
Abstract
Purpose
Recently, a large number of patients with acute ischemic stroke benefited from the use of thrombectomy, a minimally invasive intervention technique for mechanically removing thrombi from the cerebrovasculature. During thrombectomy, 2D digital subtraction angiography (DSA) image sequences are acquired simultaneously from the posterior-anterior and the lateral view to control whether thrombus removal was successful, and to possibly detect newly occluded areas caused by thrombus fragments split from the main thrombus. However, such new occlusions, which would be treatable by thrombectomy, may be overlooked during the intervention. To prevent this, we developed a deep learning-based approach to automatic classification of DSA sequences into thrombus-free and non-thrombus-free sequences.
Methods
We performed a retrospective study based on the single-center DSA data of thrombectomy patients. For classifying the DSA sequences, we applied Long Short-Term Memory or Gated Recurrent Unit networks and combined them with different Convolutional Neural Networks used as feature extractor. These network variants were trained on the DSA data by using five-fold cross-validation. The classification performance was determined on a test data set with respect to the Matthews correlation coefficient (MCC) and the area under the curve (AUC). Finally, we evaluated our models on patient cases, in which overlooking thrombi during thrombectomy had happened.
Results
Depending on the specific model configuration used, we obtained a performance of up to 0.77\(\mid \)0.94 for the MCC\(\mid \)AUC, respectively. Additionally, overlooking thrombi could have been prevented in the reported patient cases, as our models would have classified the corresponding DSA sequences correctly.
Conclusion
Our deep learning-based approach to thrombus identification in DSA sequences yielded high accuracy on our single-center test data set. External validation is now required to investigate the generalizability of our method. As demonstrated, using this new approach may help reduce the incident risk of overlooking thrombi during thrombectomy in the future.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
Medical background
The research towards enhanced treatment of patients with acute ischemic stroke has considerably improved the outcome and long-term prognosis for a majority of patients in the past few years [11]. While the drug-based thrombolytic therapy was the standard treatment for more than two decades [7], the use of thrombectomy, a minimally-invasive intervention technique for mechanically removing thrombi from the cerebrovasculature, has led to promising treatment results in several large clinical trials, recently [1, 9, 12, 30].
During thrombectomy, the digital subtraction angiography (DSA) is used as gold standard to visualize the cerebral blood perfusion and to control the recanalization after thrombus removal. The DSA imaging technique involves the administration of a contrast agent while simultaneously capturing a sequence of successive fluoroscopic images from the posterior-anterior (PA) and the lateral (LAT) view, forming a pair of the PA and LAT sequence, with the first shot image, serving as the mask, being digitally subtracted from all other images of the sequence. Usually, the thrombus itself is not directly visible in the images of a DSA sequence, as the contrast agent stops in front of the thrombus or flows only partially past the thrombus causing identifiable perfusion abnormalities (Fig. 1).

Images of DSA sequences illustrating the perfusion abnormalities caused by thrombi at different locations (proximal thrombus ending marked with a red +)
A serious complication during thrombectomy may be the thrombus fragmentation [17]. The main thrombus breaks into individual fragments that cause new embolisms in distal or not previously affected intracerebral-arterial areas. Based on overview DSA sequences showing the whole cerebral perfusion territory, such new occlusions can usually be directly identified and immediately be treated during the intervention. However, even though these DSA sequences are thoroughly examined by the neuroradiologists, the risk of intraprocedurally overlooking a thrombus or an embolus is increased due to several reasons: The perfusion abnormalities caused by some thrombi or emboli are difficult to detect, and the level of experience of the physicians may be relevant in this context. Furthermore, the neuroradiologists may be focused predominantly on the image area around the main thrombus. New emboli in distal intracerebral-arterial areas may therefore be missed (see Online Resource 3 for illustrative patient cases).
