
Abstract
The strength reduction method is often used to predict the stability of soil slopes with complex soil properties and failure mechanisms. However, it requires a considerable computational effort. In this paper, we make use of a convolutional neural network to reduce the computational cost. The factor of safety of 600 slopes with different inclination and soil properties is first calculated with the strength reduction method. A convolutional neural network is then trained and validated. We demonstrate the performance of our approach and show how to augment the dataset to further enhance its capability and prevent overfitting.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Landslides are among the most pervasive hazards in the world [16, 38, 66]. It is estimated that some 130,000 persons have lost their lives since 1900 because of landslides with economic losses amounting to over USD 50 billion [24, 47].
Slope stability analysis is pivotal to assessing and mitigating the landslide risk. Two main approaches are used by geotechnical engineers to evaluate the stability of slopes, namely the limit equilibrium method (LEM) and the strength reduction method (SRM).
In limit equilibrium methods, the equilibrium of a sliding soil mass is considered. The most popular limit equilibrium technique is the method of slices, in which the soil mass is discretised into vertical slices. Several versions of the method exist based on assumptions regarding the forces between the slices [4,18,32,46,65]. Regardless of the method, a slip surface must be assumed. Non-circular slip surfaces are preferable and recommended by geotechnical standards, especially when dealing with layered soils [17]. The critical slip surface is often determined [20, 51] with various optimisation methods [14,15,16,17,18,19,20,21,,22,44,30,60, 57,63,67, 71]. Although LEMs are widely used thanks to their low computational effort, their main drawback is the validity of the assumed force distributions. For complex scenarios, the strength reduction method is preferred [39].
The SRM is an increasingly popular numerical method to evaluate the factor of safety in geomechanics [24,25,, 23, 68] and is implemented both in the finite element (FEM) and finite-difference method (FDM). Its working principle is to progressively reduce the shear strength of the soil \(\tau _{\rm f}\) as in Equation 1, where \(c'\) and \(\varphi '\) are the cohesion and friction angle, respectively, \(\sigma '\) is the effective normal stress acting on the slip surface, and \({\text{FS}}\) is the factor of safety. FS is increased until failure, defined by unacceptably large deformations or divergence of the calculation.
Extensively used in the context of Mohr–Coulomb materials [27,28,29,, 45, 6978], the SRM can be generalised to other nonlinear failure criteria [31,32,, 59, 19]. It enjoys a substantial advantage over the LEM in the generation of realistic stress distributions since it can accommodate complex stress–strain relationships and avoids arbitrary assumptions regarding inter-slice forces [39]. Furthermore, the SRM does not require assumptions on the location and shape of the failure surface, but automatically returns the failure mechanism as an outcome of the calculation. Moreover, unlike the LEM, the SRM can also predict deformations at failure [31]. Finally, the SRM can accommodate both the peak and residual soil strength. However, the computational cost is relatively high compared with LEM.
In this study, we make use of deep learning to reduce the computational effort. As a subset of artificial intelligence (AI), deep learning has been successfully applied in geomechanics and geotechnical engineering, e.g. soil classification, design of deep foundations and tunnels and soil dynamics [35,36,37,38,39,40,41,, 34,58, 64, 70, 72, 76, 74]. Although machine learning has been widely employed in the analysis of slope stability [43,44,45,46,47,48,, 26, 50, 54,55,56, 77], very few attempts [2, 27] have been made on the application of the convolutional neural network (CNN).
CNN is a deep, feed-forward artificial neural network, inspired by the biological visual cortex that has proven to be successful in many different real-life applications, such as image classification, object detection, segmentation, face recognition and self-driving cars. Azmoon et al. [2] framed the slope stability problem as a classification problem by defining eight intervals of the factors of safety computed with the Bishop’s simplified method of slices [4]. By training their CNN on some 95,000 slopes with a constant inclination and homogeneous soil properties, the authors achieved an accuracy of 79% on the test set. He et al. [28] used a CNN to predict the factor of safety of the SRM for two homogeneous and two stratified slopes with variable soil properties of given statistical distribution.
In this study, 600 layered slopes are generated with random profiles, inclined soil layers with random density, cohesion and friction angle and their factor of safety is calculated with the SRM. A CNN is trained on this dataset to predict the factor of safety. Compared to the previous machine learning approaches to the prediction of slope stability, our training dataset considers a wide range of slope profiles, soil layers and properties within a relatively small dataset. Our CNN is capable of predicting the factor of safety with high accuracy, which is also confirmed by cross-checking the results with typical verification examples from the literature [68, 52,53,54,,21, 42, 73].
