
Abstract
The paper’s main aim is to forecast the carbon dioxide (CO2) emissions in the USA and its related components, analysing the contributions of each of those components to CO2 total volume. The empirical ground is a mix of non-linear tools, combining the artificial neural network (ANN) parametric method with a vector autoregressive (VAR) estimator. ANN includes 1 layer and 20 neurons, forecasting being based on the economic growth and net trade effects doubled by different types of renewable energy consumption. The accuracy of estimations for 14 targeted categories of CO2 emissions is ensured by 4360 observations, with 10 types of inputs over 1984M01–2020M04. ANN seems to offer superior forecasting accuracy compared with the widely used autoregressive methods, such as VAR model, but seems to be weak in capturing the output ‘spike’ forms. The main findings show that, although economic growth and net trade have an important contribution to the targeted outputs, the more prominent ones are wind, solar and total biomass energy consumption. Therefore, the CO2 emissions can be better controlled through non-polluting capacities, in parallel with the use of wind, solar and total biomass energies. The tool excellently predicts the CO2 emissions during pandemic crises being a good instrument in policy decisions. Modest contributions to CO2 prediction seem to have energy consumption generated by waste, hydroelectric power and renewable geothermal systems. This underlines an unclear current status given their collateral effects in environmental damages and high investment costs. The paper contributes to the literature in several ways. It is one of the first works focused on CO2 emissions forecasting in the USA based on a mixed approach by ANN and VAR types, considering an extended pallet of inputs to predict the volume of total CO2 emissions but also its components. As a novelty, the inputs combine both economic and environmental determinants. Not at least, the estimations are performed based on a large span, with monthly frequency.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
Introduction
During the last decades, gas emissions started to occupy high positions in the international policy agenda. Their destructive effects preoccupy not only the policymakers and researchers from all over the world but also many non-governmental organisations, companies or individuals. Therefore, the research interest in the field rapidly grew up, being focused on both theoretical and empirical explorations.
In this context, the USA is of particular interest facing high gas emissions levels over the last decades. Currently, this country is second-ranked globally after China in terms of gas emissions, followed by India, Russia and Japan. According to the Emissions Database for Global Atmospheric Research (Edgar 2019), the total CO2 gas emissions registered in the USA reached 5275.48 mega tonnes in 2018, compared with 11255.88 mega tonnes in China. In the same year, India registered 2621.92 mega tonnes, Russia 1748.35 mega tonnes and Japan 1198.55 mega tonnes. The total energy CO2 emissions in the USA also exhibited an interesting evolution, as Figure 1 plots.

