
Abstract
Renewable energy, such as wind and photovoltaic (PV), produces intermittent and variable power output. When superimposed on the load curve, it transforms the load curve into a ‘load belt’, i.e. a range. Furthermore, the large scale development of electric vehicle (EV) will also have a significant impact on power grid in general and load characteristics in particular. This paper aims to develop a controlled EV charging strategy to optimize the peak-valley difference of the grid when considering the regional wind and PV power outputs. The probabilistic model of wind and PV power outputs is developed. Based on the probabilistic model, the method of assessing the peak-valley difference of the stochastic load curve is put forward, and a two-stage peak-valley price model is built for controlled EV charging. On this basis, an optimization model is built, in which genetic algorithms are used to determine the start and end time of the valley price, as well as the peak-valley price. Finally, the effectiveness and rationality of the method are proved by the calculation result of the example.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
With the environmental degradation around the world, people are increasingly advocating and pursuing the green living concept, and electric vehicles (EVs) are being increasingly seen as eco-friendly vehicles. On the other hand, the oil and other traditional fossil fuel resources are being depleted, wind power and solar power are being widely studied and used as sustainable and clean energy. Wind, solar and other renewable energy naturally have the characteristics of intermittence and volatility, thus renewable energy generation will inevitably produce power fluctuations to the grid. When large-scale renewable energy connects to the grid, how to stabilize the fluctuation and improve the renewable energy integration ability of the grid becomes a serious problem. With the improvement in the EV technology and rapid rollout of EVs, EV charging is likely to have significant impact on the grid [1, 2]. Therefore, it is important to manage and influence EV charging behaviors in a controlled manner so as to reduce their impact. The controlled EV charging strategy can also improve the load characteristics of the grid, smooth the fluctuation of wind and solar power outputs, and optimize peak-valley of the grid load.
For the study of EV controlled charging and related fields, some results have been published. From the perspective of operation benefits of the charging station and by responding to the time-of-use (TOU) price of the grid, [3] uses the control methods of controlled charging to improve the economic benefits of charging stations, but it does not consider smoothing load fluctuations of the grid, it may result in an additional peak at night. Reference [4] proposes an optimized model for TOU price time-period. It uses the controlled charging of EVs to cut the peak and fill the valley of the power grid load curve, but it does not consider the value of peak-valley price and demand side response. Reference [5] considers reducing the peak-valley difference as the primary goal, taking into account the division of TOU periods and load fluctuations of the local distribution network. It does not consider the influence of the wind, solar and other new energy power on the grid load characteristics. Reference [6] establishes a mathematical model of dispatching EVs and wind power cooperatively, analyses the feasibility of dispatching the EV charging to smooth the load fluctuations and to consume the superfluous wind power at night. However, the paper does not propose specific solutions for controlled charging from the point of demand side response.
This paper develops a probabilistic model of wind and photovoltaic (PV) power outputs, and a method of assessing the peak-valley difference of the stochastic load curve is put forward. A two-stage peak-valley price model is constructed and is used to guide EV charging, an optimization model is built, in which genetic algorithms are used to determine the start and end time of the valley price, as well as the value of the peak-valley price.
2 Controlled EV charging based on demand side response
2.1 Two-stage model of peak-valley price
Firstly, the two-stage peak-valley price model is built for controlled EV charging as follows:
where P v is the price of valley period; P p is the price of peak period; t 1 is the start time of valley period; t 2 is the end time of valley period.
In this paper, the peak-valley rate β is defined as:
where P 0 is the grid original tariff when TOU pricing policies are not implemented.
2.2 Analysis of user response
With the increasing of β, the user response has three stages, as shown in Fig. 1. In the first stage, β is in the interval (0, a), users choosing to charge in valley period for tariff factor are very few. In the second stage, when β reaches a certain value, with the increasing of β, more and more users choose to charge in valley period for the price factor. In the third stage, the number of users choosing to charge in valley period stops increasing. In the figure, λ = n/N is the ratio of the responding EV users, in which n is the number of EVs charged in valley period and N is the total number of EVs.

Schematic diagram of user response
The EV users’ responsiveness to the peak-valley rate β is also affected by the time.
where T p is the period that users’ driving demand for EVs is urgent; T y is the period that users’ driving demand for EVs is common; and T d is the period that users’ driving demand for EVs is low.
In different periods, users’ response to peak-valley rate β is different, as shown in Fig. 2.

Responding curve considering driving demand factors
So, EV users’ price response function should be a three-dimensional surface which contains peak-valley rate β and time, as shown in Fig. 3.