The novelty of this work lies in the use of CNN to return the factor of safety of slopes of any geometry and stratification, hence bypassing analytical (LEM) or numerical (SRM) methods. Since the factor of safety is instantly predicted by the CNN, the importance of this research lies in the computational gain. As previously mentioned, although both the CNN and SRM are two familiar methods, only few authors succeeded in combining them.
This paper is organised as follows: the data acquisition and augmentation, and the architecture of the CNN are described in Sect. 2. The results of the machine learning prediction are presented in Sect. 3. Finally, the results are discussed (Sect. 4) and conclusions are drawn in Sect. 5.
2 Methods
The general-purpose programming language Python version 3.8.12 [53] is used in this study to generate the random layered slopes and implement the CNN. FLAC3D version 4.00 [31], a three-dimensional explicit Lagrangian finite-difference computer program for engineering mechanics computation, is used to calculate the factor of safety with the SRM.
2.1 Data generation
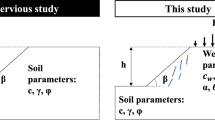
Two-dimensional slopes with the dimension of 100\(\times\)100 m are considered. The left and right boundaries are assigned the coordinates \(x = -20\) m and x = 80 m, respectively (Fig. 1). The bottom and upper boundaries are located at \(y = -\)20 m and y = 80 m. The slope width B is variable between 10 and 60 m and the origin of the coordinates is at the slope toe. The slope angle is randomly chosen every 10 m within the range \(\beta _{\rm s,i} = [5^\circ , 45^\circ ]\). Hence, the slope height is comprised between \(B\tan 5^\circ\) and \(B\tan 45^\circ\), the maximum height being thus \(H = 60\) m. Two plane boundaries between the soil layers are defined by a point with a random x-coordinate, \(y = 0\) and random inclination in the range \(\beta _{\rm p,i} = [-5^\circ , 45^\circ ]\). After each boundary is generated, the whole area below is assigned the soil properties as follows, so that three soil layers are generated. To simulate a broad range of the soil properties, encompassing both drained and undrained conditions, the resulting soil layers are assigned random values of density, cohesion and friction angle between 1100 and 2400 kg/m\(^3\), 0 and 300 kPa, 0 and 45\(^\circ\), respectively. A pseudorandom number generator with constant seed is used to ensure the replicability of the results. The scatter plot of the soil properties is shown in Fig. 2. This figure presents the various combinations of properties of all the soil layers generated. Since the soil properties are randomly chosen, they are approximately uniformly distributed. A uniform distribution of the input features ensures that the CNN is equally trained on the whole spectrum of soil properties. The soil properties are assigned to the soil above a random plane boundary. Since two planes are defined, a maximum of three layers are present. However, if the second plane is completely below the first one, only two soil layers are present. The three soil properties \(\rho\), \(c'\) and \(\varphi '\) are extracted from every element of a 1\(\times\)1 m raster and copied into three 100\(\times\)100 tensors to serve as input for the CNN. These tensors represent the channels \(\rho\), \(c'\) and \(\varphi '\) and are depicted with the heatmaps of Fig. 3. To improve numerical stability [5], the property values are scaled according to Equations 2, where \(\rho _{\rm max}\) = 2400 kg/m\(^3\), \(c'_{\rm max}\) = 300 kPa and \(\varphi '_{\rm max}\) = 45\(^\circ\) are the maximum values of the soil properties considered.
FLAC3D input files corresponding to the 3\(\times\)100\(\times\)100 CNN input tensors are generated to calculate the factor of safety with the SRM (Fig. 4). Brick-shaped elements (brick) are used for the bottom and right side of the FLAC3D model and uniform wedge-shaped elements (uwedge) are employed for the slope. The dimension of the mesh elements below the slope is 1\(\times\)1 m. The element width in the slope toe is 1 m and the height is \(\tan (\beta _{\rm {s,i}})\). The number of elements varies between 2080 and 5185, depending on the geometry of the slopes. The displacements are fixed in the horizontal direction at the vertical boundaries, in the direction perpendicular to the analysis plane and in the vertical direction at the bottom. An elastic-perfectly plastic model with Mohr–Coulomb failure criterion is selected with the associated flow rule. The bulk and shear moduli are K = 50 MPa and G = 19 MPa, respectively, and correspond to a Young’s modulus E = 50.8 MPa and Poisson’s ratio \(\nu\) = 0.34. Note that the deformation parameters have a negligible effect on the factor of safety calculated with the SRM [25].
The computed factors of safety of the generated slopes are up to 25. To ensure that the analysis be focused on more practical cases, 34 slopes are neglected for which the factor of safety returned is larger than 10. \(600 - 34 = 566\) slopes are retained.
