
Abstract
This paper presents a comparison of two different models (Land et al (1993) and Olesen and Petersen (1995)), both designed to extend DEA to the case of stochastic inputs and outputs. The two models constitute two approaches within this area, that share certain characteristics. However, the two models behave very differently, and the choice between these two models can be confusing. This paper presents a systematic attempt to point out differences as well as similarities. It is demonstrated that the two models under some assumptions do have Lagrangian duals expressed in closed form. Similarities and differences are discussed based on a comparison of these dual structures. Weaknesses of the each of the two models are discussed and a merged model that combines attractive features of each of the two models is proposed.


Similar content being viewed by others
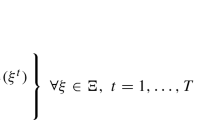

Notes
However, neither Land et al. nor Olesen and Petersen quote Aigner and Chu or Timmer.
“Repairing” the LLT-model by “adding” some wanted characteristics from the OP-model is left for future research.
The assumption of homoscedacity is easy to relax as long as we assume that all variance-covariance matrices can be written as a scalar times a common matrix. More general structures on the set of variance-covariance matrices require a more complex dual formulation, see Olesen (2005).
See footnote 6.
In sect. 4 we will propose a merge between the two models. The output possibility set from this merged model (denoted P LLTOP, see (10)) is very similar to P OP. The only difference is that the inequality \(\Phi ^{-1}\left( \alpha \right) \sqrt{\xi _{1}^{2}+\xi_{2}^{2}}\leq \lambda _{1}+\lambda _{2}+\lambda _{3}\) is replaced by \(\Phi ^{-1}\left( \alpha \right) \sqrt{\xi _{1}^{2}+\xi _{2}^{2}}\leq \sqrt{\lambda _{1}^{2}+\lambda _{2}^{2}+\lambda _{3}^{2}}\). Notice that the feasible set is no longer a convex set.
The two frontiers are given as A 3,B 3,C 3,D 3 and A 6,B 6,C 6,D 6,E 6,F 6
The structure of the dual of the LLT-certainty equivalent likewise compares directly with the OP-certainty equivalent, but details of this comparison is left for future research.
\(f\left( x,y\right) =\left\| \left( x,y\right) \right\| _{2}=\sqrt{x^{2}+y^{2}}\) is a convex function.
The non-convexities of the PPS could be a consequence of data being generated by more than one data generating process with different supports or could be caused by a genuine non-convex technology. We have not proven that the LLTOP-estimator of the PPS is consistent. However, it should be possible to prove under sufficient regularity conditions on the set of variance covarience matrices from the set of DMUs.
In relation to the notation used in lemma 8 we have
$$ \begin{aligned} k\equiv&{\frac{1}{\eta}}\left(u^{t}e_{s}+v^{t}e_{m}\right)\hbox{and}\\ \gamma_{j}\equiv &neg\left( -u^{t}\overline{Y}_{j}+v^{t}\overline{X} _{j}\right) ,j=1,\ldots,n \\ \end{aligned} $$Assume to the contrary that the optimal solution (u *,v *) implies that v * t X j0 = k < 1. The first n inequalities are all linear homogenious. Hence, k −1(u *,v *) is a feasible solution with a higher value of the objective function which is a contradiction.
Kuhn Tucker conditions state for the standard case min f(x) s.t. g(x) ≤ 0, with a Lagrange function \( \fancyscript{L}\)(x,λ) = f(x) + λ g(x) that ∇ f(x) + λ ∇ g(x) = 0. In other words a positive linear combination of the constraints gradients is equal to the negative objective gradient (negative, because we minimize). Consider now max f(x) s.t. g(x) ≥ 0. Let h(x) ≡ − g(x) and consider max f(x) s.t. h(x) ≤ 0 with a Lagrange function \( \fancyscript{L}\)(x,λ ) = f(x) + λ h(x), λ ≤ 0. Kuhn Tucker conditions state for this case state that ∇ f(x) + λ ∇ h(x) = 0 or − λ ∇ h(x) = ∇ f(x) or in other words that a positive linear combination of the constraint gradients is equal to the positive objective gradient (positive, because we maximize).
