
Abstract
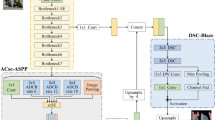
Semantic segmentation can help the perception link to better build an understanding of complex scenes, and can assist the unmanned system to better perceive the scene content. To address the problem of detailed information loss and segmentation edge blur in the semantic segmentation task for complex scenes, we propose a modified version of Deeplabv3+ based on the improved ASPP and fusion module. Firstly, we propose an RA-ASPP module combining residual network and asymmetric atrous convolution block (AACB), which further enriches the scale of feature extraction and achieves denser multi-scale feature extraction. It significantly enhances the representation power of the network. Then, we propose a parallel fusion module named convolution combine with bottleneck block (CBB), which combines 1\(\times\)1 convolution and bottleneck block to reduce the information loss in the whole network transmission process. We perform ablation experiments on the PASCAL VOC2012 dataset. When the backbone is Xception, the Mean Intersection over Union (MIoU) of Ours1 is 79.78\(\%\). At the cost of 1.72 frames per second (FPS), its MIoU is 2.81\(\%\) faster than Deeplabv3+. The proposed modules significantly improve the accuracy in semantic segmentation and achieve segmentation results comparable to state-of-the-art algorithms. When MobileNetV2 is the backbone, Ours2 achieves 37.54FPS and a MIoU of 73.32\(\%\), which ensures a balance between real-time segmentation speed and accuracy. In summary, our proposed modified module improves the segmentation performance of Deeplabv3+, and the different backbones also provide additional options for semantic segmentation tasks in complex scenes.










