
Abstract
Production systems of the automotive industry process parts that were previously designed and manufactured according to different manufacturing technologies. In car body architectures, additive manufacturing (AM) has become a relevant technology for supplementing conventional manufacturing technologies, e.g., casting or forming technologies. This paper presents a methodology for an automatic and objective early-stage analysis of part features and the subsequent identification of the parts’ most suitable manufacturing technology. For this purpose, a comprehensive database is required, in which several technological and economic parameters need to be derived and predicted, including part requirements, production inherences, expected lifecycle costs, as well as geometric information. Based on this, data screening allows to effectively evaluate the technological and economic potential for a component to be manufactured either conventionally or additively in early product development phases. One core element is the part requirements derivation and analysis within one novel module of the part screening methodology. Subsequently, the product development process and the production system can be adapted according to the identified, most promising manufacturing technologies. Hence, this early-stage decision allows for cost reduction through an increased planning reliability. This work thus contributes to a successful co-evolution of smart product development and the production processes.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
1 Introduction
Considering the challenges of modern production systems, the ability to adapt themselves early and flexibly is becoming increasingly important and represents a significant competitive advantage [1]. To ensure efficient and flexible product development and production, it is important to gain certainty regarding the parts’ manufacturing technologies early in the development process [2]. To achieve this, part screening methods can be used for this early-stage selection, allowing automatic analyses of components’ characteristics part by part [3]. These methods must consider technological and economic factors to identify the most suitable technology [4, 5]. Only in that way, they enable an early-stage, holistic comparison of manufacturing scenarios while predicting or deriving component´s features.
In addition to conventional manufacturing technologies, additive manufacturing (AM, also called 3D-printing) has potential to supplement future production systems because of exclusive advantages, e.g., geometric design freedom and reduction of manufacturing tool investments [6, 7]. However, AM still needs to achieve the productivity of conventional processes, e.g., casting or forming technologies [8, 9]. Unlike other part screening approaches, this paper’s methodology thus aims at eliminating the limitation of analyzing only one manufacturing technology at a time.
First, the work at hand analyzes existing methods to assess manufacturing technologies. Then, it presents a part screening methodology consisting of four novel part screening modules. Each module addresses one of the core aspects for an early manufacturing technology selection [10, 11]:
-
The parts’ requirements (reg. corrosion, crash, and temperature resistance),
-
Production related inherences for each manufacturing scenario (e.g., joining complexity in the final product’s production line),
-
The parts’ expected costs for each manufacturing scenario,
-
Early-stage abstract geometric information (e.g., the parts’ bounding box).
In summary, the methodology and its modules enable an early-stage prediction and derivation of component features and the subsequent selection of the most suitable manufacturing technology for each individual part. As a result, the use of the methodology prevents efficiency losses that occur when developing a component according to a manufacturing technology that is subsequently identified as not suitable.
2 Part screening and evaluating technology potentials
2.1 State of the art
Design methodology in product development. Current approaches in design methodology, such as extended mapping matrices, offer manual frameworks to facilitate and intertwine design and development processes [12]. However, they are not suitable for a highly automated field like part screening. Other approaches focus on production systems design but lack insights on a component level [13].
General approaches for evaluating technology potentials. Various screening and decision-making methods are used to assess manufacturing technology potentials [14]. Some approaches focus exclusively on identifying the best technology chain setup [15]. Others aim at a systematic and early identification of rising production technologies or at an efficient substitution management [16]. Most of the technology evaluation methodologies focus on the technology and its machines itself, rather than evaluating every component individually [17].
In contrast, part screening approaches work on a component level but mostly focus on identifying suitable AM parts. However, some approaches require manual selection steps that prevent efficient assessments of many parts at a time [5, 6]. Other AM screening methodologies focus on the cost calculation of manufacturing costs but neglect further relevant parameters for an AM evaluation [18].
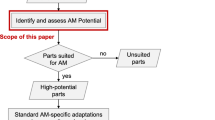
Detailed analysis of an AM part screening approach. A modular part screening approach was selected to explain and visualize AM screening [19]. This existing approach is depicted in Fig. 1. It is considered as the most suitable approach for the succeeding explanations because of the following characteristics:
-
Modular logic → suitable for necessary extensions (new modules).
-
Part screening on a component level → consistent with this paper’s methodology.
-
Application in the automotive industry → consistent application example.