Total energy CO2 emissions in the USA, over January 1984 to April 2020 (million metric tons, seasonally adjusted). Source: constructed based on ‘US Energy Information Administration’ (EIA 2020a) online database, accessed in October, 2020.
Figure 1 clearly shows that the total energy CO2 emissions continuously increased until May 2004, reducing during the crisis from 2008 to 2009. A flat sinusoidal trend is registered until 2019, with a strong rebound in 2020, as the effect of the coronavirus disease (COVID-19). Not at least, it is noteworthy that the USA does not ratify the Kyoto Protocol, signed in 1997. With several amendments, the main target of the agreement is the reduction of greenhouse gas emissions in signatory countries (i.e. 37 industrialised countries and the European Union (EU)).
Many viable solutions were proposed to reduce gas emissions in the last years, using renewable energy being the most important. Hence, a wide range of renewable energy is considered, from hydroelectric, geothermal and solar types to biofuels and biomass ones. This substantially improved the modelling techniques of CO2 emissions and their related forecasting methods.
In this light, the paper aims to predict the CO2 emissions in the USA, taking into account the economic growth, renewable energy consumption and net trade. In order to obtain accurate forecasting, the artificial neural network (ANN) methodology is used as the principal tool. A classical econometric vector autoregressive (VAR) model is employed in parallel for comparison. This allows reinforcing the results, highlighting the valence of ANN approach. Both proposed methodologies perform nonlinear estimations, and the ANN generally offering better quality results (Gallo et al. 2014). The sample covers the period 1984M01–2020M04.
Grossman and Krueger’s (1991) effects are given the theoretical ground, controlled through different types of renewable energy consumption and net international trade. The core is the link between gas emissions and economic growth evidenced by Grossman and Krueger (1991). There are three theoretical transmission channels. First channel is called the ‘scale effect’, showing that growth generates pollution due to increased output. This output requires additional inputs and, therefore, more natural resources, stimulating pollution. Second channel is the ‘technological effect’, revealing that using new technologies is not the result of environmental worries but the race for profit maximisation. The new technologies improve productivity which means fewer inputs. This lowers the prices, reducing pollution. Third channel is represented by ‘composition effects’. It supposes that the government and private follow the services as the economy growths-up as a vector of ‘technological effect’. Further, this allows reaching a low level of pollution (i.e. growth does not generate pollution if the output structure changes). An important hypothesis precedes Grossman and Krueger’s (1991) theory, namely the environmental Kuznets curve (EKC). EKC has its origin in well-known Kuznets’s (1955), claiming an inverted U-shape link between pollution and economic growth.
The valence of renewable energy consumption in the CO2 emissions is clearly evidenced by IREA (2013). Different types of energies, such as wind, solar and hydro, promote friendly environments. In parallel, this creates, in the same time, new jobs and improves skills, reducing income inequality (Zoundi 2017). Several papers also prove a negative influence of renewable energy consumption on CO2 emissions (Bilgili et al. 2016; Wesseh and Lin 2016) or mixed results (Jebli et al. 2015).
Finally, the trade also is an essential ingredient for CO2 emissions, mainly because of its EKC implications via the growth component. Two reasons are underlined by Cole (2004). On the one hand, the intensification of trade reduces pollution as the resources are used more efficient under the pressure of greater competition. On the other hand, the liberalisation of trade often required the restriction of imports of damaging environmental goods.
The contribution of the paper is fivefold. First, to the best of our knowledge, the paper is one of the first works devoted to predicting CO2 emissions in the USA, based on a mix of methodologies. ANN method is employed in parallel with a classical VAR model, helping to reinforce the results by highlighting the valence of ANN against the classical econometric methodologies. Compared with classical tools, the ANN is superior in prediction accuracy. As Appiah et al. (2018) note, the ANN can be easily used for any arbitrary function, works well with any type of model, allows for performing nonlinear estimations and, not least, considers all categories of inputs. However, they are erroneous, incomplete or incoherent. Second, it also analyses the contributions of each considered determinant to CO2 total volume, running from the gross domestic product (GDP) to different types of consumption. Third, unlike the existing studies, the paper predicts not only the volume of total CO2 emissions but also its components derived from coal, natural gas, aviation gasoline, distillate fuel oil, hydrocarbon gas liquids, jet fuel, kerosene, lubricants, motor gasoline, petroleum coke, residual fuel oil, other petroleum products and petroleum, excluding biofuels. Fourth, also as a novelty, the study considers a generous set of renewable types of consumption, as follows: hydroelectric power, geothermal energy, solar energy, wind energy, wood energy, waste energy, biofuels and biomass energy, respectively. Finally, the proposal uses an extended dataset with monthly frequency, improving the accuracy of estimations (i.e. 436 observations and 4796 inputs).
The remainder of the paper is organised as follows: the ‘Literature’ section reviews the literature, the ‘Data and methodology’ section describes the data and methodology, while the ‘Results’ section presents the empirical results. Finally, the ‘Conclusions’ section concludes.
Literature
The literature regarding CO2 emissions forecasting is generous, with a wide range of methodologies, types of predicated gas emissions, targeted countries, covered periods of exploration or dataset frequencies.
Salisu et al. (2018) state that the methodologies of CO2 emissions forecasting are various, running from univariate models (i.e. autoregressive integrated moving average (ARIMA) and autoregressive fractionally integrated moving average (ARFIMA)) to univariate volatility models (i.e. generalised autoregressive conditional heteroscedasticity (GARCH)) and multivariate models (i.e. vector autoregressive (VAR) and vector error correction (VEC)). For example, Magazzino (2014) combines growth, CO2 emissions and energy use by following a panel VAR analysis. Targeting the ASEAN group (i.e. Indonesia, Malaysia, the Philippines, Singapore, Thailand and Brunei Darussalam), over 1971–2007, he finds that the error variances in the CO2 emissions are sensitive to disturbances in both growth and in CO2 equations. Additionally, the author proves that the energy use Granger causes economic growth, validating the ‘growth hypothesis’. In the same vein, Magazzino (2016a) explores South Caucasus and Turkey over 1992–2013. His panel VAR estimations show that, in all three equations, the error variances in the CO2 emissions are sensitive to disturbances. Herein, there is no causality between energy use and growth, suggesting that the ‘neutrality hypothesis’ holds. Unlike his previous studies, Magazzino (2016b) prefers the cointegration technic with breaks for analysing the same South Caucasus and Turkey area. The findings evidence a long-run relationship between growth, CO2 emissions and energy use over 1992–2013. Finally, the author validates the ‘conservation hypothesis’ for Armenia, ‘neutrality hypothesis’ for Turkey and mixed results for Turkey (i.e. both ‘feedback hypothesis’ and ‘growth hypothesis’).
A handy and extended literature review regarding the methods of CO2 emissions forecasting is offered by Abdullah and Pauzi (2015). They identify more heterogeneous tools, such as the ANN, grey models, computer-based simulation models, optimal growth models, linear regressions, pinch analyses, ‘top-down’ methods or adaptive neuro-fuzzy intelligent system approaches.
In the last years, the literature regarding CO2 emissions forecasting based on ANN quickly extended with the development of computational models, having origins in the structure and functions of biological neural networks.
For example, Radojević et al. (2013) follow the ANN to forecast the CO2 emissions in Serbia, also performing parallel estimations for Bulgaria. The used software tool NeuroShell 2 offers excellent predictions covering 1999–2007. The main inputs are as follows: the share of renewable sources of energy, GDP, gross energy consumption and energy intensity, respectively. Liu et al. (2012) choose China to forecast CO2 emissions with good results. Their sample covers the period 1990–2010, while the input parameters are the GDP, exports, consumer price index (CPI), investment in fixed assets and population. The CO2 emissions have origins in fossil fuels and cement production. China also is investigated by Li et al. (2010) proposing a unique ANN tool, namely the radial basis function (RBF). Herein, the total energy consumption is converted to CO2 emissions from 1990 to 2010. The findings show that the RBF approach offers a superior approximation of CO2 emissions compared to the classical ANN techniques. A similar study is proposed by Sun and Sun (2017) regarding China.
