
Abstract
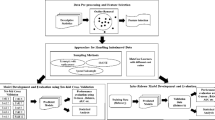
In software engineering predictive modeling, early prediction of software modules or classes that possess high maintainability effort is a challenging task. Many prediction models are constructed to predict the maintainability of software classes or modules by applying various machine learning (ML) techniques. If the software modules or classes need high maintainability, effort would be reduced in a dataset, and there would be imbalanced data to train the model. The imbalanced datasets make ML techniques bias their predictions towards low maintainability effort or majority classes, and minority class instances get discarded as noise by the machine learning (ML) techniques. In this direction, this paper presents empirical work to improve the performance of software maintainability prediction (SMP) models developed with ML techniques using imbalanced data. For developing the models, the imbalanced data is pre-processed by applying data resampling methods. Fourteen data resampling methods, including oversampling, undersampling, and hybrid resampling, are used in the study. The study results recommend that the safe-level synthetic minority oversampling technique (Safe-Level-SMOTE) is a useful method to deal with the imbalanced datasets and to develop competent prediction models to forecast software maintainability.



Similar content being viewed by others


References
Aggarwal, K. K., Singh, Y., & Chhabra, J. K. (2002). An integrated measure of software maintainability. In Proceeding of annual reliability and maintainability symposium. (cat. no. 02CH37318), IEEE, 235-241.
Ahmed, M. A., & Al-Jamimi, H. A. (2013). Machine learning approaches for predicting software maintainability: a fuzzy-based transparent model. IET Software, 7(6), 317–326.
Al Dallal, J. (2013). Object-oriented class maintainability prediction using internal quality attributes. Information and Software Technology, 55(11), 2028–2048.
Arisholm, E., Briand, L. C., & Fuglerud, M. (2007, November). Data mining techniques for building fault-proneness models in telecom java software. In 18th IEEE international symposium on software reliability (ISSRE'07), 215-224.
Ash, D., Alderete, J., Oman, P. W., & Lowther, B. (1994, September). Using software maintainability models to track code health. In In proceedings of international conference on software maintenance, 94 (pp. 154–160).
Bansiya, J., & Davis, C. G. (2002). A hierarchical model for object-oriented design quality assessment. IEEE Transactions on Software Engineering, 28(1), 4–17.
Batista, G. E., Prati, R. C., & Monard, M. C. (2004). A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explorations Newsletter, 6(1), 20–29.
Breiman, L. (1996). Bagging predictors. Machine Learning, 24(2), 123–140.
Broomhead, D. S., & Lowe, D. (1988). Radial basis functions, multi-variable functional interpolation and adaptive networks (No. RSRE-MEMO-4148). Royal Signals and Radar Establishment Malvern (United Kingdom).
Bunkhumpornpat, C., Sinapiromsaran, K., & Lursinsap, C. (2009, April). Safe-level-smote: Safe-level-synthetic minority over-sampling technique for handling the class imbalanced problem. In Pacific-Asia conference on knowledge discovery and data mining. Springer, Berlin, Heidelberg, 475-482.
Catolino, G., & Ferrucci, F. (2018, March). Ensemble techniques for software change prediction: a preliminary investigation. In 2018 IEEE workshop on machine learning techniques for software quality evaluation, IEEE, 25-30.
Chawla, N. V., Bowyer, K. W., Hall, L. O., & Kegelmeyer, W. P. (2002). SMOTE: Synthetic minority over-sampling technique. Journal of Artificial Intelligence Research, 16, 321–357.
Chawla, N. V., Japkowicz, N., & Kotcz, A. (2004). Special issue on learning from imbalanced data sets. ACM Sigkdd Explorations Newsletter, 6(1), 1–6.
Chidamber, S. R., & Kemerer, C. F. (1991, November). Towards a metrics suite for object oriented design. In proceedings of conference on object-oriented programming systems, languages, and applications, 197-211.
Chidamber, S. R., & Kemerer, C. F. (1994). A metrics suite for object oriented design. IEEE Transactions on Software Engineering, 20(6), 476–493.
Choeikiwong, T., & Vateekul, P. (2015). Software defect prediction in imbalanced data sets using unbiased support vector machine. In Information science and applications (pp. 923–931). Berlin, Heidelberg: Springer.
Cleary, J. G., & Trigg, L. E. (1995). K*: An instance-based learner using an entropic distance measure. In Machine learning proceedings. Morgan Kaufmann, 108-114.
Coleman, D., Ash, D., Lowther, B., & Oman, P. (1994). Using metrics to evaluate software system maintainability. Computer, 27(8), 44–49.