So far we have elucidated both the input (the tensors with shape 3\(\times\)100\(\times\)100) and output (the vector of the factors of safety calculated with the SRM) of the CNN. Its implementation is described in the next section.

Visual description of the procedure for the generation of the slopes with random soil profile and layers

Scatter plot of the dataset of soil properties considered for the layers of the random layered slopes

The three channels of the CNN input tensors for the prediction of the factor of safety corresponding to the FLAC3D model

Example FLAC3D mesh grid for the computation of the factor of safety with the SRM
2.2 Convolutional neural network
Convolutional neural networks are neural networks commonly used for interpreting image data. With the simple architecture of Fig. 5, the “colour” values of the three “image” channels (\(\rho\), \(c'\) and \(\varphi '\)) of Fig. 3 flow through three convolution and subsampling layers, before being flattened and transferred to a fully connected layer that returns the factor of safety. In mathematical terms, convolution layers yield dot products B between the weights of the kernels K (also called “filters”) and subsets of the input tensors A according to Equation 3 where \(n_K\) is the size of the kernels.
The chosen CNN has 32, 64 and 128 3\(\times\)3 kernels in the first, second and third layer, respectively (Fig. 5). The kernels K slide one cell to the right until the right end of the tensors A is reached, then down and right again. Hence, the dimensions of the tensors shrink by two at each convolution. The output of the convolution layers is delivered to the activation functions to impart nonlinearity to the network.
We select the leaky rectified linear unit (leaky ReLU) activation function [9], defined by Equation 4, with \(z_j = w_{ij}\cdot x_i + b_j\), where \(w_{ij}\) are the weights and \(b_j\) the bias terms of the network.
The leaky ReLU is derived from the rectified linear unit activation function (ReLU) of equation \(a_j = f(z_j) = \max (0,z_j)\), a common choice for traditional neural networks. ReLU units are affected by the problem of “dying ReLUs”, arising when the activation function constantly returns \(a_j = 0\) [43]. This problem is solved by leaky ReLUs by considering the slope \(\alpha\) for \(z_j \ge 0\) before passing the output to the subsampling layers (Equation 4). The value \(\alpha = 0.1\) is chosen in this study (Fig. 6). The activation function delivers the output to the subsampling layer.
Subsampling helps reduce the dimensions of the tensors to avoid overfitting, which happens when the model fits the training set so well, that it negatively impacts the performance on the test set. The subsampling technique named “max pooling” is considered in this study. To this end, the highest value in a region of the tensor B is selected to return C according to Equation 5 where \(n_{\rm C}\) is the size of the subsampling tensor.
Finally, the output of the last pooling layer is flattened, i.e. the cells of the tensors are inserted one by one into the vector \(d_k = C_{ij}\) that is fed to the fully connected layer to predict the factor of safety.
Notwithstanding the relative simplicity of this CNN architecture, it features already 334,433 training parameters, i.e. the weights \(w_{ij}\) and biases \(b_j\). These parameters are optimised by minimising the mean squared error \({\rm MSE}\) (backpropagation), defined in Equation 6, where \(y_i\) and \({\hat{y}}_i\) are the observed and predicted factors of safety, respectively.
The \({\rm MSE}\) is minimised using the method for stochastic optimisation Adam [37], with an initial step size (“learning rate”) of 0.001 and the parameters \(\beta _1\) and \(\beta _1\) controlling the decay rate of 0.9 and 0.999, respectively.
Ninety per cent of the data is used to train the CNN and 10% is assigned to validation. This splitting task is performed by the function train_test_split of the Scikit-learn library [48]. Early stopping, an inexpensive way to avoid strong overfitting [3], is implemented by monitoring the CNN performance to ensure that the \({\rm MSE}\) of the validation set decreases of at least 0.001 every 20 steps (patience) and by interrupting the iterations as soon as this criterion is no longer fulfilled.
Since the data generation is rather time-consuming, synthetic data augmentation is employed to increase data availability and, at the same time, improve model performance [49].

Architecture of the CNN used in this study. Image size change and hyperparameters (F: Filter size; N: Number of filters; P: Padding; S: Stride)

Comparison between the ReLU and leaky ReLU activation functions of artificial neural networks
2.3 Synthetic data augmentation
In the synthetic data augmentation, new training data are generated by performing image transformations, such as reflection, cropping, translation and deformation. The data augmentation is performed after the train/test split to avoid data leakage. In data mining, leakage is the introduction of information about the target that should not be available for mining [35].
