
Abstract
The current global pandemic, Covid-19, is a severe threat to human health and existence especially when it is mutating very frequently. Being a novel disease, Covid-19 is impacting the patients with comorbidities and is predicted to have long-term consequences, even for those who have recovered from it. To clearly recognize its impact, it is important to comprehend the complex relationship between Covid-19 and other diseases. It is also being observed that people with good immune system are less susceptible to the disease. It is perceived that if a correlation between Covid-19, other diseases, and diet is realized, then caregivers would be able to enhance their further course of medical action and recommendations. Network Analysis is one such technique that can bring forth such complex interdependencies and associations. In this paper, a Network Analysis–based approach has been proposed for analyzing the interplay of diets/foods along with Covid-19 and other diseases. Relationships between Covid-19, diabetes mellitus type 2 (T2DM), non-alcoholic fatty liver disease (NAFLD), and diets have been curated, visualized, and further analyzed in this study so as to predict unknown associations. Network algorithms including Louvain graph algorithm (LA), K nearest neighbors (KNN), and Page rank algorithms (PR) have been employed for predicting a total of 60 disease-diet associations, out of which 46 have been found to be either significant in disease risk prevention/mitigation or in its progression as validated using PubMed literature. A precision of 76.7% has been achieved which is significant considering the involvement of a novel disease like Covid-19. The generated interdependencies can be further explored by medical professionals and caregivers in order to plan healthy eating patterns for Covid-19 patients. The proposed approach can also be utilized for finding beneficial diets for different combinations of comorbidities with Covid-19 as per the underlying health conditions of a patient.

Graphical abstract
Similar content being viewed by others


1 Introduction
Covid-19 is an infectious disease developed due to transmission of novel coronavirus (2019-nCoV), causing respiratory problems and deaths across the globe [1]. It was first detected in China in 2019 and in a matter of few months, Covid-19 was declared a global pandemic affecting millions of lives. World scientists and researchers are putting in all the efforts to explore different methods related to containment of coronavirus. In the initial phase of Covid-19, it was identified to be specifically deleterious to children and older adults, but with the reappearance of the second wave and increased cases, it has been identified to be associated with many other factors like type 2 diabetes, obesity, and respiratory illness. A recent research [2] suggests to closely observe Covid-19 patients having comorbidities like diabetes or pneumonia. Similarly, many other studies and meta-analysis revealed hypertension, chronic obstructive pulmonary disease, diabetes, cerebrovascular disease, and cardiovascular disease as risk factors of Covid-19 [3,4,5.
Apart from comorbidities, another deciding factor of the progression of Covid-19 is the immune system [6, 7]. Due to variance in the immunity of individuals, their response to the virus is variable. Some patients are asymptomatic and recover through isolation and medicines, while others have mild to severe symptoms requiring hospitalization. In this time of crisis, vaccination has raised a little hope but along with that, there is an urgent need to improve our immune system to minimize the risk of Covid-19 and other related diseases. Diet is a vital component for our immune system and thus considered important for reducing risk of Covid-19 [8]. The nutrients found in fruits and vegetables have anti-inflammatory effects and are suggested for Covid-19 risk management. Vitamin A, vitamin C, selenium, and zinc are known to be potential options for prevention from Covid-19 as they are effective for immune functions [9]. Deficiency of vitamin D is known to be related to several diseases like diabetes, hypertension, and obesity, which are associated with Covid-19 risk. Thus, many researchers [2, 3] are suggesting vitamin D intake to protect against infection. Few recommendations have been suggested for optimal nutrition at different levels of health model such as leafy vegetables, dairy products, nuts, and citrus fruits, consisting of nutrients like iron, zinc, vitamin A, C, B6, and B12 [10]. Other works [7, 8] suggest foods like kiwifruit, broccoli, red pepper, strawberries, and citrus foods which are rich in vitamin C and foods rich in vitamin A like carrot, spinach, sweet potato, and vegetable oils, seeds, spinach, or supplements for vitamin D and E. Similar recommendations have been given like adding foods containing vitamin B6 and omega-3 polyunsaturated fatty acids to the list [11]. Consumption of diets rich in saturated fats, refined carbohydrates, and sugars named as Western Diet is known to severely affect the immune system leading to impairment against viruses and is thus not being recommended [12].
Diet and comorbidities contribute significantly towards the prognosis of Covid-19 in infected individuals. Further, comorbidities are also impacted by the kind of diet consumed by different individuals. Thus, in the ongoing pandemic, understanding the dynamics of Covid-19, diet (“food” and “diet” terms have been used interchangeably in this work), and other diseases is important so that progression of diseases can be traced. Understanding the interplay of different diets and diseases is a lot more complicated than is generally known. For example, it is a general notion that a person suffering from diabetes should eat eggs and leafy greens. This might be helpful for some patients but not for others. This is because diets have different interactions with diseases for different individuals depending on other factors like their lifestyle, comorbidities, or environment. Intake of different combinations of food even at different time of the day affects metabolism and health. Apart from this, allergies from food, relation of foods with disease subtypes, and even different forms of same food item might affect individuals’ health differently [13, 14]. Moreover, such kind of disease-diet database is not readily available. In order to comprehend such complex interdependencies, there is a need to integrate authentic data from literature, identify associations, visualize them, and explore future possibilities using computational techniques. Such a computational approach has already been applied in various biological studies, for example, use of machine learning to predict post-translation modification site [15–17]. Network analysis is also one such solution which offers to develop complex visualizations and draw inferences from them [18–20]. It is increasingly being used for solving many real-world problems which can be depicted as graphs. For example, social media connections are represented as graphs and analyzed to predict future connections or to understand disease outbreak mechanism. Another area where networks are scrutinized is representation of disease associations with entities like genes [21, 22], symptoms [23], microRNA[22], microbe [24], and drugs [25]. The same analogy can be applied to known associations among diet, other diseases, and Covid-19 so as to identify and predict significant unknown associations.
The motivation behind this work lies in the fact that there are associations existing among Covid-19, diet, and other diseases, which if discovered, can prove to be a valuable resource for healthcare researchers. Moreover, lack of an existing database corresponding to such associations is another reason to develop an approach for curation and analysis of such dataset. These predicted interdependencies can be further explored by researchers to understand their impact in real life. Once validated, the associations can be utilized by caregivers to plan healthy eating patterns for boosting immunity and reducing the risk of Covid-19 for patients afflicted with comorbidities. The main contributions of this work are:
-
i.
Curation of a database pertaining to known associations among Covid-19, diets, and other diseases from existing literature.
-
ii.
Introduction of Network Analysis as a computational technique for visualization and analysis of curated associations.
-
iii.
Development of a Network Analysis–based approach to identify and predict unknown associations of diets with Covid-19 and other diseases by comprehending the known associations.
2 State-of-the-art approaches
With more and more research about Covid-19, it is now a well-established fact that it is associated with the immune system and thus its prognosis is closely related to diet and certain comorbidities. There is a need to take advantage of this fact and study the association among these factors. Not much of the literature on this is available, this being a recent disease of concern. Table 1 describes the recent research works related to association of food with Covid-19. It is quite evident from the table that most of the works are based on survey of literature to understand the importance of nutrition for prevention or management of Covid-19. Only a very few studies are based on analysis of collected real-life data [25, 27]. In these studies, data related to levels of vitamins/nutrients (vitamin D, zinc, and selenium) of patients have been collected and analyzed for understanding their association with Covid-19. Since data have been collected from an academic medical center of University of Central Missouri (UCM) in the first study [25] and Tehran University of Medical Sciences in the second, it depends on factors like location, age, or ethnicity of groups involved and their physical parameters, thus covering a local view. The proposed approach aims to provide a global view by considering relations between Covid-19 and other diseases to infer unknown associations. Moreover, this approach is a novel attempt to use literature and computational approaches like Network Analysis to identify the associations between food and disease. Such an approach aims to develop a fast and efficient system which would be beneficial for caregivers and domain experts for planning a healthy lifestyle by eliminating toxic eating patterns. The approach might also act as a baseline to be used for predicting such associations for other related diseases.
The rest of the paper is organized as follows: Section 3 is a detailed description of Network Analysis and its different approaches that can be utilized for predicting disease-diet associations. Section 4 describes the proposed approach for inferring unknown associations along with the challenges encountered and their solutions. Since this is a new research domain, Section 5 discusses some probable future directions along with conclusions in Section 6.
3 Network Analysis: a technique for identification of associations
This section briefly introduces Network Analysis as an important technique for predicting relations from complex datasets. It also presents some major computational approaches of Network Analysis which have already been used in other domains and discusses its aspects that can be used for diet-related inferences.
