in the fuzzy environment. They maximized the total weight of distance parameters using a direction vector. The network system in their study was divided into two stages, production and consumption, and each stage was divided into two processes, passenger and freight. Yu [70] examined the performance of 15 domestic airports in Taiwan. The network was included two stages, production and service, and every stage was segregated into two sub-stages, airside and landside. Kao and Liu [47] also proposed a new method for the fuzzy two-stage network problems. Their approach was suitable for formulating DEA models with fuzzy L–R numbers. Wang et al. [67] studied the profitability and marketing efficiency of 65 high-tech firms in Taiwan in a three-stage network system. The system has two parallel parts connected in series with a single part. Lin and Chiu [49] evaluated 30 operating systems of banks in Taiwan that were divided into three phases: production, service, and profitability. They applied the Slack Based Model (SBM) to evaluate this network problem. Services were divided into corporate and consumer banks in parallel. Shermeh et al. [60] used a three-stage DEA network with fuzzy data to study and evaluate Iran’s regional power companies. Tuysuz and Simsek [64] evaluated the burden networks with fuzzy data in Turkey by using the α-cut approach. The efficiency of the whole system and the efficiency of internal processes were calculated separately. Hatami-Marbini and Saati [38] used the fuzzy NDEA model for ranking some organizations to examine and analyze the performance of the systems and the internal processes, separately.
Peykani and Mohammadi [54] proposed a new approach for finding the efficiency of the two-stage network with inaccurate data. Zhu et al. [77] used the fuzzy NDEA approach for energy modeling to analyze some complicated chemical industries. Each input and output parameter had five membership functions and the efficiency was reported at three levels: low efficiency, medium efficiency, and high efficiency. Zhou et al. [78] examined the sustainable supply chain as a three-stage dynamic network system consisting of suppliers, manufacturers, and distributors with fuzzy data. They reported the degree of environmental pollution and customer satisfaction as a fuzzy set. Gidion et al. [32] investigated an NDEA model to overcome some flaws in evaluation problems in using standard DEA models. They set clear guidelines for improving the performance of the organizations based on the best and worst management environments performance. Heydari et al. [40] presented a fuzzy NDEA-range adjusted measure model for evaluating airlines efficiency. Ghaffari-Hadigheh and Lio [33] considered the NDEA at which both external and internal data are provided by an expert and designed a novel procedure in the efficiency evaluation process of DMUs using the uncertainty theory. Peykani et al. [55] developed a novel fuzzy NDEA approach using adjustable possibilistic programming to the performance evaluation of investment firms.
Ostovan et al. [52] used the α-cut approach to calculate the efficiency of two-stage fuzzy airline networks. The extended model was proposed to the ratio NDEA model. Based on this approach, when the data are in the ratio form, the mentioned model also can evaluate the network systems. They have used the possibility approach to evaluate some investment companies with fuzzy data. Wang and Yao [68] used NDEA with triangular fuzzy data to evaluate the performance of ten supply chains. They analyzed the economic and environmental factors which were effective in the evaluation. Moreover, they discussed how the efficiency of the internal processes of a supply chain can affect the performance of the entire system. Mozaffari et al. [50] proposed a fuzzy linear programming model for solving fuzzy two-stage DEA model in the presence of undesirable outputs. Tavassoli et al. [63] developed a double frontier fuzzy FNDEA model for assessing the sustainable supply chains based on alpha-cut approach.
Motivations and contributions
Different from the above mentioned literature where the series structure and parallel structure as two basic structures of a fuzzy network system have been investigated, this paper investigates a fuzzy relational NDEA model, taking into account the relationship of the processes, to measure the system fuzzy efficiency as well as the processes fuzzy efficiencies. The fuzzy relational NDEA model is represented by a series system where each stage in the series has a parallel structure composed of a number of processes. Accordingly, the fuzzy efficiency decomposition for series systems and for parallel systems is utilized to obtain the mathematical relationship between the system fuzzy efficiency and the processes fuzzy efficiencies based on the alpha cut solution approach. We also show the fuzzy data affects over the efficiency results and the complete ranking of DMUs. However, different from the study of Hatami-Marbini and Saati [38] where (1) works on a simple fuzzy two-stage network with series structure, (2) needs additional effort for complete ranking of all DMUs because of providing interval efficiency and (3) not provide the interval efficiency scores within the interval (0, 1], the proposed method in this study (1) investigates a general fuzzy relational network, (2) ranks the all DMUs directly based on the obtained crisp efficiency and (3) provides the efficiency measures within the range of (0, 1]. Gas refineries are among the most important and strategic industries in any country and play a decisive role in economic development, hence we evaluate the efficiency of Iranian gas refineries using the proposed fuzzy relational network DEA model.
On such motivation basis, the main characteristics of the proposed approach are summarized as follows. (1) The ambiguous and vague input and output data in relational network DEA is reflected in this study by use of fuzzy data. (2) A common-weights relational network DEA model for the network structure with a sort of the interrelated processes is provided to measure the technical efficiency of each production system and their processes when the data are repented by fuzzy data. (3) The proposed fuzzy relational network DEA approach is not only beneficial from computation perspective by solving one LP model for all DMUs, but also equitably evaluate the efficiencies of all DMUs on the same scale by considering common set of weights. (4) In contrast to the existing fuzzy DEA approach that needs solving a non-linear model to calculate the lower upper of the efficiency interval for each DMU at given alpha cut, the proposed approach provides a crisp efficiency by solving linear programming model at the same alpha cut. (5) In contrast to the existing fuzzy DEA approach that needs additional effort for complete ranking of all DMUs because of providing interval efficiency, the proposed method in this study ranks the all DMUs directly based on the obtained crisp efficiency. (6) In contrast to the existing fuzzy DEA approach that does not provide the interval efficiency scores within the interval (0, 1], the proposed fuzzy relational network approach not only provide a unique efficiency instead of interval one, but also provides the efficiency measures within the range of (0, 1].
Organization
The rest of the paper is organized as follows. The next section formulates relational network DEA and defines the concepts of process efficiency and system efficiency. In the subsequent section first, a mathematical formulation is given for a relational network DEA model when the data are presented by fuzzy numbers. Then, an approach is extended to determine the CSW to find the fuzzy efficiency of the processes and the fuzzy efficiency of the system followed by which a numerical example is provided to illustrate the applicability of the proposed solution technique. The sensitive and comparison analysis from different perspectives are discussed next. In the penultimate section, the applicability of the proposed model is illustrated by presenting a case study in gas refineries. The final section concludes and suggests future research directions.
Relational NDEA model
In this section, first, the mathematical model of relational network data envelopment analysis with crisp data is formulated. Then the concept of efficiency for the processes and system of the corresponding model is described [39, 43]. Table 1 enlists all the symbols and notations used in this paper.
Consider a network structure involving three processes. The network system produces \(s\) outputs \(Y = (Y_{1} ,...,Y_{s} )\) by consuming \(m\) inputs \(X = (X_{1} ,...,X_{m} )\). The portion \(X_{i}\), consumed by process 1 to produce \(s_{1}\) outputs \(Y_{r}^{(1)} ,(r = 1,...,s_{1} )\), is denoted by \(X_{i}^{(1)}\). The portion \(X_{i}\), consumed by process 2 to produce \(s_{1}\) outputs \(Y_{p}^{(2)} ,(p = 1,...,s_{2} )\), is denoted by \(X_{i}^{(2)}\). The remaining amount of \(X_{i}\) which has no role in processes 1 and 2, and is consumed by process 3 to produce \(s_{3}\) outputs \(Y_{q}^{(3)} ,(q = 1,...,s_{3} )\) is denoted by \(X_{i}^{(3)}\). In this case, we have
Moreover,
It is worth mentioning that portions of the outputs of processes 1 and 2 are considered as the final output of the system and the remaining amounts of these outputs are considered as the intermediate output consumed by process 3 (inputs of process 3). In this case, the former together \(Y_{q}^{(3)} (q = 1,...,s_{3} )\) are the total output of the system, and the latter together \(X_{i}^{(3)} \,(i = 1,...,m)\) are the inputs of process 3. Figure 1 depicts this situation.

