
Abstract
Federated learning (FL) is a distributed learning approach, which allows the distributed computing nodes to collaboratively develop a global model while keeping their data locally. However, the issues of privacy-preserving and performance improvement hinder the applications of the FL in the industrial cyber-physical systems (ICPSs). In this work, we propose a privacy-preserving momentum FL approach, named PMFL, which uses the momentum term to accelerate the model convergence rate during the training process. Furthermore, a fully homomorphic encryption scheme CKKS is adopted to encrypt the gradient parameters of the industrial agents’ models for preserving their local privacy information. In particular, the cloud server calculates the global encrypted momentum term by utilizing the encrypted gradients based on the momentum gradient descent optimization algorithm (MGD). The performance of the proposed PMFL is evaluated on two common deep learning datasets, i.e., MNIST and Fashion-MNIST. Theoretical analysis and experiment results confirm that the proposed approach can improve the convergence rate while preserving the privacy information of the industrial agents.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Industrial cyber-physical system (CPS) is an emergent technology that focuses on the integration of computational applications with physical devices [1,2,3]. Industrial CPSs facilitate the remote control of large-scale heterogeneous systems, big data analysis, and condition monitoring, which has a high impact on various industrial fields [2, 4,5,6,7,8]. Industrial CPSs contain many edge devices which collect a huge amount of data, which is very helpful for developing deep learning-based methods to solve difficult industrial tasks, such as fault diagnosis [9, 10], intelligent control [11], degradation prediction [12], smart city [13], etc. The conventional centralized learning approach (CL) centralizes all the distributed data to a central server for model training. However, if the central server is attacked, the data resources may be revealed, which may result in very bad consequences. In addition, due to business competition and privacy concerns, the data holders (i.e., industrial agents) are unwilling to share their local datasets.
To address this problem, the federated learning (FL) approach is proposed to control multiple training participants to collaboratively train a global model [14, 15]. In the FL system, the training participants only share the gradients of their local models to the cloud server instead of raw data. The central cloud is responsible for updating the global model by aggregating the gradients shared by the training participants and sending the updated global model parameters to all participants. Since the FL can effectively solve data island issues, it has aroused widespread concern in many industrial fields. For instance, Li et al. [16] presented a FL-based CNN-GRU model for intrusion detection that can effectively detect different types of network threats. Kwon et al. [17] proposed a solution for joint cell association and resource allocation in smart ocean scenarios. The authors utilize the FL technologies to meet the requirements of distributed computing and unexpected time-varying states. Liu et al. [18] proposed an FL-based gated recurrent unit neural network for predicting the traffic flow. Brisimi et al. [19] developed a FL-based prediction model to predict the hospitalization of patients suffering from various heart diseases using electronic health records distributed among different data sources. This not only improves the model performance but also ensures the patients’ privacy. Zhang et al. [20] proposed a FL-based fault diagnosis method for the rolling bearing of the rotating machinery that combines a dynamic verification scheme and a self-supervised learning scheme.
Various extension methods are proposed to improve the performance of the FL. Yu et al. [21] explained the effectiveness of periodic averaging of a specific model and adopted the parallel mini-batch stochastic gradient descent (SGD) for reducing communication costs. Wang et al. [22] proposed a cooperative SGD framework that combines the periodic-averaging, elastic averaging, and decentralized SGD for simultaneously optimizing the communication cost. Zhao et al. [23] proposed a strategy for globally sharing the small data subsets among all the edge devices to improve the accuracy of FL training on non-IID data. Most of the existing research takes advantage of the first-order gradient descent (GD) for increasing the efficiency of training; however, these techniques do not consider that the previous iterative gradient update potentially accelerates the convergence speed. Liu et al. [24] proposed momentum federated learning (MFL) which uses momentum term to accelerate the convergence during the process of local model training. These works effectively improve the performance of FL; however, they do not consider the privacy concerns appropriately.
