
Abstract
Metal-based additive manufacturing requires active monitoring solutions for assessing part quality. Multiple sensors and data streams, however, generate large heterogeneous data sets that are impractical for manual assessment and characterization. In this work, an automated pipeline is developed that enables feature extraction from high-speed camera video and multi-modal data analysis. The framework removes the need for manual assessment through the utilization of deep learning techniques and training models in a weakly supervised paradigm. We demonstrate this pipeline’s capability over 700,000 high-speed camera frames. The pipeline successfully extracts melt pool and spatter geometries and links them to corresponding pyrometry, radiography, and processparameter information. 715 individual prints are examined to reveal melt pool areas that exceeds 0.07 mm2 and pyrometry signal over a threshold (375 pyrometry units) were more likely to have defects. These automated processes enable massive throughput of characterization techniques.
Similar content being viewed by others

Explore related subjects
Discover the latest articles, news and stories from top researchers in related subjects.Avoid common mistakes on your manuscript.
Introduction
Recent advancements in additive manufacturing (AM) have significantly broadened the scope of fabrication capabilities, enabling the creation of complex geometries and the use of diverse materials. Notably, laser powder bed fusion (L-PBF) produces parts through the deposition of metal powder feedstock onto a build plate, followed by selective melting and solidification using a laser [1, 2]. AM and L-PBF are challenging due to their wide range of materials and intricate geometries [3,4,5]. The interplay between material properties and process parameters necessitates robust monitoring and quality control mechanisms to ensure the reliability and integrity of printed components [6,7,8,9]. The growing adoption of AM across industries [10,11,12] highlights the critical need for advanced techniques to monitor the printing process and identify potential defects early on [13, 14].
One of the most prevalent issues in L-PBF is the formation of defects such as pores, which can compromise the mechanical properties of a build [2, 15, 16]. These defects are often correlated to melt pool characteristics, which are in turn influenced by process parameters such as laser power, speed, and hatching space [17]. For example, excessive laser power is applied can lead to keyhole defects [18, 19], characterized by deep penetrations in the melt pool [20] that introduce a morphology [21,22,23]. On the contrary, insufficient laser power may cause lack-of-fusion defects [24, 25], characterized by large, irregular voids within the printed part [26]. Literature has extensively examined process parameters such as print speed and laser power [21] to minimize the formation of pore defects [27,28,29,30].
To address these challenges, in situ monitoring techniques employing sensors such as high-speed cameras and pyrometers have been developed. These sensors enable the real-time observation of melt pool dynamics and thermal profiles [31,32,33], generating vast amounts of heterogeneous data that require sophisticated analysis methods [16]. However, the sheer volume and complexity of this data pose significant analytical challenges, necessitating advanced data processing and analytics solutions [34,35,36].
Extracting melt pool geometry from high-speed camera images in itself represents a significant challenge. Traditional feature extraction techniques, such as thresholding, edge detection, and region-based segmentation, have been employed to delineate the melt pool from the surrounding material [20, 37, 38]. Computer vision monitoring has been implemented as well to extract these features from high-speed camera images of single tracks [39,40,41]. Despite their utility, these classical image processing methods often struggle with the variability in melt pool appearance due to changes in process parameters, reflections, and spatter, requiring extensive tuning and manual intervention for each set of conditions.
Deep learning has recently enabled feature extraction to scale across large diverse data sets to enable novel insights recently [42, 43]. Convolutional Neural Networks (CNNs) in particular, offers a more robust alternative capable of capturing complex patterns in image data, including subtle variations in melt pool geometry [44, 45]. These models can learn to identify melt pools under a wide range of conditions. However, their effectiveness is contingent upon the availability of large, accurately annotated data sets. This dependency can be supported by a subfield in deep learning called weak supervision. Weak supervision leverages more accessible, albeit less precise, sources of information to train deep learning models. This approach can involve using simpler image processing techniques to generate approximate labels or reducing the dependency on extensive manual annotations.
Analysis of melt pool geometry alone, however, provides limited information [18, 23, 46]. By linking in situ monitoring data with ex-situ analysis, such as radiography, a comprehensive approach is offered to understanding and correlating observable features with the presence of defects. Radiography for example, provides granular details into qualities such as number of pores, size and pore shape [16, 23, 47] that are useful for understanding the part quality and characterization of its microstructure [48].
In this work, we develop an automated pipeline that leverages deep learning, classical image processing, and multi-modal analytics to extract melt pool and spatter visual features from over 700,000 high-speed optical monitoring camera frames, tracking 715 metal L-PBF prints. A U-Net [49] deep learning model is trained under a weakly supervised paradigm to perform feature extraction. Large-scale statistical characterization then uncovers influential trends in quantities like melt pool area and pyrometry signals that relate to a higher likelihood of flaws. The entire framework provides a workflow to connect sensor streams to data-driven part qualification insights without extensive human involvement. Through date-enabled characterization, the methodology demonstrates progress toward goals of real-time defect prediction, informed process control, and autonomous metal additive manufacturing.
Methods
Experimental Setup
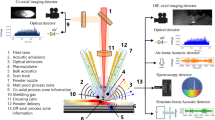
An open architecture L-PBF Aconity3D (AconityUS, Inc.) system, described in previous work [22, 50], was used for the initial fabrication of samples. In situ measurements were recorded using a coaxially aligned in-line pyrometer and high-speed video camera; this setup enabled data acquisition to be temporally synchronized to the fabrication process. This setup is depicted in Fig. 1a.