Modular part screening flow chart for additive manufacturing, based on [19] (symbols according to ISO 5807)
First, data such as parts lists containing IDs, names, and masses is collected. Then, geometric data of preceding development projects is supplemented, assuming a similar design of succeeding future parts. The component data is transformed into tessellation data (angles, wall thicknesses) to quantify the geometric complexity. A k-nearest neighbor approach (supported by a reference parts database) transfers the information into geometry-related complexity classes. Parts with a high geometric complexity are more likely to be potential AM parts in future development projects. Trained neural networks for material prediction are employed to compensate for possible information gaps. Furthermore, a filling degree prediction assesses the best arrangement of the components in the building space of the 3D printer. The prediction is based on numerous historical data sets from construction jobs that trained the underlying support vector machine. Finally, historic cost data, such as the manufacturing costs and required tool investments of conventional technology alternatives complete the data base.
At last, these collected parameters serve as input variables for a fuzzy logic system. Fuzzy systems imitate the human ability to make decisions based on imprecise and non-numerical information [20]. The scaled information of the input variables is first fuzzyfied via membership functions. Then, the fuzzy values are used for a calculation and are defuzzyfied via the fuzzy output variable: the AM potential for each component [21]. More details regarding the fuzzy logic and its extensions can be found in Sect. 4.3.
2.2 Need for action
By analyzing state-of-art methods, the need for improvement is evident regarding certain critical points: current approaches either lack automation, neglect parameters, work non-predictive, or focus exclusively on one manufacturing technology.
The relevance of missing parameters was confirmed via empirical assessments of previous screening results and interviews with experts in materials science and liability approvals. Liability approvals ensure the conformance of products with legal and technological requirements. The empirical assessments of samples from preceding development projects showed that some parts with a presumed high AM potential were, in fact, not ideally suitable to be 3D-printed (see Table 1).
Specifications regarding requirements, e.g., for corrosion, crash, and temperature resistance, are highly relevant to assess manufacturing technology potentials. However, these categories are not considered in current screening approaches due to the lack of requirements information in early development phases. This first potential improvement is addressed by the new requirements derivation module, which will be presented in Sects. 3.1 and 4.1.
Another potential improvement is the economic evaluation of the components in different manufacturing scenarios. In existing screening approaches, few costs are considered and compared in a non-predictive manner, e.g., direct manufacturing costs or one-time-investments. Hence, the current approach relies on historic cost data of preceding development projects. Furthermore, a lifecycle analysis must include the steps before and after production of the components [22]. Another decisive factor is the quantification of the respective technology’s advantages, e.g., lightweight design [23, 24]. Conducting a cost comparison at an early stage in product development inevitably requires a cost prediction to fill information gaps. This predictive cost estimation is addressed in the second and third new module, which will be presented as concepts in Sects. 3.2 and 4.2.
This paper hence contributes to overcoming the lack of automated, early-stage technology selection approaches on a component level. The modules aim at answering the following research questions:
-
1.
How can relevant screening parameters be derived and predicted early in product development?
-
2.
How can the methodology and its modules ensure an automated approach that is suitable for large amounts of data and components?
-
3.
How can manufacturing scenarios be compared objectively for each individual component?
3 General methodology for an automated manufacturing technology selection in early development phases
The methodology consists of novel modules that provide new parameters for the evaluation of manufacturing scenarios for each individual component, as illustrated in Fig. 2. Three of the four modules will be elaborated upon in Sects. 3 and 4: The requirements module, the production module, and the cost prediction module.

