
Abstract
The paper opens the debate on the need to find a stable methodological framework in the construction of composite indicators (CIs) in order to address the methodological challenges including those of sensitivity and uncertainties related to methods used. As CIs are well-known to be essential in public debate, their methodological construction must be known by a large public. Illustrating CIs’ construction steps by a simple indicator, the paper aims to “democratize” this disciplinary field which is still a black box for some researchers but also to show how composite scores are sensitive to methods used and then, its impacts on policies. For example, in the Sustainable Development Indicator case, the geometric aggregation system is favorable to emerging countries which lead the ranking table whereas high income countries (which are leaders in the linear and equal weight system) except Australia, are misclassified. Uncertainty and sensitivity analysis confirm these results showing that the indexes’ scores seem to be influenced by the orientation (implied theoretical framework) given by its sponsors including policy makers. Regarding the validity of the index, correlation tests with some lights and well known indicators, reveal very consistent results.

Similar content being viewed by others
Notes
See Bandura (2008).
United Nations University International Human Dimensions Programme.
While HPI ranks Nord-pas de Calais as one of poorest regions of France, regional HDI puts it in a higher position than some developed regions of France. See «Programme “Indicateurs 21” région Nord-pas de Calais, sept.2010».
Organization for Economic Cooperation and Development.
Joint Research Centre.
Nevertheless, we introduced both methods in Sect. 2.4 in order to highlight the difference between them and, therefore, the risks of uncertainty induced.
\(I = x\frac{{w_{j}}}{{w_{j}^{\prime}}}\); x being the ratio of the budget sums allocated to sub-indicator SI j and \(\,SI_{j}^{\prime}\); w j and w j’ relative weights of sub-indicators SI j and \(SI_{j}^{\prime}\) obtained from the allocation of budget X.
We asked 21 researchers from the University of Nantes and professionals working on issues of sustainable development to allocate 100 points to the three main dimensions of sustainable development namely economy, social and environment. The 21 experts were randomly chosen by emailing.
References
Aguna, C., & Kovacevic. M. (2010). Uncertainty and sensitivity analysis of the human development index. Human Development Research Paper, 11.
Areal, F. J., & Riesgo, L. (2015). Probability functions to build composite indicators: A methodology to measure environmental impacts of genetically modified crops. Ecological Indicators, 52, 498–516.
Bandura, R. (2008). A survey of composite indices measuring country performance: 2008 update. New York: United Nations Development Programme, Office of Development Studies (UNDP/ODS Working Paper).
Blancard, S., & Hoarau, J.-F. (2013). A new sustainable human development indicator for small island developing states: A reappraisal from data envelopment analysis. Economic Modelling, 30, 623–635.
Bornand, T., Caruso, F., Charlier, J., Colicis, O., Guio, A.-C., Juprelle, J., et al. (2011). Développement d’indicateurs complémentaires au PIB. Partie 1: Revue harmonisée d’indicateurs.
Bravo, G. (2015). The human sustainable development index: The 2014 update. Ecological Indicators, 50, 258–259.
Chiappini, R. (2012). Les indices composites sont-ils de bonnes mesures de la compétitivité des pays? hal.archives-ouvertes.
Council of Europe. (2005). Concerted development of social cohesion indicators—Methodological guide. Council of Europe Publishing.
Dialga, I. (2015). Du boom minier au Burkina Faso, opportunité de développement ou risques de péril pour des générations futures? Revue Cedres Etudes Sciences Economiques, 59, 27–47.
Donzé, L. (2001). L’imputation des données manquantes, la technique de l’imputation multiple, les conséquences sur l’analyse des données: l’enquête 1999 KOF/ETHZ sur l’innovation. Ecole polytechnique fédérale de Zurich, Centre de recherches conjoncturelles.
Gadrey, J. (2002). De la croissance au développement. A la recherche d’indicateurs. cippa.paris-sorbonne.
Homma, T., & Saltelli, A. (1996). Importance measures in global sensitivity analysis of nonlinear models. Reliability Engineering & System Safety, 52(1), 1–17.
Jacques, J. (2011). Pratique de l’analyse de sensibilité: comment évaluer l’impact des entrées aléatoires sur la sortie d’un modèle mathématique. Lille: sn.
Klugman, J., Rodríguez, F., & Choi, H.-J. (2011). The HDI 2010: New controversies, old critiques. The Journal of Economic Inequality, 9(2), 249–288.
Kutin, N., Perraudeau, Y., & Vallée, T. (2015). Sustainable fisheries management index, part 1, methodological proposal, NUM research series (vol. 3).