Relational NDE network
Let
It is assumed that \(y_{{r_{t} j}}^{(t)(O)}\) and \(y_{{r_{t} j}}^{(t)(I)}\)(\(t = 1,2\)) represent the final output of the production system and the intermediate output consumed by process 3, respectively. Figure 1 shows that \(\sum_{r = 1}^{{s_{1} }} {u_{r}^{(1)} y_{rj}^{(1)} }\) and \(\sum_{i = 1}^{m} {v_{i} x_{ij}^{(1)} }\) are respectively, the sum of weighted outputs and inputs corresponding to process 1, \(\sum_{p = 1}^{{s_{2} }} {u_{p}^{(2)} y_{pj}^{(2)} }\) and \(\sum_{i = 1}^{m} {v_{i} x_{ij}^{(2)} }\) are, respectively, the sum of weighted outputs and inputs corresponding to process 2; \(\sum_{q = 1}^{{s_{3} }} {u_{q}^{(3)} y_{qj}^{(3)} }\) and \(\sum_{i = 1}^{m} {v_{i} x_{ij}^{(3)} } + \sum_{r = 1}^{{s_{1} }} {u_{r}^{(1)} y_{rj}^{(1)(I)} } + \sum_{p = 1}^{{s_{2} }} {u_{p}^{(2)} y_{pj}^{(2)(I)} }\) are, respectively, the sum of weighted outputs and inputs corresponding to process 3. Moreover, \(\sum_{r = 1}^{{s_{1} }} {u_{r}^{(1)} y_{rj}^{(1)(O)} } + \sum_{p = 1}^{{s_{2} }} {u_{p}^{(2)} y_{pj}^{(2)(O)} } + \sum_{q = 1}^{{s_{3} }} {u_{q}^{(3)} y_{qj}^{(3)} }\) and \(\sum_{i = 1}^{m} {v_{i} x_{ij} }\) are, respectively, the sum of weighted outputs and inputs of the whole system. Hence, the system efficiency of \({\text{DMU}}_{k}\) based on the aforesaid structure is computed by solving the following fractional network data envelopment analysis model [43]:
where \(u_{r}^{(1)}\)\((r = 1,...,s_{1} )\), \(u_{p}^{(2)}\)\((p = 1,...,s_{2} )\), \(u_{q}^{(3)}\), \((q = 1,...,s_{3} )\) and \(v_{i}\) \((i = 1,...,m)\) are the weights associated with outputs of processes 1, 2, 3, and inputs of the system, respectively. Here, the first, second, third, and forth sets of constraints correspond to the efficiency of whole system, process 1, process 2 and process 3, respectively.
The fractional model (1) can be transformed into the following linear one:
After calculating the optimal weights \(u_{r}^{(1)*} \,\,\,(r = 1,...,s_{1} )\),\(u_{p}^{(2)*} \,\,\,(p = 1,...,s_{2} )\), \(u_{q}^{(3)*} \,\,\,(q = 1,...,s_{3} )\) and \(v_{i}^{*} \,\,(i = 1,...,m)\) from model (2), the efficiency of each process for \({\text{DMU}}_{k}\), the ratio of the weighted sum of outputs to the weighted sum of inputs is yielded as follows [43]:
Such a network structure can be converted into parallel and series structures to efficiency decomposition. For this purpose, dummy process 4 is defined before process 3, and dummy process 5 is defined after processes 1 and 2, in which the outputs of each dummy process are the same as its inputs. Figure 2 shows this structure that a series system consists of two stages 1 and 2, and stage 1 consists of a parallel system of three processes 1, 2, and 4, and stage 2 consists of another parallel system of processes 3 and 5. In Fig. 2, \(\sum_{r = 1}^{{s_{1} }} {u_{r}^{(1)*} y_{rk}^{(1)} + \sum_{i = 1}^{m} {v_{i}^{*} x_{ik}^{(3)} } + \sum_{p = 1}^{{s_{2} }} {u_{p}^{(2)*} y_{pk}^{(2)} } }\) and \(\sum_{i = 1}^{m} {v_{i}^{*} x_{ik} }\) give, respectively, the sum of weighted outputs and inputs of stage 1 and, \(\sum_{r = 1}^{{s_{1} }} {u_{r}^{(1)*} y_{rk}^{(1)(O)} } + \sum_{p = 1}^{{s_{2} }} {u_{p}^{(2)*} y_{pk}^{(2)(O)} } + \sum_{q = 1}^{{s_{3} }} {u_{q}^{(3)*} y_{qk}^{(3)} }\) and \(\sum_{r = 1}^{{s_{1} }} {u_{r}^{(1)*} y_{rk}^{(1)} } + \sum_{i = 1}^{m} {v_{i}^{*} x_{ik}^{(3)} } + \sum_{p = 1}^{{s_{2} }} {u_{p}^{(2)*} y_{pk}^{(2)} }\) provide respectively, the sum of weighted outputs and inputs of stage 2. Thus, the system efficiency is obtained by multiplying the efficiencies of stages 1 and 2 (denoted by \(E_{k}^{1}\) and \(E_{k}^{2}\)) [43]:

Efficiency decomposition
If model (1) has multiple optimal solutions, the efficiencies of the three processes will not be unique. On the other hand, solving model (1) for each unit leads to a different set of weights that it is not acceptable that the same factors have different weights. In the next section, a model is presented that not only solves these problems by finding the common set of weights (CSW) but also yields the efficiency of each process and the efficiency of the system with fuzzy data.
Fuzzy relational NDEA model
In this section, we first propose a relational network data envelopment analysis model when the data are presented by fuzzy numbers. Then, an approach is extended to determine the CSW to find the fuzzy efficiency of the processes and the fuzzy efficiency of the system for the aforesaid network structure.
All data in the conventional relational NDEA models are estimated with crisp values. However, in real-life problems, the input and output data inherently are inaccurate and imprecise. To deal with such a situation, DEA models are extended to fuzzy DEA ones. In the present study, the relational NDEA model is extended to a fuzzy environment in which all inputs, outputs, and intermediate measures are expressed by fuzzy numbers. Without loss of generality, triangular fuzzy numbers are used here to represent fuzzy data [16,17,18, 20, 21, 24].
Definition 1
A fuzzy number \(\tilde{A}\), denoted by \(\tilde{A} = (a_{1} ,a_{2} ,a_{3} )\), is called a triangular fuzzy number if its membership function is given as follows [24]:
Definition 2
[17, 18]: A triangular fuzzy number \(\tilde{A} = (a_{1} ,a_{2} ,a_{3} )\), is said to be a positive fuzzy number if \(a_{1} > 0\).
Definition 3
[24]: For any \(0 \le \alpha \le 1\), \(\alpha -\) cut of triangular fuzzy number \(\tilde{A} = (a_{1} ,a_{2} ,a_{3} )\), is defined as \(\left[ {\tilde{A}} \right]_{\alpha } = \left[ {\tilde{A}_{\alpha }^{L} ,\tilde{A}_{\alpha }^{U} } \right] = \left[ {\alpha a_{2} + (1 - \alpha )a_{1} ,\,\alpha a_{2} + (1 - \alpha )a_{3} } \right]\).