Considering that the transformed slopes must yield the same factor of safety of the original ones, two of the above techniques are relevant to our study, namely reflection and translation (Fig. 7). The training dataset size is doubled by simply reflecting the input data X, since the mirrored slopes will yield the same factor of safety of the original slopes. The dataset size is considerably increased by translating upwards the slopes that display constant soil properties at the bottom. Since the maximum height of the slopes is \(H_{\rm max}\) = 60 m and the model top is located at y = 80 m, all slopes can be translated by at least 20 m. The slopes whose crest is below \(y = H_{\rm max}\) can be translated further. To avoid memory issues, the slopes are translated upwards in 2 m steps. Hence, \((100-H_{\rm max})/2 = 20/2 = 10\) translations are considered.
By computing the factor of safety with these input data, the density histogram of the factor of safety shown in Fig. 8 is obtained. Its density histogram is shifted to the left with most data in the interval [0, 5].
Once the data is preprocessed as elucidated in this section, the CNN can be trained as shown in the following.

Synthetic data augmentation transformations applied to the slope images

Density histograms of the factors of safety of the training and test sets calculated with the SRM in FLAC3D for the random layered slopes
2.4 CNN training and validation
The parameters of the CNN are updated after a mini-batch of training data with a given size has passed through the network. This mini-batch size does not impact the CNN performance, but only its training time [3]. Small mini-batch sizes yield faster computations but require more iterations. There is no general agreement whether a larger mini-batch size should be preferred [66,67,, 10, 61] or vice versa [69,70,, 33, 36]. However, since a larger size determines a faster iteration, we select the largest possible mini-batch allowed by the random access memory of the workstation, namely 4096. The CNN hyperparameters are summarised in Table 1.
Once the training of the CNN is completed, the performance metrics \(R^2\), root mean square error (RMSE) and mean absolute percentage error (MAPE) [75] are computed for the training and validation sets according to Equations 7–9 where \({\bar{y}}\) is the mean factor of safety computed with the SRM and n is the dataset size.
The algorithm workflow is summarised in Fig. 9.
After the calculated factors of safety are predicted with the CNN, the network is further tested on the slope verification examples [68, 52,53,54,, 21, 42, 73, 62] depicted in Fig. 10 and with soil properties according to Table 2.
The results are shown in the next section.

Workflow of the proposed algorithm: input files’ generation, factor of safety computation with the SRM in FLAC3D, CNN training and prediction

Slope stability software verification examples considered in this study. Coordinates and numbering of the soil layers
3 Results
A workstation equipped with an Intel Core i7-4810MQ CPU at 2.80 GHz with 4 cores and 8 logical processors is used for the calculations. The individual factor of safety calculations with the SRM implemented in FLAC3D last on average 30 minutes. Hence, 600 factor of safety calculations are completed in about 12 to 13 days. The training and validation of the CNN require only a matter of a few minutes. Figure 11 shows the decrease of the \({\rm MSE}\) over time for the training and validation of the CNN. The training stops after 70 epochs due to the early stopping callback defined in Sect. 2.2. As expected, the \({\rm MSE}\) on the training set decreases steadily, whereas the \({\rm MSE}\) on the test set decreases and then plateaus. The factors of safety predicted with the CNN against the factors of safety computed with the SRM are shown in Fig. 12 for the training and test sets, where the bisector represents a perfect prediction and the dashed lines ±30% deviations. The prediction is very accurate both on the low and high values of the factor of safety as manifested by the coefficients of determination \(R^2\) of 0.972 and 0.935 on the training and test sets, respectively. Appreciable deviations occur on very few samples. Notice that, due to the data augmentation, certain values of the factor of safety appear more than once in Fig. 12. For instance, if a slope is mirrored or shifted upwards, the input file varies, whereas the factor of safety stays the same. As shown in Table 3, the positive effect of the synthetic data augmentation on the predictive performance is negligible on the training set, but considerable on the test set. The reflection doubles the size of the training set from \(0.9\cdot 566 = 509\) to 1018 and improves the performance on the test set from \(R^2 = 0.929\) to 0.917. The upward translation of the input slopes increases the size of the dataset approximately by a factor of seven from 1018 to 7158 and the coefficient of determination to \(R^2 = 0.935\). Overall, the CNN prediction of the factor of safety matches the SRM computation very well.
In Fig. 13, the factors of safety predicted by the CNN are compared to those computed with the SRM as provided by the verification manuals of the software RS2 [52] and Sofistik [62]. It is evident that the predicted factors of safety approximate the SRM computations very accurately.