Coleman, D., Lowther, B., & Oman, P. (1995). The application of software maintainability models in industrial software systems. Journal of Systems and Software, 29(1), 3–16.
Cover, T., & Hart, P. (1967). Nearest neighbor pattern classification. IEEE Transactions on Information Theory, 13(1), 21–27.
Dagpinar, M., & Jahnke, J. H. (2003, November). Predicting maintainability with object-oriented metrics-an empirical comparison. In 10th working conference on reverse engineering, 2003. WCRE 2003. IEEE, 155-164.
Ebert, C., & Dumke, R. (2007). Software measurement: establish – extract – evaluate – execute. Springer.
Elish, M. O., & Al-Rahman Al-Khiaty, M. (2013). A suite of metrics for quantifying historical changes to predict future change-prone classes in object-oriented software. Journal of Software: Evolution and Process, 25(5), 407–437.
Elish, M.O., & Elish, K.O. (2009). Application of treenet in predicting object-oriented software maintainability: a comparative study. In 13th European conference on software maintenance and reengineering, CSMR 2009. IEEE, 69-78.
Eski, S., & Buzluca, F. (2011, March). An empirical study on object-oriented metrics and software evolution in order to reduce testing costs by predicting change-prone classes. In In 2011 fourth international conference on software testing, verification and validation workshops, IEEE (pp. 566–571).
Fawcett, T., & Provost, F. (1997). Adaptive fraud detection. Data Mining and Knowledge Discovery, 1(3), 291–316.
Fenton, N., & Bieman, J. (2014). Software metrics: a rigorous and practical approach. CRC press.
Gao, K., Khoshgoftaar, T. M., & Napolitano, A. (2015). Combining feature subset selection and data sampling for coping with highly imbalanced software data. In In Proceedings of 27th international conference on software engineering and knowledge engineering, Pittsburgh (pp. 439–444).
Giger, E., Pinzger, M., & Gall, H. C. (2012, June). Can we predict types of code changes? An empirical analysis. In 9th IEEE working conference on mining software repositories (MSR), IEEE, 217-226.
Gyimothy, T., Ferenc, R., & Siket, I. (2005). Empirical validation of object-oriented metrics on open source software for fault prediction. IEEE Transactions on Software Engineering, 31(10), 897–910.
Halstead, M. H. (1977). Elements of software science. 7, p. 127. New York: Elsevier.
Han, H., Wang, W. Y., & Mao, B. H. (2005). Borderline-smote: a new over-sampling method in imbalanced data sets learning. In In International conference on intelligent computing, springer (pp. 878–887).
Hart, P. (1968). The condensed nearest neighbor rule. IEEE Transactions on Information Theory., 14(3), 515–516.
He, H., & Garcia, E. A. (2009). Learning from imbalanced data. IEEE Transactions on Knowledge & Data Engineering, 21(9), 1263–1284.
He, H., Bai, Y., Garcia, E. A., & Li, S. (2008). Adasyn: adaptive synthetic sampling approach for imbalanced learning. In In IEEE international conference on neural networks (IEEE world congress on computational intelligence) (pp. 1322–1328).
Henderson-Sellers, B. (1996). Object-oriented metrics, measures of complexity. Prentice Hall.
Jin, C., & Liu, J. A. (2010). Applications of support vector machine and unsupervised learning for predicting maintainability using object-oriented metrics. In In 2010 IEEE second international conference on multimedia and information technology (MMIT) (pp. 24–27).
Kaur, A., & Kaur, K. (2013). Statistical comparison of modeling methods for soft-ware maintainability prediction. International Journal of Software Engineering and Knowledge Engineering, 23(06), 743–774.
Kotsiantis, S., Kanellopoulos, D., & Pintelas, P. (2006). Handling imbalanced datasets: a review. GESTS International Transactions on Computer Science and Engineering, 30(1), 25–36.
Kpodjedo, S., Ricca, F., Galinier, P., Guéhéneuc, Y. G., & Antoniol, G. (2011). Design evolution metrics for defect prediction in object-oriented systems. Empirical Software Engineering, 16(1), 141–175.
Kubat, M., Holte, R. C., & Matwin, S. (1998). Machine learning for the detection of oil spills in satellite radar images. Machine Learning, 30(3), 195–215.
Kumar, L., & Rath, S.K. (2015). Predicting object-oriented software maintainability using a hybrid neural network with parallel computing concept. In Proceedings of the 8th India software engineering conference, ACM, 100-109.