Schematic of L-PBF experimental setup with co-axial in situ monitoring shown in (a) and X-ray radiography experiment shown in (b). Reprinted from [50] with permission. Final build plate consisting single and multi-tracks after L-PBF fabrication in (c)
Operational parameters were recorded, spanning a combination of laser power (from 50 to 375 W) and laser velocities (from 100 to 400 mm/s) with hatch spacing of 0.1 mm. High-speed camera videos were recorded on a 10-bit Micronton EoSens MC1362 with a capture rate of 1 kHz, with a 14 µm/pixel resolution. Pyrometry measurements were performed on a Kleiber KGA 740LO, Kleiber Infrared GmbH, tuned to capture infrared (IR) emission of wavelengths ranging from 1600–1800 nm with a 100 kHz capture rate.
The data set consists of 666 single-track printed uni-directionally along with 50 multi-track prints, as depicted in Fig. 1c. The prints systematically vary across different combinations of laser power and speed. These were a grid layout and order randomized to minimize residual thermal effects between adjacent prints. All samples were produced using a 316 L stainless steel powder feedstock with particle sizes ranging from 15 to 45 µm. Each sample used a beam second moment width of approximately 100 µm (D4\(\sigma \)).
The final build segmented for ex situ radiography is shown in Fig. 1b. Ex situ measurements through X-ray radiography imaging were completed at the Advanced Light Source at Lawrence Berkeley National Laboratory. Projections were taken with a polychromatic beam using a 5x lens, resulting in 1.3 µm/pixel resolution and 100 ms exposure time on three 0.1 \(\times \) 3 \(\times \) 7 cm3 plates, containing the laser printed tracks. Pores were manually selected using the open source software Fiji [51] Fig. 2.

High level overview of multi-modal data pipeline. High-speed camera features are extracted and integrated with radiography, pyrometry, and process parameters at the sample level
Data Science and Computing Infrastructure
Model training and data analysis were performed using the High Performance Computing (HPC) cluster at Case Western Reserve University which is described in in References [52, 53]. Distributed data storage and processing were done using the Common Research Analytics and Data Lifecycle Environment (CRADLE™), described in References [54, 55]. Large-scale data processing [56] employed Hadoop, HBase, and Spark in CRADLE.
Data cleaning was performed using R(3.3.0+)/RStudio(4.2.2) [57, 58] and the Tidyverse [59] packages. Python (3.11.4) [60] was used for image sequence preprocessing, feature extraction, and model training. Image frames were extracted from high-speed camera videos with FFmpeg [61]. Image processing and data analysis were done with NumPy [62], scikit-image [63], and pandas [64]. Image segmentation implemented U-Net [49] from scratch using TensorFlow [65].
Image Processing Feature Extraction
An image processing pipeline was developed to extract the two features of interest from high-speed camera frames: melt pool and spatter. This is a simple variation of melt pool feature extraction compared to that of related literature; it serves as a rough baseline for the downstream analysis performed in the overall feature extraction pipeline. Since the laser was not powered on for the majority of the high-speed camera video, most image frames contain neither feature. In image frames where the laser is powered, the melt pool appears as the highest intensity region of the image typically in the shape of an ellipse [22]. Spatter only exists in a subset of image frames when the laser is powered on and appears as sharp, thin streaks.
The image processing workflow can be described as follows. First, a high-speed camera video is processed with each frame analyzed to detect the presence of melt pool. The frame is flagged as containing a melt pool if the number of unique pixel values passes a threshold (meaning the image is not entirely black). If a melt pool is present, a local contrast enhancement with a neighborhood size of 10 pixels is applied. Next, a local threshold with a neighborhood size of 20 pixels is applied. These two steps binarize the image into distinct components by setting pixels corresponding to a feature classed as 1 and background pixels to 0. The determination of neighborhood sizes, was achieved through rigorous parameter testing and validation against manually annotated images.
The process of identifying and quantifying features from the captured images employs the connected components algorithm, a graph-based technique designed for object extraction in binary images. This algorithm operates by identifying adjacent pixels of identical value and grouping them into distinct components, subsequently calculating relevant statistics for each identified group. Specifically, for melt pool and spatter analysis, key metrics such as the centroid, area, mean intensity, and the lengths of the major and minor axes are determined. The object with the highest intensity is designated as the melt pool, whereas objects with lower intensity are classified as spatter. This distinction is crucial, especially in scenarios where melt pools are small and spatter objects are comparably large, making size an unreliable differentiator. Instead, intensity serves as the primary criterion for classification. A sample pipeline workflow is summarized in Fig. 3.
This pipeline was performed over 715 high-speed camera videos where each video contained 1000 frames at a 256 x 256 pixel resolution. This image processing pipeline was performed over all extracted frames in parallel using the Simple Linux Utility for Resource Management (SLURM) [66, 67]. SLURM enabled the efficient deployment of the pipeline to quantify data from over half a million image frames across hundreds of HPC nodes..

Sample pipeline for high-speed camera frames using image processing to find and mask for features. Discovered features are classified as the melt pool or spatter. Feature statistics are gathered from pixel-wise measurements
Deep Learning Feature Extraction
A deep learning pipeline was also developed for feature extraction and quantification of melt pool and spatter. In order to train a deep learning model for segmentation, the model requires both the original image and a corresponding segmentation mask, where each pixel is categorized either as a specific feature of interest or as background. Conventionally, this segmentation process relies heavily on the expertise of a subject matter expert to manually annotate images, a method both time-consuming and prone to variability. Here, however, we leverage the outputs of our image processing pipeline as a form of pseudo-ground truth to train our deep learning model. This approach, where image processing-generated masks serve as initial training data, is a form of weak supervision. It significantly streamlines the training process by utilizing readily available, albeit imperfect, data as a substitute for manually annotated data sets.