Minimisation of the MSE with the CNN for the training and test set after data augmentation

CNN predictions compared to the FLAC3D computation of the factor of safety with the SRM

Computed and predicted factors of safety of the verification examples from the literature
4 Discussion
We have generated 600 randomly inclined and layered slopes and computed their factors of safety with the SRM in FLAC3D. The information on the geometry and the three soil properties \(\rho\), \(c'\) and \(\varphi '\) of the slopes is filled into 3\(\times\)100\(\times\)100 tensors with which a CNN is trained. The CNN has been trained to predict the factor of safety of the slope with 90% of the data and validated on the remaining 10%. To increase the number of available data points whilst enhancing performance, the input tensors have been reflected and translated upwards. Furthermore, the network has been tested on customary slope stability verification examples.
The results are very accurate and they could be further improved by increasing the original dataset beyond 600 as well as by considering more than two nonlinear boundaries between the soil layers. Some additional features such as pore water pressure, external loads and structures could also be considered. Rather than retraining the CNN from scratch, these features can be included with the transfer learning approach [6, 7], a currently popular technique in deep learning to reuse pre-trained models on new problems. Note, however, that, although the CNN was trained with plane boundaries within the soil layers, it can already predict the factor of safety of more complex boundaries, such as those of the second verification example [21]. A further limitation is the two-dimensional slope analysis that could be circumvented by generating three-dimensional training data and by adapting the model to accommodate three-dimensional convolutions. Finally, more advanced CNN architectures, such as LeNet [41] or AlexNet [40] could be implemented.
5 Conclusions
Despite the aforementioned limitations, our convolutional neural network is considerably accurate both on the training and test set (\(R^2 = 0.935\)) and performs very well on the verification examples. Our method has the potential to assist the slope stability appraisals of the traditional methods. Since the method is trained on the results obtained by the strength reduction, its predictions are more accurate than the limit equilibrium method. The factor of safety is instantly returned by the proposed CNN and the computational effort of the SRM is thus sidestepped.
Data availability
All data generated or analysed during this study are included alongside this published article within its electronic supplementary material, such as the Python scripts, the input and output data and the CNN model file.
References
Arai K, Tagyo K (1985) Determination of noncircular slip surface giving the minimum factor of safety in slope stability analysis. Soils Found 25(1):43–51. https://doi.org/10.3208/sandf1972.25.43
Azmoon B, Biniyaz A, Sun Y (2021) Image-data-driven slope stability analysis for preventing landslides using deep learning. IEEE Access 9:150623–150636. https://doi.org/10.1109/ACCESS.2021.3123501
Bengio Y (2012) In: Montavon G, Orr GB, Müller K-R (eds) Practical recommendations for gradient-based training of deep architectures, pp 437–478. Springer, Berlin, Heidelberg. https://doi.org/10.1007/978-3-642-35289-8_26
Bishop AW (1955) The use of the slip circle in the stability analysis of slopes. Géotechnique 5(1):7–17. https://doi.org/10.1680/geot.1955.5.1.7
Bishop CM (1995) Neural networks for pattern recognition. Oxford University Press, Oxford
Bozinovski S (2020) Reminder of the first paper on transfer learning in neural networks, 1976. Inform 44(3):291–302. https://doi.org/10.31449/inf.v44i3.2828
Bozinovski S, Fulgosi A (1976) Utjecaj slicnosti likova i transfera ucenja na obucavanje baznog perceptrona B2 The influence of pattern similarity and transfer of learning upon training of a base perceptron B2. In: Proceedings symposia informatica 3-121-5, Bled, Croatia. In Croatian
Cheng YM, Li L, Chi SC, Wei WB (2007) Particle swarm optimization algorithm for the location of the critical non-circular failure surface in two-dimensional slope stability analysis. Comput Geotech 34(2):92–103. https://doi.org/10.1016/j.compgeo.2006.10.012
Chollet F, et al. (2015) Keras. https://github.com/fchollet/keras
