
Abstract
Circular economy (CE) paradigm fosters manufacturing companies’ sustainability taking place through different circular manufacturing (CM) strategies. These strategies allow companies to be internally committed to embrace circular values and to be externally aligned with several stakeholders not necessarily belonging to the same supply chain. Nevertheless, these CM strategies adoption is limited by heterogeneous barriers, among which the management and sharing of data and information remain the most relevant ones, bounding the decision-making process of manufacturers in CM. Moreover, the extant literature unveiled the need to structure data and information in a reference model to make them usable by manufacturers. Therefore, the goal of the present work is to propose a reference model by developing a conceptual data model to standardise and structure the necessary data in CM to support manufacturers’ decision-making process. Through this model, data and information to be gathered by manufacturers are elucidated, providing an overview of which ones should be managed internally, and shared externally, clarifying the presence of their mutual interdependencies. The model was conceptualised and developed relying on the extant literature and improved and validated through academic and industrial experts’ interviews.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Circular Economy (CE) is an industrial economy aiming to restore and regenerate resources (The Ellen MacArthur Foundation 2015) through several business models like servitization (Husain et al. 2021). In recent years, CE has been promoted as driver boosting sustainability and sustainable manufacturing, taking the name of Circular Manufacturing (CM) when the concurrent adoption of several CM strategies (e.g., circular design, servitization, cleaner production, remanufacturing, and recycling) takes place (Acerbi and Taisch 2020a). These strategies allow companies to be internally committed to embrace circular values and to be externally aligned with several stakeholders not necessarily belonging to the same supply chain. Nevertheless, although the benefits that could be triggered by this new economy are well known (Rosa et al. 2018), CM adoption is still constrained due to heterogeneous barriers, mainly financial, institutional, societal and infrastructural (Govindan and Hasanagic 2018; Masi et al. 2018; Tura et al. 2019). Among all, data and information management and sharing remain among the most difficult to be overcome (Ritzén and Sandström 2017; Acerbi et al. 2020), especially for discrete manufacturing companies, characterised by complex and heterogeneous data and data sources (Halstenberg et al. 2017). Indeed, although the literature over CE digitally enabled by Industry 4.0 technologies is quite vast, there is still an open discussion on how to make it more operative (Rosa et al. 2020; Agrawal et al. 2021).
Actually, CM benefits can be exploited through the data collection, analysis, and sharing (Jabbour et al. 2019; Kouhizadeh et al. 2020), implicitly requiring the preliminary detection of the necessary data and information to enable their standardisation (Bianchini et al. 2019). Therefore, in a recent study (Acerbi et al. 2021), the relevant data and information required for the adoption of each CM strategy were identified and a theoretical framework, unveiling the main categories of data-driven CM (i.e. product, process, management, and technology), was proposed. Based on the results from this previous research, and in accordance with the necessity to make companies understand how to structure their data to actuate their potentialities, as highlighted by Kristoffersen et al. (2019), the present contribution investigates the mutual inter-connections existing among entities, also defined as categories of data, like products, processes, and stakeholders management, relevant to operate in a data-driven CM context (Acerbi et al. 2021) and to be part of a sustainable supply chain (Chacón Vargas et al. 2018). Therefore, the following Research Question (RQ) is addressed:
RQ1 “How to unveil and to describe the links among the categories describing data-driven CM?”
Actually, data integration, with a value chain orientation, needs to first start from the factory inner strategy (Jabbour et al. 2019). This is required to fully embrace CM, avoiding to have a silos perspective focused only on single CM strategies. Data integration is the cornerstone to assist information sharing, by building the creation and absorption of knowledge within a firm, and to stimulate innovation in addressing business goals in accordance with the absorptive capacity theory (Huo et al. 2021). In this regard, RQ2 is addressed:
RQ2 “How to develop a model able to integrate the data and the information related to the categories composing data-driven CM to support the decision-makers of manufacturing companies?”
Indeed, a conceptual data model, allowing to clarify the relationships present among the categories characterising data-driven CM (i.e., considering data as a support for the concurrent adoption of the several CM strategies), is developed and validated in this contribution. The extant literature already presents some works concerning ontologies and data models developed to embrace CE in manufacturing, building on data structuring, but they usually limit the attention on a specific CM strategy (e.g. Sauter and Witjes (2018) focus on the exchange of resources to establish industrial symbiosis).
Therefore, by addressing RQ1 and RQ2, the present study aims to develop a reference model to be instantiated in different manufacturing contexts. It enables manufacturers to valorise data in CM to support their decision-making process, by grouping and structuring data into classes and by elucidating the relevant relationships established among them. The model has been developed taking in account and integrating the extant literature to provide a holistic view on CM through a new conceptual data model. Therefore, the conceptual data model proposed is not only grounded on the scientific literature (i.e. the results from a very recent systematic literature review on the domain of data and information management in CM (Acerbi et al. 2021) and further reviews in boundary domains as data modelling in CM), but has also been verified and validated through interviews with both scientific experts and practitioners to ensure consistency and completeness at both the scientific requirements and industrial needs levels.
This work is structured as follows. In Sect. 2, the research methodology adopted is described, explaining the research criteria used from the model conceptualization through its development up to its verification. In Sect. 3, the model conceptualization phase is presented. After an initial overview on data-driven CM, in sub-Sect. 3.1 the theoretical foundation on ontologies and data models is reported to elucidate the technical requirements for structuring data. Then, sub-Sect. 3.2 provides the literature review performed about the data models and ontologies so far developed in the CM context to identify the relevant classes of data. In Sect. 4, the conceptual data model proposed is described. In Sect. 5, the validation and verification of the model is presented and discussed, and the model contributions and implications to both knowledge and practice, are unveiled. Finally, Sect. 6 concludes the paper by underlining the main contributions of the research and its limitations opening the way to future research.