The model architecture and training procedure are described as follows. U-Net [49], a CNN-based architecture, was selected as the segmentation model. A standard implementation of U-Net was constructed, with four encoder and four decoder blocks. The encoder blocks, designed for feature extraction, consist of convolutional layers followed by max pooling, whereas the decoder blocks, aimed at image reconstruction, include transposed convolutional layers for upsampling, along with concatenation and convolutional layers. Each convolutional block comprises two convolutional layers, each followed by batch normalization and ReLU activation. Convolutional layers employ L2 regularization to improve generalization and reduce overfitting. Layers in the encoder increase the number of filters from 64 to 1024, doubling each layer. The opposite occurs in the contracting path. The model used a single-channel input to handle gray-scale images and contained a total of 31,054,275 parameters.
The model was trained for 200 epochs with early stopping set to a patience of 10. Adam was used as the optimizer [68] with a learning rate of 0.001. Categorical focal cross-entropy was selected as the loss function, for multi-class semantic segmentation. We measured model performance using accuracy, precision, recall, and intersection-over-union (IoU).
A curated data set of 200 sample frames, specifically selected to represent instances when the laser was active was used to train the model. This data set was balanced to include frames featuring solely the melt pool and those capturing both the melt pool and spatter, ensuring the model’s unbiased learning towards the less frequently observed spatter features. This data was distributed over different energy density and parameters regimes to provide a robust representation of process parameters. The data set was divided using an 80/10/10 split for training, validation, and testing, respectively. The respective data sets were batched into sets of 8 images per batch.
Upon training completion, the best-performing model, as determined by validation metrics, was used to performance inference across the entirety of the high-speed camera footage. After generating predictions across all high-speed camera videos, statistics of features were quantified using the same connected components approach described in the image processing pipeline. In this case, however, the label of melt pool or spatter was automatically assigned by the predictive U-Net model.
Multi-modal Data Integration
Four characterization methods of samples are integrated to give a multi-modal, spatiotemporal representation of the data set. The four methods include: process parameters, in situ pyrometry data, high-speed camera features, and X-radiography features.
High-speed camera features after quantification were labeled using a track ID and frame number from the video. These were merged with pyrometry signal measurements through spatiotemporal components such as coordinate locations and time. A single high-speed camera frame is matched to 100 pyrometry readings due to the faster rate of measurement. Fiji [51] was used for manual pore assignment using radiography projections. The pore assignment was merged with the integrated high-speed camera and pyrometry data where a single track is labeled as true or false for the presence of pore.
In total, our multi-modal data set consists of over 700,000 frames annotated with segmentation labels, regional feature vectors, aligned pyrometry signals, and registered pore labels for investigating predictive relationships. Custom correlation and multivariate analysis is conducted using Python and R to relate modalities. All information was ingested into CRADLE’s Hadoop ecosystem for efficient querying and analysis using Spark.
The resulting labeled features from the three approaches were saved into a database with the corresponding frame and track number. This enabled the comparison to other measurements such as the pyrometry signal and pore count assignments. Each approach was then compared to examine the resulting features that were extracted. These features were compared using multivariate statistical analytics to uncover statistically significant patterns and to predict defect formation.
Results
Deep Learning Model Performance
The U-Net model demonstrated strong performance on the melt pool and spatter segmentation task. As illustrated in Fig. 4, the model converged after approximately 50 epochs. Training and validation curves are plotted for both the loss function as well as the IoU metric (calculated in a class-wise and mean manner). Table 1 summarizes the metrics from the highest performing epoch, based on validation metrics during training. The results indicate robust performance in terms of accuracy, recall, and precision across both the training and validation data sets.
IoU, however, was specifically selected for plotting given it provides a more robust metric for assessing model performance. In cases where the features of interest occupy a small region relative to the background, metrics such as accuracy, precision, and recall can be biased. Both Fig. 4 and Table 1 demonstrate the model’s proficiency in segmenting the melt pool region, with IoU scores of 0.99 on both the training and validation sets. This highlights the model’s ability to effectively generalize to new data. Performance for spatter segmentation was less successful, with a maximum IoU of 0.767 on the validation set, indicating a failure to fully converge on this feature. Justification for this discrepancy in performance across the two features is provided in subsequent sections.

U-Net training and validation loss curves. Intersection-over-union (IoU) curves class-wise and mean for melt pool and spatter
Feature Extraction and Quantification
After performing inference on the full set of 715 high-speed camera videos using the trained U-Net model, measurable melt pool and spatter features were detected in 682 videos. In total, the model identified 497 individual melt pool instances and 682 distinct spatter occurrences. For each detected feature, characteristics such as area, axis lengths, perimeter, and intensity were quantified to enable detailed analysis [69, 70].
Area distributions of melt pool and spatter features are depicted in Fig. 5 with average values found in Fig. 2. The melt pool features exhibited a mean area of between 1636 to 4386 microns2 with a standard deviation of 1543–2528. Quantified metrics for the spatter features revealed greater variability, with a mean area of 342–470 microns and a standard deviation of 446–590. The increased variance indicates more diversity in the shape and size of spatter formations relative to melt pools.

Area distributions of melt pool (a) and spatter (b) features as provided by the image processing pipeline and deep learning inference. Image processing is depicted in blue and U-Net is depicted in yellow
Multi-modal Feature Analysis
After integrating multiple modalities including process parameters, pyrometry measurements, radiography, and high-speed camera features into a single data set, a comprehensive analysis was conducted to understand feature relationships. Figure 6 depicts how laser power (a), laser speed (b), and presence of defects from radiography (c) vary across the build plate by track.

