
Abstract
Purpose
To evaluate the psychometrics of the SF-36 Health Survey among Turkish and Moroccan ethnic minority populations in the Netherlands and to compare the results to those based on the indigenous Dutch population.
Methods
Data were derived from the Second Dutch National Survey of General Practice. In total, SF-36 data were available for 409 Turkish, 377 Moroccan, and 9,628 Dutch respondents. Language subgroup analyses were performed for the Turkish (n = 162) and Moroccan-Arabic (n = 52) versions of the SF-36. Psychometric properties were evaluated by descriptive statistics, factor analysis, internal consistency estimates, known-group comparisons, and differential item function (DIF) analysis.
Results
Low levels of missing SF-36 data were observed across all groups. Confirmatory factor analysis supported the hypothesized SF-36 scale structure for the Dutch and Turkish group, but high correlations between the MH and VT factors were observed in the Moroccan group. All Cronbach’s alpha coefficients were above 0.70, except for the Vitality scale in the Moroccan group and the Vitality and Social Functioning scales in the Moroccan-Arabic language subgroup. Known-groups validity was found across samples using age, sex, education, and comorbidity as grouping variables, but not marital status. Some evidence for DIF was found in both ethnic group samples.
Conclusions
The results generally support the use of the SF-36 for general population research among Turkish and Moroccan ethnic minorities in the Netherlands. Additional studies are needed to confirm the psychometrics of the questionnaire when used among these populations in other Western European countries.
Similar content being viewed by others

Avoid common mistakes on your manuscript.
Introduction
The Medical Outcomes Study SF-36-Item Short Form Health Survey (SF-36) is one of the most widely used health status questionnaires worldwide [1]. The SF-36 was originally developed in the United States in the late 1980s for a longitudinal investigation into the self-reported health status of general populations and patients with a wide range of chronic conditions [2]. Interest in the SF-36 has grown steadily, and it has been translated and psychometrically evaluated in more than 50 languages (www.sf-36.org), including non-western cultures and ethnic minorities within countries.
There are currently approximately 2.8 million Turkish and 1.2 million Moroccan immigrants living in Western Europe [3]. In the Netherlands, approximately 10% of the total population (1.8 million) is of non-western immigrant origin, of which Turkish and Moroccan immigrants constitute (together with Suriname and Antillean/Aruban immigrants) the major groups. In 2008, 2.3% of the total population was of Turkish descent (i.e., at least one parent born in Turkey) and 2.0% of Moroccan descent. Of these groups, 52 and 55%, respectively, were not born in the Netherlands and are first generation immigrants. It is expected that the number of non-western immigrants to the Netherlands will continue to increase reaching 2.7 million in 2050 [4].
Both Turkish and Moroccan immigrant groups, while clearly having some distinct cultural characteristics, come from an Islamic background, tend to be poorly educated, and come from primarily rural areas of their home country. They are of particular interest from the perspective of cultural adaptation and translation of health-related quality of life (HRQL) questionnaires in that, in comparison with other immigrant groups from former Dutch colonies (Suriname and the Antilles), they typically have no background in or exposure to the Dutch culture or language prior to their arrival in the Netherlands.
Interest in assessing the self-reported health status and HRQOL of Turkish and Moroccan immigrants is increasing. Not only are these ethnic minority populations growing, but also the first generation of immigrants is now reaching the age at which the incidence of chronic disease rises sharply. In 2003, there were 26,164 Turkish and 22,953 Moroccans over the age of 55 living in the Netherlands. These numbers are expected to rise to about 46,017 and 40,666, respectively, by 2015 [5].
The inclusion of Turkish and Moroccan immigrants in HRQOL research, and particularly those of the first generation, is hampered by two primary factors. First, the majority of first generation Turkish and Moroccan immigrants do not speak the language of their host countries. As a consequence, they are not able to complete HRQOL questionnaires in the available Western European translations. In the Netherlands, 60% of the Turkish and Moroccan immigrants above 55 years of age have difficulties speaking Dutch [6]. Second, there is a high illiteracy rate among these first generation cohorts. In the Netherlands, 70% of the Turkish and 90% of the Moroccan immigrants above 55 years of age have had no formal education [6]. These factors need to be taken into consideration when choosing the language (i.e., oral vs. official, written) and mode of administration (i.e., oral vs. written) of HRQOL measures to be used in these populations.