Recent studies demonstrate that the FL techniques also suffer from privacy security issues. Wang et al. [25] proposed a framework that combines the generative adversarial networks (GANs) with multitasking discriminators to obtain specific private data from samples without interfering with FL processes. Zhu et al. [26] discussed that the gradient transmission in FL systems may leak the private data without relying on the model generation or prior knowledge of data. Therefore, privacy protection methods for the FL have been proposed. Geyer et al. [27] utilized differential privacy technologies to protect the privacy of distributed participants in the FL system. Triastcyn et al. [28] proposed a Bayesian differential privacy method for FL, which can flexibly adjust the injection noise to provide a stringent privacy guarantee. Aono et al. [29] introduced homomorphic encryption schemes in the FL to protect the data resources of distributed participants. These research works effectively preserve the privacy information in FL under their respective security assumptions. However, they do not consider improving the convergence performance of the FL.
For industrial CPSs, it is necessary that the FL not only performs efficiently in terms of model accuracy, convergence rate, and communication costs but also preserves the privacy information of the industrial agents. To meet the above requirements, we introduce the momentum term to accelerate the convergence rate of the FL system. Furthermore, the CKKS scheme is used to preserve the privacy information of industrial agents. The contributions of this work are summarized below:
-
1.
We utilize momentum term to accelerate the convergence rate for the privacy-preserving federated learning approach. In particular, the momentum term is calculated by the cloud server to update the global model parameters, which can reduce the cryptography computing and communication costs.
-
2.
To protect the data privacy of the industrial agents, we design a CKKS-based communication scheme, where the industrial agents use the CKKS encryption method to encrypt their gradient parameters.
-
3.
We evaluate the effectiveness of the proposed approach on MNIST and Fashion-MNIST datasets. The experiment results show that the proposed PMFL improves the convergence rate while preserving the data resources of industrial agents.
The rest of this article is organized as follows. In the next section, we introduce the system model and theoretical background. In the subsequent section, we discuss two existing solutions: privacy-preserving federated learning and momentum federated learning followed by which the proposed PMFL approach is presented in detail. Then we analyze the functionality, security and communication costs of the PMFL. The experiment results are presented in the penultimate section. The final section concludes this work and introduces our future research directions.
System model and theoretical background
System model
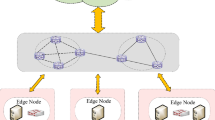
In this work, the proposed FL system comprises three participants, i.e., trust authority, cloud server, and multiple industrial agents, as shown in Fig. 1.
-
1.
Trust authority The trust authority is responsible for ensuring the start-up of the proposed FL system. It produces the public and private keys according to the CKKS-based secure communication protocol. The security communication channels are also established by the trust authority.
-
2.
Cloud server The cloud server updates the global model by aggregating all the model parameters uploaded by different industrial agents. It is also responsible for sharing the updated global model with all the industrial agents.
-
3.
Industrial agents Each industrial agent trains the model locally using its local dataset and continuously sends the model parameters to the cloud server. After downloading the updated global model, the global weight parameters are loaded as the local models.

The architecture of the FL system
Threat model In the proposed model, we assume that the trust authority is completely honest and rational. Hence, it never colludes with the cloud server and the outsiders. In addition, we assume that the cloud server and the industrial agents are honest-but-curious entities who execute the protocols correctly but try to extract additional information by inferring the intermediate data. Based on the assumptions, this work aims to preserve the privacy information of the individual agents during the entire training process (see Table 1).
Full homomorphic encryption
Fully homomorphic encryption (FHE) is a homomorphic technique that can perform multiple mathematical operations on encrypted data [30]. For a typical secure computing scheme, the distributed nodes use FHE to encrypt the data, and the encrypted data are sent to the cloud server. Then the cloud server can perform mathematical operations on the encrypted data without decryption, and send the encrypted results to the distributed nodes. In the scheme, the cloud server is unable to obtain the actual data since the encrypted data cannot be decrypted without the availability of the secret key, and the distributed nodes cannot obtain other nodes’ data. CKKS [31] is an FHE-based technique for performing approximate calculation algorithms. The CKKS adds noise after data encryption via ciphertext truncation. Due to this, the resultant scheme has excellent encryption/decryption speed [32]. Therefore, we adopt the CKKS-based communication protocol in the proposed method.
Model parameters leak information
In Fig. 2, a sample neural network with three layers is used to illustrate how the model parameters may leak the information of the input data, where xi denotes the input data, yi denotes the truth label, wi denotes the weight parameters of the neural network, and b denotes the bias.

A typical neural network model
The forward propagation of the network is calculated using the following expression, where f () denotes the sigmoid function.
