
Abstract
In this paper we present extensions to the original adaptive Parallel Tempering algorithm. Two different approaches are presented. In the first one we introduce state-dependent strategies using current information to perform a swap step. It encompasses a wide family of potential moves including the standard one and Equi-Energy type move, without any loss in tractability. In the second one, we introduce online trimming of the number of temperatures. Numerical experiments demonstrate the effectiveness of the proposed method.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
Markov chain Monte Carlo (MCMC) is a generic method to approximate an integral of the form
where \(\pi \) is a probability density function, which can be evaluated point-wise up to a normalising constant. Such an integral occurs frequently when computing Bayesian posterior expectations (Robert and Casella 1999; Gilks et al. 1998).
The random walk Metropolis algorithm (Metropolis et al. 1953) often works well, provided the target density \(\pi \) is, roughly speaking, sufficiently close to unimodal. The efficiency of the Metropolis algorithm can be optimised by a suitable choice of proposal distribution. These, in turn, can be chosen automatically by several adaptive MCMC algorithms; see Haario et al. (2001), Atchadé and Rosenthal (2005), Roberts and Rosenthal (2009), Andrieu and Thoms (2008) and references therein.
When \(\pi \) has multiple well-separated modes, the random walk-based methods tend to stuck in a single mode for long periods of time. It can lead to false convergence and severely erroneous results. Using a tailored Metropolis-Hastings algorithm can help, but, in many cases, finding a good proposal distribution is not easy. Tempering of \(\pi \), that is, considering auxiliary distributions with density proportional to \(\pi ^\beta \) with \(\beta \in (0,1)\), often provides better mixing between modes (Swendsen and Wang 1986; Marinari and Parisi 1992; Hansmann 1997; Woodard et al. 2009; Neal 1996).
We focus here particularly on the parallel tempering algorithm, which is also known as the replica exchange Monte Carlo and the Metropolis-coupled Markov chain Monte Carlo.
The tempering approach is particularly tempting in such settings where \(\pi \) admits a physical interpretation, and there is good intuition how to choose the temperature schedule for the algorithm.
In general, choosing the temperature schedule is a non-trivial task, but there are generic guidelines for temperature selection based on both empirical findings and theoretical analysis (Kofke 2002; Kone and Kofke 2005; Atchadé et al. 2011; Roberts and Rosenthal 2012). These theoretical findings were used to derive adaptive version of the Parallel Tempering (Miasojedow et al. 2013a). Another approach to temperature tuning can be found in (Behrens et al. 2012). This approach offers a different criterion for choosing temperature schedule and is developed for the Tempered Transitions algorithm (Neal 1996).
In the present paper we consider the adaptive version of the Parallel Tempering algorithm. The adaption consists in introducing state-dependent swaps between differently tempered random walks. We study the impact of different distributions on potential steps and call them Strategies. Our choice of strategies is driven by solutions already known to the literature (Kou et al. 2006) and used within Parallel Tempering algorithm by Baragatti et al. (2013). The novelty of our approach stems from an alternative implementation of Equi Energy moves that renders the algorithm parameters free, i.e. the user does not need to provide precise Energy Rings any more. We also investigate different modifications of this new approach.
We also propose an automated method for reducing the actual number of considered temperatures, in the spirit of Miasojedow et al. (2013a). The temperature adaptation scheme depends on the parameters of the adaptive random walks applied in the parallelised Metropolis-Hastings stage of the algorithm in case when the state space amounts to be the usual \({\mathbb {R}}^d\).
We have also showed that the proposed algorithm satisfies the Law of Large numbers, in the same setting as in Miasojedow et al. (2013a).
2 Definition and notations
Our basic object of interest is the density \(\pi : \varOmega \mapsto {\mathbb {R}}_+\), where \(\varOmega = {\mathbb {R}}^d\). We assume we can evaluate point-wise a function that is proportional to \(\pi \) by some constant. The Parallel Tempering approach suggests to construct a Markov chain on the product space \(\varOmega ^L\), where L is the number of temperature levels. On that space a new density \(\pi ^\beta \) is constructed by posing for \({ x}\in \varOmega ^L\)
so that \({ x}_i \in \varOmega \), \(\beta = \big ( \beta _1, \beta _2, \ldots , \beta _L\big )\) are the inverse temperatures subject to \(1 = \beta _1 > \beta _2 > \cdots > \beta _L\).
Vector \(T = (T_1, \dots , T_L)\), where \( T_\ell = \beta _\ell ^{-1}\), contains numbers known as temperatures and is itself referred to as the temperature scheme.
Density \(\pi ^\beta \) is known up to proportionality factor and by marginalising it w.r. to the first coordinate we retrieve the original distribution \(\pi \).
Markov chain \(X = \{ X^{[k]}\}_{k\ge 0}\) targets \(\pi ^\beta \) and can be thought of as L coordinate chains, \(X^{[k]} = \big ( X^{[k]}_1, \ldots , X^{[k]}_L\big )\). First coordinate chain will be referred to as the base (temperature) chain.
The main idea behind Parallel Tempering is to interweave random walk steps with random swaps between chains. Each random swap exchanges results of a random walk step from two coordinate chains. Chains corresponding to higher temperaturesFootnote 1 should, in principle, be more volatile and travel between different modes more easily than chains linked to lower temperatures. For if \({ x}\) is the last visited place by the \(l\text {th}\) chain, and \({ y}\) is a proposal drawn from a region where the density assumes smaller values, \(\pi ( { y}) < \pi ( { x})\), then the probability of accepting such proposal, that we call \(\eta _\ell \), is higher on the more tempered chainFootnote 2
Therefore, the more exchanges of higher tempered chains with the base chain, the bigger the chance of getting out from a local probability cluster where a simple Markov chain would stuck.