We have for the OP-model that
$$ \begin{aligned} &\max_{u\geq 0,v\geq 0}\left( u^{t},v^{t}\right) \left[ \left( -\overline{Y} \lambda +\overline{Y}_{j_{0}}\right) ,\left( \overline{X}\lambda -\overline{X }_{j_{0}}\right) \right] -\left( \kappa ^{-1}\lambda ^{t}e_{n}\right) \left\| u,v\right\| _{2}=\\ &-\min_{u\geq 0,v\geq 0}\left( u^{t},v^{t}\right) \left[ \left( \overline{Y} \lambda -\overline{Y}_{j_{0}}\right) ,\left( -\overline{X}\lambda +\overline{ X}_{j_{0}}\right) \right] +\left( \kappa ^{-1}\lambda ^{t}e_{n}\right) \left\| u,v\right\| _{2}\\ \end{aligned} $$Lemma 8 is then used on the last formulation, i.e. the condition is \(\left\| \gamma \right\| _{2}\leq k\) with
$$ \begin{aligned} k&\equiv \kappa^{-1}\lambda ^{t}e_{n}\\ \bigskip \gamma &\equiv neg\left[ \left( \overline{Y}\lambda -\overline{Y}_{j_{0}}\right) ,\left( -\overline{X}\lambda +\overline{X}_{j_{0}}\right) \right] \end{aligned} $$\(\overline{Y}^{k}\) denotes the k ’th row in \(\overline{Y}\).
References
Aigner DJ, Chu SF (1968) On estimating the industry production function, American Economic Review (4):826–839
Charnes A, Cooper WW (1963) Deterministic equivalents for optimizing and satisficing under chance constraints. Operations Research 11(1):18–39
Charnes A, Cooper WW, Rhodes E (1978) Measuring the efficiency of decision-making units. European Journal of Operations Research 2:429–444
Cooper WW, Deng H, Huang Z, Li SX (2002) Chance constrained programming approaches to technical efficiencies and inefficiencies in stochastic data envelopment analysis. Journal of Operational Research Society 53:1347–1356
Cooper WW, Deng H, Huang Z, Li SX (2004) Chance constrained programming approaches to congestion in stochastic data envelopment analysis. European Journal of Operations Research 155:487–501
Cooper WW, Huang Z, Lelas V, Li S, Olesen OB (1998) Chance constrained programming formulations for stochastic characterizations of efficiency and dominance in DEA. Journal of Productivity Analysis 9(1):53–80
Cooper WW, Huang Z, Li SX (1996) Satisficing DEA models under chance constraints. Annals of Operations Research 66:279–295
Cooper WW, Park KS, Yu G (1999). Idea and ar-idea: Models for dealing with imprecise data in DEA. Management Science 45(4):597–607
Cooper WW, Park KS, Yu G (2001) Idea imprecise data envelopment analysis) with cmds (column maximum decision making units). Journal of Operational Research Society 52:176–181
Cooper WW, Seiford LM, Zhu J (2004) Handbook on data envelopment analysis. Kluwer Academic Publishers, Boston
Grosskopf S (1996) Statistical inference and nonparametric efficiency. A selective survey. Journal of Productivity Analysis 7(2–3):161–176
Huang Z, Li SX (1996). Dominance stochastic models in data envelopment analysis. European Journal of Operations Research 95:390–403
Kall P (1976). Stochastic Linear Programming. Springer Verlag, Berlin
Land KC, Lovell CAK, Thore S (1988) Chance-constrained data envelopment analysis. Paper presented at the National Science Foundation Conference, Charpel Hill
Land KC, Lovell CAK, Thore S (1993) Chance-constrained data envelopment analysis. Managerial and Decision Economics 14:541–554
Lasdon LS (1970). Optimization Theory for Large Systems. MacMillan Publishing Co. Inc., New York
Li SX (1998). Stochastic models and variable returns to scale in data envelopment analysis. European Journal of Operations Research 104:532–548
Miller BL, Wagner HM (1965) Chance constrained programming with joint chance constraints. Operations Research 16:930–945
Olesen O.B. (2005) A general comparison of two approaches for chance constrained DEA., Unpublished, The paper is availible from the authors homepage, see under http://www.sam.sdu.dk
Olesen OB, Petersen NC (1995) Chance constrained efficiency evaluation. Management Science 41:442–457
Sengupta JK (1982) Efficiency measurement in stochastic input-output systems. International Journal of Systems Sceinces 13:273–287
Sengupta JK (1987) Data envelopment analysis for efficiency measurement in the stochastic case. Computers and Operations Research 14:117–129
Sengupta JK (1988a) The measurement of productive efficiency: A robust minimax approach. Managerial and Decision Economics 9:153–161
Sengupta JK (1988b) Robust efficiency measures in a stochastic efficiency model. International Journal of Systems Sciences 19:779–791
Sengupta JK (1989) Measuring economic efficiency with stochastic input output data. International Journal of Systems Sciences 20(2):203–213
Timmer CP (1971) Using a probabilistic frontier production function to measure technical efficiency. Journal of Political Economy 79:776–794
Author information
Authors and Affiliations
Corresponding author
Appendices
Appendix: Proofs of the Lagrangian duals assuming that all variance-covariances matrices are identity matrices.