Baareh (2013) constructs an ANN for CO2 emissions forecasting by selecting oil, natural gas, coal and primary energy consumption as inputs. He claims that the ANN is a powerful and efficient tool for predicting CO2 emissions. Sözen et al. (2007) focus their study on Turkey, covering 2007–2020. Based on an ANN, the authors obtain accurate estimations for the greenhouse gases (GHGs) by considering sectoral energy consumption as an indicator. The GHG is captured via CO2, carbon monoxide (CO), sulphur dioxide (SO2), nitrous dioxide (NO2) and emissions of non-methane volatile organic compound (E), respectively. Alternatively, the scaled conjugate gradient and Levenberg-Marquardt (LM) tools are also considered.
Unlike them, Behrang et al. (2011) propose an integrated multi-layer perception neural network and Bees Algorithm (BA) approach. The CO2 emissions are successfully forecasted based on a world-wide aggregate sample with 27 years, having as inputs the world’s population, GDP, oil trade movement and natural gas trade movement, respectively. As a novelty, Han et al. (2022a) recently propose a dendrite net method that relied on the adaptive mean square gradient. Their target is to predict the energy consumption of buildings in order to attenuate carbon dioxide emissions. Additionally, the authors show that the method also improves energy saving. In the same vein, Han et al. (2022b) link building energy consumption and carbon dioxide by using the input-output-based data envelopment analysis. Their saving proposed method supports carbon dioxide reduction and offers the ground for a completive socio-economic sustainable development. In the same idea of carbon reduction, the complex industrial processes are investigated by Wu et al. (2022), developing a radial basis function neural network. They integrate multi-dimensional scaling to ensure energy optimisation and carbon emission analysing. As the authors claim, the findings are reinforced by University of California Irvine (UCI) datasets. A more advanced approach suggests Geng et al. (2021) in the industrial process. The authors develop a new gated convolutional neural network (CNN), showing that the tool excellently models the polypropylene and purified terephthalic acid industrial processes.
Curiously, according to Pérez-Suárez and López-Menéndez (2015), the theoretical core of those contributions is not centred on the EKC, despite its popularity. Salisu et al. (2018) show that many studies validate the existence of the EKC (e.g. Shafic and Bandyopadhyay 1992; Panayotou 1993; Grossman and Krueger 1995; Ang 2007; Fodha and Zaghdoud 2010; Kohler 2013; Aydoğan and Vardar 2020; Malik et al. 2020), while a significant group of works does not empirically support the effect (e.g. Paudel et al. 2005; Pao and Tsai 2010; Robalino-López et al. 2014). Dinda (2004) offers a valuable review of the literature regarding the EKC. Moreover, the World Commission on Environment and Development (WCED 1987) advances a contrary EKC vision, stressing that there is a U-shape link between environmental degradation and growth. Called the Brundtland Curve hypothesis, this supposes that in poor countries, environmental degradation is high initially, decreases as the economy expands, but rises after a turning point of growth.
In many analyses, the EKC is sustained by additional control determinants. Out of them, renewable energy consumption is often considered (Bilgili et al. 2016; Zoundi 2017), agriculture size (Liu et al. 2017), foreign trade (Chen et al. 2019; Dogan and Turkekul 2016) urbanisation or financial development (Dogan and Turkekul 2016).
The literature devoted to CO2 emissions forecasting in the USA is relatively scarce. Officially, the prediction of CO2 emissions in the USA is made by Energy Information Administration (EIA 2020b). The primary gas emission sources are petroleum, natural gas, coal and total fossil fuels. There are three central modelling systems, as follows: World Energy Projection System (WEPS), offering annual global energy projections; Short-Term Integrated Forecasting System (STIFS), outputting motherly forecasting; and National Energy Modeling System (NEMS), generating annual US energy estimations. Various tools are used, ranging from linear regressions, method of solving for equilibrium, electricity load shapes, cointegration analysis, time-series benchmarking and mathematical programming.
Silva (2013) proposes alternative estimates to the official ones by entering a battery of methods, such as the ARIMA, Holt-Winters and exponential smoothing, before introducing the singular spectrum analysis (SSA). Auffhammer and Steinhauser (2012) propose a different approach using the US state-level panel dataset of CO2 emissions. They claim that the well-known models in the literature and models considering the emissions per capita or different in-sample selection criteria allow obtaining less accurate estimations than the constructed model based on the out-of-sample loss measure defined over aggregate emissions. Bennedsen et al. (2021) estimate the CO2 emissions in the USA based on a structural augmented dynamic factor model, with 226 observations. Their main finding shows that the Residential Utilities Index (RUI) is crucial for the CO2 emissions predictions. In a very recent work, Eberle and Heath (2020) estimate the carbon dioxide emissions from electricity generation in the USA. The authors offer an innovative approach with two scenarios of future emissions: one with low emissions and another with high emissions. The core of their estimations is represented by a mix of ‘ingredients’, combining the capacity forecasts of US electric generation with technology- and fuel-specific capacity factors and emission factors. They found that if no shifts in electricity sources are made, four of the six data products could exclude 1.1 to 3.3% of CO2 emissions from US electricity generation in 2040.
Three literature gaps can be identified. First, no paper is devoted to the CO2 emissions forecasting in the USA based on the mix of tools by ANN and VAR types. Second, no work related to the USA uses the GDP and net trade for CO2 emission prediction combined with additional control factors. Third, just a few papers consider the sources of CO2 emissions in parallel with various types of renewable energy consumption as the main inputs for the CO2 emission estimations in the USA. Not at least, no paper forecasts the components of CO2 emissions estimations in the USA, in parallel with an analysis of the contribution of each type of renewable energy consumption as inputs.
Therefore, the paper addresses all gaps mentioned above using the ANN approach with an extended set of inputs. The Grossman and Krueger’s (1991) growth effects, net trade and different types of renewable energy consumption are the core determinants of CO2 emissions forecasting in the USA, including CO2-related components.
Data and methodology
Data
The CO2 emissions forecasting in the USA based on the ANN follows an extended sample with 4360 observations, covering the period 1984M01–2020M04.
The targeted output is the total volume of CO2 emissions (i.e. dependent variable), with its related components derived from coal, natural gas, aviation gasoline, distillate fuel oil, hydrocarbon gas liquids, jet fuel, kerosene, lubricants, motor gasoline, petroleum coke, residual fuel oil, other petroleum products and petroleum, excluding biofuels, respectively.
The predictions follow an extended set of inputs (i.e. independent variables), including the GDP in order to capture the Grossman and Krueger’s (1991) effects, net trade (Cole 2004; Chen et al. 2019; Dogan and Turkekul, 2019) and eighth types of renewable energy consumption (Jebli et al. 2015; Wesseh and Lin 2016; Bilgili et al. 2016; Zoundi 2017). Those renewable energy consumption inputs come from hydroelectric power, geothermal energy, solar energy, wind energy, wood energy, waste energy, biofuels and total biomass energy.
Tables 3 and 4 (Appendix) describe the inputs and outputs, units of measure and data sources, while their descriptive statistics are shown in Table 5 (Appendix). All variables have been seasonally adjusted, with GDP and net trade exceptions already deseasonalised.
According to Sola and Sevilla (1997), good network performance and reduced errors in the training process can be reached by using the variables in their normalised range forms into [0,1].
Generally, the normalisation conversion has this form:
where x′ is the normalised variable x, with xmax and xmin its maximum and minimum levels, respectively.
Methodology
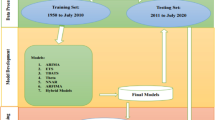
The estimation of total CO2 emissions and its related components (i.e. 14 total outputs) is performed based on a multilayer ANN perception approach, with 11 inputs (i.e. GDP, net trade and eight types of renewable energy consumption), covering 1984M01–2020M04. An alternative method is developed to reinforce the valence of the ANN method. In this way, an alternative VAR model is constructed,Footnote 1 in order to follow the nonlinearity approach of ANN.
ANN tool
The use of ANN methodology in CO2 emissions forecasting has gradually gained in popularity over the last decades. Unfortunately, the classical tools have a low propensity for modelling complex phenomena, such as those in meteorology or air pollution. Moreover, as Gallo et al. (2014, p. 33) note, the ANN methods ‘are widely used when you have no evident mathematical relationship between the variables. So, in the area of air quality forecasting the ANN model can be applied being not known a priori’.
The multilayer ANN perception model represents a nonlinear approach. Its architecture includes an extended network composed of neurons, each neuron being endowed with propagation, activation and output functions (Figure 2).