The loss value of the model is calculated as
Then, the gradients of the model are calculated as
From Eqs. (4)–(6), we observe that
Therefore, the cloud server can infer the input data xi of the industrial agent. From Fig. 3, we can notice that a certain percentage of the image may leak its core information.

Images with different proportions of information leakage
After the input data xi is obtained, the model output is calculated through forwarding propagation. The true value of the label y is inferred using Eqs. (9)–(10). Now, the information of the input data is completely leaked.
Existing solutions
Privacy-preserving federated learning
By utilizing homomorphic encryption technologies, the privacy-preserving federated learning (PFL) [29] has been proposed to protect the data resources of the training participants. In the PFL system, the training participants calculate the gradients of their local models and encrypt the gradients based on the homomorphic encryption method. Then, the industrial agents upload the encrypted gradients to the cloud server. Using these encrypted gradients, the cloud server updates the global model parameters and sends the encrypted global weight parameters to all the training participants. This is mathematically expressed as
where Enc() denotes the encryption function, wglobal denotes the weight parameters of the global model, η denotes the learning rate, Da,i denotes the total number of training samples for training participant i, and ga,i denotes the gradients of the ith training participant.
Momentum federated learning
Momentum gradient descent algorithm (MGD) is an improved method for the gradient descent algorithm (GD) to speeding up the learning process. In the GD, the update change of parameters is calculated by η▽L(w(t-1)) which is only proportional to the gradients of the model. As shown in Fig. 4, the update path of the GD is oscillatory because its update direction is always along gradient descent. In the MGD, the update change of parameters consists of η▽L(w(t-1)) and γ(w(t-2)-w(t-1)) which is the momentum term to effectively mitigate the oscillation caused by the GD. Momentum term corrects the parameter update direction so that the iterations of the MGD scheme reaching the optimal point are less than that of the gradient descent algorithm. In Fig. 4, the momentum term corrects the parameter update direction so that the iterations of MGD reaching the optimal point are less than that of the GD, which demonstrates that mitigating the oscillation by MGD leads to a faster convergence rate.

Comparison of the MGD and the GD
Since solutions to convergence acceleration can improve the training efficiency of the FL, Liu et al. [10] proposed Momentum Federated Learning (MFL), where the training participants utilize momentum term to improve the convergence rate. The detailed process is described below.
1. Initialization The initial values of momentum parameters va,i(0) and model weight parameters wa,i(0) are initialized.
2. Industrial agent local training The MGD algorithm is used by each industrial agent to calculate va,i and wa,i on its respective local dataset, which can be expressed as
where t denotes the iteration index of local training.
3. Cloud server parameter aggregation The cloud server aggregates the parameters upload by the industrial agents to update the global model. The global momentum parameters vglobal and global model parameters weight wglobal are aggregated by taking a weighted average of va,i and wa,i. This is expressed in Eqs. (15) and (16). Finally, the global parameters vglobal and wglobal are transmitted to all the industrial agents for the next training process.
where |Da,i| denotes the data size of the industrial agent i.
The proposed framework
In this section, we elaborate on the PMFL framework by introducing the implement procedure for the FL-based application first, and then presenting the workflow of the PMFL, followed by the CKKS-based secure communication scheme.
Implement procedure for the FL-based application
As the FL can solve data barrier issues, it can be utilized to develop deep learning-based applications, which mainly involves five steps as shown in Fig. 5 [15]. First, each industrial agent obtains training samples. Secondly, the agents use the same preprocessing method to process raw data for improving model performance. Then, with the assistance of the cloud server, the industrial agents collaboratively train a global model utilizing their training samples according to the federated learning framework (detailed in Sect. 4.1). Finally, the trained model is evaluated on testing data. In this section, we present the proposed PMFL and its technical details.

The typical procedures of the FL-based application implementation
The workflow for PMFL
The workflow of the PMFL comprises three phases: system initialization, local model training by industrial agents, and model parameter aggregation executed by the cloud server. The detail of each phase is presented below (see also Fig. 6 and Algorithm 1):

The workflow of the proposed PMFL
1. System initialization The trust authority generates the public key \({\mathcal{P}\mathcal{K}}\) and the private key \({\mathcal{S}\mathcal{K}}\) based on the CKKS encryption, and the cloud server establishes secure communication channels. Each industrial agent initializes the weight parameters of its local model wa,i. Then, each agent encrypts its weights by using the public key. The encrypted parameters are transmitted to the cloud server. Then the could server computes the global model by aggregating all the uploaded parameters. Finally, the server sends the initialized global model Enc(wglobal) to all the industrial agents.