3.1 Background
Network Analysis is one of the most suitable computational techniques for analysis of heterogeneous complex data. It utilizes the properties or structure of complex network to infer interesting insights from data. Network analysis offers a means to develop complex visualizations and draw inferences from them [19, 135]. It is used for solving real-world problems like predicting future connections from social media, understanding criminal networks, and food chains. Networks are also widely used for analysis of associations like disease-symptoms [23] or disease-microRNA []. Recently, Network Analysis has been in use for inferring various associations, for example, to explore disease similarities based on shared symptoms and genes []. Random walks in a network and machine learning have been used to predict microRNA-disease associations in another study [35]. Similarly, classification has been done to predict drug-disease associations from networks [36]. Adjacencies in networks have been used to score drug-disease associations which were further used as features for prediction of unknown links [36]. The same analogy can be utilized for studying complex associations of diseases and diets for Covid-19.
Network visualization and analysis can be useful for studying complex disease-diet associations in multiple dimensions. Figure 1 depicts a snapshot of subgraph of a disease-diet network including 2 disease nodes (Inflammatory Bowel Disease (IBD) and Ulcerative Colitis (UC)), 10 diet nodes, and 15 associations. The nodes in the network either represent a diet or a disease term which were searched in PubMed literature to identify if they are associated or not. The co-occurrence of the terms in research papers represents that they are linked to one another; thus, the weights of associations in the graph indicate the normalized value of their co-occurrences. A complete graph thus generated helps in recognizing unknown associations and in performing predictions. Moreover, multiple dimensions can be considered for further analysis, for example, foods can be represented on different levels like based on their ingredients or vitamins and minerals [13].

A snapshot of disease-diet subgraph based on term co-occurrences in PubMed publications
In a recent study [13, 14], analysis of disease and food networks has been carried out in different dimensions. Disease-food networks were developed and statistically analyzed using network parameters to realize significant foods. A food item was tagged as significantly harmful for a disease if multiple papers in literature report the same and vice-versa for significantly helpful. Further, a food item was tagged as significant if it is found to be associated with many diseases. Disease-disease network was constructed based on the similar foods to extract network and similarity measures for realizing disease complexity and similar diseases.
3.2 Proposed usage of Network Analysis techniques
Being a vast and novel area of research, Network Analysis can be utilized in multiple ways to extract significant disease and diet associations. The major computational approaches of Network Analysis which can be used for various diet-related inferences are as follows:
3.2.1 Overlapping of networks for prediction
Network overlapping and comparisons are done to realize unknown associations. Two networks can be overlapped if they have same types of nodes. For example, two networks having same diseases were developed in [23] where one was based on similar disease-symptoms and the other on similar disease-genes. The two graphs were integrated to create a single network of shared diseases and genes. The network parameters and analysis of this graph were useful for interpreting disease correlations and predicting unknown associations. Thus, two networks of diseases, in which one is based on diets and the other is based on a factor like symptoms, drugs, or genes, can also be overlapped to extract significant disease associations.
3.2.2 Dynamic graphs for understanding temporal relations
Apart from overlapping, a network can be compared to itself as it evolves with time so that the progression in pattern can be observed and future pattern can be forecasted [37, 38]. There are numerous meta-analysis [39–41] in which consumption data of a specific food item by patients suffering from a disease is collected. Similarly, dietary patterns of patients can be noted for a period and represent it in the form of temporal graphs. The graphs can be used to study dynamic trends for understanding disease-diet interactions.
3.3 Ranking and clustering for exploring similarity
Ranking is exploring the most significant links from networks and order them accordingly [35]. It is used for fixing the priority of links according to their rank. It also helps to simplify a dataset by identifying vital links. Ranking for diseases has been done previously based on their degree of association in the network [14]. Apart from using only the network parameters for ranking, the network can also be broken down into clusters and then ranking can be performed, so that the topmost significant associations are recognized. The inclusion of clustering will enhance the accuracy of ranking. The disease-diet network can be split into clusters and then ranking can be performed for each cluster. In this way, similar diets and disease links can be ranked.
3.3.1 Machine learning and link prediction for effective analysis
A machine learning framework can enhance traditional link prediction of networks. The features for this task can be extracted using various properties of a network and can be analyzed using machine learning techniques. The approaches like Clustering [42], Classification [36, 43,138], and Ranking [137, 138]can be applied to the database to predict future links. A framework generated using machine learning and link prediction as shown in Figure 2 can be used in forecasting the possibility of association of disease with another disease in a curated disease-disease network. Network parameters like SimRank, Common Neighbors, Adamic Adar, Clustering Coefficient, and Diameter [139, 140] can be extracted for different diseases like diabetes type 2, diabetes type 1, lung cancer, and breast cancer and used as features. Different machine learning approaches can then be applied to the retrieved dataset for inferring unknown associations.

Framework for using Machine Learning approach for Link Prediction in Networks by extracting features including SimRank (SR), Common Neighbors (CN), Adamic Adar (AA), Clustering Coefficient (CC), Diameter (D), and Betweenness Centrality (BC)
3.3.2 Personalized analysis
Work done in literature has focused on generic predictions for diseases. With technological changes and realization of customized diets, the future research focus should shift to personalized diet analysis. This can be done by collecting data from patients and then developing a network. For example, Personalized Nutrition Project [44] and Hundred Person Wellness Project [45] have collected physical and other health parameters data for exploring disease progression. In case of a diet-based analysis, data of patients’ dietary habits can be collected [44] or data of fit individuals can be accumulated using food questionnaires. Parameters like heart rate, blood pressure, Healthy Eating Index (HEI), and body mass index can be extracted and utilized as features. Using such data of different individuals, their similarities can be measured and further used to generate a network. Profiles of similar individuals can be clustered using appropriate clustering algorithm. Thus, a cluster can be predicted for a new individual based on its features and similarity. Based on the cluster an individual belongs to, diet of individual can be recommended (as shown in Figure 3). The data shown is sample data, but data for such analysis can be generated by monitoring patients as done in Personalized Nutrition Project or can be taken from resources like Eating and Health Module Dataset (American Time Use Survey) [46] as shown in Table 2. Different approaches other than this, that can be embarked for personalized inferences are:
-
i.
Understanding Diets: Diet-oriented predictions can be performed by evaluating data from food questionnaires and dietary habits. Individuals with similar diets can be clustered in a network, and then their network and other parameters can be explored in order to perform ranking.
-
ii.
Understanding temporal associations: We can also collect health parameters of an individual at different points of time and dynamic graphs can be compared to understand the progression or digression of disease based on various parameters.
-
iii.
Predicting possibility of disease: This can be done by training the dietary-based dataset of healthy and unhealthy individuals suffering from a disease using different machine learning and network algorithms and creating a suitable prediction model.

Framework for personalized dietary predictions by extracting features including heart rate (HR), systolic blood pressure (SBP), EUE (for participation in exercise in last 7 days with 1 as yes and 2 as no), body mass index (BMI), steps per day (SD)
4 Exploring diet associations with Covid-19 and other diseases: the proposed approach, challenges, and solutions
As seen in literature, many foods have been suggested as helpful or harmful for enhancing immunity and minimizing the risk of Covid-19 [1347, 8, 10, 47]. Foods are also known to be related to other diseases like diabetes and obesity, which are in turn related to Covid-19. This transitive relation can be used to infer unknown diet associations for Covid-19 and other diseases. Since Network Analysis has a great potential for understanding associations, it has been used in this study to uncover such associations. Network Analysis has been used effectively for identifying associations between diseases and entities like miRNA, symptoms, or drugs [18], but this research area has not been much explored for understanding its associations with diet. When a similar approach is undertaken for diet-based associations, it experiences challenges at different stages. This section discusses the proposed approach, challenges faced, and solutions to eliminate the challenges.
4.1 The proposed approach
In order to identify significant associations, there is a need to develop a stepwise approach which incorporates the necessary tasks of extracting, pre-processing, visualizing, and analyzing data using appropriate techniques. The approach developed in this paper is as shown in Figure 4.

Proposed approach for exploring associations among Covid-19, diet, and other diseases
4.1.1 Curation of experimentally supported disease-diet associations
Challenge
The first and foremost step for the proposed approach requires authentic data from an authentic database containing disease-diet associations in order to filter and establish meaningful associations between diet and Covid-19-related diseases. As no such database exists, curation is the only option. In order to curate such database, one method is to use existing websites, blogs, or books, but it lacks reliability because such sources provide only general notions regarding dietary habits. The second method is to identify relationships from existing literature by manually reading research papers as done in [14]. In this work, reading of abstracts has been undertaken for curation of database corresponding to dietary habits and diseases. It is again not the best method as it requires many man hours.