Response surface considering driving demand factors
The responding users’ start time of charging is described by the formula:
where t s is the start time of charging; t c is the duration of charging; and α is a random number in interval (0,1).
When the charging time is shorter than the valley period, users will choose any time in the valley period that EV can be fully charged, and when the charging time is longer than the valley period, users will choose the start time of valley period to charge.
3 Probabilistic model of regional wind and PV power
3.1 Load curve transformation when renewable energy is superimposed on
If a area has n wind farms, the number of wind turbines in farm i is N i (i = 1,2,⋯,n) and the farm has m PV power stations, the number of PV modules in PV station j is M j (j = 1, 2,⋯, m), the following assumptions are made.
-
1)
In the same wind farm, the relationship between the outputs of different wind turbines is strongly correlated, the correlation coefficient is 1; and the relationship between the outputs of different wind farms is mutually independent, the correlation coefficient is thus 0.
-
2)
Similarly, in the same PV station, the relationship between the outputs of different PV modules has a correlation coefficient of 1; and the relationship between the outputs of different PV stations is mutually independent with correlation coefficient equal to 0.
-
3)
The relationship between the outputs of PV stations and wind farms is mutually unrelated, the correlation coefficient is 0.
Then for wind farm i, its total output is \( P_{i} = N_{i} P_{\text{w} } \), in which P i is the total output of the wind farm i, P w is the output of a single wind turbine. Similar results could be obtained for PV stations.
According to the methods in [7], when wind speed meets the Weibull distribution, assuming the active power outputs of wind farms are random variables, based on the historical data, we can get their semi-invariants δ i , i = 1, 2,⋯,n. Similarly, when light intensity meets the Beta distribution, based on the historical data, the semi-invariant of the active power output of PV station j is ε j , j = 1, 2,⋯, m.
Since the active power outputs of n wind farms and m PV stations are mutually independent, based on the additivity of the semi-invariant, the semi-invariant of the regional total active power output is:
where γ is the semi-invariant of the regional total active power output.
In this paper, we consider that the distribution of wind speed and light intensity are different at different times of the day. Based on the historical hourly data, we can divide one day into 24 parts, therefore, 24 pairs of expectation μ and standard deviation σ for wind speed and light intensity can be obtained, respectively, and we can get 24 Weibull distributions and 24 Beta distributions.
Therefore we can get 24 semi-invariants of the regional total power output:
where γ k is the semi-invariant of the regional total active power output of the time k, k = 1,2,⋯,24.
In turn, by the Gram–Charlier expanding [8, 9], for the random variables of the regional total active power outputs, their probability density function f k (x) and cumulative distribution function F k (x) can be obtained, as shown in Fig. 4 (the semi-invariant of the curve is got from the historical data of wind speed and light intensity in the certain area).

Probability density function f k (x) and cumulative distribution function F k (x)
Generally, the random variable falls inside the interval (μ k − 3σ k , μ k + 3σ k ), which can be considered, for the total active power outputs of wind farms and PV stations, the minimum is μ k − 3σ k , and the maximum is μ k + 3σ k , k = 1,2,⋯,24.
Figure 5 is a typical daily load curve of a certain area, when regional wind and PV power outputs are superimposed on it, the composite load curve is shown in Fig. 6. So the load curve is no longer deterministic, it is a random curve inside the ‘load belt’ and meets certain probabilistic rules, as shown in Fig. 7.

A typical daily load curve of a certain area

Changing process of load curve

The ‘load belt’ of area
3.2 Impact of unordered charging
So when large-scale EVs get charged in an uncontrolled manner, using the Monte Carlo simulation method of [10], the load curve of uncontrolled charging can be obtained. When there are one million uncontrolled charging EVs in a certain city, its ‘load belt’ is shown in Fig. 8.

Impact of large-scale EV uncontrolled charging on original ‘load belt’
It can be obtained from Fig. 8 that, the charging peak would appear near the peak of the original load, resulting in the lifting of the original ‘load belt’ peak, and the peak-valley difference gets bigger.
3.3 Probabilistic model of wind and PV power outputs
In every hour, the load is a random value between the minimum and the maximum, and its derivation process of the probability density function is as follows.
In Fig. 9, at time t, t = 1, 2,⋯,24, if the random variable of load is L t . L t is a random value between point b and c. Point a corresponds to the original load of the grid, its value L ta is determined; point b corresponds to the load when total outputs of wind farms and PV stations are maximum, its value is L tb ; point c corresponds to the load when total output is minimum, it is L tc . The relations among them are:

Range of load fluctuation at time t
where C t is the random variable of the total output of wind farms and PV stations at time t, probability density function of C t is f t (c) (the method of calculating f t (c) has been explained before), the probability density function of random variable L t is \( g_{t} (l) = f_{t} \left( {L_{ta} - l} \right) \), in which l is the value of L t .
In the above process, the probabilistic model of wind and PV power outputs is built, thus, for each of the 24 time points of the ‘load belt’, the probability density function of the random variable has been obtained [11–13].
4 Method of assessing peak-valley of uncertain load curve
When regional wind and PV power outputs are superimposed on, the load curve is no longer deterministic, it is a random curve inside the ‘load belt’ [14]. This paper proposes a probabilistic method to assess the peak-valley difference.
If the random variable of load at t 1 is L t1, its probability density function is g t1(l), and at t 2, the probability density function of L t2 is g t2(l), assume that \( \mu_{t2} > \mu_{t1} \), then:
In this paper, we refer to θ as the peak-valley difference index. Therefore, assume that random variables L t1 and L t2 are mutually independent, and if \( L^{\prime} = \left( {1 - \theta } \right)L_{t2} - L_{t1} \), then by using the additivity of the semi-invariant, the cumulative distribution function of \( L^{\prime} \) can be obtained from g t1(l) and g t2(l), we write it F F(l), therefore:
Firstly, calculate the expectations of the 24 random variables at 24 time points, select the first three maximum points as the possible ‘peak’ time points and the last three minimum points as the possible ‘valley’ time points, then use \( P\left( {(L_{t2} - L_{t1} )/L_{t2} \le \theta } \right) \) to calculate the three pairs of time points above. Choose the minimum of the calculation results as the final value of P θ , P θ is the probability that peak-valley difference is less than or equal to the certain peak-valley difference index θ:
where L tp is the random variable of load at ‘peak’ time; L tv is the random variable of load at ‘valley’ time. As the interval between random variables L tp and L tv is long, they can be considered mutually independent [15, 16].
To illustrate P θ can effectively reflect the value of the peak-valley difference, for the first graph in Fig. 10, \( P_{\theta }^{(1)} = P\left( {(L_{t{\rm p}} - L_{t{\rm v}} )/L_{t{\rm p}} \le \theta } \right) \), and the second graph \( P_{\theta }^{(2)} = P\left( {(L_{t{\rm p}} - L_{t{\rm v}} )/L_{t{\rm p}} \le \theta } \right) \), we can get the Table 1.

Two different ‘load belts’
It can be seen from Table 1 that, for every peak-valley difference indices, \( P_{\theta }^{(1)} < P_{\theta }^{(2)} \) is right. Therefore it can be concluded that, there is a positive correlation between P θ and the peak-valley difference of the uncertain load curve, the bigger the value of P θ is, the smaller the peak-valley difference (peak-valley difference rate) is, and the flatter the load curve is.
5 Optimization model
Based on the ordered charging model, the power supply side guides the charging of EVs by formulating P p and P v, and delimiting the start and end time of valley period t 1 and t 2.
If the total number of EVs is N, corresponding to every (P p, P v, t 1, t 2), there are λN EVs choose ordered charging, its load curve is ζ o; (1 − λ)N EVs choose unordered charging, its load curve is ζ f; the ‘load belt’ superimposed on the regional wind and PV power outputs is ζ b, then corresponding to the (P p, P v, t 1, t 2), the ‘load belt’ is ζ = ζ b + ζ o + ζ f, it is meaningful and important to find the (P p, P v, t 1, t 2) that can make the peak-valley difference of the ζ minimum, that is to make the P θ of ζ maximum.
Through the above analysis, we know λ is a function and t 1, Δt, β are its independent variables, Δt is the duration of valley period, Δt = t 2 − t 1.
Therefore, in order to optimize the peak-valley difference, the following optimization model is built:
To take the maximum P θ as the target, and use genetic algorithms to determine the start time t 1 and the duration of valley period Δt, as well as the peak-valley rate β.
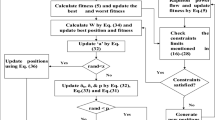
The flow chart of genetic algorithm optimization and objective function is shown in Fig. 11.

Flow chart of genetic algorithm optimization and objective function
6 Case study
In this example, the typical daily load curve of a city is selected as the basis. By assuming the specific parameters of its wind farms and PV stations, and based on the historical data, we assume the city has one million EVs. EV constant charging power is P c = 2.5 kW.
In this example, when driving demand is different, users’ response to peak-valley rate β is shown in Fig. 12. When driving demand is common, the response curve is the average of the two curves. The maximum value is β lim = 1.5.

Response curves in different driving demands
At different time, users’ driving demand for EVs is different in a day, so we divide one day into three periods according to EV users’ schedule of the city: ①T p: the period that users’ driving demand for EVs is urgent (7:00–10:00 and 16:00–20:00); ②T y: the period that users’ driving demand for EVs is common (22:00–7:00); ③T d: the period that users’ driving demand for EVs is low (10:00–16:00 and 20:00–22:00).
According to the above parameters, the genetic algorithm toolbox of MATLAB is used to achieve the simulation, the optimization results are shown in Table 2.
From the above results, it can be seen that, for different peak-valley difference indices, an optimization result (t 1, Δt, β) can be got corresponding to it, as shown in Fig. 13.