Two Lemmas.
In this appendix we will use the following notation:
The following lemmas will be useful later:
Lemma 7
Let \(\alpha \in \mathbb{R}^{p}. max_{\left\| \lambda \right\| _{2}\leq 1}\alpha^{t}\lambda =\left\| \alpha \right\| _{2} (or\, min_{\left\| \lambda \right\| _{2}\leq 1}\alpha^{t}\lambda =\left\| \alpha \right\| _{2})\) for the optimal vector \(\lambda ^{\ast }=\left( \left\| \alpha \right\| _{2}\right) ^{-1}\alpha (or\,\lambda^{\ast }=-\left( \left\| \alpha \right\| _{2}\right) ^{-1}\alpha \)).
Lemma 8
Consider the following minimization problem for \( \gamma \in \mathbb{R}_{-}^{p} \) and \(k\in \mathbb{R}_{+}.\)
The set of (γ ,k) for which this minimization is not unbounded is
For (γ, k) ∈A the minimum is attained for λ * = − γ. For (γ ,k) ∈ ∂ A and λ * = − γ we have \(\gamma ^{t}\lambda ^{\ast }+k\left\| \lambda ^{\ast }\right\| _{2}=0\).
Proof
Notice, \(\gamma \in \mathbb{R}_{-}^{p}\). Since \(k\left\|\lambda \right\|_{2}\geq 0,\forall\lambda\geq 0\) we have a bounded solution for (γ ,k) in
From lemma 7 (with α ≡ − γ), we have that \(-\gamma^{t}\left(\left\|\lambda\right\|_{2}\right)^{-1}\lambda\) attains its maximum value over all λ ≥ 0 for λ * = − γ, since
Hence, inserting this λ* in (13) gives A as the set of (γ ,k) for which the minimization is not unbounded. ■
Dual formulations to the LLT- and the OP-models (no correlation between DMUs in the LLT-model and between inputs, outputs and inputs and outputs in the OP -model).
Let us consider a radial efficiency evaluation of a mean vector from DMU j0 (X j0,Y j0) regarded as a realization, i.e. a random vector with zero variance. Let us first consider the Land etal. (1993) chance constraint formulation with no correlation between DMUs (here also homoscedacity):
where η−1 is the fractile corresponding to the chosen probability level α. Assuming \({\frac{1}{\eta }}\geq 0\) implies that (14) a convex programming problem and it is well known that the Lagrangian dual (sometimes called the minimax dual) exists and that there is no duality gap if Slater’s condition is satisfied, see e.g. Theorem 1 (Lasdon 1970, p. 435). Slater’s condition states:
Condition 9
\(Let g\left( \theta ,\lambda \right) =\left[ -\sum\limits_{j=1}^{n}\lambda _{j}\overline{Y}_{kj}+{\frac{1}{\eta }}\left\|\lambda \right\|_{2}+Y_{kj_{0}},\forall k,\sum\limits_{j=1}^{n}\lambda _{j}\overline{X}_{ij}+{\frac{1}{\eta }}\left\|\lambda\right\|_{2}-\theta X_{ij_{0}},\forall i\right]\). Assume that there exists a point \(\left( \theta ,\lambda \right)\in S\equiv \mathbb{R}\times \mathbb{R}_{+}^{n}\) such that g(θ ,λ ) < 0.
