
Abstract
Spatial linkages in returns have not yet received much attention in an asset pricing context, however, they can capture important information about idiosyncratic externalities associated with firms’ holdings. We explain returns of real estate companies by modelling the spatial comovement across their underlying assets. We connect stocks of real estate firms using the location of their property portfolios and show that spatial linkages across real estate assets explain some of the variation in abnormal returns, controlling for exposure to systematic factors and firm characteristics. We propose a trading strategy that exploits the information contained in the spatial linkages of the underlying assets. We show that a long-short hedge that sells the stocks that experience a drop in the price if their connected stocks have also gone down in price and buys the stocks that experience an increase in the price if their connected stocks have also gone up delivers a non-market return of 9.7% per year.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
Introduction
The impact of geographic location on REITs’ performance has received widespread attention by researchers and investors. Previous literature focuses on the impact on the performance of individual REITs and draws divergent conclusions. For instance, Gyourko and Nelling (1996) and Ambrose et al. (2000) find that geographic specification of a REIT’s property portfolio has no economic impact on firm returns. However, Capozza and Seguin (1998, 1999) and Hartzell et al. (2014) suggest that the geographic diversification of a REIT’s portfolio has a negative impact on the firm’s value, as allocating properties in different regions may result in higher administrative costs and a higher liquidity premium that offset the benefits of diversification.Footnote 1 In line with the home bias theory, Ling et al. (2017b) find a significant positive relation between home market concentrations and firm returns. In addition to geographic concentration, the ‘quality’ of location has recently attracted some attention. For example, Ling et al. (2017a) find a significant positive impact on REITs’ returns stemming from the exposure to the so called ‘Gateway’ markets related to the ability of REIT managers to both identify the outperforming MSAs and overcome the costs and delays associated with increasing allocations to these MSAs.
This paper focuses on the impact of the spatial linkages across REITs’ property holdings on REIT returns co-movement. This topic is of particular importance not only to REITs managers who need to identify the best property portfolio strategy, but also to institutional investors, who use REITs as a liquid vehicle to invest in real estate. Adams et al. (2015) use the geographic proximity of the underlying assets and show how risk spills over among 74 U.S. REITs in a Value at Risk setting. However, while their paper reveals important insights in the relationship between geographic location of property holdings and risk management for REITs, it is important to assess how information embedded in the spatial linkages between property holdings can be drive REIT prices and returns and how this information can be exploited in portfolios generating higher non-market returns. In general, there is no clear evidence on geographic closeness across properties in terms of the misvaluation of REITs. In particular, we investigate whether the change in the share price of one REIT can affect the performance of other REITs invested in nearby properties in a way that cannot be explained by their common exposure to regional and national factors.
By showing the linkages of REITs share prices based on the geographic closeness of underlying assets, this paper contributes to the existing literature by combining two by now independent approaches – asset pricing and spatial econometrics – to investigate the information contained in the spatial linkages of firms’ underlying assets. Spatial econometrics have been extensively applied to the hedonic property valuation (Anselin 1988; Pace et al. 1998; Zhu et al. 2011; Tu et al. 2004; Nappi-Choulet and Maury 2009; Le Sage and Pace 2009; Chegut et al. 2014) and market performance analyses (Miao et al. 2011; Holly et al. 2011; Zhu et al. 2013; Milcheva and Zhu 2016a, b). The studies show that spatial dependence can capture the unobserved local or spatial characteristics and thereby can improve the valuation of properties and identify spatial spillover effects across prices. However, asset pricing models do not account for spatial dependence across firms. Therefore, in this paper, we investigate the spatial linkages between individual stocks and their pricing which could help asset managers to identify under-priced and over-priced stocks.
The impact of location and geographic proximity for the performance of firms has received increasing attention in the finance literature. Pirinsky and Wang (2006) show that companies with closely located headquarters show stronger comovement in their non-market returns. The rationale behind using location in an asset pricing context is to uncover information asymmetries. Bernile et al. (2015) show that investors pay more attention on the location of underlying assets than the location of their headquarters. Therefore, we aim to fill the gap in the literature by studying geographic proximity of the underlying assets and the comovement in their stock returns. For this purpose, REITs provide us an ideal sample as the underlying assets of REITs is clearly associated with a single and identifiable location.
The rationale for assessing spatial comovement in an asset pricing context is twofold. First, shocks to the performance of one company can have negative or positive externalities on other companies if their holdings are located sufficiently close to each other. Campbell et al. (2011) show that the price of a house can be influenced not just by general macroeconomic conditions and hence by demand and supply but also by idiosyncratic factors like the urgency of the sale and the physical quality of the house among others. Fostel and Geanakoplos (2008) and Geanakoplos (2009) show that changes in prices of assets during a fire sale can be explained if buyers have different opinions about the true value of the asset and face borrowing constraints, even though the actual payoffs from holding real estate are the same for all market participants. Positive or negative price externalities stemming from certain buildings can affect the prices of nearby buildings owned by different real estate companies. This has direct effects on the rental income and the capital growth from the underlying assets and hence on the net asset value (NAV) of the real estate companies and can trigger the movement in stock returns. Second, the co-movement could be related to information asymmetry in the real estate market. Kurlat (2016) presents a model in which differences among buyers stem from the quality of their information. Such a setting can also be applied to real estate markets where buyers in general possess different information about the quality of the property and the neighbourhood.
We adopt a two-stage approach. First, we use the abnormal returns obtained from a factor model in a spatial panel model using a spatial weight matrix and controlling for a range of company specific characteristics. In the second stage, we build portfolios using the information in the spatial linkages and estimate non-market returns. We account for the spatial linkages by using a measure of the physical distance between the property holdings. The concept of common ownership described in Anton and Polk (2014) which relates to fund ownership of stocks can also be applied in the context of real estate firms. In the latter case, the common ownership of properties located in a common sub-market, within a range of 25 km, by one firm.
We demonstrate that excess movement can exist between REITs that hold properties locating in nearby areas, in addition to the degree of co-movement that can be explained by market risk, regional risk and other common factors. We use this finding to provide a trading strategy for real estate stocks which can achieve significant non-market returns (alpha) by using the information contained in the spatial linkages of the underlying assets.Footnote 2 Our results show that the degree of locational proximity of the property holdings of different real estate companies explains the cross-sectional variation in return correlation, controlling for exposure to systematic return factors, sectoral and regional similarity, and a range of firm characteristics. We find that spatial linkages across companies’ underlying assets can serve as an indicator for misvaluation of stocks. We demonstrate that a long-short trading strategy exacerbates the excess comovement. An investment strategy which buys the stocks that experience an increase in their price if their connected stock returns have also gone up and sells the stocks that experience a drop if their connected stock returns have also gone down can earn an average non-market return of nearly 10% per year.