Similar content being viewed by others

Data availability
The data used to support the findings of this study are available from the corresponding author upon request.
References
Ahmed, I., Ahmad, M., Jeon, G.: A real-time efficient object segmentation system based on u-net using aerial drone images. J. Real Time Image Process. 18(5), 1745–1758 (2021). https://doi.org/10.1007/s11554-021-01166-z
Badrinarayanan, V., Kendall, A., Cipolla, R.: Segnet: A deep convolutional encoder-decoder architecture for image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 39(12), 2481–2495 (2017). https://doi.org/10.1109/TPAMI.2016.2644615
Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Semantic image segmentation with deep convolutional nets and fully connected crfs. In: Y. Bengio, Y. LeCun (eds.) 3rd International Conference on Learning Representations, ICLR 2015, San Diego, CA, USA, May 7-9, 2015, Conference Track Proceedings (2015). http://arxiv.org/abs/1412.7062
Chen, L., Papandreou, G., Kokkinos, I., Murphy, K., Yuille, A.L.: Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. CoRR abs/1606.00915 (2016). http://arxiv.org/abs/1606.00915
Chen, L., Papandreou, G., Schroff, F., Adam, H.: Rethinking atrous convolution for semantic image segmentation. CoRR abs/1706.05587 (2017). http://arxiv.org/abs/1706.05587
Chen, L., Zhu, Y., Papandreou, G., Schroff, F., Adam, H.: Encoder-decoder with atrous separable convolution for semantic image segmentation. In: V. Ferrari, M. Hebert, C. Sminchisescu, Y. Weiss (eds.) Computer Vision - ECCV 2018 - 15th European Conference, Munich, Germany, September 8-14, 2018, Proceedings, Part VII, Lecture Notes in Computer Science, vol. 11211, pp. 833–851. Springer (2018). https://doi.org/10.1007/978-3-030-01234-2_49
Chollet, F.: Xception: Deep learning with depthwise separable convolutions. In: 2017 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2017, Honolulu, HI, USA, July 21-26, 2017, pp. 1800–1807. IEEE Computer Society (2017). https://doi.org/10.1109/CVPR.2017.195
Ding, X., Guo, Y., Ding, G., Han, J.: Acnet: Strengthening the kernel skeletons for powerful CNN via asymmetric convolution blocks. In: 2019 IEEE/CVF International Conference on Computer Vision, ICCV 2019, Seoul, Korea (South), October 27 - November 2, 2019, pp. 1911–1920. IEEE (2019). https://doi.org/10.1109/ICCV.2019.00200
He, K., Zhang, X., Ren, S., Sun, J.: Deep residual learning for image recognition. In: 2016 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2016, Las Vegas, NV, USA, June 27-30, 2016, pp. 770–778. IEEE Computer Society (2016). https://doi.org/10.1109/CVPR.2016.90
Howard, A.G., Zhu, M., Chen, B., Kalenichenko, D., Wang, W., Weyand, T., Andreetto, M., Adam, H.: Mobilenets: Efficient convolutional neural networks for mobile vision applications. CoRR abs/1704.04861 (2017). http://arxiv.org/abs/1704.04861
Hu, J., Shen, L., Sun, G.: Squeeze-and-excitation networks. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pp. 7132–7141. Computer Vision Foundation / IEEE Computer Society (2018)
Liu, J., Zhang, F., Zhou, Z., Wang, J.: Bfmnet: Bilateral feature fusion network with multi-scale context aggregation for real-time semantic segmentation. Neurocomputing 521, 27–40 (2023). https://doi.org/10.1016/j.neucom.2022.11.084
Long, J., Shelhamer, E., Darrell, T.: Fully convolutional networks for semantic segmentation. CoRR abs/1411.4038 (2014). http://arxiv.org/abs/1411.4038
Park, J., Yoo, H., Wang, Y.: Drivable dirt road region identification using image and point cloud semantic segmentation fusion. IEEE Trans. Intell. Transp. Syst. 23(8), 13203–13216 (2022). https://doi.org/10.1109/TITS.2021.3121710
Ronneberger, O., Fischer, P., Brox, T.: U-net: Convolutional networks for biomedical image segmentation. In: N. Navab, J. Hornegger, W.M.W. III, A.F. Frangi (eds.) Medical Image Computing and Computer-Assisted Intervention - MICCAI 2015 - 18th International Conference Munich, Germany, October 5 - 9, 2015, Proceedings, Part III, Lecture Notes in Computer Science, vol. 9351, pp. 234–241. Springer (2015). https://doi.org/10.1007/978-3-319-24574-4_28
Sandler, M., Howard, A.G., Zhu, M., Zhmoginov, A., Chen, L.: Mobilenetv2: Inverted residuals and linear bottlenecks. In: 2018 IEEE Conference on Computer Vision and Pattern Recognition, CVPR 2018, Salt Lake City, UT, USA, June 18-22, 2018, pp. 4510–4520. Computer Vision Foundation / IEEE Computer Society (2018)
Wang, F., Zhang, Y.: A de-raining semantic segmentation network for real-time foreground segmentation. J. Real Time Image Process. 18(3), 873–887 (2021). https://doi.org/10.1007/s11554-020-01042-2
Wang, H., Cao, P., Yang, J., Zaïane, O.R.: Mca-unet: multi-scale cross co-attentional u-net for automatic medical image segmentation. Health Inf. Sci. Syst. 11(1), 10 (2023). https://doi.org/10.1007/s13755-022-00209-4
Zhang, D., Zhang, H., Tang, J., Wang, M., Hua, X., Sun, Q.: Feature pyramid transformer. In: A. Vedaldi, H. Bischof, T. Brox, J. Frahm (eds.) Computer Vision - ECCV 2020 - 16th European Conference, Glasgow, UK, August 23-28, 2020, Proceedings, Part XXVIII, Lecture Notes in Computer Science, vol. 12373, pp. 323–339. Springer (2020). https://doi.org/10.1007/978-3-030-58604-1_20
Zhang, J., Yu, L., Chen, D., Pan, W., Shi, C., Niu, Y., Yao, X., Xu, X., Cheng, Y.: Dense gan and multi-layer attention based lesion segmentation method for covid-19 ct images. Biomed. Signal Process. Control 69, 102901 (2021). https://doi.org/10.1016/j.bspc.2021.102901
Zhang, S., Miao, Y., Chen, J., Zhang, X., Han, L., Ran, D., Huang, Z., Pei, N., Liu, H., An, C.: Twist-net: A multi-modality transfer learning network with the hybrid bilateral encoder for hypopharyngeal cancer segmentation. Computers in Biology and Medicine 154, 106555 (2023). https://doi.org/10.1016/j.compbiomed.2023.106555www.sciencedirect.com/science/article/pii/S0010482523000203
Zhong, Z., Lin, Z.Q., Bidart, R., Hu, X., Daya, I.B., Li, Z., Zheng, W., Li, J., Wong, A.: Squeeze-and-attention networks for semantic segmentation. In: 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition, CVPR 2020, Seattle, WA, USA, June 13-19, 2020, pp. 13062–13071. Computer Vision Foundation / IEEE (2020)
Acknowledgements
This work is supported by the Key-Area Research and Development Program of Guangdong Province under Grant 2020B0909020001, the National Natural Science Foundation of China under Grant No.61573113.
Author information
Authors and Affiliations
Contributions
PD and HQ wrote the main manuscript text. YZ and SY drew the figures. SF and SY proofread the manuscript and corrected the grammatical errors.
Corresponding author
Ethics declarations
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Springer Nature or its licensor (e.g. a society or other partner) holds exclusive rights to this article under a publishing agreement with the author(s) or other rightsholder(s); author self-archiving of the accepted manuscript version of this article is solely governed by the terms of such publishing agreement and applicable law.
About this article

Cite this article
Ding, P., Qian, H., Zhou, Y. et al. Real-time efficient semantic segmentation network based on improved ASPP and parallel fusion module in complex scenes. J Real-Time Image Proc 20, 41 (2023). https://doi.org/10.1007/s11554-023-01298-4
Received:
Accepted:
Published:
DOI: https://doi.org/10.1007/s11554-023-01298-4