Early-stage part screening for an automatic selection of the most suitable manufacturing technology for each component
Each module faces the challenge of analyzing parts regarding the most promising manufacturing technology before necessary information is available. Hence, the modules process and predict data to provide the overarching screening methodology and its fuzzy inference systems with necessary information (see Fig. 3).

The modules’ general steps for an early-stage derivation and prediction of data
3.1 Requirements module: automatic early-stage derivation of part requirements

The requirements module was elaborated to test the following hypothesis: The derivation and consideration of part requirements is essential for an early and precise evaluation of manufacturing technology potentials in part screening.
The most suitable manufacturing technology must be selected early in product development, even though some requirements might not yet be specified. Hence, a requirements module was developed, which derives part requirements based on the location (building areas) in the final product (see Fig. 4). To ensure a reliable and predictive derivation, predesign information is used: the final product’s building areas must be manually assigned with expert knowledge and data of requirement sheets (one-time step, see Fig. 5). Subsequently, components can be automatically allocated to building areas based on their coordinates allowing for a derivation of requirement classes. Relevant requirements categories include corrosion, crash, and temperature. These are used as examples for demonstrating the logic of the requirements classification in three increments: high requirements, medium requirements, and low requirements. The requirements module will be exemplarily executed in Sect. 4.1.

General steps for deriving part requirements early in product development

Requirement sheets and expert data used to assign requirement classes to building areas
3.2 Production module and cost module: estimating costs early in product development

Production module. The production module generates information regarding the different manufacturing scenarios for each part and their effect on the production line.
Predicting the joining complexity: After a training phase with historic data, abstract geometric information is used to estimate the parts’ joining complexity (JC) in the final product’s production line for each manufacturing scenario. The joining complexity is quantified using the 2014 Harbour Report Methodology. It enables a quantitative comparison of relevant joining technologies by standardizing the joining complexity with spot welding as a reference, as illustrated in Table 2 [25].
Deriving further parameters: The production module generates further data based on user selections, such as the intended production location or the so-called commodity scenarios. Backend production data (e.g., the plant’s clock rate, production quantities) and inbound logistics information for purchased parts can thus be derived for each manufacturing scenario. Furthermore, it roughly estimates the technologies’ lightweight potentials based on implemented expert knowledge and suggests the merger of smaller, separate parts for the AM and the casting scenario. These integral suggestions are based on similar materials, wall thicknesses, and adjoining locations.
Finally, the production module transmits the generated data to the cost module to contribute to an early cost prediction (see Fig. 6).

The production module predicts and derives information for the succeeding cost module
Cost prediction module. First, historic cost data must be collected to enable the subsequent training of prediction models. Machine planning and start-up costs supplement manufacturing costs and one-time investments. Costs associated with the production process, such as costs for inbound logistics, storage, and production line investments also need to be added [26]. The different cost positions are analyzed regarding their relevance for the lifecycle view. To ensure a successful training, clustering methods identify patterns in the historic data sets, such as suitable input features and specific cost structures of different manufacturing technologies. Following the data collection, different cost prediction algorithms are trained with historic data for each cost type: Linear Regressions, Neural Nets, Random Forrests and Ensemble Learning Models. The best performing prediction model is selected for each cost type based on statistical figures (bias, variance, R2-value, mean absolute error) and accuracy plots (see Fig. 7).

Exemplary accuracy plot of cost type A and prediction model A (e.g., a Neural Net)
Future costs can thus be estimated for different manufacturing scenarios to fill information gaps of upcoming development projects at an early point in time (see Fig. 8).

General steps for a predictive estimation of costs early in product development
3.3 Part screening: uniting and analyzing the modules’ outputs

Each module predicts and derives data and provides the part screening methodology with necessary information to evaluate the different manufacturing scenarios. To handle the different kinds of modular information (quantitative data, requirement classes, etc.), the screening methodology uses fuzzy rule sets for each manufacturing scenario (see Fig. 9). These fuzzy rules embody expert knowledge and thus represent the strengths and weaknesses of each manufacturing technology. Exemplary fuzzy rules can be found in Sect. 4.3.