Reconsider the network structure with the three processes given in Fig. 1. Inspired by Saati and Memariani [59], the following bounded fuzzy relational NDEA model is proposed to control the flexibility of weights by extending the crisp relational NDEA model (2):
where \(u_{r}^{(1)L}\), \(u_{p}^{(2)L}\), \(u_{q}^{(3)L}\) and \(v_{i}^{L}\) are absolute lower bounds imposed on output weights of processes 1, 2, and 3, and input weight, respectively. Also, \(u_{r}^{(1)U}\), \(u_{p}^{(2)U}\), \(u_{q}^{(3)U}\) and \(v_{i}^{U}\) are absolute upper bounds imposed on output weights of processes 1, 2, and 3, and input weight, respectively.
It is worth mentioning that such boundaries limit the flexibility of the weights to specific ranges and are the same for all units. However, these boundaries must be chosen so that model (5) does not become infeasible.
As mentioned, the bounded fuzzy relational NDEA model (5) does not completely limit the flexibility of weights. For this purpose, in the following, an approach is presented that determines a common set of weights (CSW) for all units. In this approach, a fuzzy linear programming problem corresponding to each factor is first solved to determine the upper bound of each weight. Then, by solving another fuzzy linear programming problem, a CSW is determined based on the obtained upper boundaries.
For this purpose, the following fuzzy problem is first solved to find the upper bound on the output weights of the process 1:
It should be noted that model (6) is a FDEA model. There are several ways to solve FDEA models. A common approach for solving FDEA is the alpha-cut approach introduced by Saati et al. [57], which is used here to solve model (6).
Suppose \(\tilde{x}_{ij} = \left( {x_{ij}^{L} ,x_{ij}^{M} ,x_{ij}^{U} } \right)\), \(\tilde{x}^{(1)}_{ij} = \left( {x_{ij}^{(1)L} ,x_{ij}^{(1)M} ,x_{ij}^{(1)U} } \right)\), \(\tilde{x}^{(2)}_{ij} = \left( {x_{ij}^{(2)L} ,x_{ij}^{(2)M} ,x_{ij}^{(2)U} } \right)\) and \(\tilde{x}^{(3)}_{ij} = \left( {x_{ij}^{(3)L} ,x_{ij}^{(3)M} ,x_{ij}^{(3)U} } \right)\) are, respectively, the fuzzy input of the system, the fuzzy input of process 1, the fuzzy input of process 2, and the fuzzy input of process 3, which all have triangular membership functions. Also, suppose \(\tilde{y}_{rj}^{(1)} = \left( {y_{rj}^{(1)L} ,y_{rj}^{(1)M} ,y_{rj}^{(1)U} } \right)\), \(\tilde{y}_{pj}^{(2)} = \left( {y_{pj}^{(2)L} ,y_{pj}^{(2)M} ,y_{pj}^{(2)U} } \right)\), \(\tilde{y}_{qj}^{(3)} = \left( {y_{qj}^{(3)L} ,y_{qj}^{(3)M} ,y_{qj}^{(3)U} } \right)\), \(y_{rj}^{(1)(O)} = \left( {y_{rj}^{(1)(O)L} ,y_{rj}^{(1)(O)M} ,y_{rj}^{(1)(O)U} } \right)\), \(\tilde{y}_{rj}^{(1)(I)} = \left( {y_{rj}^{(1)(I)L} ,y_{rj}^{(1)(I)M} ,y_{rj}^{(1)(I)U} } \right)\), \(\tilde{y}_{pj}^{(2)(O)} = \left( {y_{pj}^{(2)(O)L} ,y_{pj}^{(2)(O)M} ,y_{pj}^{(2)(O)U} } \right)\) and \(\tilde{y}_{pj}^{(2)(I)} = \left( {y_{pj}^{(2)(I)L} ,y_{pj}^{(2)(I)M} ,y_{pj}^{(2)(I)U} } \right)\) are, respectively, the fuzzy output of process 1, the fuzzy output of process 2, the fuzzy output of process 3 (third fuzzy output of the system), the first fuzzy output of the system, portion of the fuzzy output of the process 1 considered as the first fuzzy input of the process 3 and portion of the fuzzy output of the process 2 considered as the second fuzzy input of the process 3, which all have triangular membership functions. It is obvious that
In this case, the fuzzy model (6) is converted into the following fuzzy program:
Using alpha cuts for the fuzzy parameters of the objective function and constraints, the following interval program is concluded:
Model (8) is an interval linear programming problem that can be solved by inspiring Saati and Memariani’ [59] method. To this end, assume
By substituting the variables given in (9) into model (8), the following model is concluded:
To linearize the nonlinear programming model (10), the following variable substitutions are made [59]:
By substituting the new variables (11) into model (10), the following model is concluded:
Similarly, the following problem is solved to find the upper bound on the output weights of process 2:
Moreover, the following problem is solved to find the upper bound on the output weights of process 3:
Finally, the following problem is solved to find the upper bound on the input weights of the system:
Remark 1
Since the following solution is a feasible solution of linear programming problems (12), then model (12) is a feasible linear programming problem:
It should be mentioned that optimal value of the linear programming problems (12) is bounded and positive. Similarly, assuming each DMU has at least one positive fuzzy undesirable output and one positive fuzzy input, the optimal values of models (13), (14), and (15) are bounded and positive.
Based on the computed upper bounds, a common set of weights is now determined to evaluate the system and processes performances. To this end, considering bounded fuzzy relational NDEA model (5) with bounded weight intervals as \(u_{r}^{(1)} \in \left[ {u_{r}^{(1)L} ,u_{r}^{(1)U} } \right]\),\(u_{p}^{(2)} \in \left[ {u_{p}^{(2)L} ,u_{p}^{(2)U} } \right]\), \(u_{q}^{(3)} \in \left[ {u_{q}^{(3)L} ,u_{q}^{(3)U} } \right]\) and \(v_{i} \in \left[ {v_{i}^{L} ,v_{i}^{U} } \right]\), the common set of weights can be determined by defining identical deviation \(\Omega\) from the lower and upper weight bounds for all DMUs through solving the following fuzzy model:
It should be noted that the value of the deviation variable \(\Omega\) lies within \(\left[ {0,\,0.5} \right]\) and with increasing from zero to 0.5, the range of each weight becomes smaller, and when the value of this variable reaches 0.5, each weight ideally takes the center of its boundary range. The fuzzy model (16) is a nonlinear program because the weights are unknown. To overcome this shortcoming, by assigning the value of zero for all lower bounds of weights and the optimal values of models (12), (13) and (14) for upper bounds of weights, the following fuzzy linear model is resulted:
Similar to the process used to solve model (5), the use of alpha-cut method to solve fuzzy model (17) leads to the following linear programming problem:
The optimal solution of model (18) denoted by \(\left( {v_{i}^{**} ,u_{r}^{(1)**} ,u_{p}^{(1)**} ,u_{q}^{(3)**} } \right)\) is the common set of weights for the given alpha. Based on the obtained optimal solution, the efficiencies of the processes are calculated as follows:
Similarly, according to Fig. 2, for the given alpha, the system efficiency is obtained by multiplying the efficiencies of the first and second stages as follows:
To sum up with all the above aspects, the stepwise procedure of the proposed algorithm for solving fuzzy relational NDEA model (5) is summarized as follows:
Proposed algorithm:
For each \(\alpha\) in \(\left[0.1, 0.2, \dots , 1\right]\) \(\left[ {0,\,0.1,\,0.2,...,1.0} \right]\) do
Let \(\hat{u}_{r}^{(1)} =\) optimal value of model (12) \(\forall r\).
Let \({\widehat{\mathrm{u}}}_{\mathrm{p}}^{\left(2\right)}\) \(\hat{u}_{p}^{(2)} =\) optimal value of model (13) \(\forall \mathrm{p}\) \(\forall p\).
Let \(\hat{u}_{q}^{(3)} =\) optimal value of model (14) \(\forall \mathrm{q}\) \(\forall q\).
Let \(\hat{v}_{i}\) = optimal value of model (15) \(\forall \mathrm{i}\) \(\forall i\).