Distribution of process parameters and defects across the build plate: a represents distribution of laser power b represents distribution of laser speed c denotes presence of pore within a track
A comparative summary from all three modalities is shown in Fig. 7. For each combination of laser power and speed parameter setting, the heat maps displays: number of defects observed in radiography, mean melt pool area from high-speed camera analysis, and average pyrometry measurement. Regions of the heat map are follow a similar trend previous work with multi-modal sensors [21, 50].
The mean (\(\bar{X}\)) and standard deviation (\(\sigma \)) of pyrometry for each parameter group were calculated as:
where \(X_i\) is an individual data point and N is the sample size. A 99% confidence interval around the mean was defined as:
where Z = 2.8.
Key relationships can be observed between modalities and across process parameters. For example, pyrometry values show an inverse trend with laser power, while melt pool size increases with power. Further analysis is warranted to determine optimal parameter settings which avoid defects while maintaining an ideal melt pool morphology.

Heat map comparing the standard image processing method. Frames able to be processed have corresponding diagnostic data from in-situ monitors and dimensions
Analysis of Defect Occurrence
To elucidate potential causes of defect formation, high-speed camera features were analyzed based on whether pores were observed via radiography. Table 2 summarizes mean values of pyrometry signals and melt pool/spatter areas segmented from camera images for cases with and without pores.
As shown in Fig. 8d, the distributions of melt pool area and pyrometry signal differ substantially depending on if a pore defect occurs in the same location. Specifically, tracks containing pores exhibit higher average pyrometry intensity and larger melt pool size. This indicates excess thermal energy and unstable melt pool dynamics may increase likelihood of pore formation.

Distribution of pyrometry and high-speed camera feature (melt pool and spatter) area values by the presence of pore. The dashed line represents the mean value of measurements. Average values are found in Table 2
Discussion
Performance of Image Processing and Deep Learning

High-speed camera feature extraction from three unique regions of the parameter space. Depiction of the original image and a comparison of features segmented by image processing and U-Net
Traditional image processing and weakly supervised deep learning were each applied for automated extraction of melt pools and spatter from high-speed camera images. Figure 9 depicts specific examples and captures some general trends that emerge in comparing these approaches. As shown in Fig. 7 the image processed data had similar melt pool areas, pyrometry signals and pore defect distribution compared to the U-Net model. While the data set is limited to high speed visual imaging, this application is limited due to limitations of the detector. Over-saturation of the detector may also reduce the reliability of this data set by limiting the resolution of the image for detecting features uniquely.
Comparing the two approaches reveals the following. The image processing methodology has the ability to detect extremely low contrast phenomena not detected by the deep learning approach. This can be attributed to the contrast enhancement which improves visibility of features. The flip-side of this coin, however, is that residual light from features is also increased which results in an over-estimation of large, visible features. These errors may be due to the relatively small training data set that was initially trained on. The deep learning model (U-Net) trained on these noisy labels tends to negate this effect and produce more precise segmentation of large visible features. However, this comes at the cost of missing more small, diffuse objects. Each approach as a result tends to perform better in different data regimes. Increasing the size and distribution of the training data set, can potentially enable the deep learning model to further refine noisy labels and predict across a more robust domain.
Weak Supervision for Manual Annotation Free Training
A key advantage of weak supervision is eliminating the requirement for manual annotation of training data sets. By employing image processing as a proxy for manual annotation, a much lower effort is required to generate labels for training. We demonstrate this feasibility using the most basic and simplistic case of image processing: contrast enhancements and thresholding. However, vast literature exists on more sophisticated computer vision techniques amenable to automated feature extraction. Methods like SIFT can better capture melt pool geometry and clustering algorithms such as K-means can segment features into multiple regions of intensity. Integrating more advanced methodologies like these for automated label generation could further improve model performance over the simple pipeline presented.
The weak supervision paradigm provides flexibility to leverage emerging techniques without costly manual annotation needing scarce domain experts. Any classical or contemporary computer vision approach with parameters generating segmentation masks or feature descriptors could slot into the framework as a labeling mechanism for deep learning. In the event that large labeled data sets become available, the deep learning models can be trained directly on expert ground truth to improve accuracy further.
Towards Automated Real-Time Monitoring
Analysis of 715,000 high-speed camera frames from additive manufacturing builds demonstrates the efficiency of the automated pipeline against manual examination. The trained U-Net model was benchmarked to perform inference on a single image in 0.00393 s or roughly 250 Hz. While a gap exists between the 1 kHz capture rate and 250 Hz inference rate, these metrics demonstrate strong use for offline assessment or a system with acceptable latency. Additional batch processing in the pipeline, using a more efficient model backbone, or model pruning can all be employed for closer to real-time analysis.
This throughput opens the door for real-time melt pool morphology and quality monitoring during builds. By analyzing imagery as it is captured and linking extracted visual metrics to process variables, the pipeline could enact closed-loop feedback control. For example, detecting an unusually large or energetic melt pool could trigger adaptive adjustments to laser power or scan speed to stabilize the process before defects emerge.
However, high-speed camera data alone provides an incomplete picture. Integrating additional in situ sensor streams like infrared cameras or pyrometers as well as post-process metrology from CT scans or microscopy will likely achieve a more holistic and robust monitoring. Sensor fusion combines perspectives to enrich the process signature for accurate quality assessment. Links between visual, thermal, and parameter data streams may provide the most discerning insights into build health. An automated framework encompassing this multi-modal pipeline, computer vision techniques, real-time analytics, and actuators for process variable adjustment could significantly reduce defects through closed-loop control.
