
Abstract
A robust clustering method for probabilities in Wasserstein space is introduced. This new ‘trimmed k-barycenters’ approach relies on recent results on barycenters in Wasserstein space that allow intensive computation, as required by clustering algorithms to be feasible. The possibility of trimming the most discrepant distributions results in a gain in stability and robustness, highly convenient in this setting. As a remarkable application, we consider a parallelized clustering setup in which each of m units processes a portion of the data, producing a clustering report, encoded as k probabilities. We prove that the trimmed k-barycenter of the \(m\times k\) reports produces a consistent aggregation which we consider the result of a ‘wide consensus’. We also prove that a weighted version of trimmed k-means algorithms based on k-barycenters in the space of Wasserstein keeps the descending character of the concentration step, guaranteeing convergence to local minima. We illustrate the methodology with simulated and real data examples. These include clustering populations by age distributions and analysis of cytometric data.











Similar content being viewed by others
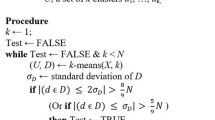

References
Agueh, M., Carlier, G.: Barycenters in the Wasserstein space. SIAM J. Math. Anal. 43(2), 904–924 (2011)
Anderes, E., Borgwardt, S., Miller, J.: Discrete wasserstein barycenters: optimal transport for discrete data. Math. Methods Oper. Res. 84, 389–409 (2016)
Álvarez-Esteban, P.C., del Barrio, E., Cuesta-Albertos, J.A., Matrán, C.: A fixed-point approach to barycenters in Wasserstein space. J. Math. Anal. Appl. 441(2), 744–762 (2016)
Álvarez-Esteban, P.C., del Barrio, E., Cuesta-Albertos, J.A., Matrán, C.: Wide Consensus aggregation in the Wasserstein Space. Application to location-scatter families. Bernoulli (2017) (to appear)
Benamou, J.D., Carlier, G., Cuturi, M., Nenna, L., Peyre, G.: Iterative Bregman projections for regularized transportation problems. SIAM J. Sci. Comput. 37(2), 1111–1138 (2015)
Bigot, J., Klein, T.: Consistent estimation of a population barycenter in the Wasserstein space (2015) ArXiv e-prints, arXiv:1212.2562v5, March 2015
Bigot, J., Gouet, R., Klein, T., López, A.: Geodesic PCA in the Wasserstein space by Convex PCA. Ann Inst. Henri Poincaré Probab. Stat. 53(1), 1–26 (2017)
Boissard, E., Le Gouic, T., Loubes, J.-M.: Distribution’s template estimate with Wasserstein metrics. Bernoulli 21(2), 740–759 (2015)
Breiman, L.: Bagging predictors. Mach. Learn. 24, 123–140 (1996)
Bühlmann, P.: Bagging, boosting and ensemble methods. In: Gentle, E.J., Härdle, K.W., Mori, Y. (eds.) Handbook of Computational Statistics: Concepts and Methods, pp. 985–1022. Springer, Berlin (2012)
Carlier, G., Oberman, A., Oudet, E.: Numerical methods for matching for teams and Wasserstein barycenters. ESAIM Math. Model. Numer. Anal. 49(6), 1621–1642 (2015)
Carlier, G., Chernozhukov, V., Galichon, A.: Vector quantile regression: an optimal transport approach. Ann. Stat. 44(3), 1165–1192 (2016)
Chernozhukov, V., Galichon, A., Hallin, M., Henry, M.: Monge-Kantorovich depth, quantiles, ranks, and signs. Ann. Stat. 45(1), 223–256 (2017)
Cuesta-Albertos, J.A., Fraiman, R.: Impartial trimmed k-means for functional data. Comput. Stat. Data Anal. 51(10), 4864–4877 (2007)
Cuesta-Albertos, J.A., Matrán, C.: The strong law of large numbers for \(k\)-means and best possible nets of Banach valued random variables. Probab. Theor. Related Fields 78, 523–534 (1988)
Cuesta-Albertos, J.A., Gordaliza, A., Matrán, C.: Trimmed k-means: an attempt to robustify quantizers. Ann. Stat. 25(2), 553–576 (1997)
Cuturi, M., Doucet, A.: Fast computation of Wasserstein barycenters. In: Proceedings of the 31st International Conference on Machine Learning, Beijing, China, 2014. JMLR: W&CP, vol. 32 (2014)