How often thrombi or emboli are overlooked during thrombectomy can only be estimated, as no studies have been published on this topic. However, with rates ranging from 0% to 11% [3, 10], studies report on new intracerebral-arterial thrombi detected postinterventionally [3, 10, 22, 24]. These could be caused by distally located, intracerebral-arterial emboli that were considered as not treatable during the intervention because the risk of injury to the thin-walled distal arteries when accessing them by a catheter was too high. However, some of them could have been overlooked in the DSA sequences due to the reasons given above, as well.
One possibility to reduce the rate of such critical incidents could be provided by a software that classifies DSA sequences into thrombus-free and non-thrombus-free sequences, termed as thrombus-yes-no-classification in the following. Such a software could alert neuroradiologists just in time intraprocedurally if thrombi are identified. These could then possibly be treated immediately during thrombectomy in order to improve the patient’s recovery prospects.
Related work
In contrast to a large number of publications on the automatic detection of aneurysms in DSA images [8, 16, 23] and on the thrombus detection in computed tomography images [2, 28], research results towards software-based analysis of DSA sequences of patients with acute ischemic stroke have been published only sparsely and mostly in recent years [20, 21, 25, 26].
In their feasibility study published in 2019, Nielsen et al. performed a Thrombolysis In Cerebral Infarction (TICI) [14] classification of DSA sequences by using a slightly modified ResNet18-based [13] Convolutional Neural Network (CNN), but they achieved only a poor classification performance [20]. In their follow-up publication based on a different DSA data set, they combined an EfficientNet-B0 [27] as feature extractor with a Gated Recurrent Unit (GRU) network [6] and obtained a significantly more accurate (0.95 ± 0.03) TICI classification compared to a purely EfficientNet-based approach (0.82 ± 0.02) [21]. In contrast, Schuldhaus et al. worked on automatically dividing DSA sequences into perfusion related different phases [25]. Furthermore, Su et al. developed an automatic, extended TICI classification scheme and reported an average area under the curve (AUC) value of 0.81 [26]. However, to the best of our knowledge, no scientific publication has reported yet on performing a thrombus-yes-no-classification.
Contribution
We present a new deep learning-based approach to thrombus-yes-no-classification of DSA image sequences. For this purpose, we addressed the challenge of automatically identifying spatio-temporal perfusion abnormalities caused by thrombi in DSA image sequences of variable sequence length and conducted a retrospective study based on the single-center DSA data of thrombectomy patients. The study-related methods, results and discussions are described in the next sections.
Methods
In the subsequent sections, the details regarding the medical imaging data and their annotation (“Imaging data and data annotation” section), the network architecture (“Network architecture” section), the network training routine (“Training routine” section) as well as the performed model evaluations on the test data (“Model evaluation” section) are given.
Imaging data and data annotation
We retrospectively collected single-center DSA imaging data of 260 stroke patients (\(n_{\mathrm{female}}~=~133\), \(n_{\mathrm{male}}~=~127\), mean age: 74,5 years) who underwent thrombectomy in the stroke unit of the district hospital Guenzburg (BV, Germany) in the time period from January 2018 to July 2019. This resulted in a total of 1197 single DSA sequences (image resolution: \(1024 \times 1024\) pixel, time resolution: 3 images/second, image sequence length: 13–61, mean: 32). The DSA sequences were acquired by the Artis zee cone beam CT scanner (Siemens Healthcare GmbH, Erlangen, BV, Germany).
To get our final data set, we excluded DSA sequences, when not both the PA and the LAT sequence were available (\(n=8\)). Furthermore, DSA sequences visualizing only the perfusion of either the vertebral arteries (\(n=103\)) or the external carotid artery (\(n=18\)) were excluded, as well. The remaining 1068 DSA sequences (534 pairs PA + LAT) were annotated by two experienced neuroradiologists. For each thrombus, they were asked to mark the proximal thrombus ending. DSA sequence pairs with no thrombus detected were classified as thrombus-free (\(n=151\) pairs). Having detected a thrombus in either the PA or LAT sequence but not in the other (\(n=16\)), both the PA and the LAT DSA sequence were classified as non-thrombus-free. DSA sequences differing in their classification based on their annotations were re-annotated jointly by both neuroradiologists to make an ultimate decision.