Uniting and analyzing the modules’ outputs with fuzzy rules
Concluding Sect. 3, the expanded part screening flow chart is illustrated in Fig. 10, containing the four new modules that contribute to an automated early stage manufacturing technology comparison.

Extended screening flow chart for an early manufacturing technology selection
4 Exemplary application: car body development
The automotive industry serves as an application example for introducing three of the new modules. The detailed construction and design of car body parts relies on the previous, early-stage selection of the respective manufacturing technology for each part (see Fig. 11). So far, this decision is based on human experience or non-automatic evaluations and is hence biased towards the status quo of preceding product developments. The modules address this issue by quantifying and objectifying relevant input and output parameters to minimize the human bias. An early technology selection inevitably implies a critical data availability since there is no holistic component information before the construction and design phase. To overcome this challenge, the modules will fill these information gaps with predictions and derivations based on elementary data that exists in early development phases, e.g.:
-
The parts’ rough geometry (bounding box).
-
The parts’ rough volume and mass.
-
The parts’ installation location in the final product (the car body).

Early application of the methodology in product development
4.1 Requirements module: automatic early-stage derivation of part requirements

Car Body Area Logic. The overarching goal is to automatically derive component requirements using input sources that exist early in product development processes, e.g. specification sheets, part names, and part installation locations. To achieve this, the vehicle architecture was divided into car body areas on a coordinate basis. The selected reference model comprises 89 cuboids as car body areas. One exemplary layer of car body areas is illustrated in Fig. 12. By using specification sheets, requirements management systems, and expert knowledge, a requirements definition was developed for each car body area. The two exemplary data sets in Fig. 12 depict the coordinates and applicable requirements of two car body areas.

Exemplary layer of the car body area division with two exemplary data sets, including the assigned requirement classes
Transferability to differing vehicle architectures. A major challenge to achieve the automatic assignment of components to car body areas is the transferability to differing vehicle architectures, which vary significantly in terms of coordinates. Two vehicle models serve as examples for the following explanations: base model (index b) builds the basis, focus model (index f) represents the target for the intended car body area conversion.
To ensure this portability, conversion formulas were developed based on the manually built base model and existing vehicle dimension databases. These formulas automatically stretch or compress the car body areas of the base model, allowing to flexibly fit the focus model’s car body architecture (see Fig. 13). The dimension databases contain more than 200 dimensions, such as different wheelbases, vehicle widths, etc. (see Fig. 14). These databases exist early in the product development process and include various vehicle types (sedan, SUV, sport) and drive variants (battery electric or combustion engine). In some cases, the variances between certain car body areas of different vehicle architectures were too big to be covered by the conversion formulas. To address this issue, a base model and respective car body areas were defined for different types of vehicle architectures.

Logic for the automatic adaption of car body area coordinates from base model b to focus model f using the existing vehicle dimension database

Exemplary dimensions III and VII: gauge front and back
Furthermore, expert knowledge about the correlation of dimension differences between base model b and focus model f and their effect on car body area coordinates was implemented (see Table 3 and Fig. 14). This knowledge also differentiates between redundant and cumulative dimension effects. For instance, some dimensions are allocated parallel to each other. In this case, only one of the parallel dimensions need to be considered to calculate the correct conversion factor. On the other hand, dimensions can also be aligned serially, causing a cumulative effect that requires considering several dimensional differences to correctly stretch or compress the respective car body area (see Eqs. 2 and 3). In combination with the conversion formulas, the implemented knowledge enables a derivation of the car body areas’ change on a coordinate basis.
Since neighboring car body areas inevitably share coordinates, calculated coordinates are also valid for the respective car body areas that adjoin. Hence, shared coordinates are adopted by neighboring car body areas (see Fig. 15). This adoption avoids superfluous calculations of shared coordinates and gaps between adjoining areas.