In 2006, the Turkish version of the SF-36 and two translated versions in oral Moroccan languages (Moroccan-Arabic and Tarifit, in phonetic Arabic and Latin script respectively) were culturally adapted and psychometrically evaluated for the use among Turkish and Moroccan ethnic minority patients with cancer in the Netherlands [7]. In this study, the original scale structure of the SF-36 and the internal consistency reliability were confirmed. The questionnaire distinguished clearly between subgroups formed on the basis of performance status and was responsive to change in performance status over time. Some evidence of differential item function (DIF) was found between the Turkish and Moroccan translations, and the Dutch version of the SF-36. The study supported the use of the SF-36 in both ethnic groups of patients with cancer. However, these translated versions have not yet been assessed and evaluated among the general (healthy) Turkish and Moroccan population in the Netherlands.
The aim of this study was to psychometrically evaluate the Dutch, Moroccan-Arabic, and Turkish versions of the SF-36 [7, 8] for use among general Turkish and Moroccan ethnic minority populations in the Netherlands. The psychometric results based on these ethnic minority groups were also compared with those based on data from the indigenous Dutch general population.
Methods
The SF-36
The SF-36 (version 1.0) is composed of 36 questions with standardized response options. The questions are organized into eight multi-item scales: physical functioning (PF), role limitations due to physical problems (RP), bodily pain (BP), general health perceptions (GH), vitality (VT), social functioning (SF), role limitations due to emotional problems (RE), and general mental health (MH). One additional item assesses health transition (HT). Response categories are of the Likert-type, ranging from two to six categories. Both a ‘standard’ version (employing a 4 week time frame) and ‘acute’ version (employing a 1 week time frame) are available [1, 2, 9]. In this study, the ‘standard’ version was used.
The Dutch and Moroccan-Arabic versions of the SF-36 were translated from the original English version following standard SF-36 guidelines [7, 8, 10, 11]. The Turkish version, originally developed in Turkey [12], was linguistically and culturally adapted for use among Turkish immigrants living in the Netherlands [7]. The translation into Moroccan-Arabic, an oral language, was done in phonetic Arabic script to make it appropriate for interviewer administration [7].Footnote 1
Data collection
The data were collected in 2001 as part of the Second Dutch National Survey of General Practice (DNSGP2), which is part of a longitudinal, nationwide health monitoring system [13]. The DNSGP2 study was carried out in 104 general practices (stratified by region, level of urbanization and practice type) throughout the Netherlands. All 385,461 patients registered in these practices were sent a one-page questionnaire in four languages that included sociodemographic information (age, sex, education, country of birth, etc.) and an informed consent form. A total of 294,999 patients returned the questionnaire (response rate = 76.5%). From this respondent pool, cohorts were formed from the indigenous Dutch general population and the four ethnic minority groups (Turkish, Moroccan, Surinamese, and Antillean) for the purpose of a 90-min health interview.
The self-reported, computer-assisted, home-based health interview was planned for an approximate 5% random sample of the indigenous Dutch cohort. In total, 12,699 of the 19,685 Dutch individuals who were invited to participate in the interview did so (response rate = 64.5%). Of these 12,699 individuals, 9,628 were 18 years of age or older and included in the current analysis.
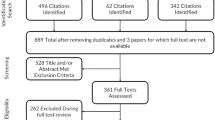
From those who returned the initial study form (294,999), 11,540 were from one of the four ethnic minority groups, of whom 7,355 were 18 years of age or older. From both the Turkish and Moroccan groups, a sample of 1,200 individuals was drawn at random. Individuals from these random samples were invited to participate in the study until approximately 400 respondents per group had been recruited. In total, 862 Turkish immigrants and 848 Moroccan were invited, of whom 409 (response rate 47%) and 377 (response rate 44%) individuals, respectively, participated (Fig. 1).