Finally, we evaluated our trained models on two additional patient cases, in which overlooking thrombi during thrombectomy had happened (Online Resource 3).

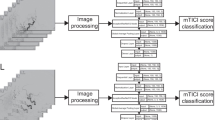
Processing a DSA sequence consisting of N single 2D images to be classified by the network. A CNN such as a ResNet or EfficientNet was used as feature extractor. The extracted features served as input to the LSTM or GRU network, which outputted the classification result
Network architecture
DSA sequences are a discrete image series \(D \in \{t_1 W x H, ... , t_{N}^{W x H}\}\) of temporally successive 2D images \(t_{i}^{W x H}\) of varying image series length N, equivalent to a video of variable video length. The goal of the thrombus-yes-no-classification is to find the correct mapping between a DSA sequence D and a label \(\hat{y} \in [0,1]\) determining whether the sequence is thrombus-free (\(\hat{y} = 0\)) or non-thrombus-free (\(\hat{y} = 1\)).
As identifying thrombi in DSA sequences is based on detecting perfusion abnormalities, the spatio-temporal contrast agent perfusion has to be analyzed to perform the classification. For this purpose, we combined a CNN as feature extractor with either a Long Short-Term Memory (LSTM) [15] network or a GRU network, that are both able to establish spatio-temporal relations between the individual images of the video sequence (Fig. 2).
To process the DSA sequence, we combined the first three single-channel grayscale images of the DSA sequence to a three-channel image, passed it through the network, prepared the following three grayscale images as next input and iterated in this way over the entire sequence. At the end of the sequence, the last image was repeatedly appended in those cases, where the sequence length was not divisible by three. Based on this approach, we were able to use pretrained weights for initializing the CNN, but the weights were not freezed during training. Before using the extracted features of the CNN as input for the LSTM/GRU network, a normalization layer and a LeakyReLu activation function were applied on the features. The bidirectional configured LSTM/GRU network consisted of 3 layers with 512 hidden units per layer and a dropout rate of 0.5 during training.
Table 1 lists the different types of CNN variants and their combination with the LSTM/GRU network used in our retrospective study. Most common, we used the GRU network, as it required less memory and trained faster compared with the LSTM network. All CNNs were modified by removing the final classification layer and adjusting the preceding average pooling layer in its pooling size such that the number of features extracted by the CNN was approximately the same for all different CNN types.
Training routine
The first 20% of the chronologically ordered data set (“Imaging data and data annotation” section) was reserved as test data. The rest was used to train and validate the models by using five-fold cross-validation with a non-randomized train\(\mid \)validation split of 80%\(\mid \)20% for each fold. PyTorch served as deep learning library. Before feeding the DSA sequences into the network, the images were normalized and uniformly resized to \(512 \times 512\) pixel to prevent out-of-memory problems on the two 24GB RAM GPUs used during training (RTX 3090 and Titan RTX, both of the NVIDIA Corporation, Santa Clara, CA, USA). Data augmentation was dynamically performed during training based on the Albumentations library [4]. The applied augmentations included vertical flipping, shift-scale-rotate transformations, changing the contrast of the images, blurring the images, adding noise and down-scaling the images to the half resolution.