del Barrio, E., Lescornel, H., Loubes, J.M.: A statistical analysis of a deformation model with Wasserstein barycenters: estimation procedure and goodness of fit test (2015). Preprint http://arxiv.org/abs/1508.06465
del Barrio, E., Cuesta-Albertos, J.A., Matrán, C.: Profiles of pyramid ages in American countries: a trimmed \(k\)-barycenters approach. Technical Report (2016)
Delicado, P.: Dimensionality reduction when data are density functions. Comput. Stat. Data Anal. 55(1), 401–420 (2011)
Dobric, V., Yukich, J.E.: Asymptotics for transportation cost in high dimensions. J. Theor. Probab. 8, 97–118 (1995)
Dudley, R.M.: Real Analysis and Probability. Cambridge University Press, Cambridge (2004)
Dudoit, S., Fridlyand, J.: Bagging to improve the accuracy of a clustering procedure. Bioinformatics 19(9), 1090–1099 (2003)
Flury, B.: Estimation of principal points. Appl. Stat. 42(1), 139–151 (1993)
Fritz, H., García-Escudero, L.A., Mayo-Iscar, A.: tclust: an R package for a trimming approach to cluster analysis. J. Stat. Softw. 47(12), 1–26 (2012)
Gallegos, M.T., Ritter, G.: A robust method for cluster analysis. Ann. Stat. 33, 347–380 (2005)
García-Escudero, L.A., Gordaliza, A.: A proposal for robust curve clustering. J. Classif. 22(2), 185–201 (2005)
García-Escudero, L.A., Gordaliza, A., Matrán, C.: Trimming tools in exploratory data analysis. J. Comput. Graph. Stat. 12(2), 434–449 (2003)
García-Escudero, L.A., Gordaliza, A., Matrán, C., Mayo-Iscar, A.: A general trimming approach to robust cluster analysis. Ann. Stat. 36(3), 1324–1345 (2008)
García-Escudero, L.A., Gordaliza, A., Matrán, C., Mayo-Iscar, A.: Exploring the number of groups in robust model-based clustering. Stat. Comput. 21, 585–599 (2011)
García-Escudero, L.A., Gordaliza, A., Matrán, C., Mayo-Iscar, A.: Avoiding spurious local maximizers in mixture modeling. Stat. Comput. 25, 619–633 (2015)
Hennig, C., Meila, M., Murtagh, F., Rocci, R. (eds.): Handbook of Cluster Analysis. Chapman and Hall/CRC, Cambridge (2016)
Kneip, A., Gasser, T.: Statistical tools to analyze data representing a sample of curves. Ann. Stat. 20(3), 1266–1305 (1992)
Le Gouic, T., Loubes, J.M.: Existence and consistency of Wasserstein barycenters. Probab. Theor. Related Fields 168(3–4), 901–917 (2017)
Leisch, F.: Bagged clustering. Technical report. (1999) http://www.ci.tuwien.ac.at/?leisch/papers/fl-techrep.html
Lember, J.: On minimizing sequences for k-centres. J. Approx. Theory 120(1), 20–35 (2003)
Lo, K., Brinkman, R.R., Gottardo, R.: Automated gating of flow cytometry data via robust model-based clustering. Cytom. Part A J. Int. Soc. Anal. Cytol. 73(4), 32132 (2008). https://doi.org/10.1002/cyto.a.20531
Luschgy, H., Pagès, G.: Functional quantization of Gaussian processes. J. Funct. Anal. 196, 486–531 (2002)
Pärna, K.: Strong consistency of k-means clustering criterion. Acta Comm. Univ. Tartuensis 733, 86–96 (1986)
Pärna, K.: On the existence and weak convergence of k-centres in Banach spaces. Acta Comm. Univ. Tartuensis 893, 17–28 (1990)
Pyne, S., Hu, X., Wang, K., et al.: Automated high-dimensional flow cytometric data analysis. Proc. Natl. Acad. Sci. USA 106(21), 8519–8524 (2009)
Pyne, S., Lee, S.X., Wang, K., Irish, J., Tamayo, P., Nazaire, M.D., Duong, T., Ng, S.K., Hafler, D., Levy, R., Nolan, G.P.: Joint modeling and registration of cell populations in cohorts of high-dimensional flow cytometric data. PLoS ONE 9(7), e100334 (2014)
Sverdrup-Thygeson, H.: Strong law of large numbers for measures of central tendency and dispersion of random variables in compact metric spaces. Ann. Stat. 9(1), 141–145 (1981)
Villani, C.: Optimal Transport: Old and New, vol. 338. Springer, Berlin (2008)
Author information
Authors and Affiliations
Corresponding author
Additional information
Research partially supported by the Spanish Ministerio de Economía y Competitividad and FEDER, Grants MTM2014-56235-C2-1-P, MTM2014-56235-C2-2, and by Consejería de Educación de la Junta de Castilla y León, Grant VA212U13.
