
Abstract
In 3D image compression, depth image based rendering (DIBR) is one of the latest techniques where the center image (say the main view, is used to synthesise the left and the right view image) and the depth image are communicated to the receiver side. It has been observed in the literature that most of the existing 3D image watermarking schemes are not resilient to the view synthesis process used in the DIBR technique. In this paper, a 3D image watermarking scheme is proposed which is invariant to the DIBR view synthesis process. In this proposed scheme, 2D-dual-tree complex wavelet transform (2D-DT-CWT) coefficients of centre view are used for watermark embedding such that shift invariance and directional property of the DT-CWT can be exploited to make the scheme robust against view synthesis process. A comprehensive set of experiments has been carried out to justify the robustness of the proposed scheme over the related existing schemes with respect to the JPEG compression and synthesis view attack.
Similar content being viewed by others
Avoid common mistakes on your manuscript.
1 Introduction
The recent improvements in multimedia communication and wide availability of cheap hardware display devices make the 3D media transmission more attractive due to its enticing viewing experience. Consequently, the secure 3D image transmission becomes an emerging research topic. Although digital image watermarking has been regarded as an efficient Digital right management (DRM) tool for efficient ownership as well as content authentication from the last decade, 3D image watermarking has been paid a bit less attention until recently. In this DRM tool (watermarking), the ownership ID (can be a signal or message) is inserted with the digital media in such a way that it does not degrade the visual quality. The main aim of this technique is to secure the media in such a way that, ownership ID could not be destroyed by different attacks.
In 3D viewing, pixels move horizontally from left to right view [7]. So, there will be a common region (dependent view), and uncommon region (independent view) in the left and right views where the independent view parts are responsible for generating the 3D view of the image and dependent view is required to generate the main view.
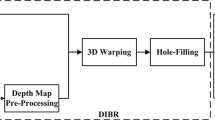
In recent time, depth-image-based rendering (DIBR) based 3D image representation [8, 36] becomes popular due to its compression efficiency. It has been observed in literature [15, 17, 29] that the efficient watermarking system for authenticating DIBR 3D image encoding should consider situations not only where both the virtual left and right views are illegally distributed as 3D content but also where each single view, including the original center view, illegitimately transmitted [5, 32, 33]. Due to certain inherent features like pixel disparity and changes in the depth image etc., the direct extension of existing conventional watermarking schemes for 2D and stereo images [4, 13, 21, 28, 30, 35] are not very useful for DIBR [9] based encoding. In other words, the main challenge is to embed the watermark in such a way that the watermark should resist the view generation process (it can be treated as a potential attack named as synthesis view attack) of the DIBR technique.
Campisi [4] first proposed the concept of 3D image watermarking technique using the depth. Few more schemes have been reported in this direction, (for example, the scheme proposed by Halici and Alatan [13] and the ROI based scheme by Li et al. [28],) but most of the schemes embed the watermark in the left and right view separately. Due to the presence of multiple watermarks for a single coefficient, these schemes are found not to be sufficiently robust against the synthesis view process. Later, Subramanyam et al. proposed a compressed domain image watermarking scheme in [30]. Wang et al. proposed a Discrete wavelet transform (DWT) based watermarking scheme in [35] for image quality enhancement. Korus et al. in [21] proposed an image watermarking scheme for fast embedding. But none of these schemes [21, 30, 35] have considered the DIBR image representation. As a result, these schemes [21, 30, 35] may not resist the view synthesis attack for the DIBR-3D image. Recently, Lin and Wu [23], proposed a blind watermarking scheme where the watermark was embedded in the center view image after detecting the dependent regions by rendering the center view to the left and right view and inverse rendering to the center view using the DIBR technique. In this scheme [23], authors embedded the watermark with the DC coefficients of block size 8 × 8 and 16 × 16. In the time of extraction, the authors take the reference locations of the shifted watermark (using disparity and DIBR technique) to generate the watermark signal. In this case, if the disparity of the image is not available at the receiver side, the extraction process may not be accurate from the left and the right view. Moreover, during watermark embedding [23], block size is taken 8 × 8 and 16 × 16. Since the average disparity normally is around 200 pixels, embedding in smaller blocks such as 8 × 8 and 16 × 16 may not always guarantee the accurate reconstruction of the watermark. As a result, this scheme may not resist the view synthesis attack efficiently. Similarly, in [16] Jaipuria proposed a blind DWT based watermarking scheme for DIBR 3D images by inserting the watermark sequence in the center view image obtained using the reverse rendering process as presented in [23]. Like the Lin and Wu’s scheme [23], it is not sustainable against view synthesis attack due to the embedding block length is lesser than that of disparity. In another work, Kim et al. proposed a DT-CWT based 3D image watermarking scheme [18] where the watermark is embedded with the shift invariant DT-CWT coefficients of the center view for DIBR-3D representation. The authors used (Iw/8) × (Ih/8) blocks to insert a single watermark bit where Iw and Ih represent the width and height of the image respectively. However, for low resolution images, the Kim’s scheme [18], having block size (Iw/8 × Ih/8), may not be able to resist the view synthesis attack specially when the disparity is higher than the block width. Later, Asikuzzaman has incorporated the dual-tree complex wavelet transform on video sequences in [3] by extending the Kim’s scheme [18] with 8 × 8 embedding block size. Like the previous scheme [18], the scheme [3] might not resist the view synthesis attack for high-resolution images and video sequences, when the disparity is higher than the block width. In [11], Yonggang proposed 3D-DCT based image watermarking scheme for DIBR technique. However, this scheme may also not be sufficiently robust against the view synthesis process due to not considering the DIBR image representation of the 3D image at the time of watermark embedding. Trick et al. proposed a context-dependent