Kumar, L., Lal, S., & Murthy, L. B. (2019). Estimation of maintainability parameters for object-oriented software using hybrid neural network and class level metrics. International Journal of System Assurance Engineering and Management, 10(5), 1234–1264.
Laradji, I. H., Alshayeb, M., & Ghouti, L. (2015). Software defect prediction using ensemble learning on selected features. Information and Software Technology, 58, 388–402.
Laurikkala, J. (2001). Improving identification of difficult small classes by balancing class distribution. In Conference on Artificial Intelligence in Medicine, Springer, Berlin, Heidelberg, 63–66.
Le Cessie, S., Van Houwelingen, J.C. (1992). Ridge estimators in logistic regression. Applied statistics, 91-201.
Lessmann, S., Baesens, B., Mues, C., & Pietsch, S. (2008). Benchmarking classification models for software defect prediction: a proposed framework and novel findings. IEEE Transactions on Software Engineering, 34(4), 485–496.
Li, W., & Henry, S. (1993). Object-oriented metrics that predict maintainability. Journal of Systems and Software, 23(2), 111–122.
Lu, H., Zhou, Y., Xu, B., Leung, H., & Chen, L. (2012). The ability of object-oriented metrics to predict change-proneness: a meta-analysis. Empirical Software Engineering, 17(3), 200–242.
McCabe, T. J. (1976). A complexity measure. IEEE Transactions on Software Engineering, 4, 308–320.
Malhotra, R. (2015). A systematic review of machine learning techniques for software fault prediction. Applied Soft Computing, 27, 504–518.
Malhotra, R., & Khanna, M. (2017). An empirical study for software change prediction using imbalanced data. Empirical Software Engineering, 22(6), 2806–2851.
Malhotra, R., & Lata, K. (2017). An exploratory study for predicting maintenance effort using hybridized techniques. In Proceedings of the 10th innovations in software engineering conference, ACM, 26-33.
Malhotra, R., Pritam, N., Nagpal, K., & Upmanyu, P. (2014). Defect collection and reporting system for git based open source software. In In 2014 international conference on data mining and intelligent computing (ICDMIC), IEEE (pp. 1–7).
Maloof, M. A. (2003). Learning when data sets are imbalanced and when costs are unequal and unknown. In In International conference on machine learning. Workshop on Learning from: Imbalanced Data Sets II.
Martin, R. C. (2002). Agile software development: principles, patterns, and practices. Prentice Hall.
Menzies, T., Greenwald, J., & Frank, A. (2007). Data mining static code attributes to learn defect predictors. IEEE Transactions on Software Engineering, 1, 2–13.
Moller, M. F. (1993). A scaled conjugate gradient algorithm for fast supervised learning. Neural Networks, 6(4), 525–533.
Morasca, S. (2009, October). A probability-based approach for measuring external attributes of software artifacts. In Proceedings of the 2009 3rd international symposium on empirical software engineering and measurement, IEEE Computer Society, 44-55.
Napierala, K., Stefanowski, J., & Wilk, S. (2010). Learning from imbalanced data in the presence of noisy and borderline examples. In In International conference on rough sets and current trends in computing, springer (pp. 158–167).
Olague, H. M., Etzkorn, L. H., Gholston, S., & Quattlebaum, S. (2007). Empirical validation of three software metrics suites to predict fault-proneness of object-oriented classes developed using highly iterative or agile software development processes. IEEE Transactions on Software Engineering, 33(6), 402–419.
Olatunji, S. O., & Ajasin, A. (2013). Sensitivity-based linear learning method and extreme learning machines compared for software maintainability prediction of object-oriented software systems. ICTACT Journal of Soft Computing, 3(3), 514–523.
Oman, P., & Hagemeister, J. (1994). Construction and testing of polynomials predicting software maintainability. Journal of Systems and Software, 24(3), 251–266.
Oza, N. C., & Tumer, K. (2008). Classifier ensembles: select real-world applications. Information Fusion, 9(1), 4–20.
Pelayo, L., & Dick, S. (2007). Applying novel resampling strategies to software defect prediction. In NAFIPS 2007 Annual meeting of the North American fuzzy information processing society, IEEE, 69–72.
Peng, Y., Kou, G., Wang, G., Wu, W., & Shi, Y. (2011). Ensemble of software defect predictors: an AHP-based evaluation method. International Journal of Information Technology & Decision Making, 10(01), 187–206.
Platt, J. (1991). A resource-allocating network for function interpolation. Neural Computation, 3(2), 213–225.
