
Abstract
We consider the hard-core model with Metropolis transition probabilities on finite grid graphs and investigate the asymptotic behavior of the first hitting time between its two maximum-occupancy configurations in the low-temperature regime. In particular, we show how the order-of-magnitude of this first hitting time depends on the grid sizes and on the boundary conditions by means of a novel combinatorial method. Our analysis also proves the asymptotic exponentiality of the scaled hitting time and yields the mixing time of the process in the low-temperature limit as side-result. In order to derive these results, we extended the model-independent framework in Manzo et al. (J Stat Phys 115(1/2):591–642, 2004) for first hitting times to allow for a more general initial state and target subset.
Similar content being viewed by others


Avoid common mistakes on your manuscript.
1 Introduction
1.1 Hard-Core Lattice Gas Model
In this paper we consider a stochastic model where particles in a finite volume dynamically interact subject to hard-core constraints and study the first hitting times between admissible configurations of this model. This model was introduced in the chemistry and physics literature under the name “hard-core lattice gas model” to describe the behavior of a gas whose particles have non-negligible radii and cannot overlap [25, 41]. We describe the spatial structure in terms of a finite undirected graph \(\Lambda \) of N vertices, which represents all the possible sites where particles can reside. The hard-core constraints are represented by edges connecting the pairs of sites that cannot be occupied simultaneously. We say that a particle configuration on \(\Lambda \) is admissible if it does not violate the hard-core constraints, i.e., if it corresponds to an independent set of the graph \(\Lambda \). The appearance and disappearance of particles on \(\Lambda \) is modeled by means of a single-site update Markov chain \(\{X_t\}_{t \in \mathbb N}\) with Metropolis transition probabilities, parametrized by the fugacity \(\lambda \ge 1\). At every step a site v of \(\Lambda \) is selected uniformly at random; if it is occupied, the particle is removed with probability \(1/\lambda \); if instead the selected site v is vacant, then a particle is created with probability 1 if and only if all the neighboring sites at edge-distance one from v are also vacant. Denote by \(\mathcal I(\Lambda )\) the collection of independent sets of \(\Lambda \). The Markov chain \(\{X_t\}_{t \in \mathbb N}\) is ergodic and reversible with respect to the hard-core measure with fugacity \(\lambda \) on \(\mathcal I(\Lambda )\), which is defined as
where \(Z_{\lambda }(\Lambda )\) is the appropriate normalizing constant (also called partition function). The fugacity \(\lambda \) is related to the inverse temperature \(\beta \) of the gas by the logarithmic relationship \(\log \lambda = \beta \).
We focus on the study of the hard-core model in the low-temperature regime where \(\lambda \rightarrow \infty \) (or equivalently \(\beta \rightarrow \infty \)), so that the hard-core measure \(\mu _\lambda \) favors maximum-occupancy configurations. In particular, we are interested in how long it takes the Markov chain \(\{X_t\}_{t \in \mathbb N}\) to “switch” between these maximum-occupancy configurations. Given a target subset of admissible configurations \(A \subset \mathcal {I}(\Lambda )\) and an initial configuration \(x \not \in A\), this work mainly focuses on the study of the first hitting time \(\tau ^x_{A}\) of the subset A for the Markov chain \(\{X_t\}_{t \in \mathbb N}\) with initial state x at time \(t=0\).
1.2 Two More Application Areas
The hard-core lattice gas model is thus a canonical model of a gas whose particles have a non-negligible size, and the asymptotic hitting times studied in this paper provide insight into the rigid behavior at low temperatures. Apart from applications in statistical physics, our study of the hitting times is of interest for other areas as well. The hard-core model is also intensively studied in the area of operations research in the context of communication networks [27]. In that case, the graph \(\Lambda \) represents a communication network where calls arrive at the vertices according to independent Poisson streams. The durations of the calls are assumed to be independent and exponentially distributed. If upon arrival of a call at a vertex i, this vertex and all its neighbors are idle, the call is activated and vertex i will be busy for the duration of the call. If instead upon arrival of the call, vertex i or at least one of its neighbors is busy, the call is lost, hence rendering hard-core interaction. In recent years, extensions of this communication network model received widespread attention, because of the emergence of wireless networks. A pivotal algorithm termed CSMA [42] which is implemented for distributed resource sharing in wireless networks can be described in terms of a continuous-time version of the Markov chain studied in this paper. Wireless devices form a topology and the hard-core constraints represent the conflicts between simultaneous transmissions due to interference [42]. In this context \(\Lambda \) is therefore called interference graph or conflict graph. The transmission of a data packet is attempted independently by every device after a random back-off time with exponential rate \(\lambda \), and, if successful, lasts for an exponentially distributed time with mean 1. Hence, the regime \(\lambda \rightarrow \infty \) describes the scenario where the competition for access to the medium becomes fiercer. The asymptotic behavior of the first hitting times between maximum-occupancy configurations provides fundamental insights into the average packet transmission delay and the temporal starvation which may affect some devices of the network, see [44].
