
Abstract
How to select the optimal strategy to compete with rivals is one of the hottest issues in the multi-attribute decision-making (MADM) field. However, most of MADM methods not only neglect the characteristics of competitors’ behaviors but also just obtain a simple strategy ranking result cannot reflect the feasibility of each strategy. To overcome these drawbacks, a two-person non-cooperative matrix game method based on a hybrid dynamic expert weight determination model is proposed for coping with intricate competitive strategy group decision-making problems within q-rung orthopair fuzzy environment. At the beginning, a novel dynamic expert weight calculation model, considering objective individual and subjective evaluation information simultaneously, is devised by integrating the superiorities of a credibility analysis scale and a Hausdorff distance measure for q-rung orthopair fuzzy sets (q-ROFSs). The expert weights obtained by the above model can vary with subjective evaluation information provided by experts, which are closer to the actual practices. Subsequently, a two-person non-cooperative fuzzy matrix game is formulated to determine the optimal mixed strategies for competitors, which can present the specific feasibility and divergence degree of each competitive strategy and be less impacted by the number of strategies. Finally, an illustrative example, several comparative analyses and sensitivity analyses are conducted to validate the reasonability and effectiveness of the proposed approach. The experimental results demonstrate that the proposed approach as a CSGDM method with high efficiency, low computation complexity and little calculation burden.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Two-person non-cooperative competitions exist universally in real-world practices. The selection of the optimal competitive strategy is vital for players to survive from current intensified competitive circumstances. Nevertheless, on account of the large number of optional strategies, competitive strategy group decision making (CSGDM) has become an extremely challenging issue facing decision makers. Hence, CSGDM problems in two-person non-cooperation competitions have captured increasing attention from specialists and practitioners [1, 2].
Matrix game theory is an effective tool for portraying two-person non-cooperation competitions and has been applied to some fields such as advertising, biology, emergency and military issues [3,4,5]. Matrix game theory considers the characteristics of players’ non-cooperative behaviors and aims to solve the conflict of interests between players. The players in a matrix game aim at maximizing their own benefits, which highly abstracts from CSGDM problems. CSGDM via solving a matrix game can not only obtain the optimal strategy in the form of probabilities but also get the value of the game, which is hard to achieve with most other methods. In addition, results obtained by matrix game are able to reflect the divergence degree between any two alternatives, while most other methods, for instance, multi-attribute decision-making (MADM) methods [6,7,8], usually order the strategies based on simple sorting results.
The general model of matrix game utilizes crisp values [9]; however, the complexity of real world determines that players cannot estimate exactly payoff outcome. Under this circumstance, fuzzy matrix game methods in uncertain environments can be viewed as an interesting topic for CSGDM problems. To describe the complicated uncertain scenarios, Zadeh [10] introduced the definition of fuzzy sets, assigning a grade of membership to each object belongs to the fuzzy sets. After that, fuzzy sets have been applied into many competitive strategy decision-making problems in uncertain situations widely because they can character the complex world more accurately [11, 12]. Atanassov [13] modified the version of fuzzy sets and first proposed the concepts of intuitionistic fuzzy sets (IFSs) which are nonstandard fuzzy subsets. The users can evaluate the support for and against membership of each object in the IFSs synchronously. A distinguishing feature of the IFSs is that the summation of the support for membership degree \(u\) and the support against membership degree \(v\) satisfies the condition that \(u + v \le 1\). Nevertheless, IFSs cannot express some particular attributes if \(u + v > 1\). Although Yager [14] developed the Pythagorean fuzzy sets (PFSs) in which \(u^{2} + v^{2} \le 1\) to depict decision-making systems with intricate fuzzy messages, PFSs are also restricted by real world. To solve this plight thoroughly, Yager [15] explored q-rung orthopair fuzzy sets (q-ROFSs) by means of broadening the scopes of IFSs and PFSs. The q-ROFSs, satisfying \(u^{q} + v^{q} \le 1\), are generalizations of IFSs and PFSs because q-ROFSs can be transformed into different forms by choosing different values of parameter \(q\). Obviously, q-ROFSs are more general and can expand the range of users’ application. Due to the high efficiency of q-ROFSs, many scholars have made some contributions under the q-ROF circumstances currently. For example, Yang et al. [16] initiated q-rung orthopair fuzzy interaction weighted Heronian mean operators by considering the interactive characteristics of decision matrix. Liu and Wang [17] established q-rung orthopair fuzzy generalized Maclaurin symmetric mean operators to tackle MADM problems. Zeng et al. [18] proposed a novel induced weighted logarithmic distance measure for handling MADM problems within q-ROF environment. Riaz et al. [19] introduced two q-ROF hybrid aggregation operators and applied q-ROF TOPSIS method to cope with a transport policy problem. Garg et al. [20] and Liu et al. [21] improved q-ROFSs and developed complex q-rung orthopair fuzzy set (Cq-ROFS) for dealing with awkward and complicated information. Thereafter, Garg et al. [22] presented generalized dice similarity measures for Cq-ROFSs. Mahmood and Ali [23] investigated a novel TOPSIS MADM method based on a complex q-rung orthopair fuzzy correlation coefficient measure. Riaz et al. [24] combined the idea of q-ROFS and m-polar fuzzy set to propose q-rung orthopair m-polar fuzzy sets which are generalizations of Pythagorean m-polar fuzzy sets [25]. Although there are some researches, regarding matrix game methods by utilizing IFSs and PFSs, can be found in the existing literatures, they will lose efficacy in complicated CSGDM problems where \(u^{2} + v^{2} > 1\). Therefore, it is vacant but crucial to explore fuzzy matrix game methods for CSGDM problems in q-rung orthopair fuzzy contexts.
The determination of experts’ weights is a momentous link belongs to the process of CSGDM, which has direct impacts on the final results. The more accurate the experts’ weights are, the more valid the decision result is. Most of the existing literatures have taken a constant experts’ weight assumption in the study process [26,27,28]. However, due to the fact that experts are discrepant concerning knowledge backgrounds, experiences, psychological behaviors or some aspects, the importance degrees of experts are often dissimilar and tend to be changed. Thus, it is reasonable to assign each expert a weight dynamically according to the individual experts’ basic information and evaluation results. Even if several scholars have attempted to eliminate the irrationality caused by constant decision makers’ weights in decision process via variable weights theory [29, 30], the experts’ individual evaluation abilities are neglected in most decision-making processes. To remedy this gap, this paper established a hybrid dynamic expert weight determining method integrating the credibility degree of experts and discrepancy degree of subjective evaluation information provided by experts. Inspired by Zhang [31], an expert credibility analysis scale consists of experts’ individual information is designed to reflect the experts’ assessment abilities and credibility degree. In addition, considering that distance is an efficient mathematical implement for measuring the discrepancy degree between two objects [32,33,34], a q-rung orthopair fuzzy Hausdorff distance measure, generalizations of Hamming distance and Euclidean distance, is defined for calculating the discrepancy degree of subjective evaluation information.
On account of the foregoing analyses, this paper aims at proposing a novel two-person fuzzy matrix game method for tackling CSGDM problems accurately and efficiently. In brief, the contributions of this manuscript mainly consist of three aspects:
-
(i)
q-ROFSs, generations of IFSs and PFSs, are employed to express the uncertainty and vague of competitive strategy group decision-making environment, which can extend the application range of the proposed approach.
-
(ii)
With the help of a credibility analysis scale and q-ROF Hausdorff distance, a novel expert weight calculation method, combining both objective individual and subjective evaluation information, is developed to determine the variable experts’ weights legitimately and comprehensively.
-
(iii)
A fuzzy two-person matrix game within the q-ROF environment is formulated to select the optimal mixed strategies in the form of probabilities, which can portray the behavior characteristics of participants in competitive strategy group decision-making problems.
-
(iv)
An illustrative example, regarding the selection of the most desirable market share competitive strategy, is conducted. Several comparative analyses and sensitive analyses are performed to verify the availability of the proposed approach. The experimental results show that the proposed game method can directly obtain the priorities of the competitive strategies with high efficiency, little calculation burden and low calculation complexity.