watermarking technique [31] for 3D images. But in the time of embedding the watermark, authors did not consider the characteristics of DIBR based rendering. As a result, the locations of the watermark may not be available after DIBR based view synthesis process which makes the scheme fragile against view synthesis attack. Arun and Poul proposed a DWT based watermarking scheme for DIBR-3D images in [2] where the middle range frequencies after 1st level of DWT are used to perform the 2nd and 3rd level of DWT and 4 × 4 block Discrete cosine transform is carried out with the middle range frequencies for insertion of the watermark to make the scheme imperceptible to the human vision. In this scheme [2], it is observed that the embedding block size is 32 × 32 [4 × 4 for DCT and 8 × 8 for 3rd level of DWT] to insert a single watermark bit. As a result, the scheme [2] may not sustain in a real scenario where the disparity is generally more than 200 pixel. Later, Guan et al. proposed a blind depth region based watermarking scheme for DIBR 3D images in [12] to secure the original image with depth. But depth is very smooth region and different smoothing attack can be used to destroy the watermarking scheme. Also, object based depth smoothing [14] can be incorporated to remove the watermark from the depth of the 3D images. Recently, Franco et al. proposed a virtual view invariant frame by frame 3D video watermarking scheme [10] where the watermark is embedded with the coefficients of each row to make the watermarking scheme robust against synthesis view attack. The row pixel positions may change with respective to the left and the right view images due to the presence of independent regions. Franco’s scheme [10] didn’t handle the above scenario at the time of embedding. Moreover, the row-wise bit embedding may result in visual artefacts. In 2014, Rana and Sur have proposed an independent view region based watermarking scheme [25] where the watermark is embedded with the independent view region (Z-axis) of the left and right view video. The main idea of this Z-axis based scheme is that the independent view region is mutually exclusive and thus the watermark region can’t be colluding [34] for multi-view depth coding [5]. But due to the partial presence of the main independent view regions in the synthesis view, the watermarking scheme could not resist the synthesis view attack. Same authors have proposed another 3D video watermarking scheme[26] where the watermark is embedded by altering the 2D-DT-DWT coefficients of the center view of the video frame to make the scheme robust against view synthesis attack. In this method, the embedding block width is taken larger than the disparity to resist the view synthesis attack. However, this makes the embedding block size to be dependent on the corresponding disparity value which may not be good design criteria.
It has been observed in the above discussion that most of the existing schemes are vulnerable to the DIBR based view synthesis process. In DIBR-3D image representation, the centre view is used to generate the synthesized views as explained earlier. As a result, the synthesized views will content the watermarked dependent view regions and the un-watermarked independent view regions (generated using the hole filling technique). Since centre view image does not have the independent component corresponding to its any of synthesized views [7], the watermark should be extracted from the dependent regions of any synthesized views. Identification of the independent regions in the synthesized views will improve the coefficient selection in time of watermark extraction. Separating the dependent regions from synthesized view, is the most important task while the watermark is extracted. This task is one of the major contributions of this paper which is done by an efficient zone selection scheme. Analysing the 2D-DT-DWT coefficients gives distinguishable characteristics to separate the dependent regions and the hole-fill regions (independent regions). Then a novel coefficients partitioning method is proposed using a threshold checking to handle the missing coefficients and movement of the pixels in the synthesized views. A polar angle orientation based watermarking embedding and extraction scheme are presented respectively.
In summary, a research background is formulated by analysing the DT-CWT coefficients for dependent and the independent views of the DIBR-3D representation in Section 2. The zone selection and the watermark embedding & extraction models are explained in the Section 3. The experimental results are presented in the Section 4 and finally, the paper is concluded in Section 5.
2 Research background
2.1 Rendering of DIBR-3D-image
As discussed in the previous section, DIBR-3D-image representation [8, 36] becomes popular for its compression efficiency. In the time of viewing of the 3D image, the independent region is only visible to either left or right view. So a visual discomfort may occur [17, 24] for the existence of the independent view. On other hands, perturbation in the independent regions may not substantially downgrade the image quality with respect to the human vision [22, 25]. In this DIBR-3D-Image representation, only centre view image and its depth map have been transmitted to the receiver end where left and right views are rendered with the help of centre view image, its depth and corresponding disparity [36] according to the (1)
where disp is the disparity, \({D_{X_{C}}}\) is the depth value of the center view image for the location XC and XL & XR are the corresponding shifted locations for the left and the right view respectively. T is the baseline distance between the reference view to the synthesis view. For the center view to the left and the right view, the baseline distance is taken as T = 1/2 for rendering from center view to left and right view.
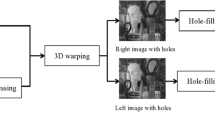
The left and the right views are obtained by rendering the center view using the DIBR technique. In this rendering process, dependent parts are fully obtained but the independent part is partially obtained from the center view (since the center view is the intermediate view of the left and the right view and independent region information is partially available). As a result, the unavailable regions creates holes in left and right views. In a DIBR-3D image, the holes of the independent regions are filled up using the hole filling process, where the average values of the boundary pixels are used to fill the regions [36] as shown in Fig. 1. As the independent regions are less sensitive to human vision, the artefacts created using the hole filling technique may not degrade the quality with respect to the human visual perception. It is observed that, due to the hole filling technique, the independent regions gives a horizontal line pattern for the left and the right views of the DIBR-3D-image (refer to Fig. 1).