Appendix
Appendix
Here we present the proofs of the main results in the paper. Most of the proofs make use of some well-known features of transportation cost metrics. For the sake of readability we include also some relevant facts concerning the \(L_2\)-Wasserstein distance defined in (3) in connection with the present work. We refer to Villani (2008) for a comprehensive approach.
We note first that the infimum in (3) is attained, that is, there exists a pair (X, Y), defined on some probability space, with \(\mathcal{L}(X)=P\) and \(\mathcal{L}(Y)=Q\) such that \( \mathbf {E}\Vert X-Y\Vert ^2={\mathcal {W}}_2^2(P,Q)\). Such a pair (X, Y) is called a optimal transportation plan (o.t.p.) or optimal coupling for (P, Q). If the probability P has a density, the o.t.p. (X, Y) for (P, Q) can be represented as (X, T(X)) for some suitable map T. This optimal transport map, minimizing the transportation cost for (P, Q) is the P-a.s. unique cyclically monotone map that transports P to Q. Thus, optimality is a feature of the map itself and cyclically monotone maps are always optimal maps from P to the image measure. As an example, an affine map, \(T: {\mathbb {R}}^d \rightarrow {\mathbb {R}}^d \), written in matrix notation as \(T(x)=Ax+b\), is an optimal map if and only if A is a (symmetric) positive semidefinite matrix. Optimality of maps is not generally preserved by composition. However, some kind of operations like positive linear combinations and pointwise limits of optimal maps keep optimality.
For probabilities on the real line, if \(F_P^{-1}\) and \(F_Q^{-1}\) are the quantile functions associated with P and Q, they are an \({\mathcal {W}}_2\)-o.t.p., that is,
In higher dimension there is no equivalent simple expression. However, if \(m_P,m_Q\) are the means of P and Q, and \(P^*,Q^*\) are the corresponding centered in the mean probabilities, then we can focus on the case of centered probabilities because
Recall that \({\mathcal {P}}_2({\mathbb {R}}^d) \) is the set of probabilities on \({\mathbb {R}}^d\) with finite second moment. Convergence in the \({\mathcal {W}}_2\) metric on \({\mathcal {P}}_2({\mathbb {R}}^d) \), \({\mathcal {W}}_2(P_n,P) \rightarrow 0\), is characterized by
Finally, we mention that if \((P_n)_n, (Q_n)_n\) are sequences in \({\mathcal {P}}_2({\mathbb {R}}^d) \), such that \(P_n \rightarrow _wP\) and \(Q_n \rightarrow _wQ\), then \({\mathcal {W}}_2(P,Q)\le \liminf {\mathcal {W}}_2(P_n,Q_n)\).
A main tool for proving convergence results in the space \(W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) (recall the definition (5) in Sect. 2) is given by the next couple of results, extending (22) and the subsequent comment for \({\mathcal {W}}_2\) [see, e.g., Theorem 6.9 and Remark 6.12 in Villani (2008)] to the Wasserstein distance, \({\mathcal {W}}_{{\mathcal {P}}_2}\), defined on \(W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) .
Theorem 6.1
Assume \((\mu _n)_n, \mu \in W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\), and consider the probability concentrated at zero, \(\delta _{\{0\}}\) (that can be substituted by any other fixed probability in \({\mathcal {P}}_2({\mathbb {R}}^d) \)). Convergence \({\mathcal {W}}_{{\mathcal {P}}_2}(\mu _n ,\mu )\rightarrow 0\) holds if and only if
Proposition 6.2
(Lower semicontinuity) If the sequences \((\mu _n)_n, (\nu _n)_n\) in \(W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) are such that \(\mu _n \rightarrow _w\mu \) and \(\nu _n \rightarrow _w\nu \), then \({\mathcal {W}}_{{\mathcal {P}}_2}(\mu ,\nu )\le \liminf {\mathcal {W}}_{{\mathcal {P}}_2}(\mu _n,\nu _n)\).