Solution
Literature mining of medical articles will expedite the curation process as well as preserve its reliability. For curating disease-diet associations, a technique named DIDACE has been proposed, designed, and used as an underlying method for automatically mining literature in our previous work [146]. This technique is further used in this study to extract experimentally supported associations among diet and Covid-19-related diseases. The proposed technique works as per the following steps (shown in Figure 5):

Steps for curation of associations between diet and Covid-19-related diseases
-
i.
DIDCorDIDACE for extracting associations: A software application has been designed in our previous work [146] to extract articles in which disease and diet terms occur together. The database acts as a benchmark containing experimentally supported associations from which required associations can be further used. Such approach has been used in many other biomedical researches to produce authentic data [23, 146]. Standard disease and diet terms were downloaded from research vocabulary named MeSH [48]. MeSH vocabulary is used to index research articles in medical literature PubMed [49]. The PubMed articles can be searched via an API called e-utilities. Thus, the programming application utilizes e-utilities to search disease and diet MeSH terms from PubMed articles. It returns an xml containing the number of articles in which the disease-diet pair occurs (termed as co-occurrence) along with their ids. The retrieved co-occurrences are further normalized using Term Frequency-Inverse Document Frequency metric [50]. A detailed description of disease-diet curation is discussed in the previous work [48, 50. Thus, the curated database is a good fit for developing a network.. It is evident from the figure that most of the associations have low co-occurrences while a very few associations have high values. This is similar to a power law distribution which is a property of complex networks [6, 141, 146]. The distribution of co-occurrences for curated disease-diet associations is as shown in Figure 6. It is evident from the figure that most of the associations have low co-occurrences while a very few associations have high values. This is similar to a power law distribution which is a property of complex networks [47, 141]. Thus, the curated database is a good fit for developing a network.
Fig. 6 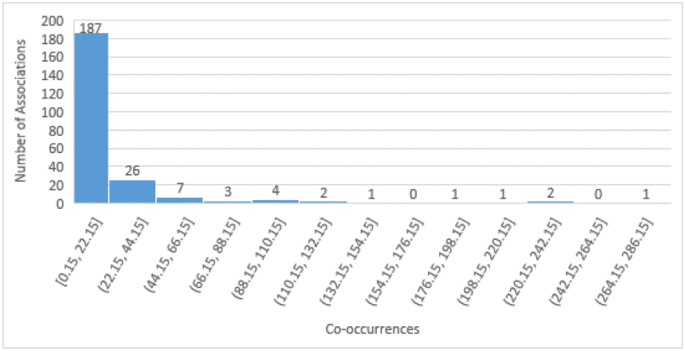
Distribution of co-occurrences for curated disease-diet associations
-
ii.
Evaluation of curated database: The retrieved disease-diets database contains associations between two variables, namely disease, and diet. A statistical significance test needs to be performed to examine the significance of their associations. Since more than 20% of the relations have expected frequencies (co-occurrences) less than 5, Fisher’s exact test is performed on this data to comprehend statistical significance [51]. The null hypothesis in this case is that the disease terms are independent to diet terms, whereas the alternative hypothesis suggests a relationship between the two variables. The obtained p-value=0.0004997 is less than 0.05; thus, the null hypothesis is rejected at 5% significance level. This affirms a significant relationship between diseases and diets in the retrieved database.
-
iii.
Selection of Covid-19-related diseases and diets associations: Covid-19 is a novel disease and research regarding its associations with other diseases is still in its infancy. Due to this, diseases having evidence in literature regarding its relation to Covid-19 are focused in this study. A study [52] explored the gene expression patterns of Covid-19 and found high similarities with the characteristic patterns of a very few other diseases. The diseases include diabetes mellitus type 2 (T2DM), leukemia, psoriasis, pulmonary arterial hypertension, and non-alcoholic fatty liver disease (NAFLD). The similarities suggest that persons suffering from these diseases might need to take extra care for prevention of Covid-19 risk. Other studies also suggest that patients suffering from T2DM and NAFLD are known to be at a greater risk of developing infections and thus Covid-19 [53–56]. Thus, out of these diseases, only T2DM and NAFLD have been considered for study due to presence of strong evidence in literature regarding association with Covid-19. The curated database contains 274131 experimentally supported associations between 1917 diseases and 153 diets. This becomes a baseline for selecting records pertaining only to diseases known to be related to Covid-19. A total of 235 relations between NAFLD-Diets and T2DM-Diets are selected from the curated database.
-
iv.
Storage and visualization of associations: The retrieved associations database is further stored as a graph in one of the benchmark platforms for graph database management, named Neo4j. The graph contains 137 diet nodes, 2 disease nodes (T2DM and NAFLD), and 235 relationships between them. A subgraph of this graph database is shown in Figure 7 in which the weight of edges depicts normalized co-occurrences using min-max scaler. Min-max normalization is used so that the complete dataset is viewed on a standard scale even if data from different sources is integrated. The most commonly used range for scaling is 0 to 1 [57], but in this study, a value of 0 would mean absence of association. For example, in this study, the minimum value of normalized co-occurrence is 0.1538 (association between NAFLD and infant food). If this value is scaled with range 0–1, it would convert to 0, which will lead to an ambiguous record. Moreover, the co-occurrences retrieved vary from very small values to very large values. For instance, the maximum value of normalized co-occurrence is 274.65 (association between T2DM and dietary fiber). A range from 0 to 1 would not be a good fit for such a vast difference between minimum and maximum values. Thus, a broader range not starting from 0, i.e., a range from 1 to 10 has been selected for this purpose. This implies association between NAFLD and infant food is taken as 1, T2DM and dietary fiber as 10, and other values lie between 1 to 10. As depicted in the figure, T2DM and NAFLD are mutually related to beer, coffee, energy drinks, carbonated beverage, and many other diet terms.
Fig. 7 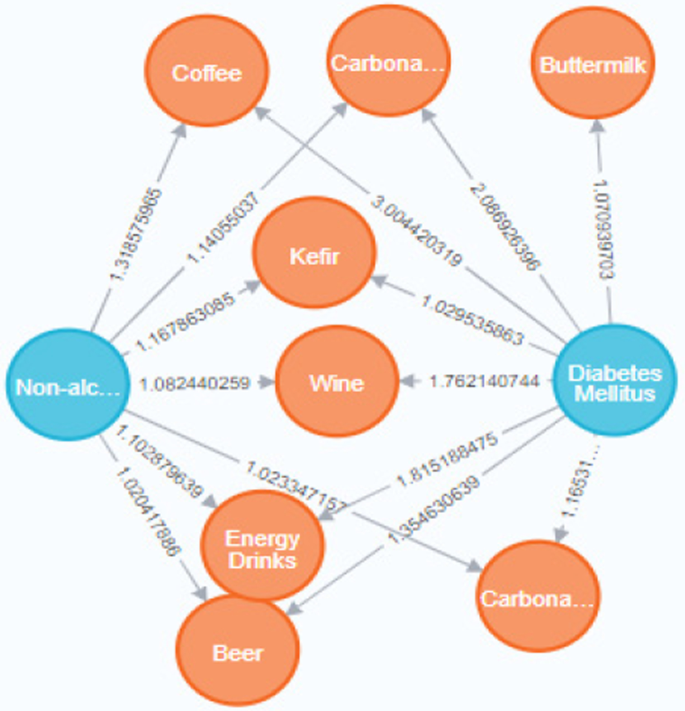
A subgraph of retrieved Covid-19-related diseases and diets associations graph


4.1.2 Curation of disease-disease associations
Challenge
After the Covid-19-related diseases and diets associations are established, the next step is to understand the associations between the underlying diseases. The associations between NAFLD and T2DM can be extracted using similarity measures. Finding an effective similarity measure is also a challenge in this study, as it will ultimately affect the results obtained. One approach is to use the curated disease-diet association graph and find similarity of diseases based on graph using traditional measures [58] like Cosine similarity or Euclidean distance, but this might make the entire database redundant.
Solution
The association between NAFLD and T2DM is extracted using semantic similarity which is based on finding relatedness from semantic meanings of terms [59]. The following tasks are performed in this step (also shown in Figure 8):

Steps for curation of disease-disease and disease-Covid-19 associations graph
-
i.
