
Abstract
In this study, using the M5 algorithm and multilayer perceptron neural network (MLPNN), the capability of stepped spillways regarding energy dissipation (ED) was approximated. For this purpose, relevant data was collected from valid sources. The study of the developed model based on the M5 algorithm showed that the Drop and Froude numbers play important roles in modeling and approximating the ED. The error indices of M5 algorithm in training were R2 = 0.99 and RMSE = 2.48 and in testing were R2 = 0.99 and RMSE = 2.23. The study of developed MLPNN revealed that this model has one hidden layer which includes five neurons. Among the tested transfer functions, the great efficiency was related to the Tansing function. The error indices of MLPNN in training were R2 = 0.97 and RMSE = 3.73 and in testing stages were R2 = 0.97 and RMSE = 3.98. Evaluation of the results of both applied methods shows that the accuracy of the MLPNN is a bit less than the M5 algorithm.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Spillways are structures that are extensively used to evacuate surplus flow over reservoir capacity of dams. One of the most important hydraulic problems of spillways is the high flow velocity, which causes cavitation and scouring at its downstream. Hence, dissipation of the energy of flow is the primary issue of spillways. In this way, using the baffles along the chute of the spillway, stepped spillway, ski jump buckets and stilling basin at the toe of spillways have been suggested (Heller et al. 2005; Movahedi et al. 2019; Xiao et al. 2015). Baffles usually are used in the small dam projects. The use of other mentioned structures is common in large dams projects (Erfanain-Azmoudeh and Kamanbedast 2013). An economic examination of three options including stilling basin, flip bucket and stepped spillway for designing the energy dissipater in large dams indicated that the use of stepped spillway is a logical decision (Christodoulou 1993). The advantage of stepped spillway in comparison with other energy dissipater structures is related to reduce or remove the probability of cavitation occurrence on the spillway (Frizell et al. 2013; Pfister and Hager 2011). The flow pattern over the stepped spillways was classified into three as napped, transition and skimming flows. The napped flow appears in the low discharge, and in the skimming flow, there is a virtual boundary between the jet stream and the steps. The transition regime is a status between the napped and skimming flow (Shahheydari et al. 2014). Although the energy lost in the nape regime is more than the skimming flow, but due economic reasons, the stepped spillways are designed under skimming flow condition. By advancing the computer technology, the investigators have tried to study the properties of flow over the spillway using the numerical methods (Parsaie et al. 2016a, 2018b). Numerical modeling is divided into two main groups as computational fluid dynamic (CFD) and soft computing. In the field of CFD, the governing equations which are usually Navier–Stokes equations are solved along the turbulence models such as K-epsilon and RNG . (Kim and Park 2005). Fortunately, nowadays, a number of user-friendly CFD packages have proposed to easily apply the CFD techniques along the physical modeling to reduce the cost of experiments (Salmasi and Samadi 2018). Along the physical and CFD modeling, another field of numerical modeling, i.e., soft computing techniques have been implemented for accurately present the results of experimental studies which are based on the defining the depended desired parameter with correspond to measuring the independent variables (Azamathulla et al. 2016; Maghsoodi et al. 2012; Najafzadeh et al. 2017; Najafzadeh and Zeinolabedini 2019; Sihag et al. 2019; Wu 2011). Among the soft computing models using the ANFIS by Salmasi and Özger (2014) and the GEP by Roushangar et al. (2014), MARS and GMDH methods by Parsaie et al. (2018a, c) have been reported to predict the energy dissipation over the stepped spillway. Reviewing the literature shows that the M5 algorithm for modeling the capabilities of stepped spillway has not been test; hence, in this a formula based on the M5 algorithm for modeling and predicting the performance of stepped spillways regarding energy dissipation is proposed.
