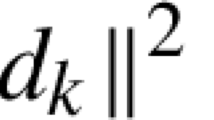Proof of Lemma 1
Proof of Lemma 1
The first assertion follows from the proof of [31, Theorem 1]. See also [19, Theorem 2.1] and [5, Lemma 4.1]. The condition (20) is given by the first order optimality condition of (17). It implies
$$\begin{aligned} \varLambda (u;\lambda ,\beta ) \in \partial h \left( u-\beta (\varLambda (u;\lambda , \beta )-\lambda )\right) . \end{aligned}$$
(91)
The equality in (21) is a direct application of the Fenchel duality theorem [37]. See also [5, Equation 4.1 and 4.2]. The inequality in (21) follows by considering \(w=0\). The condition (22) follows from the first order optimality condition and (91). Finally (23) is obtained by plugging the optimal solution \(w^\star \) in (22) into (21).
Some useful lemmas
We first state two useful lemmas.
Lemma 6
Let \(\psi (\cdot ):\mathbb {R}^n\rightarrow \mathbb {R}\cup \{+\infty \}\) be a convex function. Define:
$$\begin{aligned} {\tilde{\psi }}(x):=\inf _w\{h(p(x)-w)+\psi (w)\}, \end{aligned}$$
Then condition (15) ensures the convexity of \(\tilde{\psi }\).
Proof
For any \(x, y\in \mathbb {R}^n\) and \(\alpha \in [0,1]\), let \(z= \alpha x+ (1- \alpha )y\). By condition (15),
$$\begin{aligned} h\left( p(z)- \alpha u- (1- \alpha ) v\right) \le \alpha h(p(x)- u)+ (1- \alpha )h(p(y)- v),\forall u,v\in \mathbb {R}^d. \end{aligned}$$
It follows that
$$\begin{aligned} \tilde{\psi }(z)&= \inf _\omega \left\{ h(p(z)- \omega )+ \psi (\omega ) \right\} \\&= \inf _{u,v} \left\{ h\left( p(z)- \alpha u- (1- \alpha )v\right) + \psi (\alpha u+ (1- \alpha )v) \right\} \\&\le \inf _{u,v} \left\{ \alpha h(p(x)- u)+ (1- \alpha )h(p(y)- v)+ \alpha \psi (u)+ (1- \alpha )\psi (v) \right\} \\&= \alpha \inf _u \left\{ h(p(x)- u)+ \psi (u) \right\} + (1- \alpha )\inf _v \left\{ h(p(y)- v)+ \psi (v) \right\} \\&= \alpha \tilde{\psi }(x)+ (1- \alpha )\tilde{\psi }(y). \end{aligned}$$
\(\square \)
Similarly, we can show the following result.
Lemma 7
Let \(\psi (\cdot ):\mathbb {R}^n\rightarrow \mathbb {R}\cup \{+\infty \}\) be a convex function. Define:
$$\begin{aligned} {\tilde{\psi }}(w):=\inf _x\{h(p(x)-w)+\psi (x)\}, \end{aligned}$$
Then condition (15) ensures the convexity of \(\tilde{\psi }\).
Inexact proximal point algorithm and inexact augmented Lagrangian method
1.1 Inexact proximal point method
Let \({\mathcal {T}}:\mathbb {R}^{n+d}\rightarrow \mathbb {R}^{n+d}\) be a maximal monotone operator and \({\mathcal {J}}_{\rho }= ({\mathcal {I}}+ \rho {\mathcal {T}})^{-1}\) be the resolvent of \({\mathcal {T}}\), where \({\mathcal {I}}\) denotes the identity operator. Then for any \(z^\star \) such that \(0\in {\mathcal {T}}(z^\star )\) [39],
$$\begin{aligned} \left\| {\mathcal {J}}_{\rho }(z)- z^\star \right\| ^2+ \left\| {\mathcal {J}}_{\rho }(z)- z\right\| ^2\le \left\| z- z^\star \right\| ^2. \end{aligned}$$
(92)
Lemma 8
[39] Let \(\{z^{s}\}\) be the sequence generated by Algorithm 4. Then for any \(z^\star \) such that \(0\in {\mathcal {T}}(z^\star )\),
$$\begin{aligned} \left\| z^{s+1}- z^\star \right\| \le \left\| z_0- z^\star \right\| + \sum _{i= 0}^{s}\varepsilon _i \\ \left\| z^{s+1}- z^{s}\right\| \le \left\| z_0- z^\star \right\| + \sum _{i= 0}^{s}\varepsilon _i \end{aligned}$$
We now give a stochastic generalization of Algorithm 4.
We then extend Lemma 8 for Algorithm 5.
Lemma 9
Let \(\{z^{s}\}\) be the sequence generated by Algorithm 5. Then for any \(z^\star \) such that \(0\in {\mathcal {T}}(z^\star )\),
$$\begin{aligned} \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| \right] \le \left\| z_0- z^\star \right\| + \sum _{i= 0}^{s}\varepsilon _i \\ \mathbb {E}\left[ \left\| z^{s+1}- z^{s}\right\| \right] \le \left\| z_0- z^\star \right\| + \sum _{i= 0}^{s}\varepsilon _i \\ \left( \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| ^2\right] \right) ^{1/2}\le \left\| z_0- z^\star \right\| + \sum _{i= 0}^{s}\varepsilon _i \end{aligned}$$
Proof
By (92), we know that for all \(i\ge 0\)
$$\begin{aligned} \left\| z^{i+1}- z^\star \right\|&\le \left\| z^{i+ 1}- {\mathcal {J}}_{\rho _i}(z^i)\right\| + \left\| {\mathcal {J}}_{\rho _i}(z^i)- z^\star \right\| \\&\le \left\| z^{i+ 1}- {\mathcal {J}}_{\rho _i}(z^i)\right\| + \left\| z^i- z^\star \right\| . \end{aligned}$$
Taking expectation on both sides, we get
$$\begin{aligned} \mathbb {E}\left[ \left\| z^{i+1}- z^\star \right\| \right] \le \mathbb {E}\left[ \left\| z^{i+ 1}- {\mathcal {J}}_{\rho _i}(z^i)\right\| \right] + \mathbb {E}\left[ \left\| z^i- z^\star \right\| \right] . \end{aligned}$$
By the definition of \(z^{s}\), we have \(\left( \mathbb {E}\left\| z^{s+1}- {\mathcal {J}}_{\rho _s}(z^{s})\right\| \right) ^2\le \mathbb {E}\left\| z^{s+1}- {\mathcal {J}}_{\rho _s}(z^{s})\right\| ^2\le \varepsilon _s^2\) and therefore
$$\begin{aligned} \mathbb {E}\left[ \left\| z^{i+1}- z^\star \right\| \right] \le \epsilon _i+ \mathbb {E}\left[ \left\| z^i- z^\star \right\| \right] . \end{aligned}$$
The first estimates is derived by summing the above inequality from \(i= 0\) to s.
By (92), we know that for all for all \(s\ge 0\)
$$\begin{aligned} \left\| z^{s+1}- z^s\right\| \le \left\| z^{s+ 1}- {\mathcal {J}}_{\rho _s}(z^s)\right\| + \left\| {\mathcal {J}}_{\rho _s}(z^s)- z^s\right\| \le \left\| z^{s+ 1}- {\mathcal {J}}_{\rho _s}(z^s)\right\| + \left\| z^s- z^\star \right\| . \end{aligned}$$
Taking expectation on both sides,
$$\begin{aligned} \mathbb {E}\left[ \left\| z^{s+1}- z^s\right\| \right] \le \mathbb {E}\left[ \left\| z^{s+ 1}- {\mathcal {J}}_{\rho _s}(z^s)\right\| \right] + \mathbb {E}\left[ \left\| z^s- z^\star \right\| \right] \le \epsilon _s+ \mathbb {E}\left[ \left\| z^s- z^\star \right\| \right] . \end{aligned}$$
Together with the first estimate, the second estimate is derived.