Slater’s condition is satisfied under the following mild regularity condition:
Lemma 10
(Regularity condition): Assume that \(\overline{Y}_{kj} > 0,Y_{kj_{0}} > 0,\forall k,j, \overline{X}_{ij} > 0,X_{ij_{0}} > 0,\forall i,j\). Then there exists a \(\left(\theta,\lambda \right) \in \mathbb{R}\times \mathbb{R}_{+}^{n}\) such that g(θ,λ ) < 0.
Proof
We first look for \(\lambda^{\ast}\in \mathbb{R}_{+}^{n}\) such that the s output inequalities are satisfied with strict inequalities. Let us assume that λ j = λ1,j = 2,...,n then we get:
Next from the input inequalities we get
λ* = λ *1 (e n )t implies that all s output inequalities are satisfied strictly and g(θ*,λ*) < 0 as required.■
Let us formulate the Lagrangian dual:
where
Rearranging we get
where
The minimization over λ ≥ 0 involved in g(θ ,λ ;u,v) is bounded if \(\left( -u^{t}\overline{Y}+v^{t}\overline{X}\right)\geq 0\). Allowing some components in this vector to be negative, i.e. \(J_{0}\subseteq \left\{ 1,\ldots ,n\right\},\)such that \(-u^{t}\overline{Y}_{j}+v^{t}\overline{X}_{j} < 0\) for j∈J 0 we have from lemma 8 Footnote 13 that this minimization is bounded if
or
Hence the Lagrangian dual to (14) corresponds to
or
(21) follows from (20) based on the following argument: Consider the j 0′th component in the vector \(-u^{t}\overline{Y}+v^{t}\overline{X}\) and consider the following two cases:
-
If \(-u^{t}\overline{Y}_{j_{0}}+v^{t}\overline{X}_{j_{0}} < 0\) then by the third set of constraints in (A8) we have \(-u^{t}\overline{Y}_{j_{0}}+v^{t}\overline{X}_{j_{0}}\geq -s_{j_{0}}^{+}\) and − s + j0 ≤ 0. Hence, s + j0 > 0. To allow as large a set of feasible u,v determined from the first constraint \(\eta ^{-1}\left\| u,v\right\| _{1}\geq \left\|s^{+}\right\|_{2}\) we choose s + j0 as small as possible, i.e. \(-u^{t}\overline{Y}_{j_{0}}+v^{t}\overline{X}_{j_{0}}=-s_{j_{0}}^{+}\).
-
If \(-u^{t}\overline{Y}_{j_{0}}+v^{t}\overline{X}_{j_{0}} > 0\) then by the third set of constraints in (21) we have \(-u^{t}\overline{Y}_{j_{0}}+v^{t}\overline{X}_{j_{0}}\geq -s_{j_{0}}^{+}\) and − s + j0 ≤ 0. Hence, s + j0 ≥ 0. To allow as large a set of feasible u,v determined from the first constraint \(\eta ^{-1}\left\| u,v\right\| _{1}\geq \left\| s^{+}\right\| _{2}\) we choose s + j0 = 0, i.e. as small as possible.
Next, let us consider a radial efficiency evaluation of this mean vector from \(\hbox{DMU}_{j_0}\;\left( X_{j_0},Y_{j_0}\right)\) regarded as a realization, in the Olesen and Peterson (1995) chance constraint formulation. We focus on the situation with no correlation between inputs, outputs and inputs and outputs (here also homoscedacity). The model for this case is:
where κ−1 is the fractile corresponding to the chosen probability level α. Notice, that the constraint v t X j0 = 1 can be replaced by v t X j0 ≤ 1 since this inequality always will hold as an equality in optimum Footnote 14. In this context Slater’s condition states:
Condition 11
Let \(g\left(u,v\right) =\left[ u^{t}\overline{Y}_{j}-v^{t}\overline{X}_{j}+\kappa^{-1}\left\| u,v\right\|_{2},\forall j,v^{t}X_{j_{0}}-1\right]\). Assume that there exists a point \(\left( u,v\right)\in S\equiv \mathbb{R}_{+}^{s+m}\) such that g(u,v) < 0.