Literature Review
Our research thus relates to two strands of literature – the literature on geographic location and asset pricing and the literature on co-movements in real estate prices. Previous research incorporates a locational factor into an asset pricing model and the location stays for the location of firm’s headquarter (e.g., Bernile et al. 2015; Becker et al. 2011; Hong et al. 2008; Pirinsky and Wang 2006) and the location of assets related to the firm (see e.g., Gyourko and Nelling 1996; Capozza and Seguin 1998, 1999; Ambrose et al. 2000; Hartzell et al. 2014; Ling et al. 2017a). The majority of the studies focus on the location of the headquarters. For example, using US company data from 1993 to 2002, Pirinsky and Wang (2006) document strong comovement in the stock returns of firms headquartered in the same geographic area. The local co-movement of stock returns is not explained by economic fundamentals and is stronger for smaller firms with more individual investors. Price formation in equity markets has a significant geographic component linked to the trading patterns of local residents. Fu and Gupta-Mukherejee (2014) argue that in financial markets which are characterised with large frictions in dissemination of information, market participants can acquire information through informal channels such as the links between funds and the links between funds and companies. Coval and Moskowitz (2001) argue that geographic proximity matters as local fund managers can access local information more easily and monitor the operations of the local companies. Hong et al. (2005) identify that the word-of-mouth channel which means that fund managers in the same location would have correlated strategies. However, when it comes to the role of location proximity on comovement in returns across firms, there is hardly any evidence.
As we are focussing on spatial linkages, it is worth looking into the literature on return comovement through spatial linkages. Spatial equilibrium theories argue that spatial interdependence across agents can explain economic behaviour (Anselin 2003). In general, the concept developed in spatial econometrics is to capture the effect of a shock at a specific point in space to another place (Haining 2003). Such models are often used to explain housing transactions, as the prices of the physical assets can depend on the prices of the surrounding buildings (DiPasquale and Wheaton 1995; Fujita and Thisse 2003). The most common spatial dependence widely studied in the literature is through geographic proximity (Fingleton 2001 and Fingleton 2008). The reason is that neighbouring regions often keep close economic relationships. Therefore, as Fazio (2007) and Orlov (2009) argue, geographically closer regions would have as a result stronger economic linkages. Miao et al. (2011) explore correlations among real estate returns in 16 US metropolitan statistical areas (MSAs) and find that the strongest correlation appears to be in geographically adjacent regions. In this paper, we go one step further and investigate whether the spatial dependence detected in the aggregate regional real estate markets can also be found across individual real estate firms. Chegut et al. (2014) investigate the spatial dependence in office price in Hong Kong, London, Los Angeles, New York City, Paris, and Tokyo for 2007 to 2013. They find that only a low economic impact from spatial dependence in all six markets, and spatial and spatio-temporal dependence do not moderate the effects of hedonic characteristics statistically or economically.
Methodology
In the first stage, we estimate a factor model given as
with ri, t, the excess return of asset i (i = 1,2.., N) in period t (t = 1,2.., T) calculated as \( {r}_{i,t}={\overset{\sim }{r}}_{i,t}-{r}_t^{rf} \) with \( {r}_t^{rf} \) the risk-free rate in period t and \( {\overset{\sim }{r}}_{i,t} \) the return of stock i in period t. Ft is a vector of factors and βi is a vector of the sensitivities of the i-th asset to each factor. εi, t is the residual or the abnormal return with \( {\varepsilon}_{i,t}\sim N\left(0,{\nu}_i^2\right) \).
In the second stage, we use the monthly abnormal returns, the residuals from Eq. (1), to estimate an unbalanced spatial panel modelFootnote 3 given as:
The explanatory variables consist of a spatial term of the abnormal returns,\( {\sum}_{j=1,j\ne i}^N{w}_{i,j,t}{\varepsilon}_{i,t} \), the lagged monthly abnormal returns, εi, t − 1, and a host of firm characteristics, controlsk, i, t. Notice that wi, j, tt is a time-varying spatial weight which is based on the distance between the properties of each pair of firms at period t. The matrix is time-varying, as the property portfolio composition of each firm changes from year to year. ρ is the spatial coefficient in which are most interested. The company-specific variables control for sector and regional diversification, age, size, debt-to-equity (D/E) ratio, trading volume, return on equity, and debt ratio. We also include variables controlling for the diversification strategy and common exposure to top real estate markets. The model in Eq. (2) is solved by a maximum likelihood estimation (Baltagi et al. 2015). Second stage is nessecary in order to show if the spatial coefficient matters for abnormal returns.
If that is the case, in the third and final stage, we use the information from the spatial linkages to group firms into different portfolios and estimate Eq. (1) for entire portfolios and not firms as for the analysis in stage 2. We are interested in the non-market returns, αi, of each portfolio and determine a trading strategy based on those outcomes.
The Spatial Weight Matrix
As argued above, real estate companies provide a suitable setting to account for spatial linkages as such companies extract a large proportion of their income (80–90%) operating direct real estate assets, mostly through rental income. This enables us to directly relate the locations of the underlying assets of a company to the locations of properties of another company and calculate a spatial weight for each pair of firms. The weight is based on the proportion of the properties held by the two firms that locate within a distance of 25 km:
with l = 1, 2, . . , Lt and Lt is the total amount of properties held by firm i. \( \sum \limits_{l=1}^{L_t}{q}_{i.l,j,t} \) is the total amount of properties held by firm i in period t that has a distance of less than 25 km with ANY of the properties held by firm j, with:
The same is true for the counterparty firm j:
with l = 1, 2, . . , Kt and Kt is the total amount of properties held by firm j. qj. l, i, t is the amount of properties held by firm j in period t that has a distance less than 25 km with ANY of the properties held by firm i. In order to make sure that the matrix is symmetric, we use the minimum of these two proportions to calculate the linkage between each pair of firmsFootnote 4:
Equation (6) defines the weight between each two firms using their minimum of the individual firm weights, because the minimum distance accounts for the case in which firms have different levels of geographic asset concentration. We assume that the pair of firms would not have a strong relationship as indicated by the average weight if the two individual weights are far apart from each other. In that case, we assume overall weak relationship. In the last step, we combine each element of Eq. (6) in a Wt matrix with the pairwise proportions for each period. We then row-standardize matrix Wt so that for each i we have ∑jwi, j, t = 1.
Figure 1 shows an example of how the distance between firm A and firm B is calculated based on the individual distances between the properties. Let us assume that company A holds three properties, A1, A2 and A3, and company B holds in two properties, B1 and B2. The dashed lines show the distance between each pair of properties. For firm A, all of the properties locate within a distance of 25 km to any of the properties held by firm B, so the proportion of properties that locate within 25 km to any of the properties held by firm B is 1 (from Eqs. 3 and 4). For B, B2 locates within the 25 km distance and B1 locates beyond the range of 25 km, which leaves us with a weight of 0.5 (from Eq. 5). The spatial weight between firms A and B is then defined as the minimum of 1 and 0.5, and is thus 0.5 (from Eq. 6). If the weight is 0, it implies that none of the properties between the two firms is located within 25 km. If the weight is 1, it implies that all properties of a firm locate within 25 km from the corresponding counterparty.