Let \((\overline{x}^{**} ,\overline{x}^{(1)**} ,\overline{x}^{(2)**} ,\overline{x}^{(3)**} ,\overline{y}^{(1)**} ,\overline{y}^{(2)**} ,\overline{y}^{(3)**} ,\overline{y}_{{}}^{(1)(O)**} ,\overline{y}_{{}}^{(1)(I)**} ,\overline{y}_{{}}^{(2)(O)**} ,\overline{y}_{{}}^{(2)(I)**} )\) = optimal arg-value of model (18) using above weights.
Calculate \({E}_{k}^{\left(1\right)**},{E}_{k}^{\left(2\right)**},{E}_{k}^{\left(3\right)**}\)\(E_{k}^{(1)**} ,\,E_{k}^{(2)**} ,E_{k}^{(3)**}\) from model (19) using \((\overline{x}^{(1)**} ,\overline{x}^{(2)**} ,\overline{x}^{(3)**} ,\overline{y}^{(1)**} ,\overline{y}^{(2)**} ,\overline{y}^{(3)**} ,\overline{y}_{{}}^{(1)(I)**} ,\overline{y}_{{}}^{(2)(I)**} ),\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\forall k\).
Calculate \({E}_{k}^{1**},{E}_{k}^{2**},{E}_{k}^{**}\)\(E_{k}^{1**} ,\,E_{k}^{2**} ,E_{k}^{3**}\) from model (20) using \((\overline{x}^{**} ,\overline{x}^{(3)**} ,\overline{y}^{(1)**} ,\overline{y}^{(2)**} ,\overline{y}^{(3)**} ,\overline{y}_{{}}^{(1)(O)**} ,\overline{y}_{{}}^{(2)(O)**} ),\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\,\forall k\).
End for
It should be noted that all models solved in the proposed algorithm are linear programming problems. Therefore, the complexity of this algorithm is equal to the complexity of the solution algorithm for a problem that has more decision variables and constraints than other linear problems. It has been shown that linear programming problem with m constraints and n decision variables can be solved by the Karmarkar’s projective algorithm and the Khachian’s ellipsoid algorithm within an effort of \(O(n^{4} L)\) and \(O\left( {(m + n)^{6} L} \right)\), respectively. Here \(L\) the input length of the LP problem. Since the problem (18) has \(\left( {5mn + 4n + 2m + 2(S_{1} + S_{2} )n} \right)\) constraints and \(\left( {5mn + 2(S_{1} + S_{2} )n} \right)\) decision variables, thus if the proposed algorithm is used for solving this problem, the complexities of the Karmarkar’s projective algorithm and the Khachian’s ellipsoid algorithm will be \(O\left( {\left( {5mn + 2(S_{1} + S_{2} )n} \right)^{4} L} \right)\) and \(O\left( {\left( {10mn + 4n + 2m + 4(S_{1} + S_{2} )n} \right)^{6} L} \right)\), respectively.
Let us discuss about the main advantages of the proposed fuzzy relational network model over the existing approaches:
-
Triangular and trapezoidal membership functions are most often used for representing fuzzy numbers in real-life applications of fuzzy DEA models [25, 34, 42, 45, 46]. The main reason for using triangular or trapezoidal fuzzy numbers is that they are easy to use and interpret. However, other shapes, such as the power membership function and Gaussian membership function are preferable in some applications. Triangular, trapezoidal, power, and Gaussian fuzzy numbers are all LR flat fuzzy numbers [17, 18]. Since the proposed approach in this research is based on alpha cut of fuzzy data, in contrast to some existing fuzzy DEA approaches, it is applicable for solving fuzzy DEA models involving any kind of LR flat fuzzy numbers.
-
In contrast to fuzzy arithmetic approach [65] that (1) is limited for solving DEA models with triangular fuzzy numbers and (2) ignores the internal structure of production process of a DMU and focus on a single process, the proposed approach (1) can be applied for solving fuzzy relational network DEA models with any kind of flat LR fuzzy numbers, (2) enables us to deal with the mixed network structures, and (3) allows us to consider equality of opportunity in a fuzzy environment when evaluating the system efficiency and the component process efficiencies.
-
Kao and Liu [47] used the extension principle to find the lower and upper bounds of fuzzy efficiency of each DMU in a fuzzy two-stage DEA model. To do this, they solved two distinct mathematical programming models, one liner model for calculating the upper bound and one non-linear model for calculating the lower bound, for each DMU at given alpha level. Hence, that approach needs to solve \(2n\alpha\) models to find the interval efficiency of all DMUs. In contrast to this approach that provides interval efficiency for each DMU and needs an additional effort for complete ranking of all DMUs, our proposed approach gives a crisp efficiency for each DMU at given alpha level. In contrast to Kao and Liu’s [47] approach, the proposed approach in this study solves linear programming models for calculating the fuzzy efficiency of each DMU. Moreover, the proposed fuzzy relational network approach provides the efficiency of all DMUs by solving a single linear model at given alpha level. Finally, the present approach equitably evaluates the efficiencies of the system and their processes for all DMUs by assigning common set of weights.
-
Hatami-Marbini and Saati [38] used the alpha cut approach to find the lower and upper bounds of fuzzy efficiency of each DMU in a fuzzy two-stage DEA model by finding common set of weights. In contrast to Hatami-Marbini and Saati’s [38] approach, the proposed approach in this study enables us to deal with fuzzy mixed network DEA models. Moreover, the common-weights approach proposed by Hatami-Marbini and Saati [38] provides interval efficiencies for all DMUs. However, their proposed formulations to obtain the lower and upper bounds of efficiency measures do not provide the efficiency scores within the interval (0, 1]. Thus, the efficiency values are out of the range (0, 1]. In contrast to that approach, the proposed fuzzy relational network approach not only provide a unique efficiency instead of interval one, but also provides the efficiency measures within the range of (0, 1].
-
In contrast to Kao’s [43] and Hatami-Marbini and Saati’s [38] models, the proposed fuzzy relational network approach in this study not only depicts the impact of fuzzy data on the system efficiency and processes results of the DMUs, but also affects the complete ranking of all DMUs.
-
In contrast to defuzzification approach [66] that ignores the uncertainty in inputs and outputs, the alpha cut approach concerts effort to preserve the fuzzy information without detriment of the decision maker's intuition and subjective judgments in the performance assessment.
-
In contrast to fuzzy ranking approach [34] that ignores the possible range of fuzzy efficiency at given alpha level and requires solving a bi-level linear programming model, the proposed approach requires solving a linear programming problem with less computational effort.
Numerical example
In this section, a numerical example is provided to illustrate the proposed algorithm. The data in Table 2 are inspired by the data from the Kao’s [43] example. This means that the midpoints of the triangular numbers in Table 2 are the same as the data in Kao’s [43] example. The reason for this is to be able to compare the results of the proposed model with the results of the competing models developed in the literature to the same numerical example in the case of crisp data.
Fuzzy inputs and outputs are shown in Table 2.Footnote 1 There are five DMUs in a system with three processes, including two inputs and three outputs. Each of system input is assigned to processes 1, 2, and 3 so that each system input is the sum of the inputs of three processes. Thus, each of processes 1 and 2 consists of two fuzzy inputs and two fuzzy outputs, which are represented by triangular fuzzy numbers. Portions of the outputs of processes 1 and 2 constitute the final output of the system and the remaining portions are considered as the inputs of process 3. Therefore, process 3 consists of one output and four inputs (the remainder of the first input that is not allocated to processes 1 and 2, the remainder of the second input that is not allocated to processes 1 and 2, portion of the output of the process 1, portion of the output of the process 3), which are all represented in terms of triangular fuzzy numbers.
Based on the proposed algorithm, we obtain the efficiency of the three processes and the efficiency of the system for different values of alpha. First, the algorithm is implemented to find the upper bound of the factor weights. Thus, for different values of alpha, models (12–15) are solved based on the data given in Table 2. The results are shown in Table 3.