Nardo, M., Saisana, M., Saltelli, A., & Tarantola, S. (2005). Tools for composite indicators building. In European Commission, EUR 21682 EN, Institute for the Protection and Security of the Citizen, JRC Ispra, Italy, 131.
OECD & JRC. (2008). Handbook on constructing composite indicators: Methodology and user guide. OECD Publishing.
Ruta, G., Silva, P., Hamilton, K., Lange, G.-M., Markandya, A., Saeed Ordoubadi, M., et al. (2005). Where is the wealth of nations? Measuring capital for the 21st century. 34855. The World Bank.
Saaty, R. W. (1987). The analytic hierarchy process—what it is and how it is used. Mathematical Modelling, 9(3–5), 161–176.
Saaty, T. L. (1990). How to make a decision: The analytic hierarchy process. European Journal of Operational Research, 48(1), 9–26.
Saisana, M., & Saltelli, A. (2010). Uncertainty and sensitivity analysis of the 2010 environmental performance index. OPOCE.
Saltelli, A., Chan, K., & Scott, M. (2000). Sensitivity analysis, probability and statistics series. New York: Wiley.
Stiglitz, J., Sen, A., & Fitoussi, J.-P. (2009). Report of the commission on the measurement of economic performance and social progress.
Talberth, J., Cobb, C., & Slattery, N. (2006). The genuine progress indicator 2006. Oakland: A Tool for Sustainable Development.
Thiry, G. (2010). Indicateurs alternatifs au PIB: Au-delà des nombres. L’Épargne nette ajustée en question. Émulations, 8, 39–57.
Togtokh, C. (2011). Time to stop celebrating the polluters. Nature, 479(7373), 269.
UNU-IHDP. (2015). Inclusive wealth report 2014 measuring progress towards sustainability. Cambridge: Cambridge University Press.
Acknowledgments
The authors gratefully acknowledge Thomas Vallée for his help in technical calculations and three anonymous reviewers for their relevant comments in the previous manuscript.
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix 1: Uncertainty Analysis
1.1 Monte Carlo Method
Considering that every step and different methods of constructing a CI generate uncertainties that have effects on the resulting variable (here the rank attributed to a country by the value of the CI), the uncertainty analysis consists in determining a probabilistic distribution function relying inputs (sub-indicators) to the output (rank) via a random combination of different methods and steps.
Different methods exist to estimate the uncertainty of the resulting variable. Nardo et al. (2005) present the estimation of this uncertainty by the Monte Carlo method in the following way:
The first step is relative to the method used to impute missing data in the CI construction. The authors note \(X_{i} \left({i = 1, \ldots,k} \right)\) the random variable corresponding to different steps and methods. The random variable X 1 characterizes the imputation of missing data and takes two distinct values: 1 when the used method consists in replacing the variable with missing data by another one strongly correlated with it. For example, the variable “Investment” could be replaced by “Savings” and vice versa. X1 takes the value 2 when the zero value is given to the variable with missing data.
The second random variable is relative to the normalization method of initial variables.
The authors also assume that two discrete random variables X 1 and X 2 are evenly distributed on [0; 1]. By assuming the random number ζ, X1 = 1 if \(\zeta\in \left[{0;0,5)} \right.\) and X1 = 2 if \(\zeta \in\left[{0,5;1} \right].\)
In an analogous way, X3 is defined as the random variable representing the event “number of sub-indicators isolated for the analysis” knowing that the CI contains J sub-indicators. So:
\(\frac{1}{J + 1}\) is the probability that no sub-indicator is excluded from the analysis whereas \(1 - \frac{1}{J + 1}\) is the probability that at least one sub-indicator is excluded.
The exclusion of a sub-indicator refers to the hypothesis that some sub-indicators cannot be considered in certain methods. For example, when the aggregation method used is the geometric one, all sub-indicators with negative values should be excluded from this aggregation. Moreover, by excluding the sub-indicator j from the simulation analysis, we isolate its contribution to the CI creation and highlight, all others thing equal, the relative importance of dimension j in the explanation of the phenomenon.
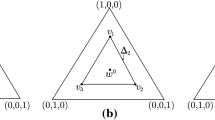
The random variable X 4 is used to capture the uncertainty related to the aggregation method. Three aggregation methods are retained: the linear method (LIN), the geometric one (GEM) and multi-criteria analysis (MCA) discussed in Sect. 4.