Construction of the spatial weights between each pair of real estate companies
Data
The data regarding the individual company characteristics is collected from SNL Financial. The returns and the market capitalization data are from Thomson Reuters Datastream. We collect data for all available US listed real estate companies between 1996 and 2015. In total we collect data for 223 firms. However, not all of them report the location of their properties, therefore we only use those which provide locational information. Furthermore, we exclude those firms holding real estate assets internationally in order to restrict the data sample to firms only invested within the US (excluding Hawaii), as REITs that invest internationally are subject to different market dynamics and require the use of different factors in the asset pricing analysis. This leaves us with 115 firms. After removing companies with missing observations for the control variables, 74 distinct companies remain in our sample.Footnote 5
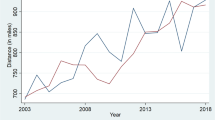
Figure 2 shows the number of firms with complete observations in our sample over the study period as well as the market capitalization in each year. Up until 2007, the number of listed real estate companies in our sample has steadily increased from 31 to 70 and the average firm size increased by over 10 times, from $0.4 billion to over $4.1 billion.Footnote 6 During the GFC, real estate companies experienced a large drop in size and shrunk to $1.2 billion as of 2009. Starting in 2009, real estate stocks have recovered to their pre-crisis values. Between 2010 and 2015, real estate companies showed the highest increase in market capitalization in the entire sample period.

Number of US real estate firms with complete observations and their market capitalization between 1996 and 2015
Figure 3 shows the average number of properties across the real estate firms with available data for each year. We can see that the number of properties held on average by a real estate firm has doubled between 1996 and 2000. Figure 5 in the Appendix shows maps with the locations of the properties of each of the real estate companies.

Average number of properties across firms over time
We use two sets of explanatory variables to estimate the abnormal returns in the first stage. The data for the factors is obtained from Ken French’s website.Footnote 7 The factors include a US market return index (MR), the difference between the returns on diversified portfolios of small stocks and big stocks (SMB), the difference between the returns on diversified portfolios of high book-to-market (value) stocks and low book-to-market (growth) stocks (HML), and the difference between the month t returns on diversified portfolios of the winners and losers of the past year (WML). The first three factors (MR, SMB, HML) are the Fama and French factors (Fama and French 1993) accounting for market return, size and type; the fourth factor (WML) is the Carhart momentum factor (Carhart 1997). The second set of factors is constructed by us only using real estate companies instead. We call those factors the constructed factors. We follow the real estate literature which shows that REITs may not perfectly move together with the stock market reflecting information specific to the underlying real estate market. We construct these factors using the 223 real estate firms. As shown in Table 1, the average excess return of the market index over the sample period is 0.6%. This is slightly less that the 0.8% return of the 223 real estate companies. We also see that the variation in the constructed factors is larger for the return, type and momentum and smaller for size.
Table 2 summarizes the firm characteristics of the real estate companies. We show data averaged across time, from 1996 to 2015, and across the 74 companies. We show descriptive statistics of the characteristics of firms with high and low total returns which are connected through their underlying assets to similarly performing companies. In particular, we sort firms according to their total returns and according to the performance of their ‘connected’ firms.Footnote 8 Panel B shows descriptive statistics only for firms with high average returns that are connected to high-return firms (HH portfolio of firms).Footnote 9 High-return firms include firms with 33% highest average annual returns across all firms in the previous year which all fall in the category of firms whose connected counterparties have on average the 33% highest returns.Footnote 10 Panel C summarizes the firms with low returns that are connected to low-return firms (LL portfolio).Footnote 11
The average return across all companies is 0.6% per month. The HH firms do not yield significantly higher returns than the average of the 74 firms. The LL firms yield significantly lower returns than the baseline, −0.17% per month. The average age of the companies is 18 years (or 215 months), with the oldest company being 53 years old and the youngest just 6 months. LL firms are on average almost 5 years older than HH firms. We also see a large variation across the size of the companies in terms of market capitalization with the highest being $26,068 million and the lowest, $0.35 million. On average a company has a market capitalization of $1856 million. The HH firms are significantly larger with a capitalization 34% higher than the average. The LL firms are significantly smaller than the average. This implies that larger firms perform on average better than smaller firms. The average M/B ratio is 0.81, the highest, 7.6, and the lowest, −5.2. It is similar to the average ratio of 0.8 across all types of industries which suggests that REITs can be seen as value stocks. The average ROAE is 6.7% but it goes down to −40% in the worst case for some of the companies. The ROAE of the companies in our sample is lower than the average for all types of industries which is nearly 11%. However, it is higher than the average ROE for the real estate industry of 1.7%. HH firms do not exhibit significantly higher ROAE. However, we see that LL firms have on average significantly lower ROAE of 2.8%. We also include the turnover ratio as a measure of liquidity. Barinov (2014) shows that the turnover ratio is negatively related to liquidity and that relationship is stronger for firms with option-like equity due to bad credit ratings. We calculate the turnover ratio as the total value of the trading volume of a company for a whole year divided by the end-of-year outstanding value of common stocks. The higher the turnover ratio the more liquid the company is. On average, each common share is traded 2.76 times a year. The LL firms have significantly lower liquidity than the average of 2.48. The HH firms on the other side are more liquid that the baseline. Real estate investment growth is 16% consistent with findings in Bond and Xue (2017) and Alcock and Steiner (2016). The growth in the LL firms is significantly smaller, taking a value of about 10%. The D/E ratio is on average 1.67 but some companies have very high D/E ratio of more than 20. This is consistent with previous findings that demonstrate that REITs carry significant leverage (Barclay et al. (2013)). The leverage is significantly higher for LL companies and significantly lower for HH firms.
Results
Baseline Results
We first estimate a factor model using the existing factors as described above. We run firm-by-firm regressions using monthly data. We can see that the performance of the model is poor as the R2 is low, at only 3.2% on average, and none of the factors is significant on average (see Model 1 in Table 3). This is compared with R2 of above 60% for stock regressions by Fama and French (2012) using the four Fama and French factors. The reason for the low explanatory power is that the general stock market factors do not include enough real estate companies and a large part of the risk is idiosyncratic. Real estate companies invest predominantly in real estate and can be driven by factors specific to certain buildings such as location, sector, etc. This is reflected in the low and insignificant beta of 0.0019. One of the reasons for the low synchronicity between real estate companies and the market, as argued by Chung et al. (2011), can be due to spatial uniqueness of the underlying assets. In order to capture the comovement in the real estate equity market, we construct factors using the 223 US real estate firms. The results are reported in Model 2 in Table 3. The R2 of Model 2 is now much higher with a value of 49%. However, this value is still not as high as the one observed for stocks. This can point again to remaining idiosyncratic price variations as we account for the REIT market. We can see that the variations in the returns are largely explained by the market index (RM). The average beta across the 74 companies is 0.95 which is very close to the beta of the market of 1. That means that the 74 companies in our sample which we regress individually on a factor constructed using 223 real estate companies commove very closely with the rest of the real estate firm universe.