Now in the next step, model (18) is solved based on the values of Tables 2 and 3 to obtain the optimal solution according to different values of alpha, which leads to the determination of the common set of weights. The results are shown in Tables 4, 5 and 6.
Finally, in the final step, based on the values of Tables 4, 5, and 6, the efficiency of each process and the efficiency of system for each unit are obtained according to different values of alpha. The results are shown in Table 7.
Sensitive and comparison analysis
In this section, the sensitive and comparison analysis are provided from different perspectives. Moreover, the obtained results are compared with those derived from Kao [43] and Hatami-Marbini and Saati [39].
Sensitivity of efficiency results to alpha
One can obtain the membership function of the fuzzy efficiency of the system and fuzzy efficiencies of the processes 1, 2 and 3 at different alpha cuts. For example, Fig. 3 illustrates the membership functions of the fuzzy efficiency of the system and fuzzy efficiencies of the processes 1, 2 and 3 for DMUs A and B. It can be observed that for three processes, DMU B is only efficient in process 2 at \(\alpha = 1\). In a similar way, DMU A is the only efficient unit in process 1 at \(\alpha = 1\) and DMU E is the efficient unit in process 3 at \(\alpha = 1\) and \(\alpha = 0.9\). Moreover, DMUs C and D are inefficient units for all three processes at all given alpha levels. This concludes that none of them are efficient for fuzzy relational network model as there is no DMU with all efficient component processes.

Membership functions of fuzzy efficiencies
As it can be seen from Fig. 3, when the value of alpha increases, then the values of efficiency for all three processes and the system are increased.
On the other hand, the fuzzy efficiency of the system can be obtained by product of two fuzzy efficiencies of the stages 1 and 2 at all alpha levels. For example, at \(\alpha = 0.7\) the fuzzy efficiency of the stages 1 and 2 for DMU D are 0.67 and 0.5972, respectively, and the product of efficiency of stage 1 (0.67) and the efficiency of stage 2 (0.5972) is equal to the efficiency of the system, i.e., 0.4001. The analogous relationship can be seen at other alpha cuts and for all DMUs.
Impact of fuzzy data on ranking and efficiency results
Let us analyze the impact of fuzzy data on the system efficiency and processes results of the DMUs. In this regards, we show that the change in the satisfaction level affects both the efficiency results and the rankings of DMUs. The last two columns of Table 6 gives the fuzzy efficiency of the system for all DMUs at \(\alpha = 0.9\) and \(\alpha = 1\). It can be seen that when the value of satisfaction level is changed the efficiency scores is changed too. Moreover, the complete rankings of DMUs for \(\alpha = 0.9\) and \(\alpha = 1\) are \(E \succ C \succ D \succ B \succ A\) and \(E \succ C \succ B \succ A \succ D\), respectively. It can be observed that DMU A has the last rank at \(\alpha = 0.9\), while this DMU has the fourth rank at \(\alpha = 1\). This indicates with the variation of the satisfaction level, the ranking of DMUs is changed. Moreover, for the process 1 the complete ranking of DMUs at \(\alpha \in \left\{ {0.8,\,0.9,1} \right\}\) is \(A \succ B \succ E \succ D \succ C\), while at \(\alpha = 0.7\) is \(A \succ B \succ E \succ C \succ D\). This indicates the uncertainty in the data affects over the efficiency results of process 1. In short, the efficiency results at different satisfaction levels confirm the influence of the fuzzy data over the complete ranking of DMUs. Table 8 shows the complete ranking of all DMUs at different alpha levels.
Comparison between results of fuzzy CCR model and fuzzy relational NDEA model
Another point worth mentioning is that the performance of individual processes 1, 2 and 3; and whole system can be measured based on fuzzy CCR model by use of their own inputs and outputs in the case that these processes are operated independently of each other. However, such viewpoint has not pay attention to the internal processes of each DMU and thus the obtained results are not acceptable for managers. Hence, it is necessary to consider the internal structure of production system. Clearly, for each given \(\alpha -\)level \(\left\{ {0,\,0.1,\,0.2,\,0.3,\,0.4,\,0.5,\,0.6,\,0.7,\,0.8,\,0.9,\,1} \right\}\), the efficiency of each DMU derived from the fuzzy CCR model will be bigger than the corresponding efficiency derived from the proposed fuzzy relational network model because of imposed additional constraints by three processes. For example, at \(\alpha = 1\), the system efficiencies calculated from the fuzzy CCR model are \(\left\{ {1,0.898,\,0.8485,\,1,\,1} \right\}\) and from the proposed fuzzy relational network model are \(\left\{ {0.4361,0.4543,\,0.5118,\,0.4658,\,0.7836} \right\}\). The same results are obtained for process efficiencies.
Computational and technical comparisons
There are several more points that should be mentioned. First, to compute the system efficiency and process efficiencies, it is required to find the weights assigned to data for all DMUs. According to Kao’s [43] method different values are obtained for the input and outputs weights of DMUs, while based on the proposed fuzzy relational network approach common weights are assigned to the input and outputs which are more reasonable for decision makers. Moreover, to find the corresponding weights, according to Kao’s [43] one model is solved for each DMU, while based on the on the proposed fuzzy relational network approach one model is solved for all DMUs. Thus, our proposed approach is preferred to Kao’s [43] method regarding the number of models being solved and finding the fair weights. Second, the system efficiencies calculated from the Kao’s [43] method are \(\left\{ {0.5227,0.5952,\,0.5682,0.4281,0.8} \right\}\) and from the proposed fuzzy relational network approach are \(\left\{ {0.4361,0.4543,\,0.5118,\,0.4658,\,0.7836} \right\}\) for \(\alpha = 1\)(deterministic case). As the efficiency measures computed by the proposed fuzzy relational network approach do not exceed those derived from Kao’s [43] method, the later has more discriminatory power from the former.
By comparing the results in Table 7 with those in Table 9, we investigate whether the efficiencies of system and processes properly show the performance of all DMUs. In this regard, we do a comparison between the methods proposed by Kao [43] and Hatami-Marbini and Saati [39] (Table 9) and our proposed fuzzy relational network in the case of \(\alpha = 1\)(the last column of Table 9), as our proposed approach gives the fuzzy efficiencies. For process 1, the resulting efficiencies from Kao’s [43] model, Hatami-Marbini and Saati’s [39] model and our proposed model are \(\left\{ {1,0.8188,\,0.5618,\,0.5990,\,0.7273} \right\}\),\(\left\{ {1,0.8000,\,0.5714,\,0.6000,\,0.7273} \right\}\), and \(\left\{ {1,0.7924,\,0.5684,\,0.5985,\,0.7213} \right\}\), respectively, that are quite similar. By taking into account, the ranking order derived from three models, it is observed the obtained rankings are same. Similarly, for process 2, the resulting efficiencies from Kao’s [43] model, Hatami-Marbini and Saati’s [39] and our proposed model are \(\left\{ {0.6613,1,\,0.3796,\,0.6069,\,0.6667} \right\}\), \(\left\{ {0.6429,1,\,0.3750,\,0.6000,\,0.6667} \right\}\), and \(\left\{ {0.6612,1,\,0.3742,\,0.6015,\,0.6512} \right\}\), respectively, that are very similar. However, by taking into account, the ranking order derived from three models, it can be seen that there is a change in the ranks of DMUs A and E between our proposed model and other two models. This means that DMUs A and E are in the second and third places, respectively, while in other two models their ranks are replaced. This confirms that the fuzzy data affects the results. In addition, for process 3, the efficiency results are \(\left\{ {0.3070,0.5003,\,0.7204,\,0.4029,\,1} \right\}\),\(\left\{ {0.3011,0.4912,\,0.6914,\,0.4058,\,1} \right\}\), and \(\left\{ {0.2989,0.4725,\,0.6875,\,0.4012,\,1} \right\}\), respectively, that are very similar too. Moreover, the rankings derived from three models are the same. Finally, for the system efficiency, the results are \(\left\{ {0.4744,0.5895,\,0.5209,\,0.4706,\,0.7931} \right\}\),\(\left\{ {0.4667,0.5833,\,0.5133,\,0.4702,\,0.7931} \right\}\), and \(\left\{ {0.4361,0.4543,\,0.5118,\,0.4658,\,0.7836} \right\}\), respectively, which are very similar. However, there are a difference in positions A and D among Kao’s [43] model, Hatami-Marbini and Saati’s [39] model and our proposed one. It means that DMUs A and D are in fourth and fifth places in Kao’s model, respectively, while these DMUs are in fifth and fourth places in Hatami-Marbini and Saati’s [39] and our proposed models. Generally speaking, speaking, the system efficiency scores obtained from our method are not exceeded those calculated from Kao’s [43] and Hatami-Marbini and Saati’s [39] models. Hence, the proposed method is preferable considering it increases the discriminatory power of the model against those models. Moreover, to compute the system efficiencies using the model proposed by Kao [43], the optimal weights assigned to inputs and outputs take different values for a specific DMU, which might be in question for the managers, whereas our proposed method yields the common base for the evaluating the efficiencies considering a common-weights fuzzy NDEA model. In sum, from the processes, stages and system viewpoints, it can been seen that in the case of \(\alpha = 1\), efficiency scores calculated form our proposed model are often smaller than those calculated from Kao [43] and Hatami-Marbini and Saati [39]. This confirms that the processes, stages and system efficiency scores calculated form our proposed model appropriately present the performance of all DMUs.