Now we prove the main results concerning existence and consistency of k-barycenters.
Theorem 6.3
(Existence of k-barycenters) Let \(\mu \in W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) and, for \(k\ge 1\), define
Then \(V_k(\mu )\le V_{k-1}(\mu )\le \dots \le V_1(\mu )<\infty \) and all the inequalities are strict unless \(\mu \) is supported on less than k elements of \({\mathcal {P}}_2({\mathbb {R}}^d) \). Moreover, there exists a k-barycenter of \(\mu \), say \({\bar{\mathbf{M}}}=\{\bar{M}_1,\ldots ,\bar{M}_k\}\subset {\mathcal {P}}_2({\mathbb {R}}^d) ,\) that satisfies
Proof
From the assumption \(\mu \in W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) we see that
Let \(\{\mathbf{H}_n\}_n=(\{Q_1^n,\ldots ,Q_k^n\})_n\) be a minimizing sequence of k-sets, namely, such that
We first prove that the sequence \(\{\mathbf{H}_n\}_n\) is bounded. After a rearrangement, if necessary, we can assume that \({\mathcal {W}}_2(Q_1^n,\delta _0)\le \cdots \le {\mathcal {W}}_2(Q_k^n,\delta _0)\). Now, since \({\mathcal {W}}_2^2(\mathbf{H}_n,\delta _0)\le 2{\mathcal {W}}_2^2(\mathbf{H}_n,P) +2{\mathcal {W}}_2^2(P,\delta _{\{0\}})\) we see, integrating, that \({\mathcal {W}}_2^2(\mathbf{H}_n,\delta _0)\) is a bounded sequence, that is, \({\mathcal {W}}_2^2(Q_1^n,\delta _0)\) is bounded, and, consequently, \(\{Q_1^n\}_n\) is a tight sequence. Taking subsequences we can assume that for some \(l\in \{2,\ldots ,k\}\), \(Q_i^n\rightarrow _w Q_i\), \(i=1,\ldots ,l\), while \({\mathcal {W}}_2^2(Q_i^n,\delta _0)\rightarrow \infty \) for \(i\ge l+1\). By lower semicontinuity and Fatou’s Lemma we find that
Therefore, \(\{Q_1,\ldots ,Q_l\}\) is a l-barycenter of \(\mu \) and, for any choice of \(\{Q_{l+1},\ldots ,Q_{k}\}\), \(\{Q_1,\ldots ,Q_k\}\) is a k-barycenter of \(\mu \). If \(\mu \) is not supported on an l-set then given an l-barycenter of \(\mu \) there exists \(Q_{l+1}\) and \(r>0\) such that \({\mathcal {W}}_2(Q_i,Q_{l+1})>2r\), \(i=1,\ldots ,l\) and \(\mu (B_{{\mathcal {W}}_2}(Q_{l+1},r))>0\). But then, on the ball \(B_{{\mathcal {W}}_2}(Q_{l+1},r)\), we have \(\min _{i=1,\dots ,l+1}{\mathcal {W}}_2^2(P,Q_i)<\min _{i=1,\dots ,l}{\mathcal {W}}_2^2(P,Q_i)\) and, as a consequence \(V_{l+1}(\mu )<V_{l}(\mu )\). \(\square \)
We note at this point that for \(\mu \in W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) and \(Q\in {\mathcal {P}}_2({\mathbb {R}}^d) \),
In particular, for \(P,Q \in {\mathcal {P}}_2({\mathbb {R}}^d) \), \({\mathcal {W}}_{{\mathcal {P}}_2}(\delta _P,\delta _Q)={\mathcal {W}}_2(P,Q)\). We note also that the set of probabilities with support on the k-set \(\bar{\mathbf{Q}}=\{Q_1,\dots ,Q_k\}\), that we will denote by \({\mathbf {P}}(\bar{\mathbf{Q}})\), is a closed convex set in \(W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) and
In particular, when \({\bar{\mathbf{M}}}\) is a k-barycenter of \(\mu \), this and (25) yield the characterization
Theorem 6.4
(Consistency of k-barycenters) Let \((\mu _n)_n, \mu \) be probabilities on \(W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) such that \({\mathcal {W}}_{{\mathcal {P}}_2}(\mu _n, \mu )\rightarrow 0\). Then the k-variations of \(\mu _n\) converge, \(V_{k}(\mu _n)\rightarrow V_{k}(\mu )\). If \(\mu \) is not supported on a \((k-1)\)-set of \(W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\) and \({\bar{\mathbf{M}}}_n\) is any k-barycenter of \(\mu _n\), the sequence \(({\bar{\mathbf{M}}}_n)_n\) is sequentially compact and any limit is a k-barycenter of \(\mu \). If \(\mu \) has a unique k-barycenter, \({\bar{\mathbf{M}}}\), then \({\bar{\mathbf{M}}}_n\) converges to \({\bar{\mathbf{M}}}\) in Hausdorff distance.