As the PA and the LAT DSA sequence are characterized by specific perfusion structures, we trained separate models for both views, but the training routine was the same for all network variants listed in Table 1. Each model was trained end-to-end for 130 epochs by using mixed precision training [19] and binary cross entropy in its default configuration as loss function. AdamW served as optimizer [18] starting with a learning rate of \(10^{-5}\), a weight decay of \(10^{-2}\) and standard \(\beta _1, \beta _2\). The batch size was 1, and the learning rate was reduced on plateau by a factor of \(10^{-1}\). Unlike the accuracy or F1-score, the Matthews correlation coefficient (MCC) [5] does not tend to overestimate the classification performance especially for an unbalanced binary class distribution, as it was the case for our DSA data set (72% positives \(\mid \) 28% negatives). Hence, we chose it as decision criterion during training and saved the model checkpoint, which achieved the highest MCC on the validation data. As we used five-fold cross-validation, we obtained five models trained on the PA sequences and five models trained on the LAT sequences (Fig. 3) for each network type listed in Table 1.
Model evaluation
We evaluated each network variant (Table 1) regarding two aspects:
-
1.
The single classification performance, i.e. classifying either the PA or the LAT DSA sequences separately, as illustrated in Fig. 3.
-
2.
The paired classification performance, i.e. classifying DSA sequence pairs (PA + LAT) as a unit.

Ensembling methods used to determine the single and the paired classification performance. In both cases, the predictions were equally weighted when calculating the mean
Furthermore, we systematically analyzed which combination of four different network variants, two for each view, resulted in the best achievable performance. Since accuracy, precision and recall used as classification metrics tend to overestimate the classification performance especially for an unbalanced binary class distribution, as it was the case for our DSA data set, we quantified the performance in terms of classification MCC (range: [-1,1]) and AUC based on the test data set. The mathematical definitions of the performance metrics are provided in Online Resource 1. As the test data set contained seven pairs of DSA sequences, which were subject to high annotation uncertainty due to inconspicuous, distally located, intracerebral-arterial perfusion abnormalities not treatable by thrombectomy (see example in Online Resource 2), we report the performance results on two variants: For test data set 1, those seven pairs were excluded, whereas they were included for test data set 2. In this way, we show how annotations that are subject to high uncertainty affect the classification performance.
Results
The results of the single and paired classification performance of all network variants are listed in Table 2. The maximum MCC\(\mid \)AUC were found to be 0.65\(\mid \)0.91, 0.68\(\mid \)0.93 and 0.73\(\mid \)0.94 for the classification of the single PA sequences, the single LAT sequences and the pair of PA + LAT sequences, respectively.
The best classification performance with MCC\(\mid \)AUC values of up to 0.77\(\mid \)0.94 and 0.69\(\mid \)0.91 for test data set 1 and 2, respectively, was achieved based on a paired classification by equally ensembling four different network variants, two for each view. In this case, classifying the PA sequences was based on the combination of the ResNet18 + GRU network and the Tf_EfficientNetV2_S + GRU network, whereas classifying the LAT sequences was performed by the EfficientNet-B0 + GRU network and the EfficientNet-B0 + LSTM network. The corresponding confusion matrices of this model ensemble with respect to the performance on test data set 1 and 2 are given in Fig. 4. It should be noted that this model configuration would have correctly classified the two reported patient cases (Online Resource 3).
Figure 5 shows the receiver operating characteristics (ROC) curves of selected network variants. The maximum AUC value of 0.94 was reached only when performing a paired classification. All further performance results on test data set 2 are provided in Online Resource 2.

Confusion matrices corresponding to the best achievable paired classification performance on test data set 1 and 2. The corresponding MCC and AUC values are given in the text. As described above, these results were achieved by ensembling four networks, two for each view

a ROC curves of the three network variants with the highest MCC in case of the paired classification performance. b ROC curve of the model achieving the best paired classification performance and consisting of four ensembled network variants. For each variant, the corresponding ROC curve is given, as well
Discussion
Acute ischemic stroke highly affects the patient’s health, but the use of thrombectomy has led to promising treatment results, recently. During thrombectomy, DSA image sequences are acquired to possibly detect newly occluded areas caused by thrombus fragments split from the main thrombus. However, such new occlusions may be overlooked during the intervention. To prevent this, we developed a new deep learning-based approach to automatic thrombus-yes-no-classification of DSA sequences and found out that we could classify DSA sequences with an MCC\(\mid \)AUC of up to 0.77\(\mid \)0.94, respectively. Notably, these results were obtained on a data set with a considerably unbalanced class distribution and the ability of the networks to differentiate well between the two classes is assumed to be very good.