Das D, Avancha S, Mudigere D, Vaidyanathan K, Sridharan S, Kalamkar DD, Kaul B, Dubey P (2016) Distributed deep learning using synchronous stochastic gradient descent. CoRR. arXiv:1602.06709. https://doi.org/10.48550/arXiv.1602.06709
Dawson E, You K, Park Y (2000) Strength-reduction stability analysis of rock slopes using the Hoek-Brown failure criterion. Geotech Special Publ 290(102):65–77. https://doi.org/10.1061/40514(290)4
Dawson EM, Roth WH (1999) Slope stability analysis with FLAC. In: Detournay C, Hart R (eds), Proceedings of the international FLAC symposium on numerical modeling in geomechanics, vol 42, pp 3–9. A.A. Balkema, Rotterdam
Dean J, Corrado GS, Monga R, Chen K, Devin M, Le QV, Mao MZ, Ranzato M, Senior A, Tucker P, Yang K, Ng AY (2012) Large scale distributed deep networks. NIPS
Donald IB, Giam SK (1988) Application of the nodal displacement method to slope stability analysis. In: Proceedings of the 5th Australia-New Zealand conference on geomechanics, pp 456–460, A.A. Balkema, Sydney
Ebid AM (2021) 35 years of (AI) in geotechnical engineering: state of the art. Geotech Geolog Eng 39:637–690. https://doi.org/10.1007/s10706-020-01536-7
Emberson R, Kirschbaum D, Stanley T (2020) New global characterisation of landslide exposure. Nat Hazards Earth Sys Sci 20(12):3413–3424. https://doi.org/10.5194/nhess-20-3413-2020
European Committee for Standardization (2004) EN 1997–1: Eurocode 7: Geotechnical design - Part 1: General rules. European Committee for Standardization, Brussels, Belgium
Fellenius W (1936) Calculation of stability of earth dam. In: Proceedings of the Second Congress of Large Dams, vol 4. Washington, U.S.A., pp 445–463
Fu W, Liao Y (2009) Non-linear shear strength reduction technique in slope stability calculation. Comput Geotech 37:288–298. https://doi.org/10.1016/j.compgeo.2009.11.002
GEO-SLOPE International (2017) Stability modeling with geostudio. GEO-SLOPE International Ltd, Calgary, Canada
Giam PSK, Donald IB (1989) Example problems for testing soil slope stability programs, vol 8. Monash University, Melbourne, Australia
Greco VR (1996) Efficient Monte Carlo technique for locating critical slip surface. J Geotech Eng 122(7):517–525. https://doi.org/10.1061/(asce)0733-9410(1996)122:7(517)
Griffiths DV, Lane PA (1999) Slope stability analysis by Finite Elements. Géotechnique 49(3):387–403. https://doi.org/10.1680/geot.1999.49.3.387
Guha-Sapir D, Below R, Hoyois P (2017) The CRED/OFDA international disaster database. Université catholique de Louvain, Louvain, Belgium
Hammah R (2022) Open secret advantages of the shear strength reduction approach in slope stability analysis. https://www.rocscience.com/learning/open-secret-advantages-of-the-shear-strength-reduction-approach-in-slope-stability-analysis Accessed 2022-03-17
He X, Wang F, Li W, Sheng D (2021) Efficient reliability analysis considering uncertainty in random field parameters: Trained neural networks as surrogate models. Comput Geotech 136:104212. https://doi.org/10.1016/j.compgeo.2021.104212
He X, Wang F, Li W, Sheng D (2021) Deep learning for efficient stochastic analysis with spatial variability. Acta Geotech. https://doi.org/10.1007/s11440-021-01335-1
He X, Xu H, Sabetamal H, Sheng D (2020) Machine learning aided stochastic reliability analysis of spatially variable slopes. Comput Geotech 126:103711. https://doi.org/10.1016/j.compgeo.2020.103711
Hoffer E, Hubara I, Soudry D (2017) Train longer, generalize better: closing the generalization gap in large batch training of neural networks. In: Guyon I, Luxburg UV, Bengio S, Wallach H, Fergus R, Vishwanathan S, Garnett R (eds) Advances in neural information processing systems, vol 30. Curran Associates?. https://proceedings.neurips.cc/paper/2017/file/a5e0ff62be0b08456fc7f1e88812af3d-Paper.pdf
Husein Malkawi AI, Hassan WF, Sarma SK (2001) An efficient search method for finding the critical circular slip surface using the Monte Carlo technique. Canadian Geotech J 38(5):1081–1089. https://doi.org/10.1139/cgj-38-5-1081
Itasca Consulting Group: FLAC3D (Fast lagrangian analysis of continua). Itasca consulting group, Minneapolis
Janbu N (1954) Application of composite slip surfaces for stability analysis. In: Proceedings of the european conference on the stability of earth slopes, vol 3. Stockholm, Sweden, pp 39–43
Jastrzębski S, Kenton Z, Arpit D, Ballas N, Fischer A, Bengio Y, Storkey A (2017) Three factors influencing minima in SGD. arXiv. https://doi.org/10.48550/ARXIV.1711.04623. https://arxiv.org/abs/1711.04623