Proof
If \({\bar{\mathbf{M}}_0}\) is a k-barycenter of \(\mu \), the convergence \({\mathcal {W}}_{{\mathcal {P}}_2}(\mu _n, \mu )\rightarrow 0\) implies the convergence of the distances to the closed set \({\mathbf {P}}(\bar{\mathbf{M}}_0)\), \({\mathcal {W}}^2_{{\mathcal {P}}_2}(\mu _n, {\mathbf {P}}(\bar{\mathbf{M}}_0)) \rightarrow {\mathcal {W}}^2_{{\mathcal {P}}_2}(\mu , {\mathbf {P}}(\bar{\mathbf{M}}_0))\). Hence, recall (27)
It the degenerate case of \(\mu \) supported on a \((k-1)\)-set, we know that \(V_k(\mu )=V_{k-1}(\mu )=0\) and the argument leading to (28) would give \(V_k(\mu _n)\le V_{k-1}(\mu _n)\rightarrow 0\). Therefore, let us assume that \(V_{k-1}(\mu )>0\) and denote by \(M_i^n\), \(i=1,\dots ,k\) the probabilities in \({\bar{\mathbf{M}}}_n\). Arguing as in the proof of Theorem 6.3, the assumption \({\mathcal {W}}_{{\mathcal {P}}_2}(\mu _n, \mu )\rightarrow 0\) easily leads to guarantee that the sequences \(\{M_i^n\}_n\) are tight. Therefore, any subsequence has a subsequence (for which we keep the same notation) with weakly convergent components \(M_i^n \rightarrow _wM_i\) for \(i=1,\dots ,k\). We write \({\bar{\mathbf{M}}}=\{M_1,\ldots ,M_k\}\).
On the other hand, since \(\mu _n \rightarrow _w\mu \), we can apply Skorohod’s Representation Theorem [see, e.g., Theorem 11.7.2 in Dudley (2004)], and assume that there are \(W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\)-valued random elements \(Z_n,Z\), defined on some probability space \((\Omega , \sigma , \varUpsilon )\) with laws \(\mathcal L(Z_n)=\mu _n, \mathcal L(Z)=\mu ,\) such that \(Z_n \rightarrow Z \ \varUpsilon -\)a.s. By lower semicontinuity (Proposition 6.2), this leads to
thus
From this, Fatou’s theorem, (26) and (28) we get
hence \(V_k(\mu _n) \rightarrow V_k(\mu )\) and any weak limit \({\bar{\mathbf{M}}}\) of a weakly convergent subsequence of \({\bar{\mathbf{M}}}_n\) is a k-barycenter of \(\mu \).
