
Abstract
This paper first examines some recent exchange rate classification schemes. There is little evidence of a trend towards greater agreement between schemes. There is a probability of between 16 and 28% that a peg in one classification scheme is coded as a float in a different scheme, or vice versa. This probability is much smaller for the tightest forms of peg and the most volatile floats. Continuous indices of exchange rate flexibility are analysed and shown to have significant potential, despite the lack of interest in them shown in previous research.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
Since the 1990s, when it was recognised that central banks had sometimes been misreporting their exchange rate regimes, there has been intensive work on finding new methods of classification (e.g. Ghosh et al. 2002; Klein and Shambaugh 2010; Levy-Yeyati and Sturzenegger 2005; Reinhart and Rogoff 2004; Shambaugh 2004). This research has almost entirely followed the path of defining a number of “fine” (disaggregated) or “coarse” (aggregated) categories to which to allocate each observation, rather than develop a numerical measure of exchange rate flexibility. Although Ghosh et al. (2002, pp. 49–51) suggest a simple numerical flexibility index, they make no use of it except to define three categories of regime (pegged, intermediate and floating). Reviews of this research effort in the classification of exchange rate regimes have generally concluded that it has been unsatisfactory, at least in so far as that is measured by the degree of agreement between alternative schemes (Bleaney et al. 2017; Eichengreen and Razo-Garcia 2013; Tavlas et al. 2008). The purpose of the present paper is twofold: to investigate whether this remains true of the more recent classification efforts, and to assess the value of numerical alternatives.
The recent exchange rate regime classifications that we consider are those of Ilzetzki et al. (2017), Obstfeld et al. (2010) and Bleaney and Tian (2017), together with numerical measures of exchange rate flexibility associated with the last two. Ilzetzki et al. (2017) have updated the Reinhart-Rogoff classification up to 2016 without amending the classification algorithm in any way. Obstfeld et al. (2010) have relaxed the rather stringent definitions of a peg used by Shambaugh (2004) and Klein and Shambaugh (2010) to be more in line with other classifications, and the data have been updated to 2014. Bleaney and Tian (2017) have suggested a method of measuring exchange rate flexibility and identifying exchange rate regimes by a regression similar to that previously used by Frankel and Wei (1995) and Slavov (2013) to identify the basket of anchor currencies for a pegged regime. For the purposes of this paper we have updated the data to 2017.
All of these classification schemes are designed to capture how much variation is permitted about a defined central rate, if one exists, but they have different ways of answering that question. In an ideal world, the different approaches would make little difference in practice, and the outcomes would be similar. Unfortunately, as we show, that remains far from true.
Section 2 discusses the classification schemes, and Section 3 compares the outcomes on a country-year basis back to 1980. In Section 4, biases caused by regime changes are discussed. Section 5 investigates continuous measures of exchange rate flexibility. Further issues are discussed in Section 6, and Section 7 concludes.
2 The Classifications
We shall be concerned here with classification systems designed to cover a large number of countries over a considerable period, whose output is then available for addressing a variety of research questions about the impact of the choice of exchange rate regime. Any system for classifying exchange rate regimes needs to address a number of issues, such as the following: (a) is it to be based on purely statistical analysis, or should it take account of other information such as stated government policy or the assessment of informed observers, which would involve a considerably more intensive research effort? (b) How disaggregated should the classification aim to be? (c) How many months’ data should be used to define the regime (there is obviously a trade-off here between accuracy and the possibility of regime change during the period)? (d) What are the critical issues: is it whether the nominal exchange rate is strictly constant or not, and should it be an exchange rate against a single currency or possibly a currency basket? How should the occasional parity change be dealt with?
If these questions are answered differently in the construction of different classification systems, clearly the outcomes will differ. How important those differences turn out to be cannot be answered in the abstract, but only in practice. In the next section we compare in some detail the outcomes for different classification schemes.
The schemes that we compare are the updated Reinhart-Rogoff scheme of Ilzetzki et al. (2017) [hereafter IRR], the updated Shambaugh classification and a modified version of the Bleaney-Tian (2017) method. We compare these schemes with each other and with the IMF de facto classification.