Jong SC, Ong DEL, Oh E (2021) State-of-the-art review of geotechnical-driven artificial intelligence techniques in underground soil-structure interaction. Tunn Undergr Space Technol 113:103946. https://doi.org/10.1016/j.tust.2021.103946
Kaufman S, Rosset S, Perlich C (2011) Leakage in data mining Formulation detection and avoidance. ACM Trans Knowl Discovery Data (TKDD) 6:556–563. https://doi.org/10.1145/2020408.2020496
Keskar N, Nocedal J, Tang P, Mudigere D, Smelyanskiy M (2017) On large-batch training for deep learning: generalization gap and sharp minima.5th international conference on learning representations, ICLR 2017; Conference date: 24-04-2017 through 26-04-2017
Kingma DP, Ba JL (2015) Adam: a method for stochastic optimization. In: In: Proceedings of the international conference on learning representations, San Diego, USA
Kirschbaum D, Stanley T (2018) Satellite-based assessment of rainfall-triggered landslide hazard for situational awareness. Earths Future 6(3):505–523. https://doi.org/10.1002/2017EF000715
Krahn J (2003) The 2001 r.m. hardy lecture: the limits of limit equilibrium analyses. Canadian Geotech J 40(3):643–660. https://doi.org/10.1139/t03-024
Krizhevsky A, Sutskever I, Hinton GE (2017) Imagenet classification with deep convolutional neural networks. Commun ACM 60(6):84–90. https://doi.org/10.1145/3065386
Lecun Y, Bottou L, Bengio Y, Haffner P (1998) Gradient-based learning applied to document recognition. Proc IEEE 86(11):2278–2324. https://doi.org/10.1109/5.726791
Low B (1989) Stability analysis of embankments on soft ground. J Geotech Eng 115(2):211–227. https://doi.org/10.1061/(ASCE)0733-9410(1989)115:2(211)
Lu L (2020) Dying ReLU and initialization: theory and numerical examples. Commun Comput Phys 28(5):1671–1706. https://doi.org/10.4208/cicp.oa-2020-0165
Mafi R, Javankhoshdel S, Cami B, Chenari RJ, Gandomi AH (2021) Surface altering optimisation in slope stability analysis with non-circular failure for random limit equilibrium method. Georisk 15(4):260–286. https://doi.org/10.1080/17499518.2020.1771739
Matsui T, San KC (1992) Finite element slope stability analysis by shear strength reduction technique. Soils Found 32(1):59–70. https://doi.org/10.3208/sandf1972.32.59
Morgenstern NR, Price VE (1965) The analysis of the stability of general slip surfaces. Géotechnique 15(1):79–93. https://doi.org/10.1680/geot.1965.15.1.79
Nadim F (2017) Landslide hazard and risk assessment. UNISDR, Geneva, Switzerland
Pedregosa F, Varoquaux G, Gramfort A, Michel V, Thirion B, Grisel O, Blondel M, Prettenhofer P, Weiss R, Dubourg V, Vanderplas J, Passos A, Cournapeau D, Brucher M, Perrot M, Duchesnay É (2011) Scikit-learn: machine learning in python. J Mach Learn Res 12(85):2825–2830
Perez L, Wang J (2017) The effectiveness of data augmentation in image classification using deep learning. CoRR. arXiv:1712.04621. https://doi.org/10.48550/arXiv.1712.04621
Qi C, Tangb X (2018) Slope stability prediction using integrated metaheuristic and machine learning approaches: a comparative study. Comput Ind Eng 118:112–122. https://doi.org/10.1016/j.cie.2018.02.028
Rocscience: Slide2 User Guide. https://www.rocscience.com/help/slide2/documentation Accessed 2021-11-29
Rocscience: RS2, 2D Finite element program for stress analysis and support design around excavations in soil and rock: slope stability verification manual, part I. https://www.rocscience.com/assets/verification-and-theory/RS2/RS2-XFEM-Verification-Manual.pdf Accessed 2022-03-23
Van Rossum G, Drake FL (2009) Python 3 reference manual. CreateSpace, Scotts Valley, CA
Sakellariou MG, Ferentinou MD (2005) A study of slope stability prediction using neural networks. Geotech Geolog Eng 23:419–445. https://doi.org/10.1007/s10706-004-8680-5
Samui P (2008) Slope stability analysis: a support vector machine approach. Environ Geol 56(2):255–267. https://doi.org/10.1007/s00254-007-1161-4
Samui P, Kothari DP (2011) Utilization of a least square support vector machine (LSSVM) for slope stability analysis. Sci Iranica 18(1):53–58. https://doi.org/10.1016/j.scient.2011.03.007
Sharma S (2008) XSTABL: An integrated slope stability analysis program for personal computers: reference manual. Interactive Software Designs Inc, Cleveland, U.S.A
Shreyas SK, Dey A (2019) Application of soft computing techniques in tunnelling and underground excavations: state of the art and future prospects. Innov Infrastruct Solut. https://doi.org/10.1007/s41062-019-0234-z