Materials and methods
Energy dissipation involved parameters
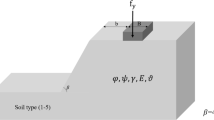
The scheme of stepped spillway is shown in Fig. 1. In this figure, the size of steps (height and length) is cleared via hs and Ls, respectively. Hw is the height of dam, y0 is the depth of flow over the crest, Lc is the length of crest, and y1 and y2 are the conjugated depths of hydraulic jump, respectively. The energy dissipation over the stepped spillway is estimated using the Bernoulli equation in the upstream and downstream of the spillway. As given in Eq. (1), the total upstream energy is cleared with \(H_{0}\) and downstream total energy as presented in Eq. (2) is calculated with \(H_{1}\).

The sketch of stepped spillway
The total head loss is evaluated using Eq. (3).
The involved geometrical and hydraulically parameters on the energy dissipation are collected in Eq. (4).
Using the Buckingham \(\Pi\) as dimensional analysis technique, the most important parameters on the energy dissipation are derived and given in Eq. (5).
With assuming the \({\text{DN}} = {{q^{2} } \mathord{\left/ {\vphantom {{q^{2} } {gH_{\text{w}}^{3} }}} \right. \kern-0pt} {gH_{\text{w}}^{3} }}\) and \(S = {{h_{\text{s}} } \mathord{\left/ {\vphantom {{h_{\text{s}} } {L_{\text{s}} }}} \right. \kern-0pt} {L_{\text{s}} }}\), Eq. (5) can be rewritten as Eq. (6).
As mentioned in the past, developing the soft computing techniques is based on the dataset. Therefore to prepare the M5 algorithm and MLPNN, the dataset published by Salmasi and Özger (2014) was used and their range are presented in Table 1.
M5 tree model
The M5 model at the first time which was proposed by the Quinlan (1992) is based on the classification tree method. The M5 model uses for the mapping the relation between the independent variables to the dependent variable and unlike the decision tree model in addition to qualities’ data uses for the quantitative data. The M5 model is similar to the piecewise linear functions method which is a combination of the linear regression and tree regression method. The M5 model is widely used in most area of the science. A linear or nonlinear regression proposes an equation for all the data which researchers attempt to mathematical modeling, whereas the M5 tree model tries to divide data into several categories which named leaf. Modeling the relationship between input and output data which categorized in each leaf by the linear regression is the main process which is conducted in the M5 tree method. This approach can be used for continuous data. The structure of the M5 tree model is similar to the natural tree which include the root, stem, leafs and nodes. Decision tree models are drawn from up to down. The root is considered as first node at the top of the graph, and during the model development the tree branches and leafs are drowned. Each of the nodes has been considered as independent variables. Constructing the M5 tree model included two stages, one developing the decision tree by data categorizing (the main criteria for data categorizing are increasing the covariance or reducing the standard deviation). Equation (4) is the criteria for the standard deviation in the each of the leafs (Kumar and Sihag 2019; Sihag et al. 2018, 2019).
where SDR is the standard deviation reduction, T the dataset inputs into the tree branches, and Ti the dataset in leafs. SD is the standard deviation. With the growth and development of M5 tree model, it is feared that the performance of the model leads to have so local behavior so usually in the second stage of the model development the pruning the tree is considered. To this purpose, the Quinlan algorithm is used. In this algorithm allowed to the tree to have enough growing then the branched which has not influence effect on the precision improvement is pruned. Figure 2 shows a schematic shape of the M5 tree model development. In Fig. 2a, the X1 and X2 are the input variables (independent parameters) and Y is the output data (dependent parameter), and Fig. 2b shows the tree model development for mapping the input and outputs data.

The sketch of the M5 tree model development (Etemad-Shahidi and Mahjoobi 2009)
Review on ANNs
The idea of ANN was given form human brain. Therefore, for the modeling of the knowledge behind the data recorded from the desired phenomenon to be transmitted by the neurons. The sketch network and a neuron are shown in Fig. 3. As shown in this figure, the collaboration of these neurons in parallel leads to the formation of a network, which may include one or more hidden layers. These types of networks are now introduced into the multilayered perceptron neural network (MLPNN). Investigating the structure of the neuron shows that the information is firstly multiplied in a coefficient and then are summarized, and finally, its result is introduced into a function that governs the behavior of the neuron. This function is named transfer or active function. So far, several types of transfer functions have been proposed for multilayer neural networks. A number of well-known transfer functions which are used for developing the MLP are present as below. The purpose of the calibration of a MLPNN is that both the coefficients multiplied in the input information and the coefficients used in the governing functions of the neurons (transfer function) are justified. This is performed via powerful methods such as Levenberg–Marquardt method (Sihag et al. 2019; Tiwari et al. 2019).