The generation of Markov chain X proceeds by repeated application of two kernels, \({\mathcal {M}}\) and \({\mathcal {S}}\), on state space points,
The random walk kernel \({\mathcal {M}}\) is defined on the product sigma algebra generator by
where
and corresponds to independently performing random walk on different chains.
Let \(T_{{ ij}}\) denote the transposition of coordinate i and j of a state space point x,
Then the proposal measure for the random swap is discrete, potentially state-dependent, and given by
where one is free to choose the precise relation between \(p_{{ ij}}\) and \({ x}\), so as to establish the probability of carrying out the transposition.
The transition kernel of the swap step is defined simply by
The precise form of the acceptance probabilities will be presented in the next section.
3 State-dependent swap strategies
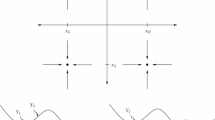
In standard Parallel Tempering algorithm the proposal of swap step is drawn from distribution independent of the current state of process. Usual choice amounts to a uniform draw from all possible pairs of temperatures or only from pairs of adjacent temperatures. However, even in trivial 1D examples one notices that swap probabilities depend on current positioning of chains, cf. Fig. 1. Our studies on swap strategies that depend on the current state are motivated by a seminal paper on Equi-Energy sampler by Kou et al. (2006), further adopted to Parallel Tempering algorithm by Baragatti et al. (2013).

Swap probabilities dependent on current state. Swap probabilities for two chains targeting standard Gaussian distribution. On both axis we plot points from the same state space, the x axis corresponding to inverse temperature 1/10 and y axis corresponding to base temperature
The main idea behind these algorithms is to exchange states with similar energy (i.e. value of log-density). The original Equi-Energy sampler is greedy in memory usage: it must store all points drawn from differently tempered trajectories. This might become problematic in high-dimensional settings. Equi Energy also targets a biased distribution instead of the proper one due to the use of asymptotic values in acceptance probability. Running this algorithm also requires specifying in advance the so called Energy Rings, i.e. the partition of the state space into regions with similar energy. Schreck et al. (2013) address the problem of choosing the Energy Rings and provide an adaptive version of the algorithm.
The Parallel Tempering algorithm with Equi-Energy moves (PTEE), proposed by Baragatti et al. (2013), also requires specification of the Energy Rings. In order to circumvent this hindrance we propose using state-dependent swap strategies that perform Equi-Energy-like moves within the Parallel Tempering algorithm framework. Our approach is flexible and might use different strategies, e.g. promoting larger jumps or other features.
The general algorithm is as follows: given the state of process \({ x}= ( { x}_1, \ldots , { x}_L )\) after the random walk phase, we propose at random a transpositionFootnote 3 \(T_{{ ij}}( { x})\) from a state-dependent discrete distribution with probabilities \(p_{{ ij}}({ x})\) defined on a discrete simplex of indices, \(i<j\).
To assure reversibility, the swap acceptance probability should be defined by
The definition of acceptance probability (3) assures that kernel \({\mathcal {S}}\) is reversible with respect to \(\varvec{\pi }\).
Proposition 1
Kernel \({\mathcal {S}}\) defined by (2) is reversible with respect to \(\varvec{\pi }( { x}) \propto \pi ({ x}_1)^{ \beta _1 } \times \cdots \times \pi ( { x}_L )^{\beta _L} \).
Proof
We need to show that for all \({ A}, { B}\in \varvec{\mathfrak {F}}\) we have
For all \(i<j\) let us define
It is enough to verify that for every \(i<j\)
For any arbitrary chosen \(i<j\) define a measure \(\mu \) on \({\mathbb {R}}^{2dL}\) as follows: for \({ A}, { B}\in \varvec{\mathfrak {F}}\) let
where \(\lambda _\text {Leb}\) denotes the Lebesgue measure on \({\mathbb {R}}^{dL}\).
Since \(T_{{ ij}}\big ( T_{{ ij}}( { x}) \big ) = { x}\), by symmetry of Lebesgue measure we get
and by definition of \({\mathcal {S}}_{{ ij}}\) we obtain
Now, using (3) we find that
and setting \({ y}=T_{{ ij}}({ x})\) to (5) and applying (4) we get
which completes the proof. \(\square \)
Remark 1
Thanks to the definition of kernel \({\mathcal {S}}\), for any positive measurable function \(F:{\mathbb {R}}^{Ld}\rightarrow {\mathbb {R}}^+\) invariant by permutation we get \({\mathcal {S}}F({ x}) = F({ x})\) which, under some regularity conditions (Miasojedow et al. 2013a), implies that Parallel Tempering algorithm with state-dependent swap steps is geometrically ergodic. For under the same set of assumptions Theorem 1 precised in the above-mentioned œuvre holds with state-dependent swap steps.