The remaining structure of this paper is as follows: the basic concepts, including q-rung orthopair fuzzy sets, Hausdorff distance as well as two-person matrix game, are briefly reviewed in the next section. The third section proposes a two-person matrix game on the strength of the variable weights’ theory and q-ROFS. In the fourth section, an illustrate example, several comparative analyses and sensitivity analyses are presented to verify the availability of the proposed approach, and then the advantages with limitations of the proposed approach are stated. Finally, the last section discusses the conclusion of this paper.
Preliminaries
q-rung orthopair fuzzy set
The q-rung orthopair fuzzy set (q-ROFS) [15] was explored to remedy the shortages of IFSs and PFSs. The general definitions and operational laws of q-ROFSs are as shown follows.
Definition 1 [15]
Suppose \(X\) be a space of points. A q-ROFS \(A\) on \(X\) can be characterized as
where for all \(x \in X\), \(u_{A} :X \to \left[ {0,1} \right]\) indicates membership grade and \(v_{A} :X \to \left[ {0,1} \right]\) indicates non-membership grade of \(x\), severally, with \(0 \le (u_{A} (x)^{q} + v_{A} (x)^{q} ) \le 1,{\kern 1pt} {\kern 1pt} {\kern 1pt} (q \ge 1)\). The uncertainty degree is described as \(\pi_{A} (x) = (u_{A} (x)^{q} + v_{A} (x)^{q} - u_{A} (x)^{q} v_{A} (x)^{q} )^{1/q}\). For convenience’s sake, \(\left\langle {u_{A} (x),v_{A} (x)} \right\rangle\) is named as a q-ROFN, symbolized by \(A = \left\langle {u_{A} ,v_{A} } \right\rangle\).
Definition 2 [35]
The score value \(S(A)\) and accuracy value H(A) of a q-ROFN \(A\) can be given by
Obviously, \(S(A) \in \left[ { - 1,1} \right]\) and \(H(A) \in \left[ {0,1} \right]\). The larger the score \(S(A)\) and the accuracy degree \(H(A)\) are, the greater \(A\) is.
On this basis, a comparative approach of q-ROFNs is presented as follows.
Definition 3 [35]
Suppose \(a = \left\langle {u_{a} ,v_{a} } \right\rangle\) and \(b = \left\langle {u_{b} ,v_{b} } \right\rangle\) are two q-ROFNs. Then, they obey the following comparative rules:
-
(i)
If \(S(a) > S(b)\), then \(a > b\);
-
(ii)
If \(S(a) = S(b)\), then
If \(H(a) > H(b)\), then \(a > b\);
If \(H(a) = H(b)\), then \(a = b\).
Let \(\alpha = \left\langle {u,v} \right\rangle\), \(\alpha_{1} = \left\langle {u_{1} ,v_{1} } \right\rangle\), and \(\alpha_{2} = \left\langle {u_{2} ,v_{2} } \right\rangle\) be any three q-ROFNs. Then, the fundamental algorithms can be represented as follows:
-
(1)
\(\alpha^{c} = \left\langle {v,u} \right\rangle\);
-
(2)
\(\alpha_{1} \oplus \alpha_{2} = \left\langle {(u_{1}^{q} + u_{2}^{q} - u_{1}^{q} u_{2}^{q} )^{1/q} ,v_{1} v_{2} } \right\rangle\);
-
(3)
\(\lambda \alpha_{1} = \left\langle {(1 - (1 - u_{1}^{q} )^{\lambda } )^{1/q} ,v_{1}^{\lambda } } \right\rangle\), for any \(\lambda > 0\);
-
(4)
\(Max\left\langle {\alpha_{1} ,\alpha_{2} } \right\rangle = \left\langle {\max \left\{ {u_{1} ,u_{2} } \right\},\min \left\{ {v_{1} ,v_{2} } \right\}} \right\rangle\);
-
(5)
\(Min\left\langle {\alpha_{1} ,\alpha_{2} } \right\rangle = \left\langle {\min \left\{ {u_{1} ,u_{2} } \right\},\max \left\{ {v_{1} ,v_{2} } \right\}} \right\rangle\).
Based on the aforementioned algorithms of q-ROFNs, Liu and Wang [35] introduced and analyzed the q-ROFWA operator.
Definition 4 [35]
Let \(\tilde{a}_{k} = \left\langle {u_{k} ,v_{k} } \right\rangle (k = 1,2,...,n)\) be a collection of q-ROFNs with weight vector \(w = (w_{1} ,w_{2} ,...,w_{n} )^{T}\) such that \(0 \le w_{k} \le 1\) and \(\sum\nolimits_{k = 1}^{n} {w_{k} = 1}\), then, the q-rung orthopair fuzzy weight averaging (q-ROFWA) operator is
Hausdorff distance
The Hausdorff distance measures how far two non-empty compact subsets \(A\) and \(B\) resemble mutually with their positions in a Banach space \(S\), which is initially put forward by Nadler [36]. Let \(d(a,b)\) be a metric for \(S\). \(d(z,A) = \min \left\{ {d(z,a)\left| {a \in A} \right.} \right\}\). The Hausdorff measure \(H^{*} (A,B) = \mathop {\max }\limits_{a \in A} d(a,B)\) is one-way. \(H(A,B)\) is defined by \(H(A,B) = \max \left\{ {H^{*} (A,B),H^{*} (B,A)} \right\}\). If \(S = \Re\), for any two intervals \(A = \left[ {a_{1} ,a_{2} } \right]\) and \(B = \left[ {b_{1} ,b_{2} } \right]\), the Hausdorff distance \(H(A,B)\) is given by \(H(A,B) = \max \left\{ {\left| {a_{1} - b_{1} } \right|,\left| {a_{2} - b_{2} } \right|} \right\}\).
Two-person matrix game
A review of the classical two-person matrix game [37] is presented in this subsection. \(S^{m} = \left\{ {x \in R_{ + }^{m} ,{\kern 1pt} {\kern 1pt} {\kern 1pt} e^{T} x = 1} \right\}\) and \(S^{n} = \left\{ {y \in R_{ + }^{n} ,{\kern 1pt} {\kern 1pt} {\kern 1pt} e^{T} y = 1} \right\}\), in which \(e^{T} = (1,1,...,1)\) is a vector of “ones”, are the pure strategies space of player I and II, severally. \(x_{i} (i = 1,2,...,n)\) is the probability that player I chooses pure strategy \(s_{i} \in S^{m}\) which belongs to the mixed strategy \(x = (x_{1} ,x_{2} ,...,x_{n} )^{T}\) of player I. Similarly, \(y_{j} (j = 1,2,...,m)\) is the probability in which player II chooses pure strategy \(s_{j} \in S^{n}\) which pertains to the mixed strategy \(y = (y_{1} ,y_{2} ,...,y_{m} )^{T}\) of player II. Let \(X\) and \(Y\) consist of all mixed strategies of player I and II, respectively. \(A = (a_{ij} )_{m \times n}\) is the payoff matrix of player I when player I chooses pure strategy \(s_{i}\) and player II chooses pure strategy \(s_{j}\) simultaneously.
Suppose player I and II play a two-person matrix game \(G\). Player I’s expected payoff is the scalar \(x^{T} Ay = \sum\nolimits_{i = 1}^{m} {\sum\nolimits_{j = 1}^{n} {x_{i} a_{ij} y_{j} } }\) if player I and II choose mixed strategies \(x \in X\) and \(y \in Y\) concurrently. Player I’s expected gain-floor can be acquired via the formula \(v_{G} (x) = \min \left\{ {\left. {x^{T} Ay} \right|y \in Y} \right\}\). The convention is to assume that player I pursues the maximizing yield; on the contrary, player II aims at the minimizing yield. Therefore, the minimum is attained in virtue of pure strategy \(y_{j} \in S^{n}\) as follows:
where \(A_{j} = (a_{1j} ,a_{2j} ,...,a_{mj} )^{T}\) is the jth column of the payoff matrix \(A\). Thus, to maximize \(v_{G} (x)\), a mixed strategy \(x^{*} \in X\) should be chosen by player I to obtain
Such \(v_{G} (x^{*} )\) is termed as player I’s gain-floor, expressed as \(v_{G} = v_{G} (x^{*} )\), and \(x^{*} \in X\) is the optimal mixed strategy for player I in the two-person matrix game \(G\).