Overview of sampling and response of the Turkish and Moroccan groups
These respondents could choose to undergo the health interview in a language for which a SF-36 translation was available: Dutch, Turkish, Moroccan-Arabic, or English. If the respondent was not proficient in one of these languages, but spoke another language such as Berber (for Moroccans) or Kurdish (for Turks), the interviewer translated the questionnaire in real time. All questionnaire data collection among the Turkish and Moroccan respondents was interview-based and was computer-administered by the interviewer.
In the DNSGP2 survey, to facilitate efficient administration of the SF-36, a “routing” algorithm was employed for the PF and the BP scales. Specifically, for the PF scale, if respondents reported no limitations for items PF1 (vigorous activities), PF4 (climbing several flights of stairs), PF7 (walking more than a kilometer), and PF8 (walking a few hundred meters), the items PF2 (moderate activities), PF5 (climbing one flight of stairs), and PF9 (walking 100 m) were respectively skipped. In the analysis, these skipped items were coded as having the response ‘no, not limited at all’. For the BP scale, respondents skipped the item BP2 (Did pain interfere with your normal social activities) if they had answered ‘none’ to item BP1 (how much bodily pain did you have in the past 4 weeks?). In these cases, for the purposes of analysis, the BP2 item was coded as ‘not at all’. Finally, in the original SF-36, the SF2 item (physical or emotional problems interfering with social activities) has five response options. In the DNSGP2 survey, the response category ‘most of the time’ was split into two response options: ‘often’ and ‘most of the time.’ For the analysis, these two response categories were combined to parallel the original five-level response scale.
Statistical analyses
Group and subgroup analysis
The indigenous Dutch sample (n = 9,628) was analyzed as one group. For the ethnic minority groups, the analysis was performed at two levels. First, the groups were formed based on culture. The analyses were conducted for the total Turkish (n = 409) and Moroccan (n = 377) samples, regardless of the language in which the SF-36 was administered (Dutch, English or in one of the mother tongue languages). These results represent the validation of the SF-36 in these cultural groups and can be considered as representative for how SF-36 data will be collected in future studies of these groups in the Netherlands. Second, subgroup analyses were performed at the language level. The analyses were performed for the Turkish and Moroccan groups that had completed the Turkish (n = 162) or Moroccan-Arabic (n = 52) language versions of the SF-36. These results represent the validation of the Turkish and Moroccan language versions of the SF-36.
As the language of administration was not systematically recorded in the DNSGP2 study (2001), we formed the language subgroups (Turkish and Moroccan-Arabic) on the basis of two assumptions: (1) we assumed that language proficiency in Dutch might have increased over time, but not decreased. The language used in a follow-up survey, performed 4 years later, in 2005, was recorded. All respondents who chose the Turkish or Moroccan language versions in 2005 were included in the language subgroups, but respondents who chose the Dutch SF-36 language version in 2005 were not included in the language subgroups, even though they might not have been proficient in Dutch in 2001. Based on this decision rule, 86 Turkish and 15 Moroccan respondents could be identified, who were assumed to have completed the SF-36 in Turkish or Moroccan-Arabic during the first survey; (2) respondents were assumed to have chosen to be interviewed in Turkish or Moroccan-Arabic if they indicated in the background questionnaire (in 2001) that they had no or only very limited proficiency in the Dutch language, that Turkish or Moroccan-Arabic was their native language and that they were proficient in that language.
Statistical analyses
All SF-36 scale scores were transformed linearly to a scale from 0 to 100, with 0 and 100 representing the least and most favorable health outcomes respectively.
Descriptive statistics were generated to evaluate the missing questionnaires, missing items, score distributions, and floor and ceiling effects. Missing were accounted for according to the standard scoring algorithm of the SF-36. Scale scores were calculated on the basis of the mean scores of the available items. If 50% or more of the items were missing, the scale score was not calculated.