2. Local model training by industrial agents After receiving the encrypted global model parameters, i.e., Enc(wglobal), from the cloud server, each industrial agent uses the private key \({\mathcal{S}\mathcal{K}}\) to decrypt the weight parameters Enc(wglobal) and obtains wglobal. After model decryption, the agent loads wglobal in its local model, and calculates the gradients of the local model ga,i using the private data resource. Lastly, the agent uses the public key to encrypt the gradients and sends Enc(ga,i) to the cloud server.
3. Model parameter aggregation by the cloud server After receiving the encrypted gradients Enc(ga,i) from each industrial agent, the cloud server calculates the encrypted global momentum term Enc(vglobal(t)) using Eq. (17), where na,i denotes the total number of training samples for industrial agent i. Then, the encrypted global parameters Enc(wglobal(t)) are updated using Eq. (18), and sent Enc(wglobal(t)) the parameters to the industrial agents.

CKKS-based secure communication protocol
Various research works [33,34,35] indicated that the encryption/decryption operations of homomorphic encryption are computationally expensive. However, the CKKS as an emerging encryption scheme has excellent encryption speed compared to the Paillier and RSA encryption schemes [36, 37]. To improve the training efficiency of the FL system, the proposed approach uses the CKKS scheme to preserve the data resources of the industrial agents.
In the PMFL, the CKKS encryption scheme is used to encrypt the model parameters. \({\mathcal{R}}\) represents a polynomial ring ℤ[X]/(Xn + 1). We use \({\mathcal{R}}\) to denote ℤ[X]/(Xn + 1) with integer coefficients modulo \({\mathcal{R}}\)q. Similarly, we use [x]q to denote x mod q. Please note that < a,b > denotes the inner product of vectors a and b. The CKKS-based secure communication protocol includes the following four functions (detailed in [31]).
1. KeyGenerate(1λ) Given a security parameter λ, we set a ring degree n, a ciphertext modulus q, and a special modulus p which is coprime of q. The trust authority generates the secret key \({\mathcal{S}\mathcal{K}}\) and the public key \({\mathcal{P}\mathcal{K}}\) as per the standard defined by CKKS cryptosystem.
2. ParaEncrypt(m, \({\mathcal{P}\mathcal{K}}\)): We sample v ← χenc and e0,e1 ← χerr, and encrypt the model parameter using the public key \({\mathcal{P}\mathcal{K}}\) by
where m denotes the plaintext.
3. ParaAggregate(Enc(m1),…, Enc(mN)): The cloud server aggregates the encrypted parameters Enc(mk)\( \in {\mathcal{R}}_{{q_{L} }}^{2}\) to update the momentum or global model parameters by
4. ParaDecrypt(Enc(magg), \({\mathcal{S}\mathcal{K}}\)): The industrial agents use the secret key \(SK\) to decrypt the encrypted parameters of the global model sent by the cloud server using the following technique.
Algorithm analysis
Functionality analysis
In Table 2, we present the functional comparison of various FL techniques, such as DPFL [28], PFL [29], and MFL [24]. The DPFL and the PFL preserve the privacy of the industrial agents. However, both solutions do not use the momentum parameters to accelerate the rate of convergence. Contrary, the MFL utilizes the momentum to accelerate the training process; however, it does not preserve the privacy of the industrial agents. The proposed PMFL incorporates the momentum parameters to improve the convergence rate while preserving the privacy of the industrial agents using the CKKS encryption scheme.
Security analysis
CPA-secure: For each probabilistic polynomial-time (PPT) and an adversary \({\mathcal{A}}\), there is a negligible function negl, such that
Π = (Gen, Enc, Dec) is a CPA security encryption method in which the probability is provided by the randomness of the adversary \({\mathcal{A}}\) and the randomness of the experiment (the generated \({\mathcal{P}\mathcal{K}}\), random bit, and any randomness used in the encryption process). Based on this definition, we obtain the following:
-
All the encryption techniques that meet the CPA security, can guarantee security even in the presence of eavesdroppers.
