
Abstract
The optimal parameter values in a feed-forward neural network model play an important role in determining the efficiency and significance of the trained model. In this paper, we propose an upgraded artificial electric field algorithm (AEFA) for training feed-forward neural network models. This paper also throws some light on the effective use of multi-agent meta-heuristic techniques for the training of neural network models and their future prospects. Seven real-life data sets are used to train neural network models, the results of these trained models show that the proposed scheme performs well in comparison to other training algorithms in terms of high classification accuracy and minimum test error values including gradient-based algorithms and differential evolution variants. Some fundamental modifications in AEFA are also proposed to make it more suitable for training neural networks. All the experimental findings show that the search capabilities and convergence rate of the proposed scheme are better than those of other capable schemes, including gradient-based schemes.























Similar content being viewed by others
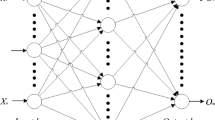
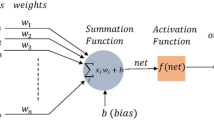
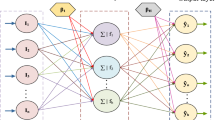
Data availibility
This work does not include any generated data. For Case study data available with UCI Machine learning repository.
References
Agahian S, Akan T (2022) Battle royale optimizer for training multi-layer perceptron. Evol Syst 13(4):563–575
Aggarwal CC et al (2018) Neural networks and deep learning. Springer, New York, pp 978–983
Agnes Lydia, Sagayaraj Francis (2019) Adagrad-an optimizer for stochastic gradient descent. Int J Inf Comput Sci 6(5):566–568
Ali Khosravi, Sanna Syri (2020) Modeling of geothermal power system equipped with absorption refrigeration and solar energy using multilayer perceptron neural network optimized with imperialist competitive algorithm. J Clean Prod 276:124216
Alireza Askarzadeh (2016) A novel metaheuristic method for solving constrained engineering optimization problems: crow search algorithm. Comput Struct 169:1–12
Altay O, Altay EV (2023) A novel hybrid multilayer perceptron neural network with improved grey wolf optimizer. Neural Comput Appl 35(1):529–556
Anita, Yadav A (2019) Aefa: artificial electric field algorithm for global optimization. Swarm Evol Comput 48:93–108
Anita, Yadav A (2020) Discrete artificial electric field algorithm for high-order graph matching. Appl Soft Comput 92:106260
Anupam Yadav, Nitin Kumar et al (2020) Artificial electric field algorithm for engineering optimization problems. Expert Syst Appl 149:113308
Arjen Van Ooyen, Bernard Nienhuis (1992) Improving the convergence of the back-propagation algorithm. Neural Netw 5(3):465–471
Baoxian Liang, Yunlong Zhao, Yang Li (2021) A hybrid particle swarm optimization with crisscross learning strategy. Eng Appl Artif Intell 105:104418
Blake CL (1998) UCI repository of machine learning databases. http://www.ics.uci.edu/~mlearn/MLRepository.html
Blum C, Socha K (2005) Training feed-forward neural networks with ant colony optimization: An application to pattern classification. In Fifth International Conference on Hybrid Intelligent Systems (HIS’05), IEEE. p. 6
Bohat VK, Arya KV (2018) An effective gbest-guided gravitational search algorithm for real-parameter optimization and its application in training of feedforward neural networks. Knowl-Based Syst 143:192–207
Chauhan D, Yadav A (2022a) Binary artificial electric field algorithm. Evol Intel. https://doi.org/10.1007/s12065-022-00726-x
Chauhan D, Yadav A (2022b) Xor-based binary aefa: Theoretical studies and applications. In 2022 IEEE Symposium Series on Computational Intelligence (SSCI), IEEE. p. 1706–1713