2 Material and methods
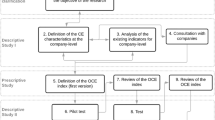
To address the research objective of developing the reference conceptual data model, a mixed usage of research traditions have been employed, leading to select specific research methodologies (Sassanelli et al. 2019). Indeed, the research process started with a literature review to employ an interpretative approach to study the research domain through an inductive reasoning (Phase 1). Then, modelling has been used to perform the system development (Phase 2), and finally experts’ interviews have been required for the system refinement (Phase 3). The resulting research process allowed the conception and development of a comprehensive model able to address the needs coming from both scientific literature and industry. Figure 1 depicts the research process explaining how these research methodologies have been articulated and used in the applied research field also indicating on the arrows the inputs and outputs from/to each phase. More in detail, these three phases have been addressed in accordance with the Design Science Research (DSR) approach proposed by (Peffers et al. 2006), also reminding the Design Research Methodology main phases (i.e. research clarification, descriptive study I, prescriptive study, descriptive study II) (Blessing and Chakrabarti 2009). The research process starts with the problem identification and motivation (i.e. the need to create a reference model within which all the data and information for CM are clustered to be used to make manufacturing companies undertake a path towards CM including all the different CM strategies at the same time), inferring the objectives of a solution. This phase is named Phase 0 in Fig. 1 since not addressed in this specific contribution but widely tackled in a previous very recent literature research in the research domain (Acerbi et al. 2021). Then, an artifact (i.e., the conceptual data model) has been first conceived in Phase 1 (model conceptualization) based on the extant literature, and then developed in Phase 2 (model development). Last, the demonstration, evaluation, and communication of the artifact took place in Phase 3 (model verification and validation).

Research Design
In particular, in Phase 1, to start conceiving the reference model, the results coming from the literature review by Acerbi et al. (2021) were selected and employed as main input. They consist in a list of data and information, characterising the several CM strategies, divided in three categories of data and information (i.e., product, process, and management) and the necessary related technologies. The work performed by Acerbi et al. (2021) was taken as reference since it is the most recent systematic literature review conducted in this domain (i.e. data and information for CE adoption in manufacturing companies). This study, hence, includes all the already developed knowledge inferring the inputs to create a single comprehensive conceptual data model for CM. Actually, Acerbi et al. (2021), not only filled the gap about the identification of the required data and information for each single CM strategy, but also proposed a theoretical framework, reported in Fig. 2, useful to pose the basis to a more comprehensive conceptual data model aiming at including concurrently all the different CM strategies.

Theoretical Framework adapted from (Acerbi et al. 2021)
In Phase 1, considering the need to provide a holistic and integrated view on data in CM, also envisaged and suggested in (Acerbi et al. 2021), a first in-depth literature review (see sub-Sect. 3.1) was performed to elucidate the theoretical foundation about ontologies and data models according to the extant literature, defining the technical requirements necessary to organize data and information for CM into structured classes of data answering to RQ1. This preliminary review was performed by querying Scopus as follows: TITLE-ABS-KEY (“model*” AND (“data” OR “information”) AND “manufacturing”), providing a huge number of results (i.e., 55822 documents) justified by the consolidated research field. Considering the high number of contributions, the authors relied on the support of academic experts in this specific research domain. Through a set of interviews, a reference book was suggested and detected (i.e. (West 2011)), together with a set of other 13 relevant contributions including two ISO (International Organization for Standardization) standards. The eligible documents reviewed led to the selection of data models as reference models to structure data since they allow to clarify and make visible the mutual interdependencies among entities.
At the same time, still in Phase 1, the classes of data to be included in this reference data model were defined starting from the already existing data models for CM selected from literature (as reported in sub-Sect. 3.2) answering to RQ2. To review the extant literature, Scopus was queried as follows: TITLE-ABS-KEY (("circular economy" OR "circular manufacturing") AND ("data model*" OR "ontolog*")). Only journal articles and conference proceedings were selected with an initial output of 22 papers (demonstrating the embryonal status of this research domain). Among them, 15 contributions were discarded because not focused on the manufacturing sector (e.g., the focus was on construction industry) or not focused on CM (e.g., the focus was only on social sustainability). The eligible papers finally selected were 7, with 2 additional contributions suggested by the two academic experts who were also involved in the previous literature analysis, and 1 additional contribution about industrial symbiosis that has been added thanks to the first-round of peer review. These 10 eligible contributions have been analysed with the aim of investigating the CM strategies addressed in these works, the main classes of data individualised and their relationships. The output of Phase 1 was the model conceptualization (including the technical requirements to structure data and the main classes of data required in CM adoption including all the different CM strategies concurrently).
In Phase 2, using as inputs the above-mentioned results, i.e., both the model structure and content, the conceptual data model has been developed. In particular, the modelling methodology has been employed to structure and standardise the data and information in a reference conceptual data model for CM. The language adopted is the Unified Modelling Language (UML) Class Diagram (in particular the UML related ISO (BS ISO/IEC 19505–1 2012a, b)) being it the most diffused language for data modelling and the most aligned one with the requirements of this research, i.e. supporting the decision process in manufacturing companies (Negri et al. 2016). To graphically represent the model, the software “Modelio Open Source 4.0” (Modelio 2020) was used since it includes all the requirements necessary to develop an UML class diagram, and it is easily accessible on the web (being an open source software). The output of Phase 2 has been the development of the conceptual data model prototype.
Phase 3, keeping as input the conceptual data model prototype developed in Phase 2, aims to improve, verify and validate it (Mettler 2011). This phase has been performed though iterative interviews conducted through a series of workshops organized by the authors with both practitioners and academics experts.
On one side, the academics interviewed are experts in CE and data modelling coming from European universities and research centres (i.e., Italy and Greece). CE experts enabled to verify the content of the model in terms of data and data relationships, while data modelling experts enabled to verify and validate the structure of the model.
On the other side, the practitioners interviewed come from European companies (i.e., from Italy and Germany) currently involved in CE-related projects. Both manufacturing companies (e.g., products producers, product recyclers) and technological consulting companies (e.g. technology and software consulting) were involved. Indeed, manufacturers provide their experience, often limited to their own company’s boundaries, while the consulting companies provided additional contributions coming from heterogeneous realities and they both supported the model validation. In addition, the consulting companies selected deal with technology and software to verify and strengthen the importance of technologies in the model as the means through which gather, manage, and share data for CM.
Table 1 reports the interviews and interviewees characteristics.
During the workshops, semi-structured interviews were conducted (DiCicco-Bloom and Crabtree 2006) to gather qualitative data for an empirical exploration and verification of the results (Maxwell 1997) to create a consistent, complete and exhaustive model embracing scientific and practitioner oriented requirements. After having completed all the interviews, the results were shared with all the other experts to evaluate whether additional feedback might arise (further details will be reported in Sect. 5). Therefore, the output of Phase 3 has been the improved and validated artifact, i.e. the final conceptual data model ready to be used in manufacturing companies. This final conceptual data model is the artifact developed to address the problem envisaged about a reference model including all the data and information required to embrace all the CM strategy concurrently.