A third area in which our results find application is discrete mathematics, and in particular for algorithms designed to find independent sets in graphs. The Markov chain \(\{X_t\}_{t \in \mathbb N}\) can be regarded as a Monte Carlo algorithm to approximate the partition function \(Z_{\lambda }(\Lambda )\) or to sample efficiently according to the hard-core measure \(\mu _\lambda \) for \(\lambda \) large. A crucial quantity to study is then the mixing time of such Markov chains, which quantifies how long it takes the empirical distribution of the process to get close to the stationary distribution \(\mu _\lambda \). Several papers have already investigated the mixing time of the hard-core model with Glauber dynamics on various graphs [4, 22–24, 38]. By understanding the asymptotic behavior of the hitting times between maximum-occupancy configurations on \(\Lambda \) as \(\lambda \rightarrow \infty \), we can derive results for the mixing time of the Metropolis hard-core dynamics on \(\Lambda \). As illustrated in [29], the mixing time for this dynamics is always smaller than the one for the usual Glauber dynamics, where at every step a site is selected uniformly at random and a particle is placed there with probability \({\frac{\lambda }{1+\lambda }}\), if the neighboring sites are empty, and with probability \({\frac{1}{1+\lambda }}\) the site v is left vacant.
1.3 Results for General Graphs
The Metropolis dynamics in which we are interested for the hard-core model can be put, after the identification \(e^\beta =\lambda \), in the framework of reversible Freidlin–Wentzell Markov chains with Metropolis transition probabilities (see Sect. 2 for precise definitions). Hitting times for Freidlin–Wentzel Markov chains are central in the mathematical study of metastability. In the literature, several different approaches have been introduced to study the time it takes for a particle system to reach a stable state starting from a metastable configuration. Two approaches have been independently developed based on large deviations techniques: The pathwise approach, first introduced in [8] and then developed in [35–37], and the approach in [9–13, 40]. Other approaches to metastability are the potential theoretic approach [5–7] and, more recently introduced, the martingale approach [1–3], see [16] for a more detailed review.
In the present paper, we follow the pathwise approach, which has already been used to study many finite-volume models in a low-temperature regime, see [14, 15, 18–20, 28, 33, 34], where the state space is seen as an energy landscape and the paths which the Markov chain will most likely follow are those with a minimum energy barrier. In [35–37] the authors derive general results for first hitting times for the transition from metastable to stable states, the critical configurations (or bottlenecks) visited during this transition and the tube of typical paths. In [31] the results on hitting times are obtained with minimal model-dependent knowledge, i.e., find all the metastable states and the minimal energy barrier which separates them from the stable states. We extend the existing framework [31] in order to obtain asymptotic results for the hitting time \(\tau ^x_{A}\) for any starting state x, not necessarily metastable, and any target subset A, not necessarily the set of stable configurations. In particular, we identify the two crucial exponents \(\Gamma _-(x,A)\) and \(\Gamma _+(x,A)\) that appear in the upper and lower bounds in probability for \(\tau ^x_{A}\) in the low-temperature regime. These two exponents might be hard to derive for a given model and, in general, they are not equal. However, we derive a sufficient condition that guarantees that they coincide and also yields the order-of-magnitude of the first moment of \(\tau ^x_{A}\) on a logarithmic scale. Furthermore, we give another slightly stronger condition under which the hitting time \(\tau ^x_{A}\) normalized by its mean converges in distribution to an exponential random variable.
