
Abstract
Social networks are the rich sources to people for sharing the knowledge on health-related issues. Nowadays, Twitter is one of the great significant social platforms to the people for a discussion on topics. Analyzing the clusters for the tweets concerning terms is a complex process due to the sparsity problem. Topic models are useful or avoiding this problem with derivations of topic clusters. Finding pre-cluster tendency is the major problem in many clustering methods. Existing methods, such as visual access tendency (VAT), cosine-based VAT (cVAT), multi viewpoints-based cosine similarity VAT (MVS-VAT) majorly used to access the prior information about clusters tendency problem. Solution of cluster tendency indicates the tractable number of clusters. The MVS-VAT enables the cluster tendency for the tweet documents effectively than other visual methods. However, it takes a higher number of viewpoints, thus requiring more computational time for the clustering of tweets data. Therefore, sampling-based visual methods are proposed to overcome the computational problem. Several standard health keywords are used for the extraction of health tweets to illustrate the effectiveness of proposed work in the experimental study.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Essential techniques of data clustering problem widely used for organizing the data into meaningful partitions based on similarity features of data objects. Relevant tweet data clustering problem is applied among the tweets (or data objects), in which the labels of tweets are initially unknown. Well-known topic clustering techniques (Xu and Wunsch 2005); (Yi et al. 2020); (Jose and Babu 2019) describes the modelling of tweets and generation of tweets features in the form of bag-of-words concerning topics rather than terms (Pessiot et al. 2010). Similarity features among the tweets are measured using distance measures, like Euclidean and cosine (Shirkhorshidi et al. 2015). The VAT (Bezdek and Hathaway 2002) and cVAT (Prasad et al. 2019b, a) use the Euclidean and cosine measures while evaluating the clustering tendency of tweets data. Cosine accurately measures the similarity features for the text documents (Oghbaie and Zanjireh 2018) than Euclidean. Thus, for the assessment of clusters, cVAT performs better than VAT. In cVAT, cosine similarity is computed among the tweets with a single viewpoint. MVS-VAT (Prasad et al. 2019b, a) is a pre-cluster assessment technique, which computes the cosine similarity among the tweets using multi viewpoints.
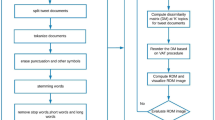
It is a more potential technique in the assessment of clusters than VAT and cVAT (Therese and Lingam 2017). The MVS-VAT computes the similarity features among two tweet documents for the set of N tweet documents is the average similarity concerning (N-2) viewpoints. Thus, it is computationally expensive than other visual methods, for reducing the computational requirements, the sampling technique proposed for the selection of a few viewpoints rather than the selection of (N-2) viewpoints. The sample viewpoints are selected from inter clusters of data objects, i.e., cosine similarity between two tweets (t1,t2) is measured with respect to sample viewpoints, and the selection of viewpoints do not belong to clusters of either t1 or t2, and it should be other than these clusters. This selection depends on the inter-cluster viewpoints of data objects; therefore, it is known as sampling inter-cluster viewpoints (SICV). Its extensive sampling MVS-VAT is known as SICV-MVS-VAT. The processing steps of proposed SICV-MVS-VAT are illustrated in Fig. 1. After pre-processing the tweets documents, cosine similarity features for every pair of tweets document are computed with the selection of sample viewpoints.

Processing Steps of Proposed SICV-MVS-VAT
Highlights of the contributions are described in following:
-
1.
Develop the sampling technique for the selection of inter-cluster viewpoints of data objects
-
2.
Estimate the clustering tendency for the tweet’s dataset with the selection of sample viewpoints
-
3.
Effective visualization for cluster images of tweets documents
-
4.
Develop the SICV-MVS-VAT for the best visual assessment of cluster of the social data (or tweets)
-
5.
Derive the crisp parts of the visual cluster for finding the cluster labels of tweets objectsin order to find the generation of social data clusters
Other sections of the paper are described as follows: Sect. 2 presents the related visual methods Sect. 3 describes the proposed sampling multi-viewpoint-based visual method, Sect. 4 discusses the experimental study and performance discussion, and Sect. 5 presents the conclusion and scope.