-
All the deterministic encryption schemes do not satisfy the CPA security, and the encryption scheme that fulfills the CPA security must be probabilistic encryption.
We assume that the commutation channel between each industrial agent and the cloud server is sufficiently secure. This allows the server to verify the integrity of the uploaded data and prevent the potential attackers from performing any malicious activity, such as injecting their own data. The intermediate data obtained by the industrial agents and the cloud server during the training process are presented in Table 3. It is noteworthy that during the training process, each industrial agent can only obtain the encrypted weight parameters of the global model Enc(wglobal) from the cloud server, the cloud server only receives the encrypted gradient parameters of the models Enc(gglobal) from each industrial agent, and sends back the encrypted global model parameters Enc(wglobal).
Theorem 1
In the PMFL, if CKKS is CPA-secure, and there is no collusion between industry agents and the cloud server/external attacker, the data privacy of the industrial agents can be preserved.
Proof Assume that there is an adversary \({\mathcal{A}}\) who eavesdrops on the encrypted weight parameters of all the models. Since the adversary does not know the security parameter λ of the CKKS scheme, \({\mathcal{A}}\) cannot generate the secret key \({\mathcal{S}\mathcal{K}}\). Based on the above security assumptions, all industrial agents do not collude with the cloud server or any external member, and \({\mathcal{S}\mathcal{K}}\) will not be leaked. Therefore, \({\mathcal{A}}\) is unable to obtain the key \({\mathcal{S}\mathcal{K}}\) and decrypt the encrypted parameters to obtain the true values. At the same time, the weight parameters of the model are stored on the cloud server in the ciphertext form. As long as the cloud server does not conspire with any industrial agents, each industrial agent cannot obtain the model parameters uploaded by other industrial agents for inferring their data resources. In addition, the agents transmit information to the cloud server through different secure communication channels, thereby preventing the transmitted information from being stolen. Therefore, the proposed PMFL can effectively protect the private information of the industrial agents.
Communication cost analysis
We assume that the FL system includes N industrial agents. We set the length of wglobal and ga,i without considering the increase in the transmission cost of the ciphertext. The communication costs of the PMFL is further analyzed and compared with the MFL.
Communication cost of the proposed PMFL For each round of model aggregation, the industrial agents send Enc(ga,i) to the cloud server and receive Enc(wglobal) from the cloud server. The communication costs of the cloud server and each industrial agent are O((|Enc(ga,i)|·N) + O(|Enc(wglobal)|)·N) and O(|Enc(ga,i)|) + O(|Enc(wglobal)|), respectively.
Communication cost for the MFL For each model aggregation, each industrial agent sends va,i and wa,i to the cloud server and receives global v and w from the cloud server. The communication costs of the cloud server and each industrial agent are O((|va,i| +|wa,i|)·N) + O((|vglobal| +|wglobal|)·N) and O(|va,i| +|wa,i|) + O(|vglobal| +|wglobal|), respectively.
In Table 4, we present a comparison of the communication cost of the proposed PMFL and the MFL. The above analyses show that the communication cost of the PMFL is lower than the MFL.
Performance evaluation
In this section, we present the simulation results to evaluate the performance of the proposed PMFL method. We first present the simulation setup, which includes the environmental setup, data resource description, and performance metrics. Then, we evaluate the proposed PMFL.
Experiment settings
The hardware operating environment is Intel CPU i7-6550, RAM 16 GB, and NVIDIA 1080Ti. We build the FL system using Python, NumPy, Pytorch, MATLAB, and CUDA. The MNIST dataset and Fashion-MNIST (F-MNIST) are used to evaluate the performance of the proposed FL system. The MNIST dataset contains 60,000 training samples and 10,000 test samples. It has 10 categories, and each sample is a 28 × 28 grayscale image. The F-MNIST data are similar to the MNIST dataset.
In this work, the FL system includes four industrial agents. To simulate real industrial scenarios, the datasets are split into non-independent and identically distributed (Non-IID) datasets, which indicates that all data held by an industrial agent have the same label (if there are more labels than the number of the industrial agents, each industrial agent have data with more than one label but not the total number of labels). That is in accordance with the real industrial scenarios since the training data are generally difficult to be achieved.