Similarly, the player II’s expected loss-ceiling of choosing mixed strategy \(y\) is
where \(A_{i} = \left\{ {a_{i1} ,a_{i2} ,...,a_{in} } \right\}\) is the ith row of the payoff matrix \(G\). Thus, to obtain
a mixed strategy \(y^{*} \in Y\) should be chosen by player II.
Such \(\omega {}_{G}(y^{*} )\) is named as player II’s loss-ceiling, expressed as \(\rho_{G} = \omega {}_{G}(y^{*} )\), and \(y^{*} \in Y\) is the optimal mixed strategy for player II in the matrix game \(G\).
Apparently, Eqs. (6) and (8) are original dual linear programming problems for player I and II. Therefore, \(\max \left\{ {v_{G} } \right\}\) is equivalent to \(\min \left\{ {\rho_{G} } \right\}\). Their equal value is termed as the game \(G^{\prime}s\) value, indicated as \(V_{G} = v_{G} = \rho_{G}\).
The proposed two-person non-cooperative matrix game group decision-making approach
In this section, a two-person non-cooperative fuzzy matrix game based on the variable weight theory and q-ROFSs is proposed to deal with competitive strategy group decision-making problems.
Description of competitive strategy group decision-making problems
Suppose a two-person non-cooperative matrix game be constituted by player I and II. Let finite sets \(\delta = \left\{ {\delta_{1} ,\delta_{2} ,...,\delta_{m} } \right\}\) and \(\beta = \left\{ {\beta_{1} ,\beta_{2} ,...,\beta_{n} } \right\}\) be the finite strategy sets of player I and II, severally. The optimal solution of the two-person non-cooperative matrix game can be obtained by the following three stages: (1) preparatory stage. Considering the costs and benefits of strategies, a group of \(t\) experts evaluates the respective advantages of player I’s and II’s competitive strategies using q-ROFNs and derive payoff matrices. Let
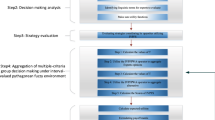
be the kth expert’s judgment matrix. (2) Computation stage: in this stage, an extended variable weighting approach is designed to aggregate the weighted payoff matrix on the basis of q-ROFWA operator. \(w_{k} (k = 1,2,...,t)\) is the initial kth expert’ weight satisfying \(w_{k} \in \left[ {0,1} \right]\) and \(\sum\limits_{k = 1}^{t} {w_{t} = 1}\), which is calculated based on the self-evaluation value of kth expert \(G_{k} (k = 1,2,...,t)\). On the basis of this, a novel Hausdorff distance measure for q-ROFNs is introduced to construct the variable expert weight \(\tilde{w}_{k} (k = 1,2,...,t)\). Utilizing the q-ROFWA operator, a comprehensive payoff matrix can be got. (3) Decision stage: the optimal strategies are chosen with a two-person matrix game via linear programming (LP). The game results are in the form of probability which have higher credibility. To present the main procedures of the proposed approach explicitly, a flowchart is plotted as displayed in Fig. 1.

The conceptual structure of the proposed method
The group decision-making approach
Step 1: Calculate the experts weights via variable weight assignment method
Step 1.1 Determine the initial experts’ weights using credibility analysis scale
The experts’ credibility indexes are shown in Table 1. The initial experts’ weights can be calculated utilizing the following two formulas:
Step 1.2 Compute the variable experts’ weights based on Hausdorff distance for q-ROFNs
Distance for the evaluation matrix can be used to measure the difference degree among experts [38,39,40,41]. Meanwhile, according to Hastie and Kameda [42], majority rules perform quite well in group decisions, at levels comparable to rules that require more resources for instance the average rule of individual judgment. Hence, based on the majority rules, the greater the sum of the differences between an expert and other experts is, the less reliable expert’s evaluation. Inspired by this inference, the variable experts’ weights can be obtained on the basis of a Hausdorff distance for q-ROFNs.
Let \(\tilde{A}\) and \(\tilde{B}\) be two q-ROFNs in a finite set \(X = \left\{ {x_{1} ,x_{2} ,...,x_{n} } \right\}\). \(I_{{\tilde{A}}} (x_{i} )\) and \(I_{{\tilde{B}}} (x_{i} )\) are two subintervals in \(\left[ {0,1} \right]\) with \(I_{{\tilde{A}}} (x_{i} ) = \left[ {u_{{\tilde{A}}}^{q} (x_{i} ),1 - v_{{\tilde{A}}}^{q} (x_{i} )} \right]\) and \(I_{{\tilde{B}}} (x_{i} ) = \left[ {u_{{\tilde{B}}}^{q} (x_{i} ),1 - v_{{\tilde{B}}}^{q} (x_{i} )} \right]\), \(i = 1,2,...,n\). \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))\) is defined as the Hausdorff distance between \(I_{{\tilde{A}}} (x_{i} )\) and \(I_{{\tilde{B}}} (x_{i} )\). The Hausdorff distance between \(\tilde{A}\) and \(\tilde{B}\) is
The normalized Hausdorff distance \(d_{NH} (\tilde{A},\tilde{B})\) from \(\tilde{A}\) to \(\tilde{B}\) is as the following formula:
Example 1
Assume two q-ROFSs \(A = \left( {0.5,{\kern 1pt} {\kern 1pt} {\kern 1pt} 0.6,{\kern 1pt} {\kern 1pt} {\kern 1pt} 0.39} \right)\) and \(B = \left( {0.4,{\kern 1pt} {\kern 1pt} {\kern 1pt} 0.7,{\kern 1pt} {\kern 1pt} {\kern 1pt} 0.35} \right)\), then the following results can be obtained by applying Eq. (10):
\(d_{NH} (A,B) = \frac{1}{1}\max \left\{ {\left| {0.25 - 0.16} \right|,\left| {0.36 - 0.49} \right|} \right\} = 0.13\).
The following proposition is given to guarantee the reasonability of Eq. (10).
Proposition 1
Let \(X = \left\{ {x_{1} ,x_{2} ,...,x_{n} } \right\}\) be a fixed set. The defined normalized distance \(d_{NH} (\tilde{A},\tilde{B})\) between q-ROFNs \(\tilde{A}\) and \(\tilde{B}\) has the following properties (\(P_{1}\))–(\(P_{4}\)):
(\(P_{1}\)) \(0 \le d_{NH} (\tilde{A},\tilde{B}) \le 1\);
(\(P_{2}\)) \(d_{NH} (\tilde{A},\tilde{B}) = 0\) if and only if \(\tilde{A} = \tilde{B}\);
(\(P_{3}\)) \(d_{NH} (\tilde{A},\tilde{B}) = d_{NH} (\tilde{B},\tilde{A})\);
(\(P_{4}\)) If \(\tilde{A} \subseteq \tilde{B} \subseteq \tilde{R}\), then \(d_{NH} (\tilde{A},\tilde{B}) \le d_{NH} (\tilde{A},\tilde{R})\) and \(d_{NH} (\tilde{B},\tilde{R}) \le d_{NH} (\tilde{A},\tilde{R})\).
Proof
Obviously, \(d_{NH} (\tilde{A},\tilde{B})\) confirms to the properties \(P_{1} - P_{3}\).
(\(P_{4}\)) Due to \(\tilde{A} \subseteq \tilde{B} \subseteq \tilde{C}\), thus \(u_{{\tilde{A}}}^{q} (x_{i} ) \le u_{{\tilde{B}}}^{q} (x_{i} ) \le u_{{\tilde{C}}}^{q} (x_{i} )\), \(v_{{\tilde{A}}}^{q} (x_{i} ) \ge v_{{\tilde{B}}}^{q} (x_{i} ) \ge v_{{\tilde{C}}}^{q} (x_{i} )\), \(\forall x_{i} \in X\).
\(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} )) = \max \left\{ {\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{B}}}^{q} (x_{i} )} \right|,\left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )} \right|} \right\}\),
\(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} )) = \max \left\{ {\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right|,\left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|} \right\}\),
\(H(I_{{\tilde{B}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} )) = \max \left\{ {\left| {u_{{\tilde{B}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right|,\left| {v_{{\tilde{B}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|} \right\}\).
Case 1. If \(\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right| \ge \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|\), \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} )) = \left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right|\). However, \(\left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right|\) and \(\left| {v_{{\tilde{B}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right|\). Based on the inequalities above, \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} )) \le H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} ))\) and \(H(I_{{\tilde{B}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} )) \le H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} ))\) can be obtained without a hitch. Hence, \(d_{NH} (\tilde{A},\tilde{B}) \le d_{NH} (\tilde{A},\tilde{C})\) and \(d_{NH} (\tilde{B},\tilde{C}) \le d_{NH} (\tilde{A},\tilde{C})\).