Dependent and independent regions of synthesized left view (view 1) of Aloe image from center view (view 3)
2.2 Dual tree complex wavelet transform (DT-CWT)
Kingsbury [1, 20] first presented the DT-CWT to analyse it’s shift invariant property. In real dual tree transform (DT-DWT), two independent discrete wavelet transforms (DWTs) are exploited for each tree. Two real dual tree wavelet coefficient (where the second transform is done by picking the opposite samples of the first one) are combined to generate the complex wavelet coefficients as shown as
where ha and hb are the real coefficients of the tree ‘a’ and tree ‘b’ as explained above for DT-CWT overx.
According to Kingsbury [1, 20], it is observed that the DT-CWT is invariant to small shift or geometric distortion. Also, it is observed in the literature [18] that the PSNR between center view and left (or right) view, is relatively better when DT-CWT is used in comparison with DCT or FFT. Moreover, it is experimentally observed that the change of the magnitude of the DT-CWT coefficients due to the DIBR is very less. For the shift of 16 pixels, the rate of change of the energies is less than the ratio of 1.025 : 1 for the DT-CWT coefficients, whereas energies of the DWT coefficient vary by up to 5.45 : 1 [19]. So insertion of the watermark with the DT-CWT coefficients may improve the robustness than DCT of FFT domain watermarking technique against DIBR based view synthesis process. DT-CWT produces six filtered real and complex coefficients at orientation angle 15°, 45°, 75°, − 75°, − 45°, − 15° (let H1, H2, H3, H4, H5, H6). Figure 2b shows the of DT-CWT coefficients for the image Fig. 2a. In the PSNR comparison, it is also observed in the literature [18] that H1, H2, H5, H6 coefficients of DT-CWT are higher than that of H3, H4 coefficients for the 2D-DT-CW transformation. It is also experimentally observed that the PSNR between coefficient H2 and H5 shows highest similarity than any other coefficient pairs for the 2D-DT-CWT [18]. These facts suggest us to embed the watermark using the H2 and H5 coefficients i.e of orientation angle 45° and − 45° to improve the strength against the horizontal shift of the pixels during DIBR process.

DTCWT coefficients
By observing the characteristics of the DT-CWT (as shown in Fig. 2), it can be said that the values of H1, H6 is maximum and H3, H4 is minimum (very close to zero) for real and complex coefficients in a horizontal straight line. Interestingly, an inverse relation has been observed for the vertical lines. Likely an inverse effect is noticed at the original image due to change of the DT-CWT real and complex coefficients which is Gabor like impulse response as shown in Fig. 3. Also, by analysing the values of the DT-CWT coefficients as shown in Fig. 2b, it is observed that H3, H4 follow the (2) for horizontal line
where H3R & H4R defines the real and H3C & H4C defines the complex part of the H3, H4 coefficients respectively. Thus it can be said that for the polar orientation, H3, H4 coefficients will follow the (3)
where \(\theta _{H_{3}}\) and \(\theta _{H_{4}}\) are defined the angle 𝜃 of the polar orientation in the form of mei𝜃 for the coefficients H3, H4 respectively. Moreover, the magnitudes (m) in the polar representation for the H2, H3, H4, H5 are near to zero (because of the real and complex coefficients are near to zero) where for H2, H5 the magnitude is minimum than other coefficients and the 𝜃 of the coefficients follow the (4)
where \(\theta _{H_{2}}\) and \(\theta _{H_{5}}\) are defined the angle 𝜃 of the polar orientation of the coefficients H2 & H5 respectively. So the embedding of watermark with the coefficients H2 & H5 should be such a way that the procedure does not match the (4) which helps to remain imperceptible with respect to the human vision.

Impact on original image due to change in DT-CWT wavelet coefficients
3 Proposed scheme
In this proposed scheme, the watermark is embedded in the center view image (or the main view), which is then used to render left and right view images for a DIBR-3D representation. One of the main challenges of the proposed scheme is to make the scheme invariant to the view generation process such that it can be efficiently extracted from any views rendered from the center view using DIBR technique. So the primary goal of this work is to choose the embedding zone such a way that view invariant watermarking can be achieved. In this scheme, the shift invariant property of the DT-CWT [1, 20] transformation has been exploited and selected DT-CWT coefficients of the carefully chosen center view image zones are used for embedding. A zone selection process is illustrated in Section 3.1 and watermark embedding and extraction algorithms are described in subsequent subsections.
3.1 Zone selection
In the DIBR-3D image representation, pixels can move horizontally towards left or right direction for different views. To generate the synthesized left and right views from the center view, depth parameter, and the disparity information are used to detect the movement of each pixel as discussed in the previous section. Due to this horizontal pixel movement during the view synthesis process, the strength of embedded watermark may degrade. In this work, this horizontal pixel movement is handled by exploiting the shift invariant property of the DT-CWT process. In other words, the DT-CWT coefficients of the center image are used for watermark embedding such that the scheme becomes invariant to the horizontal pixel shifting (view synthesis) process. To increase the robustness, 3rd level DT-CWT coefficients are used for embedding. As the watermark is embedded in the center view image, independent regions of the corresponding left or right view image (which essentially does not contain any watermark) should not be used for watermark extraction, otherwise, the robustness of the scheme may degrade. To achieve this, separate embedding and extraction zone selection schemes are explained in the next subsections.