To pursue Equi-Energy-type moves without a need to fine-tune some additional parameters, e.g. precising the Energy Rings, we propose to set the swap probabilities as follows: for \(i<j\) let
The normalising constant is equal \(\sum _{i<j}p_{{ ij}}({ x})\), so it does not depend upon permutation of \({ x}\). Hence \(p_{{ ij}}({ x})=p_{{ ij}}\big (T_{{ ij}}({ x})\big )\) and the acceptance probability simplifies to that of the standard Parallel Tempering algorithm,
In comparison to standard PT, the state-dependent swaps’ version promotes acceptance of states that are closer, i.e. the difference between their energy levels being small, enlarging the probability that such a swap is accepted. This leads to an increased number of accepted global moves in the algorithm. The simulations’ results, presented below, confirm this improvement.
Other possible strategies commonly used in the literature include uniform random choice of swap from the set of all possible pairs, i.e. \( p_{{ ij}}= \left( {\begin{array}{c}L\\ 2\end{array}}\right) ^{-1}\), or swapping at random only the adjacent temperature levels, i.e. \(p_{{ ij}}= (L-1)^{-1} \varvec{1}_{\{i=j-1\}}\). We shall refer to these strategies as RA and AL, respectively.
Remark 2
Note that the already mentioned PTEE algorithm can be considered a special case of state-dependent swap step. Let \(H_1,\ldots ,H_m\) be the Energy Rings. Denote by \(H_x\) the set \(H_i\) where x belongs to. Letting \(p_{{ ij}}({ x}) \propto \mathbf {1}_{\{ { x}_j \in H_{{ x}_i} \}}\) we note that the swap acceptance probability is reduced to (7). In the end we obtain an algorithm proposed by Baragatti et al. (2013).
Therefore, the theoretical results presented here can be directly applied to PTEEM. In particular, we note that it is geometrically ergodic under the same regularity condition and so both the convergence result and the law of large numbers for PTEEM with adaptive Metropolis step at each level can be readily obtained.
4 Reducing number of temperature levels
The choice of parameters, i.e. the schedule of temperatures and parameters of random walk Metropolis at each level, is crucial for the performance of the PT algorithm. This becomes apparent especially when temperatures are devoid of any direct physical interpretation.
In a recent paper Miasojedow et al. (2013a) have proposed an adaptive scheme to tune both temperature schedule and proposal distributions of the random walk steps at each temperature level. The above-mentioned algorithm still requires user-provided number of temperature levels and usually some pilot runs of the algorithm are necessary to determine their number.
In this section a simple criterion is presented for probing whether the algorithm has attained the correct number of temperature levels during its run time. An incorrect temperature schedule leads to unsatisfactory estimation results: underestimating the number of temperature levels might lead the most-tempered chain to explore a distribution that is still multimodal, contradicting the whole idea of parallel tempering. On the other hand, also overestimating the number of levels might lead to inefficiencies. For instance, the waiting time for swaps between ground level chain and its more tempered counterparts should in general increase with the overall number of temperatures: simply the state space of possible swaps grows larger and some of the probability previously assigned to the swaps with the base chain might have to be redistributed among other types of swaps. It also suggest that it would make sense to set the maximal temperature to the smallest possible level that makes the target distribution approximately unimodal. Note also that if more swaps occur only between the tempered levels, then the problem of poor mixing at the ground level is not really being solved.
There are several possible solutions to the above-mentioned problems, contingent upon our knowledge on \(\pi \). If the number of modes is known in advance, one could simply observe the created trajectories and consider additional temperature levels whenever the algorithm did not arrive at finding some modes. Trimming the temperature schedule could also be arranged if the distribution was known to be unimodal at more than one level. In general, the number of modes is unknown and such procedures would not be feasible, and the only safe solution remaining is to overestimate the number of levels and adaptively decrease it. That is precisely the approach we follow. In practice this leaves still one parameter to be provided by the user—the initial number of temperatures. In the supplementary materials we introduce a toy example to show that one cannot safely base the inference on the number of modes based on visual inspection of lower dimensional projections of the sampled points alone.
It is easy to construct toy problems with the temperatures extending over too limited a range. In such cases the Parallel Tempering algorithm would not find other modes except the one where it was initialized. In such cases nearly all criteria to test the target multimodality would fail. To decide that on some level target distribution is unimodal or not we will use comparison of covariance matrices of proposal of random walk and of target.
A well-known result (Roberts et al. 1997) on the optimal scaling of the random walk Metropolis for i.i.d targets, i.e. with density \(\pi (x) = \prod f(x_i)\), states that the optimal choice of the proposal covariance should amount to \({2.38^2}/{I\,d}\), where \(I = \int \Big [{\partial }/{\partial x} \log f(x)\Big ]^2 f(x) \mathrm{{d}}x\). This corresponds to stationary acceptance probability equal to 0.234. In general, by linear transformation, we can approximate the optimal choice of covariance by \({2.38^2}/{I\,d}\varSigma \), with \(\varSigma \) corresponding to the covariance of the stationary distribution \(\pi \), which is optimal in the Gaussian case. There are two popular adaptive schemes developed that try to approximate this optimal choice.