3 Model conceptualization: literature review results
The diffusion of CM can be highly facilitated by the adoption of digital technologies (Acerbi and Taisch 2020a) thanks to their capabilities of gathering and exploiting huge amount of data which, if properly managed and analysed, can improve sustainable business performances (Agrawal et al. 2021). Data-driven CM has the intention to exploit data to take proper decisions. Digitization might support the information sharing intensity (Acerbi et al. 2021), which represents an essential element in the context of sustainability (Jraisat et al. 2021). Digitization also empowers the collaboration within a network among several actors, by also facilitating the knowledge sharing and commitment of human resources within the same factory, if human resource management practices are properly conducted (Mukhuty et al. 2022). Actually, collaboration and exchange of information represent fundamental elements in embracing CM, especially if we look at the creation of industrial symbiosis networks (Martin and Harris 2018). Therefore, information-sharing platforms have been developed to facilitate the exchange of information for instance about localization of the actors, and thus of resources to exchange, and about the costs to operate in such a network (Fraccascia and Yazan 2018). Among the other possible technologies adoptable in data-driven CM, ICT emerged to be relevant especially as far as Product-Service Systems is concerned thanks to the possibility to share and manage real-time information about the several stakeholders involved (Husain et al. 2021). Moreover, blockchain represents a valid technology to be used to establish trustful relationships among actors operating in the same supply chain embracing data-driven CM, thanks to the possibility to have immutable data and shared databases (Mukherjee et al. 2021) and to rely on transparent and traceable data (Upadhyay et al. 2021). Additionally, data analytics should be performed and, Artificial Intelligence represents a cornerstone facilitating data-driven CM adoption in this sense, for instance to easily distinguish from plastic and glass waste enabling their proper recycling, and to perform real-time data on energy consumption and pollution emissions during waste treatments (Agrawal et al. 2021). Nevertheless, although it is visible how digitization enables to foster the data analysis, this can be done by relying on several indicators supporting the decision-making process such as the national indicator for CE proposed by (Geng et al. 2012). Therefore, data-driven CM is about the smart usage of data to embrace CM strategies, where “smart” is not necessarily linked to the usage of digital tools even though there is a huge awareness about the potentialities that digitization has in this context.
3.1 Data structuring for manufacturing and data model technical requirements
After the clarification of the concept of data-driven CM, the first in-depth literature review has been performed. This enabled to understand how to model data in manufacturing and exploit their value, unveiled the following results.
According to Neligan (2018), so far, the scientific literature investigating the adoption of digital solutions to support the implementation of CM strategies often ignores issues related to data integration. Data integration covers the preliminary phase towards an appropriate data and information management, since it enables to combine individual information sources with the business goals of the involved stakeholders by using the whole set of data gathered from daily business activities, (Neligan 2018). Data integration facilitates knowledge absorption of internal functions and enhances companies flexibility and ability to innovate (Huo et al. 2021). Accordingly, data models and ontologies are suggested to be used to streamline information management through data integration, since they facilitate the creation of a standard language through which define and standardise the required data and information (Polenghi et al. 2019) by supporting knowledge management (Olivier et al. 2015). Data models and ontologies allow to store, to easily maintain, to simply update data, and to support reasoning and interoperability. Therefore, they enable to represent, in a shared manner, a specific domain of discourse by creating taxonomies and by providing relationships among concepts, with a semantical enrichment that sustains information retrieval through reasoning (Negri et al. 2016). In manufacturing, an ontological framework or a data model must encounter specific requirements such as the capability to describe the main resources and the processes involved in the system, but also their relationships to enable the extraction of relevant knowledge (Zhao et al. 1999). Data models make companies to improve information quality and to empower the decision-making process, focusing on those data and information fitting for purpose (West 2011).
Out of all the possible levels of data modelling (e.g. physical, logical, conceptual, and etc. (West 2011)), the conceptual data model is the only one enabling to organize and structure data and information covering the manufacturing business needs, since it is “a structured business view of the data required to support business processes, record business events, and track related performance measures” (Sherman 2015). Indeed, conceptual data models are considered the most appropriate analytical tools to organize information within companies stimulating data sharing (Tupper 2011). They give an overall view of the structure of data in a business context, being independent from the data storage structure, and allowing to investigate and understand the enterprise needs, since they can be instanced on different companies realities (Sherman 2015). They require to respect simple rules (not constrained by the type of data included in the model itself), and all the notations of the model must be simple, memorable and capable (West 2011). In addition, conceptual data models could be based on different graphically based languages. Unified Modelling Language (UML) is one of the most diffused (Negri et al. 2017) and is composed by classes which are defined through attributes, or data, that are concretised into instances. The classes are characterised by specific relationships established with the other classes of the model (i.e. direct or reflexive associations, generalization and composition) (Bachman 1969; West 2011; BS ISO/IEC 19505–1 2012a ,b). The relationships among classes are characterised also by specific cardinalities (e.g. many-to-many, one-to many etc. (Zhou et al. 2005)).
Summarising the technical requirements, the model requires to include specific classes of data, named with simple and memorable notations, characterised by attributes and relationships established with the other classes.
3.2 Data modelling in circular manufacturing
Ontologies and data models offer to systems higher modularity and flexibility (Negri et al. 2017), characteristics that would empower firms towards the adoption of CM, that requires to be able to concurrently evaluate and manage different stakeholders’ objectives and behaviours (Acerbi and Taisch 2020b). This, for the firm’s perspective, corresponds to new requirements to be taken into account during the transition (Braun et al. 2018).
Under a CE perspective, some attempts to structure data and integrate their different data sources, also belonging to external enterprises, have been done with the intention to facilitate the sharing of information (e.g. (Derigent and Thomas 2016)) and to enhance the interaction and collaboration among different firms (Martín Gómez et al. 2018). In Table 2, the analysis conducted on the already existing data models and ontologies for CM is reported. The review objective stands in the analysis of the classes of data referred to the different CM strategies addressed in the contributions, usually with a single CM strategy perspective, and the identification of the relationships present among the classes of data to employ this knowledge in a complete model for CM.
So far, in the extant literature, an integrated vision of CM has been proposed only from an high level perspective by Gligoric et al. (2019). Nevertheless, it was neither provided an analysis of the different processes characterising CM, nor an investigation about the relationships to be established with the stakeholders involved along the product lifecycle, inter and intra firms. The other existing models neglect the holistic view employed by Gligoric et al. (2019), but they enabled to identify the main classes of data required for the specific CM strategies, and to detect, whenever present, the communalities among the classes of data characterising the distinctive strategies, creating the basement to develop a complete reference data model for CM where all the classes of data are simultaneously considered.