Quinlan, J.R. (2014). C4.5: programs for machine learning. Elsevier.
Rousseeuw, P. J., & Leroy, A. M. (2005). Robust regression and outlier detection (Vol. 589) John Wiley & sons.
Radjenović, D., Heričko, M., Torkar, R., & Živkovič, A. (2013). Software fault prediction metrics: a systematic literature review. Information and software technology, Information and Software Technology., 55(8), 1397–1418.
Schnappinger, M., Osman, M. H., Pretschner, A., & Fietzke, A. (2019, May). Learning a classifier for prediction of maintainability based on static analysis tools. In In 2019 IEEE/ACM 27th international conference on program comprehension (ICPC) (pp. 243–248).
Schneberger, S. L. (1997). Distributed computing environments: effects on software maintenance difficulty. Journal of Systems and Software, 37(2), 101–116.
Schneidewind, N. F. (1979). Application of program graphs and complexity analysis to software development and testing. IEEE Transactions on Reliability, 28(3), 192–198.
Siers, M. J., & Islam, M. Z. (2015). Software defect prediction using a cost-sensitive decision forest and voting, and a potential solution to the class imbalance problem. Information Systems, 51, 62–71.
Singh, Y., Kaur, A., & Malhotra, R. (2010). Empirical validation of object-oriented metrics for predicting fault proneness models. Software Quality Journal, 18(1), 13–35.
Stefanowski, J., & Wilk, S. (2008). Selective pre-processing of imbalanced data for improving classification performance. In In International conference on data warehousing and knowledge discovery, springer (pp. 283–292).
Sun, Z., Song, Q., & Zhu, X. (2012). Using coding-based ensemble learning to improve software defect prediction. IEEE Transactions on Systems, Man, and Cybernetics, Part C (Applications and Reviews), 42(6), 806–1817.
Tan, M., Tan, L., Dara, S., & Mayeux, C. (2015). Online defect prediction for imbalanced data. In Proceedings of the 37th IEEE Conference on Software Engineering, 2, 99-108.
Thwin, M. M. T., & Quah, T. S. (2005). Application of neural networks for software quality prediction using object-oriented metrics. Journal of Systems and Software, 76(2), 147–156.
Van Koten, C., & Gray, A. (2006). An application of Bayesian network for predicting object-oriented software maintainability. Information and Software Technology, 48(1), 59–67.
Wang, L., Hu, X., Ning, Z., & Ke, W. (2009). Predicting object-oriented software maintainability using projection pursuit regression. In In 2009 first international conference on information science and engineering, IEEE (pp. 3827–3830).
Wang, S., & Yao, X. (2013). Using class imbalance learning for software defect prediction. IEEE Transactions on Reliability, 62(2), 434–443.
Wang, X., Gegov, A., Arabikhan, F., Chen, Y., & Hu, Q. (2019). Fuzzy network based framework for software maintainability prediction. International Journal of Uncertainty, Fuzziness and Knowledge-Based Systems, 27(05), 841–862.
Xu, Y., Cao, X., & Qiao, H. (2010). An efficient tree classifier ensemble-based approach for pedestrian detection. IEEE Transactions on Systems, Man, and Cybernetics, Part B (Cybernetics), 41(1), 107–117.
Yoon, K., & Kwek, S. (2005). An unsupervised learning approach to resolving the data imbalanced issue in supervised learning problems in functional genomics. In In fifth international conference on hybrid intelligent systems, IEEE (pp. 303–308).
Zhang, W., Huang, L., Ng, V., & Ge, J. (2015). SMPLearner: learning to predict software maintainability. Automated Software Engineering, 22(1), 111–141.
Zheng, J. (2010). Cost-sensitive boosting neural networks for software defect prediction. Expert Systems with Applications, 37(6), 4537–4543.
Zhou, Y., & Leung, H. (2007). Predicting object-oriented software maintainability using multivariate adaptive regression splines. Journal of Systems and Software, 80(8), 1349–1361.
Author information
Authors and Affiliations
Corresponding author
Ethics declarations
The authors certify that this manuscript has not been submitted to more than one journal for simultaneous consideration, and it has not been published previously (partly or in full).
This article does not contain any studies with human participants or animals performed by any of the authors.
Conflict of interest
The authors declare that they have no conflict of interest.
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
About this article

Cite this article
Malhotra, R., Lata, K. An empirical study on predictability of software maintainability using imbalanced data. Software Qual J 28, 1581–1614 (2020). https://doi.org/10.1007/s11219-020-09525-y
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11219-020-09525-y