Architecture of ANN. Source: Mutascu (2020, p.4).
The key idea of the ANN tool is that the outputs (i.e. output layers) are predicted based on m inputs (i.e. input layers) through the ‘hidden layers’, while each layer performs a net output related to neuron j (netj) that receives the outputs \({o}_{i_1}\), \({o}_{i_2}\),... \({o}_{i_n}\)from neurons i1, i2,... in (Kreiner and Duca 2019). The slope of variables belonging to the activation function is calculated based on the weights (wij). The conversion of oi into a weighted sum of the outputs is allowed based on the propagation function of neuron j supported by the aforementioned weights. Supposing bj the intercept of activation function, the transformation process has this form:
The propagation function reduces the dimensionality of the neuron’s j inputs from n to 1, while an optimisation procedure can minimise the sum of in-sample squared errors.
In order to obtain accurate CO2 emission predictions, the ANN configuration is designed by following the approach of Tümer and Akkuş (2018). Their proposal has excellent results, especially in the macroeconomic forecasting field.
Consequently, the ANN is constructed by retaining the feed-forward back-propagation network type. The chosen training function is ‘Levenberg-Marquardt’ (trainlm), with ‘gradient descent’ (learngdm) as adaptive learning function. The mean squared error (MSE) represents the performance function, while ‘hyperbolic tangent’ (tansig) the transfer one. For all learning algorithms in the training process, the number of total iterations is set at 2000.
The optimal ANN architecture is chosen by alternatively testing different combinations of layers-neurons, more precisely: (1, 10), (1, 20), (2, 10), (2, 20), (3, 10) and (3, 20), respectively.
Unfortunately, no very clear rule of selection exists. That is why optimal ANN architecture selection often follows the correlation coefficient (R) as the main ‘key control’, the coefficient testing the performance criteria of ANN training. Further, the root mean square error (RMSE) and coefficient of determination (R2) allow for testing the accuracy of estimations. Both tests have high valence in assessing ANN’s performances. Finally, the model’s performance is validated in terms of accuracy by comparing the simulated data with the historical output values.
Additionally, the relative importance of input variables to the targeted outputs is calculated by following Garson’s Algorithm (Garson 1991). In other words, the algorithm allows identifying the contribution of each input to the target variables. The flowchart of the experimental process is plotted in Fig. 3.