The Reinhart-Rogoff method uses a combination of detailed chronologies and statistical methods. If the authorities announce some form of peg, statistical analysis is used to confirm that over the relevant period. If no peg is announced, rolling five-year periods are used to define the regime, based on whether 80% of the monthly absolute percentage changes in the exchange rate against the identified anchor currency fall within a limited range (1 % for a peg). If no peg or band as wide as ±5% is identified, the regime is defined as either a managed or an independent float, depending on the degree of exchange rate volatility. Because the statistical analysis is based on five years rather than one, regime switches are much rarer in IRR than in the other classifications.Footnote 1
The updated Shambaugh classification (hereafter referred to as OST) uses the definition of a peg introduced by Obstfeld et al. (2010). Shambaugh (2004) used a strict definition of a peg, according to which a currency either moved by less than 2 % in any month relative to an identified anchor currency, or (to allow for parity changes) was absolutely fixed for eleven months out of twelve, but could have any size of movement in the remaining month. The OST classification also allows for soft pegs that do not meet either of these criteria for a strict peg, but stay within a band of up to ±5%. In addition the OST classification has a category labelled “Single-Year Pegs”, that meet the criteria for a peg in year T, but not in year T-1 or year T + 1. These “Single-Year Pegs” are coded as floats in the OST system, on the grounds that such episodes are more likely to be floats that are undergoing a period of temporary stability than genuine pegs.
The Bleaney-Tian (2017) method [hereafter referred to as BT] requires the identification of a numeraire currency. Previous research has often used the Swiss franc as the numeraire currency, but in the last few years the Swiss franc has not always been floating freely, so here we modify the method by using the Japanese yen as a numeraire instead. The potential anchor currencies that we consider are the US dollar and the euro, but with others added in particular cases as listed in Bleaney and Tian (2017, p. 304). Up to 1998, when the euro had not yet been created, we use the German mark and the French franc instead. The regression relates exchange rate movements of currency i against the chosen numeraire currency N (in this case the Japanese yen) to movements of potential anchor currencies against N:
where USD is the US dollar, EUR is the euro, E(i, N) is the number of units of currency i per yen, and ∆ is the first-difference operator. In a single-currency peg to the euro, the euro-yen exchange rate should have a coefficient equal to one, and any other exchange rate should have a coefficient of zero. In a basket peg, the coefficients of the currencies making up the basket should sum to one. If the government operates a crawling peg, with a steady devaluation rate of x% per month, the value of x can be estimated from the intercept term in the regression.
The classification is based on the root mean square error (RMSE) of this regression, which we shall call Regression A. To allow for the possibility of one parity change per year, Bleaney and Tian (2017) estimate 12 extra regressions, each with a dummy variable equal to one in one month only added to Regression A. Call these regressions B(1) to B(12). If none of the dummy variables is statistically significant enough, Regressions B(1) to B(12) are ignored, and that country-year is coded a Fix if RMSE <0.01, and a Float otherwise. If any of the dummy variables is significant enough, the B regression with the most significant dummy variable becomes the focus of attention.Footnote 2 If the RMSE <0.01 in the chosen B regression, that country-year is coded as a Peg with a Parity Change, and otherwise a Float. We impose two exceptions to this rule, however. (1) If the estimated parity change is very small (< ±0.02), we treat it as a movement within an unchanged band rather than a shift in the central rate, and the observation is coded a Fix. (2) Since revaluations are in practice rare, except where one is known to have occurred, if the estimated parity change is a revaluation of >0.02, this is assumed to be spurious, and the B regressions are ignored, the coding instead being based on Regression A.Footnote 3 This classification is available up to 2017.
Finally, the IMF de facto classification is based on IMF country desks’ perception of the regime in force at the time, according to defined criteria. It identifies a number of different types of peg or band, a managed float and an independent float. Since 2012, the IMF has changed its approach, so this classification is available only up to 2011.