Conclusion
In this work, we developed an automated pipeline for analyzing melt pool morphology and quality monitoring in metal additive manufacturing from high-speed camera footage. The pipeline integrates both classical image processing methods and deep neural networks for detecting key phenomena like melt pools and spatter.
We demonstrate its capabilities on a data set of over 700,000 high-speed camera frames. Our approach affirms the feasibility of training convolution neural networks like U-Net in a weakly-supervised fashion using only the output of threshold-based segmentation algorithms on enhanced images, rather than human-annotated labels. Results indicate that although imperfect, these automated labels can empower precise feature extraction. However, model refinements based on expert-annotated visual data or more complex image processing techniques could further improve accuracy.
Trends in melt pool morphology relative to process parameters and final part properties emerge from large-scale feature extraction. In particular, tracks containing pores exhibit larger melt pools compared to pore-free regions, with average areas of 4386 µm−2 vs 1636 µm−2 respectively. Links between visual, thermal, positional data, and defects highlight the importance of multi-modal analysis for understanding process outcomes. The methodologies presented demonstrate progress toward key goals of defect prediction, informed process adjustments, and autonomous production.
The fusion of computer vision techniques with sensor streams holds potential for closing the loop with adaptive process control. By combining feature extraction with sensor-driven analytics across data modalities, the reliability and efficiency of metal additive techniques stand to rapidly advance.
Data Availability
Data sharing is not applicable to this article as no new data were created or analyzed in this study.
References
Chowdhury S, Yadaiah N, Prakash C, Ramakrishna S, Dixit S, Gupta LR, Buddhi D (2022) Laser powder bed fusion: a state-of-the-art review of the technology, materials, properties & defects, and numerical modelling. J Mater Res Technol 20:2109–2172. https://doi.org/10.1016/j.jmrt.2022.07.121
Seifi M, Salem A, Beuth J, Harrysson O, Lewandowski JJ (2016) Overview of materials qualification needs for metal additive manufacturing. JOM 68(3):747–764. https://doi.org/10.1007/s11837-015-1810-0
Ngo Tuan D, Alireza K, Imbalzano Gabriele TQ, Kate N, David H (2018) Additive manufacturing (3D printing): a review of materials, methods, applications and challenges. Compos Part B Eng 143:172–196. https://doi.org/10.1016/j.compositesb.2018.02.012
Duoss E, Zhu C, Sullivan K, Vericella J, Hopkins J, Zheng R, Pascall A, Weisgraber T, Deotte J, Frank J, Lee H, Kolesky D, Lewis J, Tortorelli D, Saintillan D, Fang N, Kuntz J, Spadaccini C (2014) Additive micro-manufacturing of designer materials: materials challenges and testing for manufacturing, mobility, biomedical applications and climate, pp. 13–24. Springer
Priarone PC, Lunetto V, Atzeni E, Salmi A (2018) Laser powder bed fusion (L-PBF) additive manufacturing: on the correlation between design choices and process sustainability. Procedia CIRP 78:85–90. https://doi.org/10.1016/j.procir.2018.09.058
Zhang Y, Safdar M, Xie J, Li J, Sage M, Zhao YF (2023) A systematic review on data of additive manufacturing for machine learning applications: the data quality, type, preprocessing, and management. J Intell Manuf. https://doi.org/10.1007/s10845-022-02017-9
Bilberg A, Malik AA (2019) Digital twin driven human–robot collaborative assembly. CIRP Ann 68(1):499–502. https://doi.org/10.1016/j.cirp.2019.04.011
Rosen R, von Wichert G, Lo G, Bettenhausen KD (2015) About the importance of autonomy and digital twins for the future of manufacturing. IFAC-PapersOnLine 48(3):567–572. https://doi.org/10.1016/j.ifacol.2015.06.141. 15th IFAC symposium on information control problems in manufacturing
Criales LE, Arisoy YM, Lane B, Moylan S, Donmez A, Özel T (2017) Laser powder bed fusion of nickel alloy 625: experimental investigations of effects of process parameters on melt pool size and shape with spatter analysis. Int J Mach Tools Manuf 121:22–36. https://doi.org/10.1016/j.ijmachtools.2017.03.004
Altıparmak SC, Xiao B (2021) A market assessment of additive manufacturing potential for the aerospace industry. J Manuf Process 68(728–738):11
Naghshineh B, Carvalho H (2022) The implications of additive manufacturing technology adoption for supply chain resilience: a systematic search and review. Int J Prod Econ 247:108387
Vafadar A, Guzzomi F, Rassau A, Hayward K (2021) Advances in metal additive manufacturing: A review of common processes, industrial applications, and current challenges. Appl Sci 11(3):1213. https://doi.org/10.3390/app11031213
Mani M, Lane BM, Donmez MA, Feng SC, Moylan SP, Fesperman R (2015) Measurement science needs for real-time control of additive manufacturing powder bed fusion processes. NIST