The first one amounts to estimating online the stationary covariance by \(\varSigma ^{[n]}\) followed by subsequent proposal with a covariance \({2.38^2}/{d}\varSigma ^{[n]}\) (Haario et al. 2001). A standard way to define \(\varSigma ^{[n]}\) follows a two step procedureFootnote 4:
-
Get the estimator of the target’s mean by
$$\begin{aligned} \mu ^{[n]} = \left( 1 - \gamma ^{[n]}\right) \mu ^{[n-1]} + \gamma ^{[n]} X^{[n-1]}. \end{aligned}$$(8) -
Get the estimator of the target’s covariance matrix
$$\begin{aligned} \varSigma ^{[n]}= & {} \left( 1 - \gamma ^{[n]}\right) \varSigma ^{[n-1]} \nonumber \\&+\, \, \gamma ^{[n]} \left( X^{[n-1]} - \mu ^{[n]}\right) \left( X^{[n-1]} - \mu ^{[n]}\right) ^\text {t}. \end{aligned}$$(9)
In (8) and (9) \(\gamma ^{[n]}\) denotes a deterministic step-sizeFootnote 5.
The second one is to use proposal with covariance of the form \(\exp (2\theta ^{[n]})\varSigma ^{[n]}\) , where \(\theta ^{[n]}\) is adjusted in order to get 0.234 acceptance rate (Andrieu and Thoms 2008; Roberts and Rosenthal 2009) by the following a Robbins–Monro type procedure
where \(\eta ^{[n-1]}\) denotes the acceptance probability of the random walk phase.
In case of unimodal distribution both approaches are approximately equivalent. In the multimodal case it is obvious that \(\exp (2\theta ^{[n]})\) will be significantly lower than \({2.38^2}/{d}\). It is motivated by the need to shrink the covariance of proposal so that it mimics the covariance of the target distribution truncated to current mode, i.e. where the chain currently is at.
In our algorithm, we initialize the algorithm with potentially too many temperature levels and consequently reduce their number. We run the Adaptive Parallel Tempering algorithm Miasojedow et al. (2013a), described in details in the next section. After initial burn-in period needed for stabilisation of the parameters of the algorithm we start to reduce the number of temperature levels L letting
if the condition is satisfied for at least one \(\ell \), and leaving the number of temperatures constant otherwise, i.e. \(L^{[n]} = L^{[n-1]}\).
The functioning of this procedure is visualised in Fig. 2. It shows above all that the criterion function consistently points to the same number of needed temperature levels independently of their initial number. The criterion choice also agrees with the intuitive notion of visual unimodality, as attained by the more tempered distributions as seen in Fig. 5.

Reducing the number of temperatures using the criterion function. The plot shows values of the criterion function, \(\exp (\theta ^{[n]}_\ell ) \sqrt{2}\), as a function of the index of a tempered chain, \(\ell \). Four different set-ups are considered, with 3, 5, 10, and 50 initial temperatures, respectively. Independently of the number of initial temperatures, the criterion function suggests cutting off all the chains above the dashed line fixed at 2.38 reducing the overall number of chains to only three. The above example was calculated for \(n = 2500\) steps, for a 2D Gaussian mixtures model, cf. Sect. 6 on the numerical experiments
Remark 3
A similar criterion to that presented in (11) uses a different threshold, namely
The above condition is more lenient than the one presented in (11), still being optimal when applied to the Gaussian target. In general \({2.38^2}/{d}\varSigma \) might be more conservative that the optimal scaling, equal to \({2.38^2}/{I\,d}\), in case of a target density in product form, where I denotes the Fisher information matrix of the shift parameter (Roberts et al. 1997). This stems from the Rao-Crammer lower bound, \(I^{-1}~\le ~\varSigma \).
There are other ways of handling the problem of adjusting the number of temperatures that are out of the scope of this paper. One of them is to detect unimodality by ocular inspection of the plots of samples. However, in high-dimensional setting, such a procedure can be misleading due to the need of using some sort of projections. Another method would involve adaptively adding and subtracting temperature levels from the schedule. However, in such a procedure, one would have to ensure that all important parts of the state space were explored. This could be achieved by fixing only the maximal temperature at some value. In contrast to our solution, such scheme cannot be easily be implemented inside the Adaptive Parallel Tempering algorithm.
5 Algorithm
We shall now pass to a detailed description of our algorithm.
In the beginning we choose the initial positioning of all the chains arbitrary. We then apply iteratively the basic step of the Adaptive Parallel Tempering as described in Algorithm 1. Each step depends on the outputs of the previous step through the positioning of chains in the state space, current estimator of the target covariance matrix and target expected value, the covariance scaling factor, and the details of the temperature scheme such as precise values of temperatures and their overall number. Also, a sequence of descending numbers \(\gamma ^{[n]}\) is being used.
The basic step consists of five phases.
In the first phase a simple random walk is carried out independently on every chain. The proposal for next step is drawn from the multivariate normal distribution with the input covariance matrix scaled by the \(\exp (2\theta ^{[n]})\). The proposals are being accepted or rejected following the standard procedure assuring the reversibility of the corresponding kernel.
In the second phase we perform random walk adaptation scheme. It consists in updating estimates of both the expected value and the covariance matrix of the target distribution. Also the proposal covariance scaling factor is being updated so that to make it dependent of the distance between the proposal acceptance calculated in the random walk phase and the theoretical optimal probability of acceptance, mentioned in Sect. 4. Every update is done using a sequence of weights \(\gamma ^{[n+1]}\) constructed so as to give less and less attention to the sampled values while the algorithm proceeds. It is also worth mentioning that no explicit calculations are done using full covariance matrices. Instead, we operate on their Cholesky decomposition and update them using the so called rank-one update, whose cost is quadratic with matrix dimension. Also, it is easier to draw the proposal in the Random Walk Phase having the covariance matrix already decomposed.
In the third phase random swaps between different chains are being performed according the rules described in Sect. 3.