3.1.1 Zone selection for embedding
To make the scheme robust against view synthesis process, a threshold based embedding coefficient selection process has been employed in this work where robustness threshold (τ) is used to select the 3rd level of 2D-DT-CWT coefficients of orientation angle 45° and − 45° (\(H^{l3}_{2}\), \(H^{l3}_{5}\)). The magnitude (m) of the coefficients are checked with the robustness threshold (τ) to satisfy the Condition 1.
In this paper, by experimental observation, threshold (τ) is defined by the (5)
where Cavg is the average of all the pixels of the image and \(\mathcal {R}\) is the robustness factor. Value of R should be taken such a way that the horizontal line pattern should not be selected as the embedding coefficients as those coefficients may create missing of coefficients in time of extraction. As 2D-DT-CWT is the combination of 4 DWT and the diagonal coefficients can be represented in the form of 45° and − 45° coefficients. In 1st DWT, the relation between the image and the low pass coefficients can be represented as \(C_{avg}=\frac {L^{l1}_{avg}}{2}\) where Lavg is the average of low pass coefficients. So after 2nd level the relation will be \(C_{avg}=\frac {L^{l1}_{avg}}{4}\). Hence the difference of one-pixel value is increased by four times. Here the increasing factor will propagate into the 3rd level diagonal coefficients. Now according to the 2D-DT-CWT the \(H^{l3}_{2}\), \(H^{l3}_{5}\) will contain four times of original pixel difference. In a real scenario, the average of the pixels of an image Cavg will be ≈ 128. To achieve the value of the 1-pixel difference at 3rd level, a robustness factor \(\mathcal {R}\) is needed to compare the relation. For experimental purpose robustness factor is taken as \(\mathcal {R}= 128/4 = 32\).
In this proposed scheme, the number of coefficients selected for embedding or extraction of the watermark, may not be always same because some of the coefficients may not available in the synthesized view due to the DIBR view synthesis process. These absent coefficients cause holes in DIBR 3D view generation process. Due to the presence of holes in the synthesized views, watermark quality can be degraded. To handle this problem, embedding coefficients (3rd level of 2D-DT-CWT coefficients) should be filtered such a way that the noisy coefficients are removed. As a result, the number of embedding and extraction coefficients may not be equal. To handle this, 3rd level of 2D-DT-CWT coefficients in each row are successively partitioned into 4 equal parts. In this scenario, let k number of coefficients in jth row satisfy the Condition 1. Now each part will contain \(\frac {k}{4}\) number of coefficients of jth row for insertion of a unique set of watermark bits.
3.1.2 Zone selection for extraction
In center view based embedding schemes, the watermark can be extracted either from the original center view or from the synthesized left or right views. In a case of original center view (where the watermark is actually embedded), the watermark extraction is very straight forward and just reverse of the embedding process. In the case of synthesized views, the extraction process is a bit involved as these views have two components, first, the dependent zone where watermark bits are generally embedded and second is the independent zone where no watermark bits are embedded. So one of the important tasks is to accurately identify the independent regions and removes them from watermark extraction process. Essentially this task is bit easy when the watermark is extracted from the main (center) view but is relatively complicated in synthesized views. In this work, the peculiarity of DT-CWT coefficients has been capitalized to accurately identify the independent zone coefficients. It is already explained (refer to Section 2.2) that in the independent region, the magnitude of the DT-CWT coefficients of orientation angle 45° and − 45° is very close to zero due to the horizontal lines. In this case, the threshold based approach (refer to Sections 3.1.1 (3.1.1)) is used to remove the independent regions and un-watermarked coefficients. Nevertheless, the proposed approach may not be able to remove all the independent region coefficients as the threshold checking is done at 3rd level of 2D-DT-CWT coefficients.
To remove the remaining independent region coefficients, a further checking has been employed. It is experimentally observed that if 3rd level DT-CWT coefficients follow the (3), (4) (the DT-CWT property as described in Section 2.2) the corresponding 2D-DT-CWT coefficients should belong to the independent region. For these case, (3) along with polar magnitudes (m) for H2, H3, H4 and H5 (the 1st level DT-CWT coefficients) are checked to decide whether the corresponding coefficients belongs to independent zone or not.
3.1.3 Key based encryption
A security key (κ) is used to select the coefficients in each partition for embedding and extraction to make the scheme more secure against naive randomization based attacks by increasing the cryptographic search space for the block selection. How the security key (κ) is used to increase the cryptographic security is described below:
as described earlier \(\frac {k}{4}\) be the number of coefficients in each group. The key (κ) is used to select η coefficients for embedding. Then the cryptographic length (κl) of the function will be a combination of number of available coefficients and the expected number of coefficient in each part as shown in (6)
where \(4\frac {I_{h}}{8} \) (as 4 partition × 3rd level of 2D-DT-CWT) represents the number of partitions in each image. In this scheme, the same key based coefficients selection is used for extraction. In time of selection the coefficients are selected in the order of magnitude (m). So that the the same coefficients are selected in time of embedding and extraction.