Murphy RD (2016) A review of in-situ temperature measurements for additive manufacturing technologies. Sandia National Laboratories
Zhao C, Parab ND, Li X, Fezzaa K, Tan W, Rollett AD, Sun T (2020) Critical instability at moving keyhole tip generates porosity in laser melting. Science 370(6520):1080–1086
Mostafaei A, Zhao C, He Y, Reza Ghiaasiaan S, Shi B, Shao S, Shamsaei N, Wu Z, Kouraytem N, Sun T, Pauza J, Gordon JV, Webler B, Parab ND, Asherloo M, Guo Q, Chen L, Rollett AD (2022) Defects and anomalies in powder bed fusion metal additive manufacturing. Current Opin Solid State Mater Sci 26(2):100974. https://doi.org/10.1016/j.cossms.2021.100974
Kolb T, Gebhardt P, Schmidt O, Tremel J, Schmidt M (2018) Melt pool monitoring for laser beam melting of metals: assistance for material qualification for the stainless steel 1.4057. Procedia CIRP 74:116–121. https://doi.org/10.1016/j.procir.2018.08.058
Cunningham R, Narra SP, Montgomery C, Beuth J, Rollett AD (2017) Synchrotron-based X-ray microtomography characterization of the effect of processing variables on porosity formation in laser power-bed additive manufacturing of Ti–6Al–4V. JOM 69(3):479–484. https://doi.org/10.1007/s11837-016-2234-1
Cunningham R, Zhao C, Parab N, Kantzos C, Pauza J, Fezzaa K, Sun T, Rollett AD (2019) Keyhole threshold and morphology in laser melting revealed by ultrahigh-speed X-ray imaging. Science 363(6429):849–852. https://doi.org/10.1126/science.aav4687
Scime L, Beuth J (2019) Using machine learning to identify in-situ melt pool signatures indicative of flaw formation in a laser powder bed fusion additive manufacturing process. Addit Manuf 25:151–165. https://doi.org/10.1016/j.addma.2018.11.010
Gaikwad A, Giera B, Guss GM, Forien J-B, Matthews MJ, Rao P (2020) Heterogeneous sensing and scientific machine learning for quality assurance in laser powder bed fusion—a single-track study. Addit Manuf 36:101659. https://doi.org/10.1016/j.addma.2020.101659
Tempelman JR, Wachtor AJ, Flynn EB, Depond PJ, Forien J-B, Guss GM, Calta NP, Matthews MJ (2022) Detection of keyhole pore formations in laser powder-bed fusion using acoustic process monitoring measurements. Addit Manuf 55:102735. https://doi.org/10.1016/j.addma.2022.102735
AbouelNour Y, Gupta N (2022) In-situ monitoring of sub-surface and internal defects in additive manufacturing: a review. Mater Design 222:111063. https://doi.org/10.1016/j.matdes.2022.111063
Yi L, Shokrani A, Bertolini R, Mutilba U, Guerra MG, Loukaides EG, Woizeschke P (2022) Optical sensor-based process monitoring in additive manufacturing. Procedia CIRP 115:107–112. https://doi.org/10.1016/j.procir.2022.10.058
Gong H, Gu H, Zeng K, Dilip JJS, Pal D, Stucker B (2014) Melt pool characterization for selective laser melting of Ti–6Al–4V pre-alloyed powder. University of Texas at Austin. https://doi.org/10.26153/tsw/15682 . https://repositories.lib.utexas.edu/handle/2152/88748 Accessed 07-14-2023
Mukherjee T, DebRoy T (2018) Mitigation of lack of fusion defects in powder bed fusion additive manufacturing. J Manuf Process 36:442–449. https://doi.org/10.1016/j.jmapro.2018.10.028
Huang SH, Liu P, Mokasdar A, Hou L (2013) Additive manufacturing and its societal impact: a literature review. Int J Adv Manuf Technol 67(5):1191–1203. https://doi.org/10.1007/s00170-012-4558-5
Wei HL, Mukherjee T, Zhang W, Zuback JS, Knapp GL, De A, DebRoy T (2021) Mechanistic models for additive manufacturing of metallic components. Prog Mater Sci 116:100703. https://doi.org/10.1016/j.pmatsci.2020.100703
Ur Rehman A, Mahmood MA, Ansari P, Pitir F, Salamci MU, Popescu AC, Mihailescu IN (2021) Spatter formation and splashing induced defects in laser-based powder bed fusion of alsi10mg alloy: a novel hydrodynamics modelling with empirical testing. Metals 11(12):2023. https://doi.org/10.3390/met11122023
Roy M, Wodo O (2020) Data-driven modeling of thermal history in additive manufacturing. Addit Manuf 32:101017
Gershenfeld N (2012) How to make almost anything the digital fabrication revolution. Foreign Aff 91(6):43–57
Majeed A, Lv J, Peng T (2018) A framework for big data driven process analysis and optimization for additive manufacturing. Rapid Prototyp J 25(2):308–321. https://doi.org/10.1108/RPJ-04-2017-0075
Majeed A, Zhang Y, Ren S, Lv J, Peng T, Waqar S, Yin E (2021) A big data-driven framework for sustainable and smart additive manufacturing. Robot Comput-Integr Manuf 67:102026. https://doi.org/10.1016/j.rcim.2020.102026
Schleder GR, Padilha ACM, Acosta CM, Costa M, Fazzio A (2019) From DFT to machine learning: recent approaches to materials science—a review. J Phys Mater 2(3):032001. https://doi.org/10.1088/2515-7639/ab084b
The NOMAD Laboratory: Claudia Draxl (2021) Stepping stones towards the fourth paradigm of materials science
Hey T, Tansley S, Tolle K (2009) The fourth paradigm: data-intensive scientific discovery. Microsoft Corporation, Redmond