Confirmatory factor analyses for ordered categorical variables were performed in Mplus using the method of weighted least squares with mean and variance adjustment (WLSMV). The comparative fit index (CFI), Tucker-Lewis index (TLI), and the root mean square error of approximation (RMSEA) were used as measures for model fit. A CFI and TLI of >0.95 and a RMSEA of <0.05 were considered as adequate fit.
Internal consistency reliability of the multi-item scales was assessed by Cronbach’s coefficient α. A value of 0.70 or greater was considered as adequate for the purposes of group comparisons.
Known-groups validity was evaluated by comparing subgroups of patients known to differ on relevant background variables. Mean differences (i.e., the mean for the group where higher scores were expected minus the mean for the group where lower scores were expected) and effect sizes (i.e., mean difference divided by the standard deviation of the group where higher mean scores were expected) were calculated for all scales. In all groups, it was hypothesized that those respondents who were male, younger, married (or having a registered partnership), who had a higher level of education, and who had no or only one comorbid condition would have significantly higher SF-36 scores than those who were female, older, not married, lower educated and with two or more comorbid conditions. It was hypothesized that the observed differences in mean scores between groups formed on the basis of age and comorbidity would be larger for the physical health scales (PF, RP, BP, and GH scale) than for the mental scales (VT, SF, RE and MH) and that the mean differences between groups formed on the basis of marital status would be larger for the mental health scales. We also hypothesized that the largest mean differences would be observed on the basis of comorbidity grouping, and the smallest differences on the basis of marital status grouping. Finally, we hypothesized that the indigenous Dutch sample would generally score higher on the SF-36 than either the Turkish or the Moroccan samples.
Differential item functioning (DIF) was evaluated to test the equivalence of the outcome of the Turkish and Moroccan cultural (language) samples to that of the indigenous Dutch sample. We tested for both uniform and nonuniform DIF for all items from the eight SF-36 scales using ordinal regression analysis [14]. We first tested for nonuniform DIF by modelling the item response as a logit-linear function of ethnic group (Dutch vs. Turkish, or Dutch vs. Moroccan), the scale score, and the interaction between ethnic group and scale score. The interaction term represents the possible nonuniform DIF. Nonuniform DIF (indicating that the magnitude and direction of ethnic group differences in item scores varies as a function of the overall scale score) was considered to be present when the interaction term was significant, with a P-value less than 0.001. Uniform DIF was tested by modeling the item response as a logit-linear function of the ethnic group and the scale score, with the translation term representing possible uniform DIF. Uniform DIF (testing the direction and magnitude of ethnic group differences in item scores) was considered to be present if the odds ratio of the ethnic group term was outside the interval 0.53–1.89 (log odds ratio β numerically larger than 0.64) [15]. All analyses were corrected for sex, age, and comorbidity.
Results
Sample background characteristics
Compared to the Dutch respondents, the total Turkish and Moroccan respondent groups were generally younger, had less formal education, and were more often married (Table 1). The Turkish and Moroccan-Arabic language subgroups consisted of relatively more women and elderly, and had lower education and more comorbid conditions compared to the total Turkish and Moroccan groups.
Descriptive statistics
Complete SF-36 data were available for all Turkish and Moroccan respondents. In the Dutch sample, 8 questionnaires could not be analyzed due to a large number of missing items. At the item level, on average, 0.22% (range 0–2.0%) of the individual questionnaire items was missing in the Turkish sample, 0.22% (range 0–3.7%) in the Moroccan sample, and 0.13% (range 0–0.21%) in the Dutch sample. The full range of scores was observed for the 8 SF-36 scales, with the exception of the GH and VT scales in the Moroccan sample (Table 2). Relatively high ceiling or floor effects were observed for the RE and RP scales in all three samples (Table 2).