In the fourth phase the temperature scheme gets adapted. It is being done so as to have the ratio of differences between adjacent temperatures reflect the difference between the last steps probability of accepting the swap between the two levels and the theoretical value of 0.234, suggested by Kone and Kofke (2005), Atchadé et al. (2011). The above-mentioned probability is calculated as if the swaps were drawn uniformly from the set of only neighbouring temperature levels alone. The rationale behind using the artificial acceptance rates stems from our requirement to make that decision independent of the number of temperature levels. In particular, the EE strategy is dependent upon the number of temperature levels (see Sect. 6).
In the fifth phase we adapt the number of temperatures by cutting all the temperature levels with their corresponding square-root of the variance scaling factor being larger than the value of the optimal covariance of the proposal kernel.

We now pass to questions regarding the theoretical underpinnings of the algorithm described above. The stability issues regarding parameters \(\varSigma ^{[n]}\), \(\beta ^{[n]}\) and \(\mu ^{[n]}\) are hard to analyse in general; thus, we proceed with examination thereof while restricting ourselves to the case where projections of parameters can be found altogether on some compact space. The precise description of the above-mentioned projections can be found in (Miasojedow et al. 2013a).
To obtain the Law of Large Numbers we need to replace Lemma 20 derived by Miasojedow et al. (2013b) by an analogous one covering other swap strategies.
Lemma 1
If swap strategy satisfies \(p_{{ ij}}(x)=p_{{ ij}}(T_{{ ij}}(x))\) for all x and all \(i<j\), and \(p_{{ ij}}\) is Lipschitz continuous as a function of inverse temperatures \(\beta \). Then kernel S is Lipschitz continuous in the V-norm with respect to the inverse temperature \(\beta \).
Proof
We explicitly denote dependence upon \(\beta \), e.g. \(S_\beta \), \(\alpha _{{ ij}}(x,\beta )\) and \(p_{{ ij}}(x,\beta )\). By definition of kernel \(S_\beta \) for any measurable function g and any \(\beta ,\beta '\) we have
where \(\bar{g}_{ij}(x)=\max \{|g(x)|,|g(T_{{ ij}})(x)|\}\). Since \(p_{{ ij}}(x,\beta )\le 1\) and \(\alpha _{{ ij}}(x,\beta )\le 1\), by triangle inequality we get
Terms whit differences of \(p_{{ ij}}\) are Lipshitz by assumption. Lipshitz-ness of \(\alpha _{{ ij}}\) terms can be obtained using the same arguments as in proof of Lemma 20 by Miasojedow et al. (2013b). \(\square \)
Theorem 1
Under assumptions of Lemma 1 and regularity conditions as in Theorem 5 of (Miasojedow et al. 2013a), for any function f such that \(\sup _x |f(x)\pi (x)^\tau |<\infty \), where \(\tau <\frac{\beta _{\text {min}}}{2}\) with \(\beta _{\text {min}}\) being the lower bound of the compact set of allowed temperatures, it is true that
where \(X_1^{[n]}\) is a first component of APT algorithm with fixed number of the temperatures levels.
Proof
The proof can be carried out using the same arguments as the one to Theorem 5 of (Miasojedow et al. 2013a), with only one minor modification consisting in explicit use of the Lipschitz continuity of swap kernel given by Lemma 1.
Remark 4
It is true that the number of temperatures is a non-increasing function of the iteration and hence almost every trajectory has asymptotically a constant number of levels. This fact suggests that the LLN might be satisfied with adaptation of the temperatures number.
6 Numerical experiments
We have carried out computer simulations to test the functioning of our algorithms. In this section we propose two case studies of application of our algorithms together with a deepened analysis or the results obtained with them. Both of the provided examples are inherently multimodal.
Our first object of interest was testing the efficiency of our algorithm on an example with a controlled number of modes. An adequate toy example used in literature as benchmark for testing MCMC algorithms comes from the article of Liang and Wong (2001). There, a mixture of 20 normal peaks with equal weights is being considered. The variances of these modes are small enough to keep the spikes well separated, as might be inspected in (Fig 3).

Twenty Gaussian Peaks Toy Example. Observe that some peaks form more dense probability clusters that are still separated by large bands of almost zero probability regions
We have performed simulations (500 runs) to check the quality of the algorithms. Since the actual first and second moments of this distribution are readily obtainable by direct calculation, we could evaluate the Root Mean Square Error of the moments estimators, as gathered in Table 1, and compare ratios thereof while using different swap strategies, see Table 3. Every simulation consisted of 2500 iterations of burn-in followed by 5000 steps of the main algorithm.
We have also modified the upper-mentioned example by considering the product of that distribution with six independent standard gaussian distributions. The final distribution is composed therefore of 20 peaks that are being stretched to additional dimensions. The purpose of that experiment was to test how our algorithms cope with the difficulty of exploring a highly multidimensional space. Results of numerical experiments (100 runs) are contained in Table 4. Each run was preliminated by 5000 steps of burn-in, followed by 10,000 steps of the proper algorithm.
To see how an exemplary trajectory manages its search for probability modes confront Figs. 4 and 5. It can be clearly seen that not at all temperature levels can the algorithm easily travel between different modes.