4 Development of the circular manufacturing (CM) reference conceptual data model
Relying on the results presented in Sect. 3, the CM reference conceptual data model has been developed. It aims to expand the single CM strategy-perspective adopted traditionally by scholars, as tracked in Table 2, with the final aim to support manufacturing companies’ managers in the decision-making process. Indeed, this model has been developed to create awareness in manufacturers about the data to be gathered, both internally and externally to the company, facilitating data integration for the concurrent adoption of the different CM strategies. This awareness makes manufacturers understand the limits which they might face due to the non-gathering of specific data, in terms of reduced possibility to adopt the different CM strategies since their adoption rely on the same data or on related data. Therefore, if a data about a specific class is missing, this might hinder the potentialities of a manufacturing company in implementing several CM strategies. Indeed, this conceptual data model allows to support manufacturers in their decision-making process by helping them to decide which type of data they should gather or use to facilitate their transition towards CM. Further details are reported in Sect. 5 where managerial implications are discussed.
The conceptual data model (whose extensive view is shown in Fig. 3 and then proposed in its detailed parts from Figs. 4, 5, 6, 7, 8, 9, 10) as reference in this domain is constituted by 29 classes of data whose exhaustive explanation is reported in sub-Sect. 4.1. Each class has been defined based on the data and information detected in Acerbi et al. (2021) and the selected existing data models among those already proposed in the field (see Table 2). These have been adapted and combined to address the research objective in the development phase, and further improved through a set of interviews in the validation phase. The specific classes of the reference model are reported from Tables 3, 4, 5 and 6 in sub-Sect. 4.1. The extensive results, declining each class with the attributes, the related definition and type of data (e.g., integer, string, float) and the examples of instances gathered during the interviews conducted with practitioners, are shown in the Appendix (see from Tables a1 to a22). The established relationships among classes of data (i.e., compositions or generalization or associations), represented in Fig. 3 and graphically differentiated through the adoption of appropriate symbols aligned with the UML standard, are reported in Table 7 (sub-Sect. 4.2) and extensively described in Table a22 of the Appendix. In the reference conceptual data model depicted in Fig. 3, the four categories of Acerbi et al. (2021) (i.e., product, process, management and technologies) are considered the main classes, also called “father” classes. These classes have been broken down into specific classes of data according to the results from the literature. In the next sub-section, this classification is reported together with the related definitions.

CM-Conceptual Data Model
4.1 Conceptual data model structure: classes of data
As just reported, the conceptual data model employs the category of data identified in Acerbi et al. (2021), as those common to the different CM strategies, building on them by creating the “father” classes of data characterising it. The first class analysed is the “product” as reported in Fig. 4.

“Product” category- related classes
In Table 3 are defined the classes of data related to the “product” class.
The second class analysed is the “process” one and it is depicted in Fig. 5.

“Process” category-related classes
From “Process” class, many classes of data have been detected (see Table 4) covering the different internal processes, both concerning the traditional manufacturing processes (e.g., production) and concerning those processes established on purpose to become circular (e.g. recycling), required to be modified, updated or integrated through the gathering of specific data to fully embrace CM as reported in Fig. 6.

"Process" related classes of data
Regarding the classes of data related with the “Circular Process” class of data, a detailed view is reported below in Fig. 7.

"Circular Process" related classes of data
Additionally, in Fig. 8 is reported the set of classes of data related to the “Traditional Manufacturing Process” class of data.

"Traditional Manufacturing Process" related classes of data
The third category analysed concerns the “management” (see Fig. 9).

“Management” category-related classes
The classes developed out of this category are focused on external entities, being them highly impactful on companies’ activities. Indeed, customers, suppliers, and industrial actors with whom exchange resources, waste and by-products broken down this category into three classes of the conceptual data model (see Table 5).
The last class investigated is the “technology” (see Fig. 10).

“Technology” category-related class
Four main groups of technologies and tools were detected as fundamentals to be introduced for the gathering and management of data in CM. These are reflected into the classes of data related to the “technology and tools” class as reported in Table 6.
4.2 Conceptual data model structure: relationships among classes of data
The classes of the conceptual data model, defined above, are linked among each other through relationships, that can be either direct or indirect whenever other classes are used as bridge. A summary of the direct relationships is reported in Table 7 (the relationships among classes are mutual, but each is reported only once).
Some considerations about the relationships that characterize the model structure are reported below.
-
1. The reflexive association on the father class “process” affects the related children classes, since this type of relationship stresses the need of data sharing to foster the concurrent adoption of different strategies and the putting in place of several processes. Indeed, having for instance the data necessary to disassemble a product facilitates the implementation of remanufacturing or recycling processes.
-
2. The distinction between direct or indirect relationships allows the manufacturer to have the whole picture in mind, visualising the mutual impacts present among the classes of data. This distinction depends on how strong the relationship is. For instance, the “by-product” is directly related to “industrial symbiosis partners’ management” since one class can be exploited only if there is the presence also of the other one. While “material” is not directly linked to “customer management”, to which class instead it is linked indirectly through “product” class, since the selling of the product corresponds the stronger relationship, and the material comes after. Instead, “material” is linked directly to “supplier management” since the material requirements are guiding element for the choice of the supplier and vice versa.
-
3. Direct and indirect relationships can be generated not necessarily through “father” classes but also through the “child” classes. Indeed, sometimes specific child classes must be directly linked to other father classes or among them to reinforce their role in respect to the others. Below some examples are reported:
-
The “process” class is directly related to the “product” class, stressing the need to treat the product through several processes, and it is linked indirectly to the “supplier management”, passing through the composition of “product”, the “material”, directly linked to the “supplier management” class, since for instance there is not a direct impact of the type of process selected on the selection of the suppliers.
-
The “by product” class, a generalization, or child, of the “product” class, is directly linked to “industrial symbiosis partners’ management” to evaluate the possible exchanges of resources. Instead, the “turned back product class”, a child class of “product”, is directly linked to “customer management” to boost reasoning on the reverse logistics.
-
The “technology and tools” class is related directly to “process” class, and thus indirectly to all the children classes, since their adoption enable the gathering and management of data concerning all the processes. However, “information systems” is directly related to “customer management”, “supplier management”, and “industrial symbiosis partners’ management” to highlight the need to manage these stakeholders with specific information systems.
-
4.3 Conceptual data model structure: relationships inside the category-related classes of data
Looking at the specific classes characterising the model and their relationships, the “Product” class is common to most of the existing models (i.e. (Vasantha et al. 2015; Sauter and Witjes 2018; Martín Gómez et al. 2018; Gligoric et al. 2019; Acerbi et al. 2021), representing the central element of the transition towards CM. Actually, the “product” class is characterised by its attributes, but in CM both “component” and “material” classes gain a prominent role (i.e. (Álvarez and Ruiz-Puente 2017; Sauter and Witjes 2018; Mboli et al. 2020), thus deserving to be elected as separated classes and not considered only as product attributes (this point was also suggested during the first interview with academics). Moreover, the “by-product” class was added, and its specific attributes were defined after the first interview with academics.
