
Abstract
Direct reciprocity is a chief mechanism of mutual cooperation in social dilemma. Agents cooperate if future interactions with the same opponents are highly likely. Direct reciprocity has been explored mostly by evolutionary game theory based on natural selection. Our daily experience tells, however, that real social agents including humans learn to cooperate based on experience. In this paper, we analyze a reinforcement learning model called temporal difference learning and study its performance in the iterated Prisoner’s Dilemma game. Temporal difference learning is unique among a variety of learning models in that it inherently aims at increasing future payoffs, not immediate ones. It also has a neural basis. We analytically and numerically show that learners with only two internal states properly learn to cooperate with retaliatory players and to defect against unconditional cooperators and defectors. Four-state learners are more capable of achieving a high payoff against various opponents. Moreover, we numerically show that four-state learners can learn to establish mutual cooperation for sufficiently small learning rates.
Similar content being viewed by others
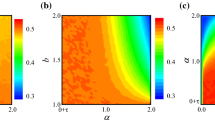

References
Axelrod, R., 1984. Evolution of Cooperation. Basic Books, New York.
Camerer, C., Ho, T.-H., 1999. Experience-weighted attraction learning in normal form games. Econometrica 67, 827–874.
Camerer, C.F., 2003. Behavioral Game Theory. Princeton University Press, New York.
Cheung, Y.-W., Friedman, D., 1997. Individual learning in normal form games: some laboratory results. Games Econ. Behav. 19, 46–76.
Daw, N.D., Doya, K., 2006. The computational neurobiology of learning and reward. Curr. Opin. Neurobiol. 16, 199–204.
Erev, I., Roth, A.E., 1998. Predicting how people play games: reinforcement learning in experimental games with unique, mixed strategy equilibria. Am. Econ. Rev. 88, 848–881.
Erev, I., Roth, A.E., 2001. On simple reinforcement learning models and reciprocation in the prisoner dilemma game. In: Gigerenzer, G., Selten, R. (Eds.), The Adaptive Toolbox, pp. 215–231. MIT Press, Cambridge
Fudenberg, D., Levine, D.K., 1998. The Theory of Learning in Games. MIT Press, Cambridge.
Gutnisky, D.A., Zanutto, B.S., 2004. Cooperation in the iterated Prisoner’s Dilemma is learned by operant conditioning mechanisms. Artif. Life 10, 433–461.
Hauert, C., Stenull, O., 2002. Simple adaptive strategy wins the Prisoner’s Dilemma. J. Theor. Biol. 218, 261–272.
Kaelbling, L.P., Littman, M.L., Moore, A.W., 1996. Reinforcement learning: a survey. J. Artif. Intell. Res. 4, 237–285.
Kraines, D., Kraines, V., 1993. Learning to cooperate with Pavlov. An adaptive strategy for the iterated Prisoner’s Dilemma with noise. Theory Decis. 35, 107–150.
Macy, M.W., 1991. Learning to cooperate: stochastic and tacit collusion in social exchange. Am. J. Sociol. 97, 808–843.
Macy, M., 1996. Natural selection and social learning in Prisoner’s Dilemma. Sociol. Methods Res. 25, 103–137.
Macy, M.W., Flache, A., 2002. Learning dynamics in social dilemmas. Proc. Natl. Acad. Sci. USA 99(3), 7229–7236.
Montague, P.R., Berns, G.S., 2002. Neural economics and the biological substrates of valuation. Neuron 36, 265–284.
Montague, P.R., King-Casas, B., Cohen, J.D., 2006. Imaging valuation models in human choice. Annu. Rev. Neurosci. 29, 417–448.
Mookherjee, D., Sopher, B., 1994. Learning behavior in an experimental matching pennies game. Games Econ. Behav. 7, 62–91.
Nowak, M., Sigmund, K., 1989. Game dynamical aspects of the Prisoner’s Dilemma. J. Appl. Math. Comput. 30, 191–213.
Nowak, M., Sigmund, K., 1990. The evolution of stochastic strategies in the Prisoner’s Dilema. Acta Appl. Math. 20, 247–265.
Nowak, M.A., 2006. Five rules for the evolution of cooperation. Science 314, 1560–1563.
Nowak, M.A., Sigmund, K., 1992. Tit for tat in heterogeneous populations. Nature 355, 250–253.
Nowak, M.A., Sigmund, K., 1993. A strategy of win-stay lose-shift that outperforms tit-for-tat in the Prisoner’s Dilemma game. Nature 364, 56–58.
Nowak, M.A., Sigmund, K., El-Sedy, E., 1995. Automata, repeated games and noise. J. Math. Biol. 33, 703–722.
Ohtsuki, H., 2004. Reactive strategies in indirect reciprocity. J. Theor. Biol. 227, 299–314.
Posch, M., Pichler, A., Sigmund, K., 1999. The efficiency of adapting aspiration levels. Proc. R. Soc. Lond. B 266, 1427–1435.
Rapoport, A., Chammah, A.M., 1965. Prisoner’ s Dilemma: A Study in Conflict and Cooperation. University of Michigan Press, Ann Arbor.
Roth, A.E., Erev, I., 1995. Learning in extensive-form games: experimental data and simple dynamic models in the intermediate term. Games Econ. Behav. 8, 164–212.
Samuel, A.L., 1959. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 3, 210–229.
Sandholm, T.W., Crites, R.H., 1996. Multiagent reinforcement learning in the Iterated Prisoner’s Dilemma. BioSystems 37, 147–166.
Sato, Y., Akiyama, E., Farmer, J.D., 2002. Chaos in learning a simple two-person game. Proc. Natl. Acad. Sci. USA 99, 4748–4751.
Schultz, W., Dayan, P., Montague, P.R., 1997. A neural substrate of prediction and reward. Science 275, 1593–1599.
Singh, S.P., Jaakkola, T., Jordan, M.L., 1994. Learning without state-estimation in partially observable Markovian decision processes. In: Proc. the Eleventh Machine Learning Conference
Singh, S., Jaakkola, T., Littman, M.L., Szepesvári, C., 2000. Convergence results for single-step on-policy reinforcement algorithms. Mach. Learn. 39, 287–308.
Sutton, R.S., Barto, A.G., 1998. Reinforcement Learning. MIT Press, Cambridge.
Taiji, M., Ikegami, T., 1999. Dynamics of internal models in game players. Physica D 134, 253–266.
Tesauro, G., 1992. Practical issues in temporal difference learning. Mach. Learn. 8, 257–277.
Trivers, R., 1971. The evolution of reciprocal altruism. Q. Rev. Biol. 46, 35–57.
Watkins, C.J.C.H., Dayan, P., 1992. Q-learning. Mach. Learn. 8, 279–292.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article
Cite this article
Masuda, N., Ohtsuki, H. A Theoretical Analysis of Temporal Difference Learning in the Iterated Prisoner’s Dilemma Game. Bull. Math. Biol. 71, 1818–1850 (2009). https://doi.org/10.1007/s11538-009-9424-8
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11538-009-9424-8