In a second stage, we use the abnormal returns from the factor model (Model 2) to estimate an unbalanced panel model with 11,031 observations. Model 3 (in Table 4) does not include a spatial term, which Models 4 and 5 regress the residuals on the spatially weighted residuals. The weights capture the spatial linkages between each pair of residuals using the locations of the underlying property holdings of each company. Model 4 includes only one matrix using 25 km as the bandwidth. Spatial models always assume that the co-movement between assets should depend on the strength of their linkages. While we construct the weights based on the strength of the linkages, we also test if that assumption is fair. For this purpose, we apply the distance decay model adding four matrices. The results are presented in Model 5. It shows other bandwidths, such as 25–125 km, 125–1000 km, and distance beyond1000 km. The first matrix is the same as the matrix in Model 4. This means, each weight between a pair of firms reflects the proportion of properties of one firm that locates within 25 km to any of the properties held by the other firm. The second matrix is defined in the same way as the first matrix; the only difference is that the weight is based on the proportion of properties held by one firm that locates between 25 km and 150 km to any of the properties held by the other firm. In the same way, we define matrix three, but the distance is 150–1000 km. Matrix four accounts for the proportion of the properties between two firms that locate further than 1000 km. For each matrix the weight is defined as the proportion of the underlying properties within the respective distance; for the rest of the firms, the weights are set to zero.
In all three models (Models 3, 4 and 5), we control for profitability, liquidity, size, as well as diversification strategies. The degree of market concentration is measured using a Herfindahl-Hirschman Index (HHI). When the index has a value of 1, the firm has a fully concentrated market/sector strategy meaning that all properties are located in the same state or in the same sector. The lower the HHI index, the more diversified the assets the firm holds. We consider two diversification strategies, by location (at the state level) and by sector (at the property type) as similar diversification strategies may yield similar REITs’ returns. Additionally, we control for common economic shocks. For example, Cotter et al. (2015) suggest that performance across geographic locations can be highly correlated because certain MSAs are more exposed to macroeconomic shocks than their others. We follow Ling et al. (2017a) and use the proportion of the properties located in the 25 major MSAs to proxy for the common exposure to top markets of each REIT. The MSAs are Atlanta, Boston, Chicago, Dallas, Denver, Detroit, Houston, Indianapolis, Kansas City, Los Angeles, Miami, Minneapolis, New York, Orlando, Philadelphia, Phoenix, Portland, Sacramento, Saint Louis, San Antonio, San Diego, San Francisco, Seattle, Tampa, and Washington, D.C.
We can see that the spatial coefficient for the 25 km bandwidth is significantly positive and takes the value of 0.2 in Model 4.Footnote 12 It means that spatial linkages across the underlying assets of firms significantly drive the comovement across the non-market returns, controlling for systematic factors as well as company-specific characteristics. Model 4 also achieves higher adjusted R2 and lower BIC than the model without spatial consideration (Model 3), confirming significant spatial dependence in the abnormal returns. Given that one standard deviation of Wy is 0.0204, a one standard deviation increase in the abnormal return of ‘neighboring’ REITs is associated with 0.4% increase in the abnormal return of the REIT of interest.
Looking at Model 5, we see that the matrix based on 25 km bandwidth has the highest coefficient of 0.14. The matrix based on the bandwidth between 25 km and 125 km has a smaller but significant coefficient of 0.05. When the distance between the properties exceeds 125 km, we cannot find evidence for spatial dependence anymore. The decrease in the spatial dependence intensity with different bandwidths implies that the comovement in the abnormal returns declines with the distance of the properties held by the two firms. If we compare the goodness of fit between Models 4 and 5, we can see that although the adjusted R2 slightly increases by 0.0005 in Model 5, the BIC is also higher. The additional matrices do not significantly improve the goodness of fit. Therefore, we choose Model 4 as the baseline model.
The control variables have the expected signs but not all of them are significant. We can see that the lagged abnormal returns have a significant effect on current abnormal returns, however the sign is negative. A 10 percentage point increase in the abnormal return would lead to a drop of the abnormal returns in the next period by 0.7 percentage points. Although the effect is small, it is significant and shows that there is some systematic correction over time in the abnormal performance of REITs. This is in line with the assumptions of mean-convergence of the residuals. REITs receives higher abnormal return when they have higher exposure to the top 25 MSAs, consistent with the findings in Ling et al. (2017a).
There is a significantly positive relationship between the size of the company and its abnormal return even after controlling for size as a systematic risk factor. We can see that another important company characteristic, real estate investment growth, has a significantly negative effect on abnormal returns which is also in line with expectations. Small stocks should compensate for the risk exposure. The more the company grows its business, the lower the chances for any additional abnormal returns. The turnover ratio has a significant impact. The abnormal return is positively related to the trading volume of shares of the respective company.
Robustness Analysis
In order to make sure that the physical distance is the best way to capture the relationships in the companies and that the spatial weight matrix does not capture some other linkages or global comovements, we add an alternative weight matrix into the spatial panel model. Those additional weight matrices are based on the similarity in the size across firms, the similarity in their M/B ratios and the similarity in their momentum.Footnote 13 As Bernile et al. (2015) show, the geographic proximity of a firm’s headquarter can also explain the correlation in the abnormal returns. Therefore, we also construct a weight matrix which is defined based on whether the headquarters of each pair of companies are located in the same city.Footnote 14 Eq. (2) can be rewritten as:
The results are reported in Table 5. In all cases, the spatial dependence triggered by geographic proximity of the underlying assets remains significant, ranging from 0.1560 to 0.1957. The spatial coefficient of the additional weight matrix ranges from 0.0099 to 0.0751. Except for the weight matrix constructed based on M/B ratio, the remainder are insignificant. This is to show that geographic distance is not capturing other linkages between the companies such as similarities in size, performance or company location. Our measure of company linkages does a good job in capturing comovements as compared to more commonly used spatial measures. Also, it is a call to using spatial distance between underlying assets rather than the spatial linkages between the actual companies.