Flowchart of the ANN experimental process
The flowchart reveals an ANN routine, running from the dataset treatment to final outputs, supposing four different stages. In the first stage, the raw dataset, including both inputs and outputs, is normalised to ensure accurate estimations. In the second stage, the optimal ANN structure is created; training and testing further the sets of variables. The dataset with 4360 observations, covering 1984M01–2020M04, is used in the training sequence. The sample includes 11 inputs (i.e. GDP, net trade and eight types of renewable energy consumption) and 14 outputs (i.e. total CO2 emissions and its components). The weight matrixes are calculated in the third stage, allowing generating the main outputs in the last stage. Herein, the contribution of each input to the estimated output can also be identified.
VAR method
VAR tools are widely used to estimate CO2 emissions, representing the classical methodologies in the field (Alam and AlArjani 2021).
This type of stochastic estimator considers the interest variables in their lagged forms (i.e. endogenous variables), offering the possibility to isolate their interaction through different control determinants (i.e. exogenous variables). In this case, the GDP and CO2 emissions are the endogenous variables, while the net trade and eight types of renewable energy consumption are used as control exogenous determinants. GDP and CO2 emissions are interest determinants to follow the EKC link, the central key of study. Noteworthy, the GDP squared is not considered as GDP’s nonlinear effect is directly captured by VAR based on lags. In this case, the VAR has this shape:
where α1 and α2 are the constants; β, γ, φ and μ denote the coefficient of endogenous variables that vary over time t with lags i and j (i, j = 1 to k). Z is the vector of control variables, with coefficients ω1 and ω2, assuming that the errors σ1 and σ2 are not correlated. The variables are treated in their logarithm forms, except GDP expressed as an index, while the variables with negative signs are upwardly rescaled to obtain strict positive values. VAR model considers variables as stationary processes to avoid any bias in estimations. Optimal common selected lag is suggested by the minimal values of Akaike and Schwarz criteria.
Results
ANN estimations
In order to construct an optimal ANN configuration, different scenarios are tested through the correlation coefficients (R) by alternatively using different ‘layers-neurons’ configurations. Table 1 shows followed scenarios based on the repetitive training routine process and their related R:
The repetitive ANN training routines for considered ‘layers-neurons’ configurations generate many closed levels of R, as Table 1 reveals. Although the R values are centred on 0.95, the structures with 1 layer and 20 neurons, and 2 layer and 20 neurons, seem more appropriate to construct an optimal ANN to forecast the total volume of CO2 emissions and its components in the USA. More precisely, the highest R levels (i.e. ≈ 0.95485 and 0.95387) are registered by the (1, 20) and (2, 20) scenarios, recommending those ANN configurations for accurate predictions.
Table 2, the RMSE and R2 are calculated for each scenario to test the accuracy of estimations.
By following the highest R2 and/or lower RMSE, both tests in Table 2 suggest that good predictions in terms of accuracy can be obtained by calibrating the ANN with 1 layer and 20 neurons (1, 20) or 2 layers and 20 neurons (2, 20). Corroborating with R level, it is clear that the more appropriate ANN architecture to accurately forecast the total volume of CO2 emissions and its components in the USA is by (1, 20) form. For this ANN configuration, the RMSE ≈ 0.070275, while R2 ≈ 0.9248.
The simulated output regarding the total volume of CO2 emissions in the USA is presented in parallel with afferent historical data in Fig. 4. The retained (1, 20) ANN has a forecasting power of almost 92.42%, with a related error of 7.58%.