It is reasonable to hypothesise that the primary reason for managing a floating exchange rate is to reduce its volatility (see Frankel 2019, for some evidence). In order to create some symmetry between the classifications that distinguish between managed and independent floats and those that do not, we make use of a continuous measure of exchange rate flexibility to distinguish high-volatility from low-volatility floats in the latter. In the BT system, the RMSE from the regression on which the classification is decided is that measure. Floats are deemed to be high-volatility if RMSE >0.02, and low-volatility otherwise. For the OST system, the dataset provides a slightly different flexibility measure, named EVOL, which is the standard deviation of monthly proportional changes in the exchange rate against the identified anchor currency. A similar criterion is applied: if EVOL >0.02, it is a high-volatility float; otherwise it is a low-volatility float. One of the main differences between RMSE and EVOL is that the size of any parity change in the year will tend to affect EVOL but not RMSE, since in the latter case it will have been captured by the dummy variable in the regression.
Table 1 summarises the categories used for each classification scheme in the subsequent analysis.Footnote 4
3 Comparisons Between Classifications
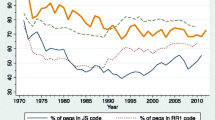
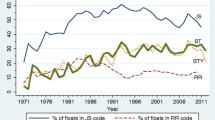
Table 2 summarises the pairwise comparisons between our four schemes, using the regime categories shown in Table 1 (for a more disaggregated presentation, see Appendix Tables 12, 13, 14, 15, 16 and 17). For each regime category, the table shows the percentage of country-years which are in that category in one classification scheme that are classified as some form of float by each of the other three. For example the top row of Table 2 shows that, of the 3440 BT Fixes in the first column of Appendix Table 12, 12.8% were classified by the IMF as a managed or independent float. The other two figures in the first row of Table 2 show that a similar proportion of BT fixes (12.2% and 8.1%) were classified as floats in the other two classifications.
The second row of Table 2 shows the proportion of floats identified by the other classifications when BT identifies a peg with a parity change. For IMF and IRR, this proportion is still quite low, at 17.7% and 26.7% respectively, but for OST it is much higher, at 49.0%. The third row shows the figures for BT Low-Volatility Floats, which in other classifications are fairly evenly split between pegs and floats (the proportion of floats is 59.4%, 47.6% and 48.1% for IMF, IRR and OST respectively). Finally, in the fourth row of Table 2, we see that there is a heavy majority of floats in other classifications when the BT classification is a High-Volatility Float (76.2% for IMF, 68.8% for IRR and 90.1% for OST).
Thus the clear pattern in the top panel of Table 2, which compares each other classification in turn with the BT classification, is that there is much more likely to be agreement in the case of the more extreme regimes; for intermediate regimes, the disagreements are quite numerous.
The other panels of Table 2 repeat the exercise for the other three classifications. The general pattern is the same. There is a high degree of agreement (greater than 90%) in the case of the tightest form of peg, and a reasonably high one (always greater than 60%) for the more extreme form of floating, but much less so for intermediate regimes. Managed or low-volatility floats in one classification tend to be coded as pegs in any alternative classification in about 50% of cases. For pegs other than the tightest form, there is generally a solid but not overwhelming majority of pegs in the comparison classification; for IRR Crawls the proportion of floats is 31.6% (BT), 42.0 % (IMF) and 27.7% (OST); for OST Other Pegs the proportion of floats is 38.4% (BT), 45.0% (IMF) and 30.4% (IRR); and for IMF Pegs there is a clear difference between Conventional Pegs, which other classifications almost always identify as pegs (91.5% for BT, 84.9% for IRR and 92.2% for OST), and Basket Pegs, Bands and Crawls which are considerably more likely to be identified as floats in the comparison classification (the percentages of floats range from 19 to 53%).
In the OST classification, Single-Year Pegs are coded as floats. It can be seen from Table 2 that they tend not to be coded as floats in the other classifications. In the BT classification only 11.7% of these observations are floats; the figure for the IMF classification is 38.0%, and for the IRR classification it is 24.7%. The low figure for IRR is particularly striking, because one would expect that temporarily rather stable floats would still come out as floats in the IRR classification, because of its reliance on five-year rolling windows rather than twelve-month windows. This may in part reflect the reluctance of IRR to identify a free float, a feature which we have previously attributed to their decision to treat particularly high-volatility bilateral exchange rate pairs as typical of the volatility of free floats in general (Bleaney et al. 2017).