Optimization ‘load belts’ of different peak-valley difference indices
Take the optimization result when θ = 35% as an example, (t 1, Δt, β) is (0.926, 6.4787, 1.1822).
After using the genetic algorithm to optimize P θ , the probability that the peak-valley difference is less than or equal to 35% is 79.69%, in the valley period of load, after guiding EV ordered charging, the load increases. It can be intuitively seen from Fig. 13b that, the optimized ‘load belt’ tends to be smooth. It can be obtained from the optimization results that, when considering the regional wind and PV power outputs, the method of ordered charging in this paper can effectively optimize the peak-valley difference.
7 Conclusion
Through the probabilistic model of regional wind and PV power outputs and the model of peak-valley price in two-stage, this paper solves the problem of large scale EV ordered charging. Furthermore, it achieves the goal of stabilizing the power fluctuations caused by the regional wind and PV outputs and optimizing the peak-valley difference in the gird. As analyzed above, the effectiveness and rationality of the models and methods have been proved.
References
Zhang WL, Wu B, Li WF et al (2009) Discussion on development trend of battery electric vehicles in China and its energy supply mode. Power Syst Technol 33(4):1–5 (in Chinese)
Zhuang X, Jiang KJ (2012) A study on the roadmap of electric vehicle development in China. Automot Eng 34(2):91–97 (in Chinese)
Xu ZW, Hu ZC, Song YH et al (2012) Coordinated charging of plus-in electric vehicles in charging stations. Autom Electr Power Syst 36(11):38–43 (in Chinese)
Ge SY, Huang L, Liu H (2012) Optimization of peak-valley TOU power price time-period in ordered charging mode of electric vehicle. Power Syst Protect Control 40(10):1–5 (in Chinese)
Sun XM, Wang W, Su S et al (2013) Coordinated charging strategy for electric vehicles based on time-of-use price. Autom Electr Power Syst 37(1):191–195 (in Chinese)
Yu DY, Song SG, Zhang B et al (2011) Synergistic dispatch of PEVs charging and wind power in Chinese regional power grids. Autom Electr Power Syst 35(14):24–28 (in Chinese)
Wang CS, Zheng HF, Xie YH et al (2005) Probabilistic power flow containing distributed generation in distribution system. Autom Electr Power Syst 29(24):39–44 (in Chinese)
Shi DY, Cai DF, Chen JF et al (2012) Probabilistic load flow calculation based on cumulant method considering correlation between input variables. Proc CSEE 32(28):104–113 (in Chinese)
Zhang P, Lee ST (2004) Probabilistic load flow computation using the method of combined cumulants and Gram-Charlier expansion. IEEE Trans Power Syst 19(1):676–682
Peterson SB, Whitacre JF, Apt J (2010) The economics of using plug-in hybrid electric vehicle battery packs for grid storage. J Power Sources 195(8):2377–2384
Wang JH, Shahidehpour M, Li ZY (2008) Security constrained unit commitment with volatile wind power generation. IEEE Trans Power Syst 23(3):1319–1327
Tian LT, Shi SL, Jia Z (2010) A statistical model for charging power demand of electric vehicles. Power Syst Technol 34(11):126–130 (in Chinese)
Hu ZC, Song YH, Xu ZW et al (2012) Impacts and utilization of electric vehicles integration into power systems. Proc CSEE 32(4):1–10 (in Chinese)
Zhao JH, Wen FS, Xue YS et al (2010) Power system stochastic economic dispatch considering uncertain outputs from plug-in electric vehicles and wind generators. Autom Electr Power Syst 34(20):22–29 (in Chinese)
Saber AY, Venayagamoorthy GK (2011) Plug-in vehicles and renewable energy sources for cost and emission reductions. IEEE Trans Ind Electron 58(4):1229–1238
Hübner M, Zhao L, Mirbach T, et al (2009) Impact of large-scale electric vehicle application on the power supply. In: Proceedings of the 2009 IEEE electrical power and energy conference (EPEC’09), Montreal, Canada, 22–23 Oct 2009, 6 pp
Acknowledgments
This work is supported by National Natural Science Foundation of China (No. 51477116) and the Special Founding for “Thousands Plan” of State Grid Corporation of China (No. XT71-12-028).
Author information
Authors and Affiliations
Corresponding author
Additional information
CrossCheck date: 3 March 2015
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
LIU, H., ZENG, P., GUO, J. et al. An optimization strategy of controlled electric vehicle charging considering demand side response and regional wind and photovoltaic. J. Mod. Power Syst. Clean Energy 3, 232–239 (2015). https://doi.org/10.1007/s40565-015-0117-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40565-015-0117-z