Concerns may arise as the real estate markets can perform quite differently in each MSA due to variations in local legislations and economies. Consequently, the estimated comovement may not be due to the closeness of the underlying assets but rather to these properties locating in the same region. In the baseline model, we have controlled for the exposure to the top 25 real estate markets. Nevertheless, the comovement might still be caused by a common exposure to regions with similar economic dynamics and industries. We follow Ling et al. (2017a) and account for the exposure to eight geographic regions (Northeast, Mideast, Southeast, East North Central, West North Central, Southwest, Mountain and Pacific) and construct firm-level geographic concentration measures pertaining to each region. The geographic exposure to the eight regions can be proxied by eight variables. Each variable is built based on the proportion of properties located in a given economic region for each firm. In this way, we construct the firm-level exposure to each economic region. However, the sensitivity of abnormal returns to regional common factors can be time-varying. To account for this, we use cluster-fixed time effects. In other words, instead of adding above eight variables, each regional exposure variable is split into 19 years (Model 10), with each variable equaling to the proportion for that year and zero otherwise. This way, we end up with 152 variables (19 × 8). We also perform the analysis with two other groupings as Ling et al. (2017a). One grouping is based on economic activities (Hartzell et al. 1986). We sort the 25 major MSAs into one of the following eight economic activity regions (New England; Mid-Atlantic Corridor; Old South; Industrial Midwest; Farm Belt; Mineral Extraction Area; Southern California; and Northern California). Similarly, we insert the interaction variables of exposure to eight regions and nineteen years. The exposure to eight regions is measured as the share of properties in each region during a given year (Model 11). As an alternative to economic regions, in Model 12, we also sort MSAs into seven industry clusters (Professional and Business; Government; Information and Finance; Leisure and Hospitality; Education and Health Services; Natural Resources, Construction, and Manufacturing; and Trade, Transportation, and Utilities). Additionally, instead of grouping the 25 MSAs into several regions, we insert an interaction variable of the exposure to each of the 25 MSAs and year dummies (Model 14). We also control for the exposure to the 50 most populous American downtownsFootnote 15 and add an interaction variable between the exposure to the major 50 CBDs and an year dummy. Finally, we also add a matrix based on the proportion of the properties held by the two firms that are located in the same MSA (Model 15).Footnote 16 If the comovement is purely triggered by common factors within one MSA rather than geographic distance, the coefficient for the distance based matrix would be insignificant if the MSA based weight matrix is added.
The results are reported in Table 6. In all cases, the spatial dependence by geographic proximity of the underlying assets remains significant. It ranges from 0.1636 to 0.2013. The spatial coefficient of the weight matrix based on the same MSA is insignificant. This shows that the weight matrix based on the geographic closeness of the underlying assets can capture the comovement between REITs abnormal returns more than the degree that can be explained by common shocks to regions with similar economic and industry bases.
Furthermore, we examine whether any movement still exists after we control for some of the local economic fundamentals such as rent or unemployment rate. In other words, whether the spatial spillover is just because of common exposure to local fundamentals. We proxy MSA level economic shocks using the local unemployment rate and housing returns during the period between 1996 and 2015. We collect unemployment rate data for over 300 MSAs from the Bureau of Labor Statistics and construct the weighted average unemployment rate that each firm’s exposure. The average unemployment rate for each firm is calculated as the proportion of properties in the MSA multiplied with the unemployment rate of that MSA (Model 16). Similarly, in Model 17, we control for an MSA level housing market shock by including the average housing return according to the housing return in each MSA and the exposure of each firm to that MSA. The MSA level housing return comes from Federal Housing Finance Agency.
Besides, we also control for local fundamentals in a more precise way. We calculate the average rent each firm received from their portfolio (Model 18) and the average occupancy of the properties that each firm holds (Model 19). If the returns are no more than just compensation for local exposure to tail risk, the comovement may not exist after controlling for firm level rents and occupancy rate. However, not all firms report the rent or occupancy of their properties, thus the number of observations is sharply reduced, as shown in Models 18 and 19 in Table 7. Even after explicitly controlling for local fundamentals, the results still show significant spatial dependence, ranging from 0.0977 to 0.1944. After the firm level rent is controlled for, the spatial dependence is reduced, which implies that a considerable proportion of spatial dependence could be explained by the similarity in rents. However, the spatial dependence coefficient still remains significant. Overall, the spatial dependence can capture the comovement in firm performance beyond what can be explained by local fundamentals.
Moreover, concerns may arise that REITs’ performance may be affected by the density of the local markets. REITs have higher exposure to markets with higher commercial real estate density may have better performance. We therefore control for the density of properties. We use the average number of properties located with a 25 km radius of each of property (Model 20, Table 7) to measure the density. The result is reported in Table 7. The coefficient for density is significant positive, confirming that investing in more dense locations can yield higher abnormal returns. The spatial dependence coefficient stays robust in all cases demonstrating that the spatial linkages capture different information from density.
Finally, we check for potential endogeneity between REIT’s returns and the weight matrix. One shortcoming of previous papers explaining the comovement across returns with common ownership is that institutional ownership can be endogenous to the model. Investment funds for example can choose to invest in stocks that have common fundamentals. Moreover, different funds can have correlated trading needs and thus naturally commove (Greenwood and Thesmar 2011). Our location-based measure of comovement is less striking because it is based on the location of properties. Although managers can choose the property location taking into account the surrounding properties and their managing companies, making a single spatial linkage endogenous to the model, it is hard to imagine that a company would base the location of its assets in its entire portfolio, which can be more than 100 assets, strategically accounting for spatial linkages of each pair. Due to the nature of the real estate market, most real estate companies albeit following certain investment strategy, take a more ad-hoc approach due to the illiquidity of the market. Therefore, across the entire property portfolio, a pair of firms will end up having an independent asset allocation.
We conduct three robustness checks for the endogeneity issue. First, we regress the abnormal return on lagged weighted abnormal returns (\( {\sum}_{j=1,j\ne i}^N{w}_{i,j,t-1}{\varepsilon}_{i,t-1}\Big) \) and lagged control variables
The second robustness check uses the property holdings in the initial period. In other words, we assume that firms keep a constant property portfolio over the entire estimation period. Under this scenario, as firms cannot change their property portfolio composition, they cannot strategically select the properties by observing the performance for other firms. We estimate thus the following model
The third robustness check adds a variable controlling changes in local supply. If managers can choose the property location taking into account the surrounding properties and their managing companies, the properties held by REITs in top performing markets will gradually increase while the properties purchased by REITs in poor performing markets will gradually decrease. We use the change in the property density to control for the change in local demand and supply. We include the variable of density of 25 km radius interacted with time dummies (Model 23, Table 7).
Table 8 reports the results. The spatial dependence coefficient slightly decreases from 0.19 in Model 4 to 0.17 in Model 21 and 0.14 in Model 22, but remain quite robust in Model 23. As the spatial dependence coefficient remains significant, the endogeneity issue is not severe and does not affect the findings in our analysis.