3.2 Watermark embedding
A random binary sequence (W ) is used as the watermark which is embedded in the selected coefficients of the suitable embedding zone as discussed in the previous section. A pair of two watermark bits (Wp) are embedded into each of the suitable coefficients of a partition as discussed in Section 3.1.1. For embedding the 3rd level of DT-CWT coefficients of orientation angle 45° and − 45° (say \(H^{l3}_{2}\) and \(H^{l3}_{5}\) respectively) are altered such a way that the embedding policy does not match the independent zone selection characteristics. In this scheme, the polar orientation angle 𝜃 of each \(H^{l3}_{2}\), \(H^{l3}_{5}\) coefficients (\(\theta _{H^{l3}_{2}}\) and \(\theta _{H^{l3}_{5}}\)) are altered with respect to the watermark bit pair. The corresponding embedding rule is depicted in Fig. 4. The embedding process is described in (7), (8)
where \(H^{l3}_{2R}\), \(H^{l3}_{2C}\) and \(H^{l3}_{5R}\), \(H^{l3}_{5C}\)are the real and complex part of the coefficient \(H^{l3}_{2}\) and \(H^{l3}_{5}\) respectively. m2 is defined the magnitude as \(m_{2}=\sqrt {\left (H^{l3}_{2R}\right )^{2}+\left (H^{l3}_{2C}\right )^{2}}\) successively \(m_{5}=\sqrt {\left (H^{l3}_{5R}\right )^{2}+\left (H^{l3}_{5C}\right )^{2}}\) and WpM & WpL are represented as the MSB and LSB of the two consecutive bits of the watermark bit pair (Wp).
In the embedding scheme as depicted in Fig. 4, the watermark bit pair “00” represents 45°, “01” represents 135°, “10” represents − 45°, “11” represents − 135° polar orientation angle of the coefficients \(H^{l3}_{2}\) and opposite quadrant for \(H^{l3}_{5}\) to increase the robustness of the watermarking scheme.

Watermark embedding rule
The step by step embedding scheme is narrated in Algorithm 1 and a block diagram of the overall embedding process is depicted in the Fig. 5.


Watermark embedding block diagram. (Explanation : 3rd level of 2D-DT-CWT is carried out on the centre view image. Embedding zone selection is carried out to find embedding coefficients with the key κ. Watermark is embedded with the selected coefficients. 3rd level of inverse 2D-DT-CWT is carried out to generate the watermarked image)
3.3 Watermark extraction
In the proposed watermarking scheme, the watermark can be extracted from any of the original or synthesized views. The extraction scheme is almost the reverse of the embedding scheme. Using the quadrant of the polar orientation of the coefficients, possible watermark bit is calculated for each part as shown in (9), (10)
where \(W^{\prime }_{00}\), \(W^{\prime }_{01}\), \(W^{\prime }_{10}\), \(W^{\prime }_{11}\) are the possible watermark variable for watermark 00, 01, 10 and 11 successively. \(\theta ^{\prime }_{H^{l3}_{2}}\) and \(\theta ^{\prime }_{H^{l3}_{5}}\) are defined as the 𝜃 of the polar orientation of the watermark coefficient.
The watermark variables are used to calculate the final extracted watermark using the (11)
where \(W^{\prime }_{p}\) is the extracted watermark bit for partition p. Finally the watermark is accumulated to get the bit sequence of the extracted watermark W′.
The step by step extraction scheme is narrated in Algorithm 2 and a block diagram of the overall extraction process is depicted in the Fig. 6.


Watermark extraction block diagram
4 Results
The proposed scheme has been tested with the Middlebury Stereo 2006 Dataset of 21 image [27] [link: http://vision.middlebury.edu/stereo/data/scenes2006/]. As the scheme is view invariant, the watermark can be extracted from the center view as well as any of the synthesis view. Also, the embedding and the extraction is independent of the depth map. So the scheme can be robust against the baseline distance change of the depth.
In this paper, the experiment is carried out using the 21 stereo image dataset, where the view id ‘1’ and view id ‘5’ are taken separately as the center view image to increase the experiment dataset. The detailed set-up for the proposed scheme is tabulated in the Table 1, where \(\mathcal {R}\) is the embedding factor and the disparity value represents the shift of pixels for DIBR-3D technique. To justify the applicability of the proposed scheme, comparisons are done with the recent existing schemes such as Lin & Wu’s scheme [23], Kim’s scheme [18], Kim’s scheme* [18], Franco’s scheme [10] and Rana’s scheme [26]. In the Kim’s scheme*, the embedding sub-block is modified to (Iw/32) × (Ih/32) to make the similar embedding payload as proposed scheme for comparison purpose.
4.1 Visual quality
Here the degradation of the watermarked image of the proposed scheme is evaluated using different visual quality metrics such as Peak Signal-to-Noise Ratio (PNSR), Structural Similarity (SSIM) and Visual Information Fidelity for pixel domain (VIFp) [link: http://mmspg.epfl.ch/vqmt]. Peak Signal-to-Noise Ratio taking into account Contrast Sensitivity Function (PSNR-HVS) [6] are used to check the visual degradation due to watermark embedding with respect to the human vision. The visual quality comparison results of the proposed scheme with the existing Lin & Wu’s scheme [23], Kim’s scheme, Kim’s scheme* [18], Franco’s scheme [10] and Rana’s scheme [26] are given in the Figs. 7, 8, 9 and 10 and Table 2.