The third estimate is derived from (92):
$$\begin{aligned} 0&\le \left\| {\mathcal {J}}_{\rho _s}- z^{s}\right\| ^2\le \left\| z^{s}- z^\star \right\| ^2- \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^\star \right\| ^2 \\&= \left\| z^{s}- z^\star \right\| ^2- \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}+ z^{s+1}- z^\star \right\| ^2 \\&\le \left\| z^{s}- z^\star \right\| ^2- \left\| z^{s+1}- z^\star \right\| ^2- \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| ^2\\&\quad + 2 \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| \left\| z^{s+1}- z^\star \right\| \end{aligned}$$
Taking expectation on both sides we have:
$$\begin{aligned} 0&\le \mathbb {E}\left[ \left\| z^{s}- z^\star \right\| ^2\right] - \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| ^2\right] \\&\quad - \mathbb {E}\left[ \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| ^2\right] + 2 \mathbb {E}\left[ \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| \left\| z^{s+1}- z^\star \right\| \right] \\&\le \mathbb {E}\left[ \left\| z^{s}- z^\star \right\| ^2\right] - \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| ^2\right] \\&\quad - \mathbb {E}\left[ \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| ^2\right] + 2\left( \mathbb {E}\left[ \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| ^2\right] \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| ^2\right] \right) ^{1/2} \\&= \mathbb {E}\left[ \left\| z^{s}- z^\star \right\| ^2\right] - \left( \left( \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| ^2\right] \right) ^{1/2}- \left( \mathbb {E}\left[ \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| ^2\right] \right) ^{1/2}\right) ^2 \end{aligned}$$
where the second inequality we use \(\mathbb {E}[XY]\le (\mathbb {E}[X^2])^{1/2}(\mathbb {E}[Y^2])^{1/2}\). Therefore
$$\begin{aligned} \left( \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| ^2\right] \right) ^{1/2}- \varepsilon _s&\le \left( \mathbb {E}\left[ \left\| z^{s+1}- z^\star \right\| ^2\right] \right) ^{1/2}- \left( \mathbb {E}\left[ \left\| {\mathcal {J}}_{\rho _s}(z^{s})- z^{s+1}\right\| ^2\right] \right) ^{1/2}\\&\le \left( \mathbb {E}\left[ \left\| z^{s}- z^\star \right\| ^2\right] \right) ^{1/2} \end{aligned}$$
Then summing up the latter inequalities from \(s= 0\) we obtain the third inequality. \(\square \)
1.2 Inexact ALM
We define the maximal monotone operator \({\mathcal {T}}_{l}\) as follows.
$$\begin{aligned} {\mathcal {T}}_l(x;\lambda )&=\left\{ (v;u): (v;-u)\in \partial L(x;\lambda )\right\} \\&=\left\{ \begin{pmatrix} \nabla f(x)+\partial g(x)+\nabla p(x)\lambda \\ -p(x)+\partial h^*(\lambda ) \end{pmatrix}\right\} \end{aligned}$$
In the following we denote
$$\begin{aligned} \begin{aligned} L^\star (y,\lambda ,\beta )&:=\min _x L(x;y,\lambda ,\beta ),\\ x^\star (y,\lambda , \beta )&:=\arg \min _x L(x;y,\lambda ,\beta ),p^\star (y,\lambda ,\beta ):=p(x^\star (y,\lambda ,\beta )). \end{aligned} \end{aligned}$$
(93)
We further let \(\varLambda ^\star (y,\lambda ,\beta ):=\varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )\). By first order optimality condition and (18), we know that
$$\begin{aligned}&0\in \nabla f(x^\star (y,\lambda ,\beta ))+\partial g(x^\star (y,\lambda ,\beta ))\\&\qquad +\nabla p(x^\star (y, \lambda ,\beta )) \varLambda ^\star (y,\lambda ,\beta )+\beta (x^\star (y,\lambda ,\beta )-y) \end{aligned}$$
Secondly we know from (20) that
$$\begin{aligned} p^\star (y,\lambda ,\beta )-\beta (\varLambda ^\star (y,\lambda , \beta )-\lambda )\in \partial h^*(\varLambda ^\star (y,\lambda ,\beta )). \end{aligned}$$
It follows that
$$\begin{aligned} ( {\mathcal {I}}+\beta ^{-1}{\mathcal {T}}_l)^{-1}(y;\lambda )=(x^\star (y,\lambda ,\beta );\varLambda ^\star (y,\lambda ,\beta )) \end{aligned}$$
(94)
Lemma 10
For any \(x\in \mathbb {R}^n\) we have,
$$\begin{aligned} \begin{aligned} L(x;y,\lambda ,\beta )-L^\star (y,\lambda ,\beta )&\ge \frac{\beta }{2}\Vert x-x^\star (y,\lambda ,\beta )\Vert ^2\\&\quad +\frac{\beta }{2} \Vert \varLambda (p(x);\lambda ,\beta )- \varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )\Vert ^2. \end{aligned} \end{aligned}$$
(95)
Proof
In this proof we fix \(y\in \mathbb {R}^n\), \(\lambda \in \mathbb {R}^d\) and \(\beta >0\). Recall the definitions in (93). Define
$$\begin{aligned} L(x, w; y, \lambda ,\beta ):= & {} f(x)+g(x)+ h(p(x)-w)+\frac{1}{2\beta }\Vert w\Vert ^2+\langle w,\lambda \rangle \\&+\frac{\beta }{2}\Vert x-y\Vert ^2-\frac{\beta }{2}\Vert x-x^\star (y,\lambda ,\beta )\Vert ^2. \end{aligned}$$
Then by (21),
$$\begin{aligned} \min _w L(x, w; y, \lambda ,\beta )= L(x;y,\lambda ,\beta )-\frac{\beta }{2}\Vert x-x^\star (y,\lambda ,\beta )\Vert ^2. \end{aligned}$$
(96)
Since \(L(x;y,\lambda ,\beta )-\frac{\beta }{2}\Vert x-x^\star (y,\lambda ,\beta )\Vert ^2\) is a convex function with \(x^\star (y,\lambda ,\beta )\) being a critical point, it follows that
$$\begin{aligned} \min _x \min _w L(x, w; y, \lambda ,\beta )=L^\star (y, \lambda ,\beta ). \end{aligned}$$
(97)
Denote
$$\begin{aligned} H(w;y, \lambda ,\beta ):=\min _x L(x, w;y, \lambda ,\beta ). \end{aligned}$$
(98)
In view of (22),
$$\begin{aligned} \begin{aligned} L(x;y, \lambda ,\beta )-\frac{\beta }{2}\Vert x-x^\star (y,\lambda ,\beta )\Vert ^2&=L(x, \beta (\varLambda (p(x); \lambda ,\beta )-\lambda ); y,\lambda ,\beta )\\&\overset{(98)}{\ge } H(\beta (\varLambda (p(x);\lambda ,\beta )-\lambda ); y,\lambda ,\beta ). \end{aligned} \end{aligned}$$
(99)
Note that
$$\begin{aligned} \min _w H(w;y,\lambda ,\beta )&=\min _w \min _x L(x,w;y,\lambda ,\beta )\nonumber \\&=\min _x \min _w L(x,w;y,\lambda ,\beta )\overset{(97)}{=}L^\star (y,\lambda ,\beta ). \end{aligned}$$
(100)
Denote \(\varLambda ^\star (y,\lambda ,\beta )=\varLambda (p^\star (y,\lambda ,\beta ); \lambda ,\beta )\). It follows that,
$$\begin{aligned}&H( \beta (\varLambda ^\star (y,\lambda ,\beta )-\lambda );y,\lambda ,\beta )\\&\quad \ge \min _w H(w;y,\lambda ,\beta )\overset{(100)}{=}L^\star (y,\lambda ,\beta )=L(x^\star ( y,\lambda ,\beta ); y,\lambda ,\beta ). \end{aligned}$$
Using again (99) with \(x=x^\star ( y,\lambda ,\beta )\) we deduce
$$\begin{aligned} H( \beta (\varLambda ^\star (y,\lambda ,\beta )-\lambda );y,\lambda ,\beta ) = \min _w H(w;y,\lambda ,\beta ). \end{aligned}$$
(101)
Moreover, it follows from Lemma 7 that \(H( w;y, \lambda ,\beta )\) is \(1/\beta \)-strongly convex with respect to w. Thus,
$$\begin{aligned}&L(x;y,\lambda ,\beta )-L^\star (y,\lambda ,\beta )-\frac{\beta }{2}\Vert x-x^\star (y,\lambda ,\beta )\Vert ^2\\&\quad \overset{(99)+(100)}{\ge } H(\beta (\varLambda (p(x);\lambda ,\beta )-\lambda );y,\lambda ,\beta )-\min _w H(w;y,\lambda ,\beta ) \\&\quad \overset{(101)}{\ge } \quad \frac{1}{2\beta }\Vert \beta (\varLambda (p(x);\lambda ,\beta )-\lambda )-\beta (\varLambda ^\star (y,\lambda ,\beta )-\lambda ) \Vert ^2\\&\quad =\frac{\beta }{2} \Vert \varLambda (p(x);\lambda ,\beta )- \varLambda ^\star (y,\lambda ,\beta )\Vert ^2. \end{aligned}$$
\(\square \)
We can then establish the following well known link between inexact ALM and inexact PPA.
Proposition 3
(Compare with [39]) Algorithm 1 is a special case of Algorithm 5 with \({\mathcal {T}}={\mathcal {T}}_l\), \(\rho _s=1/\beta _s\) and \(\varepsilon _s= \sqrt{2\epsilon _s/\beta _s}\).
Proof
This follows from (94) and Lemma 10. \(\square \)
Missing proofs
1.1 Proofs in Section 2.2
Proof of Lemma 2
The convexity of \({\tilde{\psi }}\) follows from (21) and Lemma 6 with \(\psi (w):=\frac{1}{2\beta }\Vert w\Vert ^2+\langle w,\lambda \rangle \). The gradient formula follows from (18).