2 Related visual methods
For the tweet data clustering (Sechelea et al. 2016); (Rehioui and Idrissi 2019), topic models (Amelio and Pizzuti 2015; Xu et al. 2019; Hu et al. 2012; Ismail et al. 2018) are required for modelling the tweets with respect to topics instead of terms for avoiding the problem of data sparsity. Topic models, i.e. non-matrix factorization (NMF) (Lee and Seung 2001), Latent Dirichlet Allocation (LDA) (Blei et al. 2003), Latent Semantic Indexing (LSI) (Deerwester et al. 1990), and Probabilistic Latent Sematic Indexing (PLSI) (Hofmann 1999) are widely used for the modelling and extraction of tweets features in bag-of-words (Wallach 2006) format. Each tweet document features are considered as a single data object. The data objects i.e. tweet feature are used for the clustering tweet documents. Clustering of text documents (or tweets documents) is performed through TF-IDF analysis (Neogi et al. 2020). However, such analysis is suffered with data sparsity problem. Topic models are well suited for performing of text clustering based on topics derivations instead of deriving the TF-IDF. It less sensitive to data sparsity problem when compared to TF-IDF based clustering approaches. Topic models are recommended for big text data clustering problems (Sukhija et al. 2016). The LDA is the probabilistic topic model; which enables the text data clustering results in an unsupervised approaches for large set of text documents. The LDA is a generative topic model in which each document represents the mixture of word probabilities of certain topics (Ramage et al. 2009). NMF model is optimistic model when compared to other topic models. It has the capable of extracting the documents information in terms of valid topics without knowing any prior information (Suri and Roy 2017). Key objective of NMF is to decompose the input matrix (document-term matrix) into two matrices, namely, document-topic matrix and topic term matrix. So that it perfectly extracts the topics information for the set of documents.
Cluster tendency is one the crucial problem in data clustering (Tang et al. 2011; Suleman Basha et al. 2019). (Pushpalatha et al. 2020; Devisetty et al. 2019) of text documents. Many pre-cluster tendency methods are surveyed (Mahallati et al. 2019; Hu and Hathaway 2008; Park et al. 2016; Kumar et al. 2015; Kumar and Bezdek 2020; Varish et al. 2020) for finding the cluster tendency. It is recognized that VAT and iVAT (Havens and Bezdek 2011) are the best choices for finding the assessment of cluster tendency, whereas VAT and iVAT are suited for normal and path-shaped datasets respectively. They are initially measuring the dissimilarity features using distance metrics (Blei et al. 2003) and re-order the indices of data objects (or tweets) in order to find their visual images as shown in Fig. 2.

Visual Method—VAT- Visual Images
It illustrates the clusters as visual dark black coloured blocks in the images (Srinivas 2018) of corresponding VAT. Cluster tendency (or clusters prior information) determined with the count of dark black coloured blocks obtained in the diagonal of visual images. Based on spectral features, the affinity values are computed for dissimilarity features of data objects).
Both VAT and cVAT are procedurally same, however, they compute the dissimilarity features with Euclidean and cosine respectively. Cosine takes the distance among the data objects based on magnitude and directions, whereas in an Euclidean takes distances based on differences among two data object vectors. Thus, cVAT estimates the good assessment of clusters with cosine based dissimilarities when compared to VAT.
Spectral features-based VAT is known as SpecVAT (Wang et al. 2008). SpecVAT finds the affinity matrix for the set of data objects and then Laplacian matrix is derived for determining the spectral (or Eigen features) of data objects. Cluster tendency is accessed from the VAT image of spectral features. It also shows the clusters effectively in the visual image for the set of data objects. Cosine measure is more effective than Euclidean for measuring the distance data objects in text data clustering (Nguyen et al. 2010). It computes the cosine similarity among the objects with reference of a single viewpoint. cVAT use the cosine measure for the assessment of cluster tendency. It justifies the cluster tendency using a single viewpoint only. Recently, multi viewpoints-based cosine similarity is developed and it is MVS-VAT (Reddy and Prasad 2016). It justifies the cluster tendency using more than two viewpoints unlike cVAT, it also produces the efficient data clustering results for the tweet datasets. MVS-VAT effectively utilized for the different topics of tweet datasets in (Prasad et al. 2019b, a) for the experimental of health data clustering results. It suffers with the problem of high computational time for the reason of spent much time in the measuring of similarity among the tweets with respect to (N-2) viewpoints, here N is the total number of viewpoints. Based on the observation of state-of-the-art of visual methods, it needs be development of sampling technique for the selection of few viewpoints rather than selection of (N-2) viewpoints. Thus, sampling based visual method needs to be developed to overcome the problem of high computational time. The proposed work is discussed in the following section, which explains the sample procedure for the selection of viewpoints.