Convolutional neural network (CNN) has been widely used in computer vision and image recognition fields. Therefore, referring to Pytorch tutorials, a CNN model is selected as the local model of the industrial agents for evaluating the performance of the proposed PMFL approach. The construction parameters of the CNN are listed in Table 5. The mini-batch size of the industrial agents is set to 64.
Case 1 (comparisons of different learning approaches)
In this subsection, we evaluate the performance of CL, FL, MFL and PMFL. The experimental curves and classification results of different learning approaches are presented in Fig. 7 and Table 6, respectively. In general, there is a performance gap between the FL and the CL. It can be seen from Fig. 7 that the accuracy and the loss value curves of the PMFL are closer to the CL compared to the FL. As listed in Table 6, the PMFL achieves the classification accuracies of 86.53% and 98.13% on F-MNIST dataset and MNIST dataset, respectively. The classification results of the PMFL are very close to the CL and superior to the FL. Compared with the MFL, the PMFL not only has almost the same performance but also saves half of the communication cost between the cloud server and the industrial agents.

The experiment curves of different learning approaches
Case 2 (varying experiment setting)
In this subsection, we verify the convergence performance of the PMFL and explore the effects of the momentum rate γ and the number of the industrial agents N on the PMFL convergence by simulation evaluation.
.1 Varying momentum rates In this subsection, the experiment curves of the proposed PMFL with different momentum rates are presented in Fig. 8. When the momentum rate γ is set to 0, the PMFL is the same as the traditional PFL. From the figure, it can be noticed that the accuracy curves with different momentum rates have a consistent overall trend. The convergence speed of PMFL is improved with the increasing momentum rate. The classification results of the proposed PMFL with different momentum rates are listed in Table 7. When γ = 0.6, the PMFL has the best classification performance on F-MNINST and MNIST datasets. The classification results reveal that the classification performance of the PEMFL is affected by the momentum rate. Therefore, the momentum rate value needs to be appropriately selected instead of just a large value.

The experiment curves of the PMFL with different momentum rates
2. Varying numbers of industrial agents For this case, we set the momentum rate γ to 0.5 and varies the number of industrial agents N. The experiment curves of the PMFL with different numbers of the industrial agents are shown in Fig. 9. The classification results of the proposed PMFL with different N are listed in Table 8. The trend of the curves shows the convergence performance of the PMFL. It can be noticed that when N increases from 4 to 32, the PMFL achieves the classification accuracies of 80.09–86.53% and 95.91–98.13% on F-MNIST dataset and MNIST dataset, respectively. Further analysis of Table 8 shows that the convergence speed of the PMFL slows as the number N increases, because the model aggregation process utilizes more data. Consequently, the PMFL has a bright prospect in the CPSs with multiple industrial agents.

The classification results of the CNN-based PMFL with different numbers of Industrial Agents
Case 3 (hyperparameter tuning)
Liking most deep learning tasks, the hyperparameters of the CNN trained by the FL need to be tuned for improving model accuracy. In this subsection, the first hyperparameter to tune is the learning rate η. We set momentum rate γ to 0.5 and mini-batch to 64. The learning rate η is set to be from 0.01 to 0.1. The learning rate tuning results of the PMFL are shown in Fig. 10.

The learning rate tuning results of the PMFL on F-MNIST and MNIST datasets
The second hyperparameter to tune is the momentum rate γ. From the above results, we set the learning rate η = 0.07 for the F-MNIST task and η = 0.08 for the MNIST task. The momentum rate γ is set to be from 0.1 to 0.9. The learning rate tuning results of the PMFL are shown in Fig. 11. From the above results, we set the momentum rate γ = 0.5 for the F-MNIST task and γ = 0.7 for the MNIST task.

The momentum rate tuning of the PMFL on F-MNIST and MNIST datasets
Based on the above results, we set learning rate η to 0.08, momentum rate γ to 0.7 and mini-batch size to 64 for MNSIT task, and learning rate η to 0.07, momentum rate γ to 0.5 and mini-batch size to 64 for MNSIT task.
Conclusions
In this work, we present a privacy-preserving momentum federated learning (PMFL) for industrial cyber-physical systems (ICPSs). In the proposed FL approach, a CKKS-based secure communication protocol is designed to guarantee the privacy of the industrial agents by encrypting the weight parameters of the local models. The momentum term is utilized in the PMFL to accelerate the convergence rate. In particular, the momentum term is calculated in the cloud server, which reduces the communication costs compared to the MFL. Theoretical analysis and experiment results demonstrate that the proposed approach can effectively preserve the local privacy of the industrial agents and has high accuracy as well.