Grasso M, Laguzza V, Semeraro Q, Colosimo BM (2017) In-process monitoring of selective laser melting: spatial detection of defects via image data analysis. J Manuf Sci Eng 139(5):051001. https://doi.org/10.1115/1.4034715
Khairallah SA, Anderson AT, Rubenchik A, King WE (2016) Laser powder-bed fusion additive manufacturing: physics of complex melt flow and formation mechanisms of pores, spatter, and denudation zones. Acta Mater 108:36–45. https://doi.org/10.1016/j.actamat.2016.02.014
Zhang Y, Hong GS, Ye D, Zhu K, Fuh JYH (2018) Extraction and evaluation of melt pool, plume and spatter information for powder-bed fusion AM process monitoring. Mater Design 156:458–469. https://doi.org/10.1016/j.matdes.2018.07.002
Fang Q, Tan Z, Li H, Shen S, Liu S, Song C, Zhou X, Yang Y, Wen S (2021) In-situ capture of melt pool signature in selective laser melting using u-net-based convolutional neural network. J Manuf Process 68:347–355. https://doi.org/10.1016/j.jmapro.2021.05.052
Thanki A, Goossens L, Ompusunggu AP, Bayat M, Bey-Temsamani A, Van Hooreweder B, Kruth J-P, Witvrouw A (2022) Melt pool feature analysis using a high-speed coaxial monitoring system for laser powder bed fusion of Ti–6Al–4V grade 23. Int J Adv Manuf Technol 120(9):6497–6514. https://doi.org/10.1007/s00170-022-09168-2
Lu M, Venkat SN, Augustino J, Meshnick D, Jimenez JC, Tripathi PK, Nihar A, Orme CA, French RH, Bruckman LS, Wu Y (2023) Image processing pipeline for fluoroelastomer crystallite detection in atomic force microscopy images. Integr Mater Manuf Innov. https://doi.org/10.1007/s40192-023-00320-8
Yue W, Tripathi PK, Ponon G, Ualikhankyzy Z, Brown DW, Clausen B, Strantza M, Pagan DC, Willard M, Ernst F, Ayday E, Chaudhary V, French RH (2024) Phase identification in synchrotron X-ray diffraction patterns of Ti–6Al–4V using computer vision and deep learning. Integr Mater Manuf Innov. https://doi.org/10.1007/s40192-023-00328-0
Proakis JG, Manolakis DG Digital signal processing: principles, algorithms, and applications, 3. ed edn. Prentice Hall international editions. Prentice-Hall International, London
Bracewell RN The fourier transform and its applications, 3rd ed edn. McGraw-Hill series in electrical and computer engineering. McGraw Hill, Boston
Dilip JJS, Zhang S, Teng C, Zeng K, Robinson C, Pal D, Stucker B (2017) Influence of processing parameters on the evolution of melt pool, porosity, and microstructures in Ti–6Al–4V alloy parts fabricated by selective laser melting. Prog Addit Manuf 2(3):157–167. https://doi.org/10.1007/s40964-017-0030-2
Calta NP, Wang J, Kiss AM, Martin AA, Depond PJ, Guss GM, Thampy V, Fong AY, Weker JN, Stone KH, Tassone CJ, Kramer MJ, Toney MF, Buuren AV, Matthews MJ (2018) An instrument for in situ time-resolved X-ray imaging and diffraction of laser powder bed fusion additive manufacturing processes. Rev Sci Instrum 89(5):055101. https://doi.org/10.1063/1.5017236
Khanzadeh M, Chowdhury S, Tschopp MA, Doude HR, Marufuzzaman M, Bian L (2019) In-situ monitoring of melt pool images for porosity prediction in directed energy deposition processes. IISE Trans 51(5):437–455. https://doi.org/10.1080/24725854.2017.1417656
Ronneberger O, Fischer P, Brox T (2015) U-Net: convolutional networks for biomedical image segmentation. Springer. https://doi.org/10.1007/978-3-319-24574-4_28
Forien J-B, Calta NP, DePond PJ, Guss GM, Roehling TT, Matthews MJ (2020) Detecting keyhole pore defects and monitoring process signatures during laser powder bed fusion: a correlation between in situ pyrometry and ex situ X-ray radiography. Addit Manuf 35:101336. https://doi.org/10.1016/j.addma.2020.101336
Schindelin J, Arganda-Carreras I, Frise E, Kaynig V, Longair M, Pietzsch T, Preibisch S, Rueden C, Saalfeld S, Schmid B, Tinevez J-Y, White DJ, Hartenstein V, Eliceiri K, Tomancak P, Cardona A 2012 Fiji: an open-source platform for biological-image analysis 9(7), 676–682. https://doi.org/10.1038/nmeth.2019
Petri I, Li H, Rezgui Y, Chunfeng Y, Yuce B, Jayan B (2016) A HPC based cloud model for real-time energy optimisation. Enterp Inf Syst 10(1):108–128. https://doi.org/10.1080/17517575.2014.919053
Hudak D, Johnson D, Chalker A, Nicklas J, Franz E, Dockendorf T, McMichael B (2018) Open OnDemand: a web-based client portal for HPC centers. J Open Source Softw 3(25):622
Nihar A, Ciardi T, Chawla R, Akanb OD, Chaudhary V, Wu Y, French RH (2023) Accelerating time to science using cradle: A framework for materials data science. In: 30th IEEE International Conference On High Performance Computing, Data, and Analytics. IEEE, Goa, India. https://doi.org/10.1109/HiPC58850.2023.00041
Roger H French: Energy CRADLE: the path forward for scalable analytics of energy systems. CWRU/Tohoku university data science symposium in life sciences and engineering
Kim DB, Witherell P, Lu Y, Feng S (2017) Toward a digital thread and data package for metals-additive manufacturing. Smart Sustain Manuf Syst 1(1):20160003. https://doi.org/10.1520/SSMS20160003