Case 2. If \(\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|\), \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} )) = \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|\). However, \(\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{B}}}^{q} (x_{i} )} \right| \le \left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|\) and \(\left| {u_{{\tilde{B}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|\). On the contrary, \(\left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|\) and \(\left| {u_{{\tilde{B}}}^{q} (x_{i} ) - u_{{\tilde{C}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{C}}}^{q} (x_{i} )} \right|\). Based on the inequalities above, \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} )) \le H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} ))\) and \(H(I_{{\tilde{B}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} )) \le H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{C}}} (x_{i} ))\). Hence, \(d_{NH} (\tilde{A},\tilde{B}) \le d_{NH} (\tilde{A},\tilde{C})\) and \(d_{NH} (\tilde{B},\tilde{C}) \le d_{NH} (\tilde{A},\tilde{C})\). Thus, the containment property (\(P_{4}\)) is proved.
Proposition 2
The proposed normalized Hausdorff distance \(d_{NH} (\tilde{A},\tilde{B})\) between q-ROFNs \(\tilde{A}\) and \(\tilde{B}\) increases as the \(q\) increases.
Proof
-
(i)
If \(\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{B}}}^{q} (x_{i} )} \right| \ge \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )} \right|\) and \(u_{{\tilde{A}}}^{q} (x_{i} ) \ge u_{{\tilde{B}}}^{q} (x_{i} )\), \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} )) = u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{B}}}^{q} (x_{i} )\). Then, \(\frac{{\partial H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))}}{\partial q} = q(u_{{\tilde{A}}}^{q - 1} (x_{i} ) - u_{{\tilde{B}}}^{q - 1} (x_{i} )) \ge 0\) which proves that with the increase of \(q\), the Hausdorff distance \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))\) increases. Therefore, the proposed normalized Hausdorff distance \(d_{NH} (\tilde{A},\tilde{B})\) between q-ROFNs \(\tilde{A}\) and \(\tilde{B}\) increases with the increasing value of \(q\).
-
(ii)
If \(\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{B}}}^{q} (x_{i} )} \right| \ge \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )} \right|\) and \(u_{{\tilde{A}}}^{q} (x_{i} ) \le u_{{\tilde{B}}}^{q} (x_{i} )\), \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} )) = u_{{\tilde{B}}}^{q} (x_{i} ) - u_{{\tilde{A}}}^{q} (x_{i} )\). Then, \(\frac{{\partial H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))}}{\partial q} = q(u_{{\tilde{B}}}^{q - 1} (x_{i} ) - u_{{\tilde{A}}}^{q - 1} (x_{i} )) \ge 0\) which proves that with the increase of \(q\), the Hausdorff distance \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))\) increases. Therefore, the proposed normalized Hausdorff distance \(d_{NH} (\tilde{A},\tilde{B})\) between q-ROFNs \(\tilde{A}\) and \(\tilde{B}\) increases with the increasing value of \(q\).
-
(iii)
If \(\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{B}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )} \right|\) and \(v_{{\tilde{A}}}^{q} (x_{i} ) \ge v_{{\tilde{B}}}^{q} (x_{i} )\), \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} )) = v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )\). Then, \(\frac{{\partial H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))}}{\partial q} = q(v_{{\tilde{A}}}^{q - 1} (x_{i} ) - v_{{\tilde{B}}}^{q - 1} (x_{i} )) \ge 0\) which proves that with the increase of \(q\), the Hausdorff distance \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))\) increases. Therefore, the proposed normalized Hausdorff distance \(d_{NH} (\tilde{A},\tilde{B})\) between q-ROFNs \(\tilde{A}\) and \(\tilde{B}\) increases with the increasing value of \(q\).
-
(iv)
If \(\left| {u_{{\tilde{A}}}^{q} (x_{i} ) - u_{{\tilde{B}}}^{q} (x_{i} )} \right| \le \left| {v_{{\tilde{A}}}^{q} (x_{i} ) - v_{{\tilde{B}}}^{q} (x_{i} )} \right|\) and \(v_{{\tilde{B}}}^{q} (x_{i} ) \ge v_{{\tilde{A}}}^{q} (x_{i} )\), \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} )) = v_{{\tilde{B}}}^{q} (x_{i} ) - v_{{\tilde{A}}}^{q} (x_{i} )\). Then, \(\frac{{\partial H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))}}{\partial q} = q(v_{{\tilde{B}}}^{q - 1} (x_{i} ) - v_{{\tilde{A}}}^{q - 1} (x_{i} )) \ge 0\) which proves that with the increase of \(q\), the Hausdorff distance \(H(I_{{\tilde{A}}} (x_{i} ),I_{{\tilde{B}}} (x_{i} ))\) increases. Therefore, the proposed normalized Hausdorff distance \(d_{NH} (\tilde{A},\tilde{B})\) between q-ROFNs \(\tilde{A}\) and \(\tilde{B}\) increases with the increasing value of \(q\).
Proposition 2 means that for the same evaluation information, the increasing parameter value of \(q\) can cause miscalculation of Hausdorff distance between q-ROFNs \(\tilde{A}\) and \(\tilde{B}\). In other words, it is not a sensible choice giving the experts more freedom sometimes.
The variable expert weight \(\tilde{w}_{k} (k = 1,2,...,t)\) can be calculated as
As can be observed from Eq. (11), the initial expert weight \(w_{k}\), obtained on the basis of experts’ individual information, plays an important role in the calculation process of \(\tilde{w}_{k}\). On the other hand, it can be easily seen that the variable expert weight \(\tilde{w}_{k}\) changes with \(d_{NH} (A^{k} ,A^{l} )\), and the variation of subjective information evaluated by experts can result in the change of \(d_{NH} (A^{k} ,A^{l} )\). Thus, the proposed expert weight dynamic determination model is capable of taking into account the objective individual information of experts and varying with changeable subjective evaluation information to make the decision results more reliable in a real scenario.
Step 2. Obtain the overall payoff matrix by the q-ROFWA operator
Player I’s comprehensive payoff matrix \(\overline{A} = (\overline{u}_{ij} ,\overline{v}_{ij} )\) can be constructed by aggregating all payoff values \(a_{ij}^{k} (i = 1,2,..,m;j = 1,2,...,n)\) to the overall preference value \(\overline{a}_{ij} (i = 1,2,..,m;j = 1,2,...,n)\) utilizing the \(q - ROFWA\) operator:
Step 3. Select the optimal strategies via two-person non-cooperative matrix game theory
Step 3.1 Construct expected payoffs of player I and II
The expected payoff of player I can be computed by the following formula:
which is a q-ROFN. Stated as earlier, the expected payoff of player II can be obtained via the equation
which is still a q-ROFN. Denote the maximum payoff of player I and the minimum payoff of player II as \(v_{G}\) and \(\rho_{G}\), respectively, which can be calculated using the following two expressions:
\(v_{G} = \left( {\tilde{u},\tilde{v}} \right) = (\mathop {\min }\limits_{y \in Y} (1 - \prod\limits_{j = 1}^{n} {\prod\limits_{i = 1}^{m} {(1 - \overline{u}_{ij}^{q} )^{{x_{i} y_{j} }} )^{1/q} ,\mathop {\max }\limits_{y \in Y} (\prod\limits_{j = 1}^{n} {\prod\limits_{i = 1}^{m} {\overline{v}_{ij}^{{x_{i} y_{j} }} ))} } } }\),
\(\rho_{G} = \left( {\tilde{\mu },\tilde{\gamma }} \right) = (\mathop {\max }\limits_{x \in X} (1 - \prod\limits_{i = 1}^{m} {\prod\limits_{j = 1}^{n} {(1 - \overline{v}_{ij}^{q} )^{{x_{i} y_{j} }} )^{1/q} } } ,\mathop {\min }\limits_{x \in X} (\prod\limits_{i = 1}^{m} {\prod\limits_{j = 1}^{n} {\overline{u}_{ij}^{{x_{i} y_{j} }} } } ))\).
