
Abstract
This study aims to model monthly electrical conductivity (EC) values in the Asi River using artificial neural networks (ANNs) to evaluate water quality conditions using pH, temperature, water discharge, sodium, sum of calcium and magnesium concentrations. The results are compared using multiple linear regression (MLR). Recorded data are available at a gauging site in Antakya, Turkey, for the period from 1984 to 2008. Comparing the modeled values by ANNs with the experimental data indicates that neural network model with seven neurons in hidden layer provides accurate results (R 2 = 0.968, RMSE = 46.927 µS/cm, MAE = 32.462 µS/cm and MRSE = 0.0029 for the training data and R 2 = 0.965, RMSE = 50.810 µS/cm, MAE = 37.495 µS/cm and MRSE = 0.0024 for the testing data). The Garson method of the connection weights of the network was used to study the relative % contribution of each of the input variables. It was found that the sum of calcium and magnesium concentration and temperature had the most effect on the predicted EC. The results indicate that two proposed models were able to approximate the EC parameter reasonably well; however, the ANN was found to perform better than the MLR model.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
Water quality is an explanation of chemical, physical, and biological characteristics of water in relation with intended use(s) and a set of standards (Gazzaz et al. 2012). Water quality can be evaluated by a single parameter such as electrical conductivity (EC) or by a number of critical parameters (e.g., temperature, pH, EC, turbidity; pathogens, nutrients, organics, and metals) for certain objective. The EC is a measurable quantity but their direct measurements are expensive, time-consuming and expensive. Artificial neural networks (ANNs) have been applied widely to time series analyses, including local water quality parameters and EC values, in which the model is developed even in the presence of correlation among the variables. ANN is nonlinear, non-parametric model and does not need necessarily higher physical meaning background of the subject. The initial model derived from data is a neural network model that can be built and handled quite easily and quickly. A disadvantage of ANNs is that they are black box models unable to provide any insight into the key relationships. Since statistical regression is the simplest and most straightforward form of a model, it is usually the first approach that is adopted for investigating a relationship between variables. Therefore, MLR was investigated as possible alternative, and its prediction abilities were compared with ANN models. Predictions by the MLR are simply based on linear and additive associations of the explanatory variables, and these models are not able to incorporate the nonlinearities of the parameters. Finally, the importance of each of the input parameters is estimated by a technique given by Garson (1991), which employs the weights between the artificial neurons produced by the ANN model. Several studies reported the use of ANN in water quality prediction (Liong et al. 1999; Diamantopoulou et al. 2005; Sahoo et al. 2005; Recknagel et al. 2007; El-Shafie et al. 2008; Amiri and Nakane 2009; Bertini et al. 2010; Maier et al. 2010; Sivapragasam et al. 2010; Pai et al. 2011; Ghorbani et al. 2012; Najad et al. 2013; Nemati et al. 2015).
The main purpose of this study is to investigate the applicability ANN methods to estimate the EC, and the results are compared with MLR. From 11 input candidates, pH, temperature, water discharge, sodium, and sum of calcium and magnesium concentrations, for a set of recorded data from 1984 to 2008 in the Asi River (also referred to as Orontes River), were used as input parameters to predict EC. Among water quality parameters, EC concentration is very important in classifying irrigation water (Singh et al. 2005). The paper also estimates the relative importance of these input variables.
Materials and methods
Multiple linear regression (MLR)
Multiple linear regression (MLR) is a conventional approach in the modeling of the relationship between variables in which the unknown parameters of the regression model are estimated. MLR fits a linear combination of the components of a multiple signal x to a single output signal y, as defined by (1) and returns the residual, r, i.e., the difference signal, as defined by (2):
where the values of parameters a i are unknown a priori and, in this study, they are determined using the least squares method to minimize the residual errors, r.