Application in oil and gas refineries
In this section, we evaluate the performance of 15 oil and gas companies of Iran in 2018 based on the proposed relational network DEA model.
The Central Oil Company of Iran, established in 1998, is one of the five oil and gas companies and the second largest gas producer in the country. This company is responsible for production and development of some geographical areas which are facing the fuel shortages such as Lorestan, Kordestan, Kermanshah, Markazi, Qom, Ilam, Khorasan, West and East Azerbaijan, Ardebil, Fars, Bushehr, Hormozgan, and Chaharmahal Bakhtiari. Currently, about half of the gas required by the country is supplied by the 15 mentioned gas supply operational zones. The Central Oil Company is responsible for the development and production of more than 80 gas and oil fields. The company’s headquarters, which handles how to develop and spread resources to other places and control the strategy of the whole system, is located in Tehran and the headquarters of the West, East, and South Zagros’s oil companies, are located in Kermanshah, Mashhad, and Shiraz, respectively.
The main goals of these oil and gas companies are supplying the annual oil and gas production required by other subdivided areas, Reducing the deviation from the schedule and financial planning of field development projects, Reducing the volume of associated gases and oil burned, and also the risk of hazards in the workplace, increasing production capacity, optimization of energy consumption in activities, compliance of design and, implementation of projects with technical specifications specialized national/international standards.
Here, 15 operational areas of gas supply in a network system in 2018 are studied. Gas transmission conditions depend on different parameters, therefore high gas pressure or gas pressure drop causes problems in the gas transmission network. For this reason, cities located near gas refineries or cities that are far away may face gas service problems. In general, each gas supply operation area has two inputs \(\left( {x_{1} ,x_{2} } \right)\) for the whole system, which are divided into three processes and three final outputs \(\left( {y^{(O)(1)} ,y^{(O)(2)} ,y^{(3)} } \right)\) coming out of the three processes. The data of the gas supply operation area in the network structure is based on the gas transfer process, which is considered as triangular fuzzy numbers. The process performed in each operational area of gas supply depends on the distance of gas lines to gas pressure control stations. The distance of gas transmission lines of the first process is less than 200 (km). In the second process, this distance is between 200 and 410 (km) and in the third process, the distance is more than 410 (km). Inputs \(x_{1}\) and \(x_{2}\) are the two quantities of inlet gas flow in the first process (depending on the distance considered). The outputs \(y^{(O)(1)}\), \(y^{(O)(2)}\) and \(y^{(3)}\) are the amount of gas that can be released from the first, second, and third processes, respectively. Table 10 shows the dates of 15 gas companies in Iran that are responsible to supply the needed of other smaller gas companies in the country.
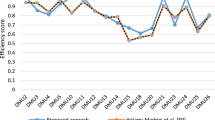
Now, we analyze the performance of these 15 gas companies by considering the internal structure using the proposed algorithm. The common set of weights of all inputs and outputs are provided using the proposed algorithm for different values of alpha, which are shown in Table 11. As can be seen from Table 10, the obtained CWS can be categorized into five groups:\(\alpha \in \left\{ {0.0,\,0.1,0.2,0.6} \right\}\), \(\alpha \in \left\{ {0.3,0.4} \right\}\), \(\alpha = 0.5\), \(\alpha \in \left\{ {0.7,0.8,0.9} \right\}\) and \(\alpha = 1\). This means that all inputs and outputs have the same CWS for \(\alpha \in \left\{ {0.0,\,0.1,0.2,0.6} \right\}\) and so on. By employing the provided CWS, the system efficiency and three processes efficiencies can be calculated using the proposed algorithm as listed in Table 12 for different values of alpha.
Let us interpret the observed results in the case of \(\alpha = 0.8\) as given in Table 12. According to obtained results, Refineries 13 and 12 are known as the best and the worst system efficiency among the refineries. However, the management team is interested to know about the source of inefficiency of Refinery 12 to make appropriate decisions. The results show that this refinery has the weakest performance in Process 2 and Process 3 compared to other refineries. However, this refinery has not bad performance in Process 1 compared to other refineries. In a similar way, in the case of \(\alpha = 0.3\), Refinery 4 has the second rank of system efficiency among the refineries. Although this refinery has not good performance in Process 1 and Process 3, but its performance is very effective in Process 1. Hence, according to this approach it is possible to management team to distinguish the source of efficiency and inefficiency for different values of alpha. Such approach enables management team to make appropriate decisions.
The complete rank of all refineries in terms of system efficiency and process efficiency for different values of alpha is reported in Table 13.
Conclusions
Traditional DEA models with measuring the efficiency of a system based on black-box structure does not attention to the structure of a production system. Hence, in this study we formulated relational network DEA model to account the relationship between the efficiency of system and efficiencies of the processes. On the other hand, in real application of relational network DEA models, the input and output data are imprecise. To deal with such imprecise data, we incorporated the fuzzy notion into the relational network DEA model. We have utilized the alpha cut approach for calculating the fuzzy efficiency scores of all DMUs in the proposed fuzzy relational NDEA model based on common sets of weights. The proposed fuzzy approach was useful to recognize the impact of fuzzy data on both efficiency results and complete ranking of DMUs. Finally, we evaluated the performance of 12 gas refineries in Iran based on the proposed fuzzy model.
The main limitations of the proposed method in practical applications can be summarized as follows:
-
The proposed approach for solving fuzzy relational NDEA model increases the number of constraints significantly rather than the primary fuzzy DEA model. This issue can increase the complexity of the model for large-scale real-world applications.
-
The proposed algorithm gives the membership functions of the fuzzy efficiency scores numerically. Thus, the proposed algorithm cannot be useful for situations in which decision makers needs the exact form of membership functions for the fuzzy efficiency scores.
-
In addition to desirable outputs, undesirable outputs often arise in the production process in real-world applications, especially when evaluating environmental performance. Thus, the performance evaluation becomes more complex when desirable outputs and undesirable outputs simultaneously exist in the system.
Based on the mentioned limitations, the future research can be extended in various directions. Some of these are discussed below.