Proof of Lemma 3
This is a direct consequence of Proposition 3 and Lemma 9.
Proof of Corollary 1
By Lemma 3, we have
$$\begin{aligned} \mathbb {E}\left[ \left\| (x^{s},\lambda ^{s+ 1})- (x^{s-1},\lambda ^{s})\right\| \right] \le \left\| (x^{-1},\lambda ^0)- (x^\star ,\lambda ^\star )\right\| + \frac{2\sqrt{\epsilon _0/\beta _0}}{1-\sqrt{\eta /\rho }},\forall s\ge 0, \end{aligned}$$
and
$$\begin{aligned} \mathbb {E}\left[ \left\| (x^{s},\lambda ^{s+ 1})- (x^\star ,\lambda ^\star )\right\| ^2\right] \le \left( \left\| (x^{-1},\lambda ^0)- (x^\star ,\lambda ^\star )\right\| + \frac{2\sqrt{\epsilon _0/\beta _0}}{1-\sqrt{\eta /\rho }} \right) ^2,\forall s\ge 0. \end{aligned}$$
Consequently,
$$\begin{aligned} \mathbb {E}\left[ \left\| \lambda ^{s+ 1}-\lambda ^{s}\right\| \right] \le \left\| (x^{-1},\lambda ^0)- (x^\star ,\lambda ^\star )\right\| + \frac{2\sqrt{\epsilon _0/\beta _0}}{1-\sqrt{\eta /\rho }},\forall s\ge 0, \end{aligned}$$
and
$$\begin{aligned}&\max \left( \mathbb {E}\left[ \left\| x^{s}-x^\star \right\| ^2\right] , \mathbb {E}\left[ \left\| \lambda ^{s+1}-\lambda ^\star \right\| ^2\right] \right) \\&\quad \le \left( \left\| (x^{-1},\lambda ^0)- (x^\star ,\lambda ^\star )\right\| + \frac{2\sqrt{\epsilon _0/\beta _0}}{1-\sqrt{\eta /\rho }} \right) ^2,\forall s\ge 0. \end{aligned}$$
We then conclude.
Proof of Theorem 1
First,
$$\begin{aligned} \begin{array}{ll} h_1(p_1(x^s))- h(p(x^s);\lambda ^s,\beta _s) &{}\overset{(23)}{=} h_1(p_1(x^s))-h_1(p_1(x^s)-\beta _s(\lambda _1^{s+1}-\lambda _1^s))\\ &{}\qquad -\frac{\beta _s}{2}(\Vert \lambda ^{s+1}\Vert ^2-\Vert \lambda ^s\Vert ^2)\\ {} &{}\le L_{h_1} \beta _s \Vert \lambda _1^{s+1}-\lambda _1^s\Vert +\frac{\beta _s}{2}(\Vert \lambda ^{s}\Vert ^2-\Vert \lambda ^{s+1}\Vert ^2). \end{array} \end{aligned}$$
(102)
Then we know that
$$\begin{aligned} F(x^s)-L(x^s; x^{s-1}, \lambda ^s, \beta _s)&= h_1(p_1(x^s))- h(p(x^s);\lambda ^s,\beta _s)-\frac{\beta _s}{2}\Vert x^{s}-x^{s-1}\Vert ^2\\&\overset{(102)}{\le } L_{h_1} \beta _s \Vert \lambda _1^{s+1}-\lambda _1^s\Vert +\frac{\beta _s}{2}(\Vert \lambda ^{s}\Vert ^2-\Vert \lambda ^{s+1}\Vert ^2)\\&\quad -\frac{\beta _s}{2}\Vert x^{s}-x^{s-1}\Vert ^2. \end{aligned}$$
Since \(H_s(\cdot )\) is \(\beta _s\)-strongly convex, we know that
$$\begin{aligned} L^\star (x^{s-1}, \lambda ^s,\beta _s)&\le L(x^\star ; x^{s-1}, \lambda ^s, \beta ^s)-\frac{\beta _s}{2}\Vert x^\star -x^\star (x^{s-1}, \lambda ^s, \beta _s)\Vert ^2 \\&\overset{(21)}{\le } F^\star +\frac{\beta _s}{2}\Vert x^\star -x^{s-1}\Vert ^2-\frac{\beta _s}{2}\Vert x^\star -x^\star (x^{s-1}, \lambda ^s, \beta _s)\Vert ^2. \end{aligned}$$
Combining the latter two bounds we get
$$\begin{aligned} F(x^s)-F^\star&\le L(x^s; x^{s-1}, \lambda ^s, \beta _s)-L^\star (x^{s-1}, \lambda ^s,\beta _s)+ L_{h_1} \beta _s \Vert \lambda _1^{s+1}-\lambda _1^s\Vert \\&\quad +\frac{\beta _s}{2}(\Vert \lambda ^{s}\Vert ^2-\Vert \lambda ^{s+1}\Vert ^2)+\frac{\beta _s}{2}\Vert x^\star -x^{s-1}\Vert ^2 \\&\quad -\frac{\beta _s}{2}\Vert x^\star -x^\star (x^{s-1}, \lambda ^s, \beta _s)\Vert ^2 -\frac{\beta _s}{2}\Vert x^{s}-x^{s-1}\Vert ^2. \end{aligned}$$
Furthermore, by convexity of \(h_1(\cdot )\),
$$\begin{aligned} \inf _x F(x)+ \langle \lambda _2^\star , p_2(x) \rangle -h_2^*(\lambda _2^\star ) \ge \inf _x f(x)+g(x)+\langle \lambda ^\star , p(x) \rangle -h^*(\lambda ^\star )=D(\lambda ^\star ). \end{aligned}$$
Now we apply the strong duality assumption (11) to obtain:
$$\begin{aligned} F(x^s)+ \langle \lambda _2^\star , p_2(x^s) \rangle -h_2^*(\lambda _2^\star )\ge \inf _x F(x)+ \langle \lambda _2^\star , p_2(x) \rangle -h_2^*(\lambda _2^\star ) \ge F^\star . \end{aligned}$$
Consequently,
$$\begin{aligned}&F(x^s)-F^\star \ge \langle \lambda _2^\star , -p_2(x^s) \rangle + h_2^*(\lambda _2^\star ) \\&\quad \ge \sup _v \langle \lambda _2^\star , v-p_2(x^s) \rangle -h_2(v) \ge -\Vert \lambda _2^\star \Vert {\text {dist}}(p_2(x^s),{\mathcal {K}}). \end{aligned}$$
From (20) we know
$$\begin{aligned} p_2(x^s)-\beta _s(\lambda _2^{s+1}-\lambda _2^s)\in {\mathcal {K}}, \end{aligned}$$
and thus
$$\begin{aligned} {\text {dist}}(p_2(x^s), {\mathcal {K}})\le \beta _s\Vert \lambda _2^{s+1}-\lambda _2^s\Vert . \end{aligned}$$
Proof of Corollary 2
Taking expectation on both sides of the bounds in Theorem 1 we have:
$$\begin{aligned}&\mathbb {E}\left[ F(x^s)-F^\star \right] \le \epsilon _s+ L_{h_1} \beta _s\left( \mathbb {E}\left\| \lambda ^{s+ 1}_1\right\| + \mathbb {E}\left\| \lambda ^s_1\right\| \right) \\ \\&\quad +\frac{\beta _s}{2}\mathbb {E}\left[ \left\| \lambda ^s\right\| ^2\right] + \frac{\beta _s}{2}\mathbb {E}\left[ \left\| x^s- x^{s- 1}\right\| ^2\right] , \\&\mathbb {E}\left[ F(x^s)-F^\star \right] \ge -\beta _s\Vert \lambda _2^\star \Vert \mathbb {E}\left[ \left\| \lambda ^{s+ 1}- \lambda ^s\right\| \right] ,\\&\mathbb {E}[{\text {dist}}(p_2(x^s), K)]\le \beta _s \mathbb {E}\left[ \left\| \lambda ^{s+ 1}- \lambda ^s\right\| \right] . \end{aligned}$$
By condition (a) in Assumption 1, we have for all \(s\ge 0\), \(\lambda _1^s\in {\text {dom}}(h_1^*)\) and \(\left\| \lambda _1^s\right\| \le L_{h_1}\) due to [9, Proposition 4.4.6]. Then using Corollary 1, the above bounds can be relaxed as:
$$\begin{aligned}&\mathbb {E}[ F(x^s)-F^\star ] \le \epsilon _s+ 2L_{h_1}^2 \beta _s +c_0\beta _s \\&\mathbb {E}[F(x^s)-F^\star ] \ge -\beta _s\Vert \lambda _2^\star \Vert \sqrt{c_0},\\&\mathbb {E}[{\text {dist}}(p_2(x^s), K)]\le \beta _s \sqrt{c_0}. \end{aligned}$$
We then conclude by noting that (32) guarantees
$$\begin{aligned} \max (\epsilon _0+ 2L_{h_1}^2 \beta _0 +c_0\beta _0, \beta _0\Vert \lambda _2^\star \Vert \sqrt{c_0}, \beta _0 \sqrt{c_0})\le \epsilon \rho ^{-s}. \end{aligned}$$
(103)
1.2 Proof of Proposition 1
This section is devoted to the proof of Proposition 1.