Chauhan D, Yadav A (2023a) Optimizing the parameters of hybrid active power filters through a comprehensive and dynamic multi-swarm gravitational search algorithm. Eng Appl Artif Intell 123:106469
Chauhan D, Yadav A (2023b) An adaptive artificial electric field algorithm for continuous optimization problems. Expert Syst e13380. https://doi.org/10.1111/exsy.13380
De Souto MCP, Costa IG, de Araujo DSA, Ludermir TB, Schliep A (2008) Clustering cancer gene expression data: a comparative study. BMC Bioinformatics 9(1):1–14
Deo RC, Ghorbani MA, Samadianfard S, Maraseni T, Bilgili M, Biazar M (2018) Multi-layer perceptron hybrid model integrated with the firefly optimizer algorithm for windspeed prediction of target site using a limited set of neighboring reference station data. Renew Energy 116:309–323
Diederik K, Jimmy B (2014) Adam: a method for stochastic optimization, pp 273–297. arXiv preprint arXiv:1412.6980
ElSaid A, Jamiy FE, Higgins J, Wild B, Desell T (2018) Optimizing long short-term memory recurrent neural networks using ant colony optimization to predict turbine engine vibration. Appl Soft Comput 73:969–991
Esmat Rashedi, Hossein Nezamabadi-Pour, Saeid Saryazdi (2009) Gsa: a gravitational search algorithm. Inf Sci 179(13):2232–2248
Fahlman SE et al (1988) An empirical study of learning speed in back-propagation networks. Computer Science Department. Carnegie Mellon University, Pittsburgh
Fine TL (1999) Algorithms for designing feedforward networks. Springer, Berlin
García-Ródenas R, Linares LJ, López-Gómez JA (2021) Memetic algorithms for training feedforward neural networks: an approach based on gravitational search algorithm. Neural Comput Appl 33(7):2561–2588
Gardner MW, Dorling SR (1998) Artificial neural networks (the multilayer perceptron)-a review of applications in the atmospheric sciences. Atmos Environ 32(14–15):2627–2636
Gudise VG, Venayagamoorthy GK (2003) Comparison of particle swarm optimization and backpropagation as training algorithms for neural networks. In Proceedings of the 2003 IEEE Swarm Intelligence Symposium. SIS’03 (Cat. No. 03EX706) IEEE. p. 110–117
Guo ZX, Wong WK, Li M (2012) Sparsely connected neural network-based time series forecasting. Inf Sci 193:54–71
Hertz J, Krogh A, Palmer RG (2018) Introduction to the theory of neural computation. CRC Press, New York
Hossam Faris, Ibrahim Aljarah, Seyedali Mirjalili (2016) Training feedforward neural networks using multi-verse optimizer for binary classification problems. Appl Intell 45(2):322–332
Houssein EH, Helmy BE-D, Elngar AA, Abdelminaam DS, Shaban H (2021) An improved tunicate swarm algorithm for global optimization and image segmentation. IEEE Access 9:56066–56092
Ibrahim Aljarah, Hossam Faris, Seyedali Mirjalili (2018) Optimizing connection weights in neural networks using the whale optimization algorithm. Soft Comput 22(1):1–15
Jianbo Yu, Shijin Wang, Lifeng Xi (2008) Evolving artificial neural networks using an improved pso and dpso. Neurocomputing 71(4–6):1054–1060
Jihoon Yang, Vasant Honavar (1998) Feature subset selection using a genetic algorithm. IEEE Intell Syst Appl 13(2):44–49
Kennedy J, Eberhart R (1995) Particle swarm optimization. In Proceedings of ICNN’95-international conference on neural networks, IEEE volume 4. p. 1942–1948
Khishe M, Mosavi MR (2020) Chimp optimization algorithm. Expert Syst Appl 149:113338
Le HL, Neri F, Triguero I (2022) Spms-als: a single-point memetic structure with accelerated local search for instance reduction. Swarm Evol Comput 69:100991
Lee Y, Oh S-H, Kim MW (1993) An analysis of premature saturation in back propagation learning. Neural Netw 6(5):719–728