The observed minor drop of the classification performance in case of test data set 2 (Fig. 4) was caused by the additionally included seven pairs of DSA sequences that were subject to high annotation uncertainty. They were mostly misclassified as thrombus-free (false negative), even though they contained small, inconspicuous, distally located, intracerebral-arterial perfusion abnormalities, which, however, would not be treatable by thrombectomy or thrombolysis.
Nielsen et al. [20] reported an accuracy of 0.89 for classifying DSA sequences into the TICI 0 and TICI 3 class. To a limited extend, this may be regarded as equivalent to our classification performance, but we would like to point out that, contrarily to Nielsen et al. [21] we did not exclusively use DSA sequences with thrombi in the middle cerebral artery. Instead, our DSA sequences included thrombi at various locations inside the whole perfusion territory of the internal carotid artery as well as sequences with imaging artifacts. This diversity of affected brain regions reflects the commonly observed variety of ischemic strokes treated in stroke units, even though classifying these correctly should be regarded a challenging task.
As our retrospective study was based on single-center DSA imaging data, the trained neural networks could be less generalizable with respect to DSA data of other stroke units. Nevertheless, it is worth to note that the DSA data of the case reports (Online Resource 3) had a different image and time resolution compared with the training DSA data set, but these case report DSA sequences were classified correctly by the neural networks, too.
To further help the neuroradiologists in localizing thrombi, that are hard to detect, a next step to be investigated could be the thrombus detection. However, even though the annotations of our DSA data set already contained the thrombus positions, the task of automatically detecting thrombi in the DSA images should not be underestimated. In particular, this is related to the high interobserver variability of the thrombus position annotation, which was 23 ± 28 image pixels (i.e., 2% ± 3% of image width) for our DSA data set. Due to this annotation variability, it could be difficult to objectively assess the ability of a neural network to detect thrombi by using commonly evaluation metrics such as the mean average precision, as for this, the network predictions must be clearly categorized into right and false. Prospective studies should therefore determine how to best deal with high annotation variability and which evaluation metrics are most suitable for the thrombus detection problem.
From a medical perspective, the reached classification performance may seem acceptable, but only a prospective study can analyze how the trained neural networks will perform in clinical practice. To improve the classification performance and the generalizability, a substantially larger amount of multi-center training data would be required. Additionally, using transformer-based neural networks could be an option for improving classification performance, as well. As demonstrated by our final evaluation test on two patient cases, our deep learning-based approach could have prevented overlooking thrombi during thrombectomy. Thus, the goal of minimizing the risk of this incident may be fulfilled.
Conclusion
Our deep learning-based approach to thrombus identification in DSA sequences yielded high accuracy on our single-center test data set. External validation is now required to investigate the generalizability of our method. As demonstrated, using this new approach may help reduce the incident risk of overlooking thrombi during thrombectomy in the future.
Data availability
Due to data protection reasons, the DSA data set cannot be published.
Code availability
The training scripts are available on GitHub (https://github.com/BMittmannTest/DeepLearningBasedDsaClassification). The corresponding trained network models are published on the open science framework (https://osf.io/n8k4r/).