Factor analysis
In the Dutch sample, the factor structure had an adequate fit (CFI 0.963, TLI 0.992, RMSEA 0.058). In the Turkish sample, the model had a borderline fit (CFI 0.961, TLI 0.989, RMSEA 0.080). In the Moroccan sample, we first found a nonadmissible solution, i.e., nonpositive definiteness of the factor correlation matrix. There was also a negative residual variance for item RE1 and a high correlation of the factor vitality with mental health (0.98). After some restrictions (correlation between factor VT and MH fixed at 0.95 and error variance of item RE1 fixed at 0.05), the model fit was borderline (CFI 0.965, TLI 0.983., RMSEA 0.083). The only item that did not fit well was item VT1 [(estimated) loading 0.155] (Table 3). This item correlated with VT2, but not with the other items.
Internal consistency reliability
Cronbach’s alpha coefficients for the eight SF-36 scales were above 0.70 for all samples, with the exception of the VT scale in the total Moroccan sample (α = 0.61) and the VT (α = 0.54) and the SF (α = 0.63) scales in the Moroccan-Arabic language subgroup (Table 2).
Known-groups validity
A summary of the results of the known-groups validity analyses are presented in Table 4. The hypothesis that respondents who were male, younger, married, more highly educated, and having no or only one comorbid condition would report a better health status as assessed by the SF-36 (in total, 40 comparisons) was confirmed for 80% in the Turkish sample, 60% in the Moroccan sample, and 95% in the Dutch sample. The hypothesis that married respondents would have significantly higher SF-36 scores than unmarried respondents was not confirmed for any of the SF-36 scales in the Turkish or Moroccan samples.
The hypothesis that the mean differences between age and comorbidity subgroups would be larger for the physical health scales than for the mental health scales of the SF-36 (16 comparisons each) was confirmed in 75–100% of the cases in the three study samples. The hypothesis that the mean differences between the marital status groups would be larger for the mental health scales than for the physical health scales could not be confirmed in the Moroccan group.
The hypothesis that the largest observed mean differences would be between comorbidity subgroups and the smallest between marital status subgroups (32 comparisons) was confirmed in the large majority of cases (84–100%) in all three study samples.
Finally, as hypothesized, the Dutch sample reported better health outcomes than the total Turkish group (for all scales) and the total Moroccan group (except for the PF and the RP scales, where the differences were not statistically significant, data not presented in tabular form).
DIF analyses
The results of the DIF analyses are summarized in Table 5. In the total Turkish sample, nonuniform DIF was found for 6 items (PF1, PF2, GH1, VT1, MH3, and MH5). In the total Moroccan sample, non-uniform DIF was found for 3 items (PF1, GH1, and MH3).
Uniform DIF was observed for 7 items in the total Turkish and Moroccan samples. The PF1, VT4, and RE1 showed uniform DIF in both ethnic groups. High odds ratios (odds ratio and confidence interval outside the range 0.53–1.89) were found in the Turkish sample for the items PF1 and PF7. In the Moroccan sample, high odds ratios were found for the items VT1 and VT3.
In the language subgroups, similar patterns (OR above or below 1) of uniform DIF were found (for 86% of the items in the Turkish subgroup and 80% of the items in the Moroccan subgroup). Nonuniform DIF was found in 7 items (5 similar items) in the Turkish subgroup and 1 (similar item) in the Moroccan-Arabic subgroup.
Discussion
In this paper we have reported the results of a study of the psychometric properties of the SF-36 Health Survey when employed among Turkish and Moroccan ethnic minority groups in the Netherlands, and compared to individuals from the indigenous Dutch population.
Descriptive statistics
In the Turkish and Moroccan samples, the number of missing items was very low (mean of less than 1%) and was comparable to rates found in other studies in which the SF-36 was administered as a (telephonic) interview in non-Western samples. [16–20]. Higher rates of missing data (3–4.5%) were observed in the study of Hoopman et al. [7], in which the SF-36 was administered (primarily in interview form) to Turkish and Moroccan patients diagnosed with cancer in the Netherlands. The higher (but still low) rates of missing data observed in the latter study may be due to the fact that, in that study, interviewers were explicitly instructed to be restraint in explaining any items to the respondents or to assist in any way in completing the questionnaire. Such stringent administrative rules are not always applied in survey research.