A toolkit named DincRNA [60] provides DisSim tool offering five state-of-art methods to choose for calculating similarity of diseases. In this work, Wang’s method [59] is used which is based on finding semantic similarity between terms using hierarchical structure in the ontology. This method is used because it adds a different perspective (using semantic meanings) to the dataset unlike other traditional similarity metrics. The retrieved data is further normalized using min-max scaler with a range of 1–10. This range is same as the previous step so that complete dataset follows same distribution. Thus, a graph containing disease-diet and disease-disease associations is obtained.
-
ii.
If Covid-19 node is introduced in this graph along with its similarity with the other diseases as relationships, then its association with diets can be calculated. Due to its novelty, associations database between Covid-19 and other diseases is not available as of now. Thus, similarity of Covid-19 with other diseases is computed in a similar manner as done in the previous step by curating its co-occurrences using PubMed and e-utilities. The retrieved dataset is normalized using min-max scaler (range 1–10) and records pertaining to relationships with NAFLD and T2DM are used to develop a graph containing disease-diet, disease-disease, and disease-Covid-19 associations.
4.1.3 Prediction of diet associations for Covid-19 and other diseases
Challenge
Traditional methods of predicting probable links in a network mainly include techniques based on nodes similarity [14], statistics, and probability [61]. There is a need for a more powerful and computationally intelligent approach to handle complex networks. The approach should be able to utilize network structure as well as must possess learning capabilities.
Solution
In this step, inferences are drawn using graph algorithms, namely, the Louvain algorithm (LA) and K-Nearest Neighbors (KNN) using the Page rank algorithm (PR). These two algorithms (LA and KNN) are selected because they utilize different learning properties, i.e., unsupervised and supervised respectively to infer relations. Initially, the Louvain algorithm is used to divide the graph database into communities. Since only two communities are identified in this step, another algorithm KNN is introduced to further refine the analysis. In KNN, the Page Rank algorithm is applied to rank all the nodes in graph. This is done so that the ranks can be further used for finding similarity. Thus, LA finds communities in the graph whereas KNN fetches the top most related nodes in the graph. Use of combination of graph algorithms ensures refined results and better precision. The steps performed are discussed as follows (also shown in Figure 9):

Steps for prediction of diet associations for Covid-19 and comorbidities (bigger size of node depicts a better rank in Page Ranking algorithm)
-
i.
Louvain algorithm is an unsupervised graph algorithm for inferring communities [62]. Nodes reported in the same community are known to be more related to one another than those in other communities. The algorithm works on the principle of maximizing modularization gain, developing communities, and reiterating the previous steps until no more changes are evident. The modularity gain of a node in a community is defined as in Equation (1):
$$\mathrm{M}=\left[ \frac{{\Sigma }_{in}+2{k}_{i,in }}{2m}-{\left(\frac{{\Sigma }_{tot}+{k}_{i}}{2m}\right)}^{2}\right]-\left[\frac{{\Sigma }_{in}}{2m}-{\left(\frac{{\Sigma }_{tot}}{2m}\right)}^{2}-{\left(\frac{{k}_{i}}{2m}\right)}^{2}\right]$$(1)where m is the sum of weights of all the relationships in the graph, \({\Sigma }_{in}\) is the sum of relationships in the community, \({k}_{i,in}\) is the sum of weights of relationships starting from node i to other nodes in the community, \({k}_{i}\) is the sum of weights of relationships incident to i, and \({\Sigma }_{tot}\) is the sum of weights of relationships incident to nodes in the community. This algorithm is selected because it has no prior assumptions regarding community of nodes and is specifically designed for graphs. Graph retrieved from the above steps is stored in Neo4j and Louvain algorithm is run using cypher queries. Two communities are identified containing a total of 140 nodes.
-
ii.
In order to retrieve refined results and enhance the analysis, another algorithm following supervised property is performed. KNN algorithm is applied for all nodes in the graph to infer most related nodes. It is a machine learning algorithm for finding top K similar nodes for each node in the dataset using a similarity function. Similarity function is calculated using a given property of nodes in the graph. In this study, page rank of nodes is taken as the given property based on the principle that more connected nodes are more similar. Page Rank (PR) calculates the rank of a node by using the number of nodes with which it is connected [63]. It was introduced in Google for ranking the webpages so as to optimize the search. Since page rank is a float value in this study, cosine similarity is used as similarity function by KNN. This algorithm is selected because it is a simple technique with good accuracy and less runtime, which is suitable for our small dataset.
4.2 Results and evaluation
The two communities identified using the Louvain algorithm contain 46 and 94 nodes respectively. One of the communities contains NAFLD and Covid-19 terms along with 44 diet terms. The second community contains 93 diet terms related to T2DM. The disease and diet nodes retrieved in different communities are described in Table 3.
KNN and PR algorithms are performed for refining the results further. The graph database is used to firstly obtain page ranks of the nodes and then K nearest neighbors algorithm is applied for all the nodes. A higher sample rate increases the accuracy of KNN, thus it is chosen as 0.8 along with delta threshold of 0.001. Different variations of algorithm are performed with value of K ranging from 2 to 20. Initially, two topmost similar nodes are retrieved, but as the value of K increases, other most similar nodes are added as described in Table 4.
The obtained associations are validated by searching Pubmed research papers with respective diet terms. Table 5 represents important associations validated from Pubmed literature.
All the associations predicted for T2DM have been identified from literature as shown in Table 5 (records for terms “sweetening agents,” “flavoring agents,” and “food additives” are displayed collectively because of same literature involved). Interestingly, most of the diets associated with NAFLD have also been identified except bread, dietary fats unsaturated, and edible grains. Being a novel disease, research related to Covid-19 is in its infancy; thus, lesser number of diets have been validated for it. The diets predicted and validated for Covid-19 risk management include egg yolk, celery, sesame oil, strawberry, raspberries, honey, carrot, kefir, and onion. The predicted associations which could not be validated include food items like beets, watermelon, shellfish, cucumber, egg white, pumpkin, brazil nuts, infant formula, raw food, peach, and carbonated water.
Evaluation for this study is done using precision as a measure due to the nature of database. Being a prediction from dietary database and relating directly to human health, precision has utmost importance in this case. A high precision might mean returning less results, but most of it is correct. This kind of database cannot afford low precision with high number of incorrect results. Precision is calculated as ratio of true positives and all the positives where true positives refer to actual associations (confirmed using PubMed literature validation) and all positives refer to the predicted associations. Since relation between Covid-19 and diets is a very fresh domain, validation of its corresponding results in literature is difficult. If only NAFLD and T2DM are considered, then precision is around 92.5% as shown in Table 6. The table depicts different combinations of data samples of results and their corresponding precision. The precision with all the data samples (76.7%) is also quite interesting because of the presence of results related to a novel disease.
4.3 Discussion
In this study, Network Analysis algorithms aim to uncover diet and disease associations from a graph database. Important inferences can be drawn from the results retrieved as follows:
-
Similar diets have been predicted for T2DM and NAFLD which confirms the overlap seen in Figure 10. The diets include Dietary Fats, Dietary Fibre, Dietary Carbohydrates, Sweetening Agents, Flavoring Agents, Food Additives, Dietary Sucrose, Nutritive Sweeteners, Dietary Supplements, Vegetables, Whole grains, Bread, Dietary Fat Unsaturated, Fruits, Red Meat, Coffee, Nuts, Edible grains, Meat, and High Fructose Corn Syrup. All the predicted diets have been validated from literature for T2DM. This is due to the existence of a substantial research regarding association of T2DM with diets. In case of NAFLD, all the diets except bread, dietary fats unsaturated, and edible grains have been validated.
-
It is evident from the results and validations that diets like whole grains, vegetables, fruits, and nuts are found to be helpful for both NAFLD and T2DM diseases. The reason behind this relation lies in the fact that many researchers suggest Mediterranean Diet (MD) for prevention and management of chronic diseases like T2DM and NAFLD [99, 145]. Mediterranean Diet corresponds to more consumption of plant-based foods and fish but less consumption of dairy products and meat, which very well agrees with the results obtained.
-
The top 20 predicted diets for Covid-19 include Egg yolk, Celery, Beets, Sesame oil, Watermelon, Peach, Carrot, Strawberry, Raspberries, Shellfish, Brazil nuts, Pumpkin, Infant Formula, Raw foods, Cucumber, Egg white, Carbonated water, Kefir, Onion, and Honey. Out of these, 9 associations have been validated including egg yolk, celery, sesame oil, strawberry, raspberries, honey, carrot, kefir, and onion. Validated diets for Covid-19 imply that they are currently being inspected for future prospectives of disease prevention and management. Food items containing vitamin C and A like strawberry and carrot respectively along with those exhibiting antiviral properties like kefir are found in the list of validated diets.