Artificial neural networks (ANNs)
Artificial neural network is a nonlinear black box model and is a powerful tool for nonlinear problems. The feed-forward neural network (FFNN) is the widely used neural network architecture in literature and comprises a system of neurons, which are arranged in layers. Between the input and output layers, there may be one or more hidden layers. The number of neurons in the input and output layers is equal to the number of input and output variables, but the number of hidden layers and neurons in hidden layer are determined by trial-and-error method. Each neuron in a layer receives weighted inputs from a previous layer and transmits its output to neurons in the next layer. These are summed to produce a net value, which is then transformed to an output value upon the application of an activation function. Figure 1 represents a three layers structure (MLP) that consists of (i) input layer, (ii) hidden layer and (iii) output layer. For more information, see (Nemati et al. 2015).

Simple configuration of multilayer perceptron neural network (Nemati et al. 2015)
Relative importance index
Relative importance values and the saliency analysis are two of the approaches to open up the black box of the weights associated with the ANN models to gain some insight into the physical conditions of the site. This paper uses the relative importance method of the input variables, as given by the Garson equation (1991). It is based on the neural net weight matrix. Garson proposed following equation based on the partitioning of connection weights:
where I j is the relative importance of the jth input variable on the output variable, N i and N h are the number of input and hidden neurons, respectively, and W is the connection weight, the superscripts i, h and o refer to input, hidden and output layers, respectively, and subscripts k, m and n to input, hidden and output neurons, respectively. For more details, see (Ghorbani et al. 2012). The disadvantage of this method is that the network is not retrained after the removal of each input. This can lead to erroneous results if zero is not a reasonable value for the input. The result can be particulary questionable if the inputs are statistically dependent, because in general, the effects of different inputs cannot be separated (Chen et al. 2009).
Model performance evaluation
Four performance criteria are used in this study to assess the goodness of fit of the models, which are: root mean square error (RMSE), mean absolute error (MAE), mean square relative error (MSRE), and coefficient of determination (R 2) (further discussed by Ghorbani et al. 2012).
Study area and data specification
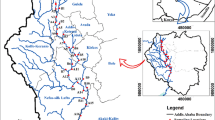
The investigation on EC in this paper is based on water quality parameters of one gauging station in Asi River. This river is international river; for this purpose, it has been divided into three basin districts, which originate in Lebanon in the Hermel Hills, cross Syria and end in Turkey. The location of this river is illustrated in Fig. 2.

Location of the Asi River
The Asi River Basin, which was used to develop the model, is in southern Turkey in Antakya. Every month, samples were collected from one location, from the steel bridge station in Asi River, Turkey, for analysis which was located between latitude, 36°15′05′′ North, longitude, 36°21′12′′ East, and elevation 67 m.
From 11 input candidates, the most important and selected input variables were pH, temperature, water discharge, sodium, and sum of calcium and magnesium. The models were then used to predict EC. Concentrations of these parameters have been measured in 270 streams of Asi River at the steel bridge station in Antakya, Turkey, and on a monthly basis for the period of 24 years, from 1984 to 2008. The mean variations of EC and the other parameters of the gauging site used in this study are monthly intervals are shown in Fig. 3a–f, which also displays the missing data. The data are divided into two sets: (i) 80 % of data (216 months) for training the models; (ii) 20 % of data (54 months) for testing the models.

Measured monthly time series of the water quality parameters at the Asi River: a temperature (temp, °C), b pH, c water discharge (Q, m3/s), d sodium (Na, mg/L), e calcium and magnesium (Ca + Mg, mg/L), f electrical conductivity (EC, μS/cm)
The statistical parameters of the water quality data are given in Table 1. The mean, minimum, maximum, standard deviation (Std Dev), variance (Var), skewness (Skew) and kurtosis can describe variability of the data. As described in Table 1, water temperature is one of the water quality variables that have a low skewness coefficient. Water discharge has a large skewness coefficient; the minimum and maximum values of the EC have large differences. Probably, the mean of the EC data set is heavily influenced by the presence of a few extreme values.