Exemplary logic for adopting shared coordinates between neighboring body areas
The conversion formulas work as follows: dimensions (DX, DY, DZ) are automatically gathered from the existing databases in x, y, and z direction for base model b and focus model f. Afterwards, percentage deviations between dimensions of the base model and the focus model can be quantified and converted into conversion factors FX, FY, or FZ for all three coordinate directions and each dimension(i), where i is the running index (Eq. 1).
Next, the manually built base model’s car body areas (running index j) are stretched or compressed by multiplying its coordinates with relevant conversion factors (Eqs. 2 and 3). The coordinates of one car body area can be affected by more than one dimension, potentially leading to a sum of relevant conversion factors in Eqs. 2 and 3 according to the implemented expert knowledge (see Table 2).
Additionally, Table 4 and Fig. 16 help to understand the equations by providing an exemplary calculation of the coordinates of focus model car body area 7.

Exemplary adaption of car body area 7 from base model b to focus model f, using Eq. 1 and Eq. 2.1 with 2.2
The combination of calculating further changes and adopting shared coordinates enables an automatic adaptation of all car body areas, thus leading to a comprehensive car body area model. Hence, this automatic adaption achieves the goal of ensuring a transferability of the methodology to differing car models.
Application and output of the requirements module. By using existing parts lists as an input, components from a wide range of vehicle architectures can be automatically allocated to car body areas based on their coordinates. This assignment allows an auto-matic derivation of requirements that the components need to fulfill (see Figs. 17, 18). The derivation of crash requirements is supplemented with information drawn out of specific crash databases. The gained knowledge regarding the requirements enriches the fuzzy logic system for the manufacturing technology potential assessment, as described in Sect. 4.3. Furthermore, an approach related to named entity recognition is applied: The components names are being searched for defined strings and combined with the automatic allocation in a specific car body area to enable a functionality classification for each part. Unlike the usual named entity recognition, this approach focuses on words only rather than full sentences [27]. Exemplary functionalities include sealing, directing strains, connecting parts, or deliberate deforming in crash scenarios. For instance, if the comp-

Relevant excerpt of Fig. 10

Logic of assigning parts (existing info in light blue) to car body areas for deriving requirement classes and functionalities for three exemplary parts
onent’s name contains strings such as {strut, reinforcement, column, crash} or if the component is installed in the car body area of a suspension strut dome, the primary task is that of guiding high forces and strains. The knowledge regarding these functionalities allows further analyses and fuzzy rule extensions that are currently being developed.
4.2 First steps towards the cost prediction

Production module. The production module provides the cost module with necessary data to allow for a cost prediction on a component level.
As a first step, a feature database must be built to enable the prediction training and the future derivation of production parameters based on user selections. The database contains abstract geometry data and production information of preceding product generations (see Table 5).
After a successful training and validation phase, the joining complexity can be predicted for each manufacturing scenario. Furthermore, the user can select the intended production location and the relevant vehicle segment (SUV, coupé). Based on that, the module’s backend derives further parameters (see Table 6). Finally, the production module transmits the gathered data to the cost module (see Fig. 19).

Relevant excerpt of Fig. 10
Cost module. Table 7 shows exemplary data sets for the first step towards cost prediction: collecting historic data for prediction training. It is evident that costs for production are higher when the part is manufactured additively. Nonetheless, AM parts offer benefits such as lightweight design opportunities and do not require tool investments due to the geometrical variability of the 3D-printing machines [28, 29].
The cost data is supplemented with the geometric and production related data as input features, to allow for the subsequent training and selection of cost prediction models (see Fig. 20). Each cost type requires specific input features that can be identified through correlation analyses of the historic data. Based on the production module’s output, the cost prediction models estimate costs for each manufacturing scenario to identify the cheapest manufacturing technology for each part.