R Core Team: R: (2021) A language and environment for statistical computing. R Foundation for Statistical Computing, Vienna, Austria. R Foundation for Statistical Computing. https://www.R-project.org/
RStudio Team: RStudio: (2020) Integrated development environment for R. RStudio, PBC. Boston, RStudio, PBC. http://www.rstudio.com/
Wickham H, Averick M, Bryan J, Chang W, McGowan LD, François R, Grolemund G, Hayes A, Henry L, Hester J, Kuhn M, Pedersen TL, Miller E, Bache SM, Müller K, Ooms J, Robinson D, Seidel DP, Spinu V, Takahashi K, Vaughan D, Wilke C, Woo K, Yutani H (2019) Welcome to the tidyverse. J Open Source Softw 4(43):1686
Van Rossum G, Drake FL (2009) Python 3 reference manual. CreateSpace, Scotts Valley, CA. 1441412697
Tomar S (2006) Converting video formats with ffmpeg. Linux J 2006(146):10
Harris CR, Millman KJ, Walt SJ, Gommers R, Virtanen P, Cournapeau D, Wieser E, Taylor J, Berg S, Smith NJ, Kern R, Picus M, Hoyer S, Kerkwijk MH, Brett M, Haldane A, Río JF, Wiebe M, Peterson P, Gérard-Marchant P, Sheppard K, Reddy T, Weckesser W, Abbasi H, Gohlke C, Oliphant TE (2020) Array programming with NumPy. Nature 585(7825):357–362. https://doi.org/10.1038/s41586-020-2649-2
Walt S, Schönberger JL, Nunez-Iglesias J, Boulogne F, Warner JD, Yager N, Gouillart E, Yu T (2014) contributors: scikit-image: image processing in Python. PeerJ 2:453. https://doi.org/10.7717/peerj.453
McKinney W et al (2010) Data structures for statistical computing in python. In: Proceedings of the 9th Python in Science Conference, vol. 445, pp. 51–56. Austin, TX
Abadi M, Agarwal A, Barham P, Brevdo E, Chen Z, Citro C, Corrado GS, Davis A, Dean J, Devin M, Ghemawat S, Goodfellow I, Harp A, Irving G, Isard M, Jia Y, Jozefowicz R, Kaiser L, Kudlur M, Levenberg J, Mané D, Monga R, Moore S, Murray D, Olah C, Schuster M, Shlens J, Steiner B, Sutskever I, Talwar K, Tucker P, Vanhoucke V, Vasudevan V, Viégas F, Vinyals O, Warden P, Wattenberg M, Wicke M, Yu Y, Zheng X (2015) TensorFlow: large-scale machine learning on heterogeneous systems. Software available from tensorflow.org. https://www.tensorflow.org/
Yoo AB, Jette MA, Grondona M (2003) SLURM: simple linux utility for resource management. vol. 2862, pp. 44–60. Springer, Berlin, Heidelberg. https://doi.org/10.1007/10968987_3
Pascual JA, Navaridas J, Miguel-Alonso J. (2009) Effects of topology-aware allocation policies on scheduling performance. In: Frachtenberg E, Schwiegelshohn U (eds) pp. 138–156. Springer, Berlin, Heidelberg.https://doi.org/10.1007/978-3-642-04633-9_8
Kingma DP, Ba J (2017) Adam: a method for stochastic optimization (2017)
Shapiro LG, Stockman GC (2001) Computer Vision, pp. 186–205. Prentice Hall, Upper Saddle River
Sezgin M, Sankur B (2004) Survey over image thresholding techniques and quantitative performance evaluation. J Electron Imaging 13:146–168. https://doi.org/10.1117/1.1631315
Acknowledgements
The views expressed herein do not necessarily represent the views of the U. S. Department of Energy or the United States Government.
Funding
This material is based upon research conducted at the Materials Data Science for Stockpile Stewardship Center of Excellence (MDS3-COE), and supported by the Department of Energy’s National Nuclear Security Administration under Award Number(s) DE-NA0004104. The Advanced Light Source is supported by the Director, Office of Science, Office of Basic Energy Sciences, of the U.S. Department of Energy under Contract No. DE-ACO2-05 CH11231; special thanks for Harold Barnard and Dula Parkinson for beamtime support. This work was performed, in part, under the auspices of U.S, Department of Energy by Lawrence Livermore National Laboratory under Contract DE-AC52-07NA27344, LLNL-JRNL-854540. DOE-NNSA-LLNS Project: Materials Degradation and Lifetime Extension (MDLE): Contract number B647887.
Author information
Authors and Affiliations
Contributions
The authors confirm contribution to the paper as follows: JBF, BG, LSB, JCJ, RHF helped in study conception, design, data collection; KJH, TGC, RY done analysis and interpretation of results; PKT; draft manuscript preparation: KJH, LSB organizing meeting and drafting. All authors reviewed the results and approved the final version of the manuscript. This work made use of the High Performance Computing Resource in the Core Facility for Advanced Research Computing at Case Western Reserve University.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no known competing financial interests or personal relationships that could have appeared to influence the work reported in this paper.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Hernandez, K.J., Ciardi, T.G., Yamamoto, R. et al. L-PBF High-Throughput Data Pipeline Approach for Multi-modal Integration. Integr Mater Manuf Innov 13, 758–772 (2024). https://doi.org/10.1007/s40192-024-00368-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s40192-024-00368-0