The two-person matrix game \(G\) gains a fuzzy value \(V_{G}\) if \(V_{G} = v_{G} = \rho_{G}\).
Step 3.2 Determine the optimal competitive strategies of player I and II
According to Eq. (6), solving the following non-linear multi-objective programming model can generate the gain-floor of player I and a maximum strategy \(x^{*}\):
\(\tilde{u} \ge 0,{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} \tilde{v} \ge 0,{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} x_{i} \ge 0{\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} {\kern 1pt} (i = 1,2,...,m)\).
Obviously, the existing methods cannot directly solve the above non-linear programming (NLP) model. Thus, inspired by Li [37], a novel approach based on the weighted average theory is proposed to transform model (M-1) into the standard LP model.
For \(0 \le \tilde{u} \le 1\), \(\max \left\{ {\tilde{u}} \right\}\) is equivalent to \(\min \left\{ {1 - \tilde{u}} \right\}\) which is equivalent to \(\min \left\{ {\ln (1 - \tilde{u})} \right\}\). \(\min \left\{ {\ln (1 - \tilde{u})} \right\}\) is equivalent to \(\min \left\{ {\ln (1 - \tilde{u}^{q} )} \right\}\). Hence, \(\max \left\{ {\tilde{u}} \right\}\) is equivalent to \(\min \left\{ {\ln (1 - \tilde{u}^{q} )} \right\}\) for \(0 \le \tilde{u} \le 1\). Similarly, \(\min \left\{ {\tilde{v}} \right\}\) is equivalent to \(\min \left\{ {\ln (\tilde{v})} \right\}\). Thus, model (M-1) can be transformed into
except for \(\overline{u}_{ij} = 1\), \(\tilde{u} = 1\), \(\overline{v}_{ij} = 0\), \(\tilde{v} = 0\). \(\lambda\) is the weight determined by players, which measures the objectives’ priorities.
In light of that the set \(Y\) is compact and finite, it is reasonable to transform model (M-2) into the linear model (M-3) as follows:
In a same analysis, according to Eq. (7), solving the following non-linear multi-objective programming model can generate the loss-ceiling of player II and a minimum strategy \(y^{*}\):
Obviously, for \(\tilde{\mu } \in \left[ {0,1} \right]\), \(\min \left\{ {\tilde{\mu }} \right\}\) is equivalent to \(\max \left\{ {1 - \tilde{\mu }} \right\}\). \(\max \left\{ {1 - \tilde{\mu }} \right\}\) is equivalent to \(\max \left\{ {\ln (1 - \tilde{\mu })} \right\}\) for \(\tilde{\mu } \in \left[ {0,1} \right)\). Hence,
except for \(\overline{u}_{ij} = 1\), \(\tilde{\mu } = 1\), \(\overline{v}_{ij} = 0\), \(\tilde{\gamma } = 0\). \(\lambda\) is the weight determined by players, which measures the objectives’ priorities.
In light of that the set \(X\) is compact and finite, it is reasonable to transform model (M-5) into the linear model (M-6) as follows:
However, \(\ln (1 - \overline{u}_{ij}^{q} ) \to - \infty\), and/or \(\ln (\overline{v}_{ij} ) \to - \infty\) if \(\overline{u}_{ij}^{q} = 1\), and/or \(\overline{v}_{ij} = 0\). Under these circumstances, model (M-3) and (M-6) are meaningless. To expand the application of the proposed method, the following NLP models should be formulated:
and
Let \(L = (1 - \tilde{u}^{q} )^{\lambda } (\tilde{v})^{1 - \lambda }\) and \(T = (1 - \tilde{\mu }^{q} )^{\lambda } (\tilde{\gamma })^{1 - \lambda }\). Then, \(0 \le L \le 1\) since \(\lambda \in \left[ {0,1} \right]\), \(0 \le 1 - \tilde{u}^{q} \le 1\) and \(0 \le \tilde{v} \le 1\). Similarly, \(0 \le T \le 1\). Thus, (M-7) and (M-8) can be overtyped into the NLP models as follows:
and
Evidently, models (M-9) and (M-10) are original dual linear programming problems for player I and II. According to the duality theorem, \(\max \left\{ T \right\}\) is equivalent to \(\min \left\{ L \right\}\). The optimal strategies of players can be obtained by solving models (M-9) and (M-10) via simplex methods.
Illustrative example
In this section, to demonstrate the availability of the proposed group decision-making method, a market share competition between two new energy electric vehicles sharing companies is exemplified.
Case description
Due to the advantages of energy conservation and pollution reduction, new energy electric vehicles become more and more popular in Shanghai, China. Two new energy electric vehicles sharing companies \(A\) and \(B\) compete for market share in Shanghai market. The company \(A\) was formed by the cooperation of two big companies, which has more than 3673 branches. The company \(B\) is a local brand in Shanghai and owns over 226 branches. The company \(A\) has advantages in company size, branch quantity, usability. For the company \(B\), it has the techniques of backstage big data processing provided by a national renowned college’s smart grid center located in Shanghai and uses only pure electric cars, which can improve the satisfaction of green consumers. Although the unit price are different with the vehicle type, there is no big difference in unit price between the two companies. Since an increase in one company’s market share means a decrease in another company’s market share, the competition game between \(A\) and \(B\) belongs to a two-person matrix game. The company \(A\) and \(B\) consider the following three strategies to maximum market share: \(\eta_{1}\)(improving the quality subscribers), \(\eta_{2}\)(advertising investment) and \(\eta_{3}\)(technology improvement). Five experts \(e_{1} - e_{5}\) comprehensively evaluate the relative competitive advantages between the companies \(A\) and \(B\) considering the factors including capital demand, labor cost, time cost, execution difficulty coefficient and sustainability, and give the payoff matrices of the companies \(A\) and \(B\). Table 2 shows the payoff matrices of the company \(A\) evaluated by the five experts. Due to \(\max \left\{ {(u_{ij}^{k} )^{1} + (v_{ij}^{k} )^{1} } \right\} = (0.6)^{1} + (0.8)^{1} = 1.4 \ge 1\) and \(\max \left\{ {(u_{ij}^{k} )^{2} + (v_{ij}^{k} )^{2} } \right\} = (0.6)^{2} + (0.8)^{2} = 1 \ge 1\), IFSs and PFSs cannot describe this market share competition. Note that \(\max \left\{ {(u_{ij}^{k} )^{3} + (v_{ij}^{k} )^{3} } \right\} = (0.6)^{3} + (0.8)^{3} = 0.728 < 1\). Hence, to conquer the shortcomings of IFSs and PFSs in depicting this illustrative example, q-ROFS is utilized as the evaluation language by assigning the parameter value of \(q\) to 3.
Illustration of the proposed method
Step 1: Calculate the experts’ weights via variable weight assignment method
Step 1.1 Determine the initial experts’ weights using credibility analysis scale
Based on the objective credibility information provided by the five experts, the initial experts weights can be obtained using the Eqs. (8) and (9) as \(w_{k} = (0.2177,0.2177,0.2016,0.1774,0.1855)\). From Table 3 which presents the main results of Step 1.1, the ordering of experts’ total credibility index is \(G_{1} = G_{2} > G_{3} > G_{5} > G_{4}\) in accordance with the ranking of experts’ evaluation credibility. This confirms the accuracy of the initial experts’ weights obtained by this step.
Step 1.2 Compute the variable experts’ weights based on Hausdorff distance for q-ROFNs
First, the Hausdorff distances between the experts are calculated by Eq. (10). After that, the variable experts’ weights are computed via Eq. (11) as \(\tilde{w}_{k} = (0.1778,0.2363,0.1935,0.2022,0.1902)\). The above results are shown in Table 4. Compared to the initial weights in Table 3, the experts’ weights vary with respect to the difference degree of experts. First, the big difference between Expert 1 and other experts signifies that the payoff matrix evaluated by Expert 1 may exist biased errors resulted from some key evaluation factors such as knowledge deficits. Thus, the ordering weight of Expert 1 falls from first to fifth. Second, the Expert 2’s and 4’s ordering weights move up because of relatively small differences with others. Next, the ordering weight of Expert 3 and 5 are constant. The final ranking result of experts weights, \({\text{w}}_{5} > w_{1} > w_{3} > w_{2} > w_{4}\), reveals that the dynamic experts weight, derived by the hybrid weight determination model, can not only combine objective individual information but also make efficient adjustments according to changes in subjective evaluation information.