Factor analysis
The scale structure of the SF-36 fit well in the Dutch and Turkish groups. In the Moroccan group, the expected structure did not fit well, as the MH and VT scale were highly correlated, indicating that they are not discerning factors. After the correction (where this correlation was “allowed”), the model fit was improved.
The only item that did not fit well into the scale was item VT1. This corresponds with the finding of uniform DIF for this item in this study and in our previous study on patients with cancer [7]. Item VT1 also showed low item convergent and item discriminant validity (using multitrait scaling analysis) in the Moroccan group in the previous study of Hoopman et al. [7].
Internal consistency reliability
The internal consistency reliability of the SF-36 scales was satisfactory for all 3 samples, with the exception of the VT scale in the total Moroccan group and the VT and SF scales in the Moroccan-Arabic language subgroup. The less-than-satisfactory results for the VT scale were also reported in a study of Moroccan ethnic minority patients with cancer [7].
Known groups validity
The majority of the know groups comparisons yielded results consistent with what had been hypothesized. In the Turkish and Moroccan samples, no significant differences were observed in SF-36 scores as a function of marital status. This lack of association between marital status and health status has also been reported in studies in Lebanon [19], Greece [21], and Morocco [18].
DIF analyses
Considering the items that showed uniform DIF either in the current study or in the previous study of Hoopman et al. [7], we found in the Turkish group that 83% (15 of 18 items) and in the Moroccan group 67% (16 of 24 items) of these items had an odds ratio in the same direction (below or above 1.0, although not all significant). This indicates that there were relatively consistent findings across the two studies. In contrast, there were almost no consistent findings between the current study and that of Hoopman et al. with regard to non-uniform DIF (only item MH3 in the Turkish group showed non-uniform DIF in both studies).
Items that showed uniform DIF in both studies in the Turkish group were PF1, RP2 and RE1 and in the Moroccan group PF1, PF9, VT1 and VT4. In both studies in both ethnic groups, clear DIF was found in the PF1 item (participating in strenuous sports and running), with Dutch respondents tending to report more limitations than Turkish or Moroccan respondents. Turks and Moroccans may be less likely to indicate problems with these activities, simply because they tend not to perform them [7]. There is no obvious explanation for the finding that, in both studies, in the Moroccan group, items VT1 and VT4 showed clear DIF, with Dutch respondents tending to report less energy and more tiredness.
The fact that similar results were obtained in the current study as in the previous study among patients diagnosed with cancer [7], is important, in that it suggests that: (1) the findings are not specific to cancer patient populations only; and (2) the findings are not specific to a certain language version of the SF-36. Rather the results suggest that culture is responsible for the fact that Turkish and Moroccan respondents respond differently to some of the SF-36 items compared to Dutch respondents. In future research, investigators should be aware of possible cultural differences in responses to and interpretation of some SF-36 items. However, this is primarily of importance when comparing results across cultural groups, rather than investigating within group issues.
This study had several limitations that should be noted. First, recruitment into the study began with a one-page postal questionnaire that required self-completion. This could possibly have had a negative effect on the response rate, particularly among illiterate individuals. This, in turn, may have led to an under-representation of certain subgroups (e.g., elderly and women) whose literacy rates tend to be lower in these ethnic minority populations. Nevertheless, the distribution of age and sex of the respondents per ethnic group did not differ systematically from the national figures [22, 23].
Second, the failure to systematically record the language in which the questionnaire was administered in the DNSGP2 survey required post-hoc classification into language categories based on the best available information and certain assumptions. Although we are fairly confident that the criteria used to classify language of administration were appropriate, we cannot rule out some degree of misclassification.