Concerning the “process” class, Martín Gómez et al. (2018) highlighted the need to include the traditional manufacturing processes classes (e.g. design) also in a CM-oriented data models, while Mboli et al. (2020) and Sauter and Witjes (2018) added the classes concerning CM-related processes (e.g. remanufacturing, recycling, reuse). In addition, (Vasantha et al. 2015; Sauter and Witjes 2018; Gligoric et al. 2019; Mboli et al. 2020) considered important to add a class regarding the repair and maintenance of products, and thus the data model developed includes the “Maintenance, Repair & Overhaul” class which covers the data referred to services provided to extend the product lifecycle. Therefore, considering also that some data is shared among the classes of data above reported, the “process” class is the generalization of two other classes: “traditional manufacturing processes” and “circular processes”, which respectively grouped under themselves other distinctive classes (see Fig. 5). This choice was also reinforced by the interviews conducted with practitioners who considered important to have a clear idea about traditional process data and circular-oriented process data.
Moving to attention to the management-related class, the consumer is considered a relevant class in literature (i.e. (Vasantha et al. 2015; Sauter and Witjes 2018; Martín Gómez et al. 2018; Gligoric et al. 2019; Mboli et al. 2020)). Therefore, the “selling & customer management” has been inserted as a separate class in the proposed model in alignment also with suggestions from the interviewees.
In addition, suppliers and industrial symbiosis partners-related classes were included as other two separate classes. The “supplier management” class is especially important for the strong link with the material selection process which gains a relevant position in CM, and during the interviews emerged the importance to evaluate the location of the suppliers to decide the type of relationship to establish with them, thus the “facility location” was added as attribute. The “industrial symbiosis management” class has been inserted to enable the manufacturers adopting this model to be open to exploit synergies with external industrial actors in exchanging by-products or other resources.
The “technology and tools” class is also recognised as an important class by (Vasantha et al. 2015). The four types of technologies individualized from the previous study (Acerbi et al. 2021) correspond here to specific and separate classes to make visible the relationships with the other classes as above reported. They all inherit the type of attributes of the “technology and tools” which then are instantiated differently according to the class.
5 Model discussion, verification, and validation
The conceptual data model developed is not-sector specific, since CM has the embedded potentiality to increase companies’ flexibility in optimizing resource usage, by relying on both cross-sectors and within-sectors exchanges of resources (Herczeg et al. 2018). To verify and validate the reliability of the model from both a scientific and industrial perspective and to discuss the applicability of the model in industrial manufacturing companies, the model verification and validation was performed through a series of workshops involving both academics and practitioners’ experts. The interviews during the workshops were based on the questions reported in Table 8.
A summary of the feedback collected through the workshops is reported in Table 9 and furtherly discussed below, underlining both theoretical and managerial implications of the model.
5.1 Scientific verification and validation
Starting with scientific experts, they analysed and discussed the classes of data and their relationships by evaluating their completeness and coherence in accordance with their experience in the CE domain. The academic experts involved firstly provided some suggestions about possible new classes to be inserted in the model. For instance, “waste” (previously included in the “material”) became a separate class to create direct relationships with other classes, among which the “industrial symbiosis partnership management” and “consumer management”, making visible the potentialities from waste exchange and treatment. Besides, the “by-product” has been added as a separate class after the following statement: “by-products existence is critical for CE, and to be similarly attractive to a core product, attributes like strength, integrity and usability need to be monitored to the by-products”. Moreover, another aspect underlined regards the lack of knowledge on consumer behaviours and type, and the importance of the product “selling” information, since according to them “the selling is the major part of circularity as this will enable the different streams Business to Business (B2B), Business to Customers (B2C), but it is also important in the context of a secondary market with these two parties”. Therefore, the type of customer (i.e. B2B or B2C) was added as attribute of “customers’ management” class.
Although some suggestions were given, the scientific experts considered the model a comprehensive picture of the data and the information required in CM covering the gap envisioned in the scientific literature about the presence of models limited only to a single CM strategy while lacking a comprehensive reference data model. According to them, from a scientific perspective, this model enables to merge the scattered knowledge already present in the extant literature by developing a reference conceptual data model aiming at structuring and standardising into classes the data required for CM, to elucidate their mutual relationships and impacts.
5.2 Practical verification and validation
Moving to practitioners, the verification and validation process have been conducted by screening the entire conceptual data model content trying also to implement it in their industrial contexts. In doing that, they provided some feedback. For instance, they underlined the need to include the required skills and knowledge to implement a certain process, thus “skills and knowledge about the process” was added as attribute of the “process” class. The same was stressed for the “technology and tools” class. Actually, the experts emphasised the exhaustiveness and completeness of the model that somehow can scare small and medium enterprise (SMEs) due to the lack of data. This encouraged the authors to ensure the model modularity allowing to instantiate the model according to the company’s specifications. For instance, the definition of two main classes of data regarding the processes (i.e., “traditional manufacturing processes” and “circular process”) allows to perform a separated analysis on the already implemented processes, out of which some more data is required to be collected to be adherent to circular values, and on the circular oriented processes that should be implemented ad hoc for the transition. Last, practitioners suggested to investigate in future research the potential new procedures to be adopted by manufacturers to gather some of the data and the information reported in the model (as the case of the attribute “Supplier Local Community Influence” which might require new procedures).
6 Conclusions
This research was aimed at structuring data and information concerning CM in a reference conceptual data model to facilitate their management to support the decision-making process of manufacturers while embracing CM. The trigger of the study has been the lack in the extant literature of a complete data model to be kept as reference allowing to address multiple concurrent CM strategies to be considered in manufacturing based on the structuring of data and information to make them operationalised in this context. To do this, a conceptual data model has been developed, verified and validated through scientific literature and experts’ interviews (involving both practitioners and academics experts).
The model, thus the artifact, raises and creates awareness about the data required by manufacturers to embrace CM and to generate consciousness about the need to use both internal and external data to succeed in this path. Indeed, having this holistic view, manufacturers are aware of the type of data required in CM, how detrimental is the lack of a specific data in limiting resource circularity, and how resources coming from external entities could be used in case appropriate information are available. This model promotes the collaboration among enterprises in an integrated way based on data. Indeed, the classes of data, with the relative attributes, provide the big picture without forcing the single manufacturer in implementing everything together from the beginning, but only underlining the data requirements to become, also gradually, an enabler or promoter of CM.