-
The diet-based associations predicted for Covid-19 are depicted in Figure 11 along with their similarity scores. The most similar diets as seen in the figure include egg yolk, celery, beets, sesame oil, and watermelon. Out of these 5 diets, 3 diets including egg yolk, celery, and sesame oil have been validated in literature. These kinds of validations are interesting, considering the novelty of disease.
-
Considering the high similarity scores retrieved for diets with Covid-19 (refer to Figure 11), associations which could not be validated in literature should be studied for further research. These include beets, watermelon, shellfish, cucumber, egg white, pumpkin, brazil nuts, infant formula, raw food, peach, and carbonated water which must be considered for research in this time of pandemic. The significance of associations can be confirmed by performing randomized trial or cohort study. Similarly, associations that could not be validated for NAFLD including bread, dietary fats unsaturated, and edible grains should also be inspected for future associations.
-
Covid-19 and NAFLD are seen in the same community, thus the diets present in the community must be explored for utilizing them in case of patients suffering from both the diseases. The confirmed associations can then be used for planning a better diet for patients suffering from Covid-19, T2DM, or NAFLD or combinations of these. This approach can help to expedite the process of testing different diets for Covid-19 and act as a baseline to discover dynamics of Covid-19 with different comorbidities as per patients’ health status.

Important communities identified using the Louvain algorithm (diet terms including almonds, cashew, and mustard are clearly visible in one cluster with T2DM whereas pumpkin, apricot etc. are visible in other clusters with Covid-19 and NAFLD. Certain diets are also visible in the overlapping of both clusters including whole grains and nuts)

Top 20 associations identified for Covid-19 along with similarity scores
5 Limitations and future research directions
Understanding the associations of disease and diet requires integration of multiple dimensions of networks. Due to a lack of dataset and novelty of disease in consideration, there are limitations to this work which can be overcome by undertaking certain research directions in future:
-
The approach followed in this paper covers a small scope. This is due to consideration of only a few diseases (T2DM and NAFLD) as comorbidities. This small scope can be used by caregivers for planning dietary recommendations of patients with comorbidities. This work can also be extended with a larger scope in which other known diseases can be added in the network to enlarge the network. This will require more validated database of associations, but this approach might be helpful for domain experts for understanding generic food and disease dynamics. Moreover, a similar approach can be developed for predicting associations for other novel diseases.
-
The relation of diets with Covid-19 and other comorbidities is predicted through the proposed approach but its type (harmful/helpful) is still unknown. In addition to finding the strength of correlation with other diets, another dimension of relationship type should also be explored. Some diets may be harmful for one disease, but helpful for its subtype or vice versa. For example, consumption of cheese is known to be helpful for a disease named Inflammatory Bowel Disease (IBD) [132], whereas it is harmful for its subtype named Crohn’s Disease (CD) and Ulcerative Colitis (UC) [133]. A graph containing such complex relationships is as shown in Figure 12. Such underlying graph can be utilized to understand the role of different diets for diseases. Similar to the previous analysis, we can introduce Covid-19 node in this graph and its relation (harmful/helpful) can be predicted with other diets. Label propagation algorithms can be used for this purpose.
-
It is known that different individuals have different response to same diet. The food item which suits one person, may not suit the other. In case of conditions like food allergies, diabetes, or pregnancy, individuals might need alternate diet recommendations. The proposed approach does not take this scenario in consideration. A similar approach can be devised in which associations between diets can be known based on their associated diseases. If two diet/food items are associated with many mutual diseases, they will be more similar. Based on this principle, their similarity can be predicted using similarity algorithms. Once the similarities are known, a graph can be generated and clustering/community detection can be performed. Alternate diets can be recommended using inferred communities and relationships.
-
This approach aims to explore unknown diet associations for Covid-19 and other diseases using computational methods. The main purpose is to expedite the process of understanding diet-based associations using Network Analysis. The predictions might act as a base for researchers to further explore the actual significance of associations. Only after the predicted diets are validated by dieticians and medical researchers, the associations can further be used to design a service to be utilized by caregivers for entering the comorbidities of patients and plan diets for them.

Harmful and helpful diets for Inflammatory Bowel Disease, Ulcerative Colitis, and Crohn’s Disease
6 Conclusion
Disease-diet association is one of the most unexplored databases but can be extremely valuable for understanding progression of novel diseases if mined using appropriate computational methods. Covid-19 is a novel and life-threatening disease which currently requires steadfast analysis in multiple dimensions including disease and diet associations. In this paper, a computational approach has been proposed to identify diet associations for Covid-19 and other diseases (NAFLD and T2DM) using Network algorithms (LA, KNN, and PR). There are certain challenges which are faced during development of the approach but computational methods like Network analysis and literature mining have been introduced to eliminate them. A blend of disease-diet, disease-disease, and disease-Covid-19 associations along with computational techniques aims to infer unknown diet associations with high precision. The computational techniques expedite the process of exploration of diet associations which can be further validated by medical researchers or dieticians so as to design future dietary guidelines. This article also explores different methods in which Network analysis can further aid in recognizing unknown associations based on diets and diseases. Such powerful computational frameworks will not only help in predicting unknown associations but can also transform into personalized healthcare solutions.
6.1 Ethics approval
This article does not contain any studies with human participants or animals performed by any of the authors.
References
“Coronavirus disease 2019.” [Online]. Available: https://www.who.int/emergencies/diseases/novel-coronavirus-2019. [Accessed: 01-May-2020].
Chang MC, Park YK, Kim BO, Park D (2020) Risk factors for disease progression in COVID-19 patients. BMC Infect Dis 20(1):1–6
Yang J et al (2020) Prevalence of comorbidities and its effects in coronavirus disease 2019 patients: a systematic review and meta-analysis. Int J Infect Dis 94:91–95
Adekunle, Sanyaolu Chuku, Okorie Aleksandra, Marinkovic Risha, Patidar Kokab, Younis Priyank, Desai Zaheeda, Hosein Inderbir, Padda Jasmine, Mangat Mohsin, Altaf (2020) Comorbidity and its Impact on Patients with COVID-19. SN Comprehensive Clinical Medicine 2(8) 1069-1076 10.1007/s42399-020-00363-4
Bolin, Wang Ruobao, Li Zhong, Lu Yan, Huang (2020) Does comorbidity increase the risk of patients with COVID-19: evidence from meta-analysis. Aging 12(7) 6049-6057 10.18632/aging.103000
Long QX et al (2020) Clinical and immunological assessment of asymptomatic SARS-CoV-2 infections. Nat Med 26(8):1200–1204
Tay MZ, Poh CM, Rénia L, MacAry PA, Ng LFP (2020) The trinity of COVID-19: immunity, inflammation and intervention. Nat Rev Immunol 20(6):363–374
Calder PC (2020) Nutrition, immunity and COVID-19. BMJ Nutr Prev Health 3(1):74
Gasmi A, Noor S, Tippairote T, Dadar M, Menzel A, Bjørklund G (2020108409) Individual risk management strategy and potential therapeutic options for the COVID-19 pandemic. Clin Immunoly 215
Naja F, Hamadeh R (2020) Nutrition amid the COVID-19 pandemic: a multi-level framework for action. Eur J Clin Nutr 74(8):1117–1121
Muscogiuri G, Barrea L, Savastano S, Colao A (2020) Nutritional recommendations for CoVID-19 quarantine. Eur J Clin Nutr 74(6):850–851
Butler MJ, Barrientos RM (2020) The impact of nutrition on COVID-19 susceptibility and long-term consequences. Brain Behav Immun 87:53–54
Bhattacharyya M (2015) Disease dietomics. XRDS: Crossroads, The ACM Mag Stud 21(4):38–44
Bhattacharyya M, Maity S, Bandyopadhyay S (2017) Exploring the Missing Links between Dietary Habits and Diseases. IEEE Trans Nanobiosci 16(3):226–238
Bao W et al (2018) Mutli-Features Prediction of Protein Translational Modification Sites. IEEE/ACM Trans Comput Biol Bioinforma 15(5):1453–1460
Bao W, Yang B, Chen B (2021) 2-hydr_Ensemble: Lysine 2-hydroxyisobutyrylation identification with ensemble method. Chemom Intell Lab Syst 215:104351