The data subsets were normalized so that the data rage fell between −1 and 1. Such scaling of data smooths the solution space and averages out some of the noise (ASCE 2000). Since results from these normalized models indicated that performance of the models did not change very much, the results here are represented without normalized data. The available records of monthly water quality parameters of Asi River at the steel bridge station suffer additionally from missing data. Some of appropriate strategies to treat the missing data are used (Honaker and King 2010).
Results
A typical feed-forward neural network of multilayer perceptrons model has been constructed for predicting the monthly EC time series. Table 2 shows the best values of the calibrating parameters for the ANNs. These parameters were fixed for all runs.
Relative importance
In this study, to determine the relative importance of temperature (Temp), pH, water discharge (Q), sodium (Na), and calcium and magnesium (Ca + Mg) concentration on EC, the Garson equation (6) was used. The ANN model architecture refers to the layout of neurons and the number of hidden layers, as shown in Fig. 1. Table 3 shows the results of ANN model for the training and testing periods.
In the testing phase, the model with 13 neurons for the hidden layer rendered comparatively better values of RMSE, MAE, MSRE, and R 2 (60.825 µS/cm, 45.639 µS/cm, 0.0033, and 0.952, respectively). Table 4 shows the matrices of weights between input, hidden and output layers.
Table 5 shows relative importance of the input variables on EC, and indicates that (Ca + Mg), Q and pH play the most significant role on the EC model (with relative importance of 24.46, 21.97, and 19.67 %, respectively), whereas Na and temperature have less influential role (with relative importance of 18.10 and 15.84 %, respectively).
Input combinations
The relative importance of the input variables were used to determine appropriate input combinations. Different combinations of variables (Temp, pH, Q, Na, Ca + Mg) as input data, and EC as output of models were presented in Table 6.
MLR model
The standard form of the MLR model based on Eq. (1) is used for predicting EC, which included only the first order of the independent variables pH, Temp, Q, Na, and Ca + Mg. Table 7 presents the performance of the MLR model, and Fig. 4 illustrates the visual comparison between the observed and predicted values of EC for a typical data range of 270 data points. Comparison of the results in the training and testing steps indicated that combination 8 is the best of EC prediction for MLR model.

Comparison of predicted MLR time series with observed values for EC: a sequence plot, b scatter plot for the training dataset, c scatter plot for the testing dataset
ANN model
In the preliminary investigations, the architecture of the ANN model was identified by trial-and-error procedure. A three-layer network was selected, and the number of neurons in the hidden layer was determined by training and testing four models: M1, M2, M3, and M4. The study tested the following recommendations: model M1 with I neurons as recommended by Tang and Fishwick (1993), model M2 with 2I as recommended by Wong (1992), and model M3 with 2I + 1 as recommended by Lippmann (1987), where I is the number of input variables, and model M4 with 13 neurons. The ANN was compared based upon their prediction accuracy to identify the most appropriate and efficient combinations of inputs. The results showed that the network geometry with seven hidden neurons is required for a relatively better performance. This is shown in Fig. 5.

Implementation of the ANN model
Table 8 shows the assessment of performance of the ANN model for the training and testing steps with different combinations of input parameters and structure. Among the models assessed, combination 1 with seven hidden neurons resulted in relatively better statistical measures. The visual comparison of predicted and observed EC values indicates that the ANN was able to properly model the variation of the EC parameter. However, some of the extreme values of EC have been underestimated or overestimated by the ANN model showing its relative weakness in the estimation of EC values (Fig. 6).

Comparison of predicted ANN time series with observed values for EC: a sequence plot, b scatter plot for the training dataset, c scatter plot for the testing dataset
Based on the visual comparison, no substantial difference appears to be observed among the predictive abilities of the proposed models, and the predicted results for EC are just as good as those by MLR as shown in Fig. 4. The overall performance of the MLR and ANN techniques are presented in Table 9. It is clearly that the ANN model performed better than the MLR model.