References
Albers GW, Marks MP, Kemp S, Christensen S, Tsai JP, Ortega-Gutierrez S, McTaggart RA, Torbey MT, Kim-Tenser M, Leslie-Mazwi T, Sarraj A, Kasner SE, Ansari SA, Yeatts SD, Hamilton S, Mlynash M, Heit JJ, Zaharchuk G, Kim S, Carrozzella J, Palesch YY, Demchuk AM, Bammer R, Lavori PW, Broderick JP, Lansberg MG (2018) Thrombectomy for stroke at 6 to 16 hours with selection by perfusion imaging. N Engl J Med 378(8):708–718. https://doi.org/10.1056/NEJMoa1713973
Amukotuwa SA, Straka M, Dehkharghani S, Bammer R (2019) Fast automatic detection of large vessel occlusions on CT angiography. Stroke 50(12):3431–3438. https://doi.org/10.1161/STROKEAHA.119.027076
Behme D, Gondecki L, Fiethen S, Kowoll A, Mpotsaris A, Weber W (2014) Complications of mechanical thrombectomy for acute ischemic stroke - A retrospective single-center study of 176 consecutive cases. Neuroradiology 56(6):467–476. https://doi.org/10.1007/s00234-014-1352-0
Buslaev A, Iglovikov VI, Khvedchenya E, Parinov A, Druzhinin M, Kalinin AA (2020) Albumentations: Fast and flexible image augmentations. Information. https://doi.org/10.3390/info11020125
Chicco D, Jurman G (2020) The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom 21:6. https://doi.org/10.1186/s12864-019-6413-7
Cho K, van Merriënboer B, Gulcehre C, Bahdanau D, Bougares F, Schwenk H, Bengio Y (2014) Learning phrase representations using RNN encoder–decoder for statistical machine translation. In: Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP). Association for Computational Linguistics, pp 1724–1734, https://doi.org/10.3115/v1/D14-1179
Donnan GA, Davis SM, Parsons MW, Ma H, Dewey HM, Howells DW (2011) How to make better use of thrombolytic therapy in acute ischemic stroke. Nat Rev Neurol 7(7):400–409. https://doi.org/10.1038/nrneurol.2011.89
Duan H, Huang Y, Liu L, Dai H, Chen L, Zhou L (2019) Automatic detection on intracranial aneurysm from digital subtraction angiography with cascade convolutional neural networks. BioMed Eng OnLine 18:110. https://doi.org/10.1186/s12938-019-0726-2
Falk-Delgado A, Kuntze Söderqvist Å, Fransén J, Falk-Delgado A (2016) Improved clinical outcome 3 months after endovascular treatment, including thrombectomy, in patients with acute ischemic stroke: a meta-analysis. J Neurointerv Surg 8(7):665–670. https://doi.org/10.1136/neurintsurg-2015-011835
Gory B, Mazighi M, Blanc R, Labreuche J, Piotin M, Turjman F, Lapergue B (2018) Mechanical thrombectomy in basilar artery occlusion: influence of reperfusion on clinical outcome and impact of the first-line strategy (adapt vs stent retriever). J Neurosurg 129(6):1482–1491. https://doi.org/10.3171/2017.7.JNS171043
Goyal M, Menon BK, van Zwam WH, Dippel DWJ, Mitchell PJ, Demchuk AM, Dávalos A, Majoie CBLM, van der Lugt A, de Miquel MA, Donnan GA, Roos YBWEM, Bonafe A, Jahan R, Diener HC, van den Berg LA, Levy EI, Berkhemer OA, Pereira VM, Rempel J, Millán M, Davis SM, Roy D, Thornton J, Román LS, Ribó M, Beumer D, Stouch B, Brown S, Campbell BCV, van Oostenbrugge RJ, Saver JL, Hill MD, Jovin TG (2016) Endovascular thrombectomy after large-vessel ischaemic stroke: a meta-analysis of individual patient data from five randomised trials. Lancet 387(10029):1723–1731. https://doi.org/10.1016/S0140-6736(16)00163-X