Twenty Gaussian Peaks 2D Simulation. Here we plot one individual trajectory. Each subplot represents the natural projection of that trajectory on the state space containing the original multimodal distributions and their transforms. The simulation lasted 7500 iterations, preceded by 2500 iterations of burn-in. The criterion for temperature scheme reduction was not set on until the burn-in period has finished. When turned on, it reduced the problem to three levels out of original four

Twenty Gaussian Cylinders 8D Simulation. Here we plot one individual trajectory. Each subplot represents the natural projection of that trajectory on the state space containing the original multimodal distributions and their transforms. The simulation lasted 15,000 iterations, preceded by 5000 iterations of burn-in. The criterion for temperature scheme reduction was not set on until the burn-in period has finished. When turned on, it reduced the temperature scheme usually to four or five levels. When the criterion has been turned on after 7500 iterations, it indicated always that one should consider five levels
It was of interest to us how well do the algorithms perform when dealing with the inherent multimodality of the upper-mentioned problems. In case of both 2D and 8D Gaussian mixtures mentioned above we do know the number of modes a priori and checking whether an algorithm managed to explore a particular mode could be dealt with use of clustering of the state space into regions representing particular modes. Tables 2 and 4 do present the efficiency of estimates as measured by the expected number missed modes during one run of the algorithm and also the frequency of case when the algorithms do not miss any mode.
We have run the algorithms in two modes. In first mode we have neglected temperature scheme reduction (but maintained the temperature adaptation as such). These simulations were carried out to provide insight into how the initial number of temperatures affects different strategies results. The results for the 2D toy example are gathered in Tables 2 and 3. It can be generally observed that the Equi-Energy (EE) strategy outperforms the state-independent swap strategies, the difference getting bigger with more temperature levels being taken into account. Clearly this can be attributed to the fact that a state-dependent swap is more immune to the quadratic growth in the number of possible swaps: choosing a swap uniformly from all potential swaps renders exchanges between the base level and other levels less likely in overall. On the other hand, choosing only adjacent levels (AL) seems to be only slightly worse.
Figures 6 and 7 show how the Root Mean Square Error decays while the algorithm proceeds. One can note that only in the higher dimensional setting the difference between strategies becomes manifest, to the advantage of the Equi-Energy strategy.

Root Mean Square Error as a function of simulation length. Root Mean Square Error of estimates of the first two moments of two-dimensional Gaussian mixtures target for different strategies: Equi-Energy type moves (EE), swapping only two adjacent levels (AL) and swapping between all levels at random (RA)

Root Mean Square Error as a function of simulation length. Root Mean Square Error of estimates of the first two moments of eight dimensional Gaussian mixtures target for different strategies: Equi-Energy type moves (EE), swapping only two adjacent levels (AL) and swapping between all levels at random (RA)
We have therefore tumbled upon an important rationale for temperature scheme adaptation as such: if the probability of proposed swaps is not concentrated on a relatively small subset, then it is less likely for the algorithm to convey information about a new mode discovery to the base chain. Observe however, that one cannot a priori underestimate the proper number of temperatures; for in such case the tempered chains could be still exploring poorly separated probability modes of the transformed target distribution. For instance, in Fig. 8 one can explicitly see that there is a huge difference between the errors in first two moments estimates for the 8D toy example when one uses 3 temperature levels instead of 4 or more. Similarly, in Table 2 one notices that AL and RA strategies do perform worse with more temperature levels considered, for on average the number of modes that they miss slightly grows. It is completely different in case of the state-dependent EE strategy that works actually better with the growing number of temperatures. The supremacy of this state-dependent strategy can be clearly seen in Table 3 that presents direct comparison of the Root Mean Square Errors of other strategies when compared to that of the EE strategy. Tables 4 and 5 show similar results for the 8D toy example.

Root mean square error of estimators of first and second moments. Calculated for 8D Gaussian mixtures target for different number of temperatures with Equi-Energy type swap strategy at different temperature levels. Apparently there exists a threshold value of the initial number of temperatures that renders the estimates much more accurate. Not knowing it a priori, we are bound to overshot the true value to obtain high quality estimates. This is also a rationale behind any automated temperature reduction algorithm
Table 6 shows also another interesting phenomenon: the overall percentage of accepted swaps grows with the number of temperature levels when applying the EE strategy. It suggests that the algorithm performs well in finding points in the state space with similar probabilities. It also suggests that that truly the temperature adaptation procedure should not be using the original probabilities of acceptances but some other quantities independent of the number of initial temperatures. This provides a rationale for our choice of probabilities that would result from application of any swap proposal kernel that is symmetric (see the description of the fourth phase of the algorithm in Sect. 5).
The general message from the above analysis is clearly that there exists a threshold number of temperature levels that significantly ameliorates the Parallel Tempering algorithm’s performance and that the state-dependent strategy might partially solve problems resulting in unlikely swaps with the base level chain. We shall now describe the second phase of our numerical experiments with the toy examples, namely the verification of how well does our temperature scheme reduction criterion works in practice.
To this end we have carried out yet another series of experiments (100 runs). In the 2D toy example (7500 steps, out of which 2500 burn-in) the ultimate number of temperature levels in every simulation reached three, cf. Fig. 2. In the 8D example the result depended on the burn-in period: if out of 15,000 steps the burn-in amounted to 7500 then the algorithm always reached five levels of temperatures. When given a shorter burn-in period in \(85~\%\) of cases, it reached five levels, otherwise descending even to four. It seems therefore that the algorithm approaches levels that could have been intuitively chosen and, what is important, in a more conservative way: it simply at worse slightly overestimates the actual level that might have been chosen by visual inspection of the “scree plots” such as the ones depicted in Fig. 8.