From the visual quality comparison results, it is observed that the proposed scheme gives almost comparable (sometimes better) result for the PSNR, PSNR-HVS, SSIM, VIFp against the Lin & Wu’s scheme [23], Kim’s scheme, Kim’s scheme* [18], Franco’s scheme [10] and Rana’s scheme [26] for similar embedding payload. Also it is observed that for same embedding payload, the proposed scheme gives better visual quality than that of the existing schemes. Intuitively, using the high-level coefficients for embedding reduce the visual degradation of the proposed scheme. Maintaining the overall magnitude (refer to (8)) of the complex coefficients of 2D-DT-CWT in time of embedding gives a noticeable improvement in visual quality.
4.2 Robustness
The primary goal of this paper is to make the proposed scheme invariant to views generation process from the center view. Assuming the view synthesis using the DIBR technique as an attack, robustness of the proposed scheme is compared with the existing schemes [10, 18, 23, 26]. Moreover, since most of the images are being communicated in compressed format (such as JPEG), the robustness of the proposed scheme against JPEG compression at different quality levels that of the existing schemes and different noise addition attacks are also taken into account in this subsection. In DIBR-3D representation, viewers can adjust the baseline to a proper range (up to 10% of the image width). So the baseline distance change can be used as an attack for the DIBR-3D image representation. The robustness of the proposed scheme is compared with the existing schemes [10, 18, 23, 26] against baseline distance change attack. Also in DIBR-3D representation, the depth can be preprocessed to a blurred image or using DIBR technique, can be shifted from its original position. For this kind of preprocessing depth attack, the robustness of the proposed scheme is compared with the existing schemes [10, 18, 23, 26].
In this scheme, a random bit stream is used to embed with the original center view image. After different attack (view synthesis, JPEG compression, noise addition, baseline distance change [18] and the depth preprocessing [18, 36]), Hamming distance between the extracted watermark and the original watermark is used to determine the robustness. Here hamming distance is used as a robustness metric by comparing the normalized bit error rate where the smaller hamming distance denotes the better robustness as shown in Figs. 11, 12, 13, 14, 15, 16, 17, 18, 19, 20 and 21.











From the Figs. 11 and 12, it is observed that the proposed scheme shows almost negligible hamming distance for the center view as well as for the synthesized view at different positions. Here the experiment is done using view id ‘1’ and view id ‘5’ from the Middlebury Stereo 2006 Dataset as the center view separately. Where left and the right views are synthesized using the given disparity and the depth map. It is also observed that proposed scheme outperforms the existing schemes [10, 18, 23, 26] for different views.
From the Figs. 13 and 14, it is observed that the proposed scheme gives a better result than the existing schemes [10, 18, 23, 26] for JPEG compression quality from 20 to 100. The similar result can be observed for addition Gaussian noise (up to variance 200) and the addition of salt & pepper noise (up to the density of 0.2) as depicted in Figs. 15, 16, 17 and 18.
From the Fig. 19, it is observed that proposed scheme outperforms Lin’s scheme [23] and Franco’s scheme [10] and comparable result with the Kim’s scheme, Kim’s scheme* [18] and Rana’s scheme [26]. For a change of small baseline distance. For larger baseline distance, proposed scheme outperforms the Kim’s scheme, Kim’s scheme* [18] and Rana’s scheme [26].
Figures 20 and 21 shows the result after depth modification attack. After depth modification, the watermark is extracted from the left and the right synthesized views. Here Kim’s scheme, Kim’s scheme* [18] and Rana’s scheme [26] can somehow handle the depth modification attack for the left and the right view. Lin’s scheme [23] could not handle the depth modification attack. It is observed that the proposed scheme can handle depth blurring as well as shifted depth using DIBR technique.
From this robustness analysis, it can be claimed that the proper selection of embedding regions, improve the sustainability of the proposed scheme against different intentional and unintentional attacks. Moreover, embedding with the shift invariant \(H^{l3}_{2}\), \(H^{l3}_{5}\) coefficients, improve the robustness against view synthesis process.
4.3 Discussion
In this work, the watermark is embedded with the DT-CWT coefficients to make the watermarking scheme view invariant. The spatial synchronization has been achieved at the time of embedding and extraction of watermark for the shift invariant property of the DT-CWT coefficients.
In this scheme, the relative orientation angle of the real and complex values of 2D-DT-CWT coefficients are used for watermarking. As the magnitude remains unchanged, the embedding effect is not noticeable in the images. Due to embedding, the embedding effect will distribute in the diagonal direction due to use of \(H^{l3}_{2}\), \(H^{l3}_{5}\) coefficients. Though the absolute relation of the coefficients remains unchanged, the combined effect of real and complex coefficients does not make any visible change (as shown in Fig. 3). Also, embedding with the high-level 2D-DT-CWT coefficients does not make any visual degradation as shown in Figs. 7, 8, 9 , 10 and Table 2.
To improve the shift invariance characteristics of the proposed scheme, 3rd level of DT-CWT coefficients are used for embedding. Moreover, in the time of watermark extraction, by analysing the DT-CWT coefficients, hole filled regions (which does not contain watermark) are shorted out to remove the noise of the watermark extraction. In existing literature, it has been observed that if the embedding view and the extraction view are not same, the watermark signal is degraded. Intuitively, if the size of the embedding block is less than the disparity, the watermark signal may be extracted other than embedding coefficients. So, random noise may occur in the extracted watermark. This may be the cause that existing schemes are not performing well for the relatively large disparity values. In this proposed scheme the selection of DT-CWT coefficients are invariant to the DIBR technique (refer to Sections 3.1.1 and 3.1.2), the extracted watermark is not degraded in case of large disparity as well as baseline distance change and depth modification attack.