Relevant excerpt of Fig. 10
4.3 Integrating the new modules into the screening methodology

The modules’ outputs are requirement classes and cost information for each component and manufacturing scenario, which in turn serve as an input for the fuzzy logic system (see Table 8).
The fuzzy logic system. The new requirements fuzzy rules were developed in close collaboration with experts from material sciences and liability approvals. Hence, the rules illustrate the current capabilities of the respective manufacturing technology to fulfill challenging requirements. The exemplary use case in the automotive industry thus leads to the fuzzy inference system (fis) and rule set below. Since an AM potential assessment is used for validating the expanded rule set, the selected examples focus on the rules for evaluating the parts’ AM potentials. Further rules of other manufacturing technologies and input parameters are represented by excerpts.
Setting up the fuzzy inference system:

Defining the requirement parameters as fuzzy input variables:

AM-Rules resulting from the novel requirements module:

Rules resulting from other modules, e.g. the novel cost prediction module:

Validating the new requirements fuzzy rules. The desired positive effect of the requirement fuzzy rules on the quality of the potential assessment was validated through an exemplary AM potential analysis. First, the fuzzy logic was applied with and without the novel requirements fuzzy rules for 28 validation parts. These validation parts were selected based on previous AM potential assessments. By integrating requirements into the fuzzy logic system, the main hypothesis was confirmed through a more precise potential assessment:
The AM potential is quantified on a scale from 0 to 100 by the fuzzy logic system. When taking the requirements into account, some validation parts lost significant AM potential. The AM potential loss resulted from high requirements and led to a decrease in the overall ranking, as indicated by the ranking position in brackets in Table 9. In contrast, low requirements did not have a negative impact on the AM potential which led to a higher placement in the AM potential ranking. Figure 21 depicts the relative AM potential loss, a ratio of the AM potential loss and the previous AM potential evaluation without the novel fuzzy rules. To quantify the average requirements class regarding the three requirements categories per part, the three increments were replaced by numeric values: high ≙ 3, medium ≙ 2, low ≙ 1. Parts that already had a low AM potential before introducing the novel fuzzy rules did not lose significantly more potential due to high requirements (see orange area in Fig. 21). However, the current fuzzy rules need to be constantly updated regarding potential technological developments and an increasing number of completed liability approvals in AM. These developments might lead to an increasing robustness of AM parts to challenging requirements.