This conceptual data model, can be considered the basement upon which start tracking data on flows in a more specific way, encouraging a smoother analysis of circular performances. Indeed, the modularity of the model allows manufacturing companies to gradually apply it, highlighting the need to develop, based on this model, a maturity assessment facilitating the usage of this reference model. Theoretical, practitioners and managerial implications coming from this research are worth to be reported.
6.1 Theoretical implications
Regarding the theoretical implications, based on these suggestions and feedback, the model was improved and then validated. This finally allowed to add a small brick to the scientific literature creating a reference conceptual data model for CM. This research enables to create the ground to data integration by ensuring a holistic view over the several existing CM strategies simultaneously. Thus, this conceptual data model can be considered as a reference in this domain since it elucidates in a structured and complete way the required classes of data in CM without employing a silos perspective over a single strategy as stated by the interviewees. Moreover, this model contributes to the absorptive capacity theory in assisting manufacturing companies in integrating and sharing information by enhancing their knowledge towards circular-driven innovations. In addition, the model triggers the need to develop a standard language in future research.
6.2 Practical implications
Regarding the practitioners’ implications, modelling data in a conceptual data model, where the classes of data and their relationships are easily visible, facilitates data exploitation in embracing CM and it enables to provide companies, and more specifically manufacturers, with a holistic picture of the entire system including both internal and external necessary data. The relationships among classes enable to better understand why and when the different data must be used, and they also make aware the manufacturer about the missing option/s at the current state of the company by opening new opportunities. In addition, practitioners, thanks to the adoption of this reference conceptual data model, can be facilitated in improving practices like data management, knowledge management, innovation management, customers’ and suppliers’ relationships management. Moreover, the model could be also useful to pave the way to find opportunities for co-designing circular solutions by relying on the data gathered from external entities.
More specifically, by relying on this reference conceptual data model, manufacturers are supported, at a preliminary stage, in their decision-making process since the reference conceptual data model makes them highlight the main data-related issues, in terms of wrong and fuzzy decisions which might arise whenever specific data are not gathered or used. For instance, focusing the attention on the “material” class, collecting data about material allows the manufacturer to take decisions on how to treat the materials used, to evaluate how to manage potential industrial waste generated, to decide in which type of technologies they should invest in order to manage a specific material type, to decide which processes need to be empowered, and to decide the characteristics required by a supplier to be selected to ensure a certain level of circularity in their designed products. The “material” class is also indirectly related to “process” class and thus, the manufacturer can evaluate the data available about the material and then about the product to decide whether it is possible to think about a recycling of the material under analysis or not and he can also start monitoring the material consumptions registered during the production processes for example. In addition, looking at the “process” class, the data concerning this class stimulates the development of specific Key Performance Indicators related to different processes, both traditional or circular, to concretely keep under control the organization’s circular performances and put in practice actions according to the state. All these decisions are stimulated by this reference conceptual data model which hence does not support a what if analysis or simulated scenarios, but it only aims to create the ground defining the data and information able to support manufacturers in directing their decisions while embracing CM. Therefore, it does not support the manufacturer in taking the correct choice but only in understanding the panel of decisions which should be taken into account whenever a CM-oriented transition is tackled by a manufacturing company. In addition, it allows manufacturers to evaluate the required data to be gathered in this context leading to data integration. This support is possible thanks to the relationships visible in the conceptual data model previously reported in Fig. 3.
6.3 Managerial implications
Regarding the managerial implications, the present work provides a decision-support tool for manufacturers willing to make their companies embracing CM, by enabling them to consider all the interested data and evaluate their mutual interactions. This model represents a strategic tool that contributes to practice:
-
enabling to analytically explore in a deeper way the entire value chain in which the manufacturing company operates,
-
allowing to envisage all the key classes of data necessary to be considered in CM to take decisions,
-
enhancing data value in pursuing this transition,
-
easing the operationalisation of strategic intensions and facilitating the transition towards CM relying on data
6.4 Limitations and future works
As final remark, some limitations are worth to be reported, opening the way to future research.
-
It has not been performed an empirical analysis over a prolonged time horizon involving a specific manufacturing company or a supply chain. Therefore, in future research this point needs to be addressed to evaluate the benefits obtained on the long run and to better investigate the complexity to be addressed at the supply chain level when open and closed loops are established;
-
as far as emerged from the interviews, the reference model may be difficult to be instantiated in SMEs due to its complexity and the extensive structure that it has. This encouraged the development of a modular model leading to the creation, in future researches, of a maturity model allowing to support the path of manufacturers along subsequent levels of data exploitation for enhanced circularity;
-
the difficulty in instantiating the reference model is also connected to the lack of structured procedures about data gathering, which must be studied in future researches;
-
data gathering difficulties are also linked to the data sharing problem which is usually encountered due to the absence of the necessary technologies and limited support from external actors. To solve this issue, tailored actions are supposed to be put in practice by policymakers on one side and on the other side information systems interoperability should be guaranteed;
-
last, the specific procedures to be put in practice by practitioners can be furtherly investigated to provide prescriptive directions to be implemented when the conceptual data model is used.
As final remark, potential implications from this research for policymakers are worthy to be highlighted. Policymakers, by relying on this model, can sustain and direct tailored future scientific research and practitioners’ investments to help companies in pursuing a data-driven circular path fostering data sharing with adequate data protection policies, facilitating manufacturers in addressing what is proposed in the “Circular Economy Action Plan” (European Commission 2020).
Change history
07 September 2022
Springer Nature’s version of this paper was updated: Missing Open Access funding information has been added in the Funding Note.