Trading Strategies
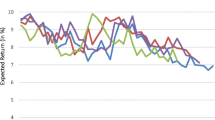
Given above findings, we propose a trading strategy that exploits the information in the locational comovements across the abnormal returns of all 115 U.S. REITs.Footnote 17 Similar trading strategies have been previously used to exploit the information contained in the linkages between companies resulting from fire sales of stocks related to common institutional ownership (Chen et al. 2012; Anton and Polk 2014). Chen et al. (2012) develop a trading strategy that benefits from the divergence in the prices of a pair of similar stocks. Anton and Polk (2014) present an investment strategy that identifies stocks that temporarily move together and profits from their eventual divergence in price. Our trading strategy is similar to the one in Anton and Polk (2014), however, we use the proximity in the location of companies’ underlying assets to measure how similar or different stocks are. If geographic proximity between properties can cause comovement in the returns of the companies that own those assets, our trading strategy would use the return of a portfolio consisting of the connected stocks to benchmark against. The difference in the returns would be used as a signal of the mispricing of the respective company. The strategy exploits upward and downward real estate price pressures channelled through the spatial proximity of the companies’ underlying assets. We examine the buy-and-hold non-market returns on two portfolios. The first portfolio consists of an equally-weighted portfolio of the worst performing (low-return) companies (33% lowest returns in the past 12 months). In addition, these companies also invest in properties which locate close to properties of other bad-performing companies (33% lowest returns in the past 12-months). We call this the LL portfolio which stays for for low own return (L) and low connected portfolio return (L). Respectively, the second portfolio consists of an equally-weighted portfolio of companies with high returns (33% highest returns in the last 12 months) that invest in properties located close to properties of other high-performing firms (33% highest returns in the past 12 months). We call this the HH portfolio, for high own return (H) and high connected portfolio return (H). We then show in Fig. 4 the non-market buy-and-hold portfolio cumulative returns over a period of 12 months. The alphas of the buy-and-hold portfolios are calculated by regressing the returns of each of the two portfolios on the common factors and extending the sample period by one period each time (Anton and Polk 2014). Figure 4 shows the cumulative non-market returns of the two portfolios. The cumulative alpha of the LL portfolio is negative and increasing in absolute value over time. The LL portfolio is consistently underperforming, delivering increasing negative alphas in every subsequent period. These findings suggest that stock prices of real estate companies are pushed away from fundamentals by the spatial dynamics of the underlying property portfolio and this pattern is persistent. We can see that using a portfolio of spatially connected stocks helps to detect mispriced companies. Similar to the findings in Anton and Polk (2014), we show that the misvaluation seems to be much larger in value and more prolonged in time than the standard short-term reversal effect.

Cumulative alphas for a connected-stock strategy. This figure graphs the non-market buy-and-hold performance of a trading strategy that exploits information about spatial linkages in the underlying assets of 115 real estate companies. The stocks are sorted into two portfolios – high own-return and high connected-return portfolio (HH), low own-return and low connected-return portfolio (LL) – based on independent quintile sorts on their own 12-month return and the 12-month return on their connected stock portfolio. We first measure the degree of connectedness by the distance between the properties as formalized in Eqs. (3)–(6). We then define the connected return as \( {\sum}_{j=1}^N{w}_{i,j,t}{\overset{\sim }{r}}_{j,t} \). We use equal-weighted firm returns. The figure plots the buy-and-hold cumulative alphas of the HH and LL portfolios as well as the difference between the high and low non-market returns (HH-LL). Returns are benchmarked against the four constructed factors as explained in the text
Given above findings, we construct composite portfolios that take into account the predictability of cross-sectional variation using the spatial linkages across the underlying assets. We construct 12-month buy-and-hold portfolios. We independently sort stocks according to their returns (own return) and the returns of a portfolio of companies which are connected to the stock of interest through their properties (connected portfolio return) over the past year. The connected portfolio return is calculated as \( {\sum}_{j=1}^N{w}_{i,j,t}{\overset{\sim }{r}}_{j,t} \). In total, we construct nine portfolios based on groupings at the 33th and 67th percentiles.Footnote 18 We have the following portfolios which consist of the own return and the connected portfolio return as follows: HH, HM, HL, MH, MM, ML, LH, LM, and LL. H, M and L stay for high, medium (or median), and low returns in the own or the connected portfolio domain respectively. We construct the high (low) portfolio using the 33% highest (lowest) returns of each category. HL for example means a portfolio consisting of the companies with the stocks having the 33% highest returns and the stocks of the firms they are connected to which fall within the bottom of the 33th return percentile. We then use the time series of returns of each of those nine composite portfolios to estimate the alphas in a four-factor model using the constructed factors. Table 9 shows the results.
We can see that the locational proximity of properties pushes the returns of portfolios of connected companies away from their fundamental values on both ends of the performance spectrum. The connected portfolio return is a good measure of the extent of mispricing. Similar to the observations in Fig. 4, the alphas of the nine composite portfolios decrease as we move from high to low connected portfolio returns within the own-return quantile and as we move from high to low own-return portfolios within the connected-return quantile. This is to show that the information contained in the connected portfolio returns is a useful predictor of the own return. Those results remain robust when we use different return quantiles and different factor model specifications. Therefore, we propose a long-short trading strategy (HH-LL strategy) which exploits the information in the connected returns. This HH-LL strategy buys the composite HH portfolio and sells the composite LL portfolio yielding a significantly positive alpha of about 0.8% per month. We can use above long-short hedge to exacerbate excess comovement stemming from the spatial linkages across the property holdings. An investment strategy which buys the stocks that experience an increase in their price if their connected stocks have also gone up and sells the stocks that experience a drop in their price if their connected stocks have also gone down can earn an average non-market return of 9.7% per year. This is in line with previous findings who report non-market returns from a long-short strategy extracting information from institutional ownership of 9% (Anton and Polk 2014) and 10% (Coval and Stafford 2007) per year.
This table reports the non-market returns of composite portfolios as well as of trading strategies exploiting the connectedness across property holdings of 115 real estate companies. We independently sort stocks into quantiles based on firm’s own return over the last year and the return on firm’s connected portfolio over the last year. We first measure the degree of connectedness using the distance of the properties as formalized in Eqs. (3)–(6). We then calculate the connected return as \( {\sum}_{\mathrm{j}=1}^{\mathrm{N}}{\mathrm{w}}_{\mathrm{i},\mathrm{j},\mathrm{t}}{\overset{\sim }{\mathrm{r}}}_{\mathrm{j},\mathrm{t}} \). Each composite portfolio is an equal-weighted average of the corresponding simple strategies. We also report the average returns on an HH-LL trading strategy that buys the high own-return and high connected-return composite portfolio (HH) and sells the low own-return and low connected-return composite portfolio (LL).
Conclusion
We show that spatial linkages between property holdings of real estate firms matter for the performance of those companies as the former contain additional information that is not captured by common factors. We model spatial comovement across abnormal returns of real estate companies to show that spatial linkages have a significant explanatory power for firm performance. We connect the stocks using the location of their real estate portfolios. We show that the degree of spatial comovement explains the variation in abnormal returns, controlling for exposure to systematic return factors, style and sector similarity, and range of other individual and pair characteristics. We then use this information to design a long-short trading strategy by grouping real estate firms into composite portfolios based on the spatial linkages of the properties. The investment strategy exploits information contained in the spatial linkages across the companies’ properties to extract a non-market return. An investment strategy which sells the stocks that experience a drop if their connected stocks have also gone down and buys the stocks that experience an increase if their connected stocks have also gone up can earn a non-market return of nearly 10% per year.
Notes
A more general form of unbalanced spatial panel model is: \( {\varepsilon}_{i,t}=a+{b}_0{\varepsilon}_{i,t-1}+\rho {\sum}_{j=1,j\ne i}^N{w}_{i,j,t}{\varepsilon}_{i,t}+\delta {\sum}_{j=1,j\ne i}^N{w}_{i,j,t-1}{\varepsilon}_{i,t-1}+{\sum}_{k=1}^K{b}_k control{s}_{k,i,t}+{u}_{i,t} \). The results are reported in Table 10 in the Appendix. The conclusions of the study remain robust with different forms of spatial model.