Discussion
Prediction models are considered useful for river basin management and are used to predict the behavior of water quality with respect to changes in hydrological conditions. Neural networks have gained great popularity in time series prediction because of their robustness and simplicity with respect to underlying data distributions.
Asi River during its course receives varying levels of pollution from many diffuse (non-point) and point sources. This river is intensively used for agriculture owing to the existence of very fertile soil around the river, contributing significantly to the regional economy, so it is degraded by diffuse sources. In addition, nearly 200 industrial plants and hundreds of small factories are located around or nearby the river and discharge their effluents into the river at a rate of 500,000 m3/year (Karakilcik and Erkul 2002), thus exhibiting large variations in water quality variables. On the other hand, measuring pH in the Asi River Basin for the past 24 years has shown that conditions of this river have also changed.
Water quality data for this analysis were limited to concentrations of sodium, potassium, calcium, magnesium, carbonate, chlorate, sulfate, bicarbonate as well as temperature, pH, and water discharge. Since, one of the most important steps in the development process of a model is the determination of an appropriate set of inputs, but on the other hand, inclusion of more inputs to the system increases system complexity, the input variables were selected and generated from the system description through literature experience.
In this study, the ANN modeling technique was used to predict future conditions in this river using pH, temperature, water discharge, sodium, sum of calcium and magnesium concentrations. The study also includes an estimation of the relative importance of these variables to identify important variables affecting the EC parameter. MLR is investigated as possible alternative and its prediction abilities were compared with ANNs.
Comparison between the models indicated that the interaction input with delay time is no more responsible for EC estimation than the individual variables, so increasing the amount of memory was not found to be a significant explanatory variable. The modeling results also indicated that similar performances were obtained with MLR and ANNs in the testing step, but better performance indices were achieved with ANN models in both steps, suggesting that it could be successfully applied for EC predicting. Despite the accuracy of MLR models being slightly lower than the ANN model, the MLR was superior to other artificial intelligence models in giving a simple equation for the phenomenon which shows the relationship between the input and output parameters. The ANN model can generate output values in continuous form, which makes water quality assessment more comprehensible, so this model was selected as the best fitting.
For the modeling and analysis of EC, only monthly data were available and used in this study, which might not be sufficient for accurate modeling and model assessment, for monthly data may not include all extreme conditions.
Conclusion
The general objective of this study is to predict monthly EC time series using local water quality parameters of pH, temperature, water discharge, sodium, and sum of calcium and magnesium. The recorded data at one station located in Asi River, at a gauging site in Antakya, Turkey, are used to investigate the performance of two modeling strategies: ANNs, and MLR for the estimation of the EC amounts. This study also employs the Garson equation to assess the relative importance of these input variables. The modeling study employed different input combinations, and model performances have been estimated by means of several indicators. The results indicated that reasonable prediction accuracy was achieved for these models.