For the sake of completeness, Tables 12, 13, 14, 15, 16 and 17 in the Appendix show a fully disaggregated version of this comparison for each pair of schemes. For example Table 12 shows the number of country-years with a given IMF classification that fall within each of the BT classifications.
Looking at Table 2 as a whole, there are a few striking disagreements. One is that where a peg with a parity change is identified by the BT classification, a particularly high proportion of cases (51.7%) are classified by OST as floats (and the vast majority as high-volatility floats, as Table 14 shows), compared with 18.8% and 28.4% in the IMF and IRR classifications respectively. This reflects the fact that parity changes are often too big to stay within the ±5% criterion used by OST for a soft peg, whereas other classifications do not impose such a restriction on the size of a parity change in a pegged regime. For a similar reason, where the IMF classification identifies a crawl, this is classified as a float by OST on 52.6% of occasions, compared with 35.1% for BT and 29.5% for IRR (Table 17). The focus of the IRR and OST algorithms on single-currency pegs, rather than possible basket pegs, is reflected in the fact that IMF basket pegs are classified as floats 40.6% of the time by IRR and 38.8% of the time by OST, compared with only 18.8% for BT.
Table 3 shows the aggregate disagreement rate between each pair of schemes, based on the figures in Tables 12 to 17. A disagreement is registered when one of the pairs codes a form of peg or band and the other codes a form of float. The BT classification has a disagreement rate of between 16 and 21% with each of the other three schemes, whereas the disagreement rate between the other three is always somewhat higher (27.2% for IMF/IRR, 27.6% for IMF/OST and 22.7% for IRR/OST). Whether one should conclude from these figures that the BT classification is in some sense better than the others is not entirely clear.
4 Regime Changes
Regime changes during the period are obviously going to distort the results of any classification based on purely statistical data. In any regression analysis, any structural change tends to worsen the fit. Deciding whether an exchange rate regime is a peg or a float is largely based on the idea that the exchange rate is more predictable under a peg; any regime switch will reduce that predictability, and one would therefore expect that regime switches would make a float classification more likely. In Tables 4 and 5 we separate the comparison between the BT classification and the IMF classification shown in Table 12 into cases where the IMF regime is the same in year T as in year T-1 (Table 4) and cases where it is not (Table 5).Footnote 5
In Table 4 (no regime change) there are a total of 782 cases out of 4567 (17.1%) where the BT classification is some type of float when the IMF classification is a peg or band, or vice versa. In Table 5 (regime change) the disagreements of this sort amount to 208 cases out of 728 (28.6%), substantially higher than in Table 4. We can further separate these disagreements into cases where an IMF float is a BT peg and vice versa. In Tables 4, 430 out of 1307 IMF floats (31.1%) are BT pegs, whereas in Table 5 this proportion is actually lower (78 out of 2876, or 27.3%). If we look at IMF pegs that are BT floats, however, we get very much the opposite picture: there are 375 out of 3260 such cases in Table 4 (11.5%), and 130 out of 462 such cases in Table 5 (28.1%). So a switch of IMF regime makes a BT peg classification less likely but a BT float classification more likely. This confirms the conjecture that regime switches tend to bias statistical measures towards greater exchange rate flexibility.
5 Continuous Measures of Exchange Rate Flexibility
Two of the classification schemes that we have been considering offer continuous measures of exchange rate flexibility. In each case there tend to be some outliers at the upper end, so any statistics that we report refer to the median or percentiles rather than the mean of these measures, and in any regression, each measure is trimmed at the upper end by dropping the highest 2 % of observations. In the BT classification, the RMSE itself is a natural measure of flexibility relative to the estimated central rate, which may be a constant, or undergo one step change (if the B regressions are being used) and/or be subject to a trend. In the OST dataset, data are given for the standard deviation of the proportional rate of change of the nominal exchange rate against the identified anchor currency (EVOL). This allows for a trend, which would emerge in the mean rather than the standard deviation, but unlike RMSE EVOL will be affected by a step change in the central rate.Footnote 6
Table 6 shows the median value of these two statistics (each multiplied by 100) for each regime classification. In the first column RMSE has a steady gradation from zero or close to it for the tightest peg, up to the highest value for an independent or high-volatility float. In the second column EVOL shows a similar pattern but with two exceptions. For a BT Peg with Parity Change, its median is 3.323, which is considerably higher than for a Low-Volatility Float. This is because a parity change affects the value of EVOL. The other classification where EVOL seems out of line with RMSE is an IMF Basket Peg, where the EVOL median value of 1.556 is well above the value for a Band or a Crawl, and almost as large as for an IMF Managed Float. This presumably reflects the fact that the OST algorithm searches for single-currency pegs only, and not basket pegs.