Results based on average weights are reported in Table 10, Model 2 in the Appendix.
Results based on 202 firms are shown in Table 10 in Model 3 in the Appendix. The spatial coefficient is even higher. This is because REITs investing only in the domestic market tend to show higher correlation among each other as compared to REITs that hold properties internationally. The high correlation can be explained by the shorter distance across the properties but it can also be explained by differences in the dynamics of domestic versus international markets. Therefore, in the baseline estimations, we only use REITs that invest in the domestic market.
Given that there is variation across the number of firms over time, we estimate an unbalanced panel model as explained in Section II. The advantage of using an unbalanced panel regression is to avoid the survival bias. The specification of an unbalanced sample of spatially-weighted returns may create some concerns if the cross-sectional distribution of stocks is not constant. Therefore, we also estimate the baseline model based on 27 REITs with complete data over the entire sample period using a balanced spatial panel regression. As shown in Table 10 in Model A4 in the Appendix, the results remain robust.
By ‘connected’ firms we mean the companies which own properties in a proximity on less than 25 km to each other.
These are the HH portfolios in Table 8.
The grouping of firms into HH and LL categories in explained in more detail in Section IV.
These are the LL portfolios in Table 8.
The results based on the residuals using the existing factors are robust. They are shown in Table 10 in the Appendix. The estimated comovement is much higher in this case than when using the constructed factors. This implies that real estate specific factors can eliminate the comovement in the abnormal returns and capture some of the idiosyncratic risk.
Detailed information about the construction of these alternative weight matrices is provided in the Appendix.
Detailed information about the construction of this weight matrix is provided in the Appendix.
We collect the zip-code for each downtown and match the location of the properties using their zip-code. The full list of the 50 major downtowns can be found in https://en.wikipedia.org/wiki/Downtown
Detailed information about the construction of these alternative weight matrices is in the Appendix.
In the spatial panel regression analysis, we have 74 firms due to missing values of some dependent variables. In the portfolio analysis, we use all 115 firms which invest in the US only and for which locational data is available.
A portfolio constructed based on the median provides consistent results (see Table 11 in the Appendix).
References
Adams, Z., Füss, R., & Schindler, F. (2015). The sources of risk spillovers among U.S. REITs: Financial characteristics and regional proximity. Real Estate Economics, 43, 67–100.
Alcock, J. and E. Steiner. (2016) Fundamental drivers of dependence in real estate securities returns. Journal of real estate finance and economics forthcoming.
Ambrose, B., Ehrlich, S., Hughes, W., & Wachter, S. (2000). REIT economies of scale: Fact or fiction? The Journal of Real Estate Finance and Economics, 20, 211–224.
Anselin, L. (1988). Spatial econometrics: Methods and Models. Studies in operational regional science. Dordrecht: Springer.
Anselin, L. (2003). Spatial externalities, Spatial Multipliers and Spatial Econometrics. International Regional Science Review, 26, 153–166.
Anton, M., & Polk, C. (2014). Connected stocks. Journal of Finance, 69, 1099–1127.
Asgharian, H.,Hess, W., & Liu L. (2013). A Spatial Analysis of International Stock Market Linkages. Journal of Banking and Finance, 37, 4738–4754.
Baltagi, B. H., Bresson, G., & Etienne, J. M. (2015). Hedonic housing prices in Paris: An unbalanced spatial lag pseudo-panel model with nested random effects. Journal of Applied Econometrics, 30(3), 509–528.
Barberis, N., & Shleifer, A. (2003). Style investing. Journal of Financial Economics, 68, 161–199.
Barberis, N., Shleifer, A., & Wurgler, J. (2005). Comovement. Journal of Financial Economics, 75, 283–317.
Barclay, M. J., Heitzman, S. M., & Smith, C. W. (2013). Debt and taxes: Evidence from the real estate industry. Journal of Corporate Finance, 20, 74–93.
Barinov, A. (2014). Turnover: Liquidity or uncertainty? Management Science, 60(10), 2478–2495.
Becker, B., Cronqvist, H., & Fahlenbrach, R. (2011). Estimating the effects of large shareholders using a geographic instrument. Journal of Financial and Quantitative Analysis, 46, 907–942.
Bernile, G., Kumar, A., & Sulaeman, J. (2015). Home away from home: Geography of information and local investors. Review of Financial Studies, 28(7), 2009–2049.
Bond, S., & Xue, C. (2017). The cross section of expected real estate returns: Insights from investment-based asset pricing. Journal of Real Estate Finance and Economics, 54(3), 403–428.
Campbell, J., Giglio, S., & Pathak, P. (2011). Forced sales and house prices. American Economic Review, 101(5), 2108–2131.
Capozza, D. R., & Seguin, P. J. (1998). Managerial style and firm value. Real Estate Economics, 26, 131–150.
Capozza, D. R., & Seguin, P. J. (1999). Focus, transparency, and value: The REIT evidence. Real Estate Economics, 27, 587–619.
Carhart, M. M. (1997). On persistence in mutual fund performance. Journal of Finance, 52, 57–82.
Chegut, A. M., Eichholtz, P. M. A., & Rodrigues, P. J. M. (2014). Spatial dependence in international office markets. Journal of Real Estate Finance and Economics, 51(2), 317–350.
Chen, H., S. Chen and F. Li. (2012) Empirical investigation of an equity pairs trading strategy. Working Paper, University of British Columbia.
Cheok, S. M. C., Sing, T. F., & Tasi, I.-C. (2011). Diversification as a value-adding strategy for Asian REITs: A myth or reality? International Real Estate Review., 14, 184–207.
Chung, R., Fung, S., Shilling, J. D., & Simmons-Mosley, T. (2011). What determines stock price synchronicity in REITs? Journal of Real Estate Finance and Economics, 43, 73–98.
Cotter, J., Gabriel, S., & Roll, R. (2015). Can housing risk be diversified? A cautionary tale from the housing boom and bust. Review of Financial Studies, 28(3), 913–936.
Coval, J., & Moskowitz, T. (2001). The geography of investment: Informed trading and asset prices. Journal of Political Economy, 109, 811–841.
Coval, J., & Stafford, E. (2007). Asset fire sales (and purchases) in equity markets. Journal of Financial Economics, 86, 479–512.
DiPasquale, D., & Wheaton, W. (1995). Urban economics and real estate markets. Upper Saddle River: Prentice Hall.
Eichholtz, P. M. A., Hoesli, M., MacGregor, B. D., & Nanthakumaran, N. (1995). Real estate portfolio diversification by property type and region. Journal of Property Finance., 6, 39–59.
Fama, E., & French, K. (1993). Common risk factors in the returns on stocks and bonds. Journal of Financial Economics, 33, 3–56.