In other words, selection of the proper embedding coefficient, improves the robustness factor of the proposed scheme make outperform other existing schemes [10, 18, 23, 26] for different attacks as shown in Figs. 11–21. Additionally, the careful coefficient selection method and the embedding policy improves the visual quality of the proposed scheme compare to the existing schemes [10, 18, 23, 26] as shown in Figs. 7, 8, 9 and 10 and Table 2.
4.4 Time complexity analysis
In this proposed scheme, the watermark is embedded with the DT-CWT coefficients of the center view. For embedding, 3rd layer of DT-CWT is used to increase the robustness with respect to the synthesis view. It is observed that, DT-CWT is a combination of 4 DWT [1, 19, 20] (as discussed in Section 2.2). The time complexity for a 2D-DWT is \(\mathcal {O}(I_{h} I_{w})\) where Iw and Ih represent the image with and height respectively. So the time complexity for 3rd layer DT-CWT is \(\mathcal {O}\left (4I_{h} I_{w}+ 4\frac {I_{h}}{2} \frac {I_{w}}{2}+ 4\frac {I_{h}}{4} \frac {I_{w}}{4}\right )\simeq \mathcal {O}(I_{h} I_{w})\). In zone selection method (as discussed in Section 3.1), all the coefficients are checked for validate the embedding threshold. For embedding the DT-CWT coefficient values are altered (as explained in Section 3.2) for watermark insertion. For worst case all the coefficients \(4\frac {I_{h}}{8} \frac {I_{w}}{8}\)may participate for embedding. So the total time complexity can be written as \(\mathcal {O} \left ((I_{h} I_{w})+ 4\frac {I_{h}}{8} \frac {I_{w}}{8}+ 4\frac {I_{h}}{8} \frac {I_{w}}{8}\right )\simeq \mathcal {O}(I_{h} I_{w})\). For inverse DT-CWT the tome complexity is \(\mathcal {O}(I_{h} I_{w})\). Hence the final time complexity can be written as \(\mathcal {O}(I_{h} I_{w})\).
5 Conclusion
In this paper, a blind 3D image watermarking scheme has been proposed to resist the view synthesis process (synthesis view attack) and collusion attack. In this scheme, horizontally shifted spatially coherent dependent view regions of the left and right view are embedded with identical watermarks to make the scheme robust against synthesis view attack as well as the collusion attack. To improve the robustness of the proposed scheme against image compression and different noise addition attacks, a secret key is used to select the DC coefficients of the selected 4 × 4, 8 × 8 and 16 × 16 blocks to embed the watermark. A comprehensive set of experiments has been carried out to justify the applicability of the proposed scheme over the existing literature against the different attacks.
The present study is mainly restricted for the uncompressed domain 3D image watermarking. In future 3D motion can be used to proposed a content based watermarking technique.
References
Anderson R, Kingsbury N, Fauqueur J (2005) Determining multiscale image feature angles from complex wavelet phases. In: Kamel M, Campilho A (eds) Image Analysis and Recognition, ser. Lecture Notes in Computer Science, vol 3656, pp 490–498. [Online]. Available: https://doi.org/10.1007/11559573_61. Springer, Berlin
Arun K, Poul P (2013) Protection of depth-image-based rendering 3d images using blind watermarking. In: 2013 4th International Conference on Computing Communications and Networking Technologies (ICCCNT), pp 1–6
Asikuzzaman M, Alam M, Lambert A, Pickering M (2014) A blind watermarking scheme for depth-image-based rendered 3d video using the dual-tree complex wavelet transform. In: 2014 IEEE International Conference on Image Processing (ICIP), pp 5497–5501
Campisi P (2008) Object-oriented stereo-image digital watermarking. J Electron Imaging 17(4):043 024–043 024–5. [Online]. Available: https://doi.org/10.1117/1.3009554
Chen Y, Tech G, Wegner K, Yea S (2014) Test model 8 of 3d-HEVC and MV-HEVC, jct3v-h1003 ed., Joint collaborative team on 3D video coding extension development of ITU-T SG 16 WP 3 and ISO/IEC JTC 1/SC 29/WG 11 Mar.-Apr
Egiazarian K, Astola J, Ponomarenko N, Lukin V, Battisti F, Carli M (2006) New full-reference quality metrics based on hvs. In: Proceedings of the 2nd International Workshop Video Process. Quality Metrics, pp 1–4
Fan Y-C, Chi T-C (2008) The novel non-hole-filling approach of depth image based rendering. In: 3DTV Conference: The True Vision - Capture, Transmission and Display of 3D Video, 2008, pp 325–328
Fehn C (2004) Depth-image-based rendering (dibr), compression, and transmission for a new approach on 3d-tv, pp 93–104. [Online]. Available: https://doi.org/10.1117/12.524762
Fehn C, Pastoor R (2006) Interactive 3-dtv-concepts and key technologies. Proc IEEE 94(3):524–538
Franco-Contreras J, Baudry S, Doerr G (2011) Virtual view invariant domain for 3d video blind watermarking. In: 2011 18th IEEE International Conference on Image Processing (ICIP), pp 2761–2764
Fu Y (2009) Robust image watermarking scheme based on 3d-dct. In: 6th International Conference on Fuzzy Systems and Knowledge Discovery, 2009. FSKD ’09, vol 5, pp 437–441