Bao W, Huang D-S, Chen Y-H (2020) MSIT: Malonylation Sites Identification Tree. Curr Bioinforma 15(1):59–67
Toor R, Chana I (2020) Network analysis as a computational technique and its benefaction for predictive analysis of healthcare data: a systematic review. Arch Comput Methods Eng 28(3):1689–1711
“Network Analysis. Lecture 1. Introduction to Network Science - YouTube.” [Online]. Available: https://www.youtube.com/watch?v=UHnmPu8Zevg. [Accessed: 08-Oct-2020]
“Graph Analytics for Big Data | Coursera.” [Online]. Available: https://www.coursera.org/learn/big-data-graph-analytics. [Accessed: 08-Oct-2020]
Razaghi-Moghadam Z, Abdollahi R, Goliaei S, Ebrahimi M (2016) HybridRanker: integrating network topology and biomedical knowledge to prioritize cancer candidate genes. J Biomed Inf 64:139–146
U. Martin, Singh-Blom Nagarajan, Natarajan Ambuj, Tewari John O., Woods Inderjit S., Dhillon Edward M., Marcotte Patrick, Aloy (2013) Prediction and Validation of Gene-Disease Associations Using Methods Inspired by Social Network Analyses. PLoS ONE 8(5) e58977-10.1371/journal.pone.0058977
Zhou X, Menche J, Barabási AL, Sharma A (2014) Human symptoms-disease network. Nat Commun 5(1):1–10
Ma W, Zhang L, Zeng P, Huang C, … JL-B In, and U (2017) An analysis of human microbe–disease associations. academicoupcom 18(1):85–97
Meltzer DO, Best TJ, Zhang H, Vokes T, Arora V, Solway J (2020) Association of Vitamin D Status and Other Clinical Characteristics With COVID-19 Test Results. JAMA Netw Open 3(9):e2019722–e2019722
Quan, Zou Jinjin, Li Qingqi, Hong Ziyu, Lin Yun, Wu Hua, Shi Ying, Ju (2015) Prediction of MicroRNA-Disease Associations Based on Social Network Analysis Methods. BioMed Research International 20151-9 10.1155/2015/810514
Razeghi Jahromi S et al. (2021) The correlation between serum selenium, zinc, and COVID-19 severity: an observational study. BMC Infect Dis 21(1):1–9
Abdulah DM, Hassan AB (2020) Relation of Dietary Factors with Infection and Mortality Rates of COVID-19 across the World. J Nutr Health Aging 24(9):1011–1018
Gasmi A et al (2020) Micronutrients as immunomodulatory tools for COVID-19 management. Clin Immunol 220:108545
Jayawardena R, Sooriyaarachchi P, Chourdakis M, Jeewandara C, Ranasinghe P (2020) Enhancing immunity in viral infections, with special emphasis on COVID-19: a review. Diabetes Metab Syndr 14(4):367–382
Abobaker A, Alzwi A, Alraied AHA (2020) Overview of the possible role of vitamin C in management of COVID-19. Pharmacol Rep 72(6):1517–1528
Budhwar S, Sethi K, Chakraborty M (2020) A Rapid Advice Guideline for the Prevention of Novel Coronavirus Through Nutritional Intervention. Curr Nutr Rep 9(3):119–128
Losso JN, Losso MJN, Toc M, Inungu JN, Finley JW (2021) The Young Age and Plant-Based Diet Hypothesis for Low SARS-CoV-2 Infection and COVID-19 Pandemic in Sub-Saharan Africa. Plant Foods Hum Nutr 76(3):270–280
Rocha J, Basra T, El Kurdi B, Venegas-Borsellino C (2021) Effects of Potential Micro- and Macro-nutrients in Combatting COVID-19. Curr Surg Rep 9(10):1–6
Alhajj Reda, Rokne Jon (eds) (2018) Encyclopedia of Social Network Analysis and Mining,” Encyclopedia of Social Network Analysis and Mining. Springer, New York
Moghadam H, Rahgozar M, Gharaghani S (2016) Scoring multiple features to predict drug disease associations using information fusion and aggregation. SAR QSAR Environ Res 27(8):609–628
Carroll N, Richardson I (2019) Mapping a Careflow Network to assess the connectedness of Connected Health. Health Inform J 25(1):106–125
Holme P, Saramäki J (2012) Temporal networks. Phys Rep 519(3):97–125
Aune D, Norat T, Romundstad P, Vatten LJ (2013) Whole grain and refined grain consumption and the risk of type 2 diabetes: a systematic review and dose-response meta-analysis of cohort studies. Eur J Epidemiol 28(11):845–858
Schwingshackl L et al (2017) Food groups and risk of type 2 diabetes mellitus: a systematic review and meta-analysis of prospective studies. Eur J Epidemiol 32(5):363–375
Ding M, Bhupathiraju SN, Chen M, Van Dam RM, Hu FB (2014) Caffeinated and decaffeinated coffee consumption and risk of type 2 diabetes: a systematic review and a dose-response meta-analysis. Diabetes Care 37(2):569–586
Wu J, Zhang G, Ren Y (2017) A balanced modularity maximization link prediction model in social networks. Inf Process Manag 53(1):295–307
Oh M, Ahn J, Yoon Y (2014) A network-based classification model for deriving novel drug-disease associations and assessing their molecular actions. PLoS ONE 9(10):e111668
“Personalized Nutrition Project.” [Online]. Available: http://newsite.personalnutrition.org/WebSite/Home.aspx. [Accessed: 10-Oct-2020]
“100K Wellness Project · Institute for Systems Biology.” [Online]. Available: https://isbscience.org/research/100k-wellness-project/. [Accessed: 24-Jul-2021]
“Eating & Health Module Dataset | Kaggle.” [Online]. Available: https://www.kaggle.com/bls/eating-health-module-dataset. [Accessed: 10-Oct-2020]
Zhang L, Liu Y (2020) Potential interventions for novel coronavirus in China: a systematic review. J Med Virol 92(5):479–490
“Medical Subject Headings.” [Online]. Available: https://www.nlm.nih.gov/mesh/meshhome.html. [Accessed: 10-2-2022]
“Home - PubMed - NCBI.” [Online]. Available: https://www.ncbi.nlm.nih.gov/pubmed/. [Accessed: 11-Feb-2020]
Jones KS (1972) A statistical interpretation of term specificity and its application in retrieval. 1972. J Inf Sci Eng
Kim H-Y (2017) Statistical notes for clinical researchers: Chi-squared test and Fisher’s exact test. Restor Dent Endod 42(2):152–155
Singh MK, Mobeen A, Chandra A, Joshi S, Ramachandran S (2021) A meta-analysis of comorbidities in COVID-19: which diseases increase the susceptibility of SARS-CoV-2 infection? Comput Biol Med 130:104219
Kyrou I, Robbins T, Randeva HS (2020) COVID-19 and diabetes: no time to drag our feet during an untimely pandemic. J Diabetes Complicat 34(9):107621
Portincasa P, Krawczyk M, Smyk W, Lammert F, Di Ciaula A (2020) COVID-19 and non-alcoholic fatty liver disease: Two intersecting pandemics. Eur JClin Investig 50(10):e13338
Prins GH, Olinga P (2020) Potential implications of COVID-19 in non-alcoholic fatty liver disease. Liver Int
Huang R et al (2020) Clinical Features of Patients With COVID-19 With Nonalcoholic Fatty Liver Disease. Hepatol Commun 4(12):1758–1768
“6.3. Preprocessing data — scikit-learn 1.0.1 documentation.” [Online]. Available: https://scikit-learn.org/stable/modules/preprocessing.html. [Accessed: 06-Dec-2021]
Lesot MJ, Rifqi M, Benhadda H (2009) Similarity measures for binary and numerical data: a survey. Int J Knowl Eng Soft Data Paradigms 1(1):63–84
Wang JZ, Du Z, Payattakool R, Yu PS, Chen CF (2007) A new method to measure the semantic similarity of GO terms. Bioinformatics 23(10):1274–1281
Cheng L, Hu Y, Sun J, Zhou M, Jiang Q (2018) DincRNA: A comprehensive web-based bioinformatics toolkit for exploring disease associations and ncRNA function. Bioinformatics 34(11):1953–1956
Martínez V, Berzal F, Cubero JC (2016) A survey of link prediction in complex networks. ACM Comput Surv 49(4):1–33
Blondel VD, Guillaume JL, Lambiotte R, Lefebvre E (2008) Fast unfolding of communities in large networks. J Stat Mech Theory Exp 10:P10008
Page L, Brin S, Motwani R, Winograd T (1998) The PageRank Citation Ranking: Bringing Order to the Web
Yanni AE et al (2018) Controlling type-2 diabetes by inclusion of Cr-enriched yeast bread in the daily dietary pattern: a randomized clinical trial. Eur J Nutr 57(1):259–267
Kyrø C, Tjønneland A, Overvad K, Olsen A, Landberg R (2018) Higher whole-grain intake is associated with lower risk of type 2 diabetes among middle-aged men and women: the Danish diet, cancer, and health cohort. J Nutr 148(9):1434–1444
Ericson U et al (2013) High intakes of protein and processed meat associate with increased incidence of type 2 diabetes. Br J Nutr 109(6):1143–1153
Liatis S et al (2009) The consumption of bread enriched with betaglucan reduces LDL-cholesterol and improves insulin resistance in patients with type 2 diabetes. Diabetes Metab 35(2):115–120
Akhoundan M, et al. (2016) The association of bread and rice with metabolic factors in type 2 diabetic patients. PLoS ONE 11(12)
Haimoto H, Watanabe S, Maeda K, Murase T, Wakai K (2020) Reducing carbohydrate from individual sources has differential effects on glycosylated hemoglobin in Type 2 Diabetes Mellitus Patients on Moderate Low-Carbohydrate Diets. Diabetes Metab 44
Schwingshackl L et al (2017) Food groups and risk of type 2 diabetes mellitus: a systematic review and meta-analysis of prospective studies. Eur J Epidemiol 32(5):363–375
Aune D, Norat T, Romundstad P, Vatten LJ (2013) Whole grain and refined grain consumption and the risk of type 2 diabetes: a systematic review and dose-response meta-analysis of cohort studies. Eur J Epidemiol 28(11):845–858
Basiak-Rasała A, Różańska D, Zatońska K (2019) Food groups in dietary prevention of type 2 diabetes. Roczniki Panstwowego Zakladu Higieny 70(4)
Gabrial SGN, Shakib MCR, Haleem MSMA, Gabrial GN, El-Shobaki FA (2020) Hypoglycemic potential of supplementation with a vegetable and legume juice formula in type 2 diabetic patients. Pak J Biol Sci 23(2):132–138
Tiwari A (2014) Revisiting ‘Vegetables’ to combat modern epidemic of imbalanced glucose homeostasis. Pharmacogn Mag 10(2):S207
Ley SH, Hamdy O, Mohan V, Hu FB (2014) Prevention and management of type 2 diabetes: dietary components and nutritional strategies. Lancet 383(9933):1999–2007 (Elsevier B.V.)