It only remains to show that, in fact, these weakly convergent subsequences are convergent (through subsequences) in the \({\mathcal {W}}_2\)-sense. For this, observe that inequalities in (31) are, in fact, equalities. But then (30) must be also an equality. From this, taking into account that the support of \(\mu \) is not degenerated in a \((k-1)\)-set and (29), we conclude that the sets \(\Omega _i:=\left\{ \omega : {\mathcal {W}}_2(Z(\omega ),M_i) =\liminf _{n\rightarrow \infty } {\mathcal {W}}_2(Z_n(\omega ),M_i^n)\right\} \) have positive probability, \(\varUpsilon (\Omega _i)>0, i=1,\dots ,k.\) Choose any subsequence and take \(\omega \in \Omega _i\) satisfying also \(Z_n(\omega )\rightarrow Z(\omega )\). Then there exists a new subsequence for which we additionally have \({\mathcal {W}}_2(Z_n(\omega ),M_i^n)\)\( \rightarrow {\mathcal {W}}_2(Z(\omega ),M_i)\). But then, by Lemma 14 in Le Gouic and Loubes (2017), \({\mathcal {W}}_2 (M_i^n,M_i)\rightarrow 0\). This shows that from every subsequence we can extract a further subsequence such that \(d_H({\bar{\mathbf{M}}}_n, {\bar{\mathbf{M}}})\rightarrow 0\). All the other claims follow from this fact. \(\square \)
When \(\mu _n\) are the sample distributions obtained from n realizations, \(P_1,\dots ,P_n\), of the random probability measure \(\mu \in W_2({\mathcal {P}}_2({\mathbb {R}}^d) ),\) Varadarajan’s Theorem guarantees that \(\mu _n \rightarrow _w\mu \) almost surely. Taking the probability degenerated at zero, \(\delta _{\{0\}},\) the classical Strong Law of Large Numbers applied to the i.i.d. random variables \({\mathcal {W}}_2^2(P_i, \delta _{\{0\}})\) states
hence the characterization in Theorem 6.1 of convergence in the \({\mathcal {W}}_{{\mathcal {P}}_2}\) sense, and Theorem 6.4, prove the Strong Law of Large Numbers for k-barycenters.
Theorem 6.5
Assume that \(\mu \in W_2({\mathcal {P}}_2({\mathbb {R}}^d) )\). If \(\mu _n\) is the sample probability giving mass 1 / n to the probabilities \(P_1,\ldots ,P_n\) obtained as independent realizations of \(\mu \), then \(V_k(\mu _n) \rightarrow V_k(\mu )\) a.s.. If the k-barycenter of \(\mu , {\bar{\mathbf{M}}}\), is unique and \({\bar{\mathbf{M}}}_n\) is a sample k-barycenter, then the k-barycenters are consistent, i.e., \({\bar{\mathbf{M}}}_n\rightarrow _{\text{ a.s. }}{\bar{\mathbf{M}}}\) in Hausdorff distance.
Once the existence and consistency for k-barycenters have been proved, the adaptation to cover the trimmed versions relies on the same arguments as those employed in Section 5.5 of Álvarez-Esteban et al. (2017). Therefore, we omit the proofs for Proposition 2.2 and Theorems 2.3 and 2.4. In particular it must be stressed that, in the trimmed setting, the integrability condition on the \(\mu _n\) and \(\mu \) probability measures is unnecessary. In contrast, we give the following proof because it involves a different way of looking at clustering of clusters.
Proof of Theorem 2.5
We write \(r=r(\eta )\) and note that \({{\mathcal {G}}}>2\). Since
we see that,
Let us set now \(X_{i}^j=I\{\sharp \big ({\mathbb {F}}( \mathbb {\hat{P}}_j)\cap B(N_i,r)\big )=1\}\). Observe that, for fixed i, \(X_1^1,\ldots ,X_i^{m}\) are independent Bernoulli random variables. Call \(p_i^j=\text{ Pr }(X_i^j=1)\). The balls \(B(N_i,r)\) are pairwise disjoint (recall that \({{\mathcal {G}}}>2\)) and therefore, \(\left[ \bigcup _{i=1}^k\left( {\mathbb {F}}( {\hat{P}}_j)\cap B(N_i,r)=\emptyset \right) \right] ^C \subset (X_i^j=1)\), which implies that \(p_{i}^j> 1-\frac{\alpha }{2}\). But then, if \(B_k\) denotes a binomial r.v. with parameters m and \(1-\frac{\alpha }{2},\) we see from Hoeffding’s inequality that \(\text{ Pr }\big (\sum _{j=1}^m X_i^j<m(1-\alpha ) \big )\le \text{ Pr }\big (B_k<m(1-\alpha ) \big )\le e^{-\frac{\alpha ^2 }{2}m}\). As a consequence,