Step 2. Obtain the overall payoff matrix by the q-ROFWA operator
Step 3. Select the optimal strategies by a two-person non-cooperative matrix game theory
According to the company \(A^{\prime}s\) overall payoff matrix calculated in the previous step, the optimal strategies of \(A\) and \(B\) are obtained via model (M-9) and (M-10), respectively. Table 6 presents the results. It is easily to see that the optimal strategies of \(A\) and \(B\) are constant regardless of the changes in the weight \(\lambda\). The optimal strategy of the company \(A\) and \(B\) are \((0,1,0)\) and \((0,0,1)\), respectively. The company \(A^{\prime}s\) expected payoff is equal to the expected payoff of \(B\) as \(E(x^{*} ,y^{*} ) = (0.6315,0.4445)\). The above results show that the company \(A\) only considers the strategy \(\eta_{2}\) to compete with \(B\) when the company \(B\) takes the competitive strategy \(\eta_{3}\).
Sensitivity analysis
It can be observed that the parameter \(q\) plays a crucial part in the proposed two-person non-cooperative matrix game group decision-making approach. To study the sensitivity of the parameter \(q\), let the value of \(q\) increase one unit at a time until 10 in the above example.
Figure 2 displays how the variation of \(q\) impacts the total Hausdorff distance between each expert and the other experts. Obviously, the increasing of \(q\) decreases the Hausdorff distance between each experts simultaneously even though the payoff matrices provided by the experts are unaltered. It means that as the parameter \(q\) increases, the difference degree between any two experts is preposterously reduced. Hence, the greater value of \(q\) is not better because it will generate the incorrect experts’ difference degrees.

The experts’ total Hausdorff distance with different \(q\)
Figure 3 illustrates the dynamic expert weights’ ordering changes. Specifically, only the Expert 2’s weight ordering is constant, however, the rest of the experts’ weight orderings have changed in varying degrees. Expert 1’s weight remains unchanged at the last place when \(q\) changes from 3 to 5, but when \(q\) is greater than 5, it rises to the fourth place. For Expert 3 and 5, their weights order fluctuate depending on the value of the parameter \(q\). Besides, as the value of \(q\) increases, the order of Expert 5 is more and more backward until it becomes the last one. Based on the foregoing analyses, it is necessary for experts to choose the appropriate parameter \(q\) prudently because the expert weights ordering results are allergic to the variation of \(q\).

The changes in the experts’ weights ranking ordering with different \(q\)
Table 7 shows the impacts of the different \(q\) on the market share matrix game solution. Note that Table 7 only displays the summary results because the game results are same regardless of the weight \(\lambda ^{\prime}s\) variation. Firstly, the optimal strategy and strategies ranking of \(B\) are unchanged. Next, the optimal strategy of \(A\) has changed from \((0,1,0)\) to \((0,0,1)\) when the value of \(q\) changes from 3 to 10, which means that the company \(A\) will takes strategy \(\eta_{3}\) to compete with \(B\) in these cases. In addition, the expected payoff \(E(x^{*} ,y^{*} )\) changes with the different \(q\). Concretely, the winning gains of \(A\) and \(B\) increase in the value of \(q\). Inversely, the increasing of \(q\) makes the losses of failure decrease. Seemingly, the larger the parameter value of \(q\), the better the decision result. However, this verdict is unauthentic because improper parameter values of \(q\) lead to significant biases in the expert weights and the total Hausdorff distance between each expert and the other experts. These biases distort the final decision-making results.
From the above analyses, it is easily to find that the value of \(q\) has vital adverse influence on the proposed method. In other word, although the greater the \(q\), the more freedom the experts have, the proposed method will be impacted by the increasing value of \(q\) negatively. On the one hand, the increasing value of \(q\) will bridge the gap on Hausdorff distance between the experts, which may impact the correct calculation of the variable experts weights. On the other hand, the winning probabilities increase with \(q\) and the aggregated payoff matrix has changes, which causes the computing deviations of matrix game optimal solutions. Hence, the minimal value of \(q\) should be chosen meeting the condition that \(0 \le (u_{A} (x)^{q} + v_{A} (x)^{q} ) \le 1,{\kern 1pt} {\kern 1pt} {\kern 1pt} (q \ge 1)\) where for all \(x \in X\), \(u_{A} :X \to \left[ {0,1} \right]\) indicates membership grade and \(v_{A} :X \to \left[ {0,1} \right]\) indicates non-membership grade of \(x\), respectively.
Comparative analysis
In this subsection, the stability and superiorities of the proposed approach are demonstrated and highlighted through comparative analyses.
Comparison with other fuzzy evaluation languages
There have been several fuzzy languages improved to describe complex decision-making problems since FSs was proposed. To examine the effectiveness of q-ROFS, it is compared with some classic and novel fuzzy languages including FS [10], IFS [13], PFS [14], spherical fuzzy set [43], bipolar soft set [44] and bipolar picture fuzzy set [45]. The corresponding results are concluded as follows:
-
FS is characterized by a single membership function and ignores the non-membership degree of an object. Hence, this fuzzy set cannot describe fuzzy decision-making problems as q-ROFS can.
-
As special cases of q-ROFSs, IFS and PFS are unable to depict situations where \(u + v > 1,{\kern 1pt} {\kern 1pt} {\kern 1pt} u^{2} + v^{2} > 1\).
-
Spherical fuzzy set and bipolar soft set, generalizations of IFS, are also invalid when \(u + v > 1\).
-
Bipolar picture fuzzy set, a reformative extension of PFS, loses its efficacies if \(u^{2} + v^{2} > 1\).
On the basis of the above comparisons, it can be easily observed that q-ROFS has dominant advantages of portraying complexity systems because it can be transformed into different forms by choosing different values of parameter \(q\).
Comparison with other expert weight calculation methods
Over the past few years, several expert weight assignment methods have been put forward. The devised hybrid dynamic expert weight determination model is compared with three representative categories of weight assignment methods to emphasize its advantages. Table 8 displays the main characteristics of different expert weight calculation methods. The comparative results show that the proposed model is a powerful tool to assign reasonable weight to experts, which can portray experts’ objective individual information and vary with subjective evaluation information.
Comparison with other fuzzy matrix game solution methods
In addition to the weighted average method integrated into the proposed approach, ideal point method and sequential optimization method, widely applied in market share competition strategy selection problems, are also classical methods to solve fuzzy matrix models. Hence, the validity of the proposed method is demonstrated in comparisons with ideal point method [52] and sequential optimization method [53] based on the aforementioned illustrative example. The comparative results are shown in Table 9.
Table 9 shows that there is no significant difference in optimal strategies obtained by the three methods, which verifies the accuracy of the proposed approach. However, compared to the proposed approach, the ideal point method and sequential optimization method have the following two shortcomings: (1) Heavy calculation burden cannot be avoided. Both the ideal point method and the sequential optimization method require two steps to solve four linear programming models, while the proposed approach only needs to solve two linear programming models at once. (2) Intermediate variables are needed. To measure differences between the ideal point and alternatives, distance variables are inevitably introduced into the ideal point method. Similarly, in the calculation process of the fuzzy sequential optimization method, intermediate variables are designed to define comparative laws of fuzzy numbers. The presence of intermediate variables increases computation complexities of the above two method.
According to the above three comparative analyses, the superiorities of the proposed approach in solving competitive strategy decision-making problems are highlighted. Regardless of the number of alternative strategies, the proposed approach can obtain the correct optimal strategies in the form of probability with high efficiency, little calculation burden and low calculation complexity.
Advantages with limitations of the proposed approach
In light of the above comparative analyses, the proposed approach for addressing intricate competitive strategy group decision-making problems has the following advantages:
-
(i)
The fuzzy evaluation language utilized by this paper, q-ROFS, is capable of conveying more complex information than part of existing sets such as FS, IFS, PFS, spherical fuzzy set, bipolar soft set and bipolar picture fuzzy set. It can adapt to changes in the language environment.
-
(ii)
The devised expert weight determination model integrates the objective individual information and subjective evaluation information, which is more reasonable and close to the actual expert weights.
-
(iii)
The proposed two-person non-cooperative fuzzy matrix game decision-making method is less affected by the number of competitive strategies, and can present the specific difference degree of each strategy rather than simple ranking results.