Lemma 11
For any \(x\in \mathbb {R}^n\), \(\lambda ,\lambda '\in \mathbb {R}^d\) and \(\beta ,\beta '\in \mathbb {R}_+\) we have,
$$\begin{aligned} \begin{aligned}&L(x;y,\lambda ,\beta )-L(x;y',\lambda ',\beta ')+\frac{\beta }{2}\Vert \varLambda (p(x); \lambda ,\beta )-\lambda \Vert ^2 \\&\qquad -\frac{\beta '}{2}\Vert \varLambda (p(x);\lambda ',\beta ')-\lambda '\Vert ^2\\&\quad \le \langle \varLambda (p(x);\lambda ,\beta )-\varLambda (p(x);\lambda ',\beta '), \beta '( \varLambda (p(x);\lambda ',\beta ')-\lambda ') \rangle \\&\qquad +\frac{\beta }{2}\Vert x-y\Vert ^2-\frac{\beta '}{2}\Vert x-y'\Vert ^2, \end{aligned} \end{aligned}$$
(104)
and
$$\begin{aligned} \begin{aligned}&L(x;y,\lambda ,\beta )-L(x;y',\lambda ',\beta ')+\frac{\beta }{2}\Vert \varLambda (p(x);\lambda ,\beta )-\lambda \Vert ^2\\&\qquad -\frac{\beta '}{2}\Vert \varLambda (p(x);\lambda ',\beta ')-\lambda '\Vert ^2\\&\quad \ge \langle \varLambda (p(x);\lambda ,\beta )-\varLambda (p(x);\lambda ',\beta '), \beta ( \varLambda (p(x);\lambda ,\beta )-\lambda ) \rangle \\&\qquad +\frac{\beta }{2}\Vert x-y\Vert ^2-\frac{\beta '}{2}\Vert x-y'\Vert ^2. \end{aligned} \end{aligned}$$
(105)
Proof
By the definitions (24), (16) and (17), we have
$$\begin{aligned}&L(x;y, \lambda ,\beta )-L(x;y',\lambda ',\beta ')+\frac{\beta }{2}\Vert \varLambda (p(x);\lambda ,\beta )-\lambda \Vert ^2-\frac{\beta '}{2}\Vert \varLambda (p(x);\lambda ',\beta ')-\lambda '\Vert ^2\\&\quad =\langle \varLambda (p(x);\lambda ,\beta )-\varLambda (p(x);\lambda ',\beta '), p(x) \rangle - h^*( \varLambda (p(x);\lambda ,\beta ))\\&\qquad + h^*( \varLambda (p(x);\lambda ',\beta '))+\frac{\beta }{2}\Vert x-y\Vert ^2-\frac{\beta '}{2}\Vert x-y'\Vert ^2. \end{aligned}$$
Next we apply (20) to get
$$\begin{aligned} h^*( \varLambda (p(x);\lambda ',\beta '))&\ge h^*( \varLambda (p(x);\lambda ,\beta ))\\&\quad +\langle \varLambda (p(x);\lambda ,\beta )-\varLambda (p(x);\lambda ',\beta ') ,\beta (\varLambda (p(x);\lambda , \beta )-\lambda )-p(x) \rangle , \end{aligned}$$
and
$$\begin{aligned} h^*( \varLambda (p(x);\lambda ,\beta ))&\ge h^*( \varLambda (p(x);\lambda ',\beta '))\\&\quad +\langle \varLambda (p(x);\lambda ,\beta )\\&-\varLambda (p(x);\lambda ',\beta ') ,p(x)-\beta '(\varLambda (p(x);\lambda ', \beta ')-\lambda ') \rangle . \end{aligned}$$
\(\square \)
Lemma 12
Consider any \(u, \lambda , \lambda '\in \mathbb {R}^d\) and \(\beta ,\beta '\in \mathbb {R}_+\). Condition (a) in Assumption 1 ensures:
$$\begin{aligned} \begin{aligned}&\Vert \beta (\varLambda (u;\lambda , \beta )-\lambda )-\beta '(\varLambda (u;\lambda ', \beta ')-\lambda ')\Vert \\&\qquad \le \sqrt{ ((\beta +\beta ')L_{h_1} + \Vert \beta \lambda _1-\beta '\lambda _1'\Vert )^2+\Vert \beta \lambda _2-\beta '\lambda _2'\Vert ^2}. \end{aligned} \end{aligned}$$
(106)
Proof
Denote
$$\begin{aligned} \varLambda _i(u_i;\lambda _i, \beta ):=\arg \max _{\xi _i}\left\{ \langle \xi _i, u_i \rangle -h_i^*(\xi _i)- \frac{\beta }{2}\Vert \xi _i-\lambda _i\Vert ^2 \right\} , i=1,2, \end{aligned}$$
(107)
so that \(\varLambda (u;\lambda , \beta )=\left( \varLambda _1(u_1;\lambda _1, \beta ); \varLambda _{2}(u_{2};\lambda _{2}, \beta )\right) \). We can then decompose (20) into two independent conditions:
$$\begin{aligned} \varLambda _i(u_i;\lambda _i,\beta )\in \partial h_i(u_i-\beta (\varLambda _i(u_i;\lambda _i, \beta )-\lambda _i)),i=1,2. \end{aligned}$$
(108)
By condition (a) in Assumption 1,
$$\begin{aligned} \Vert \varLambda _1(u_1;\lambda _1, \beta )\Vert \le L_{h_1} \end{aligned}$$
(109)
which yields directly
$$\begin{aligned} \Vert \beta (\varLambda _1(u_1;\lambda _1, \beta )-\lambda _1)-\beta '(\varLambda _1(u_1;\lambda _1', \beta ')-\lambda _1')\Vert \le (\beta +\beta ')L_{h_1}+\Vert \beta \lambda _1-\beta '\lambda _1'\Vert . \end{aligned}$$
(110)
On the other hand, since \(h_2\) is an indicator function, \(\partial h_2\) is a cone and (108) implies
$$\begin{aligned} \beta \varLambda _2(u_2;\lambda _2,\beta )\in \partial h_2(u_2-\beta (\varLambda _2(u_2;\lambda _2, \beta )-\lambda _2)). \end{aligned}$$
(111)
The latter condition further leads to
$$\begin{aligned}&\langle \beta \varLambda _2(u_2;\lambda _2,\beta )-\beta '\varLambda _2(u_2;\lambda '_2,\beta '),\beta (\varLambda _2(u_2;\lambda _2, \beta )-\lambda _2)\\&\quad -\beta '(\varLambda _2(u_2;\lambda _2', \beta ')-\lambda _2') \rangle \le 0, \end{aligned}$$
which by Cauchy-Schwartz inequality implies
$$\begin{aligned} \Vert \beta (\varLambda _2(u_2;\lambda _2,\beta )-\lambda _2)-\beta '(\varLambda _2(u_2;\lambda '_2,\beta ')-\lambda _2')\Vert \le \Vert \beta \lambda _2-\beta '\lambda _2'\Vert . \end{aligned}$$
Then (106) is obtained by simple algebra. \(\square \)
Remark 9
If
$$\begin{aligned} h(u)=\left\{ \begin{array}{ll}0 &{}\quad \mathrm {if~} u=b\\ +\infty &{} \quad \mathrm {otherwise } \end{array}\right. \end{aligned}$$
for some constant vector \(b\in \mathbb {R}^d\), then by (20) we have
$$\begin{aligned} u-\beta (\varLambda (u;\lambda , \beta )-\lambda )=b, \end{aligned}$$
for any \(u,\lambda \in \mathbb {R}^d\) and \(\beta \ge 0\). In this special case a refinement of Lemma 12 can be stated as follows:
$$\begin{aligned} \Vert \beta (\varLambda (u;\lambda , \beta )-\lambda )-\beta '(\varLambda (u;\lambda ', \beta ')-\lambda ')\Vert =0. \end{aligned}$$
Lemma 13
Consider any \(0<\beta /2<\beta '\) and any \(w,w',y,y'\in \mathbb {R}^n\). We have
$$\begin{aligned} \begin{aligned}&-\frac{\beta }{2}\Vert w'-w\Vert ^2+\frac{\beta }{2}\Vert w'-y\Vert ^2-\frac{\beta '}{2}\Vert w'-y'\Vert ^2\\&\qquad \le \frac{\beta }{2}\Vert w-y'\Vert ^2+ \frac{\beta (2\beta '+\beta )}{2(2\beta '-\beta )}\Vert y-y'\Vert ^2. \end{aligned} \end{aligned}$$
(112)
Proof
We first recall the following basic inequality:
$$\begin{aligned} \Vert u+v\Vert ^2\le (1+a)\Vert u\Vert ^2+(1+1/a)\Vert v\Vert ^2,\forall u,v\in \mathbb {R}^n, a>0. \end{aligned}$$
(113)
In view of (113) and the fact that \(\beta '>\beta /2\), we know that
$$\begin{aligned}&-\frac{\beta }{2}\Vert w'-w\Vert ^2\le \frac{\beta }{2}\Vert w-y'\Vert ^2-\frac{\beta }{4}\Vert w'-y'\Vert ^2,\\&-\frac{\beta '+\beta /2}{2}\Vert w'-y'\Vert ^2\le \frac{\beta (2\beta '+\beta )}{2(2\beta '-\beta )}\Vert y-y'\Vert ^2 -\frac{\beta }{2}\Vert w'-y\Vert ^2. \end{aligned}$$
Combining the latter two inequalities we get (112). \(\square \)
Using the above four lemmas, we establish a relation between \(L(x; y',\lambda ', \beta ') -L^\star (y',\lambda ',\beta ')\) and \(L(x; y, \lambda , \beta )-L^\star (y,\lambda ,\beta )\).