Third, the routing algorithms used in administering the PF and the BP items may have had some influence on the scale score distributions, factor analysis results, internal consistency estimates, and DIF results. To examine the possible influence of routing in the PF scale, we reanalyzed the data from the study of Hoopman et al. [7] to compare the results based on the standard administration procedures with those based on the routing algorithm used in the current study. The scale score distributions and the internal consistency reliability estimates were nearly identical. Similarly, the mean PF scale score and the Cronbach’s α coefficients derived from the current study for the Dutch sample were very similar to those reported by Aaronson et al. in 1996 in a study employing the original administrative algorithm [8]. For these reasons, we believe that routing did not have a significant influence on the current study results.
Finally, to ensure that collapsing the 6-level response scale used for the SF2 item in the DNSGP2 survey to 5 levels as in the original SF2 item did not effect the psychometric results, we repeated all statistical analyses using the 6-level response scale. The results were very nearly identical to those obtained when using the collapsed 5 item response scale, with only very much deviations that were not statistically significant (data not presented but available upon request).
In conclusion, the findings from this study indicate that the SF-36 has generally satisfactory psychometric properties when employed among Turkish and Moroccan ethnic minority populations in the Netherlands and that the psychometric results are similar to those observed in the indigenous Dutch population. Additional studies are needed to confirm the psychometrics of the SF-36 when used among these ethnic minority groups residing in other Western European countries, including Belgium, France, Germany, and Spain.
Notes
The oral Moroccan language Tarifit [7] was not used in this study.
References
Ware, J. E., Snow, K. K., Kosinski, M., & Gandek, B. (1993). SF-36 health survey manual and interpretation guide. Boston, MA: New England Medical Center, The Health Institute.
Ware, J. E., & Sherbourne, C. D. (1992). The MOS 36-item short-form health survey (SF-36). I. Conceptual framework and item selection. Medical Care, 30, 473–483. doi:10.1097/00005650-199206000-00002.
Salt, J. (2002). European international migration: Evaluations of the current situation. Strasbourg: Council of Europe.
Centraal Bureau voor de Statistiek. (2008). Jaarrapport Integratie 2008. Den Haag/Heerlen: CBS.
Sociaal en Cultureel Planbureau. (2004). Cijferrapport Allochtone Ouderen. Werkdocument 105. Den Haag: SCP.
Sociaal en Cultureel Planbureau. (2005). Jaarrapport Integratie 2005. Den Haag: SCP/WPDC/CBS.
Hoopman, R., Terwee, C. B., Muller, M. J., & Aaronson, N. K. (2006). Translation and validation of the SF-36 health survey for use among Turkish and Moroccan ethnic minority cancer patients in The Netherlands. European Journal of Cancer, 42, 2982–2990. doi:10.1016/j.ejca.2006.08.011.
Aaronson, N. K., Muller, M., Cohen, P. D., Essink-Bot, M. L., Fekkes, M., Sanderman, R., et al. (1998). Translation, validation, and norming of the Dutch language version of the SF-36 health survey in community and chronic disease populations. Journal of Clinical Epidemiology, 51, 1055–1068. doi:10.1016/S0895-4356(98)00097-3.
Ware, J. E., Kosinski, M., & Keller, S. D. (1994). SF-36 physical and mental health summary scales—a users’ manual. Boston, MA: New England Medical Center, the Health Institute.
Bullinger, M., Alonso, J., Apolone, G., Leplege, A., Sullivan, M., Wood-Dauphinee, S., et al. (1998). Translating health status questionnaires and evaluating their quality: The IQOLA project approach. International quality of life assessment. Journal of Clinical Epidemiology, 51, 913–923. doi:10.1016/S0895-4356(98)00082-1.
Ware, J. E., Keller, S. D., Gandek, B., Brazier, J. E., & Sullivan, M. (1995). Evaluating translations of health status questionnaires. Methods from the IQOLA project. International quality of life assessment. International Journal of Technology Assessment in Health Care, 11, 525–551. doi:10.1017/S0266462300008710.