Fama, E., & French, K. (2012). Size, value, and momentum in international stock returns. Journal of Financial Economics, 105, 457–472.
Fazio, G. (2007). Extreme interdependence and extreme contagion between emerging markets. Journal of International Money and Finance, 26, 1261–1291.
Fingleton, B. (2001). Equilibrium and economic growth spatial econometric models and simulations. Journal of Regional Science, 41, 117–141.
Fingleton, B. (2008). A generalized method of moments estimator for a spatial model with moving average errors, with application to real estate prices. Empirical Economics, 34, 35–57.
Fostel, A., & Geanakoplos, J. (2008). Leverage cycles and the anxious economy. American Economic Review, 98(4), 1211–1244.
Fu, R., & Gupta-Mukherejee, S. (2014). Geography, informal information flows and mutual fund portfolios. Financial Management, 43(1), 181–214.
Fujita, M., & Thisse, J.-F. (2003). Economics of agglomeration: Cities, industrial location, and globalization. Cambridge University Press.
Geanakoplos, J. (2009) The leverage cycle, In NBER macroeconomics annual, 24, ed. by D. Acemoglu, K. Rogoff, and M. Woodford. Chicago: University of Chicago Press, 1–65.
Greenwood, R., & Thesmar, D. (2011). Stock price fragility. Journal of Financial Economics, 102, 471–490.
Gyourko, J., & Nelling, E. (1996). Systematic risk and diversification in the equity REIT market. Real Estate Economics, 24, 493–515.
Haining, R. (2003). Spatial data analysis: Theory and practice. Cambridge: Cambridge University Press.
Hartzell, D. J., Heckman, J., & Miles, M. (1986). Diversification categories in investment real estate. AREUEA Journal, 14(2), 230–254.
Hartzell, J. C., Sun, L., & Titman, S. (2014). Institutional investors as monitors of corporate diversification decisions: Evidence from real estate investment trusts. Journal of Corporate Finance, 25, 61–72.
Holly, S., Pesaran, M. H., & Yamagata, T. (2011). The spatial and temporal diffusion of house prices in the UK. Journal of Urban Economics, 69(1), 2–23.
Hong, H., Kubik, J. D., & Stein, J. C. (2005). Thy Neighbor’s portfolio: Word-of-mouth effects in the holdings and trades of money managers. Journal of Finance, 60, 2801–2824.
Hong, H., Kubik, J. D., & Stein, J. C. (2008). The only game in town: Stock-price consequences of local Bias. Journal of Financial Economics, 90, 20–37.
Kurlat, P. (2016). Asset markets with heterogeneous information. Econometrica, 84(1), 33–85.
LeSage, J. & Pace, R.K. (2009). Introduction to Spatial Econometrics. Boca Raton, Florida: Chapman & Hall/CRC.
Ling, D. C, A. Naranjo and B. Scheick (2017a) Asset location, timing ability, and the cross-section of commercial real estate returns. Real Estate Economics, forthcoming.
Ling, D. C, A. Naranjo and B. Scheick (2017b) There’s no place like home: local asset concentration, information asymmetries and commercial real estate returns. Working Paper.
Miao, H., Ramchander, S., & Simpson, M. C. (2011). Return and volatility transmission in U.S. Housing Markets. Real Estate Economics, 39, 701–741.
Milcheva, S., & Zhu, B. (2016a). Bank integration and co-movements across housing markets. Journal of Banking & Finance, 72, S148–S171.
Milcheva, S., & Zhu, B.(2016b) Spatial Linkages in Listed Property Returns in Tranquil and Distressed Periods. Journal of Real Estate Portfolio Management, 22(2), 129–146.
Nappi-Choulet, I., & Maury, T. P. (2009). A spatiotemporal autoregressive price index for the Paris office property market. Real Estate Economics, 37(2), 305–340.
Orlov, A. G. (2009). A Cospectral analysis of exchange rate Comovements during Asian financial crisis. Journal of International Financial Markets, Institutions & Money, 19, 742–758.
Pace, R. K., Barry, R., Clapp, J. M., & Rodriquez, M. (1998). Spatiotemporal autoregressive models of neighborhood effects. The Journal of Real Estate Finance and Economics, 17(1), 15–33.
Pirinsky, C., & Wang, Q. (2006). Does Corporate Headquarters location matter for stock returns? The Journal of Finance, 61, 1991–2015.
Tu, Y., Yu, S. M., & Sun, H. (2004). Transaction-based office price indexes: A spatiotemporal modeling approach. Real Estate Economics, 32(2), 297–328.
Zhu, B., & Milcheva, S. (2016). Spatial linkages in listed property returns in tranquil and distressed periods. Journal of Real Estate Portfolio Management, 22(2), 129–146.
Zhu, B., Füss, R., & Rottke, N. (2011). The predictive power of anisotropic spatial correlation modeling in housing prices. Journal of Real Estate Finance and Economics., 42(4), 542–565.
Zhu, B., Fuess, R., & Rottke, N. (2013). Spatial linkages in returns and volatilities among US regional housing markets. Real Estate Economics, 41, 29–64.
Author information
Authors and Affiliations
Corresponding author
Appendix
Appendix




The locations of the properties owned by individual listed real estate firms in US as of 2015 (Ticker code of the company used as the heading of each graph)
Definition of Alternative Spatial Linkages
Similarity in size
In addition to geographic closeness of the underlying assets, comovement can also arise due to the similarity of the characteristics of the firms. We follow Asgharian et al. (2013) and construct the matrix according to the similarity in size:
where Sizei,t is the market capitalization of firm i in period t. \( {F}_{i,j,t}^{size} \) measures the proximity of the size between two firms i and j.
Similarity in M/B ratio
We also construct the matrix according to the similarity in Market to Book ratio of the two firms:
where MBi,t is the market to book ratio of firm i in period t. \( {F}_{i,j,t}^{MB} \) measures the proximity of the size between two firms i and j.
Similarity in Momentum
We also construct the matrix according to the similarity in previous return of the two firms:
where Ri,t is the average return of firm i in the past year.
The above three kinds of F matrix is then converted to a contiguity matrix C as:
C matrix is then standardized to matrix W so that for each i, ∑j, twi, j, t = 1.
Closeness of Headquarters
We also construct weight matrix according to the headquarter location, which is defined as
Then F matrix is then standardized to matrix W so that for each i, ∑j, twi, j, t = 1. This headquarter location matrix can also be defined according to the criteria of whether the headquarters are within the same MSAs, the results are similar.
Continuity definition using MSA
We also use alternative ways to define the location of the underlying assets. For example, in Eq. (4), instead of using a bandwidth of 25 km, we use a dummy variable for whether the two properties are in the same MSAs:
and then we use the minimum proportion of the underlying properties in the same MSA for the two firms:
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Zhu, B., Milcheva, S. The Pricing of Spatial Linkages in Companies’ Underlying Assets. J Real Estate Finan Econ 61, 443–475 (2020). https://doi.org/10.1007/s11146-018-9666-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11146-018-9666-z