The structure of developed the MLPNN for predicting the EDR
-
1.
Gaussian: \(F(x) = a\exp \left( { - \frac{{\left( {x - b} \right)^{2} }}{{c^{2} }}} \right)\)
-
2.
Sigmoidal: \(F(x) = \frac{1}{1 + \exp ( - x)}\)
-
3.
Tansing: \(F(x) = \frac{2}{{\left( {1 + \exp ( - 2x)} \right)}} - 1\)
Results and discussion
Here, results of modeling and predicting the energy dissipation of flow over the stepped spillways using the M5 algorithm and MLPNN are presented. The first stage of modeling each phenomenon using soft computing techniques is data preparation. The purpose of data preparation is to divide them into two categories of training and testing. The training and testing dataset are utilized for development and validation of model, respectively. In this study, 80% of the data was used to train and the rest was assigned to test the models. The data shuffling method has been used to assign data to training and testing categories. In the phase of preparation and development models, the training data are used for calibration of the final model. For example, in developing phase the M5 algorithm for modeling and prediction of energy dissipation, firstly the space of inputs features based on the training data, are classified. Then, a linear function is fitted on the each class. The results of feature classification of training dataset of energy dissipation using M5 algorithm are given in Eq. (8). As presented in this equation, the first and most important parameter on which the first classification of training dataset is performed is the Drop number. The second important parameter is the Froude number. The examination of the above points shows that these two parameters (Drop and Froude numbers) are the most important parameters in estimating the amount of energy dissipation of flow passing over the stepped spillways. Of course, this also confirms the results obtained by previous studies. It is worth noting that the threshold criterion is considered for branching and classification of 0.05. As outlined in the materials and methods, the development of the M5 algorithm consists of two steps: the first stage involves the growth and development of the model, and the second stage involves pruning the additional branches produced in the first stage. The results of developed M5 algorithm in training and testing stages are shown in Fig. 4. As shown in this figure, the error indices of the M5 algorithm in training were RMSE = 2.48 and R2 = 0.99 and in testing stages were RMSE = 2.23 and R2 = 0.99.

The performance of applied models in training (a) and testing (b) stages

To examine the efficiency of the M5 algorithm, its performance was compared with MLPNN a common model of soft computing methods. The same dataset was used for training and testing of MLPNN. The MLPNN which was proposed by Haghiabi et al. (2018) was considered. They recommend that, in order to reduce the trial and error process in designing the structure of the MLPNN, first, a single-layer network, which contains a number of neurons equal to the number of input features, is considered. Then in next stage, the different type transfer functions can be tested to define the best of them. In this study, the structure of developed MLPNN model is shown in Fig. 3. As shown in this figure, the developed MLPNN has one hidden layer which includes five neurons. The best performance of transfer function is related to Tansing function. The performance of developed MLPNN in training and testing stages is shown in Fig. 4. The error indices of MLPNN in training were R2 = 0.97 and RMSE = 3.73 and in testing stages were R2 = 0.97 and RMSE = 3.98. Comparing the performance of M5 algorithm with MLPNN shows that the accuracy of M5 algorithm is a bit more than MLPNN. The performance of stepped spillways regarding energy dissipation has been predicted using group method of data handling (GMDH), genetic programming (GP), support vector machine (SVM) and multivariate adaptive regression splines (MARS) (Parsaie et al. 2016b, 2018a, c). According to the reports, the error indices of MARS technique in preparation stages were R2 = 0.99 and RMSE = 0.65. The error indices of GMDH in development stages (training and testing stages) were R2 = 0.95 and RMSE = 5.4. The performance of SVM and GP in training and testing was R2 = 0.98, RMSE = 2.61 and R2 = 0.96, RMSE = 4.94, respectively. Comparing the performance of developed M5 algorithm with previous applied models shows that the accuracy of M5 algorithm is a bit more than the GP and GMDH, and is a bit less than the MARS and SVM.