3 Proposed sampling based multi viewpoints visual method
Cluster tendency is the major issue for the tweets data clustering. This problem is effectively handled by visual methods, VAT, cVAT, and MVS-VAT. In this paper, sampling strategy is developed with the selection of best samples of inter clusters viewpoints (SICV) in the extended work of MVS-VAT, say as SICV-MVS-VAT method. Algorithm 1 shows the procedural steps of SICV-MVS-VAT.

Samples of data objects are selected from the inter-cluster data objects. Inter clusters are identified with the selection of most dissimilar data objects (or the centroids of inter clusters); Next, nearest data objects of inter-clusters are identified with the least dissimilar data objects. These inter clusters are generated for the selection of best samples in our proposed work.
Feature extraction of tweets is performed with the derivations of bag-of-features. Topic model aims to derive the tweets feature with respect to topics rather than terms. Thus, problem complexity of data sparsity is handled and simplified with the topics-based feature extraction for wide range of tweets- documents, which process denoted in Step 1, and the features of N tweets are derived as {T1, T2, …. TN}. Pre-estimations of inter clusters are derived using Step 2 to Step6. These steps describe the most deviated data object based distances, in which random object is selected in Step 2 and most deviated data objects (it is considered as centroid of one of assumed cluster) is selected by finding the data object who maintains the maximum distance and it shown in Step 3 and Step 4. Updates the corresponding distances of data objects with centroid in Step 5. The centroids are excluded for further processing steps and considered the new centroids from remaining data objects and it is performed by Step 6. Step 7 shows the multi viewpoints-based cosine similarity (MVS) computation procedure with respect to selection of few viewpoints as per the sample size of ‘np sample’. MVS is applied for every pair of tweet documents (or data objects), which is (Di,Dj), the viewpoints vp should be selected from inter clusters of Di, and Dj; whereas the information of inter clusters are obtained from the earlier steps. The MVS of data pairs shown the similarity value between respective pair and the value is normalized between 0 and 1; find the dissimilarity matrix (M) with subtraction of normalized similarity value from 1, which shown in Step 8. In Step 9, visual method VAT is applied on M for re-ordered dissimilarity matrix (RDM), which represents that re-alignment of data based on ordering of dissimilarity features. Step 10 displays the image of RDM for visualizing the cluster tendency (‘k’). Finally, the cluster labels of tweet documents are computed with the crisp partition matrix of visual clusters shown in Step 11. The crisp partitions are derived with finding of squareness properties of appeared black coloured blocks along the diagonal of VAT image. The squareness property of dark coloured blocks are derived from the difference of pixel values appeared between dark coloured blocks and non-dark coloured blocks. The significance of the proposed work is to assess the excellent value of cluster tendency and generate efficient clustering results with the technique of sampling inter-cluster viewpoints (SICV). The efficiency of the proposed methodology (SICV-MVS-VAT) for the tweets data clustering is demonstrated experimentally in the following section.
4 Experimental study and performance discussion
Existing visual methods, VAT, cVAT, MVS-VAT and proposed method SICV-MVS-VAT are experimented on tweet documents, which are extracted based on standard health keywords, TREC 2015 and TREC2017. Data sets descriptions and performance evaluation of visual methods are presented in this section for demonstrating the efficiency of proposed method in assessment of cluster tendency and its data partitioning results.
4.1 Tweet datasets description
Table 1 shows the tweets description in terms of total number of topics, keywords or health topics. In the experimental, various subsets of tweets are merged as per mentioned keywords. The standard health keywords are used in the experimental, which are trendy or most discussed tweets. Benchmarked TREC2015 and TREC2017 keywords are used for tweets extraction.
4.2 Topic models
Popular topic models, NMF, LDA, LSI, and PLSI, are used to model extracted tweets. During the modelling, bag-of-words of the tweets are extracted to the purpose of feature extraction. The dissimilarity matrix and re-ordered dissimilarity matrix are computed in the existing and proposed visual methods after the extraction of feature extraction. Exploration of tweets data clustering results are demonstrated in the following sub-section for a comparison study of visual methods for the four topic models.
4.3 Performance discussion
The comparative visualizations for the cluster tendency shown in Figs. 3, 4, 5, and 6 for TREC2015 (two-topic), TREC2017 (three-topic), standard health tweets (10-topics), and standard health tweets (15-topics), respectively. Resulting visual images of three existing methods and proposed SICV-MVS-VAT. The following figures having three variations of visual images, which are derived from VAT, MVS-VAT, and SICV-MVS-VAT methods respectively. Key variation of these images is that visual appearance and clarity of square-shaped black coloured dark blocks along the diagonal for the three methods in Figs. 3 and 4. Based on the experimental of existing VAT and MVS-VAT and SICV-MVS-VAT, it is observed that proposed SICV-MVS -VAT effectively determines the similarity features among the data objects with inter-cluster viewpoints.