1.4 Results for Rectangular Grid Graphs
We apply these model-independent results to the hard-core model on rectangular grid graphs to understand the asymptotic behavior of the hitting time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\), where \({\mathbf {e}}\) and \({\mathbf {o}}\) are the two configurations with maximum occupancy, where the particles are arranged in a checkerboard fashion on even and odd sites. Using a novel powerful combinatorial method, we identify the minimum energy barrier between \({\mathbf {e}}\) and \({\mathbf {o}}\) and prove absence of deep cycles for this model, which allows us to decouple the asymptotics for the hitting time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) and the study of the critical configurations. In this way, we then obtain sharp bounds in probability for \(\tau ^{\mathbf {e}}_{\mathbf {o}}\), since the two exponents coincide, and find the order-of-magnitude of \(\mathbb E\tau ^{\mathbf {e}}_{\mathbf {o}}\) on a logarithmic scale, which depends both on the grid dimensions and on the chosen boundary conditions. In addition, our analysis of the energy landscape shows that the scaled hitting time \(\tau ^{\mathbf {e}}_{\mathbf {o}}/ \mathbb E\tau ^{\mathbf {e}}_{\mathbf {o}}\) is exponentially distributed in the low-temperature regime and yields the order-of-magnitude of the mixing time of the Markov chain \(\{X_t\}_{t \in \mathbb N}\).
By way of contrast, we also briefly look at the hard-core model on complete K-partite graphs, which was already studied in continuous time in [43]. While less relevant from a physical standpoint, the corresponding energy landscape is simpler than that for grid graphs and allows for explicit calculations for the hitting times between any pair of configurations. In particular, we show that whenever our two conditions are not satisfied, \(\Gamma _-(x,A) \ne \Gamma _+(x,A)\) and the scaled hitting time is not necessarily exponentially distributed.
2 Overview and Main Results
In this section we introduce the general framework of Metropolis Markov chains and show how the dynamical hard-core model fits in it. We then present our two main results for the hitting time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) for the hard-core model on grid graphs and outline our proof method.
2.1 Metropolis Markov Chains
Let \(\mathcal {X}\) be a finite state space and let \(H: \mathcal {X}\rightarrow \mathbb R\) be the Hamiltonian, i.e., a non-constant energy function. We consider the family of Markov chains \(\{X^\beta _t \}_{t \in \mathbb N}\) on \(\mathcal {X}\) with Metropolis transition probabilities \(P_\beta \) indexed by a positive parameter \(\beta \)
where \(q: \mathcal {X}\times \mathcal {X}\rightarrow [0,1]\) is a matrix that does not depend on \(\beta \). The matrix q is the connectivity function and we assume it to be
-
Stochastic, i.e., \(\sum _{y \in \mathcal {X}} q(x,y) = 1\) for every \(x \in \mathcal {X}\);
-
Symmetric, i.e., \(q(x,y)=q(y,x)\) for every \(x,y \in \mathcal {X}\);
-
Irreducible, i.e., for any \(x,y \in \mathcal {X}\), \(x \ne y\), there exists a finite sequence \(\omega \) of states \(\omega _1,\ldots ,\omega _n \in \mathcal {X}\) such that \(\omega _1=x\), \(\omega _n=y\) and \(q(\omega _i,\omega _{i+1})>0\), for \(i=1,\ldots , n-1\). We will refer to such a sequence as a path from x to y and we will denote it by \(\omega : x \rightarrow y\).
We call the triplet \((\mathcal {X}, H, q)\) an energy landscape. The Markov chain \({\{X^\beta _t \}_{t \in \mathbb N}}\) is reversible with respect to the Gibbs measure
Furthermore, it is well-known (see e.g. [11, Proposition 1.1]) that the Markov chain \({\{X^\beta _t \}_{t \in \mathbb N}}\) is aperiodic and irreducible on \(\mathcal {X}\). Hence, \(\{X^\beta _t \}_{t \in \mathbb N}\) is ergodic on \(\mathcal {X}\) with stationary distribution \(\mu _\beta \).