Proposition 4
For any \(x,y,y'\in \mathbb {R}^n\), \(\lambda ,\lambda '\in \mathbb {R}^d\) and \(0<\beta /2<\beta '\), we have
$$\begin{aligned}&L(x; y',\lambda ', \beta ') -L^\star (y',\lambda ',\beta ')- \left( L(x; y, \lambda , \beta )-L^\star (y,\lambda ,\beta )\right) \nonumber \\&\quad \le \Vert \lambda -\lambda '\Vert \sqrt{ ((\beta +\beta ')L_{h_1} + \Vert \beta \lambda _1-\beta '\lambda _1'\Vert )^2+\Vert \beta \lambda _2-\beta '\lambda _2'\Vert ^2}\nonumber \\&\qquad +{\beta }\Vert \lambda -\lambda '\Vert ^2+ \frac{\beta -\beta '}{2}\Vert \varLambda (p(x); \lambda ',\beta ')-\lambda '\Vert ^2\nonumber \\&\qquad +\frac{\beta '-\beta }{2}\Vert \varLambda (p^\star (y',\lambda ',\beta '); \lambda ,\beta )-\lambda \Vert ^2\nonumber \\&\qquad +\frac{ \beta }{2} \Vert \varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )-\varLambda (p(x);\lambda ,\beta )\Vert ^2\nonumber \\&\qquad +\frac{\beta }{2}\Vert x^\star (y,\lambda ,\beta )-y'\Vert ^2 +\frac{\beta (2\beta '+\beta )}{2(2\beta '-\beta )}\Vert y-y'\Vert ^2\nonumber \\&\qquad -\frac{\beta }{2}\Vert x-y\Vert ^2+\frac{\beta '}{2}\Vert x-y'\Vert ^2. \end{aligned}$$
(114)
Proof
We first separate \(L(x; y', \lambda ', \beta ') -L^\star (y',\lambda ',\beta ')\) into four parts:
$$\begin{aligned}&L(x; y',\lambda ', \beta ') -L^\star (y',\lambda ',\beta ')\\&\quad =\underbrace{L(x; y,\lambda , \beta )-L^\star (y,\lambda ,\beta )}_{\varDelta _1}+\underbrace{L(x;y', \lambda ', \beta ')-L(x; y,\lambda , \beta )}_{\varDelta _2}\\&\qquad +\underbrace{L(x^\star (y',\lambda ',\beta ');y, \lambda ,\beta ) -L^\star (y',\lambda ',\beta ')}_{\varDelta _3}\\&\quad +\underbrace{L^\star (y,\lambda ,\beta )-L(x^\star (y',\lambda ',\beta '); y,\lambda ,\beta )}_{\varDelta _4}. \end{aligned}$$
By Lemma 11,
$$\begin{aligned} \varDelta _2&\le \frac{\beta }{2}\Vert \varLambda (p(x);\lambda ,\beta )-\lambda \Vert ^2-\frac{\beta '}{2}\Vert \varLambda (p(x);\lambda ',\beta ')-\lambda '\Vert ^2-\frac{\beta }{2}\Vert x-y\Vert ^2\\&\quad +\frac{\beta '}{2}\Vert x-y'\Vert ^2+ \langle \varLambda (p(x);\lambda ',\beta ')-\varLambda (p(x);\lambda ,\beta ), \beta ( \varLambda (p(x);\lambda ,\beta )-\lambda ) \rangle , \end{aligned}$$
and
$$\begin{aligned} \varDelta _3&\le \frac{\beta '}{2}\Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta ')-\lambda '\Vert ^2-\frac{\beta }{2}\Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\lambda \Vert ^2\\&+ \langle \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta '),\\&\beta '( \varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta ')-\lambda ') \rangle \\&\quad +\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')-y\Vert ^2-\frac{\beta '}{2}\Vert x^\star (y',\lambda ',\beta ')-y'\Vert ^2. \end{aligned}$$
We then get
$$\begin{aligned} \varDelta _2+\varDelta _3&\le -\frac{\beta }{2}\Vert \varLambda (p(x);\lambda ,\beta )-\lambda \Vert ^2-\frac{\beta '}{2}\Vert \varLambda (p(x);\lambda ',\beta ')-\lambda '\Vert ^2\\&\quad + \langle \varLambda (p(x);\lambda ',\beta ') -\lambda ', \beta ( \varLambda (p(x);\lambda ,\beta )-\lambda ) \rangle \\&\quad -\frac{\beta '}{2}\Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta ')-\lambda '\Vert ^2\\&\quad -\frac{\beta }{2}\Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\lambda \Vert ^2\\&\quad + \langle \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\lambda , \beta '( \varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta ')-\lambda ') \rangle \\&\quad +\langle \lambda -\lambda ',\beta '( \varLambda (p^\star (y',\lambda ',\beta ');\lambda ', \beta ')-\lambda ') -\beta ( \varLambda (p(x);\lambda ,\beta )-\lambda ) \rangle \\&\quad -\frac{\beta }{2}\Vert x-y\Vert ^2+\frac{\beta '}{2}\Vert x-y'\Vert ^2 +\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')-y\Vert ^2\\&\quad -\frac{\beta '}{2}\Vert x^\star (y',\lambda ',\beta ')-y'\Vert ^2\\&\le \frac{\beta -\beta '}{2}\Vert \varLambda (p(x);\lambda ',\beta ') -\lambda '\Vert ^2+ \frac{\beta '-\beta }{2}\Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\lambda \Vert ^2\\&\quad +\langle \lambda -\lambda ',\beta '( \varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta ')-\lambda ') -\beta ( \varLambda (p(x);\lambda ,\beta )-\lambda ) \rangle \\&\quad -\frac{\beta }{2}\Vert x-y\Vert ^2+\frac{\beta '}{2}\Vert x-y'\Vert ^2+\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ') -y\Vert ^2\\&\quad -\frac{\beta '}{2}\Vert x^\star (y',\lambda ',\beta ')-y'\Vert ^2, \end{aligned}$$
where the last inequality simply relies on \(2\langle x,y \rangle \le \Vert x\Vert ^2+\Vert y\Vert ^2\). Further, according to Lemma 10,
$$\begin{aligned} \varDelta _4&\le -\frac{\beta }{2} \Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )- \varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )\Vert ^2\\&\quad -\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')- x^\star (y,\lambda ,\beta )\Vert ^2. \end{aligned}$$
Therefore,
$$\begin{aligned}&\varDelta _2+\varDelta _3+\varDelta _4 - \frac{\beta -\beta '}{2}\Vert \varLambda (p(x);\lambda ',\beta ') -\lambda '\Vert ^2- \frac{\beta '-\beta }{2}\Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\lambda \Vert ^2\nonumber \\&\quad \le \langle \lambda -\lambda ',\beta '( \varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta ')-\lambda ') -\beta ( \varLambda (p(x);\lambda ,\beta )-\lambda ) \rangle \nonumber \\&\qquad -\frac{\beta }{2} \Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )- \varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )\Vert ^2\nonumber \\&\qquad -\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')- x^\star (y,\lambda ,\beta )\Vert ^2-\frac{\beta }{2}\Vert x-y\Vert ^2+\frac{\beta '}{2}\Vert x-y'\Vert ^2\nonumber \\&\qquad +\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')-y\Vert ^2-\frac{\beta '}{2}\Vert x^\star (y',\lambda ',\beta ')-y'\Vert ^2\nonumber \\&\quad =\langle \lambda -\lambda ',\beta '( \varLambda (p^\star (y',\lambda ',\beta ');\lambda ',\beta ')-\lambda ') -\beta ( \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\lambda ) \rangle \nonumber \\&\qquad +\beta \langle \lambda -\lambda ',\varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )-\varLambda (p(x);\lambda ,\beta ) \rangle \nonumber \\&\qquad +\beta \langle \lambda -\lambda ', \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )-\varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta ) \rangle \nonumber \\&\qquad -\frac{\beta }{2} \Vert \varLambda (p^\star (y',\lambda ',\beta ');\lambda ,\beta )- \varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )\Vert ^2\nonumber \\&\qquad -\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')- x^\star (y,\lambda ,\beta )\Vert ^2-\frac{\beta }{2}\Vert x-y\Vert ^2+\frac{\beta '}{2}\Vert x-y'\Vert ^2\nonumber \\&\qquad +\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')-y\Vert ^2-\frac{\beta '}{2}\Vert x^\star (y',\lambda ',\beta ')-y'\Vert ^2\nonumber \\&\quad \le \Vert \lambda -\lambda '\Vert \sqrt{ ((\beta +\beta ')L_{h_1} + \Vert \beta \lambda _1-\beta '\lambda _1'\Vert )^2+\Vert \beta \lambda _2-\beta '\lambda _2'\Vert ^2}+{\beta }\Vert \lambda -\lambda '\Vert ^2 \nonumber \\&\qquad +\frac{ \beta }{2} \Vert \varLambda (p^\star (y,\lambda ,\beta );\lambda ,\beta )-\varLambda (p(x);\lambda ,\beta )\Vert ^2-\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')- x^\star (y,\lambda ,\beta )\Vert ^2\nonumber \\&\qquad -\frac{\beta }{2}\Vert x-y\Vert ^2+\frac{\beta '}{2}\Vert x-y'\Vert ^2+\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')-y\Vert ^2 -\frac{\beta '}{2}\Vert x^\star (y',\lambda ',\beta ')-y'\Vert ^2, \end{aligned}$$
(115)
where the last inequality follows from Lemma 12 and Cauchy Schwartz inequality. Now we apply Lemma 13 with \(w=x^\star (y,\lambda ,\beta )\) and \(w'=x^\star (y',\lambda ',\beta ')\) to obtain:
$$\begin{aligned}&-\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')-x^\star (y,\lambda ,\beta )\Vert ^2+\frac{\beta }{2}\Vert x^\star (y',\lambda ',\beta ')\nonumber \\&\quad -y\Vert ^2-\frac{\beta '}{2}\Vert x^\star (y',\lambda ',\beta ')-y'\Vert ^2\nonumber \\&\quad \le \frac{\beta }{2}\Vert x^\star (y,\lambda ,\beta )-y'\Vert ^2+ \frac{\beta (2\beta '+\beta )}{2(2\beta '-\beta )}\Vert y-y'\Vert ^2. \end{aligned}$$
(116)
Plugging (116) into (115) with we derive (114). \(\square \)
Now we are ready to give a proof for Proposition 1.
Proof of Proposition 1
We apply Proposition 4 with \(\lambda =\lambda ^s\), \(\lambda '=\lambda ^{s+1}\), \(\beta =\beta _s\), \(\beta '=\beta _{s+1}\), \(x=x^s\), \(y=x^{s-1}\) and \(y'=x^s\) to obtain
$$\begin{aligned}&H_{s+1}(x^s) -H_{s+1}^\star -\left( H_{s}(x^s) -H_{s}^\star \right) \\&\quad \le \Vert \lambda ^s-\lambda ^{s+1}\Vert \sqrt{ \left( (\beta _s+\beta _{s+1})L_{h_1}+\Vert \beta _s \lambda _1^s-\beta _{s+1}\lambda _1^{s+1}\Vert \right) ^2 +\Vert \beta _s \lambda _2^s-\beta _{s+1}\lambda _2^{s+1}\Vert ^2 }\\&\qquad +{\beta _s}\Vert \lambda ^s-\lambda ^{s+1}\Vert ^2+ \frac{\beta _s-\beta _{s+1}}{2}\Vert \varLambda (p(x^s); \lambda ^{s+1},\beta ^{s+1})-\lambda ^{s+1}\Vert ^2\\&\qquad + \frac{\beta _{s+1}-\beta _s}{2}\Vert \varLambda (p^\star (x^s,\lambda ^{s+1},\beta _{s+1}); \lambda ^s,\beta _s)-\lambda ^s\Vert ^2\\&\qquad +\frac{ \beta _s}{2} \Vert \varLambda (p^\star (x^{s-1},\lambda ^s,\beta _s);\lambda ^s,\beta _s) -\varLambda (p(x^s);\lambda ^{s},\beta _s)\Vert ^2\\&\qquad +\frac{\beta _s}{2}\Vert x^\star (x^{s-1},\lambda ^s,\beta _s)-x^s\Vert ^2+ \frac{\beta _s(2\beta _{s+1}+\beta _s)}{2(2\beta _{s+1}-\beta _s)}\Vert x^{s-1}-x^s\Vert ^2 -\frac{\beta _s}{2}\Vert x^s-x^{s-1}\Vert ^2. \end{aligned}$$
We apply Lemma 10 with \(x=x^s\), \(y=x^{s-1}\), \(\lambda =\lambda ^s\) and \(\beta =\beta _s\) and get:
$$\begin{aligned}&\frac{ \beta _s}{2} \Vert \varLambda (p^\star (x^{s-1},\lambda ^s,\beta _s);\lambda ^s,\beta _s)-\varLambda (p(x^s);\lambda ^{s},\beta _s)\Vert ^2+\frac{\beta _s}{2}\Vert x^\star (x^{s-1},\lambda ^s,\beta _s)-x^s\Vert ^2\\&\quad \le H_{s}(x^s) -H_{s}^\star . \end{aligned}$$
Furthermore, since \(\beta _{s+1}\le \beta _s\) we have,
$$\begin{aligned} \frac{\beta _{s+1}-\beta _s}{2}\Vert \varLambda (p^\star (x^s,\lambda ^{s+1},\beta _s); \lambda ^s,\beta _s)-\lambda ^s\Vert ^2\le 0. \end{aligned}$$
We then derive (34) by the latter three bounds.
Remark 10
If
$$\begin{aligned} h(u)=\left\{ \begin{array}{ll}0 &{}\quad \mathrm {if } u=b\\ +\infty &{} \quad \mathrm {otherwise } \end{array}\right. \end{aligned}$$
for some constant vector \(b\in \mathbb {R}^d\), for the reason stated in Remark 9, the number of inner iterations \(m_{s+1}\) in Algorithm 2 can be taken as the smallest integer satisfying
$$\begin{aligned}&2\epsilon _s+{{\beta _s}}\Vert \lambda ^{s+1}-\lambda ^{s}\Vert ^2 \frac{\beta _s-\beta _{s+1}}{2}\Vert \varLambda (p(x^s); \lambda ^{s+1},\beta _{s+1})-\lambda ^{s+1}\Vert ^2+ \frac{\beta _s^2}{2\beta _{s+1}-\beta _s}\Vert x^{s-1}-x^s\Vert ^2 \\&\le {2^{\lfloor m_{s+1}/ K_{s+1}\rfloor }} {\epsilon _{s+1}/2 } . \end{aligned}$$
1.3 Proofs in Section 3.1
Proof of Corollary 3
By (36), we have
$$\begin{aligned} \mathbb {E}\left[ H_{s+1}\left( x^{s+1}\right) -H_{s+1}^\star |{\mathcal {F}}_s\right] \le {2^{-\lfloor m_{s+1}/K_{s+1}\rfloor }} \left( H_{s+1}(x^s)-H_{s+1}^\star \right) . \end{aligned}$$
Then we apply Proposition 1 and obtain
$$\begin{aligned} \begin{array}{ll} \mathbb {E}\left[ H_{s+1}\left( x^{s+1}\right) -H_{s+1}^\star | {\mathcal {F}}_s \right] &{}\le {2^{1-\lfloor m_{s+1}/K_{s+1}\rfloor }} \left( H_{s}(x^s)-H_{s}^\star \right) \\ {} &{} \quad + {2^{-\lfloor m_{s+1}/K_{s+1}\rfloor }} M_s . \end{array} \end{aligned}$$
(117)
If (38) holds, then
$$\begin{aligned} {2^{-\lfloor m_{s+1}/K_{s+1}\rfloor }} \le \frac{\epsilon _{s+1}}{4\epsilon _s}, {2^{-\lfloor m_{s+1}/K_{s+1}\rfloor }} M_s\le \frac{\epsilon _{s+1}}{2}. \end{aligned}$$
It follows that
$$\begin{aligned} \mathbb {E}\left[ H_{s+1}\left( x^{s+1}\right) -H_{s+1}^\star | {\mathcal {F}}_s\right] \le \frac{\epsilon _{s+1}}{2\epsilon _s} \left( H_{s}(x^s)-H_{s}^\star \right) + \frac{\epsilon _{s+1}}{2}. \end{aligned}$$
Then (39) is guaranteed by taking expectation on both sides of the last inequality.