More detailed information about the distribution of RMSE and EVOL, including the quintiles of the distribution, are given in Appendix Table 18. To test the statistical significance of the differences in RMSE and EVOL across regime classifications, Table 7 shows some regression analysis of each numerical index (multiplied by 100) on the regime dummies for the IMF classification. The numerical indices are trimmed at the upper end (2 %), and the regressions include country and year dummies. The omitted category is a hard peg, so the coefficients show the difference in mean RMSE between the relevant category and a hard peg. In Column (1), the mean RMSE for conventional and basket pegs is about half the value for crawls and bands, which are in turn quite a bit smaller than managed floats, with independent floats having the highest value. At the foot of Table 7, two p-values are shown, one for the test that the coefficients of bands and managed floats are equal, and one for the test of equality between the coefficients of managed and independent floats. Both p-values in Column (1) are 0.000, indicating that independent floats have significantly higher RMSE on average than managed floats, which in turn have significantly higher RMSE than bands.
Column (2) shows a similar regression for EVOL. The pattern is similar, except for the rather high coefficient for basket pegs, and the p-values are both significant at the 0.05 level. A second significant feature is that the t-statistics in Table 7 are in most cases about twice as large for BT RMSE as for EVOL, which indicates that the RMSE measure is much more consistent for a given regime than the EVOL measure, because its standard error is about half as large. Finally Column (3) shows that the coefficients for RMSE and EVOL are not significantly different from one another in most cases, with the exception of basket pegs.
Overall, these regression results suggest that BT RMSE in particular is a satisfactory index of exchange rate flexibility that captures what classification schemes are designed to achieve: regimes that are generally thought of as more flexible have significantly higher flexibility measures on average. For EVOL, that is also true except for basket pegs.
Figures 1, 2, 3 and 4 illustrate the evolution of RMSE and EVOL since 1995 for a selection of countries. Figure 1 shows that China was narrowly pegged between 1997 and 2004, after which it shifted to a somewhat more flexible regime. Figure 2 demonstrates that RMSE tends to be quite a bit smaller than EVOL for a basket-pegging country such as Fiji. Figures. 3 and 4 show RMSE and EVOL for two floating countries: Canada and Australia. These graphs show that RMSE tends to be more stable over time, and both measures tend to be higher for Australia, which is more distant from its main trading partners than Canada.

Exchange rate flexibility measures: China

Exchange rate flexibility measures: Fiji

Exchange rate flexibility measures: Canada

Exchange rate flexibility measures: Australia
We might also ask what would happen if we used a numerical index of flexibility instead of the standard classification dummy variables in empirical applications. Here we take a very simple example: whether the world has been moving towards greater exchange rate flexibility up to 2000, and since. We first do this for our flexibility indices, and then for a float dummy from each classification scheme, based on the categories in Table 1, that is equal to one for a float and zero for a peg or band. The results are shown in Table 8 for the flexibility indices and Table 9 for the float dummies.
In Table 8 results are presented both for pooled OLS and for currency fixed effects. The results are very similar. For BT RMSE, there is a positive trend, which is significant at the 0.01 level, up to the year 1999, and a slight negative trend (significant at 0.05 with currency fixed effects but not without) since, suggesting that the late twentieth-century trend towards greater exchange rate flexibility has been reversed during the twenty-first century. For OST EVOL, the picture is rather different: a slightly negative but insignificant trend up to 1999, and a rather fast and highly significant downward trend since.