For a nonempty subset \(A \subset \mathcal {X}\) and a state \(x \in \mathcal {X}\), we denote by \(\tau ^x_{A}\) the first hitting time of the subset A for the Markov chain \({\{X^\beta _t \}_{t \in \mathbb N}}\) with initial state x at time \(t=0\), i.e.,
Denote by \(\mathcal {X}^s\) the set of stable states of the energy landscape \((\mathcal {X},H,q)\), that is the set of global minima of H on \(\mathcal {X}\), and by \(\mathcal {X}^m\) the set of metastable states, which are the local minima of H in \(\mathcal {X}\setminus \mathcal {X}^s\) with maximum stability level (see Sect. 3 for definition). The first hitting time \(\tau ^x_{A}\) is often called tunneling time when x is a stable state and the target set is some \(A \subseteq \mathcal {X}^s\setminus \{x\}\), or transition time from metastable to stable when \(x \in \mathcal {X}^m\) and \(A = \mathcal {X}^s\).
2.2 The Hard-Core Model
The hard-core model on a finite undirected graph \(\Lambda \) of N vertices evolving according to the dynamics described in Sect. 1 can be put in the framework of Metropolis Markov chains. Indeed, we associate a variable \(\sigma (v)\in \{0,1\}\) with each site \(v \in \Lambda \), indicating the absence (0) or the presence (1) of a particle in that site. Then the hard-core dynamics correspond to the Metropolis Markov chain determined by the energy landscape \((\mathcal {X},H,q)\) where
-
The state space \({\mathcal {X}\subset \{0,1\}^{\Lambda }}\) is the set of admissible configurations on \(\Lambda \), i.e., the configurations \(\sigma \in \{0,1\}^\Lambda \) such that \(\sigma (v)\sigma (w)=0\) for every pair of neighboring sites v, w in \(\Lambda \);
-
The energy of a configuration \(\sigma \in \mathcal {X}\) is proportional to the total number of particles,
$$\begin{aligned} H(\sigma ) := - \sum _{v \in \Lambda } \sigma (v); \end{aligned}$$(4) -
The connectivity function q allows only for single-site updates (possibly void): For any \(\sigma ,\sigma ' \in \mathcal {X}\),
$$\begin{aligned} q(\sigma ,\sigma '):= {\left\{ \begin{array}{ll} \frac{1}{N}, &{}\quad \text {if } |\{v \in \Lambda ~\mathbin {|}~\sigma (v) \ne \sigma '(v)\}|=1,\\ 0, &{}\quad \text {if } |\{v \in \Lambda ~\mathbin {|}~\sigma (v) \ne \sigma '(v)\}| > 1, \\ 1 - \sum _{\eta \ne \sigma } q(\sigma ,\eta ), &{}\quad \text {if } \sigma =\sigma '. \end{array}\right. } \end{aligned}$$
For \(\lambda =e^\beta \) the hard-core measure (1) on \(\Lambda \) is precisely the Gibbs measure (3) associated with the energy landscape \((\mathcal {X},H,q)\).
Our main focus in the present paper concerns the dynamics of the hard-core model on finite two-dimensional rectangular lattices, to which we will simply refer to as grid graphs. More precisely, given two integers \(K,L \ge 2\), we will take \(\Lambda \) to be a \(K \times L\) grid graph with three possible boundary conditions: Toroidal (periodic), cylindrical (semiperiodic) and open. We denote them by \(T_{K,L}\), \(C_{K,L}\) and \(G_{K,L}\), respectively. Figure 1 shows an example of the three possible types of boundary conditions.

Examples of grid graphs with different boundary conditions. a Open grid graph \({G_{9,7}}\), b cylindrical grid graph \({C_{8,6}}\), c toric grid graph \({T_{6,12}}\)
Each of the grid graphs described above has vertex set \(\{0,\ldots ,L-1\} \times \{0,\ldots ,K-1\}\) and thus \(\Lambda \) has \(N = KL\) sites in total. Every site \(v \in \Lambda \) is described by its coordinates \((v_1, v_2)\), and since \(\Lambda \) is finite, we assume without loss of generality that the leftmost (respectively bottommost) site of \(\Lambda \) has the horizontal (respectively vertical) coordinate equal to zero. A site is called even (odd) if the sum of its two coordinates is even (odd, respectively) and we denote by \(V_e\) and \(V_o\) the collection of even sites and that of odd sites of \(\Lambda \), respectively.