To show that the algorithms developed in this article can be of use in applications, we have tested them on the problem of the estimation of linear model coefficients. The formulation of the problem comes from Park and Casella (2008) and is known in the literature under the name of Bayesian Bridge regression. It consists in performing Bayesian inference on the parameters of a standard linear model
where one postulates that \(\varvec{\epsilon } \sim \mathcal {N}(\varvec{0}_n, \varSigma )\), resulting in
and additionally one poses a shrinkage prior on the \(\varvec{\beta }\) coefficients
Here, p is the number of different features gathered in the data set X, and n is the overall number of sample points. Finally, one poses a scale invariant prior on the model variance \(\sigma \sim \pi ( \sigma ) = {1}/{\sigma ^2}\). There is an explicit relation between the maximum a posteriori estimate of parameters in the above-mentioned model and the solution to the problem of coefficients estimates provided by the Lasso algorithm (Tibshirani 1996). The a priori independence of the \(\varvec{\beta }\) from \(\sigma ^2\) might render the \(\varvec{\beta }\) a posteriori distribution multimodal, as in the case studied herein—following Park and Casella (2008) we have run the algorithms on the diabetes dataset taken from Efron et al. (2004).
In this example the starting point for the algorithms (namely - a pair \((\varvec{\beta }^{[0]}, \sigma ^{[0]})\)) was set to be a simple OLS estimate for the coefficients \(\hat{\varvec{\beta }}\) together with the resulting mean residual sum of squares being a proxy for real variance, \(\hat{\sigma }\). We have carried out one hundred simulations each consisting of 20,000 iterations of burn-in and 100,000 iterations of the actual algorithm, for different initial number of temperatures. The results of our simulations are represented in Table 7. While performing the simulations it was observed that a simple random walk could not leave the neighbourhood of \(\varvec{0}_n\) even though most of the probability mass lays elsewhere, as can be investigated from the plot for the first temperature level (\(L = 1\)) in Fig. 9.

Posterior distribution of coefficients in bridge regression. Above, projections of one simulated chain on the subspace spanned by two parameters in the Bayesian Lasso model. Visual inspection of base temperature (\(L=1\)) reveals the inherent multimodality of the a posteriori distribution. The simulations were performed on nine different temperature levels. One notices visually that at temperature ranging from the 6th and 7th level the modes are not easily recognisable, which implies that the corresponding chains no longer experience local behaviour. Also our criterion (verified every 1000 steps of the algorithm) did cut off levels higher than 7
Results on the final number of reached temperatures are gathered in Fig. 10 and demonstrate that its inclusion in the algorithm gives rather conservative results in terms of temperature levels reduction, which might be considered safe an option. The simple swapping levels at random strategy often chooses a number of temperature levels lower than other strategies. This can be explained by its tendency to get trapped in the mode with the highest probability mass, as can deduced from Table 7: the estimate of \(\beta _9\) is closer to 0 for that strategy.

Distribution of ultimate number of temperature levels in the Bayesian Bridge regression. The above plot counts how many times different numbers of temperature were reached when using the temperature number adaptation and different swap strategies: Equi-Energy type moves (EE), swapping only two adjacent levels (AL), and swapping between all levels at random (RA). The simulations lasted 100K iterations, preceded with 20K steps of burn-in. It is interesting to observe that the EE strategy never reached a number smaller than six and usually promoted a conservative choice of eight levels of temperature. Confront that with Fig. 6
7 Conclusions
In this article it was demonstrated that the Parallel Tempering algorithm’s efficiency is highly dependent upon the number of initial temperature levels; for underestimating that number leads to poor quality estimates resulting from neglecting some of the modes of the distribution of interest. On the other hand, overestimation of the number of temperatures does not significantly improve these estimates but highly increases the computational cost. Finally, if in that case one uses a naive state-independent strategy, then the overall efficiency of the algorithm drops due to longer waiting times for significant swaps, i.e. ones involving the base level temperature.
We have developed an algorithm with adaptable temperature scheme. Using it, one can overshot the number of temperature levels needed for performing good quality simulation and the procedure will automatically reduce some of the redundant levels. The results of our simulation support our claim of the method correctness.
We have also proposed a novel framework encompasing state-dependent strategies. These allow promotion of swaps based on various properties of the current state, e.g. Equi-Energy-type moves, big-jumps promotion, and similar. We have shown that this framework is susceptible to analytical analysis based on already known results. Specifically, we have concentrated here on evaluating the equi-energy type strategy and thoroughly tested it. The results show that it is more efficient than the standard state-independent swap strategy, since the overall acceptance of a global moves is higher, the difference getting larger with the initial number of temperatures. Similar conclusions can be drawn on the behaviour of the Root Mean Square Error. It is also more robust when it comes to overshooting the number of temperatures, as the quality of the estimates of importance does not diminish while introducing extra chains.
We find out that in comparison with the previous results (Kou et al. 2006; Baragatti et al. 2013) we do not observe significant differences between strategies both based on classical Parallel Tempering approach and the Equi Energy type moves: they all provide similarly good quality results. We conclude that a good choice of temperatures schedule is far more important than the way how differently tempered chains interact. Similar observations could be found in previous work (Miasojedow et al. 2013a).
All the scripts used in simulations are readily obtainable on request.
Notes
Chains with lower \(\beta \).
Here we assume that random walk proposal kernel is symmetric.