1.4 Proofs in Section 3.2
Proof of Lemma 4
We first bound
$$\begin{aligned}&\mathbb {E}[ \left( (\beta _s+\beta _{s+1})L_{h_1}+\Vert \beta _s \lambda _1^s-\beta _{s+1}\lambda _1^{s+1}\Vert \right) ^2 +\Vert \beta _s \lambda _2^s-\beta _{s+1}\lambda _2^{s+1}\Vert ^2 ]\\&\quad \le 2(\beta _s+\beta _{s+1})^2 L^2_{h_1}+2\mathbb {E}[ \Vert \beta _s \lambda ^s-\beta _{s+1}\lambda ^{s+1}\Vert ^2]\\&\quad \le 2(\beta _s+\beta _{s+1})^2 L^2_{h_1}+4(\beta _s^2+\beta _{s+1}^2) c\\&\quad \le 4(\beta _s^2+\beta _{s+1}^2)(L^2_{h_1}+c). \end{aligned}$$
Since
$$\begin{aligned} \lambda ^{s+1}=\varLambda (p(x^s);\lambda ^{s},\beta _{s}), \end{aligned}$$
by Lemma 12 we have
$$\begin{aligned}&\Vert \beta _{s+1}\left( \varLambda (p(x^s);\lambda ^{s+1},\beta _{s+1})-\lambda ^{s+1}\right) -\beta _s(\lambda ^{s+1}-\lambda ^{s})\Vert \end{aligned}$$
(118)
$$\begin{aligned}&\quad \le \sqrt{ \left( (\beta _s+\beta _{s+1})L_{h_1}+\Vert \beta _s \lambda _1^s-\beta _{s+1}\lambda _1^{s+1}\Vert \right) ^2 +\Vert \beta _s \lambda _2^s-\beta _{s+1}\lambda _2^{s+1}\Vert ^2 }. \end{aligned}$$
(119)
Therefore,
$$\begin{aligned}&\Vert \varLambda (p(x^s);\lambda ^{s+1},\beta _{s+1})-\lambda ^{s+1}\Vert \\&\quad \le \beta _{s+1}^{-1} \beta _s \Vert \lambda ^{s+1}-\lambda ^s\Vert \\&\qquad + \beta _{s+1}^{-1}\sqrt{ \left( (\beta _s+\beta _{s+1})L_{h_1}+\Vert \beta _s \lambda _1^s-\beta _{s+1}\lambda _1^{s+1}\Vert \right) ^2 +\Vert \beta _s \lambda _2^s-\beta _{s+1}\lambda _2^{s+1}\Vert ^2 }. \end{aligned}$$
If follows that
$$\begin{aligned}&\mathbb {E}[ \Vert \varLambda (p(x^s);\lambda ^{s+1},\beta _{s+1})-\lambda ^{s+1}\Vert ^2]\le 2 \beta _{s+1}^{-2} \beta ^2_s c+8\beta _{s+1}^{-2 } (\beta _s^2+\beta _{s+1}^2)(L^2_{h_1}+c) \end{aligned}$$
(120)
By \(\mathbb {E}[XY]\le (\mathbb {E}[X^2])^{1/2}(\mathbb {E}[Y^2])^{1/2}\), we get
$$\begin{aligned} \begin{aligned}&\mathbb {E}\left[ \Vert \lambda ^{s+1}-\lambda ^{s}\Vert \sqrt{ \left( (\beta _s+\beta _{s+1})L_{h_1}+\Vert \beta _s \lambda _1^s-\beta _{s+1}\lambda _1^{s+1}\Vert \right) ^2 +\Vert \beta _s \lambda _2^s-\beta _{s+1}\lambda _2^{s+1}\Vert ^2 }\right] \\&\quad \le \sqrt{4c(\beta _s^2+\beta _{s+1}^2)(L^2_{h_1}+c)}. \end{aligned} \end{aligned}$$
(121)
Combining (44), (120) and (121), we then get an upper bound for \(\mathbb {E}[M_{s}]\):
$$\begin{aligned} \begin{array}{ll} \mathbb {E}[M_{s+1}]&{}\le {{\beta _s}}c+ \frac{\beta _s-\beta _{s+1}}{2}\left( 2 \beta _{s+1}^{-2} \beta ^2_s c+8\beta _{s+1}^{-2 } (\beta _s^2+\beta _{s+1}^2)(L^2_{h_1}+c)\right) \\ &{}\quad + \frac{\beta _s^2}{2\beta _{s+1}-\beta _s}c + \sqrt{4c(\beta _s^2+\beta _{s+1}^2)(L^2_{h_1}+c)} \\ &{}\le {{\beta _s}}c+ \beta _s\left( \beta _{s+1}^{-2} \beta ^2_s c+4\beta _{s+1}^{-2 } (\beta _s^2+\beta _{s+1}^2)(L^2_{h_1}+c)\right) \\ &{} \quad + \frac{\beta _s^2}{2\beta _{s+1}-\beta _s}c + 2 \beta _s \sqrt{c(1+\beta _{s+1}^2\beta _s^{-2})(L^2_{h_1}+c)} \\ &{} \le 2{{\beta _s}}c + \beta _s\left( \beta _{s+1}^{-2} \beta ^2_s c+(5+4\beta _{s+1}^{-2 } \beta _s^2+\beta _{s+1}^2 \beta _s^{-2})(L^2_{h_1}+c)\right) + \frac{\beta _s^2}{2\beta _{s+1}-\beta _s}c \end{array}, \end{aligned}$$
where the last inequality used \(2\sqrt{ab}\le a+b \) for any \(a,b>0\). Next we plug in \(\beta _s=\beta _0\rho ^s\) to obtain
$$\begin{aligned} \mathbb {E}[M_s]&\le \beta _s \left( 2c+\rho ^{-2}c+(9+\rho ^{-2})(L^2_{h_1}+c)+(2\rho -1)^{-1}c\right) \\&\le \beta _s \left( (11+2\rho ^{-2})(L^2_{h_1}+c)+(2\rho -1)^{-1}c\right) . \end{aligned}$$
Proof of Proposition 2
Since Algorithm 2 is a special case of Algorithm 1 with \(\beta _s=\beta _0 \rho ^s\) and \(\epsilon _s=\epsilon _0 \eta ^s\), we know from Corollary 1 that (44) holds with \(c=4c_0\). Applying Lemma 4 we know that
$$\begin{aligned} \mathbb {E}[M_s]\le C\beta _s , \end{aligned}$$
with \(C=(11+2\rho ^{-2})(L^2_{h_1}+4c_0)+4(2\rho -1)^{-1}c_0\). If \(m_{s+1}\) is the smallest integer satisfying (38), then
$$\begin{aligned} m_{s+1}\le K_{s+1}\left( \log _2 \left( 4\epsilon _s \epsilon ^{-1}_{s+1} + 2M_s \epsilon ^{-1}_{s+1}\right) +1\right) +1. \end{aligned}$$
(122)
By the concavity of \(\log _2\) function we get
$$\begin{aligned} \mathbb {E}[m_{s+1}]&\le K_{s+1}\left( \log _2 \left( 4\epsilon _s \epsilon ^{-1}_{s+1} + 2C\beta _s \epsilon ^{-1}_{s+1}\right) +1\right) +1 \\&=K_{s+1}\left( \log _2 \left( 4 \eta ^{-1} + 2C\beta _0 \epsilon _0^{-1}\eta ^{-1}\rho ^s\eta ^{-s}\right) +1\right) +1. \end{aligned}$$
Since \(\rho >\eta \), we get
$$\begin{aligned} \mathbb {E}[m_{s+1}]&\le K_{s+1}\left( \log _2 \left( \left( 4 \eta ^{-1} + 2C\beta _0 \epsilon _0^{-1}\eta ^{-1}\right) \rho ^s\eta ^{-s}\right) +1\right) +1\\ {}&=K_{s+1}\left( \log _2 \left( 4 \eta ^{-1} + 2C\beta _0 \epsilon _0^{-1}\eta ^{-1}\right) +1+\log _2 \left( \rho ^s\eta ^{-s}\right) \right) +1\\&=K_{s+1}\left( s\log _2\left( \rho \eta ^{-1}\right) +c_2\right) + 1. \end{aligned}$$
Proof of Theorem 2
By Corollary 2, (48) holds if
$$\begin{aligned} s\ge \frac{\ln (c_1/\epsilon )}{\ln (1/\rho )}. \end{aligned}$$
Thus (48) is true for some integer s satisfying
$$\begin{aligned} s\le \frac{\ln (c_1/\epsilon )}{\ln (1/\rho )}+1=\frac{\ln (c_1/(\epsilon \rho ))}{\ln (1/\rho )}. \end{aligned}$$
(123)
Since \(\epsilon \le \epsilon _0\), we know that \(\epsilon \le c_1\) and
$$\begin{aligned} s\le \frac{\ln (c_1/(\epsilon \rho ))}{\ln (1/\rho )}=\frac{\ln (c^\ell _1/(\epsilon ^\ell \rho ^\ell ))}{\ell \ln (1/\rho )}\le \frac{c^\ell _1}{\epsilon ^\ell \rho ^\ell \ell \ln (1/\rho )}, \end{aligned}$$