The open grid graph \(G_{K,L}\) is naturally a bipartite graph: All the first neighbors of an even site are odd sites and vice versa. In contrast, the cylindrical and toric grid graphs may not be bipartite, so that we further assume that K is an even integer for the cylindrical grid graph \(C_{K,L}\) and that both K and L are even integers for the toric grid graph \(T_{K,L}\). Since the bipartite structure is crucial for our methodology, we will tacitly work under these assumptions for the cylindrical and toric grid graphs in the rest of the paper. As a consequence, \(T_{K,L}\) and \(C_{K,L}\) are balanced bipartite graphs, i.e., \(|V_e| =|V_o|\). The open grid graph \(G_{K,L}\) has \(|V_e| = \lceil KL/2 \rceil \) even sites and \(|V_o| = \lfloor KL/2 \rfloor \) odd sites, hence it is a balanced bipartite graph if and only if the product K L is even. We denote by \({\mathbf {e}}\) (\({\mathbf {o}}\) respectively) the configuration with a particle at each site in \(V_e\) (\(V_o\) respectively). More precisely,
Note that \({\mathbf {e}}\) and \({\mathbf {o}}\) are admissible configurations for any of our three choices of boundary conditions, and that, in view of (4), \(H({\mathbf {e}})=-|V_e|=-\lceil KL/2 \rceil \) and \(H({\mathbf {o}})=-|V_o|=-\lfloor KL/2 \rfloor \). In the special case where \(\Lambda =G_{K,L}\) with \(KL \equiv 1 \pmod 2\), \(H({\mathbf {e}}) < H({\mathbf {o}})\) and, as we will show in Sect. 5, \(\mathcal {X}^s= \{ {\mathbf {e}}\}\) and \(\mathcal {X}^m=\{ {\mathbf {o}}\}\). In all the other cases, we have \(H({\mathbf {e}}) = H({\mathbf {o}})\) and \(\mathcal {X}^s= \{ {\mathbf {e}}, {\mathbf {o}}\}\); see Sect. 5 for details.
2.3 Main Results and Proof Outline
Our first main result describes the asymptotic behavior of the tunneling time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) for any grid graph \(\Lambda \) in the low-temperature regime \(\beta \rightarrow \infty \). In particular, we prove the existence and find the value of an exponent \(\Gamma (\Lambda )>0\) that gives an asymptotic control in probability of \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) on a logarithmic scale as \(\beta \rightarrow \infty \) and characterizes the asymptotic order-of-magnitude of the mean tunneling time \(\mathbb E\tau ^{\mathbf {e}}_{\mathbf {o}}\). We further show that the tunneling time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) normalized by its mean converges in distribution to an exponential unit-mean random variable.
Theorem 2.1
(Asymptotic behavior of the tunneling time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\)) Consider the Metropolis Markov chain \(\{X^\beta _t \}_{t \in \mathbb N}\) corresponding to hard-core dynamics on a \(K \times L\) grid graph \(\Lambda \) as described in Sect. 2.2. There exists a constant \(\Gamma (\Lambda ) >0\) such that
-
(i)
For every \(\varepsilon >0\), \(\displaystyle \lim _{\beta \rightarrow \infty }\mathbb P_{\beta } \Big ( e^{\beta (\Gamma (\Lambda )-\varepsilon )} < \tau ^{\mathbf {e}}_{\mathbf {o}}< e^{\beta (\Gamma (\Lambda )+\varepsilon )} \Big ) =1\);
-
(ii)
\(\displaystyle \lim _{\beta \rightarrow \infty }\frac{1}{\beta } \log \mathbb E\tau ^{\mathbf {e}}_{\mathbf {o}}= \Gamma (\Lambda )\);
-
(iii)
\(\displaystyle \frac{\tau ^{\mathbf {e}}_{\mathbf {o}}}{\mathbb E\tau ^{\mathbf {e}}_{\mathbf {o}}} \xrightarrow {d}\mathrm {Exp}(1), \quad \beta \rightarrow \infty .\)
In the special case where \(\Lambda =G_{K,L}\) with \(K L \equiv 1 \pmod 2\), (i), (ii), and (iii) hold also for the first hitting time \(\tau ^{\mathbf {o}}_{\mathbf {e}}\), but replacing \(\Gamma (\Lambda )\) by \(\Gamma (\Lambda )-1\).