Shukha R, Baker R (2003) Mesh geometry effects on slope stability calculation by FLAC strength reduction method- linear and non-linear criteria. In: Brummer R, e.a. (ed) Proceedings of the 3rd international FLAC symposium on numerical modeling in geomechanics. A. A. Balkema, Lisse
Siegel RA, Kovacs WD, Lovell CW (1981) Random surface generation in stability analysis. J Geotech Geoenviron Eng 107(GT7):996–1002
Smith S, Kindermans P-j, Ying C, Le QV (2018) Don’t decay the learning rate, increase the batch size. https://openreview.net/pdf?id=B1Yy1BxCZ
Sofistik AG: Verification manual: benchmark example No. 38, Calculation of slope stability by Phi-C reduction. https://www.sofistik.de/documentation/2018/en/verification/_static/verification/pdf/be38.pdf Accessed 2022-04-01
Soranzo E, Guardiani C, Saif A, Wu W (2022) A reinforcement learning approach to the location of the non-circular critical slip surface of slopes. Computers & Geosciences 166:105182. https://doi.org/10.1016/j.cageo.2022.105182
Soranzo E, Guardiani C, Wu W (2022) The application of reinforcement learning to natm tunnel design. Underground Space 7(6):990–1002. https://doi.org/10.1016/j.undsp.2022.01.005
Spencer E (1967) A method of analysis of the stability of embankments assuming parallel inter-slice forces. Géotechnique 17(1):11–26. https://doi.org/10.1680/geot.1967.17.1.11
Stanley T, Kirschbaum DB (2017) A heuristic approach to global landslide susceptibility mapping. Nat Hazards 87:145–164. https://doi.org/10.1007/s11069-017-2757-y
Su X (2009) Global optimization of general failure surfaces in slope analysis by hybrid simulated annealing. Rocscience, Toronto, Canada
Tschuchnigg F, Schweiger HF, Sloan SW, Lyamin AV, Raissakis I (2015) Comparison of finite-element limit analysis and strength reduction techniques. Géotechnique 65(4):249–257. https://doi.org/10.1680/geot.14.P.022
Ugai K, Leshchinsky D (1995) Three-dimensional limit equilibrium and finite element analyses: a comparison of results. Soils Found 35(4):1–7. https://doi.org/10.3208/sandf.35.4_1
Wang X, Lu H, Wei X, Wei G, Behbahani SS, Iseley T (2020) Application of artificial neural network in tunnel engineering: a systematic review. IEEE Access 8:119527–119543. https://doi.org/10.1109/ACCESS.2020.3004995
Wu A (2012) Locating general failure surfaces in slope analysis via Cuckoo Search. Rocscience Inc, Toronto, Canada
Wu C, Hong L, Wang L, Zhang R, Pijush S, Zhang W (2022) Prediction of wall deflection induced by braced excavation in spatially variable soils via convolutional neural network. Gondwana Res. https://doi.org/10.1016/j.gr.2022.06.011
Yamagami T, Ueta Y (1988) Search noncircular slip surfaces by the morgenstern-price method. In: Proceedings of the 6\(^{th}\) international conference of numerical methods in geomechanics, pp 1335–1340
Zhang W, Li H, Li Y, Liu H, Chen Y, Ding X (2021) Application of deep learning algorithms in geotechnical engineering: a short critical review. Artif Intell Rev 54(8):5633–5673
Zhang W, Wu C, Zhong H, Li Y, Wang L (2021) Prediction of undrained shear strength using extreme gradient boosting and random forest based on bayesian optimization. Geosci Front 12(1):469–477. https://doi.org/10.1016/j.gsf.2020.03.007
Zhang W, Zhang R, Wu C, Goh ATC, Lacasse S, Liu Z, Liu H (2020) State-of-the-art review of soft computing applications in underground excavations. Geosci Front 11(4):1095–1106. https://doi.org/10.1016/j.gsf.2019.12.003
Zhou J, Li E, Yang S, Wang M, Shi X, Yao S, Mitri HS (2019) Slope stability prediction for circular mode failure using gradient boosting machine approach based on an updated database of case histories. Saf Sci 118:505–518. https://doi.org/10.1016/j.ssci.2019.05.046
Zienkiewicz OC, Humpheson C, Lewis RW (1975) Associated and non-associated visco-plasticity and plasticity in soil mechanics. Géotechnique 25(4):671–689. https://doi.org/10.1680/geot.1975.25.4.671
Acknowledgements
Financial support for this research is provided by the Otto Pregl Foundation for Geotechnical Fundamental Research.
Funding
Open access funding provided by University of Natural Resources and Life Sciences Vienna (BOKU).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Supplementary Information
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Soranzo, E., Guardiani, C., Chen, Y. et al. Convolutional neural networks prediction of the factor of safety of random layered slopes by the strength reduction method. Acta Geotech. 18, 3391–3402 (2023). https://doi.org/10.1007/s11440-022-01783-3
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11440-022-01783-3