In Table 9, the float dummies in the IMF and BT classifications show a pattern similar to that of BT RMSE, of increasing flexibility up to 1999 and decreasing flexibility thereafter. For IRR, the trend is slightly negative in both periods but not statistically significant, and for OST there is a strong negative trend from 2000 onwards and an insignificant one before that, which is similar to the results for OST EVOL.
Bleaney et al. (2016) find, in particular, that inflation rates up to a level of 25% p.a. are highly significant in the choice of exchange rate regime, with higher inflation being associated with a greater likelihood of floating, and have argued that time trends in regime choice should control for this effect. They argue that the apparent increase in popularity of pegging in the twenty-first century is largely a result of falling inflation rates rather than an increased preference for pegging at a given inflation rate. For versions of the regressions in Tables 8 and 9 that control for this inflation effect, see Bleaney and Tian (2019).
6 Other Information in the Classifications
In the BT classification, there are other statistics that one might consider. The intercept of the regression provides an estimate of the trend in the central rate. In the B regressions, the coefficient of the dummy variable provides an estimate of the size of the parity change. Here, however, we focus on another statistic: the coefficients of the exchange rates themselves. What do they reveal about the choice of exchange rate anchors?
In Table 10 we tabulate, for observations coded in the BT system as some form of peg, the number of cases in which an exchange rate coefficient is greater than 0.9 (suggesting a single-currency peg), and the number of cases where there is no exchange rate coefficient greater than 0.9, by IMF regime, because that is the most disaggregated classification. It is clear that most pegs or bands are single-currency pegs to the US dollar or to the euro, except in the case of those classified by the IMF as Basket Pegs, for which 372 out of 423 cases (87.9%) have no exchange rate coefficient greater than 0.9, as one would expect for a basket peg. This result may be interpreted as statistical confirmation of these cases as basket pegs. About two-thirds (274 out of 404) of IMF Managed Floats show strong attachment to a single currency, which in 90% of cases is the US dollar.
Table 11 provides a similar tabulation for BT pegs by IRR regime. If the IRR classification is a peg, then the overwhelming likelihood is that the BT regression results suggest that it is a single-currency peg. If the IRR classification is a Crawl or a Wide Moving Band/Managed Float, then the chance of a BT exchange rate coefficient being greater than 0.9 is not that much above 50% (673/1203 = 55.9% for crawls, and 294/555 = 52.9% for Managed Floats). This figure is lower for Managed Floats than in the IMF classification, possibly because it includes some IMF Basket Pegs.
7 Conclusion
It is not easy to classify exchange rate regimes into a number of discrete categories, or to develop a satisfactory continuous measure of exchange rate flexibility. Different classification schemes are not showing any signs of converging towards agreement, because there has been little convergence on approaches to some fundamental issues, such as how much to rely on purely statistical methods, how long a time span over which to measure the regime and how much allowance to make for basket pegs and parity changes. The BT and OST classifications depend entirely on statistical algorithms, and the IRR classification largely does so, whereas the IMF de facto classification might be described as a judgement by well-informed observers backed up by statistical information. Strictly speaking, a regime exists at a point in time, but the relevant statistics can only be calculated over a certain time span, which is a year in the case of BT and OST, but somewhat longer for IRR. It has been shown here, by comparing country-years with and without a regime change according to the IMF classification, that regime changes tend to bias statistical methods towards greater flexibility. Whereas the BT and IMF classifications can identify basket pegs, OST and IRR focus solely on single-currency pegs, and our results suggest that they tend to mis-classify basket pegs as a result. Provided sizeable parity changes are infrequent, they are treated as compatible with a peg status in BT, IMF and IRR, but in many cases not so in OST.
Previous literature has not taken continuous measures of exchange rate flexibility seriously. Our results suggest that they deserve more attention. Particularly in the case of the BT RMSE measure, they show the expected relationship to discrete classifications, and with considerable consistency.
Notes
See Reinhart and Rogoff (2004, Appendix) for details. If the rolling five-year data yield a different result for years T to T + 4 to that for years T + 1 to T + 5, presumably it is the result for the later period that is used for the overlapping years T + 1 to T + 4, although this is not explicitly stated.
Bleaney and Tian (2017) suggest an F-statistic >30 for the addition of the dummy variable as the critical value.