Slater’s condition is satisfied under the following mild regularity condition:
Lemma 12
(Regularity condition): Assume Y kj_0 > 0, k, X ij_0 > 0, i and that for all (δ+,δ−) where \(\left\|\left(\delta ^{+},\delta ^{-}\right) \right\| _{2}\leq \kappa\) we have \(\left(\overline{Y}_{kj}+\delta _{k}^{+}\right) > 0,\left( \overline{X}_{ij}+\delta _{i}^{-}\right) > 0,\forall i,j\). Then there exists a \(\left( u,v\right) \in \mathbb{R}_{+}^{s+m}\) such that g(u,v) < 0.
Proof.
The regularity condition states that all confidence regions (balls of radius κ with centers at the mean input output vectors) are strictly contained in the non-negative orthant. Hence there exists a hyperplane with a normal vector \(\left( u^{\ast},v^{\ast }\right)\in \mathbb{R}_{+}^{s+m}\) such that all confidence regions are located in the open halfspace bounded by this hyperplane. More formally, for j = 1,...,n
From Lemma 7 we have that
from which follows that in particular we have for j = 1,... ,n
Finally, notice that feasibility of (u *,v *) in the first n constraints implies feasibility of k(u *,v *) , for \(k\in \mathbb{R}_{+}\). Hence to assure that v t X j0 − 1 < 0 we simply downscale (u *,v *) until g(u *,v *) < 0 as required.■
Let us formulate the Lagrangian Footnote 15 dual:
where
Hence,
A sufficient condition for this maximization to be bounded is \(\left[ \left( -\overline{Y}\lambda +\overline{Y}_{j_{0}}\right) ,\left( \overline{X}\lambda -\theta \overline{X}_{j_{0}}\right) \right] \leq 0\). However, we can allow components in this vector to be positive. A necessary and sufficient condition Footnote 16 (see again (lemma 8)) is
Hence the Lagrangian dual corresponds to
or
As above (28) follows from (27) based on the following argument: Consider the k th component in the vector \(\left[ \left( \overline{Y}\lambda -Y_{j_{0}}\right) ,\left( -\overline{X}\lambda +\theta X_{j_{0}}\right) \right] \), say \(\overline{Y}^{k}\lambda -Y_{kj_{0}}\), and consider the following two cases Footnote 17
-
If \(\overline{Y}^{k}\lambda -Y_{kj_{0}} < 0\) then by the second set of s constraints in (28) we have \(\overline{Y}^{k}\lambda -Y_{kj_{0}}\geq -\xi _{k}^{+}\) and − ξ + k ≤ 0. Hence, ξ + k > 0. To allow as large a set of feasible λ determined from the first constraint \(\kappa ^{-1}\left\| \lambda \right\| _{1}\geq \left\| \xi ^{+},\xi ^{-}\right\| _{2}\) we choose ξ + k as small as possible, i.e. \(\overline{Y}^{k}\lambda -Y_{kj_{0}}=-\xi _{k}^{+}\).
-
If \(\overline{Y}^{k}\lambda -Y_{kj_{0}} > 0\) then by the second set of s constraints in (28) we have \(\overline{Y}^{k}\lambda -Y_{kj_{0}}\geq -\xi _{k}^{+}\) and − ξ + k ≤ 0. Hence, ξ + k ≥ 0. To allow as large a set of feasible λ determined from the first constraint \(\kappa ^{-1}\left\| \lambda \right\| _{1}\geq \left\| \xi ^{+},\xi ^{-}\right\| _{2}\) we choose ξ + k = 0, i.e. as small as possible.
Rights and permissions
About this article
Cite this article
Olesen, O.B. Comparing and Combining Two Approaches for Chance Constrained DEA. J Prod Anal 26, 103–119 (2006). https://doi.org/10.1007/s11123-006-0008-4
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11123-006-0008-4
Keywords
- Data envelopment analysis
- Chance constraints
- Production possibility set
- Stochastic efficiency
- Stochastic frontier estimation