Jannasch F, Kröger J, Schulze MB (2017) Dietary patterns and type 2 diabetes: a systematic literature review and meta-analysis of prospective studies. J Nutr 147(6):1174–1182
Salas-Salvadó J, Martinez-González MÁ, Bulló M, Ros E (2011) The role of diet in the prevention of type 2 diabetes. Nutr Metab Cardiovasc Dis 21(SUPPL):2
Carrasquilla GD, Jakupović H, Kilpeläinen TO (2019) Dietary fat and the genetic risk of type 2 diabetes. Curr Diabetes Rep 19(11):1–6
Tay J et al (2015) Comparison of low- and high-carbohydrate diets for type 2 diabetes management: a randomized trial. Am J Clin Nutr 102(4):780–790
Santos RMM, Lima DRA (2016) Coffee consumption, obesity and type 2 diabetes: a mini-review. Eur J Nutr 55(4):1345–1358 (Dr. Dietrich Steinkopff Verlag GmbH and Co. KG)
Guasch-Ferré M, Merino J, Sun Q, Fitó M, Salas-Salvadó J (2017) Dietary polyphenols, Mediterranean diet, prediabetes, and type 2 diabetes: a narrative review of the evidence. Oxidative Med Cell Longev 2017
Carlström M, Larsson SC (2018) “Coffee consumption and reduced risk of developing type 2 diabetes: a systematic review with meta-analysis. Nutr Rev 76(6):395–417 (Oxford University Press)
Neuenschwander M, et al. (2019) Role of diet in type 2 diabetes incidence: umbrella review of meta-analyses of prospective observational studies. BMJ 366 BMJ Publishing Group
Pan A et al (2011) Red meat consumption and risk of type 2 diabetes: 3 Cohorts of US adults and an updated meta-analysis. Am J Clin Nutr 94(4):1088–1096
Shetty SS, Kumari SN, Shetty PK (2020) ω-6/ω-3 fatty acid ratio as an essential predictive biomarker in the management of type 2 diabetes mellitus. Nutrition (Burbank, Los Angeles County, Calif) 79–80
Misra A, Singhal N, Khurana L (2010) Obesity, the metabolic syndrome, and type 2 diabetes in developing countries: role of dietary fats and oils. J Am Coll Nutr 29(3 Suppl):289S-301S
Davison KM, Temple NJ (2018) Cereal fiber, fruit fiber, and type 2 diabetes: explaining the paradox. J Diabetes Complicat 32(2):240–245
Zhao L et al (2018) Gut bacteria selectively promoted by dietary fibers alleviate type 2 diabetes. Science (New York, NY) 359(6380):1151–1156
Pcsolyar NS, de Jonghe BC (2014) Examining the Use of Dietary Fiber in Reducing the Risk of Type 2 Diabetes Mellitus in Latino Youth. J Transcult Nurs 25(3):249–255
Jung CH, Choi KM (2017) Impact of High-Carbohydrate Diet on Metabolic Parameters in Patients with Type 2 Diabetes. Nutrients 9(4)
O’Neill BJ (2020) Effect of low-carbohydrate diets on cardiometabolic risk, insulin resistance, and metabolic syndrome. Cur Opin Endocrino Diabetes Obesity 27(5):301–307
Qin P et al (2020) Sugar and artificially sweetened beverages and risk of obesity, type 2 diabetes mellitus, hypertension, and all-cause mortality: a dose-response meta-analysis of prospective cohort studies. Eur J Epidemiol 35(7):655–671
Paglia L (2019) The sweet danger of added sugars. Eur J Paediatr Dent 20(2):89–89
Hu FB, Malik VS (2010) Sugar-sweetened beverages and risk of obesity and type 2 diabetes: epidemiologic evidence. Physiol Behav 100(1):47–54
Tsilas CS, et al. (2017) “Relation of total sugars, fructose and sucrose with incident type 2 diabetes: a systematic review and meta-analysis of prospective cohort studies. CMAJ: Can Med Assoc J 189,( 20):E711–E720
Behrouz V, Dastkhosh A, Sohrab G (2020) Overview of dietary supplements on patients with type 2 diabetes. Diabetes Meta synd 14(4):325–334
Pittas AG, Jorde R, Kawahara T, Dawson-Hughes B (2020) “Vitamin D Supplementation for Prevention of Type 2 Diabetes Mellitus: To D or Not to D? J Clin Endocrinol Metab 105(12)
Patterson ME, Yee JK, Wahjudi P, Mao CS, Lee WNP (2018) Acute metabolic responses to high fructose corn syrup ingestion in adolescents with overweight/obesity and diabetes. J Nutr Intermediary Metab 14:1–7
Zelber-Sagi S, Salomone F, Mlynarsky L (2017) The Mediterranean dietary pattern as the diet of choice for non-alcoholic fatty liver disease: evidence and plausible mechanisms. Liver Int 37(7):936–949 (Blackwell Publishing Ltd)
Razavi Zade M, Telkabadi MH, Bahmani F, Salehi B, Farshbaf S, Asemi Z (2016) The effects of DASH diet on weight loss and metabolic status in adults with non-alcoholic fatty liver disease: a randomized clinical trial. Liver Int 36(4):563–571
Riazi K, Raman M, Taylor L, Swain MG, Shaheen AA (2019) “Dietary patterns and components in nonalcoholic fatty liver disease (NAFLD): what key messages can health care providers offer? Nutrients 11(12)
George ES et al (2018) Practical dietary recommendations for the prevention andmanagement of nonalcoholic fatty liver disease in adults. Adv Nutr 9(1):30–40 (Oxford University Press)
Hayat U, Siddiqui AA, Okut H, Afroz S, Tasleem S, Haris A (2021) The effect of coffee consumption on the non-alcoholic fatty liver disease and liver fibrosis: a meta-analysis of 11 epidemiological studies. Ann Hepatol 20
Yesil A, Yilmaz Y (2013) Review article: coffee consumption, the metabolic syndrome and non-alcoholic fatty liver disease. Aliment Pharmacol Ther 38(9):1038–1044
Wijarnpreecha K, Thongprayoon C, Ungprasert P (2017) Coffee consumption and risk of nonalcoholic fatty liver disease: a systematic review and meta-analysis. Eur J Gastroenterol Hepatol 29(2):e8–e12
Zelber-Sagi S et al (2018) High red and processed meat consumption is associated with non-alcoholic fatty liver disease and insulin resistance. J Hepatol 68(6):1239–1246
Mirmiran P, Amirhamidi Z, Ejtahed HS, Bahadoran Z, Azizi F (2017) Relationship between diet and non-alcoholic fatty liver disease: a review article. Iran J Public Health 46(8):1007–1017 (Iranian Journal of Public Health)
Jensen T et al (2018) Fructose and sugar: a major mediator of non-alcoholic fatty liver disease. J Hepatol 68(5):1063–1075 (Elsevier B.V.)