References
Amiri BJ, Nakane K (2009) Comparative prediction of stream water total nitrogen from land cover using artificial neural network and multiple linear regression approaches. Polish J Environ Stud 18(2):151–160
ASCE Task Committee on Application of Artificial Neural Networks in Hydrology (2000) Artificial neural networks in hydrology, I: preliminary concepts. J Hydrol Eng 5(2):115–123
Bertini I, Ceravolo F, Citterio M, Felice MD, Pietra BD, Margiotta F, Pizzuti S, Puglisi G (2010) Ambient temperature modeling with soft computing techniques. Sol Energy 84(7):1264–1272
Chen T, Zhang Ch, Chen X, Li L (2009) An input variable selection method for the artificial neural network of shear stiffness of worsted fabrics. Statistical analysis and data mining. ASA Data Sci J 1(5):287–295
Diamantopoulou MJ, Papamichail DM, Antonopoulos VZ (2005) The use of a neural network technique for the prediction of water quality parameters. Oper Res 5(1):115–125
El-Shafie A, Noureldim AE, Taha MR, Basri H (2008) Neural network model for Nile River inflow forecasting analysis of historical inflow data. J Appl Sci 8(24):4487–4499
Garson GD (1991) Interpreting neural-network connection weights. Artif Intell Expert 6:47–51
Gazzaz NM, Yusoff MK, Aris AZ, Juahir H, Ramli MF (2012) Artificial neural network modeling of the water quality index for Kinta River (Malaysia) using water quality variables as predictors. Mar Pollut Bull 64(11):2409–2420
Ghorbani MA, Khatibi R, Hosseini B, Bilgili M (2012) Relative importance of parameters affecting wind speed prediction using artificial neural networks. Theor Appl Climatol 110(4). doi:10.1007/s00704-012-0821-9
Honaker J, King G (2010) What to do about missing values in time series cross-section data. Am J Polit Sci 54(3):561–581
Karakilcik Y, Erkul H (2002) Management of Asi River. Detay, Turkey, p 356
Liong SY, Lim WH, Paudyal G (1999) Real time river stage forecasting for flood Bangladesh: neural network approach. J Comput Civil Eng 14(1):1–18
Lippmann RP (1987) An introduction to computing with neural nets. ASSP Mag IEEE 4(2):4–22
Maier HR, Jain A, Dandy GC, Sudheer KP (2010) Methods used for the development of neural networks for the prediction of water resource variables in river systems: current status and future directions. Environ Model Softw 25(8):891–909
Najad A, El-Shafie A, Karim OA, El-Shafie AH (2013) Application of artificial neural networks for water quality prediction. Neural Comput Appl 22(1):187–201
Nemati S, Fazelifard MH, Terzi O, Ghorbani MA (2015) Estimation of dissolved oxygen using data-driven techniquesin the Tai Po River. Environ Earth Sci, Hong Kong. doi:10.1007/s12665-015-4450-3
Pai TY, Yang PY, Wang SC, Lo MH, Chiang CF, Kuo JL, Chu HH, Su HC, Yu LF, Hu HC, Chang YH (2011) Predicting effluent from the wastewater treatment plant of industrial park based on fuzzy network and influent quality. Appl Math Model 35(8):3674–3684
Recknagel F, Chan WS, Cao H, Park HD (2007) Elucidation and short-term forecasting of microcystin concentrations in Lake Suwa (Japan) by means of artificial neural networks and evolutionary algorithms. Water Res 41(10):2247–2255
Sahoo GB, Ray C, Wang JZ, Hubbs SA, Song RG, Jasperse J, Seymour D (2005) Use of artificial neural networks to evaluate the effectiveness of riverbank filtration. Water Res 39(12):2505–2516
Singh AK, Mondal GC, Sing PK, Singh S, Singh TB, Tewary BK (2005) Hydrochemistry of reservoirs of Damodar river basin, India: weathering processes and water quality assessment. J Environ Geol 48:1014–1028
Sivapragasam C, Jegatheesan V, Arun VM, Vanitha S (2010) Spatial modeling of electrical conductivity with neural network. Int J Eng Sci Technol 2(7):3128–3136
Tang Z, Fishwick PA (1993) Feedforward neural nets as models for time series forecasting. ORSA J Comput 5(4):374–385
Wong FS (1992) Time series forecasting using back propagation neural network. Neurocomputing 2(4):147–159
Acknowledgments
The authors would like to acknowledge and thank Prof. Ozgur Kisi, from Keyseri University, Turkey, for providing the data used in this study. The authors would also like to express their gratitude to Dr. Michael S. Smith for his generous helps in editing this paper.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Ghorbani, M.A., Aalami, M.T. & Naghipour, L. Use of artificial neural networks for electrical conductivity modeling in Asi River. Appl Water Sci 7, 1761–1772 (2017). https://doi.org/10.1007/s13201-015-0349-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s13201-015-0349-0