(124)
where in the last inequality we used \(\ln a\le a\) for any \(a\ge 1\). In view of (47), we have
$$\begin{aligned} \sum _{t=1}^s K_t&\le \varsigma s+\frac{\omega }{\beta _0^\ell } \sum _{t=1}^s \rho ^{-\ell t}\le \varsigma s+\frac{\omega \rho ^{-\ell (s+1)}}{\beta _0^\ell (\rho ^{-\ell }-1)} \overset{(123)}{\le } \varsigma s+ \frac{\omega c_1^\ell }{\beta _0^\ell (1-\rho ^\ell )\rho ^\ell \epsilon ^\ell }\\&\overset{(124)}{\le } \left( \frac{ \varsigma c^\ell _1}{\rho ^\ell \ell \ln (1/\rho )}+ \frac{\omega c_1^\ell }{\beta _0^\ell (1-\rho ^\ell )\rho ^\ell } \right) \frac{1}{\epsilon ^\ell }. \end{aligned}$$
Then we apply Proposition 2 to obtain
$$\begin{aligned} \sum _{t=1}^s \mathbb {E}[m_t]&\le s \left( 1+\log _2({\rho }/{\eta })+c_2\right) \left( \frac{ \varsigma c^\ell _1}{\rho ^\ell \ell \ln (1/\rho )}+ \frac{\omega c_1^\ell }{\beta _0^\ell (1-\rho ^\ell )\rho ^\ell } \right) \frac{1}{\epsilon ^\ell } \\&\!\!\overset{(123)}{\le } \frac{1+\log _2({\rho }/{\eta })+c_2}{\ln (1/\rho )}\left( \frac{ \varsigma c^\ell _1}{\rho ^\ell \ell \ln (1/\rho )}+ \frac{\omega c_1^\ell }{\beta _0^\ell (1-\rho ^\ell )\rho ^\ell } \right) \frac{1}{\epsilon ^\ell }\ln \frac{c_1}{\epsilon \rho }. \end{aligned}$$
1.5 Proof in Section 5.1
Proof of Corollary 5
If \(K_s\) satisfies (62), then
$$\begin{aligned} K_s\le 2\sqrt{\frac{2(L\beta _0+\Vert A\Vert ^2)}{\mu _g\beta _s+\beta ^2_s}}+1\le \left\{ \begin{array}{ll} \frac{2\sqrt{2(L\beta _0+\Vert A\Vert ^2)/\mu _g}}{ \sqrt{\beta _s}}+1 &{} \mathrm {if} ~\mu _g>0 \\ \frac{2\sqrt{2(L\beta _0+\Vert A\Vert ^2)}}{{\beta _s}}+1 &{} \mathrm {if} ~\mu _g=0 \end{array}\right. \end{aligned}$$
We then apply Corollary 4.
The proof of Corollary 6 and 7 are similar.
1.6 Proofs in Section 5.2
We first state a useful Lemma.
Lemma 14
For any \(u,\lambda \in \mathbb {R}^d\), \(\beta >0\),
$$\begin{aligned} \Vert \varLambda (u;\lambda ,\beta )\Vert \le L_{h_1}+ \beta ^{-1}{\text {dist}}(u_2+\beta \lambda _2, {\mathcal {K}}) \end{aligned}$$
(125)
Proof
From (21),
$$\begin{aligned}&h(u;\lambda ,\beta )=\min _z\left\{ h(z)+\frac{1}{2\beta }\Vert u+\beta \lambda -z\Vert ^2-\frac{\beta }{2}\Vert \lambda \Vert ^2 \right\} \end{aligned}$$
(126)
with optimal solution
$$\begin{aligned} z^\star =u+\beta \lambda -\beta \varLambda (u;\lambda ,\beta ). \end{aligned}$$
In particular, \({\text {dist}}(u_2+\beta \lambda _2, {\mathcal {K}})^2=\beta ^2\Vert \varLambda _2(u_2;\lambda _2,\beta )\Vert ^2\). Together with (109) we obtain the desired bound. \(\square \)
Proof of Lemma 5
$$\begin{aligned}&\Vert \nabla p(x) \varLambda (p(x);\lambda ^s,\beta _s)-\nabla p(y) \varLambda (p(y);\lambda ^s,\beta _s) \Vert \\&\quad \le \Vert \nabla p(x)-\nabla p(y)\Vert \Vert \varLambda (p(x);\lambda ^s,\beta _s)\Vert +\Vert \nabla p(y)\Vert \Vert \varLambda (p(x);\lambda ^s,\beta _s)\\&\qquad -\varLambda (p(y);\lambda ^s,\beta _s) \Vert \\&\quad \overset{(125)+(19)}{\le } L_{\nabla p} \Vert x-y\Vert \left( L_{h_1}+ \beta _s^{-1}{\text {dist}}(p_2(x)+\beta _s\lambda ^s_2, {\mathcal {K}})\right) \\&\qquad + M_{\nabla p}\Vert p(x)-p(y)\Vert \beta _s^{-1}\\&\quad \le \left( L_{\nabla p} \left( L_{h_1}+ \beta _s^{-1}{\text {dist}}(p_2(x)+\beta _s\lambda ^s_2, {\mathcal {K}})\right) + M^2_{\nabla p}\beta _s^{-1}\right) \Vert x-y\Vert . \end{aligned}$$
Note that by (74) and the definition of \(d_s\),
$$\begin{aligned} {\text {dist}}(p_2(x)+\beta _s\lambda _2^s, {\mathcal {K}})\le d_s. \end{aligned}$$
1.7 Proofs in Section 6.2
Proof of Theorem 3
We know from the basic property of proximal gradient step [32] that
$$\begin{aligned} \Vert x^{s} -{\tilde{x}}^s\Vert ^2 \le 2\left( H_s(\tilde{x}^s)-H_s^\star \right) /L_{s}. \end{aligned}$$
By Line 4 in Algorithm 3,
$$\begin{aligned} 0\in \nabla \phi _s({\tilde{x}}^s)+L_{s}(x^s-{\tilde{x}}^s)+{\beta _s}( x^s-x^{s-1})+\partial g(x^s). \end{aligned}$$
Therefore,
$$\begin{aligned}&{\text {dist}}(0, \nabla \phi _s( x^s)+\partial g(x^s))\\ {}&\quad \le L_{s} \Vert \tilde{x}^s-x^s\Vert +\Vert \nabla \phi _s(x^s)-\nabla \phi _s({\tilde{x}}^s)\Vert +\beta _s \Vert x^s-x^{s-1} \Vert \\&\quad \le 2L_{s}\Vert {\tilde{x}}^s-x^s\Vert +\beta _s \Vert x^s-x^{s-1} \Vert \end{aligned}$$
Combining the last two bounds and (18) we get \(\nabla \phi _s( x^s)= \nabla f( x^s)+\nabla p(x^s) \lambda ^{s+1}\) and
$$\begin{aligned} {\text {dist}}(0, \nabla f( x^s)+\nabla p(x^s) \lambda ^{s+1}+\partial g( x^{s}))^2\le 16 L_{s} \left( H_s(\tilde{x}^s)-H_s^\star \right) +2\beta _s^2\Vert x^s-x^{s-1}\Vert ^2. \end{aligned}$$
Secondly we know from (20) that
$$\begin{aligned} p(x^s)-\beta _s(\lambda ^{s+1}-\lambda ^s)\in \partial h^*(\lambda ^{s+1}). \end{aligned}$$
It follows that
$$\begin{aligned} {\text {dist}}(0, p(x^s)-\partial h^*(\lambda ^{s+1}))\le \beta _s \Vert \lambda ^{s+1}-\lambda ^s\Vert . \end{aligned}$$
Proof of Corollary 9
Due to (82), we can have the same bound (in expectation) of the sequence \(\{({\tilde{x}}^s, x^s, \lambda ^s)\}\) as Corollary 1. Hence,
$$\begin{aligned}&\mathbb {E}\left[ {\text {dist}}(0,\partial _x L(x^s, \lambda ^{s+1})) \right] \le \sqrt{16 L_{s}\epsilon _s+8c_0\beta _s^2}\le \sqrt{16\gamma \epsilon _0/\beta _0+8c_0\beta _0}\rho ^s,\\&\mathbb {E}\left[ {\text {dist}}(0,\partial _{\lambda }L(x^s, \lambda ^{s+1})) \right] \le \beta _0\sqrt{c_0} \rho ^s. \end{aligned}$$