-
Development of a new fuzzy approach that not only decreases the number of constraints but also provides the exact form of membership functions is left to the next study.
-
Development of the proposed fuzzy relational NDEA model in the presence of undesirable outputs could be an interesting topic for future research.
-
The study can also be extended to many practical applications such as fuzzy transportation problem [6, 7] and fuzzy shortest path problem [5, 26, 28, 53].
-
The proposed approach for fuzzy relational network DEA models in fuzzy environment can be developed for solving them in intuitionistic fuzzy environments [23] and interval-valued fuzzy environments [17,18,19].
Notes
The data used in this study can be observed at the web address http://nigtc.ir/en-US/IGTC/1/page/Home, which is the official website of the Iranian gas transmission company.
References
Adler N, Liebert V, Yazhemsky E (2013) Benchmarking airports from a managerial perspective. Omega 41(2):442–458
Amin GR, Toloo M (2007) Finding the most efficient DMUs in DEA: an improved integrated model. Comput Ind Eng 52(1):71–77
An Q, Meng F, Xiong B, Wang Z, Chen X (2020) Assessing the relative efficiency of Chinese high-tech industries: a dynamic network data envelopment analysis approach. Ann Oper Res 290:707–729
Arana-Jiménez M, Sánchez-Gil MC, Lozano S (2020) A fuzzy DEA slacks-based approach. J Comput Appl Math. https://doi.org/10.1016/j.cam.2020.113180
Bagheri M, Ebrahimnejad A, Razavyan S, HosseinzadehLotfi F, Malekmohammadi N (2021) Solving fuzzy multi-objective shortest path problem based on data envelopment analysis approach. Complex Intell Syst 7:725–740. https://doi.org/10.1007/s40747-020-00234-4
Bagheri M, Ebrahimnejad A, Razavyan S, HosseinzadehLotfi F, Malekmohammadi N (2020) Solving the fully fuzzy multi-objective transportation problem based on the common set of weights in DEA. J Intell Fuzzy Syst 39(3):3099–3124
Bagheri M, Ebrahimnejad A, Razavyan S, HosseinzadehLotfi F, Malekmohammadi N (2020) Fuzzy arithmetic DEA approach for fuzzy multi-objective transportation problem. Oper Res Int J. https://doi.org/10.1007/s12351-020-00592-4
Banker RD, Charnes A, Cooper WW (1984) Some models for estimating technical and scale inefficiencies in data envelopment analysis. Manag Sci 30(9):1078–1092
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision-making units. Eur J Oper Res 2(6):429–444
Cook WD, Roll Y, Kazakov A (1990) A DEA model for measuring the relative efficiency of highway maintenance patrols. INFOR Inf Syst Oper Res 28(2):113–124
Cheng P et al (2021) Asynchronous fault detection observer for 2-D Markov jump systems. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2021.3112699
Cheng P, He S, Stojanovic V, Luan X, Liu F (2021) Fuzzy fault detection for Markov jump systems with partly accessible hidden information: an event-triggered approach. IEEE Trans Cybern. https://doi.org/10.1109/TCYB.2021.3050209
Chen TCT, Wang YC (2021) A fuzzy mid-term capacity and production planning model for a manufacturing system with cloud-based capacity. Complex Intell Syst 7:71–85. https://doi.org/10.1007/s40747-020-00177-w
Chen Y, Zhu J (2004) Measuring information technology’s indirect impact on firm performance. Inf Technol Manag 5(1–2):9–22
Das SK (2021) An approach to optimize the cost of transportation problem based on triangular fuzzy programming problem. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00535-2
Ebrahimnejad A (2015) A duality approach for solving bounded linear programming problems with fuzzy variables based on ranking functions and its application in bounded transportation problems. Int J Syst Sci 46(11):2048–2060
Ebrahimnejad A (2016) New method for solving fuzzy transportation problems with LR flat fuzzy numbers. Inf Sci 37:108–124
Ebrahimnejad A (2016) Fuzzy linear programming approach for solving transportation problems with interval-valued trapezoidal fuzzy numbers. Sadhana 41(3):299–316
Ebrahimnejad A (2021) An acceptability index based approach for solving shortest path problem on a network with interval weights. RAIRO Oper Res 55(1):1568–1587
Ebrahimnejad A, JafarnejadGhomi S, Mirhosseini-Alizamini SM (2018) A revisit of numerical approach for solving linear fractional programming problem in a fuzzy environment. Appl Math Model 57:459–473
Ebrahimnejad A, Nasseri SH, HoseinzadehLotfi F, Soltanifar M (2010) Bounded linear programs with trapezoidal fuzzy numbers. Internet J Uncertain Fuzziness Knowl Based Syst 8(3):269–286
Ebrahimnejad A, Tavana M, HosseinzadehLotfi F, Shahverdi R, Yousefpour M (2014) A three-stage data envelopment analysis model with application to banking industry. Measurement 49:308–319
Ebrahimnejad A, Verdegay JL (2016) An efficient computational approach for solving type-2 intuitionistic fuzzy numbers based transportation problems. Int J Comput Intell Syst 9(6):1154–1173
Ebrahimnejad A, Verdegay JL (2018) Fuzzy sets-based methods and techniques for modern analytics. Springer, New York
Ebrahimnejad A, Amani N (2021) Fuzzy data envelopment analysis in the presence of undesirable outputs with ideal points. Complex Intell Syst 7:279–400
Ebrahimnejad A, Enayattabr M, Motameni H et al (2021) Modified artificial bee colony algorithm for solving mixed interval-valued fuzzy shortest path problem. Complex Intell Syst 7:1527–1545. https://doi.org/10.1007/s40747-021-00278-0
Emrouznejad A, Tavana M, Hatami-Marbini A (2014) The state of the art in fuzzy data envelopment analysis. In: Emrouznejad A, Tavana M (ed) Performance measurement with fuzzy data envelopment analysis. Springer, Berlin, pp 1–45
Enayattabar M, Ebrahimnejad A, Motameni H (2019) Dijkstra algorithm for shortest path problem under interval-valued Pythagorean fuzzy environment. Complex Intell Syst 5:93–100. https://doi.org/10.1007/s40747-018-0083-y
Entani T, Maeda Y, Tanaka H (2002) Dual models of interval DEA and its extension to interval data. Eur J Oper Res 136(1):32–45
Färe R, Grosskopf S (1996) Productivity and intermediate products: a frontier approach. Econ Lett 50(1):65–70
Färe R, Grosskopf S, Lundgren T, Marklund PO, Zhou W (2016) The impact of climate policy on environmental and economic performance: evidence from Sweden. Routledge, London
Gidion DK, Hong J, Adams MZ, Khoveyni M (2019) Network DEA models for assessing urban water utility efficiency. Utilities Policy 57:48–58
Ghaffari-Hadigheh A, Lio W (2020) Network data envelopment analysis in uncertain environment. Comput Ind Eng 148:106657
Guo P, Tanaka H (2001) Fuzzy DEA: a perceptual evaluation method. Fuzzy Sets Syst 119:149–160
Hatami-Marbini A, Tavana M, Agrell PJ, Lotfi FH, Beigi ZG (2015) A common-weights DEA model for centralized resource reduction and target setting. Comput Ind Eng 79:195–203
Hatami-Marbini A, Emrouznejad A, Tavana M (2011) A taxonomy and review of the fuzzy data envelopment analysis literature: two decades in the making. Eur J Oper Res 214(3):457–472
Hatami-Marbini A, Ebrahimnejad A, Lozano S (2017) Fuzzy efficiency measures in data envelopment analysis using lexicographic multiobjective approach. Comput Ind Eng 105:362–376
Hatami-Marbini A, Saati S (2018) Efficiency evaluation in two-stage data envelopment analysis under a fuzzy environment: a common-weights approach. Appl Soft Comput 72:156–165
