
Abstract
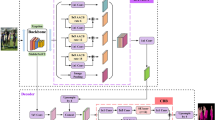
Current semantic segmentation methods have high accuracy. However, it has the disadvantage of high computational complexity and time consumption, which makes it difficult to meet the application requirements in complex environments. To achieve fast and accurate semantic segmentation of images, we propose a lightweight semantic segmentation method called Light-Deeplabv3+. First, a MobileNetV2Lite-SE architecture with SE module is proposed as the backbone network of the model, which can reduce the number of model parameters and improve the segmentation speed. Second, we propose an ACsc-ASPP module based on asymmetric dilated convolution block (ADCB) and scSE module to solve the semantic information loss during feature extraction. Our improvements can obtain more semantic features and improve segmentation accuracy. Finally, we propose a DSC-Blaze module to replace the original \(3\times 3\) standard convolution. It consists of depthwise separable convolution (DSC) and Blaze module, which can improve the model segmentation speed while maintaining the receptive field. The experimental results prove that the Mean Intersection over Union (MIoU) of Light-Deeplabv3+ on the PASCAL VOC2012 dataset is 73.15\(\%\), and the parameter size is only 6.291MB. Its calculation amount is only 20.883G, and the speed on the 3060Ti platform is 37.66 frames per second (FPS). Compared with traditional Deeplabv3+, Light-Deeplabv3+ can achieve efficient and accurate image segmentation results with less computational overhead, and its performance is comparable to state-of-the-art algorithms.











Similar content being viewed by others


Data availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Bazarevsky, V., Kartynnik, Y., Vakunov, A., et al.: Blazeface: Sub-millisecond Neural Face Detection on Mobile gpus. arXiv preprint arXiv:1907.05047 (2019)
Chen, J., Liu, Z., Jin, D., et al.: Light transport induced domain adaptation for semantic segmentation in thermal infrared urban scenes. IEEE Trans. Intell. Transp. Syst. 23(12), 23194–23211 (2022)
Chen, L., Papandreou, G., Kokkinos, I.: Semantic image segmentation with deep convolutional nets and fully connected crfs. In: 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7–9, 2015, Conference Track Proceedings (2015). arXiv:1412.7062
Chen, L.C., Papandreou, G., Kokkinos, I., et al.: Deeplab: semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 40(4), 834–848 (2017)
Chen, L.C., Papandreou, G., Schroff, F., et al.: Rethinking Atrous Convolution for Semantic Image Segmentation, vol. 2. arXiv preprint arXiv:1706.05587 (2019)
Chen, L.C., Zhu, Y., Papandreou, G., et al.: Encoder–decoder with atrous separable convolution for semantic image segmentation. In: Proceedings of the European Conference on Computer Vision (ECCV), pp. 801–818 (2018)
Chollet, F.: Xception: deep learning with depthwise separable convolutions. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21–26, 2017, pp. 1800–1807. IEEE Computer Society (2017). https://doi.org/10.1109/CVPR.2017.195
Ding, X., Guo, Y., Ding, G.: Acnet: Strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks. In: 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27–November 2, 2019, pp. 1911–1920. IEEE (2019). https://doi.org/10.1109/ICCV.2019.00200
Fu, J., Liu, J., Tian, H.: Dual attention network for scene segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16–20, 2019, pp. 3146–3154. Computer Vision Foundation/IEEE (2019)
Gao, X., Bai, H., Xiong, Y., et al.: Robust lane line segmentation based on group feature enhancement. Eng. Appl. Artif. Intell. 117, 105568 (2023)
He, K., Zhang, X., Ren, S., et al.: Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 37(9), 1904–1916 (2015)
Howard, A.G., Zhu, M., Chen, B., et al.: Mobilenets: Efficient Convolutional Neural Networks for Mobile Vision Applications. arXiv preprint arXiv:1704.04861 (2017)
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pp. 7132–7141 (2018)
Li, H., Xiong, P., Fan, H.: Dfanet: Deep feature aggregation for real-time semantic segmentation. In: IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2019, Long Beach, CA, USA, June 16–20, 2019, pp. 9522–9531 (2019)
