
Abstract
In recent years, ensemble learning has become a prolific area of study in pattern recognition, based on the assumption that using and combining different learning models in the same problem could lead to better performance results than using a single model. This idea of ensemble learning has traditionally been used for classification tasks, but has more recently been adapted to other machine learning tasks such as clustering and feature selection. We propose several feature selection ensemble configurations based on combining rankings of features from individual rankers according to the combination method and threshold value used. The performance of each proposed ensemble configuration was tested for synthetic datasets (to assess the adequacy of the selection), real classical datasets (with more samples than features), and DNA microarray datasets (with more features than samples). Five different classifiers were studied in order to test the suitability of the proposed ensemble configurations and assess the results.












Similar content being viewed by others
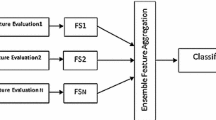
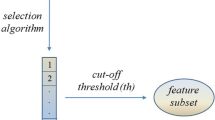
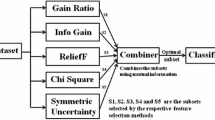
References
Abdi H (2007) The Kendall rank correlation coefficient. Encyclopedia of measurement and statistics. Sage, Thousand Oaks
Abeel T, Helleputte T, Van de Peer Y, Dupont P, Saeys Y (2010) Robust biomarker identification for cancer diagnosis with ensemble feature selection methods. Bioinformatics 26(3):392–398
Aerts S, Lambrechts D, Maity S, Van Loo P, Coessens B, De Smet F, Tranchevent LC, De Moor B, Marynen P, Hassan B et al (2006) Gene prioritization through genomic data fusion. Nat Biotechnol 24(5):537–544
Aha DW, Kibler D, Albert MK (1991) Instance-based learning algorithms. Mach Learn 6(1):37–66
Asuncion A, Newman D (2007) UCI machine learning repository. http://archive.ics.uci.edu/ml/datasets.html
Basu M, Ho TK (2006) Data complexity in pattern recognition. Springer Science & Business Media, Berlin
Bay SD (1998) Combining nearest neighbor classifiers through multiple feature subsets. In: ICML, vol 98, Citeseer, pp 37–45
Bolón-Canedo V, Sánchez-Maroño N, Alonso-Betanzos A (2013) A review of feature selection methods on synthetic data. Knowl Inf Syst 34(3):483–519
Bolón-Canedo V, Sánchez-Maroño N, Alonso-Betanzos A (2014) Data classification using an ensemble of filters. Neurocomputing 135:13–20
Bolón-Canedo V, Sánchez-Maroño N, Alonso-Betanzos A (2015) Feature selection for high-dimensional data. Springer International Publishing, Berlin
Bolón-Canedo V, Sánchez-Maroño N, Alonso-Betanzos A (2015) Recent advances and emerging challenges of feature selection in the context of big data. Knowl-Based Syst 86:33–45
Bolon-Canedo V, Moran-Fernandez L, Alonso-Betanzos A (2015) An insight on complexity measures and classification in microarray data. In: 2015 international joint conference on neural networks (IJCNN). IEEE, pp 42–49
Brahim AB, Limam M (2013) Robust ensemble feature selection for high dimensional data sets. In: 2013 international conference on high performance computing and simulation (HPCS). IEEE, pp 151–157
Breiman L (1996) Bagging predictors. Mach Learn 24(2):123–140
Breiman L (2001) Random forests. Mach Learn 45(1):5–32
Breiman L, Friedman J, Stone CJ, Olshen RA (1984) Classification and regression trees. CRC Press, Boca Raton
Burges CJ (1998) A tutorial on support vector machines for pattern recognition. Data Min Knowl Disc 2(2):121–167
Fernández-Delgado M, Cernadas E, Barro S, Amorim D (2014) Do we need hundreds of classifiers to solve real world classification problems? J Mach Learn Res 15(1):3133–3181
Freund Y, Schapire RE (1995) A decision-theoretic generalization of on-line learning and an application to boosting. In: European conference on computational learning theory. Springer, pp 23–37
Gao K, Khoshgoftaar TM, Wang H (2009) An empirical investigation of filter attribute selection techniques for software quality classification. In: IRI’09. IEEE international conference on information reuse and integration. IEEE, pp 272–277
Guyon I (2006) Feature extraction: foundations and applications, vol 207. Springer Science & Business Media, Berlin
Guyon I, Elisseeff A (2003) An introduction to variable and feature selection. J Mach Learn Res 3:1157–1182
Guyon I, Weston J, Barnhill S, Vapnik V (2002) Gene selection for cancer classification using support vector machines. Mach Learn 46(1–3):389–422
Ho TK (1998) The random subspace method for constructing decision forests. IEEE Trans Pattern Anal Mach Intell 20(8):832–844
Jain AK, Chandrasekaran B (1982) 39 Dimensionality and sample size considerations in pattern recognition practice. Handb Stat 2:835–855
Joachims T (2002) Optimizing search engines using clickthrough data. In: Proceedings of the 8th ACM SIGKDD international conference on knowledge discovery and data mining. ACM, pp 133–142
Khoshgoftaar TM, Golawala M, Van Hulse J (2007) An empirical study of learning from imbalanced data using random forest. In: 2007. ICTAI 2007. 19th IEEE international conference on tools with artificial intelligence, vol 2. IEEE, pp 310–317
Kira K, Rendell LA (1992) The feature selection problem: traditional methods and a new algorithm. In: AAAI, pp 129–134
Kolde R, Laur S, Adler P, Vilo J (2012) Robust rank aggregation for gene list integration and meta-analysis. Bioinformatics 28(4):573–580