Theorem 2.1 relies on the analysis of the hard-core energy landscape for grid graphs and novel results for hitting times in the general Metropolis Markov chains context. We first explain these new model-independent results and, afterwards, we give details about the properties we proved for the energy landscape of the hard-core model.
The framework [31] focuses on the most classical metastability problem, which is the characterization of the transition time \({\tau ^{\eta }_{\mathcal {X}^s}}\) between a metastable state \(\eta \in \mathcal {X}^m\) and the set of stable states \(\mathcal {X}^s\). However, the starting configuration for the hitting times we are interested in, is not always a metastable state and the target set is not always \(\mathcal {X}^s\). In fact, the classical results can be applied for the hard-core model on grids for the hitting time \(\tau ^{\mathbf {o}}_{\mathbf {e}}\) only in the case of an \(K \times L\) grid graph with open boundary conditions and odd side lengths, i.e., \(KL \equiv 1 \pmod 2\). Many other interesting hitting times are not covered by the literature. We therefore generalize the classical pathwise approach [31] to study the first hitting time \(\tau ^x_{A}\) for a Metropolis Markov chain for any pair of starting state x and target subset A. The interest of extending these results to the tunneling time between two stable states was already mentioned in [31, 37], but our framework is even more general and we could study \(\tau ^x_{A}\) for any pair (x, A), e.g. the transition between a stable state and a metastable one.
Our analysis relies on the classical notion of a cycle, which is a maximal connected subset of states lying below a given energy level. The exit time from a cycle in the low-temperature regime is well-known in the literature [11, 12, 16, 35, 37] and is characterized by the depth of the cycle, which is the minimum energy barrier that separates the bottom of the cycle from its external boundary. The usual strategy presented in the literature to study the first hitting time from \(x \in \mathcal {X}^m\) to \(A = \mathcal {X}^s\) is to look at the decomposition into maximal cycles of the relevant part of the energy landscape, i.e., \(\mathcal {X}\setminus \mathcal {X}^s\). The first model-dependent property one has to prove is that the starting state x is metastable, which guarantees that there are no cycles in \(\mathcal {X}\setminus \mathcal {X}^s\) deeper than the maximal cycle containing the starting state x, denoted by \(C_{A}(x)\). In this scenario, the time spent in maximal cycles different from \(C_{A}(x)\), and hence the time it takes to reach \(\mathcal {X}^s\) from the boundary of \(C_{A}(x)\), is comparable to or negligible with respect to the exit time from \(C_{A}(x)\), making the exit time from \(C_{A}(x)\) and the first hitting time \(\tau ^x_{A}\) of the same order.
In contrast, for a general starting state x and target subset A all maximal cycles of \(\mathcal {X}\setminus A\) can potentially have a non-negligible impact on the transition from x to A in the low-temperature regime. By analyzing these maximal cycles and the possible cycle-paths, we can establish bounds in probability for the hitting time \(\tau ^x_{A}\) on a logarithmic scale, i.e., obtain a pair of exponents \(\Gamma _-(x,A),\Gamma _+(x,A)\) such that for every \(\varepsilon >0\)
The sharpness of the exponents \(\Gamma _-(x,A)\) and \(\Gamma _+(x,A)\) crucially depends on how precisely one can determine which maximal cycles are likely to be visited and which ones are not, see Sect. 3 for further details. Furthermore, we give a sufficient condition (see Assumption A in Sect. 3), which is the absence of deep typical cycles, which guarantees that \(\Gamma _-(x,A)=\Gamma =\Gamma _+(x,A)\), proving that the random variable \(\beta ^{-1} \log \tau ^x_{A}\) converges in probability to \(\Gamma \) as \(\beta \rightarrow \infty \), and that \(\lim _{\beta \rightarrow \infty }\beta ^{-1} \log \mathbb E\tau ^x_{A}= \Gamma \). In many cases of interest, one could show that Assumption A holds for the pair (x, A) without detailed knowledge of the typical paths from x to A. Indeed, by proving that the model exhibits absence of deep cycles (see Proposition 3.18), similarly to [31], also in our framework the study of the hitting time \(\tau ^x_{A}\) is decoupled from an exact control of the typical paths from x to A. More precisely, one can obtain asymptotic results for the hitting time \(\tau ^x_{A}\) in probability, in expectation and in distribution without the detailed knowledge of the critical configuration or of the tube of typical paths. Proving the absence of deep cycles when \(x \in \mathcal {X}^m\) and \(A = \mathcal {X}^s\) corresponds precisely to identifying the set of metastable states \(\mathcal {X}^m\), while, when \(x \in \mathcal {X}^s\) and \(A = \mathcal {X}^s\setminus \{x\}\), it is enough to show that the energy barrier that separates any state from a state with lower energy is not bigger than the energy barrier separating any two stable states.