The random variable X 5 is generated to take into account the uncertainty related to the chosen weighting system. Three weighting systems have been retained by the authors- Benefit of the Doubt (BOD), Budget Allocation Process (BAP) and Analytic Hierarchy Process (AHP). The latter is not developed in this paper.
The last random variable generated is X 6. It allows the capture of the uncertainty related to the judgement of the expert especially when there is incoherence in their value judgement such as an illogical allocation of points between different dimensions. X 6 takes values \(0,1, \ldots,N\) where N is the number of experts participating in the study. As experts are chosen randomly, each expert selected is associated to the weight that he/she gives dimensions.
However, in the analysis if X 5 = 3, X 6 = 0 because the weighting method chosen randomly (X 5 = 3 corresponds with BOD) does not involve the expert’s point of view. The weights in this case are endogenously determined.
Give six random variables generated above, the Monte Carlo analysis consists in defining a probabilistic function combining these six variables. It is then possible to generate N combinations from \(X_{i}^{l}\) (\(i = 1, \ldots k\) with k = 6 in our case and \(l = 1,2, \ldots,N\)) random variables, then analyze the impact of each combination on the value of the final CI or on the induced ranking. The samples \(X_{i}^{l}\) could be obtained from many randomization methods such as simple random sampling, quasi-random sampling, stratification sampling, etc. (Saltelli et al. 2000). The result variable (CI or rank of country) is related to random variables by the probabilistic density function mentioned above. From an arbitrarily set threshold, it is possible to determine the characteristics of this density function from the number of simulations N obtained. By applying this Monte Carlo method to the Technology Achievement Index, Nardo et al. (2005) find that the ranking of countries varies when all uncertainties related to different steps of the CI construction are taken into account.
Appendix 2: Sensitivity Analysis by Variance Decomposition
This method aims at evaluating the output (CI) robustness since the variance is a measurement of imprecision. The analysis evaluates the contribution of each sub-indicators to the CI total variance and finds the part attributable to interactions between different inputs (co-linearity, endogeneity, etc.). This decomposition allows the construction of CI sensitivity indexes.
With CI being considered the variable of interest and sub-indicators inputs, the first step of the method consists in specifying a function linking the output (here the CI) to explanatory variables (sub-indicators). When the functional specification linking the output variable Y to input variables X—supposedly independent—is linear (\(Y = \beta_{0} + \mathop \sum \nolimits_{i = 1}^{P} \beta_{i} X_{i}\)) a first sensitivity index can be built (Jacques 2011). The index SRC i (Standardized Regression Coefficient) expresses the part of the CI variance imputable to the variance of variable X i . \(SRC_{i} = \frac{{\beta_{i} V(X_{i})}}{V\left(Y \right)}\) where \(\beta_{i} V(X_{i})\) is the variance of X i .
Nardo et al. (2005) note that given uncertainties related to different levels of CI construction, the functional form of the model cannot be linear nor additive. They support a non-linear model with an undetermined specification. Although these models are not known in advance, they should verify the following properties.
-
For n sub-indicators, models make possible an estimation of the total variance explained by these n factors;
-
Models allow a sensitivity analysis in which inputs containing uncertainties are considered in groups rather than individually in order to estimate the part of the variance attributable to interactions between variables (cumulative effects of uncertainties, endogeneity biases of variables etc.).
-
Variances are quantifiable and allow a decomposition in main variance and in residual variance (variance related to interactions between different explanatory variables);
-
Variances are easy to interpret and explain;
-
Finally, they allow the discussion of the CI robustness.
Given X i inputs (sub-indicators), the relative contribution of variable X i to the total variance of output Y (CI) is given by the variance of the conditional expectations of Y. \(V_{i} = V_{i} (E\left({X_{- i} \left({Y\backslash X_{i}} \right)} \right)\). For a precise value of \(X_{i} = x_{i}^{*}\), it is possible to calculate the conditional mean of Y. In particular, when X i does not influence the principal variance of Y, V i = 0 and when the output variance is totally explained by this factor X i , \(V_{i} = V\left(Y \right)\), the other factors having no effect on the total variance.
The decomposition of the total variance into main variance and residual variance is given by: \(V\left(Y \right) = V_{{X_{i}}} \left({E_{{X_{- i}}} \left({Y\backslash X_{i}} \right)} \right) + E_{{X_{i}}} \left({V_{{X_{- i}}} \left({Y\backslash X_{i}} \right)} \right).\) Thus, when a factor X is important in the composition of the variance of Y, residual variance \(E_{{X_{i}}} \left({V_{{X_{- i}}} \left({Y\backslash X_{i}} \right)} \right)\) is small and vice versa.