On the other hand, the proposed approach has some limitations:
-
(1)
This approach cannot be applied under some particular fuzzy circumstances where various membership functions are independently.
-
(2)
Competitive strategy group decision-making problems in non-linear nature are powerless to be handled via the proposed approach which uses linear membership and non-membership function.
Conclusion
A two-person non-cooperative fuzzy matrix game method integrating the superiorities of variable experts’ weights and q-ROFSs is devised to handle competitive strategy group decision-making problems in this paper. First, q-ROFS is utilized to present the payoff matrices provided by experts, which renders experts more freedom of evaluation and describes the uncertainties of CSGDM problems more flexibly because the parameter value of q can be chosen according to the information expression range. Next, a new mechanism to calculate the variable experts’ weights is formulated, taking the objective and subjective weights of experts into consideration simultaneously, based on the q-ROF Hausdorff distances among the experts and the initial weights calculated with experts’ individual information. Then, the q-ROFWA operator is implemented to compute the comprehensive payoff matrices of the players. After that, a q-ROF two-person matrix game is formulated to select the optimal mixed strategy which can present the priorities of the competitive strategies explicitly and concretely. In addition, an illustrative example, several comparative analyses and sensitivity analyses are performed to highlight the superiorities of the proposed approach, the insights show that the optimal strategies in the form of probabilities are close to competitive strategy selection practice, and the proposed approach as a CSGDM method with high efficiency, low computation complexity and little calculation burden. Besides, although the increasing parameter value of q gives the experts more freedom, it would cause decision-making biases. Hence, the minimum value of q that satisfies the language constraints should be chosen with the same evaluation information.
In the future, the following two research directions can be pursued. As a starter, the proposed method can be extended resort to utilizing other forms of fuzzy language such as neutrosophic sets [54, 55] and linear Diophantine fuzzy sets [56,57,58]. Moreover, the proposed fuzzy matrix game is between two persons, and future researches can focus on fuzzy multi-player game method for competitive strategy group decision-making problems.
Availability of data and material
All data generated or analyzed during this study are included in this published article.
Code availability
Python.
References
Khanzadi M, Turskis Z, Amiri GG, Chalekaee A (2017) A model of discrete zero-sum two-person matrix games with grey numbers to solve dispute resolution problems in construction. J Civ Eng Manag 23(6):824–835. https://doi.org/10.3846/13923730.2017.1323005
Ding XF, Liu HC (2019) A new approach for emergency decision-making based on zero-sum game with Pythagorean fuzzy uncertain linguistic variables. Int J Intell Syst 34:1667–1684. https://doi.org/10.1002/int.22113
Seyedesfahani MM, Biazaran M, Gharakhani M (2011) A game theoretic approach to coordinate pricing and vertical co-op advertising in manufacturer-retailer supply chains. Eur J Oper Res 211(2):263–273. https://doi.org/10.1016/j.ejor.2010.11.014
Ale SB, Brown JS, Sullivan AT (2013) Evolution of cooperation: combining kin selection and reciprocal altruism into matrix games with social dilemmas. PLoS One 8(5):e63761. https://doi.org/10.1371/journal.pone.0063761
Zhou L, Xiao F (2019) A new matrix game with payoffs of generalized Dempster-Shafer structures. Int J Intell Syst 34(9):2253–2268. https://doi.org/10.1002/int.22164
Zhou JL, Shia YB, Sun ZY (2015) A hybrid fuzzy FTA-AHP method for risk decision-making in accident emergency response of work system. J Intell Fuzzy Syst 29(4):1381–1393. https://doi.org/10.3233/IFS-141512
Xue YX, You JX, Lai XD, Liu HC (2016) An interval-valued intuitionistic fuzzy MABAC approach for material selection with incomplete weight information. Appl Soft Comput 38:703–713. https://doi.org/10.1016/j.asoc.2015.10.010
Sha X, Yina C, Xu Z, Zhang S (2021) Probabilistic hesitant fuzzy TOPSIS emergency decision-making method based on the cumulative prospect theory. J Intell Fuzzy Syst 40(3):1–17. https://doi.org/10.3233/JIFS-201119
Neumann JV, Morgenstern O (1944) Theory of games and economic behavior. New York, Princeton University Press
Zadeh LA (1965) Fuzzy sets. Inf Control 8(3):338–353. https://doi.org/10.1016/S0019-9958(65)90241-X
Zadeh LA, Bellman RE (1970) Decision-making in a fuzzy environment. Manag Sci 17(4):B141–B164. https://doi.org/10.1287/mnsc.17.4.B141
Zimmermann HJ (1978) Fuzzy programming and linear programming with several objective functions. Fuzzy Sets Syst 1(1):45–55. https://doi.org/10.1016/0165-0114(78)90031-3
Atanassov KT (1986) Intuitionistic fuzzy sets. Fuzzy Sets Syst 20(1):87–96. https://doi.org/10.1016/S0165-0114(86)80034-3
Yager RR (2013) Pythagorean fuzzy subsets. In: 2013 joint IFSA world congress and NAFIPS annual meeting (IFSA/NAFIPS). IEEE 57–61
Yager RR (2016) Generalized orthopair fuzzy sets. IEEE Trans Fuzzy Syst 25(5):1222–1230. https://doi.org/10.1109/TFUZZ.2016.2604005
Yang Z, Ouyang T, Fu X, Peng X (2020) A decision-making algorithm for online shopping using deep-learning-based opinion pairs mining and q-rung orthopair fuzzy interaction Heronian mean operators. Int J Intell Syst 35(5):783–825. https://doi.org/10.1002/int.22225
Liu P, Wang Y (2020) Multiple attribute decision making based on q-rung orthopair fuzzy generalized Maclaurin symmetic mean operators. Inf Sci 518(2020):181–210. https://doi.org/10.1016/j.ins.2020.01.013
Zeng SZ, Hu YJ, Xie XY (2021) Q-rung orthopair fuzzy weighted induced logarithmic distance measures and their application in multiple attribute decision making. Eng Appl Artif Intell 100(7):104167. https://doi.org/10.1016/j.engappai.2021.104167
Riaz M, Farid H, Karaaslan F, Hashmi MR (2020) Some q-rung orthopair fuzzy hybrid aggregation operators and TOPSIS method for multi-attribute decision-making. J Intell Fuzzy Syst 39(1):1227–1241. https://doi.org/10.3233/JIFS-192114
Garg H, Gwak J, Mahmood T, Ali Z (2020) Power aggregation operators and VIKOR methods for complex q-rung orthopair fuzzy sets and their applications. Mathematics 8(4):538. https://doi.org/10.3390/math8040538
Liu P, Ali Z, Mahmood T (2021) Generalized complex q-rung orthopair fuzzy Einstein averaging aggregation operators and their application in multi-attribute decision making. Complex Intell Syst 7(1):511–538. https://doi.org/10.1007/s40747-020-00197-6
Garg H, Ali Z, Mahmood T (2020) Generalized dice similarity measures for complex q-Rung Orthopair fuzzy sets and its application. Complex Intell Syst 7:667–686. https://doi.org/10.1007/s40747-020-00203-x
Mahmood T, Ali Z (2021) Entropy measure and TOPSIS method based on correlation coefficient using complex q-rung orthopair fuzzy information and its application to multiple attribute decision making. Soft Comput 25:1249–1275. https://doi.org/10.1007/s00500-020-05218-7
Riaz M, Hamid MT, Afzal D, Pamucar D, Chu YM (2021) Multi-criteria decision making in robotic agri-farming with q-rung orthopair m-polar fuzzy sets. PLoS One 16(2):e0246485. https://doi.org/10.1371/journal.pone.246485
Naeem K, Riaz M, Karaaslan F (2021) Some novel features of Pythagorean m-polar fuzzy sets with applications. Complex Intell Syst 7:459–475. https://doi.org/10.1007/s40747-020-00219-3
Zhang ZM, Wu C (2014) A decision support model for group decision making with hesitant multiplicative preference relations. Inf Sci 282:136–166. https://doi.org/10.1016/j.ins.2014.05.057
Zhang ZM, Wang C, Tian XD (2015) A decision support model for group decision making with hesitant fuzzy preference relations. Knowledge-Based Syst 86:77–101
Wu ZB, Xu JP (2016) Managing consistency and consensus in group decision making with hesitant fuzzy linguistic preference relations. Omega 65:28–40. https://doi.org/10.1016/j.omega.2015.12.005
Xu Y, Rui D, Wang H (2017) A dynamically weight adjustment in the consensus reaching process for group decision-making with hesitant fuzzy preference relations. Int J Syst Sci 48(5–8):1311–1321
Liu S, Yu W, Liu L, Hu Y, Li Y (2019) Variable weights theory and its application to multi-attribute group decision making with intuitionistic fuzzy numbers on determining decision maker’s weights. PLoS One 14(3):e0212636. https://doi.org/10.1371/journal.pone.0212636
Zhang ZC (2006) A new method for the problem of multi-attribute decision making. J Wuhan Univ Technol 28(6):117–120
Tycab C (2020) Pythagorean fuzzy linear programming technique for multidimensional analysis of preference using a squared-distance-based approach for multiple criteria decision analysis. Expert Syst Appl 164:113908. https://doi.org/10.1016/j.eswa.2020.113908
Hao ZN, Xu ZS, Zhao H, Zhang R (2021) The context-based distance measure for intuitionistic fuzzy set with application in marine energy transportation route decision making. Appl Soft Comput 101:107044. https://doi.org/10.1016/j.asoc.2020.107044
Sarkar B, Biswas A (2021) Pythagorean fuzzy AHP-TOPSIS integrated approach for transportation management through a new distance measure. Soft Comput 7:1–17. https://doi.org/10.1007/s00500-020-05433-2
Liu P, Wang P (2018) Some q-rung orthopair fuzzy aggregation operators and their applications to multiple-attribute decision making. Int J Intell Syst 33(4):259–280. https://doi.org/10.1002/int.21927
Nadler SB (1978) Hyperspaces of sets. New York, Marcel Dekker, Inc.