Conclusion
Stepped spillways are hydraulic structures that are commonly used in water engineering and watershed projects. These structures have been very much considered due to the economics, easy in construction and proper operation of energy dissipation and elimination of probability of cavitation. In watershed projects, this type of spillways can also be constructed from local materials such as loose rock dams. In this paper, new formula based on the M5 algorithm was proposed for estimating the performance of stepped spillways regarding energy dissipation. To compare the performance of M5 algorithm with other type of soft computing methods, the MLPNN was chosen. Results of M5 algorithm showed that there is good agreement between observed data and M5 algorithm outputs. Reviewing the structure of formula derived from the M5 algorithm declared that the Drop and Froude numbers are the main parameters used for feature classification in M5 algorithm. Results of MLPNN model showed that this model also has good performance in predicting the performance of stepped spillways regarding energy dissipation of flow. However, the accuracy of M5 algorithm is a bit more than the MLPNN. The best performance of tested transfer function during the development of the MLPNN model is related to Tansing function.
Abbreviations
- ANFIS:
-
Adaptive neuro-fuzzy inference system
- CFD:
-
Computational fluid dynamic
- DN:
-
Drop number
- ED:
-
Energy dissipation
- Fr :
-
Froude number
- g :
-
Gravity acceleration
- GEP:
-
Genetic expression programming
- GMDH:
-
Group method of data handling
- H :
-
Total head of flow
- h s :
-
Height of steps
- L c :
-
Length of crest
- L s :
-
Length of steps
- MARS:
-
Multivariate adaptive regression splines
- Max:
-
Maximum
- Min:
-
Minimum
- MLPNN:
-
Multilayer perceptron neural network
- N :
-
Number of steps
- q :
-
Discharge per width
- y 0 :
-
Flow depth over the crest
- y 1 and y 2 :
-
Conjugated depths of hydraulic jump
References
Azamathulla HM, Haghiabi AH, Parsaie A (2016) Prediction of side weir discharge coefficient by support vector machine technique. Water Sci Technol Water Supply 16(4):1002–1016
Christodoulou GC (1993) Energy dissipation on stepped spillways. J Hydraul Eng 119(5):644–650
Erfanain-Azmoudeh M-H, Kamanbedast AA (2013) Determine the appropriate location of aerator system on Gotvandoliadam’s spillway using flow 3D. Am Eur J Agric Environ Sci 13(3):378–383
Etemad-Shahidi A, Mahjoobi J (2009) Comparison between M5′ model tree and neural networks for prediction of significant wave height in Lake Superior. Ocean Eng 36(15):1175–1181. https://doi.org/10.1016/j.oceaneng.2009.08.008
Frizell KW, Renna FM, Matos J (2013) Cavitation potential of flow on stepped spillways. J Hydraul Eng 139(6):630–636
Haghiabi AH, Parsaie A, Ememgholizadeh S (2018) Prediction of discharge coefficient of triangular labyrinth weirs using adaptive neuro fuzzy inference system. Alex Eng J 57(3):1773–1782. https://doi.org/10.1016/j.aej.2017.05.005
Heller V, Hager WH, Minor H-E (2005) Ski jump hydraulics. J Hydraul Eng 131(5):347–355
Kim D, Park J (2005) Analysis of flow structure over ogee-spillway in consideration of scale and roughness effects by using CFD model. KSCE J Civ Eng 9(2):161–169
Kumar M, Sihag P (2019) Assessment of infiltration rate of soil using empirical and machine learning-based models. Irrig Drain. https://doi.org/10.1002/ird.2332
Maghsoodi R, Roozgar MS, Sarkardeh H, Azamathulla HM (2012) 3D-simulation of flow over submerged weirs. Int J Model Simul 32(4):237