Goyal N, Tsivgoulis G, Frei D, Turk A, Baxter B, Froehler MT, Mocco J, Vachhani J, Hoit D, Elijovich L, Loy D, Turner RD, Mascitelli J, Espaillat K, Alexandrov AV, Alexandrov AW, Arthur AS (2018) A multicenter study of the safety and effectiveness of mechanical thrombectomy for patients with acute ischemic stroke not meeting top-tier evidence criteria. J Neurointerv Surg 10(1):10–16. https://doi.org/10.1136/neurintsurg-2016-012905
He K, Zhang X, Ren S, Sun J (2016) Deep residual learning for image recognition. Proc IEEE Comput Soc Conf Comput Vis Pattern Recognit. https://doi.org/10.1109/CVPR.2016.90
Higashida RT, Furlan AJ, Roberts H, Tomsick T, Connors B, Barr J, Dillon W, Warach S, Broderick J, Tilley B, Sacks D (2003) Trial design and reporting standards for intra-arterial cerebral thrombolysis for acute ischemic stroke. Stroke 34(8):e109-37. https://doi.org/10.1161/01.STR.0000082721.62796.09
Hochreiter S, Schmidhuber J (1997) Long short-term memory. Neural Comput 9(8):1735–1780. https://doi.org/10.1162/neco.1997.9.8.1735
Jin H, Yin Y, Hu M, Yang G, Qin L (2019) Fully automated unruptured intracranial aneurysm detection and segmentation from digital subtraction angiography series using an end-to-end spatiotemporal deep neural network. In: Angelini ED, Landman BA (eds) Medical Imaging 2019: Image Processing, International Society for Optics and Photonics, vol 10949. SPIE, pp 379–386, https://doi.org/10.1117/12.2512623
Kaesmacher J, Boeckh-Behrens T, Simon S, Maegerlein C, Kleine JF, Zimmer C, Schirmer L, Poppert H, Huber T (2017) Risk of thrombus fragmentation during endovascular stroke treatment. AJNR Am J Neuroradiol 38(5):991–998. https://doi.org/10.3174/ajnr.A5105
Loshchilov I, Hutter F (2019) Decoupled weight decay regularization. arXiv: 1711.05101
Micikevicius P, Narang S, Alben J, Diamos GF, Elsen E, García D, Ginsburg B, Houston M, Kuchaiev O, Venkatesh G, Wu H (2017) Mixed precision training. arXiv: 1710.03740
Nielsen M, Waldmann M, Frölich A, Fiehler J, Werner R (2019) Machbarkeitsstudie zur CNN-basierten Identifikation und TICI-Klassifizierung zerebraler ischämischer Infarkte in DSA-Daten. In: Handels H, Deserno TM, Maier A, Maier-Hein KH, Palm C, Tolxdorff T (eds) Bildverarbeitung für die Medizin 2019 Informatik aktuell. Springer Vieweg, Wiesbaden, pp 200–205. https://doi.org/10.1007/978-3-658-25326-4_45
Nielsen M, Waldmann M, Sentker T, Frölich A, Fiehler J, Werner R (2020) Time matters: Handling spatio-temporal perfusion information for automated TICI scoring. In: Martel AL, Abolmaesumi P, Stoyanov D, Mateus D, Zuluaga MA, Zhou SK, Racoceanu D, Joskowicz L (eds) Medical image computing and computer assisted intervention - MICCAI 2020. Springer, Berlin, pp 86–96. https://doi.org/10.1007/978-3-030-59725-2_9
Pereira VM, Gralla J, Davalos A, Bonafé A, Castaño C, Chapot R, Liebeskind DS, Nogueira RG, Arnold M, Sztajzel R, Liebig T, Goyal M, Besselmann M, Moreno A, Schroth G, Alamovitch S, Arquizan C, Dohmen C, Killer-Oberpfalzer M, Broussalis E, Krause L, Lopez-Ibor L, Macho J, Amaro S, Menon B, Millàn M, Miteff F, Faulder K, Piotin M, Weber R, Parrilla G (2013) Prospective, multicenter, single-arm study of mechanical thrombectomy using solitaire flow restoration in acute ischemic stroke. Stroke 44(10):2802–2807. https://doi.org/10.1161/STROKEAHA.113.001232
Rahmany I, Guetari R, Khlifa N (2018) A fully automatic based deep learning approach for aneurysm detection in DSA images. In: 2018 IEEE international conference on image processing, applications and systems (IPAS), pp 303–307, https://doi.org/10.1109/IPAS.2018.8708897
