
Abstract
Sparse matrix–vector multiplication (SpMV) is one of the most indispensable kernels of solving problems in numerous applications, but its performance of SpMV is limited by the need for frequent memory access. Modern processors exploit data-level parallelism to improve the performance using single-instruction multiple data (SIMD). In order to take full advantage of SIMD acceleration technology, a new storage format called Variable Blocked-\(\sigma\)-SIMD Format (VBSF) is proposed in this paper to change the irregular nature of traditional matrix storage formats. This format combines the adjacent nonzero elements into variable size blocks to ensure that SpMV can be computed with SIMD vector units. We compare the VBSF-based SpMV with traditional storage formats using 15 matrices as a benchmark suite on three computing platforms (FT2000, Intel Xeon E5 and Intel Silver) with different SIMD length. For the matrices in the benchmark suite, the VBSF obtains great performance improvement on three platforms, respectively, and it proves to have better storage efficiency compared with other storage formats.










Similar content being viewed by others


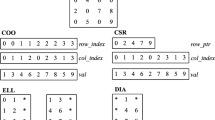
References
Blelloch GE, Heroux MA, Zagha M (1993) Segmented operations for sparse matrix computation on vector multiprocessors. Technical reports, Pittsburgh, PA, USA
Chen S, Fang J, Chen D, Xu C, Wang Z (2018) Optimizing sparse matrix–vector multiplication on emerging many-core architectures. ArXiv preprint arXiv:1805.11938
Chen X, Xie P, Chi L et al (2018) An efficient SIMD compression format for sparse matrix-vector multiplication. Concurr Comput Pract Exp 30(23):e4800
Davis TA, Hu Y (2011) The University of Florida sparse matrix collection. ACM Trans Math Softw 38(1):1:1–1:25
DAzevedo EF, Fahey MR, Mills RT (2005) Vectorized sparse matrix multiply for compressed row storage format. In: Proceedings of the 5th International Conference on Computational Science-Volume Part I, ICCS’05. Springer, Berlin, pp 99–106
Goumas G, Kourtis K, Anastopoulos N, Karakasis V, Koziris N (2009) Performance evaluation of the sparse matrix–vector multiplication on modern architectures. J Supercomput 50(1):36–77
Im EJ, Yelick K, Vuduc R (2004) Sparsity: optimization framework for sparse matrix kernels. Int J High Perform Comput Appl 18(1):135–158
Im EJ, Yelick KA (2001) Optimizing sparse matrix computations for register reuse in SPARSITY. In: Proceedings of the International Conference on Computational Sciences-Part I, ICCS ’01. Springer, Berlin, pp 127–136
Karakasis V, Goumas G, Koziris N (2009) A comparative study of blocking storage methods for sparse matrices on multicore architectures. In: Proceedings of the 2009 International Conference On Computational Science And Engineering-Volume 01, CSE ’09. IEEE Computer Society, Washington, DC, pp 247–256
Karakasis V, Goumas G, Koziris N (2009) Perfomance models for blocked sparse matrix–vector multiplication kernels. In: Proceedings of the 2009 International Conference on Parallel Processing, ICPP ’09. IEEE Computer Society, Washington, DC, pp 356–364
Kreutzer M, Hager G, Wellein G, Fehske H, Bishop A (2013) A unified sparse matrix data format for efficient general sparse matrix–vector multiplication on modern processors with wide SIMD units. SIAM J Sci Comput 36(5):C401–C423
Langr D, Tvrdik P (2015) Evaluation criteria for sparse matrix storage formats. IEEE Trans Parallel Distrib Syst 27(2):428–440
Li J, Tan G, Chen M, Sun N (2013) SMAT: an input adaptive auto-tuner for sparse matrix–vector multiplication. SIGPLAN Not. 48(6):117–126
Li J, Zhang X, Tan G, Chen M (2014) Study of choosing the optimal storage format of sparse matrix vector multiplication. J Comput Res Dev 51(4):882–894