Hatami-Marbini A, Saati S (2020) Measuring performance with common weights: network DEA. Neural Comput Appl 32:3599–3617
Heydari C, Omrani H, Taghizadeh R (2020) A fully fuzzy network DEA-range adjusted measure model for evaluating airlines efficiency: a case of Iran. J Air Transp Manag 89:101923
HosseinzadehLotfi F, Hatami-Marbini A, Agrell PJ, Aghayi N, Gholami K (2013) Allocating fixed resources and setting targets using a common-weights DEA approach. Comput Ind Eng 64(2):631–640
Kachouei M, Ebrahimnejad A, Bagherzadeh-Valami H (2020) A common-weights approach for efficiency evaluation in fuzzy data envelopment analysis with undesirable outputs: application in banking industry. J Intell Fuzzy Syst 39(5):7705–7722
Kao C (2009) Efficiency decomposition in network data envelopment analysis: a relational model. Eur J Oper Res 192:949–962
Kao C, Hwang SN (2008) Efficiency decomposition in two-stage data envelopment analysis: an application to non-life insurance companies in Taiwan. Eur J Oper Res 185(1):418–429
Kao C, Liu ST (2000) Fuzzy efficiency measures in data envelopment analysis. Fuzzy Sets Syst 113(3):427–437
Kao C, Liu ST (2003) A mathematical programming approach to fuzzy efficiency ranking. Int J Prod Econ 86(2):145–154
Kao C, Liu ST (2011) Efficiencies of two-stage systems with fuzzy data. Fuzzy Sets Syst 176(1):20–35
Lovell CK, Walters LC, Wood LL (1994) Stratified models of education production using modified DEA and regression analysis. In: Data envelopment analysis: theory, methodology, and applications. Springer, Dordrecht, pp 329–351
Lin TY, Chiu SH (2013) Using independent component analysis and network DEA to improve bank performance evaluation. Econ Model 32:608–616
Mozaffari MR, Mohammadi S, Wanke PF, Correa HL (2021) Towards greener petrochemical production: two-stage network data envelopment analysis in a fully fuzzy environment in the presence of undesirable outputs. Expert Syst Appl 164:113903
Noulas AG, Lazaridis J, Hatzigayios T, Lyroudi K (2001) Non-parametric production frontier approach to the study of efficiency of non-life insurance companies in Greece. J Financ Manag Anal 14(1):19
Ostovan S, Mozaffari MR, Jamshidi A, Gerami J (2020) Evaluation of Two-Stage Networks Based on Average Efficiency Using DEA and DEA-R with Fuzzy Data. Int J Fuzzy Syst 22(5):1665–1678
Parimala M, Broumi S, Prakash K et al (2021) Bellman-Ford algorithm for solving shortest path problem of a network under picture fuzzy environment. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00430-w
Peykani P, Mohammadi E (2018) Interval network data envelopment analysis model for classification of investment companies in the presence of uncertain data. J Ind Syst Eng 11(Special issue: 14th International Industrial Engineering Conference):63–72
Peykani P, Mohammadi E, Emrouznejad A (2021) An adjustable fuzzy chance-constrained network DEA approach with application to ranking investment firms. Expert Syst Appl 166:113938
Roll Y, Cook WD, Golany B (1991) Controlling factor weights in data envelopment analysis. IIE Trans 23(1):2–9
Saati S, Memariani A, Jahanshahloo GR (2002) Efficiency analysis and ranking of DMUs with fuzzy data. Fuzzy Optim Decis Mak 1:255–267
Saati S, Hatami-Marbini A, Agrell PJ, Tavana M (2012) A common set of weight approach using an ideal decision-making unit in data envelopment analysis. J Ind Manag Optim 8(3):623
Saati S, Memariani A (2005) Weight flexibility in fuzzy DEA. Appl Math Comput 161:611–622
Shermeh HE, Najafi SE, Alavidoost MH (2016) A novel fuzzy network SBM model for data envelopment analysis: a case study in Iran regional power companies. Energy 112:686–697
Sun Y, Yu N, Huang B (2021) Green road–rail intermodal routing problem with improved pickup and delivery services integrating truck departure time planning under uncertainty: an interactive fuzzy programming approach. Complex Intell Syst. https://doi.org/10.1007/s40747-021-00598-1
Tavana M, Khalili-Damghani K, Arteaga FJS, Hosseini A (2019) A fuzzy multi-objective multi-period network DEA model for efficiency measurement in oil refineries. Comput Ind Eng 135:143–155
Tavassoli M, Fathi A, Saen RF (2021) Assessing the sustainable supply chains of tomato paste by fuzzy double frontier network DEA model. Ann Oper Res. https://doi.org/10.1007/s10479-021-04139-4
Tüysüz F, Şimşek B (2017) A hesitant fuzzy linguistic term sets-based AHP approach for analyzing the performance evaluation factors: an application to cargo sector. Complex Intell Syst 3(3):167–175
Wang YM, Luo Y, Liang L (2009) Fuzzy data envelopment analysis based upon fuzzy arithmetic with an application to performance assessment of manufacturing enterprises. Expert Syst Appl 36(3):5205–5211
Wang YM, Chin KS (2011) Fuzzy data envelopment analysis: a fuzzy expected value approach. Expert Syst Appl 38(2011):11678–11685
Wang CH, Lu YH, Huang CW, Lee JY (2013) R&D, productivity, and market value: an empirical study from high-technology firms. Omega 41(1):143–155
Wang L, Yao C (2020) Non-radial fuzzy network DEA model based on directional distance function and application in supply chain efficiency evaluation. In: Proceedings of the sixth international forum on decision sciences. Springer, Singapore, pp 251–273
Yu MM, Lin ET (2008) Efficiency and effectiveness in railway performance using a multi-activity network DEA model. Omega 36(6):1005–1017
Yu MM (2010) Assessment of airport performance using the SBM-NDEA model. Omega 38(6):440–452
Yu S, Liu J, Li L (2020) Evaluating provincial eco-efficiency in China: an improved network data envelopment analysis model with undesirable output. Environ Sci Pollut Res 27:6886–6903
Yu MM, Lin C, Chen KC, Chen LH (2021) Measuring Taiwanese bank performance: a two-system dynamic network data envelopment analysis approach. Omega 98:102145
Zhao Y, Triantis K, Murray-Tuite P, Edara P (2011) Performance measurement of a transportation network with a downtown space reservation system: a network-DEA approach. Transport Res Part E Logist Transport Rev 47(6):1140–1159
Zadeh LA (1965) Fuzzy sets. Inf Control 8(3):338–353
Zhang X et al (2021) Asynchronous fault detection for interval type-2 fuzzy nonhomogeneous higher-level Markov jump systems with uncertain transition probabilities. IEEE Trans Fuzzy Syst. https://doi.org/10.1109/TFUZZ.2021.3086224
Zhu J (2003) Imprecise data envelopment analysis (IDEA): A review and improvement with an application. Eur J Oper Res 144(3):513–529
Zhu QX, Zhang C, He YL, Xu Y (2018) Energy modeling and saving potential analysis using a novel extreme learning fuzzy logic network: a case study of ethylene industry. Appl Energy 213:322–333
Zhou X, Wang Y, Chai J, Wang L, Wang S, Lev B (2019) Sustainable supply chain evaluation: a dynamic double frontier network DEA model with interval type-2 fuzzy data. Inf Sci 504:394–421
Acknowledgements
The authors would like to thank the anonymous reviewers and the associate editor for their insightful comments and suggestions.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Tabatabaei, S., Mozaffari, M.R., Rostamy-Malkhalifeh, M. et al. Fuzzy efficiency evaluation in relational network data envelopment analysis: application in gas refineries. Complex Intell. Syst. 8, 4021–4049 (2022). https://doi.org/10.1007/s40747-022-00687-9
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-022-00687-9