We treat Germany 1983 and China 2005 as genuine parity changes.
The sources of regime classification data are https://www2.gwu.edu/~iiep/about/faculty/jshambaugh/data.cfm;http://www.carmenreinhart.com/data/browse-by-topic/topics/11/; and [information suppressed to preserve author anonymity].
Since the IMF classification is essentially an observation at a point in time (at the end of the year), a change in the classification since the previous year tends to indicate a change of regime during the year.
EVOL is quite similar to the z-statistic suggested by Ghosh et al. (2002), which is equal to the square root of the sum of the square of the mean rate of monthly depreciation against the anchor currency and its variance. The difference is that EVOL takes no account of the mean.
References
Bleaney MF, Tian M (2017) Measuring exchange rate flexibility by regression methods. Oxf Econ Pap 69(1):301–319
Bleaney MF, Tian M (2019) Exchange rate flexibility: how should we measure it? University of Nottingham Centre for Finance Credit and Macroeconomics Discussion Paper no. 19/03
Bleaney MF, Tian M, Yin L (2016) Global trends in the choice of exchange rate regime. Open Econ Rev 27:71–85
Bleaney MF, Tian M, Yin L (2017) De facto exchange rate regime classifications: an evaluation. Open Econ Rev 28:369–382
Eichengreen B, Razo-Garcia R (2013) How reliable are De Facto exchange rate regime classifications? Int J Financ Econ 18:216–239
Frankel J (2019) Systematic managed floating, Open Economies Review, forthcoming
Frankel J, Wei S-J (1995) Emerging currency bBlocs. In: Genberg H (ed) The International Monetary System: its institutions and its future. Berlin, Springer
Ghosh AR, Gulde A-M, Wolf HC (2002) Exchange rate regimes: causes and consequences. MIT Press, Cambridge
Ilzetzki E, Reinhart CM, Rogoff KS (2017) Exchange rate arrangements entering the 21st century: which anchor will hold? Q J Econ 134:599–646
Klein MW, Shambaugh JC (2010) Exchange rate regimes in the modern era. MIT Press, Cambridge, Mass
Levy-Yeyati E, Sturzenegger F (2005) Classifying exchange rate regimes: deeds versus words. Eur Econ Rev 49(3):1603–1635
Obstfeld M, Shambaugh JC, Taylor AM (2010) Financial stability, the Trilemma, and international reserves. Am Econ J Macroecon 2:57–94
Reinhart CM, Rogoff K (2004) The modern history of exchange rate arrangements: a re-interpretation. Q J Econ 119:1–48
Rose AK (2011) Exchange rate regimes in the modern era: fixed, floating and flaky. J Econ Lit 49(3):652–672
Shambaugh J (2004) The effect of fixed exchange rates on monetary policy. Q J Econ 119(1):301–352
Slavov ST (2013) De jure versus de facto exchange rate regimes in sub-Saharan Africa. J Afr Econ 22:732–756
Tavlas G, Dellas H, Stockman AC (2008) The classification and performance of alternative exchange-rate systems. Eur Econ Rev 52:941–963
Acknowledgements
the authors wish to thank the editor, George Tavlas, and two anonymous referees for helpful comments on a previous version of this paper. Any errors that remain are of course the authors’ responsibility.
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s Note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Appendix
Appendix
Rights and permissions
Open Access This article is licensed under a Creative Commons Attribution 4.0 International License, which permits use, sharing, adaptation, distribution and reproduction in any medium or format, as long as you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons licence, and indicate if changes were made. The images or other third party material in this article are included in the article's Creative Commons licence, unless indicated otherwise in a credit line to the material. If material is not included in the article's Creative Commons licence and your intended use is not permitted by statutory regulation or exceeds the permitted use, you will need to obtain permission directly from the copyright holder. To view a copy of this licence, visit http://creativecommons.org/licenses/by/4.0/.
About this article

Cite this article
Bleaney, M., Tian, M. Exchange Rate Flexibility: How Should We Measure It?. Open Econ Rev 31, 881–900 (2020). https://doi.org/10.1007/s11079-019-09577-z
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11079-019-09577-z