ANN simulated and historical data for total volume of CO2 emissions in the USA
Figure 4 evidences that the ANN simulation for the total volume of CO2 emissions in the USA offers excellent results. The estimations follow the historical values with pretty high accuracy. This strongly supports the idea that the total volume of CO2 emissions can be successfully predicted based on the ANN, having as main inputs the GDP, net trade and, very important, renewable energy use and its components. Moreover, this approach excellently covers the economic crisis from 2008 to 2009, and the pandemic coronavirus disease (COVID-19) started at the end of 2019. Unfortunately, the proposed ANN does not capture all registered historical ‘spikes’, being more prone to ‘smooth’ dynamics. In this light, the ‘dynamic neural networks could have a better performance when it comes to estimating high and peak inflows’ (Hadiyan et al. 2020, p. 8). An extensive palette of models developed during the last years to better capture the peak inflows, the spiking neural network (SNN) type being the prominent oneFootnote 2. Although such models offer good quality results, they seem to be more efficient in the machine learning algorithm in real life (Lee et al. 2020), including human or animal behaviours (Gerstner and Kistler 2002).
The forecasting of the components of CO2 emissions is shown in Figs. 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16 and 17 (Appendix), maintaining the accuracy of the aggregated volume of CO2 emissions. Interesting, the ANN excellently captures the fall of CO2 components related to the most affected economic sectors during the pandemic coronavirus crisis. Concretely, those components are distillate fuel, hydrocarbon gas liquids, jet fuel, lubricants and motor gasoline (without ethanol). Between March and April 2020, the generalised world-wide lockdown negatively altered the transportation industry, which uses the types mentioned above of energy. The total number of commercial flights collapsed by 73% in the USA, while truck tonnage transportation by 9.18% (Mack et al. 2021). Private transportation was also significantly reduced, with a decongestion of highway traffic by around 30% in 2020 compared with 2019. For example, the collapse has been by 36% in Los Angeles, 30% in New York and 25% in Miami (Kelly and Sharafedin 2021). Therefore, a strong rebound has also registered in the related energy use, the consumption redaction being more than significant.
Based on Garson’s Algorithm, the contribution of each input to targeted outputs is presented in Table 6 (Appendix). Wind energy consumption explains 13.61% of predicted outputs, while solar and total biomass energy consumptions contribute 13.24% and 12.61%, respectively. The GDP and biofuels consumption covers 10.48% and 9.97% of forecasting, while net trade and wood energy consumption are around 9.06% and 8.65%, respectively. The lowest contribution levels to the predicted outputs have the waste, hydroelectric power and geothermal renewable energy consumption, each with cca. 7–8% of the total.
The results highlight the importance of the GDP and net trade in the CO2 emissions forecasting, but with the strong support for renewable energy consumption. The outputs are in line with the contribution of Grossman and Krueger (1991), reinforcing the link between environment and growth. The valence of net trade is also underlined, validating the findings of Cole (2004), Chen et al. (2019) or Dogan and Turkekul (2019). But more important is the crucial contribution of renewable energy consumption to CO2 emissions forecasting, fully confirming Jebli et al. (2015), Wesseh and Lin (2016), Bilgili et al. (2016) and Zoundi (2017).
The essential explanatory renewable energy variables are wind energy consumption, followed by solar and biomass energy components. All those offer strong support for the future of green energy. The analysis highlights the low importance in CO2 emissions forecasting of waste, hydroelectric power and geothermal renewable energy consumption. Hydroelectric power production is ‘eco-friendly’ on the one side but can generate substantial natural damage on the other hand.
VAR alternative estimations
The variables’ stationarity tests are presented in Table 7 (Appendix). Augmented Dickey-Fuller (ADF), Phillips-Perron (PP) and Kwiatkowski–Phillips–Schmidt–Shin (KPSS) tests are employed, considering both constants, and constant and trend. Corroborating the results, all variables are I(1), except for hydroelectric power consumption, geothermal energy consumption and wood energy consumption. Therefore, in the VAR model, all I(1) variables are considered in their first differences.
The complete VAR estimations are presented in Table 8 (Appendix). Optimal common selected lag is 4 being indicated by the minimal values of Akaike and Schwarz criteria. According to the LM test in Table 9 (Appendix), no residual serial correlations are observed at lag 4, while the residuals are homoskedastic at the limit (i.e. Chi2 = 134.9, with a probability of 0.0162).
The simulated output of CO2 emissions in the USA in parallel with its historical values is shown in Fig. 18 (Appendix). In order to ensure comparability with ANN simulations, VAR estimation is normalised to 1. Compared with ANN, the findings reveal that the VAR method offers a good prediction of trend dynamics but falls under high gaps between simulated and historical output values. The conclusion is reinforced by Fig. 19 (Appendix). This indicates that the simulated CO2 emissions with ANN have lower residual values than the VAR tool, despite not capturing better the ‘spike’ forms. The superior accuracy of ANN against the autoregressive models as VAR is in line with Lahane (2008) or Adebiyi et al. (2014).
The study has two significant limits. First, no extended set of inputs is considered because of the lack of data. Many of the main CO2 emissions factors evidenced by literature are not officially available with infra-annual frequency, such as the agriculture size, urbanisation or financial development. Second, forecasting quality is exclusively checked based on a classical econometric VAR method, not considering alternative ANN types. This allows us to compare the valence of ANN against the classical methodology and analyse the forecasting quality of similar ANN tools.
Conclusions
The paper offers a mixed tool approach for predicting the total volume of CO2 emissions and its related components in the USA by following a non-linear ANN parametric and VAR methodologies. The forecasting of 14 targeted categories of CO2 emissions is ensured by 4360 observations, including 10 types of inputs, over the period 1984M01–2020M04.
An optimal ANN architecture is proposed by selecting the more appropriate ‘layers-neurons’ pair from different computed combinations, such as (1, 10), (1, 20), (2, 10), (2, 20), (3, 10) and (3, 20). Following the criteria of highest R2 and/or lower RMSE tests (i.e. R2≈ 0.9248, and RMSE ≈ 0.070275), the ANN is finally calibrated as (1, 20) configuration, with 1 layer and 20 neurons.
Overall, the forecasting power has 92.42%, with a related error of 7.58%. The tool is excellently adapted in capturing general crises, especially those pandemic ones, but partially falls under ‘spike’ forms. In parallel, a VAR stochastic method is also proposed to test the quality of ANN. The comparison between ANN and VAR simulations reveals that the ANN tool offers superior results from an accuracy point of view. Although the VAR generates good forecasting as trend dynamic, it completely falls in terms of residuals. Despite not capturing the ‘spike’ forms of CO2 emissions better, ANN experiences much lower residual values than VAR.
The results strongly support the idea that the CO2 emissions and their related components in the USA can be successfully predicted based on the growth effect by controlling for renewable energy consumption and net trade. Except for economic growth, the most significant contributions to targeted outputs are wind, solar and total biomass energy consumption. This supports the idea of CO2 control based on non-polluting capacities, corroborated by the intensively use of green energy by wind, solar and total biomass origins. Net trade and wood energy consumption are also not negligible, while waste, hydroelectric power and geothermal renewable energy consumptions have modest contributions. Herein, dam and reservoir construction can irreversibly alter water temperatures, water chemistry, river flow characteristics, and silt loads, negatively impacting both plants and animals (EIA 2021). As waste and geothermal renewable energy require high investment costs, their current use is modest.
In the light of policy implications, the proposed ANN approach based on growth effect, renewable energy consumption and net trade can be successfully used to predict the CO2 emissions and their related components in the USA. Several policy implications can be identified.
First, such estimations are very useful for US policymakers in the environmental area and any other actor involved in the field (i.e. national statistical offices, international organisations and non-governmental organisations). The tool should be considered with caution given its lack of accuracy in the prediction of ‘spike’ values. Therefore, autoregressive methods seem to capture the dynamic trend better but are limited in their accuracy due to the high gap between simulated and historical output data. In this context, smoothed datasets seem more prone to be analysed via the ANN approach.
Second, in their CO2 predictions, the interested actors should focus on the growth and net trade but more pregnant on the wind, solar and total biomass energy consumptions. The energy consumption components coming from waste, hydroelectric power and renewable geothermal systems should be used in moderation given their unclear status (i.e. collateral environmental damages or high investment costs).
Thirds, the results offer important information for designing environmental policies. The input components are useful in CO2 predictions and in identifying the leading renewable energy sources that allow controlling the CO2 emissions.
As for further research, two directions should be identified. First research direction regards the insertion of more input variables with infra-annual frequency as soon as they are officially available. In this way, the agriculture size (Liu et al. 2017), urbanisation or financial development (Dogan and Turkekul, 2019) can be considered. Second research direction is related to the methodology. Herein, the dynamic ANN can be resorted as a gradual further step in using ANN tools in the CO2 emissions forecasting process. According to Hadiyan et al. (2020), such a technique generally adds more quality in estimations because all layers have feedback links with different time delays. However, the field of dynamic ANN research is still in progress, especially regarding the ‘spike’ behaviour (Versace 2022).
Data availability
The data that support the findings of this study are openly available in OECD dataset, at https://doi.org/10.1787/data-00285-en, and in US Energy Information Administration, at https://www.eia.gov/totalenergy/data/browser/.
Notes
Because of lack of space, only the simulation of the total volume of CO2 is offered, the rest of the components being available upon request.
A Matlab code is available and dated April 5th, 2022 (Versace 2022), at https://ch.mathworks.com/ matlabcentral/fileexchange/25931-spiking-neurons-simulator.
References
Abdullah L, Pauzi HM (2015) Methods in forecasting carbon dioxide emissions: a decade review. J Teknol (Sciences & Engineering) 75(1):67–82