Leung FH-F, Lam H-K, Ling S-H, Tam PK-S (2003) Tuning of the structure and parameters of a neural network using an improved genetic algorithm. IEEE Trans Neural Netw 14(1):79–88
Liang JJ, Qu BY, Suganthan PN (2013) Problem definitions and evaluation criteria for the cec 2014 special session and competition on single objective real-parameter numerical optimization. Computational Intelligence Laboratory, Zhengzhou University, Zhengzhou China and Technical Report, Nanyang Technological University, Singapore, p 490
Mangasarian OL, Wolberg WH (1990) Cancer diagnosis via linear programming. SIAM News 23:1–18
Mirjalili S (2015) How effective is the grey wolf optimizer in training multi-layer perceptrons. Appl Intell 43(1):150–161
Mirjalili S, Gandomi AH (2017) Chaotic gravitational constants for the gravitational search algorithm. Appl Soft Comput 53:407–419
Mirjalili S, Hashim SZM (2012) Sardroudi HM Training feedforward neural networks using hybrid particle swarm optimization and gravitational search algorithm. Appl Math Comput 218(22):11125–11137
Mirjalili SM, Abedi K, Mirjalili S (2013) Optical buffer performance enhancement using particle swarm optimization in ring-shape-hole photonic crystal waveguide. Optik 124(23):5989–5993
Mirjalili S, Mirjalili SM, Lewis A (2014) Let a biogeography-based optimizer train your multi-layer perceptron. Inf Sci 269:188–209
Mirjalili S, Mirjalili SM, Lewis A (2014) Grey wolf optimizer. Adv Eng Softw 69:46–61
Nguyen H, Moayedi H, Foong LK, Najjar HAHA, Jusoh WAW, Rashid ASA, Jamali J (2020) Optimizing ann models with pso for predicting short building seismic response. Eng Comput 36(3):823–837
Patricia Melin, Daniela Sánchez, Oscar Castillo (2012) Genetic optimization of modular neural networks with fuzzy response integration for human recognition. Inf Sci 197:1–19
Pedro JO, Dangor M, Dahunsi OA, Ali MM (2018) Dynamic neural network-based feedback linearization control of full-car suspensions using pso. Appl Soft Comput 70:723–736
Qin AK, Huang VL, Suganthan PN (2008) Differential evolution algorithm with strategy adaptation for global numerical optimization. IEEE Trans Evol Comput 13(2):398–417
Rainer Storn, Kenneth Price (1997) Differential evolution-a simple and efficient heuristic for global optimization over continuous spaces. J Global Optim 11(4):341
Rosenblatt F (1957) The perceptron: a perceiving and recognizing automaton. Cornell Aeronautical Laboratory, Buffalo, New York
Saeed Samadianfard, Sajjad Hashemi, Katayoun Kargar, Mojtaba Izadyar, Ali Mostafaeipour, Amir Mosavi, Narjes Nabipour, Shahaboddin Shamshirband (2020) Wind speed prediction using a hybrid model of the multi-layer perceptron and whale optimization algorithm. Energy Rep 6:1147–1159
Seiffert U (2001) Multiple layer perceptron training using genetic algorithms. In ESANN, Citeseer. p. 159–164
Seyedali Mirjalili (2016) Sca: a sine cosine algorithm for solving optimization problems. Knowl-Based Syst 96:120–133
Shubham Gupta, Kusum Deep (2020) A novel hybrid sine cosine algorithm for global optimization and its application to train multilayer perceptrons. Appl Intell 50(4):993–1026
Shun-ichi Amari (1993) Backpropagation and stochastic gradient descent method. Neurocomputing 5(4–5):185–196
Singh P, Chaudhury S, Panigrahi BK (2021) Hybrid mpso-cnn: Multi-level particle swarm optimized hyperparameters of convolutional neural network. Swarm Evol Comput 63:100863
Stelios Tsafarakis, Konstantinos Zervoudakis, Andreas Andronikidis, Efthymios Altsitsiadis (2020) Fuzzy self-tuning differential evolution for optimal product line design. Eur J Oper Res 287(3):1161–1169
Tae-Young Kim, Sung-Bae Cho (2021) Optimizing cnn-lstm neural networks with pso for anomalous query access control. Neurocomputing 456:666–677