In future work, we aim to further investigate the process of model aggregation for alleviating the adverse effects of the industrial agents with low-quality training data, and use intelligent algorithms to tune hyper-parameters of the FL to achieve better model performance.
References
Huang S, Lin C, Zhou K, Yao Y, Lu H, Zhu F (2020) Identifying physical-layer attacks for IoT security: An automatic modulation classification approach using multi-module fusion neural network. Phys Commun 43:101180
Ding D, Han Q, Wang Z, Ge X (2019) A survey on model-based distributed control and filtering for industrial cyber-physical systems. IEEE Trans Ind Inf 15:2483–2499
Yang F, Gu S (2021) Industry 4.0, a revolution that requires technology and national strategies. Complex Intel Syst 7(3):1–15
Chen H, Zhang Z, Guan C, Gao H (2020) Optimization of sizing and frequency control in battery/supercapacitor hybrid energy storage system for fuel cell ship. Energy 197:117285
Zhang Z, Guan C, Liu Z (2020) Real-time optimization energy management strategy for fuel cell hybrid ships considering power sources degradation. IEEE Access 8:87046–87059
Khalid A, Kirisci P, Khan ZH, Ghrairi Z, Thoben K, Pannek J (2018) Security framework for industrial collaborative robotic cyber-physical systems. Comput Ind 97:132–145
Khalifa AH, Shehata MK, Gasser SM, El-Mahallawy MS (2020) Enhanced cooperative behavior and fair spectrum allocation for intelligent IoT devices in cognitive radio networks. Phys Commun 43:101190
Huo W, Li W, Zhang Z, Sun C, Zhou F, Gong G (2021) Performance prediction of proton-exchange membrane fuel cell based on convolutional neural network and random forest feature selection. Energy Convers Manag 243:114367
Gong W, Chen H, Zhang Z, Zhang M, Wang R, Guan C, Wang Q (2019) A novel deep learning method for intelligent fault diagnosis of rotating machinery based on improved CNN-SVM and multichannel data fusion. Sensors 19:1693
Zhang J, Huang K (2020) Fault diagnosis of coal-mine-gas charging sensor networks using iterative learning-control algorithm. Phys Commun 43:101175
Lan Y, Li F, Li Z, Yue B, Zhang Y (2020) Intelligent IoT-based large-scale inverse planning system considering postmodulation factors. Complex Intell Syst, pp 1–15
Zuo B, Cheng J, Zhang Z (2021) Degradation prediction model for proton exchange membrane fuel cells based on long short-term memory neural network and Savitzky-Golay filter. Int J Hydrog Energy 46(29):15928–15927
Gomathi P, Baskar S, Shakeel PM (2020) Concurrent service access and management framework for user-centric future internet of things in smart cities. Complex Intell Syst 7:1723–1732
Zhu H, Zhang H, Jin Y (2020) From federated learning to federated neural architecture search: a survey. Complex Intell Syst 7:639–657
Zhang Z, Xu X, Gong W, Chen Y, Gao H (2021) Efficient federated convolutional neural network with information fusion for rolling bearing fault diagnosis. Control Eng Pract 116:104913
Li B, Wu Y, Song J, Lu R, Li T, Zhao L (2020) DeepFed: Federated deep learning for intrusion detection in industrial cyber-physical systems. IEEE Trans Ind Inf 17:5615–5624
Kwon D, Jeon J, Park S, Kim J, Cho S (2020) Multiagent DDPG-Based Deep Learning for Smart Ocean Federated Learning IoT Networks. IEEE Internet Things J 7:9895–9903
Liu Y, James JQ, Kang J, Niyato D, Zhang S (2020) Privacy-preserving traffic flow prediction: a federated learning approach. IEEE Internet Things J 7:7751–7763
Brisimi TS, Chen R, Mela T, Olshevsky A, Paschalidis IC, Shi W (2018) Federated learning of predictive models from federated electronic health records. Int J Med Inf 112:59–67
Zhang W, Li X, Ma H, Luo Z, Li X (2021) Federated learning for machinery fault diagnosis with dynamic validation and self-supervision. Knowl-Based Syst 213:106679
Yu H, Yang S, Zhu S (2019) Parallel restarted SGD with faster convergence and less communication: demystifying why model averaging works for deep learning. In: Proceedings of the AAAI Conference on Artificial Intelligence, 2019, pp 5693–5700
Wang J, Joshi G. Cooperative SGD: A unified framework for the design and analysis of communication-efficient SGD algorithms[C]//ICML Workshop on Coding Theory for Machine Learning. 2019.