References
Acerbi F et al (2020) ‘Towards a Data-Based Circular Economy: Exploring Opportunities from Digital Knowledge Management’, in Lecture Notes in Networks and Systems. Springer, pp. 331–339.https://doi.org/10.1007/978-3-030-41429-0_33
Acerbi F et al (2021) ‘A Systematic Literature Review on Data and Information Required for Circular Manufacturing Strategies Adoption. Sustainability 13(4):2047. https://doi.org/10.3390/su13042047
Acerbi F, Taisch M (2020a) ‘A literature review on circular economy adoption in the manufacturing sector. J Clean Prod, 123086. https://doi.org/10.1016/j.jclepro.20210.123086
Acerbi F, Taisch M (2020b) ‘Towards a Data Classification Model for Circular Product Life Cycle Management’, in. Springer, Cham, 473–486. https://doi.org/10.1007/978-3-030-62807-9_38
Agrawal R, Wankhede VA et al (2021) ‘An Exploratory State-of-the-Art Review of Artificial Intelligence Applications in Circular Economy using Structural Topic Modeling. Oper Manag Res (0123456789). https://doi.org/10.1007/s12063-021-00212-0
Agrawal R, Wankhede VA et al (2021) Nexus of circular economy and sustainable business performance in the era of digitalization. Int J Product Perform Manag. https://doi.org/10.1108/IJPPM-12-2020-0676
Álvarez R, Ruiz-Puente C (2017) Development of the Tool SymbioSyS to Support the Transition Towards a Circular Economy Based on Industrial Symbiosis Strategies. Waste and Biomass Valorization 8(5):1521–1530. https://doi.org/10.1007/s12649-016-9748-1
Bachman CW (1969) ‘Data Structure Diagrams’, in Data Base. Available at: https://web.archive.org/web/20151003005325/https://www.minet.uni-jena.de//dbis/lehre/ws2005/dbs1/Bachman-DataStructureDiagrams.pdf. (Accessed: 25 February 2021)
Belaud JP et al (2019) Framework for sustainable management of agricultural byproduct valorization. Chem Eng Trans 74:1255–1260. https://doi.org/10.3303/CET1974210
Bianchini A, Rossi J, Pellegrini M (2019) ‘Overcoming the Main Barriers of Circular Economy Implementation through a New Visualization Tool for Circular Business Models’. Sustainability 11(23):6614. https://doi.org/10.3390/SU11236614
Blessing L, Chakrabarti A (2009) DRM, a Design Research Methodology. Springer, LondoN. https://doi.org/10.1007/978-1-84882-587-1
Braun AT et al (2018) ‘Case Study Analysing Potentials to Improve Material Efficiency in Manufacturing Supply Chains, Considering Circular Economy Aspects. Sustainability 10(3):1–12. Available at: https://ideas.repec.org/a/gam/jsusta/v10y2018i3p880-d137113.html. (Accessed: 3 May 2019).
BS ISO/IEC 19505–1 (2012a) ‘Information technology — Object Management GroupUnified Modeling Language (OMG UML)’, BSI STANDARD PUBLICATIONS, 1
BS ISO/IEC 19505–2 (2012b) ‘Information technology — Object Management Group Unified Modeling Language (OMG UML)’, BSI STANDARD PUBLICATIONS, 2
Chacón Vargas JR, Moreno Mantilla CE, de Sousa Jabbour ABL (2018) Enablers of sustainable supply chain management and its effect on competitive advantage in the Colombian context. Resour Conserv Recycl 139(September):237–250. https://doi.org/10.1016/j.resconrec.2018.08.018
Derigent W, Thomas A (2016) ‘End-of-life information sharing for a circular economy: Existing literature and research opportunities’, in Studies in Computational Intelligence. Springer Verlag, pp. 41–50. https://doi.org/10.1007/978-3-319-30337-6_4
DiCicco-Bloom B, Crabtree BF (2006) ‘The qualitative research interview’, Medical Education. John Wiley & Sons, Ltd, pp. 314–321. https://doi.org/10.1111/j.1365-2929.2006.02418.x.
Sauter EM, Witjes M (2018) ‘Linked Spatial Data for a Circular Economy -- Exploring its potential through a Textile Use Case’, in Hellmann S. and Fernandez J.D. (eds) 13th International Conference on Semantic Systems SEMANTiCS, SEMPDS 2017. CEUR-WS. Available at: http://ceur-ws.org/Vol-2044/paper10/paper10.html. (Accessed: 30 September 2020)
European Commission (2020) Circular Economy Action Plan. Available at: https://ec.europa.eu/commission/presscorner/detail/en/ip_20_420
Fraccascia L, Yazan DM (2017) (2018) ‘The role of online information-sharing platforms on the performance of industrial symbiosis networks.’ Resour Conserv Recycl 136:473–485. https://doi.org/10.1016/j.resconrec.2018.03.009
Geng Y et al (2012) Towards a national circular economy indicator system in China: An evaluation and critical analysis. J Clean Prod 23(1):216–224. https://doi.org/10.1016/j.jclepro.2011.07.005
Gligoric N et al (2019) ‘Smarttags: IoT product passport for circular economy based on printed sensors and unique item-level identifiers’. Sensors (Switzerland), 19(3). https://doi.org/10.3390/s19030586
Govindan K, Hasanagic M (2018) A systematic review on drivers, barriers, and practices towards circular economy: a supply chain perspective. Int J Prod Res 7543:1–34. https://doi.org/10.1080/00207543.2017.1402141
Halstenberg FA, Lindow K, Stark R (2017) Utilization of Product Lifecycle Data from PLM Systems in Platforms for Industrial Symbiosis. Procedia Manufacturing 8:369–376. https://doi.org/10.1016/j.promfg.2017.02.047
He Y et al (2020) An ontology-based method of knowledge modelling for remanufacturing process planning. J Clean Prod 258:120952. https://doi.org/10.1016/j.jclepro.2020.120952
Herczeg G, Akkerman R, Hauschild MZ (2018) Supply chain collaboration in industrial symbiosis networks. J Clean Prod 171:1058–1067. https://doi.org/10.1016/j.jclepro.2017.10.046
Huo B, Haq MZU, Gu M (2021) The impact of information sharing on supply chain learning and flexibility performance. Int J Prod Res 59(5):1411–1434. https://doi.org/10.1080/00207543.2020.1824082
Husain Z et al (2021) ‘Analyzing the business models for circular economy implementation: a fuzzy TOPSIS approach’. Oper Manag Res (0123456789). https://doi.org/10.1007/s12063-021-00197-w.
Jabbour CJC et al (2019) Unlocking the circular economy through new business models based on large-scale data: An integrative framework and research agenda. Technol Forecast Soc Chang 144:546–552. https://doi.org/10.1016/J.TECHFORE.2017.09.010
Jraisat L et al (2021) Triads in sustainable supply-chain perspective: why is a collaboration mechanism needed?. Int J Prod Res 1 https://doi.org/10.1080/00207543.2021.1936263
Kouhizadeh M, Zhu Q, Sarkis J (2020) Blockchain and the circular economy: potential tensions and critical reflections from practice. Product Plan Control 31(11–12):950–966. https://doi.org/10.1080/09537287.2019.1695925
Kristoffersen E et al (2019) ‘Exploring the Relationship Between Data Science and Circular Economy : an Enhanced CRISP-DM Process Model’, in Pappas I., Mikalef P., Dwivedi Y., Jaccheri L., Krogstie J., M. M. (ed.) Digital Transformation for a Sustainable Society in the 21st Century. I3E 2019. Lecture Notes in Computer Science. https://doi.org/10.13140/RG.2.2.23182.41285.