Movahedi A, Kavianpour M, Aminoroayaie Yamini O (2019) Experimental and numerical analysis of the scour profile downstream of flip bucket with change in bed material size. ISH J Hydraul Eng 25(2):188–202
Najafzadeh M, Zeinolabedini M (2019) Prognostication of waste water treatment plant performance using efficient soft computing models: an environmental evaluation. Measurement 138:690–701
Najafzadeh M, Tafarojnoruz A, Lim SY (2017) Prediction of local scour depth downstream of sluice gates using data-driven models. ISH J Hydraul Eng 23(2):195–202
Parsaie A, Dehdar-Behbahani S, Haghiabi AH (2016a) Numerical modeling of cavitation on spillway’s flip bucket. Front Struct Civ Eng 10(4):438–444
Parsaie A, Haghiabi AH, Saneie M, Torabi H (2016b) Prediction of energy dissipation on the stepped spillway using the multivariate adaptive regression splines. ISH J Hydraul Eng 22(3):281–292
Parsaie A, Haghiabi AH, Saneie M, Torabi H (2018a) Prediction of energy dissipation of flow over stepped spillways using data-driven models. Iran J Sci Technol Trans Civ Eng 42(1):39–53
Parsaie A, Moradinejad A, Haghiabi AH (2018b) Numerical modeling of flow pattern in spillway approach channel. Jordan J Civ Eng 12(1):1–9
Parsaie A, Haghiabi AH, Saneie M, Torabi H (2018c) Applications of soft computing techniques for prediction of energy dissipation on stepped spillways. Neural Comput Appl 29(12):1393–1409
Pfister M, Hager WH (2011) Self-entrainment of air on stepped spillways. Int J Multiphase Flow 37(2):99–107
Quinlan JR (1992) Learning with continuous classes. In: Proceedings of the 5th Australian joint conference on artificial intelligence. World Scientific, pp 343–348
Roushangar K, Akhgar S, Salmasi F, Shiri J (2014) Modeling energy dissipation over stepped spillways using machine learning approaches. J Hydrol 508:254–265
Salmasi F, Özger M (2014) Neuro-fuzzy approach for estimating energy dissipation in skimming flow over stepped spillways. Arab J Sci Eng 39(8):6099–6108
Salmasi F, Samadi A (2018) Experimental and numerical simulation of flow over stepped spillways. Appl Water Sci 8(8):229
Shahheydari H, Nodoshan EJ, Barati R, Moghadam MA (2014) Discharge coefficient and energy dissipation over stepped spillway under skimming flow regime. KSCE J Civ Eng 19(4):1174–1182
Sihag P, Tiwari NK, Ranjan S (2018) Prediction of cumulative infiltration of sandy soil using random forest approach. J Appl Water Eng Res 7:1–25
Sihag P, Mohsenzadeh Karimi S, Angelaki A (2019) Random forest, M5P and regression analysis to estimate the field unsaturated hydraulic conductivity. Appl Water Sci 9(5):129. https://doi.org/10.1007/s13201-019-1007-8
Tiwari NK, Sihag P, Singh BK, Ranjan S, Singh KK (2019) Estimation of tunnel desilter sediment removal efficiency by ANFIS. Iran J Sci Technol Trans Civ Eng. https://doi.org/10.1007/s40996-019-00261-3
Wu F (2011) Support vector machine approach to for longitudinal dispersion coefficients in streams. Appl Soft Comput 11(2):2902–2905
Xiao Y, Wang Z, Zeng J, Zheng J, Lin J, Zhang L (2015) Prototype and numerical studies of interference characteristics of two ski-jump jets from opening spillway gates. Eng Comput 32(2):289–307
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
This article is part of the Topical Collection “Water and Energy” guest edited by Enrico Drioli.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Parsaie, A., Haghiabi, A.H. Evaluation of energy dissipation on stepped spillway using evolutionary computing. Appl Water Sci 9, 144 (2019). https://doi.org/10.1007/s13201-019-1019-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s13201-019-1019-4