Zhao Y, Li M, Lai L, Suda N, Civin D, Chandra V (2018) Federated learning with non-iid data. arXiv preprint arXiv:1806.00582
Liu W, Chen L, Chen Y, Zhang W (2020) Accelerating Federated Learning via Momentum Gradient Descent. IEEE Trans Parallel Distrib Syst 31:1754–1766
Wang Z, Song M, Zhang Z, Song Y, Wang W, Qi H (2019) Beyond inferring class representatives: user-level privacy leakage from federated learning. In: IEEE INFOCOM 2019-IEEE Conference on computer communications, IEEE, 2019, pp 2512–2520
Zhu L, Han S (2020) Deep Leakage from Gradients. In: Yang Q, Fan L, Yu H (eds) Federated Learning. Lecture Notes in Computer Science, Vol. 12500. Springer, Cham. https://doi.org/10.1007/978-3-030-63076-8_2
RGeyer RC, Klein T, Nabi M (2017), Differentially private federated learning: a client level perspective. arXiv preprint arXiv:1712.07557
Triastcyn A, Faltings B (2019) Federated learning with Bayesian differential privacy. In: 2019 IEEE International Conference on Big Data (Big Data), IEEE, 2019, pp 2587–2596
Aono Y, Hayashi T, Phong LT, Wang L (2016) Privacy-preserving logistic regression with distributed data sources via homomorphic encryption. IEICE Trans Inf Syst, 99(8):2079–2089
Sumathi M, Sangeetha S (2020) A group-key-based sensitive attribute protection in cloud storage using modified random Fibonacci cryptography. Complex Intell Syst, pp 1–15
Cheon JH, Kim A, Kim M, Song Y (2017) Homomorphic encryption for arithmetic of approximate numbers. In: Takagi T, Peyrin T (eds) Advances in Cryptology-ASIACRYPT 2017. ASIACRYPT 2017. Lecture Notes in Computer Science, Vol. 10624. Springer, Cham. https://doi.org/10.1007/978-3-319-70694-8_15
Ou W, Zeng J, Guo Z, Yan W, Liu S, Fuentes S (2020) Ahomomorphic-encryption-based vertical federated learning scheme for rick management. Comput Sci. Inf Syst 17(3):819–834
Hao M, Li H, Xu G, Liu S, Yang H (2019) Towards efficient and privacy-preserving federated deep learning. In: ICC 2019–2019 IEEE International Conference on Communications (ICC), IEEE, 2019, pp 1–6
Li L, Fan Y, Tse M, Lin K (2020) A review of applications in federated learning. Comput Ind Eng 149:106854
Zhou C, Fu A, Yu S, Yang W, Wang H, Zhang Y (2020) Privacy-preserving federated learning in fog computing. IEEE Internet Things J 7:10782–10793
Chen H, Dai W, Kim M, et al. Efficient multi-key homomorphic encryption with packedciphertexts with application to oblivious neural network inference[C]. In: Proceedings of the2019 ACM SIGSAC Conference on Computer and Communications Security. 2019: 395–412.
Liu X, Li H, Xu G, Liu S, Liu Z, Lu R (2020) PADL: privacy-aware and asynchronous deep learning for IoT applications. IEEE Internet Things J 7:6955–6969
Acknowledgements
This work was supported in part by National Natural Science Foundation of China (51909200), International S&T Cooperation Program of China (2019YFE0104600), Tianjin Research Innovation Project for Postgraduate Students (2019YJSB06).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Zhang, L., Zhang, Z. & Guan, C. Accelerating privacy-preserving momentum federated learning for industrial cyber-physical systems. Complex Intell. Syst. 7, 3289–3301 (2021). https://doi.org/10.1007/s40747-021-00519-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00519-2