Martín Gómez AM, Aguayo González F, Marcos Bárcena M (2018) Smart eco-industrial parks: A circular economy implementation based on industrial metabolism. Resour Conserv Recycl 135:58–69. https://doi.org/10.1016/j.resconrec.2017.08.007
Martin M, Harris S (2018) Prospecting the sustainability implications of an emerging industrial symbiosis network. Resour Conserv Recycl 138(July):246–256. https://doi.org/10.1016/j.resconrec.2018.07.026
Masi D et al (2018) Towards a more circular economy: exploring the awareness, practices, and barriers from a focal firm perspective. Production Planning & Control 29(6):539–550. https://doi.org/10.1080/09537287.2018.1449246
Matsokis A, Kiritsis D (2010) An ontology-based approach for Product Lifecycle Management. Comput Ind 61(8):787–797. https://doi.org/10.1016/j.compind.2010.05.007
Maxwell JA (1997) ‘Designing a Qualitative Study’, in The SAGE Handbook of Applied Social Research Methods, pp. 214–253
Mboli JS, Thakker DK, Mishra JL (2020) An Internet of Things-enabled decision support system for circular economy business model. Software - Practice and Experience. https://doi.org/10.1002/spe.2825
Mettler T (2011) Maturity assessment models: a design science research approach. Internatl J Soc Syst Sci 3(1/2):81. https://doi.org/10.1504/ijsss.2011.038934
Modelio (2020) Modelio_the open source modeling environment. Available at: https://www.modelio.org/
Mukherjee AA et al (2021) ‘Application of blockchain technology for sustainability development in agricultural supply chain: justification framework’. Oper Manag Res (0123456789). https://doi.org/10.1007/s12063-021-00180-5
Mukhuty S, Upadhyay A, Rothwell H (2022) ‘Strategic sustainable development of Industry 4.0 through the lens of social responsibility: The role of human resource practices’. Bus Strategy Environ (July 2021), pp. 1–14. https://doi.org/10.1002/bse.3008
Negri E et al (2016) Requirements and languages for the semantic representation of manufacturing systems. Comput Ind 81:55–66. https://doi.org/10.1016/j.compind.2015.10.009
Negri E et al (2017) Modelling internal logistics systems through ontologies. Comput Ind 88:19–34
Neligan A (2018) Digitalisation as Enabler Towards a Sustainable Circular Economy in Germany. Intereconomics 53(2):101–106. https://doi.org/10.1007/s10272-018-0729-4
Olivier S et al (2015) ‘Knowledge management for sustainable performance in industrial maintenance’, IIE Annual Conference and Expo
Peffers K, Tuunanen T, Gengler CE, Rossi M, Hui W, Virtanen V, Bragge J (2006) ‘The Design Science Research Process : A Model for Producing and Presenting Information Systems Research’, in 1st International Conference, DESRIST 2006 Proceedings. (pp. 83–106). Claremont Graduate University
Polenghi A et al (2019) ‘Conceptual framework for a data model to support Asset Management decision-making process’, in Ameri, F. et al. (eds) Advances in Production Management Systems. Production Management for the Factory of the Future. APMS 2019. IFIP Advances in Information and Communication Technology. Springer, Cham, pp. 283–290. https://doi.org/10.1007/978-3-030-30000-5_36
Raafat T et al (2013) An ontological approach towards enabling processing technologies participation in industrial symbiosis. Comput Chem Eng 59:33–46. https://doi.org/10.1016/j.compchemeng.2013.03.022
Ritzén S, Sandström GÖ (2017) Barriers to the Circular Economy - Integration of Perspectives and Domains. Procedia CIRP 64:7–12. https://doi.org/10.1016/j.procir.2017.03.005
Rosa P et al (2020) Assessing relations between Circular Economy and Industry 4.0: a systematic literature review. Int J Prod Res 58(6):1662–1687. https://doi.org/10.1080/00207543.2019.1680896
Rosa P, Sassanelli C, Terzi S (2018) ‘Circular Economy in action: uncovering the relation between Circular Business Models and their expected benefits’, in XXIII Summer School Francesco Turco – Industrial Systems Engineering. AIDI - Italian Association of Industrial Operations Professors, pp. 228–235
Sassanelli C et al (2019) The PSS design GuRu methodology : guidelines and rules generation to enhance PSS detailed design Giuditta Pezzotta and Fabiana Pirola Monica Rossi and Sergio Terzi. J Design Res 17:125–162
Sherman R (2015) ‘Fundational Data Modelling’, in Business Intelligence Guidebook, pp. 173–195. https://doi.org/10.1016/B978-0-12-411461-6.00008-3
The Ellen MacArthur Foundation (2015) Towards a circular economy: Business rationale for an accelerated transition. https://emf.thirdlight.com/link/ip2fh05h21it-6nvypm/@/preview/1?o
Tupper CD (2011) ‘Model constructs and model types’, in Data Architecture, pp. 207–221. https://doi.org/10.1016/B978-0-12-385126-0.00011-5
Tura N et al (2019) Unlocking circular business: A framework of barriers and drivers. J Clean Prod 212:90–98. https://doi.org/10.1016/j.jclepro.2018.11.202
Upadhyay A et al (2021) A review of challenges and opportunities of blockchain adoption for operational excellence in the UK automotive industry. J Global Oper Strategic Sourc 14(1):7–60. https://doi.org/10.1108/JGOSS-05-2020-0024
Vasantha GVA, Roy R, Corney JR (2015) ‘Advances in Designing Product-Service Systems’. J Indian Inst Sci 429–447
West M (2011) Developing High Quality Data Models
Zhao J, Cheung WM, Young RIM (1999) ‘A consistent manufacturing data model to support virtual enterprises’. Internatl J Agile Manag Syst
Zhou B-H, Wang S-J, Xi L-F (2005) ‘Data model design for manufacturing execution system’. https://doi.org/10.1108/17410380510627889
Funding
Open access funding provided by Politecnico di Milano within the CRUI-CARE Agreement.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors have no relevant financial or non-financial interests to disclose.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Acerbi, F., Sassanelli, C. & Taisch, M. A conceptual data model promoting data-driven circular manufacturing. Oper Manag Res 15, 838–857 (2022). https://doi.org/10.1007/s12063-022-00271-x
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s12063-022-00271-x