Correlation between assigned requirement classes and the parts’ AM potential loss
The rule set extension thus avoids false screening assessments that previously had to be manually corrected by an expert at a later point in time. For instance, some of the validation parts were ranked very highly in former AM potential assessments that did not take requirements into account. Subsequently, many of those parts were identified as not suitable for AM due to challenging requirements and missing liability approvals (e.g., first part in Table 9). However, without novel AM liability approvals, e.g. for AM coating processes, these parts are not capable of resisting corrosion-related challenges in the long term, as confirmed by experts in material sciences. These imprecise screening assessments caused an efficiency loss that can now be avoided early in the development process. Accordingly, the novel fuzzy rules also support the differentiation within conventional manufacturing technologies in part screening. E.g. casting parts lack robustness to high crash loads.
5 Summary and outlook
The analysis of existing technology evaluation methods shows a lack of automated, early-stage technology selection approaches on a component level. This paper thus proposes a part screening methodology to select a manufacturing technology for each individual component in early development phases. In general, four core aspects need to be considered in a predictive manner for such a technology comparison and selection: the parts’ requirements, production related inherences, the parts’ expected costs, and early-stage abstract geometric information (e.g. bounding box) for each manufacturing scenario. These four fields are addressed by one module each, providing the overarching part screening methodology and its fuzzy rules with essential predictions and derived information. Three of the modules were introduced in this paper. These modules were exemplarily applied in the car body development. The requirements module offers the following achievements:
Addressing research question 1:
-
Part requirements can be derived early in product development based on specification lists, requirements management systems, and part coordinates.
-
Addressing research question 2:
-
Components can thus be automatically classified according to different requirement classes and functionalities.
-
The described requirements analysis methodology can be automatically adapted to differing product architectures, ensuring its general applicability.
-
Addressing research question 3:
-
The outputs of the requirements module are suitable for expanding and specifying the fuzzy logic system.
-
A validation analysis (AM focus) confirmed a more precise technology assessment, corroborating the main hypothesis of this paper:
-
Considering requirements in part screening leads to more precise manufacturing technology potential assessments.
-
The necessity of manually correcting former screening results due to neglected requirements can be avoided.
Additionally, the production module and the cost prediction module were conceptually introduced. First, historic cost data is clustered and analyzed to identify cost patterns and input features for cost prediction. Potential input features are the parts quantities, abstract geometric information, and production related information. Production related data is predicted and derived by the production module to provide the cost module with necessary input features. Based on that, a technology-dependent cost estimation and comparison for future product developments can be trained and conducted at an early point in time.
In conclusion, this paper provides an outlook on necessary scientific efforts within the scope of the topic at hand. To ensure an early-stage and automated manufacturing technology comparison for a variety of parts, all four core aspects (requirements, production environment, expected costs, abstracted geometry) need to be considered. The remaining modules will be published in the main author’s upcoming articles. Finally, each module’s fuzzy rules will be assessed by applying a sensitivity analysis.
References
Piller FT (2006) Mass customization: ein wettbewerbsstrategisches konzept im Informationszeitalter, 4th edn. Dit. Univ, Uttarakhand, pp 39–40. https://doi.org/10.1007/978-3-8350-9204-4
Schmenner RW, Swink ML (1998) On theory in operations management. J Oper Manag Wiley 17(1):97–113. https://doi.org/10.1016/S0272-6963(98)00028-X
Gänsicke T, Sandiano J (2015) Systematische Bewertung von Leichtbaupotenzialen in der Fahrzeugentwicklung. Lightweight Des Springer 2(2015):42–46. https://doi.org/10.1007/s35725-015-0019-z
Baumers M, Holweg M (2019) On the economics of additive manufacturing: experimental findings. J Oper Manag Wiley 65(8):794–809. https://doi.org/10.1002/joom.1053
Vayre B, Vignat F, Villeneuve F (2013) Identification on some design key parameters for additive manufacturing: application on electron beam melting. In: 46th CIRP conference, Sesimbra, Portugal, pp. 264–269. DOI https://doi.org/10.1016/2013.05.045.