Mundi MS, Velapati S, Patel J, Kellogg TA, Abu Dayyeh BK, Hurt RT (2020) Evolution of NAFLD and Its Management. Nutr Clin Pract 35(1):72–84 (John Wiley and Sons Inc.)
Hernández EA et al (2017) Acute dietary fat intake initiates alterations in energy metabolism and insulin resistance. J Clin Investig 127(2):695–708
Hodson L, Rosqvist F, Parry SA (2020) The influence of dietary fatty acids on liver fat content and metabolism. Proc Nutr Soc 79(1):30–41
de Oca APM, Julián MT, Ramos A, Puig-Domingo M, Alonso N (2020) Microbiota, fiber, and NAFLD: is there any connection? Nutrients 12(10):1–9
Krawczyk M, et al. (2018) Gut Permeability Might be Improved by Dietary Fiber in Individuals with Nonalcoholic Fatty Liver Disease (NAFLD) Undergoing Weight Reduction. Nutrients 10(11)
Chiu S, Mulligan K, Schwarz JM (2018) Dietary carbohydrates and fatty liver disease: de novo lipogenesis. Curr Opin Clin Nutr Metab Care 21(4):277–282
Jensen T et al (2018) Fructose and sugar: a major mediator of non-alcoholic fatty liver disease. J Hepatol 68(5):1063–1075
Softic S, Cohen DE, Kahn CR (2016) Role of Dietary Fructose and Hepatic De Novo Lipogenesis in Fatty Liver Disease. Dig Dis Sci 61(5):1282–1293
Kakleas K, Christodouli F, Karavanaki K (2020) Nonalcoholic fatty liver disease, insulin resistance, and sweeteners: a literature review. Expert Rev Endocrinol Metab 15(2):83–93
Perumpail B et al (2018) Potential Therapeutic Benefits of Herbs and Supplements in Patients with NAFLD. Diseases (Basel, Switzerland) 6(3):80
Kilchoer B, Vils A, Minder B, Muka T, Glisic M, Bally L (2020) Efficacy of Dietary Supplements to Reduce Liver Fat. Nutrients 12(8):1–16
Hamida RS, Shami A, Ali MA, Almohawes ZN, Mohammed AE, Bin-Meferij MM (2021) Kefir: a protective dietary supplementation against viral infection. Biomedicine and Pharmacotherapy 133:110974 (Elsevier Masson s.r.l.)
Tyagi SC, Singh M (2021) Multi-organ damage by covid-19: congestive (cardio-pulmonary) heart failure, and blood-heart barrier leakage. Mol Cell Biochem 476(4):1891–1895
Thota SM, Balan V, Sivaramakrishnan V (2020) Natural products as home-based prophylactic and symptom management agents in the setting of COVID-19. Phytother Res 34(12):3148–3167 John Wiley and Sons Ltd
Pieroni A, et al. (2020) Taming the pandemic? The importance of homemade plant-based foods and beverages as community responses to COVID-19. J Ethnobiol Ethnomed 16(1) BioMed Central Ltd
Somasundaram R, Choraria A, Antonysamy M (2020) An approach towards development of monoclonal IgY antibodies against SARS CoV-2 spike protein (S) using phage display method: a review. Int Immunopharmacol 85:106654
Wei S et al (2021) Chicken Egg Yolk Antibodies (IgYs) block the binding of multiple SARS-CoV-2 spike protein variants to human ACE2. Int Immunopharmacol 90:107172
Pérez de la Lastra JM, Baca-González V, Asensio-Calavia P, González-Acosta S, Morales-Delanuez A (2020) Can immunization of hens provide oral-based therapeutics against covid-19? Vaccines 8(3):486
Lu Y, et al. (2020) Generation of Chicken IgY against SARS-COV-2 Spike Protein and Epitope Mapping. J Immunol Res
Khalil M, Salih M, Mustafa A (2020) Broad beans (Vicia faba) and the potential to protect from COVID-19 coronavirus infection. Sudanese J Paediatr 20(1):10–12
Al-Sanea MM, et al. (2021) Strawberry and Ginger Silver Nanoparticles as Potential Inhibitors for SARS-CoV-2 Assisted by In Silico Modeling and Metabolic Profiling. Antibiotics (Basel, Switzerland), 10(7)
Singh A, Mishra A (2021) Leucoefdin a potential inhibitor against SARS CoV-2 M pro. J Biomol Struct Dyn 39(12):4427–4432
Hossain KS, et al. Prospects of honey in fighting against COVID-19: pharmacological insights and therapeutic promises. Heliyon 6(12)
Rondanelli M et al (2021) A food pyramid, based on a review of the emerging literature, for subjects with inflammatory bowel disease. Endocrinol Diabetes Nutr 68(1):17–46
Maconi G, Ardizzone S, Cucino C, Bezzio C, Russo AG, Porro GB (2010) Pre-illness changes in dietary habits and diet as a risk factor for inflammatory bowel disease: a case-control study. World J Gastroenterol 16(34):4297–4304
Galanakis CM (2020) The Food Systems in the Era of the Coronavirus (COVID-19) Pandemic Crisis. Foods 9:523
Emmanuel, Lazega Stanley, Wasserman Katherine, Faust (1995) Social Network Analysis: Methods and Applications. Revue Française de Sociologie 36(4) 781-10.2307/3322457
Wen, Zhang Yanlin, Chen Feng, Liu Fei, Luo Gang, Tian Xiaohong, Li (2017) Predicting potential drug-drug interactions by integrating chemical biological phenotypic and network data. BMC Bioinformatics 18(1) 10.1186/s12859-016-1415-9
Pujari, M., & Kanawati, R. (2012, April). Supervised rank aggregation approach for link prediction in complex networks. In Proceedings of the 21st international conference on world wide web 1189-1196.
Wang, D., Pedreschi, D., Song, C., Giannotti, F., & Barabasi, A. L. (2011, August). Human mobility, social ties, and link prediction. In Proceedings of the 17th ACM SIGKDD international conference on Knowledge discovery and data mining (pp. 1100-1108).
S., Ghasemi A., Zarei Improving link prediction in social networks using local and global features: a clustering-based approach. Progress in Artificial Intelligence 10.1007/s13748-021-00261-3
Needham, M., & Hodler, A. E. (2019). Graph algorithms: practical examples in Apache Spark and Neo4j. O'Reilly Media.
Wasserman, S., & Faust, K. (1994). Social network analysis: Methods and applications.
Paolo, Tessari Anna, Lante (2017) A Multifunctional Bread Rich in Beta Glucans and Low in Starch Improves Metabolic Control in Type 2 Diabetes: A Controlled Trial. Nutrients 9(3) 297-10.3390/nu9030297
Huimin, Zhao Aihua, Yang Lina, Mao Yaning, Quan Jiajia, Cui Yongye, Sun (2020) Association Between Dietary Fiber Intake and Non-alcoholic Fatty Liver Disease in Adults. Frontiers in Nutrition 710.3389/fnut.2020.593735
Mohammad A. I., Al-Hatamleh Ma’mon M., Hatmal Kamran, Sattar Suhana, Ahmad Mohd Zulkifli, Mustafa Marcelo De Carvalho, Bittencourt Rohimah, Mohamud (2020) Antiviral and Immunomodulatory Effects of Phytochemicals from Honey against COVID-19: Potential Mechanisms of Action and Future Directions. Molecules 25(21) 5017-10.3390/molecules25215017
Esposito K, Maiorino MI, Bellastella G, Chiodini P, Panagiotakos D, Giugliano D (2015) A journey into a Mediterranean diet and type 2 diabetes: a systematic review with meta-analyses. BMJ Open 5(8) BMJ Publishing GroupEsposito K, Maiorino MI, Bellastella G, Chiodini P, Panagiotakos D, Giugliano D (2015) A journey into a Mediterranean diet and type 2 diabetes
Rashmeet Toor and Inderveer Chana (2022) DIDACE: literature mining and exploration of disease-diet associations. J Inf Sci Eng 38(1)
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
Conflict of interest
The authors declare no competing interests.
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
About this article

Cite this article
Toor, R., Chana, I. Exploring diet associations with Covid-19 and other diseases: a Network Analysis–based approach. Med Biol Eng Comput 60, 991–1013 (2022). https://doi.org/10.1007/s11517-022-02505-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11517-022-02505-3