We exchangeably refer to coordinate transposition as swaps.
For simplicity we do omit the chain level index, \(\ell \).
A usual choice is \(\gamma ^{[n]} \propto n^{-\alpha }\), where \(\alpha \in (0.5, 1)\).
References
Andrieu, C., Thoms, J.: A tutorial on adaptive MCMC. Stat. Comput. 18(4), 343–373 (2008)
Atchadé, Y.F., Rosenthal, J.S.: On adaptive Markov chain Monte Carlo algorithms. Bernoulli 11(5), 815–828 (2005)
Atchadé, Y.F., Roberts, G.O., Rosenthal, J.S.: Towards optimal scaling of Metropolis-coupled Markov chain Monte Carlo. Stat. Comput. 21(4), 555–568 (2011)
Baragatti, M., Grimaud, A., Pommeret, D.: Parallel tempering with equi-energy moves. Stat. Comput. 23(3), 323–339 (2013)
Behrens, G., Friel, N., Hurn, M.: Tuning tempered transitions. Stat. Comput. 22(1), 65–78 (2012)
Efron, B., Hastie, T., Johnstone, I., Tibshirani, R.: Least angle regression. Ann. Stat. 32, 407–499 (2004)
Gilks, W.R., Richardson, S., Spiegelhalter, D.J.: Markov Chain Monte Carlo in Practice. Chapman & Hall/CRC, Boca Raton, FL (1998)
Haario, H., Saksman, E., Tamminen, J.: An adaptive Metropolis algorithm. Bernoulli 7(2), 223–242 (2001)
Hansmann, U.H.E.: Parallel tempering algorithm for conformational studies of biological molecules. Chem. Phys. Lett. 281(1–3), 140–150 (1997)
Kofke, D.: On the acceptance probability of replica-exchange Monte Carlo trials. J. Chem. Phys. 117(15), 6911–6914 (2002)
Kone, A., Kofke, D.: Selection of temperature intervals for parallel-tempering simulations. J. Chem. Phys. 122, 206101 (2005)
Kou, S.C., Zhou, Q., Wong, W.H.: Equi-energy sampler with applications in statistical inference and statistical mechanics. Ann. Stat. 34(4), 1581–1619 (2006)
Liang, F., Wong, W.H.: Evolutionary Monte Carlo for protein folding simulations. J. Chem. Phys. 115(7), 3374–3380 (2001)
Marinari, E., Parisi, G.: Simulated tempering: a new Monte Carlo scheme. Europhys. Lett. 19(6), 451–458 (1992)
Metropolis, N., Rosenbluth, A.W., Rosenbluth, M.N., Teller, A.H., Teller, E.: Equations of state calculations by fast computing machines. J. Chem. Phys. 21(6), 1087–1092 (1953)
Miasojedow, B., Moulines, E., Vihola, M.: An adaptive parallel tempering algorithm. J. Comput. Graph. Stat. 22(3), 649–664 (2013a)
Miasojedow, B., Moulines, E., Vihola, M.: Appendix to “An adaptive parallel tempering algorithm”. J. Comput. Graph. Stat. 22, 649–664 (2013)
Neal, R.: Sampling from multimodal distributions using tempered transitions. Stat. Comput. 6(4), 353–366 (1996)
Park, T., Casella, G.: Bayesian lasso. J. Am. Stat. Assoc. 103(482), 681–686 (2008)
Robert, C.P., Casella, G.: Monte Carlo Statistical Methods. Springer, New York (1999)
Roberts, G.O., Rosenthal, J.S.: Examples of adaptive MCMC. J. Comput. Graph. Stat. 18(2), 349–367 (2009)
Roberts, G.O., Rosenthal, J.S.: Minimising MCMC variance via diffusion limits, with an application to simulated tempering. Technical report, http://probability.ca/jeff/research.html (2012)
Roberts, G.O., Gelman, A., Gilks, W.R.: Weak convergence and optimal scaling of random walk Metropolis algorithms. Ann. Appl. Probab. 7(1), 110–120 (1997)
Schreck, A., Fort, G., Moulines, E.: Adaptive equi-energy sampler: Convergence and illustration. ACM Trans. Model Comput. Simul. 23(1), 5:1–5:27 (2013)
Swendsen, R.H., Wang, J.S.: Replica Monte Carlo simulation of spin-glasses. Phys. Rev. Lett. 57(21), 2607–2609 (1986)
Tibshirani, R.: Regression shrinkage and selection via the lasso. J. R. Stat. Soc. Ser. B 58, 267–288 (1996)
Woodard, D.B., Schmidler, S.C., Huber, M.: Conditions for rapid mixing of parallel and simulated tempering on multimodal distributions. Ann. Appl. Probab. 19(2), 617–640 (2009)
Acknowledgments
We are grateful to Matti Vihola for useful discussions. We would also like to thank the associated editor and two reviewers for comments and suggestions that helped us to improve the paper. Work partially supported by Polish National Science Centre Grant No. N N201 608740 and Grant No. 2011/01/B/NZ2/00864
Author information
Authors and Affiliations
Corresponding author
Electronic supplementary material
Below is the link to the electronic supplementary material.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Łącki, M.K., Miasojedow, B. State-dependent swap strategies and automatic reduction of number of temperatures in adaptive parallel tempering algorithm. Stat Comput 26, 951–964 (2016). https://doi.org/10.1007/s11222-015-9579-0
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11222-015-9579-0