Borille AV, de Oliveira GJ (2011) Selection of additive manufacturing technologies using decision methods. InTech, USA, pp 29–53. https://doi.org/10.5772/24045
Huang Y, Leu MC, Mazumder J, Donmez A (2015) Additive manufacturing: current state, future potential, gaps and needs, and recommendations. J Manuf Sci Eng 137:014001–014003. https://doi.org/10.1115/1.4028725
Lindemann C, Koch R (2016) Cost efficient design and planning for Additive Manufacturing technologies. In: 27th annual international solid freeform symposium, University of Texas, Austin, USA, pp 93–110
Lindemann C, Jahnk U, Reiher T, Koch R (2015) Towards a sustainable and economic selection of part candidates for Additive Manufacturing. In: Annual international solid freeform symposium, University of Texas, Austin, USA, pp 935–949, DOI https://doi.org/10.1108/RPJ-12-2014-0179.
Nandhakumar S, Thirumalai R, Viswaaswaran J, Senthil TA, Vishnuvardhan VT (2020) Investigation of production costs in manufacturing environment using innovative tools. Mater Today Proc. https://doi.org/10.1016/j.matpr.2020.06.433
Nagulpelli KS, King RE, Warsing D (2019) Integrated traditional and additive manufacturing production profitability model. ScienceDirect Proc Manuf. https://doi.org/10.1016/j.promfg.2019.06.121
Kleemann S, Fröhlich T, Vietor T, Türck E (2017) A methodological approach towards multi-material design of automotive components. Proced CIRP 60:68–73. https://doi.org/10.1016/j.procir.2017.01.010
Dante CB, Luis EV, Jhonattan M, Arturo M, Rafael B, Inti G, Emilio G, Jaime P (2018) Methodology to support manufacturing system design using digital models and simulations: an automotive supplier case study. IFAC-PapersOnLine 51(11):1598–1603. https://doi.org/10.1016/j.ifacol.2018.08.267
Reiher T, Lindemann C, Jahnke U, Deppe G, Koch R (2017) Holistic approach for industrializing AM technology: from part selection to test and verification. Prog Addit Manuf Springer. https://doi.org/10.1007/s40964-017-0018-y
Schindler S (2014) Strategische planung von technologieketten für die produktion. TU Munich, http://mediatum.ub.tum.de/?id=1188825.
Greitemann J (2016) Methodik für die systematische identifikation von produktionstechnologien. TU Munich, http://mediatum.ub.tum.de/?id=1292557.
Hofer A, Schnell J, Beck B, Reinhart G (2019) Potential-based technology planning for production companies. Proced CIRP 81:1400–1405
Rudolph JP (2018) Cloudbasierte potentialbewertung für die additive fertigung. Springer, Light Engineering für die Praxis. https://doi.org/10.1007/978-3-662-58263-3
Schumacher F (2021) Methodische Identifikation und Entwicklung von Automobilkomponenten für die additive Serienfertigung. TU Braunschweig.
Valaskova K, Kliestik T, Misankova M (2014) The role of Fuzzy Logic in Decision Making Process. In: 2nd International conference on management innovation and business innovation, Bangkok, Thailand.DOI https://doi.org/10.5729/lnms.vol44.143
Vinodh S, Sakthi N, Jeya G (2014) Application of fuzzy VIKOR for selection of rapid prototyping technologies in an agile environment. Rapid Prototyp J Emerald 20(6):523–532. https://doi.org/10.1108/RPJ-07-2012-0060
Knofius N, van der Heijden M, Zijm WHM (2016) Selecting parts for additive manufacturing in service logistics. J Manuf Technol Manag Emerald 27(7):915–931. https://doi.org/10.1108/JMTM-02-2016-0025
Mançanares CG, Zancul ES, Cavalcante da Silva J, Cauchick Miguel PA (2014) Additive manufacturing process selection based on parts’ selection criteria. Int J Adv Manuf Technol Springer 93:869–880. https://doi.org/10.1007/s00170-015-7092-4
Laplume AO, Petersen B, Pearce JM (2016) Global value chains from a 3D printing perspective. J Int Bus Stud 47(5):595–609. https://doi.org/10.1057/jibs.2015.47
Harbour, R (2014) The harbour report. Automotive Industry Publication of Oliver Wyman.
Lindemann C, Jahnke U (2017) Modelling of laser additive manufactured product lifecycle costs. Laser Addit Manuf. https://doi.org/10.1016/B978-0-08-100433-3.00011-7
Jing L, Aixin S, Jianglei H, Chenliang L (2020) A survey on deep learning for named entity recognition. IEEE Trans Knowl Data Eng 99:1–1. https://doi.org/10.1109/TKDE.2020.2981314
Lachmayer R, Lippert RB (2016) Additive manufacturing quantifiziert. Springer, Berlin, pp 49–63. https://doi.org/10.1007/978-3-662-54113-5
Baumers M, Dickens P, Tuck C, Hague R (2016) The cost of additive manufacturing: machine productivity, economies of scale and technology-push. Technol Forecast Soc Change. https://doi.org/10.1016/j.techfore.2015.02.015
Acknowledgements
This work was carried out as part of a cooperative project between the Technical University of Munich and the BMW Group.
Funding
Open Access funding enabled and organized by Projekt DEAL.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Buechler, T., Schumacher, F., Reimann, P. et al. Methodology for an automatic and early manufacturing technology selection on a component level. Prod. Eng. Res. Devel. 16, 23–41 (2022). https://doi.org/10.1007/s11740-021-01070-2
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11740-021-01070-2