Guan Y, Zhu Y, Liu X, Luo G, Sun Z, Zhang L (2014) A digital blind watermarking scheme based on quantization index modulation in depth map for 3d video. In: 2014 13th International Conference on Control Automation Robotics Vision (ICARCV), pp 346–351
Halici E, Alatan A (2009) Watermarking for depth-image-based rendering. In: 2009 16th IEEE International Conference on Image Processing (ICIP), pp 4217–4220
Han Y (2005) Geometric algorithms for least squares estimation of 3-d information from monocular image. IEEE Trans Circuits Syst Video Technol 15(2):269–282
Hoffman DM, Girshick AR, Akeley K, Banks MS (2008) Vergence–accommodation conflicts hinder visual performance and cause visual fatigue. J Vis 8(3):33
Jaipuria S (2014) Watermarking for depth map based 3d images using wavelet transform. In: 2014 International Conference on Communications and Signal Processing (ICCSP), pp 181–185
Kim H, Lee S (2015) Transition of visual attention assessment in stereoscopic images with evaluation of subjective visual quality and discomfort. IEEE Trans Multimed 17(12):2198–2209
Kim H-D, Lee J-W, Oh T-W, Lee H-K (2012) Robust dt-cwt watermarking for dibr 3d images. IEEE Trans Broadcast 58(4):533–543
Kingsbury N (1998) The dual-tree complex wavelet transform: a new technique for shift invariance and directional filters. In: IEEE digital signal processing workshop, pp 319–322
Kingsbury N (2001) Complex wavelets for shift invariant analysis and filtering of signals. Appl Comput Harmon Anal 10(3):234–253. [Online]. Available: http://www.sciencedirect.com/science/article/pii/S1063520300903439
Korus P, Biaas J, Dziech A (2015) Towards practical self-embedding for jpeg-compressed digital images. IEEE Trans Multimed 17(2):157–170
Lee M-J, Lee J-W, Lee H-K (2011) Perceptual watermarking for 3d stereoscopic video using depth information. In: 2011 7th International Conference on Intelligent Information Hiding and Multimedia Signal Processing (IIH-MSP), pp 81–84
Lin Y-H, Wu J-L (2011) A digital blind watermarking for depth-image-based rendering 3d images. IEEE Trans Broadcast 57(2):602–611
Patterson R (2007) Human factors of 3-d displays. J Soc Inf Disp 15(11):861–871. [Online]. Available: https://doi.org/10.1889/1.2812986
Rana S, Sur A (2014) Blind 3d video watermarking based on 3d-hevc encoder using depth. In: Proceedings of the 9th Indian Conference on Computer Vision, Graphics and Image Processing, ser. ICVGIP ’14. [Online]. Available: https://doi.org/10.1145/2683483.2683535. ACM, New York
Rana S, Sur A (2015) 3D Video watermarking using DT-DWT to resist synthesis view attack. In: 23rd European Signal Processing Conference (EUSIPCO) (EUSIPCO 2015). Nice, France
Scharstein D, Pal C (2007) Learning conditional random fields for stereo. In: IEEE Conference on Computer Vision and Pattern Recognition, 2007. CVPR ’07, pp 1–8
Sheng-li F, Mei Y, Gang-yi J, Feng S, Zong-ju P (2012) A digital watermarking algorithm based on region of interest for 3d image. In: 2012 eighth international conference on computational intelligence and security, pp 549–552
Silva VD, Fernando A, Worrall S, Arachchi HK, Kondoz A (2011) Sensitivity analysis of the human visual system for depth cues in stereoscopic 3-d displays. IEEE Trans Multimed 13(3):498–506
Subramanyam AV, Emmanuel S, Kankanhalli MS (2012) Robust watermarking of compressed and encrypted jpeg2000 images. IEEE Trans Multimed 14(3):703–716
Trick D, Berchtold W, Schafer M, Steinebach M (2013) 3d watermarking in the context of video games. In: 2013 IEEE 15th International Workshop on Multimedia Signal Processing (MMSP), pp 418–423
Valizadeh S, Nasiopoulos P, Ward R (2016) Perceptual distortion measurement in the coding unit mode selection for 3d-hevc. In: 2016 IEEE International Conference on Consumer Electronics (ICCE), pp 347–350
Valizadeh S, Nasiopoulos P, Ward R (2017) Perceptual rate distortion optimization of 3d–hevc using psnr-hvs, Multimedia Tools and Applications. [Online]. Available: https://doi.org/10.1007/s11042-017-5486-z
Vinod P, Bora P (2006) Motion-compensated inter-frame collusion attack on video watermarking and a countermeasure. In: IEE Proceedings-Information Security 153(2):61–73
Wang S, Zheng D, Zhao J, Tam WJ, Speranza F (2014) Adaptive watermarking and tree structure based image quality estimation. IEEE Trans Multimed 16(2):311–325
Zhang L, Tam WJ (2005) Stereoscopic image generation based on depth images for 3d tv. IEEE Trans Broadcast 51(2):191–199
Author information
Authors and Affiliations
Corresponding author
Additional information
Publisher’s note
Springer Nature remains neutral with regard to jurisdictional claims in published maps and institutional affiliations.
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Rana, S., Sur, A. View invariant DIBR-3D image watermarking using DT-CWT. Multimed Tools Appl 78, 16665–16693 (2019). https://doi.org/10.1007/s11042-018-7024-z
Received:
Revised:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s11042-018-7024-z