Tanabe R, Fukunaga A (2013) Success-history based parameter adaptation for differential evolution. In 2013 IEEE congress on evolutionary computation, IEEE. p. 71–78
Weir MK (1991) A method for self-determination of adaptive learning rates in back propagation. Neural Netw 4(3):371–379
Werbos P (1974) Beyond regression:" new tools for prediction and analysis in the behavioral sciences. Ph. D. dissertation, Harvard University
Wienholt W (1993) Minimizing the system error in feedforward neural networks with evolution strategy. International conference on artificial neural networks. Springer, New York, pp 490–493
Wolpert DH, Macready WG (1997) No free lunch theorems for optimization. IEEE Trans Evol Comput 1(1):67–82
Xu Y, Li F, Asgari A (2022) Prediction and optimization of heating and cooling loads in a residential building based on multi-layer perceptron neural network and different optimization algorithms. Energy 240:122692
Xubin Wang, Yunhe Wang, Ka-Chun Wong, Xiangtao Li (2022) A self-adaptive weighted differential evolution approach for large-scale feature selection. Knowl-Based Syst 235:107633
Xue B, Zhang M, Browne WN (2014) Particle swarm optimisation for feature selection in classification: Novel initialisation and updating mechanisms. Appl Soft Comput 18:261–276
Xue Yu, Bing Xue, Mengjie Zhang (2019) Self-adaptive particle swarm optimization for large-scale feature selection in classification. ACM Trans Knowl Discov Data (TKDD) 13(5):1–27
Xue Yu, Yiling Tong, Ferrante Neri (2022) An ensemble of differential evolution and adam for training feed-forward neural networks. Inf Sci 608:453–471
Yadav N, Yadav A, Kumar M, Kim JH (2017) An efficient algorithm based on artificial neural networks and particle swarm optimization for solution of nonlinear troesch’s problem. Neural Comput Appl 28:171–178
Yadav A, Kumar N et al (2019) Application of artificial electric field algorithm for economic load dispatch problem. International conference on soft computing and pattern recognition. Springer, New York, pp 71–79
Yantao Li, Shaojiang Deng, Di Xiao (2011) A novel hash algorithm construction based on chaotic neural network. Neural Comput Appl 20(1):133–141
Zhang Q, Yoon S (2022) A novel self-adaptive convolutional neural network model using spatial pyramid pooling for 3d lung nodule computer-aided diagnosis. IISE Trans Healthcare Syst Eng 12(1):75–88
Acknowledgements
The corresponding author is thankful to Science Education Research Board (SERB) for the financial support under MATRICS Scheme with grant number MTR/2021/000503.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
All the authors declare that they have no conflict of interest.
Ethical approval
This article does not contain any studies with human participants or animals performed by any of the authors.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Function 1
The range of this function is \([-5, 5]\) with dimension 4.
Function 2
The range of this function is \([-5, 5]\) with dimension 2.
Function 3
The range of this function is \([-2, 2]\) with dimension 2.
Function 4
The range of this function is [0, 1] with dimension 3.
Function 5
The range of this function is [0, 1] with dimension 6.
Function 6
The range of this function is [0, 1] with dimension 4.
Function 7
The range of this function is [0, 1] with dimension 4.
Function 8
The range of this function is [0, 1] with dimension 4.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Chauhan, D., Yadav, A. & Neri, F. A multi-agent optimization algorithm and its application to training multilayer perceptron models. Evolving Systems (2023). https://doi.org/10.1007/s12530-023-09518-9
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s12530-023-09518-9