By dividing the conditional variance by the total variance, we get a first indicator of the sensitivity of CI to X i : \(S_{i} = \frac{{V_{{X_{i}}} \left({E_{{X_{- i}}} \left({Y\backslash X_{i}} \right)} \right)}}{V\left(Y \right)} = \frac{Vi}{V\left(Y \right)}\). S i is the relative contribution of the ith variable to the total variance. When the variable explains the quasi-totality of variations of the output, the sensitivity indicator tends towards 1 \((S_{i} \rightsquigarrow 1\)) as uncertainties and interactions are negligible.
Analogously, it is possible to calculate relative contributions to the total variance.
For two given factors X i and X, the conditional variance in relation to two factors is written: \(V_{{X_{i} X_{j}}} ({\text{Ex}}_{{- {\text{ij}}}} ({\text{Y}}\backslash {\text{X}}_{\text{i}},{\text{X}}_{\text{j}}\))). The residual variance (resulting from the interaction between X i and X j ) is given by: \(V_{ij} = V_{{X_{i} X_{j}}} \left({{\text{Ex}}_{{- {\text{ij}}}} \left({{\text{Y}}\backslash {\text{X}}_{\text{i}},{\text{X}}_{\text{j}}} \right)} \right) - V_{{X_{i}}} \left({E_{{X_{- i}}} \left({Y\backslash X_{i}} \right)} \right) - V_{{X_{j}}} \left({E_{{X_{- j}}} \left({Y\backslash X_{j}} \right)} \right)\). It allows us to detect relations between different explanatory variables. In the absence of any interaction between X i and X j in the CI construction model, V ij equals zero. In other words, all explanatory variables are independent and no-collinear.
For k explanatory variables independent from one another, the decomposition of the total variance is given by the following formula:
In the hypothesis of total independence between inputs, the model of decomposition of total variance is the sum of the marginal contributions of each factor.
From the decomposition into residual variances, it is possible to calculate the indexes of sensitivity related to interactions between the X i explanatory variables. However, Nardo et al. (2005) show that the number of these indexes n gets larger with the number of variables k; \(n = 2^{k} - 1\). In practice we would rather calculate a condensed index of interactions between variables. It gives the marginal effect of factor i in explaining the total variance of Y, given the effects attributable to interactions between other variables i.e. residual variances of k − i factors.
For a CI with three factors, the marginal sensitivity index is: \(S_{T1} = \frac{{V\left(Y \right) - V_{{X_{2} X_{3}}} \left({E_{{X_{1}}} \left({Y\backslash X_{2},X_{3}} \right)} \right)}}{V\left(Y \right)} = S_{1} + S_{12} + S_{13} + S_{123}\). S T1 is the ration between the sum of variances in which the indicator 1 intervenes individually (S 1) or in interaction with the other indicators (\(S_{12},S_{13} \,et\,S_{123}\)) and the total variance of the CI.
The residual index of factor 2 is: \(S_{T2} = S_{2} + S_{12} + S_{23} + S_{123}\) and the residual index of factor 3 is \(S_{T3} = S_{3} + S_{13} + S_{23} + S_{123} .\)
Homma and Saltelli (1996) show that \(V_{{X_{2} X_{3}}} \left({E_{{X_{1}}} \left({Y\backslash X_{2},X_{3}} \right)} \right)\) could be generalised like this:\(V_{{X_{\_i}}} \left({E_{{X_{i}}} \left({Y\backslash X_{\_i}} \right)} \right)\). It gives the contribution of k − i variables to the explanation of the total variance.
So
Finally, two sensitivity indicators (S i and S Ti ) allow the appreciation of the degree of global appropriateness of the model and its robustness. In particular, when there is a significant difference between indexes S i and S Ti , this result shows the effects of endogeneity and multi-collinearity between factors Xi which are to be corrected (by deconstruction, by change of weighting or by substitution of some variables by other ones which are non-collinear). If there is no correction, the final CI would be very biased.
Appendix 3: Budget Allocation Process (BAP) Results
The question asked to experts is: Considering the three main dimensions of sustainable development namely economic, social and environment, you are asked to distribute 100 points among these three dimensions according to the importance you give to each of them knowing that the total points awarded must be equal to 100 (Table 10).
Rights and permissions
About this article

Cite this article
Dialga, I., Thi Hang Giang, L. Highlighting Methodological Limitations in the Steps of Composite Indicators Construction. Soc Indic Res 131, 441–465 (2017). https://doi.org/10.1007/s11205-016-1263-z
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11205-016-1263-z