Li DF (2012) A fast approach to compute fuzzy values of matrix games with payoffs of triangular fuzzy numbers. Eur J Oper Res 223(2):421–429. https://doi.org/10.1016/j.ejor.2012.06.020
Hung WL, Yang MS (2004) Similarity measures of intuitionistic fuzzy sets based on Hausdorff distance. Pattern Recognit Lett 25(14):1603–1611. https://doi.org/10.1016/j.patrec.2004.06.006
Gou XJ, Xu ZS, Liao HC, Herrera F (2018) Multiple criteria decision making based on distance and similarity measures under double hierarchy hesitant fuzzy linguistic environment. Comput Ind Eng 126:516–530. https://doi.org/10.1016/j.cie.2018.10.020
Hu MM, Lan JB, Wang ZX (2019) A distance measure, similarity measure and possibility degree for hesitant interval-valued fuzzy sets. Comput Ind Eng 137:106088. https://doi.org/10.1016/j.cie.2019.106088
Hussain Z, Yang MS (2019) Distance and similarity measures of Pythagorean fuzzy sets based on the Hausdorff metric with application to fuzzy TOPSIS. Int J Intell Syst 34(10):2633–2654. https://doi.org/10.1002/int.22169
Hastie R, Kameda T (2005) The robust beauty of majority rules in group decisions. Psychol Rev 112(2):494–508. https://doi.org/10.1037/0033-295X.112.2.494
Ashraf S, Abdullah S (2020) Emergency decision support modeling for COVID-19 based on spherical fuzzy information. Int J Intell Syst 35:1601–1645. https://doi.org/10.1002/int.22262
Mahmood T (2020) A novel approach towards bipolar soft sets and their applications. J Math 2020:4690808. https://doi.org/10.1155/2020/4690808
Riaz M, Garg H, Farid H, Chinram R (2021) Multi-criteria decision making based on bipolar picture fuzzy operators and new distance measures. Comp Model Eng Sci 127(2):771–800. https://doi.org/10.32604/cmes.2021.014174
Chen TY, Li CH (2011) Objective weights with intuitionistic fuzzy entropy measures and computational experiment analysis. Appl Soft Comput 11(8):5411–5423. https://doi.org/10.1016/j.asoc.2011.05.018
Liu S, Chan FTS, Ran W (2013) Multi-attribute group decision-making with multi-granularity linguistic assessment information: an improved approach based on deviation and TOPSIS. Appl Math Model 37(24):10129–10140. https://doi.org/10.1016/j.apm.2013.05.051
Zhang Q, Chen JCH, Chong PP (2004) Decision consolidation: criteria weight determination using multiple preference formats. Decis Support Syst 38(2):247–258. https://doi.org/10.1016/s0167-9236(03)00094-0
Wang YM (2005) On fuzzy multiattribute decision-making models and methods with incomplete preference information. Fuzzy Sets Syst 151(2):285–301. https://doi.org/10.1016/j.fss.2004.08.015
Fu C, Wang Y (2015) An interval difference based evidential reasoning approach with unknown attribute weights and utilities of assessment grades. Comput Ind Eng 81:109–117. https://doi.org/10.1016/j.cie.2014.12.031
Chin KS, Fu C, Wang Y (2015) A method of determining attribute weights in evidential reasoning approach based on incompatibility among attributes. Comput Ind Eng 87:150–162. https://doi.org/10.1016/j.cie.2015.04.016
Nan JX, Wang T, Wang GX, An JJ (2016) The method for solving multi-objective zero-sum and constrained matrix games with heterogeneous values. Fuzzy Syst Math 30(4):121–128
Nan JX, Li DF, Zhang MJ (2008) A lexicographic method for matrix games with payoffs of triangular intuitionistic fuzzy numbers. Int J Comput Intell Syst 3(3):280–289. https://doi.org/10.2991/ijcis.2010.3.3.4
Ali M, Smarandache F, Vladareanu L. (2016) Neutrosophic Sets and Logic. Emerging Research on Applied Fuzzy Sets and Intuitionistic Fuzzy Matrices
Zeng S, Hu Y, Balezentis T, Streimikiene D (2020) A multi-criteria sustainable supplier selection framework based on neutrosophic fuzzy data and entropy weighting. Sustain Dev 28(5):1431–1440. https://doi.org/10.1002/sd.2096
Riaz M, Hashmi MR, Kalsoom H, Pamucar D, Chu Y (2020) Linear Diophantine fuzzy soft rough sets for the selection of sustainable material handling equipment. Symmetry 12(8):1215. https://doi.org/10.3390/sym12081215
Riaz M, Hashmi MR, Pamucar D, Chu Y (2021) Spherical linear diophantine fuzzy sets with modeling uncertainties in MCDM. CMES-Comp Model Eng Sci 126(3):1125–1164. https://doi.org/10.32604/cmes.2021.013699
Kamacı H (2021) Linear Diophantine fuzzy algebraic structures. J Ambient Intell Human Comput. https://doi.org/10.1007/s12652-020-02826-x
Acknowledgements
The authors are very grateful to the respected editor and the referees for their insightful and constructive comments, which helped to improve the overall quality of the paper. This work was supported by the National Natural Science Foundation of China [Grant number 71502098]; Soft Science Research Support Project of Shanghai Science and Technology Development Foundation [Grant numbers 19692109000 and 20692109400]; and the Training Special Projects of Shanghai University School of Management [2020-SDGY-KZ-003].
Funding
This work was supported by the National Natural Science Foundation of China [Grant number 71502098]; Planning fund of Chinese Ministry of Education Humanities and Social Sciences Research [Grant number 21YJA630010]; Soft Science Research Support Project of Shanghai Science and Technology Development Foundation [Grant numbers 19692109000 and 20692109400]; and the Training Special Projects of Shanghai University School of Management [2020-SDGY-KZ-003].
Author information
Authors and Affiliations
Contributions
Y-DY: conceptualization, methodology, software, validation, formal analysis, investigation, writing—original draft, and project administration. D-XF: formal analysis, resources, data curation, supervision, and funding acquisition.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that there are no conflict of interests.
Ethical approval
This paper does not contain any studies with human participants or animals.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Yang, YD., Ding, XF. A q-rung orthopair fuzzy non-cooperative game method for competitive strategy group decision-making problems based on a hybrid dynamic experts’ weight determining model. Complex Intell. Syst. 7, 3077–3092 (2021). https://doi.org/10.1007/s40747-021-00475-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40747-021-00475-x