Liu F, Yang C (2014) A new sparse matrix storage format for improving SpMV performance by SIMD. J Numer Methods Comput Appl 35(4):269–276
Liu W, Vinter B (2015) CSR5: an efficient storage format for cross-platform sparse matrix–vector multiplication. In: Proceedings of the 29th ACM on International Conference on Supercomputing, ICS ’15. New York, pp 339–350
Liu X, Smelyanskiy M, Chow E, Dubey P (2013) Efficient sparse matrix–vector multiplication on x86-based many-core processors. In: Proceedings of the 27th International ACM Conference on International Conference on Supercomputing. ACM, pp 273–282
Patterson DA (2007) The parallel computing landscape: a Berkeley view. In: ACM/IEEE International Symposium on Low Power Electronics and Design
Pinar A, Heath M.T (1999) Improving performance of sparse matrix–vector multiplication. In: Proceedings of the 1999 ACM/IEEE Conference on Supercomputing, SC ’99. ACM, New York
Saad Y (1990) SPARSKIT: a basic tool kit for sparse matrix computations NASA Ames Research Center TR 90-20
Saad Y (2003) Iterative methods for sparse linear systems, 2nd edn. Society for Industrial and Applied Mathematics, Philadelphia
Sedaghati N, Mu T, Pouchet L.N, Parthasarathy S, Sadayappan P (2015) Automatic selection of sparse matrix representation on GPUs. In: Proceedings of the 29th ACM on International Conference on Supercomputing, ICS ’15. New York, pp 99–108
Shalf J, Dosanjh S, Morrison J (2011) Exascale computing technology challenges. In: Proceedings of the 9th International Conference on High Performance Computing for Computational Science, VECPAR’10. Springer, Berlin, pp 1–25
Shen J, Varbanescu AL, Zou P, Lu Y, Sips H (2014) Improving performance by matching imbalanced workloads with heterogeneous platforms. In: Proceedings of the 28th ACM International Conference on Supercomputing, ICS ’14. ACM, New York, pp 241–250
Sun X, Zhang Y, Wang T, Long G, Zhang X, Li Y (2011) CRSD: application specific auto-tuning of SpMV for diagonal sparse matrices. In: Proceedings of the 17th International Conference on Parallel Processing-Volume Part II, Euro-Par’11. Springer, pp 316–327
Vuduc R.W, Moon H.J (2005) Fast sparse matrix–vector multiplication by exploiting variable block structure. In: Proceedings of the First International Conference on High Performance Computing and Communications, HPCC’05. Springer, Berlin, pp 807–816
Xu C, Deng X, Zhang L, Fang J, Wang G, Jiang Y, Cao W, Che Y, Wang Y, Wang Z (2014) Collaborating CPU and GPU for large-scale high-order CFD simulations with complex grids on the TianHe-1A supercomputer. J Comput Phys 278:275–297
Yelick K (2008) pOSKI: an extensible autotuning framework to perform optimized SpMVs on Multicore Architectures. Ph.D. Thesis, Department of Electrical Engineering and Computer Sciences, University of California at Berkeley
Zhang A, An H, Yao W, Liang W, Jiang X, Li F (2016) Efficient sparse matrix–vector multiplication on intel xeon phi. J Chin Comput Syst 37(4):818–823
Zhao Y, Li J, Liao C, Shen X (2018) Bridging the gap between deep learning and sparse matrix format selection. SIGPLAN Not. 53(1):94–108
Acknowledgements
This research work was supported in part by the National Key Research and Development Program of China (2017YFB0202104).
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher's Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Li, Y., Xie, P., Chen, X. et al. VBSF: a new storage format for SIMD sparse matrix–vector multiplication on modern processors. J Supercomput 76, 2063–2081 (2020). https://doi.org/10.1007/s11227-019-02835-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11227-019-02835-4