Adebiyi AA, Adewumi AO, Ayo CK (2014) Comparison of ARIMA and artificial neural networks models for stock price prediction. J Appl Math 2014:614342
Alam T, AlArjani A (2021) A comparative study of CO2 emission forecasting in the gulf countries using autoregressive integrated moving average, artificial neural network, and holt-winters exponential smoothing models. Adv Meteorol 2021:8322590
Ang JB (2007) CO 2 emissions, energy consumption, and output in France. Energy Policy 35(10):4772–4778
Appiah K, Du J, Appah R, Quacoe D (2018) Prediction of potential carbon dioxide emissions of selected emerging economies using artificial neural network. J Environ Sci Eng A7:321–335
Auffhammer M, Steinhauser R (2012) Forecasting the path of U.S, CO2 emissions using state-level information. Rev Econ Stat 94(1):172–185
Aydoğan B, Vardar G (2020) Evaluating the role of renewable energy, economic growth and agriculture on CO2 emission in E7 countries. Int J Sustain Energy 39(4):335–348
Baareh AK (2013) Solving the carbon dioxide emission estimation problem: an artificial neural network model. J Softw Eng Appl 6:338–342
Behrang MA, Assareh E, Assari M, Ghanbarzadeh RA (2011) Using bees algorithm and artificial neural network to forecast world carbon dioxide emission. Energy Sources, Part A: Recovery, Util Environ Effects 33(19):1747–1759
Bennedsen M, Hillebrand E, Koopman SJ (2021) Modeling, forecasting, and nowcasting U.S. CO2 emissions using many macroeconomic predictors. Energy Econ 96:1–17. [105118]. https://doi.org/10.1016/j.eneco.2021.105118
Bilgili F, Koçak E, Bulut Ü (2016) The dynamic impact of renewable energy consumption on CO2 emissions: a revisited Environmental Kuznets Curve approach. Renew Sust Energ Rev 54:838–845
Chen Y, Zheng W, Zhangqi Z (2019) CO2 emissions, economic growth, renewable and non-renewable energy production and foreign trade in China. Renew Energy 131(C):208–216
Cole MA (2004) Trade, the pollution haven hypothesis and the environmental Kuznets curve: examining the linkages. Ecol Econ 48:71–81
Dinda S (2004) Environmental Kuznets curve hypothesis: a survey. Ecol Econ 49(4):431–455
Dogan E, Turkekul B (2016) CO2 emissions, real output, energy consumption, trade, urbanisation and financial development: testing the EKC hypothesis for the USA. Environ Sci Pollut Res Int 23:1203–1213
Eberle AL, Heath GA (2020) Estimating carbon dioxide emissions from electricity generation in the United States: how sectoral allocation may shift as the grid modernises. Energy Policy 140:111324
Edgar (2019) Emissions database for global atmospheric research. In: Crippa M, Oreggioni G, Guizzardi D, Muntean M, Schaaf E, Lo Vullo E, Solazzo E, Monforti-Ferrario F, Olivier JGJ, Vignati E (eds) Fossil CO2 and GHG emissions of all world countries - 2019 Report. Office of the European Union, Luxembourg
EIA (2020a) US energy information administration online database. https://www.eia.gov/international/data/world. Accessed October 2020
EIA (2020b) Analysis & projections, Handbook of Energy Modeling Methods, October, 14th. https://www.eia.gov/analysis/handbook/
EIA (2021) Hydropower explained, hydropower and the environment. https://www.eia.gov/energyexplained/hydropower/hydropower-and-the-environment.php
Fodha M, Zaghdoud O (2010) Economic growth and pollutant emissions in Tunisia: an empirical analysis of the environmental Kuznets curve. Energy Policy 38(2):1150–1156
Gallo C, Contò F, Fiore M (2014) A neural network model for forecasting CO2 emission. Agris On-line Pap Econ Inform 6(2):31–36
Garson GD (1991) Interpreting neural network connection weights. AI Expert 6:47–51
Geng Z, Chen Z, Meng Q, Han Y (2021) Novel transformer based on gated convolutional neural network for dynamic soft sensor modeling of industrial processes. IEEE Trans Ind Inform. https://doi.org/10.1109/TII.2021.3086798
Gerstner W, Kistler WM (2002) Spiking neuron models: single neurons, populations, plasticity. Cambridge University Press, Cambridge
Grossman GM, Krueger AB (1991) Environmental Impacts of a North American Free Trade Agreement. WP No. 3914, National Bureau of Economic Research (NBER). https://www.nber.org/papers/w3914
Grossman GM, Krueger AB (1995) Economic growth and the environment. Q J Econ 110(2):353–377
Hadiyan PP, Moeini P, Ehsanzadeh E (2020) Application of static and dynamic artificial neural networks for forecasting inflow discharges, case study: Sefidroud Dam reservoir. Sustain Comp: Inform Syst 27:100401
Han Y, Li J, Lou X, Fan C, Geng Z (2022a) Energy saving of buildings for reducing carbon dioxide emissions using novel dendrite net integrated adaptive mean square gradient. Appl Energy 309:118409
Han Y, Li J, Lou X, Feng M, Geng Z, Chen L, Ping W, Lu G (2022b) Energy consumption analysis and saving of buildings based on static and dynamic input-output models. Energy 239(Part C):122240
Ibrahim OM (2013) A comparison of methods for assessing the relative importance of input variables in artificial neural networks. J Appl Sci Res 9(11):5692–5700
IREA, (2013). Africa’s renewable future: the path to sustainable growth, International Renewable Energy Agency - IRENA Secretariat. https://irena.org/publications/2013/Jan/Africas-Renewable-Future-the-Path-to-Sustainable-Growth.
Jebli BM, Youssef BS, Ozturk I (2015) The role of renewable energy consumption and trade: environmental Kuznets curve analysis for sub-Saharan Africa countries. Afr Dev Rev 27:288–300
Kelly S, Sharafedin B, (2021). Pandemic cut traffic congestion in most countries last year - report, Reuters, accessed in April 4th, 2022. https://www.reuters.com/world/china/pandemic-cut-traffic-congestion-most-countries-last-year-report-2021-01-13/
Kohler M (2013) CO2 emissions, energy consumption, income and foreign trade: a South African perspective. Energy Policy 63:1042–1050
Kreiner A, Duca JV (2019) Can machine learning on economic data better forecast the unemployment rate? Appl Econ Lett. https://doi.org/10.1080/13504851.2019.1688237
Kuznets S (1955) Economic growth and income inequality. Am Econ Rev 45:1–28
Lahane AG (2008) Financial forecasting: comparison of ARIMA, FFNN and SVR, Presentation. http://www.it.iitb.ac.in
Lee C, Sarwar SS, Panda P, Srinivasan G, Roy K (2020) Enabling spike-based backpropagation for training deep neural network architectures. Front Neurosci 14:119. https://doi.org/10.3389/fnins.2020.00119
Li S, Zhou R, Ma X, (2010). The forecast of CO2 emissions in China based on RBF neural networks. In: Industrial and Information Systems (IIS), 2nd International Conference 2010, 319-322
Liu P, Zhang G, Cheng X, (2012). Carbon emissions modeling of china using neural Network. In: Computational Sciences and Optimisation (CSO), Fifth International Joint Conference, 679-682
Liu X, Zhang S, Bae J (2017) The impact of renewable energy and agriculture on carbon dioxide emissions: investigating the environmental Kuznets curve in four selected ASEAN countries. J Clean Prod 164:1239–1247
Mack EA, Agrawal S, Wang S (2021) The impacts of the COVID-19 pandemic on transportation employment: a comparative analysis. Transp Res Interdiscip Perspect 12:100470
Magazzino C (2014) A panel VAR approach of the relationship among economic growth, CO2 emissions, and energy use in the ASEAN-6 countries. Int J Energy Econ Policy 4(4):546–553
Magazzino C (2016a) Economic growth, CO2 emissions and energy use in the South Caucasus and Turkey: a PVAR analyses. Int Energy J 16:153–162
Magazzino C (2016b) The relationship among real gross domestic product, CO2 emissions, and energy use in South Caucasus and Turkey. Int J Energy Econ Policy 6(4):672–683
Malik MY, Latif K, Khan Z, Butt HD, Hussain M, Nadeem MA (2020) Symmetric and asymmetric impact of oil price, FDI and economic growth on carbon emission in Pakistan: evidence from ARDL and non-linear ARDL approach. Sci Total Environ 726:138421
Mutascu M, (2020). An artificial neural network approach for the prediction of unemployment rate based on artificial intelligence, Mimeo.
OECD, (2020). Organisation for Economic Co-operation and Development (OECD), statistics online database, accessed in 2020.
Panayotou T, (1993). Empirical tests and policy analysis of environmental degradation at different stages of economic development. Int Labour Org 292778
Pao HT, Tsai CM (2010) CO2 emissions, energy consumption and economic growth in BRIC countries. Energy Policy 38(12):7850–7860
Paudel KP, Zapata H, Susanto D (2005) An empirical test of environmental Kuznets curve for water pollution. Environ Resour Econ 31(3):325–348
Pérez-Suárez R, López-Menéndez AJ (2015) Growing green? Forecasting CO2 emissions with environmental Kuznets curves and logistic growth models. Environ Sci Pol 54:428–437
Radojević D, Pocajt V, Popović I, Perić-Grujić A, Ristić M (2013) Forecasting of greenhouse gas emission in Serbia using artificial neural networks. Energy Sources, Part A: Recovery, Util Environ Effects 35(8):733–740
Robalino-López A, García-Ramos JE, Golpe AA, Mena-Nieto Á (2014) System dynamics modelling and the environmental Kuznets curve in Ecuador (1980–2025). Energy Policy 67:923–931
Salisu AA, Akanni LO, Ogbonna AE, (2018). Forecasting CO2 emissions: does the choice of estimator matter? Centre for Econometric and Allied Research, University of Ibadan Working Papers Series, CWPS 0045
Shafic N, Bandyopadhyay S, (1992). Economic growth and environmental quality. Time-series and Cross Country Evidence. Policy Research Working Paper no. 904, World Development Report 1992, The World Bank.
Silva E (2013) A combination forecast for energy related CO2 emissions in the United States. Int J Energy Stat 1(4):269–279
Sola J, Sevilla J (1997) Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans Nucl Sci 44(3):1464–1468
Sözen A, Gülseven Z, Arcaklioğlu E (2007) Forecasting based on Sectoral energy consumption of GHGs in Turkey and Mitigation Policies. Energy Policy 35(12):6491–6505
Sun W, Sun J (2017) Prediction of carbon dioxide emissions based on principal component analysis with regularised extreme learning machine: the case of China. Environ Eng Res 22(3):302–311
Tümer AE, Akkuş A (2018) Forecasting gross domestic product per capita using artificial neural networks with non-economical parameters. Physica A: Statistical Mech Appl 512:468–473
Versace M, (2022). Spiking Neurons simulator, https://www.mathworks.com/matlabcentral/ fileexchange/25931-spiking-neurons-simulator), MATLAB Central File Exchange. Retrieved April 5, 2022
WCED (1987) Our Common Future, World Commission on Environment and Development. Oxford University Press, Oxford
Wesseh PK, Lin B (2016) Can African countries efficiently build their economies on renewable energy? Renew Sust Energ Rev 54:161–173
Wu H, Han Y, Geng Z, Fan J, Xu W (2022) Production capacity assessment and carbon reduction of industrial processes based on novel radial basis function integrating multi-dimensional scaling. Sustain Energy Technol Assess 49:101734
Zoundi Z (2017) CO2 emissions, renewable energy and the environmental Kuznets curve, a panel cointegration approach. Renew Sust Energ Rev 72:1067–1075
Author information
Authors and Affiliations
Contributions
The author confirms sole responsibility for the following: study conception and design, data collection, analysis and interpretation of results, and manuscript preparation.
Corresponding author
Ethics declarations
Ethics approval
Not applicable, because this article does not contain any studies with human or animal subjects.
Consent to participate
Not applicable
Consent for publication
Not applicable
Competing interests
The authors declare no competing interests.
Additional information
Responsible Editor: V.V.S.S. Sarma
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix

Simulated data and historical data for coal CO2 emissions in the USA

Simulated data and historical data for natural gas CO2 emissions in the USA

Simulated data and historical data for aviation gasoline CO2 emissions in the USA

Simulated data and historical data for distillate fuel oil CO2 emissions in the USA

Simulated data and historical data for hydrocarbon gas liquids CO2 emissions in the USA

Simulated data and historical data for jet fuel CO2 emissions in the USA

Simulated data and historical data for kerosene CO2 emissions in the USA

Simulated data and historical data for lubricants, CO2 emissions in the USA

Simulated data and historical data for motor gasoline, excluding ethanol, CO2 emissions in the USA

Simulated data and historical data for petroleum coke CO2 emissions in the USA

Simulated data and historical data for residual fuel oil CO2 emissions in the USA

Simulated data and historical data for other petroleum products, CO2 emissions in the USA

Simulated data and historical data for petroleum, excluding biofuels, CO2 emissions in the US

VAR simulated and historical data for total volume of CO2 emissions in the USA

ANN and VAR simulated data and historical values of total volume of CO2 emissions in the USA
Rights and permissions
About this article

Cite this article
Mutascu, M. CO2 emissions in the USA: new insights based on ANN approach. Environ Sci Pollut Res 29, 68332–68356 (2022). https://doi.org/10.1007/s11356-022-20615-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11356-022-20615-1