Pinar, R. (2005). Reliability and construct validity of the SF-36 in Turkish cancer patients. Quality of Life Research, 14, 259–264. doi:10.1007/s11136-004-2393-3.
Westert, G. P., Schellevis, F. G., De Bakker, D. H., Groenewegen, P. P., Bensing, J. M., & van der, Z. J. (2005). Monitoring health inequalities through general practice: The Second Dutch National Survey of general practice. European Journal of Public Health, 15, 59–65. doi:10.1093/eurpub/cki116.
Petersen, M. A., Groenvold, M., Bjorner, J. B., Aaronson, N., Conroy, T., Cull, A., et al. (2003). Use of differential item functioning analysis to assess the equivalence of translations of a questionnaire. Quality of Life Research, 12, 373–385. doi:10.1023/A:1023488915557.
Holland, P. W., & Wainer, H. (Eds.). (1993). Differential item functioning. Hillsdale, NJ: Erlbaum.
Demiral, Y., Ergor, G., Unal, B., Semin, S., Akvardar, Y., Kivircik, B., et al. (2006). Normative data and discriminative properties of short form 36 (SF-36) in Turkish urban population. BMC Public Health, 6, 247. doi:10.1186/1471-2458-6-247.
Gandek, B., Ware, J. E., Jr, Aaronson, N. K., Alonso, J., Apolone, G., Bjorner, J., et al. (1998). Tests of data quality, scaling assumptions, and reliability of the SF-36 in eleven countries: Results from the IQOLA project. International quality of life assessment. Journal of Clinical Epidemiology, 51, 1149–1158. doi:10.1016/S0895-4356(98)00106-1.
Khoudri, I., Ali, Z. A., Abidi, K., Madani, N., & Abouqal, R. (2007). Measurement properties of the short form 36 and health-related quality of life after intensive care in Morocco. Acta Anaesthesiologica Scandinavica, 51, 189–197. doi:10.1111/j.1399-6576.2006.01225.x.
Sabbah, I., Drouby, N., Sabbah, S., Retel-Rude, N., & Mercier, M. (2003). Quality of Life in rural and urban populations in Lebanon using SF-36 health survey. Health and Quality of Life Outcomes, 1, 30. doi:10.1186/1477-7525-1-30.
Wagner, A. K., Wyss, K., Gandek, B., Kilima, P. M., Lorenz, S., & Whiting, D. (1999). A Kiswahili version of the SF-36 health survey for use in Tanzania: Translation and tests of scaling assumptions. Quality of Life Research, 8, 101–110. doi:10.1023/A:1026441415079.
Pappa, E., Kontodimopoulos, N., & Niakas, D. (2005). Validating and norming of the Greek SF-36 health survey. Quality of Life Research, 14, 1433–1438. doi:10.1007/s11136-004-6014-y.
Centraal Bureau voor de Statistiek. (2002). Jaarboek Statistiek 2002. Voorburg: CBS.
Uiters, E. (2007). Primary health care use among ethnic minorities in the Netherlands. A comparative study. Rotterdam: Erasmus Universiteit Rotterdam.
Acknowledgments
This study was funded, in part, by grant no. NKI 99-1724 from the Dutch Cancer Society. We would like to thank the Netherlands Institute for Health Services Research (NIVEL), and the National Information Network of GPs (LINH) for providing access to the data from the Second Dutch National Survey of General Practice.
Open Access
This article is distributed under the terms of the Creative Commons Attribution Noncommercial License which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This is an open access article distributed under the terms of the Creative Commons Attribution Noncommercial License (https://creativecommons.org/licenses/by-nc/2.0), which permits any noncommercial use, distribution, and reproduction in any medium, provided the original author(s) and source are credited.
About this article
Cite this article
Hoopman, R., Terwee, C.B., Devillé, W. et al. Evaluation of the psychometric properties of the SF-36 health survey for use among Turkish and Moroccan ethnic minority populations in the Netherlands. Qual Life Res 18, 753–764 (2009). https://doi.org/10.1007/s11136-009-9491-1
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11136-009-9491-1