From (33) we see that, with probability at least \(1-ke^{-\frac{\alpha ^2 }{2}m}\), each ball \(B(N_i,r)\) contains, at least, \(m(1-\alpha )\) sample points \(\hat{N}_i^j\) and, in particular, the number of points outside \(\cup _{i=1}^k B(N_i,r)\) is less than \(\alpha k m\). Hence, the optimal \(\alpha \)-trimmed k-variation is upper bounded by \(r^2\) (take a trimming of the empirical measure concentrated on \(\cup _{i=1}^k B(N_i,r)\) and use the \(N_i\)’s as centers). To ease notation let us write \({\mathbf {M}}={\mathbf {M}}_{n_1,\ldots ,n_m; m}\) and \(\hat{r}_\alpha \) for the associated optimal trimming radius as in Proposition 2.2. Since, by assumption, \(\alpha k m\) is an integer, we can assume that the optimal trimming function, \(\tau _\alpha \) takes values in \(\{0,1\}\). We write \(\tilde{B}({\mathbf {M}},\hat{r}_\alpha ) =\{x\in \bar{B}({\mathbf {M}},\hat{r}_\alpha ): \, \tau _\alpha (x)=1 \}\) and similarly for \(\tilde{B}(N,\hat{r}_\alpha )\) for \(N\in {\mathbf {M}}\). Now, the number of points outside \(\tilde{B}({\mathbf {M}},\hat{r}_\alpha )\) is \(\alpha k m\). Hence, each ball \(B(N_i,r)\) contains, at least, \(m(1-\frac{\delta }{k} -\alpha k)=m(1-(k+1)\alpha )\) points in \(\tilde{B}({\mathbf {M}},\hat{r}_\alpha )\). Let us focus on the ball \(B(N_1,r)\). There exists \(N\in {\mathbf {M}}\) such that \(\tilde{B}(N,\hat{r}_\alpha )\) contains at least a fraction \(\frac{1}{k}\) of the points in \(B(N_1,r)\cap \tilde{B}({\mathbf {M}},\hat{r}_\alpha )\). But then \(C:=B(N_1,r)\cap \tilde{B}(N,\hat{r}_\alpha ) \) contains at least \(\frac{m}{k} (1-(k+1)\alpha )\) points and, from Eq. (10) we conclude
and, therefore,
This, in turn, implies that \({\mathcal {W}}_2(N,N_1)\le r \frac{H}{2} \) (recall that \({{\mathcal {G}}}=2 \big (1+k\big (\frac{1-\alpha }{1-\alpha (k+1)} \big )^{1/2}\big )\)). Observe that the choice of r guarantees that the balls \(\bar{B}(N_i, r\frac{{\mathcal {G}}}{2})\) are disjoint. Since the choice of \(N_1\) was arbitrary, we conclude that for every \(i=1,\ldots ,k\) there exists \(\tilde{N}_i\in {\mathbb {M}}\) such that \(W_2(N_i,\tilde{N}_i)\le r\frac{{\mathcal {G}}}{2}\). The fact that the balls \(\bar{B}(N_i, r\frac{{\mathcal {G}}}{2})\) are disjoint ensures that \(\{\tilde{N}_1,\ldots ,\tilde{N}_k\}\) is just a relabeling of \({\mathbf {M}}\) and, as a consequence that, with probability at least \(1-k e^{-\frac{\alpha ^2}{2} m}\),
This completes the proof. \(\square \)
Next we prove that the algorithm introduced in Sect. 3 converges when applied to a finite set of absolutely continuous or to discrete (with finite support) probabilities. This will be the consequence of the following propositions.
Proposition 6.6
Let \(P_i, \ i = 0,\ldots ,n\) be probability measures in \(\mathcal{P}_2({{\mathbb {R}}}^d)\) with associated weights \(\lambda _i, \ i = 0,\ldots ,n\), with \(\sum _{i=0}^n\lambda _i=1.\) Let \(\overline{P}\) be the barycenter of \(P_i, \ i = 1,\ldots ,n\) with weights \(\lambda _i^*=\lambda _i(\sum _{i=1}^n\lambda _i)^{-1}, \ i = 1,\ldots ,n\) and \(\overline{P}_0\) be the barycenter of \(P_i, \ i = 0,\ldots ,n\). If we assume that \(\lambda _0>0 \), that \(P_0\ne \overline{P}\), and that \(\overline{P}\) is absolutely continuous, then \(\overline{P}_0 \ne \overline{P}\).