Kononenko I (1994) Estimating attributes: analysis and extensions of relief. In: Machine learning: ECML-94. Springer, pp 171–182
Kuncheva L (2004) Combining pattern classifiers: methods and algorithms. Wiley, New York
Kuncheva L, Whitaker C (2003) Measures of diversity in classifier ensembles and their relationship with the ensemble accuracy. Mach Learn 51(2):181–207
Liu H, Setiono R (1995) Chi2: feature selection and discretization of numeric attributes. In: 2012 IEEE 24th international conference on tools with artificial intelligence. IEEE Computer Society, pp 388–388
Lyerly SB (1952) The average spearman rank correlation coefficient. Psychometrika 17(4):421–428
Mejía-Lavalle M, Sucar E, Arroyo G (2006) Feature selection with a perceptron neural net. In: Proceedings of the international workshop on feature selection for data mining, pp 131–135
Molina LC, Belanche L, Nebot À (2002) Feature selection algorithms: a survey and experimental evaluation. In: 2002. ICDM 2003. Proceedings. 2002 IEEE international conference on data mining. IEEE, pp 306–313
Morán-Fernández L, Bolón-Canedo V, Alonso-Betanzos A (2017) Centralized vs. distributed feature selection methods based on data complexity measures. Knowl Based Syst 117:27–45
Olsson J, Oard DW (2006) Combining feature selectors for text classification. In: Proceedings of the 15th ACM international conference on information and knowledge management. ACM, pp 798–799
Opitz DW (1999) Feature selection for ensembles. In: AAAI/IAAI, pp 379–384
Peng H, Long F, Ding C (2005) Feature selection based on mutual information criteria of max-dependency, max-relevance, and min-redundancy. IEEE Trans Pattern Anal Mach Intell 27(8):1226–1238
Quinlan JR (1986) Induction of decision trees. Mach Learn 1(1):81–106
Quinlan JR (2014) C4. 5: programs for machine learning. Elsevier, Amsterdam
Ren Y, Zhang L, Suganthan P (2016) Ensemble classification and regression-recent developments, applications and future directions. IEEE Comput Intell Mag 11(1):41–53
Rish I (2001) An empirical study of the naive Bayes classifier. In: IJCAI 2001 workshop on empirical methods in artificial intelligence, vol 3. IBM, New York, pp 41–46
Rodríguez D, Ruiz R, Cuadrado-Gallego J, Aguilar-Ruiz J (2007) Detecting fault modules applying feature selection to classifiers. In: IEEE international conference on information reuse and integration, IRI 2007. IEEE, pp 667–672
Schapire R (1990) The strength of weak learnability. Mach Learn 5(2):197–227
Schölkopf B, Burges CJ, Smola AJ (1999) Advances in kernel methods: support vector learning. MIT Press, Cambridge
Seijo-Pardo B, Bolón-Canedo V, Porto-Díaz I, Alonso-Betanzos A (2015) Ensemble feature selection for ranking of features. In: Advances in computational intelligence. Lecture notes in computer science, vol LN-9095, pp 29–42
Tsymbal A, Pechenizkiy M, Cunningham P (2005) Diversity in search strategies for ensemble feature selection. Inf Fus 6(1):83–98
Tukey JW (1949) Comparing individual means in the analysis of variance. Biometrics 5(2):99–114
Vapnik V (2000) The nature of statistical learning theory. Springer Science & Business Media, Berlin
Wang H, Khoshgoftaar TM, Gao K (2010) Ensemble feature selection technique for software quality classification. In: SEKE, pp 215–220
Wang H, Khoshgoftaar TM, Napolitano A (2010) A comparative study of ensemble feature selection techniques for software defect prediction. In: 2010 9th international conference on machine learning and applications (ICMLA). IEEE, pp 135–140
Willett P (2013) Combination of similarity rankings using data fusion. J Chem Inf Model 53(1):1–10
Windeatt T, Duangsoithong R, Smith R (2011) Embedded feature ranking for ensemble mlp classifiers. IEEE Trans Neural Netw 22(6):988–994
Yang F, Mao K (2011) Robust feature selection for microarray data based on multicriterion fusion. IEEE/ACM Trans Comput Biol Bioinform (TCBB) 8(4):1080–1092
Yang CH, Huang CC, Wu KC, Chang HY (2008) A novel ga-taguchi-based feature selection method. In: International Conference on Intelligent Data Engineering and Automated Learning. Springer, Berlin, Heidelberg, pp 112–119
Yu L, Liu H (2004) Efficient feature selection via analysis of relevance and redundancy. J Mach Learn Res 5:1205–1224
Zheng Z, Webb GI (1998) Stochastic attribute selection committees. Springer, Berlin
Acknowledgements
This research was financially supported in part by the Spanish Ministerio de Economía y Competitividad (Research Project TIN 2015-65069-C2-1R), partially funded by FEDER funds of the European Union and by the Consellería de Industria of the Xunta de Galicia (Research Project GRC2014/035). V. Bolón-Canedo acknowledges Xunta de Galicia postdoctoral funding (ED481B 2014/164-0). Financial support from the Xunta de Galicia (Centro singular de investigación de Galicia accreditation 2016–2019) and the European Union (European Regional Development Fund—ERDF) (Research Project ED431G/01), is gratefully acknowledged.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
About this article

Cite this article
Seijo-Pardo, B., Bolón-Canedo, V. & Alonso-Betanzos, A. Testing Different Ensemble Configurations for Feature Selection. Neural Process Lett 46, 857–880 (2017). https://doi.org/10.1007/s11063-017-9619-1
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11063-017-9619-1