Lin, Z., Sun, W., Tang, B., et al.: Semantic segmentation network with multi-path structure, attention reweighting and multi-scale encoding. Vis. Comput. 39(2), 597–608 (2023)
Minaee, S., Boykov, Y., Porikli, F., et al.: Image segmentation using deep learning: a survey. IEEE Trans. Pattern Anal. Mach. Intell. 44(7), 3523–3542 (2021)
Noh, H., Hong, S., Han, B.: Learning deconvolution network for semantic segmentation. In: 2015 IEEE International Conference on Computer Vision, ICCV 2015, Santiago, Chile, December 7–13, 2015, pp. 1520–1528. IEEE Computer Society (2015). https://doi.org/10.1109/ICCV.2015.178
Paszke, A., Chaurasia, A., Kim, S., et al.: Enet: A Deep Neural Network Architecture for Real-time Semantic Segmentation. arXiv preprint arXiv:1606.02147 (2016)
Qureshi, I., Yan, J., Abbas, Q., et al.: Medical image segmentation using deep semantic-based methods: a review of techniques, applications and emerging trends. Inf. Fusion 90, 316–352 (2022)
Roy, A.G., Navab, N., Wachinger, C.: Concurrent spatial and channel ’squeeze & excitation’ in fully convolutional networks. In: Medical Image Computing and Computer Assisted Intervention—MICCAI 2018—21st International Conference, Granada, Spain, September 16–20, 2018, Proceedings, Part I, Lecture Notes in Computer Science, vol. 11070, pp. 421–429. Springer (2018). https://doi.org/10.1007/978-3-030-00928-1_48
Sandler, M., Howard, A.G., Zhu, M.: Mobilenetv2: inverted residuals and linear bottlenecks. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18–22, 2018, pp. 4510–4520. Computer Vision Foundation/IEEE Computer Society (2018)
Wang, Z., Wang, J., Yang, K., et al.: Semantic segmentation of high-resolution remote sensing images based on a class feature attention mechanism fused with deeplabv3+. Comput. Geosci. 158, 104969 (2022)
Xu, H., Wang, S., Huang, Y.: Fpanet: feature-enhanced position attention network for semantic segmentation. Mach. Vis. Appl. 32, 1–9 (2021)
Yi, Q., Dai, G., Shi, M.: Elanet: effective lightweight attention-guided network for real-time semantic segmentation. Neural Process. Lett. 55(12), 1–18 (2023)
You, L., Jiang, H., Hu, J., et al.: Gpu-accelerated faster mean shift with Euclidean distance metrics. In: 2022 IEEE 46th Annual Computers, Software, and Applications Conference (COMPSAC), pp. 211–216. IEEE (2022)
Yu, F., Koltun, V.: Multi-scale context aggregation by dilated convolutions. In: 4th International Conference on Learning Representations, ICLR 2016, San Juan, Puerto Rico, May 2–4, 2016, Conference Track Proceedings (2016). arXiv:1511.07122
Zhao, H., Shi, J., Qi, X.: Pyramid scene parsing network. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21–26, 2017, pp. 6230–6239. IEEE Computer Society (2017). https://doi.org/10.1109/CVPR.2017.660
Zhao, M., Jha, A., Liu, Q., et al.: Faster mean-shift: Gpu-accelerated clustering for cosine embedding-based cell segmentation and tracking. Med. Image Anal. 71, 102048 (2021)
Zhao, M., Liu, Q., Jha, A., et al.: Voxelembed: 3d instance segmentation and tracking with voxel embedding based deep learning. In: Machine Learning in Medical Imaging: 12th International Workshop, MLMI 2021, Held in Conjunction with MICCAI 2021, Strasbourg, France, September 27, 2021, Proceedings vol. 12, pp. 437–446. Springer (2021)
Zheng, Z., Hu, Y., Guo, T., et al.: Aghrnet: An attention ghost-hrnet for confirmation of catch-and-shake locations in jujube fruits vibration harvesting. Comput. Electron. Agric. 210, 107921 (2023)
Zhou, E., Xu, X., Xu, B., et al.: An enhancement model based on dense atrous and inception convolution for image semantic segmentation. Appl. Intell. 53(5), 5519–5531 (2023)
Acknowledgements
This work is supported by the Key-Area Research and Development Program of Guangdong Province under Grant 2020B0909020001, the National Natural Science Foundation of China under Grant No.61573113.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ding, P., Qian, H. Light-Deeplabv3+: a lightweight real-time semantic segmentation method for complex environment perception. J Real-Time Image Proc 21, 1 (2024). https://doi.org/10.1007/s11554-023-01380-x
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11554-023-01380-x