Cluster Tendency Assessment for Visual Methods (TREC2015-Two Topics)

Cluster Tendency Assessment for Visual Methods (TREC2017-Three Topics)

Cluster Tendency Assessment for Visual Methods (Standard Health Tweets—Ten Topics)

Cluster Tendency Assessment for Visual Methods (Standard Health Tweets—Fifteen Topics)
Experimental is conducted under different topic models with finding of similarity features using cosine and Euclidean distance metrics. Cosine is based text data clusters assessment proven as the best when compared to Euclidean for any topic model. Experimental results of VAT based topic models, MVS-VAT based topic models, and SICV-MVS-VAT based topic models under Euclidean and cosine metrics are illustrated in Figs. 5 and 6; which results states that cosine based clusters assessment are the best when compared to Euclidean under any topic model and proven that our SICV-MVS-VAT visualizes the best clusters assessment compared to others.
With the sampling of inter-cluster viewpoints, the similarity among the tweets documents is computed. Cluster tendency generates with the count of dark black coloured blocks of visual method images. More clarity of visual clusters indicates proper and accurate social data clusters; for the text tweets, cosine shown the quality of clusters than Euclidean.
This assessment of cluster tendency is performed with a single viewpoint and it is with origin—the proposed methodology used multiple viewpoints during the assessment of cluster tendency. More informative assessment is extracted with multi viewpoints rather than a single viewpoint.
Therefore, SICV-MVS-VAT has shown the best quality of clusters than other visual methods, and the same is observed in Figs. 3 to 6. With the derivations of crisp partitions, the complete clustering results are obtained. Table 2 shows the sample tweets data. Table 3 shown the performance evaluation of visual methods using the performance measures mentioned in (Datta et al. 2018); (Vinh et al. 2010); (Bhatnagar et al. 2018) and with these five measures, study of performance for the visual methods are evaluated and presented in Table 4.
For the evaluation of performance, five performance measures are used, cluster accuracy (CA) (Pattanodom et al. 2016), normalized mutual information (NMI) (Amelio and Pizzuti 2015), precision (P), Recall (R), and F-Measure (F) (Xu et al. 2019; Li et al. 2016).
More visual clarity of clusters are appeared with the black coloured blocks of visual images using cosine similarity than Euclidean. The similarity features are computed with reference of a single viewpoint (i.e. origin) in cosine based visual method.
Recent visual method, MVS-VAT uses (N-2) viewpoints for measure the cosine similarity between any two documents among the ‘N’ documents. Hence, it showed the more clarity of visual clusters than cosine metric. However, it taken high computation time for the similarity computation of N documents with respect to (N-2) documents. Our proposed method (SICV-MVS-VAT) also uses the multiple viewpoints for the good assessment of visual clusters. This method use the sample viewpoints of pre-generated inter clusters instead of (N-2) viewpoints. Thus, it takes the fewer amounts of computational time and memory allocations than MVS-VAT.
Figures 7 and 8 visualizes the performance comparison with the measures, CA and NMI respectively. It states that proposed visual method SICV-MVS-VAT-NMF shown an excellent performance for the different sets of topic models i.e. 2-topics to 15-topics.

Performance Comparison of Visual Methods for the Topics Datasets (Using Clustering Accuracy)

Performance Comparison of Visual Methods for the Topics Datasets (Using NMI)
Topic model NMF greatly supports to proposed sampling based visual method compared to other topic models. The same performance values are illustrated experimentally and presented in the performance graph comparison charts.
Based on the observation of time and space values of SICV-MVS-VAT and MVS-VAT, we stated that proposed SICV-MVS-VAT taken the less computational time and less memory allocation than MVS-VAT due to fact for the selected sample viewpoints instead considering (N-2) viewpoints, unlike MVS-VAT. Hence, proposed SICV-MVS-VAT has outperformed the other visual methods with respect to the quality of tweets data clustering results, time and space requirements.