Proof
Since \(\overline{P}\) is absolutely continuous, there exist maps \(T_i: {{\mathbb {R}}}^d \rightarrow {{\mathbb {R}}}^d, i=0,\ldots , k\) pushing forward \(\overline{P}\) to \(P_i\), such that \( \mathcal{W}^2(\overline{P},P_i)= \int _{{\mathbb {R}}^d} \Vert x - T_i(x)\Vert ^2 d \overline{P}(x) . \) Moreover, by Proposition 3.3 in Álvarez-Esteban et al. (2016), it must be
On the other hand,
Since \(T_0\) is not the identity \(\overline{P}\)-a.s., and \(\lambda _0>0\), it is clear that \(\overline{P}\{T_0(x) \ne x\} >0\), and consequently [see the proof of Proposition 3.3 in Álvarez-Esteban et al. (2016)] we get:
\(\square \)
Recall that the condition \(\overline{P}\) is absolutely continuous is verified if we know that \(P_i, \ i = 1,\ldots ,n\) are absolutely continuous. Concerning the discrete case, let us retain the notation of the previous proposition and let \(\{a^i_1\ldots , a^i_{h_i}\}\) be the support of \(P_i, i=0,1,\dots ,n\). As stated in Lemma 6.7 below, \(\overline{P}\) also has a finite support, say \(\{b_1, \ldots , b_h\}\). In this case, the optimal coupling between \(\overline{P}\) and \(P_i, \ i=0,\ldots ,n\), is determined by a family of positive numbers \(p^i_{u,v} , \ u=1,\ldots , h; \ v=1,\ldots , h_i\) which satisfy
Slight modifications of the proof of Theorem 1 in Anderes et al. (2016) lead to the following lemma.
Lemma 6.7
With the notation above, we have that,
-
1.
The support of \(\overline{P}\) is finite.
-
2.
For every \(u=1,\ldots ,h\), and \(i=1,\ldots , n\), it holds: \(\# \{u: p^i_{u,v} >0 \}=1\). Moreover, if \(k_i\) denotes the only index such that \(p^i_{u,k_i} >0\), then
$$\begin{aligned} b_u = \sum _i \lambda _i^* a^i_{k_i}, \ \text{ and } P_i[a^i_{k_i}] \ge \overline{P}[b_u]. \end{aligned}$$ -
3.
There exist maps \(T_i: {{\mathbb {R}}}^d \rightarrow {{\mathbb {R}}}^d\) such that, if the distribution of X is \(\overline{P}\), then the distribution of \(T_i(X)\) is \(P_i\) and \( \mathcal{W}^2(\overline{P},P_i)= \int _{{\mathbb {R}}^d} \Vert x - T_i(x)\Vert ^2 d \overline{P}(x) . \)
Item 3 in Lemma 6.7 allows to repeat the proof of Proposition 6.6 to obtain:
Proposition 6.8
Assume the same notation as in the previous proposition, and let \(P_i, \ i = 0,\ldots ,n\) be probability measures with finite support. If \(\lambda _0>0 \) and \(P_0\ne \overline{P}\), then \( \overline{P}_0 \ne \overline{P}\).
Proof of Theorem 3.1
Notice that Step 4 in the algorithm provides a partition of the set \(\{1,\ldots , n\}\) in the finite family of subsets
Thus, \(T^s\) contains the indices of the probabilities which are completely trimmed and \(R_j^s \) those of the probabilities which are not trimmed and are associated with group j. After this, at most one index \(i_q\) remains. In such a case, it belongs to one of the sets \(Q_j^s\), while the remaining sets are empty. Moreover, once the two sets \(\cup _j R_j^s\) and \(T^s\) have been fixed, the value of \(\lambda _{i_q}^s\) is also fixed, and, then, only the index \(g_{i_q}^s\) can vary. Thus, Step 4 only has a finite number of possibilities. Therefore, if we show that each time we run steps 2 and 3 the value of the objective function strictly decreases, the result will be proved because this implies that we cannot visit twice the same solution. But this is trivial because, if the probabilities are absolutely continuous, then Proposition 6.6 implies that if the stopping condition is not fulfilled, then at least a barycenter \(P_j^{s+1}\) will vary and we will have a reduction of the objective function. The same happens using Proposition 6.8 if the supports of the probabilities are finite.
Rights and permissions
About this article

Cite this article
del Barrio, E., Cuesta-Albertos, J.A., Matrán, C. et al. Robust clustering tools based on optimal transportation. Stat Comput 29, 139–160 (2019). https://doi.org/10.1007/s11222-018-9800-z
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11222-018-9800-z
Keywords
- Cluster prototypes
- k-barycenter
- Trimmed barycenter
- Robust aggregation
- Wasserstein distance
- Monge–Kantorovich problem
- Transport maps
- Trimmed distributions
- Parallelized inference
- Bragging
- Subragging
- Trimmed k-means algorithm