Schönfeld MH, Kabiri R, Kniep HC, Meyer L, McDonough R, Sedlacik J, Ernst M, Broocks G, Faizy T, Schön G, Cheng B, Thomalla G, Fiehler J, Hanning U (2020) Effect of balloon guide catheter utilization on the incidence of sub-angiographic peripheral emboli on high-resolution DWI after thrombectomy: A prospective observational study. Front Neurol 11:386. https://doi.org/10.3389/fneur.2020.00386
Schuldhaus D, Spiegel M, Redel T, Polyanskaya M, Struffert T, Hornegger J, Doerfler A (2011) Classification-based summation of cerebral digital subtraction angiography series for image post-processing algorithms. Phys Med Biol 56(6):1791–1802. https://doi.org/10.1088/0031-9155/56/6/017
Su R, Cornelissen SAP, van der Sluijs M, van Es ACGM, van Zwam WH, Dippel DWJ, Lycklama G, van Doormaal PJ, Niessen WJ, van der Lugt A, van Walsum T (2021) autoTICI: Automatic brain tissue reperfusion scoring on 2D DSA images of acute ischemic stroke patients. IEEE Trans Med Imag 40(9):2380–2391. https://doi.org/10.1109/TMI.2021.3077113
Tan M, Le QV (2019) Efficientnet: Rethinking model scaling for convolutional neural networks. arXiv:1905.11946
Tolhuisen ML, Ponomareva E, Boers AMM, Jansen IGH, Koopman MS, Sales Barros R, Berkhemer OA, van Zwam WH, van der Lugt A, Majoie CBLM, Marquering HA (2020) A convolutional neural network for anterior intra-arterial thrombus detection and segmentation on non-contrast computed tomography of patients with acute ischemic stroke. Appl Sci. https://doi.org/10.3390/app10144861
Wightman R (2019) Pytorch image models. https://github.com/rwightman/pytorch-image-models, https://doi.org/10.5281/zenodo.4414861
Yoo AJ, Tommy A (2017) Thrombectomy in acute ischemic stroke: Challenges to procedural success. J Stroke 19(2):121–130. https://doi.org/10.5853/jos.2017.00752
Funding
Open Access funding enabled and organized by Projekt DEAL. This work was founded by the Federal Ministry of Economics and Energy (BMWi, Funding Code: ZF4640301GR8).
Author information
Authors and Affiliations
Contributions
Benjamin Mittmann wrote the first version of this article, evaluated the data set and programmed/trained/evaluated the networks. Michael Braun analyzed/annotated all DSA sequences and provided medical expertise. Frank Runck annotated the DSA sequences, too. Thuy Tran and Amine Yamlahi helped in optimizing the neural network training. Alfred Franz, Bernd Schmitz and Lena Maier-Hein supervised the study. All authors approved the final manuscript.
Corresponding authors
Ethics declarations
Conflict of Interest
The authors declare that they have no conflict of interest.
Ethical approval
All procedures performed in studies involving human participants were in accordance with the ethical standards of the institutional and/or national research committee and with the 1964 Helsinki Declaration and its later amendments or comparable ethical standards. Approval was granted by the Ethics Committee of University Ulm, Germany (Date: 2020-09-16; No: 306/20).
Informed consent
Informed consent was obtained from all individual participants included in the study.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article’s Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article’s Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Mittmann, B.J., Braun, M., Runck, F. et al. Deep learning-based classification of DSA image sequences of patients with acute ischemic stroke. Int J CARS 17, 1633–1641 (2022). https://doi.org/10.1007/s11548-022-02654-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11548-022-02654-8