5 Conclusion and scope
Visual methods are well suited for accessing the pre-clusters information (cluster tendency ‘k’) and generation of tweets data clustering results. It proved that cosine-based pre-clusters estimations are reasonable when compared to clusters assessment with Euclidean in text clustering. However, a single viewpoint is considered when considering similarity features among tweets in the tweet data clustering. Another visual method MVS-VAT access the cluster tendency with multi viewpoints rather than a single viewpoint. Thus, it produces more effective clustering results than cosine based visual methods. Due to overcome the time and space issues of MVS-VAT, proposed work uses the sampling of inter-cluster viewpoints. The in-depth experimental analysis proved that proposed SICV-MVS-VAT is an efficient technique for the tweet data clustering.
References
Amelio A, Pizzuti C (2015) Is normalized mutual information a fair measure for comparing community detection methods. In: IEEE/ACM international conference on advances in social networks analysis and mining, pp. 1584–1585.
Bezdek JC, Hathaway RJ (2002) VAT: A tool for visual assessment of (cluster) tendency. In: Proceedings of the 2002 international joint conference on neural networks. IJCNN'02 (Cat. No. 02CH37290), pp 2225–2230.
Bhatnagar V, Majhi R, Jena PR (2018) Comparative performance evaluation of clustering algorithms for grouping manufacturing firms. Arab J Sci Eng 43(8):4071–4083
Blei DM, Ng AY, Jordan MI (2003) Latent dirichlet allocation. J Mach Learning Res pp 993–1022.
Datta S, Bhattacharjee S, Das S (2018) Clustering with missing features: a penalized dissimilarity measure based approach. Mach Learn 107(12):1987–2025
Deerwester S, Dumais ST, Furnas GW, Landauer TK, Harshman R (1990) Indexing by latent semantic analysis. J Am Soc Inform Sci 41(6):391–407
Devisetty SDP, Yarramneni MS, Akash VY, Pellakuri V (2019) Sentiment analysis of tweets using rapid miner tool. Int J Innovative Technol Exploring Eng 8(6):1410–1414
Havens TC, Bezdek JC (2011) An efficient formulation of the improved visual assessment of cluster tendency (iVAT) algorithm. IEEE Trans Knowl Data Eng 24(5):813–822
Hofmann T (1999) Probabilistic latent semantic indexing. In: Proceedings of the 22nd annual international ACM SIGIR conference on Research and development in information retrieval, pp 50–57.
Hu Y, Hathaway RJ (2008) An algorithm for clustering tendency assessment. WSEAS Trans Math 7(7):441–450
Hu Y, John A, Wang F, Kambhampati S (2012) ET-LDA: joint topic modeling for aligning events and their twitter feedback. In: AAAI, pp 59–65.
Ismail M, Prakash KB, Rao MN (2018) Collaborative filtering-based recommendation of online social voting. Int J Eng Technol (UAE) 7(3):1504–1507
Jose T, Babu SS (2019) Detecting spammers on social network through clustering technique. J Ambient Intell Human Comput, pp 1–15.
Kumar D, Bezdek JC (2020) Visual approaches for exploratory data analysis: a survey of the visual assessment of clustering tendency (VAT) family of algorithms. IEEE Syst Man Cybernet Mag 6(2):10–48
Kumar D, Bezdek JC, Palaniswami M, Rajasegarar S, Leckie C, Havens TC (2015) A hybrid approach to clustering in big data. IEEE Trans Cybernet 46(10):2372–2385
Lee DD, Seung HS (2001) Algorithms for non-negative matrix factorization. In: Advances in neural information processing systems, pp 556–562.
Li Z, Shang W, Yan M (2016) News text classification model based on-the topic model. In: IEEE/ACIS 15th international conference on computer and information science (ICIS), pp 1–5.
Mahallati S, Bezdek JC, Popovic MR, Valiante TA (2019) Cluster tendency assessment in neuronal spike data. PLoS ONE 14(11):1–29
Neogi PPG, Das AK, Goswami S, Mustafi J (2020) Topic modeling for text classification. In: Emerging technology in modelling and graphics, pp 395–407.
Nguyen DT, Chen L, Chan CK (2010) Multi-viewpoint based similarity measure and optimality criteria for document clustering. In: Asia information retrieval symposium, pp 49–60.
Oghbaie M, Zanjireh MM (2018) Pairwise document similarity measure based on present term set. J Big Data 5(1):1–23
Park LA, Bezdek JC, Leckie C, Kotagiri R, Bailey J, Palaniswami M (2016) Visual assessment of clustering tendency for incomplete data. IEEE Trans Knowl Data Eng 28(12):3409–3422
Pattanodom M, Iam-On N, Boongoen T (2016) Clustering data with the presence of missing values by ensemble approach. In: 2016 second asian conference on defence technology (acdt), pp 151–156.
Pessiot JF, Kim YM, Amini MR, Gallinari P (2010) Improving document clustering in a learned concept space. Inf Process Manage 46(2):180–192
Prasad KR, Mohammed M, Noorullah RM (2019) Hybrid topic cluster models for social healthcare data. Int J Adv Comput Sci Appl 10(11):490–506
Prasad KR, Mohammed M, Noorullah RM (2019) Visual topic models for healthcare data clustering. Evolutionary Intelligence, pp 1–18.
Pushpalatha A, Harivarthini S, Akil S, Akshaya V, Amarendra K, Bhanu Prakash K (2020) Real time objects recognition and classification to audio conversion for visually impaired person. Int J Adv Sci Technol 29(3):8290–8297
Ramage D, Hall D, Nallapati R, Manning CD (2009) Labeled LDA: a supervised topic model for credit attribution in multi-labeled corpora. In:Proceedings of the 2009 conference on empirical methods in natural language processing, pp. 248–256.
Reddy BE, Prasad KR (2016) Improving the performance of visualized clustering method. Int J Syst Assurance Eng Manag 7(1):102–111
Rehioui H, Idrissi A (2019) New clustering algorithms for twitter sentiment analysis. IEEE Syst J 14(1):530–537
Sechelea A, Do Huu T, Zimos E, Deligiannis N (2016) Twitter data clustering and visualization. In: 2016 23rd international conference on telecommunications (ICT), pp. 1–5.
Shirkhorshidi AS, Aghabozorgi S, Wah TY (2015) A comparison study on similarity and dissimilarity measures in clustering continuous data. PLoS ONE 10(12):1–20
Srinivas K (2018) Test case prioritization with special emphasis on automation testing using hybrid framework. J Theoretical Appl Inform Technol 96(13):4180–4190
Sukhija N, Tatineni M, Brown N, Van Moer M, Rodriguez P, Callicott S (2016)Topic modeling and visualization for big data in social sciences. In: IEEE Conferences on ubiquitous intelligence & computing, advanced and trusted computing, scalable computing and communications, cloud and big data computing, internet of people, and smart world congress (UIC/ATC/ScalCom/CBDCom/IoP/SmartWorld), pp 1198–1205.
Suleman Basha M, Mouleeswaran SK, Rajendra Prasad K (2019) Cluster tendency methods for visualizing the data partitions. Int J Innovative Technol Exploring Eng 8 (11): 2978–2982.
Suri P, Roy NR (2017) Comparison between LDA & NMF for event-detection from large text stream data. In: International conference on computational intelligence & communication technology (CICT), pp. 1–5.
Tang H, Chu S, Hasegawa-Johnson M, Huang T (2011) Partially supervised speaker clustering. IEEE Trans Pattern Anal Mach Intell 34(5):959–971
Therese SS, Lingam C (2017) A linear visual assessment tendency based clustering with power normalized cepstral coefficients for audio signal recognition system. J Ambient Intell Human Comput pp. 1–14.
Varish N, Pal AK, Hassan R, Hasan MK, Khan A, Parveen N, Memon I (2020) Image retrieval scheme using quantized bins of color image components and adaptive tetrolet transform. IEEE Access, pp 117639–117665.
Vinh NX, Epps J, Bailey J (2010) Information theoretic measures for clusterings comparison: Variants, properties, normalization and correction for chance. J Mach Learn Res pp 2837–2854.
Wallach HM (2006) Topic modeling: beyond bag-of-words. In: Proceedings of the 23rd international conference on Machine learning, pp 977–984.
Wang L, Geng X, Bezdek J, Leckie C, Kotagiri R (2008) SpecVAT: Enhanced visual cluster analysis. In: 2008 eighth IEEE international conference on data mining, pp 638–647.
Xu R, Wunsch D (2005) Survey of clustering algorithms. IEEE Trans Neural Netw 16(3):645–678
Xu G, Meng Y, Chen Z, Qiu X, Wang C, Yao H (2019) Research on topic detection and tracking for online news texts. IEEE Access, pp 58407–58418.
Yi F, Jiang B, Wu J (2020) Topic modeling for short texts via word embedding and document correlation. IEEE Access, pp 30692–30705.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Prasad, K.R., Reddy, B.E. & Mohammed, M. An effective assessment of cluster tendency through sampling based multi-viewpoints visual method. J Ambient Intell Human Comput (2021). https://doi.org/10.1007/s12652-020-02710-8
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12652-020-02710-8