Moreover, we give another sufficient condition (see Assumption B in Sect. 3), called “worst initial state” assumption, to show that the hitting time \(\tau ^x_{A}\) normalized by its mean converges in distribution to an exponential unit-mean random variable. However, checking Assumption B for a specific model can be very involved, and hence we provide a stronger condition (see Proposition 3.20), which includes the case of the tunneling time between stable states and the classical transition time from a metastable to a stable state. The hard-core model on complete K-partite graphs is used as an example to illustrate scenarios where Assumption A or B is violated, \(\Gamma _-(x,A) \ne \Gamma _+(x,A)\) and the asymptotic result for \(\mathbb E\tau ^x_{A}\) of the first moment and the asymptotic exponentiality of \(\tau ^x_{A}/ \mathbb E\tau ^x_{A}\) do not hold.
In the case of the hard-core model on a grid graph \(\Lambda \), we develop a powerful combinatorial approach which shows the absence of deep cycles (Assumption A) for this model, concluding the proof of Theorem 2.1. Furthermore, it yields the value of the energy barrier \(\Gamma (\Lambda )\) between \({\mathbf {e}}\) and \({\mathbf {o}}\), which turns out to depend both on the grid size and on the chosen boundary conditions. This is established by the next theorem, which is our second main result.
Theorem 2.2
(The exponent \(\Gamma (\Lambda )\) for grid graphs) Let \(\Lambda \) be a \(K\times L\) grid graph. Then the energy barrier \(\Gamma (\Lambda )\) between \({\mathbf {e}}\) and \({\mathbf {o}}\) appearing in Theorem 2.1 takes the values
The additional condition \(K+L>4\) leaves out the \(2\times 2\) toric grid graph \(T_{2,2}\) since it requires special consideration. However, Theorem 2.1 holds also in this case, since effectively \(T_{2,2}=G_{2,2}\).
The proof of Theorem 2.2 is given in Sect. 5. The crucial idea behind the proof of Theorem 2.2 is that along the transition from \({\mathbf {e}}\) to \({\mathbf {o}}\), there must be a critical configuration where for the first time an entire row or an entire column coincides with the target configuration \({\mathbf {o}}\). In such a critical configuration particles reside both in even and odd sites and, due to the hard-core constraints, an interface of empty sites should separate particles with different parities. By quantifying the “inefficiency” of this critical configuration we get the minimum energy barrier that has to be overcome for the transition from \({\mathbf {e}}\) to \({\mathbf {o}}\) to occur. The proof is then concluded by exhibiting a path that achieves this minimum energy and by exploiting the absence of deep cycles in the energy landscape. By proving that the energy landscape corresponding to the hard-core model on grid graphs exhibits the absence of deep cycles, the study of the hitting time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) is decoupled from an exact control of the typical paths from \({\mathbf {e}}\) to \({\mathbf {o}}\). For this reason, the study of critical configurations and of the minimal gates along the transition from \({\mathbf {e}}\) to \({\mathbf {o}}\) is beyond the scope of this paper and will be the focus of future work.
Lastly, we show that by understanding the global structure of an energy landscape \((\mathcal {X}, H, q)\) and the maximum depths of its cycles, we can also derive results for the mixing time of the corresponding Metropolis Markov chains \({\{X^\beta _t \}_{t \in \mathbb N}}\), as illustrated in Sect. 3.8. In particular, our results show that in the special case of an energy landscape with multiple stable states and without other deep cycles, the hitting time between any two stable states and the mixing time of the chain are of the same order-of-magnitude in the low-temperature regime. This is the case also for the Metropolis hard-core dynamics on grids, see Theorem 5.4 in Sect. 5.
The rest of the paper is structured as follows. Section 3 is devoted to the model-independent results valid for a general Metropolis Markov chain, which extend the classical framework [31]. The proofs of these results are rather technical and therefore deferred to Sect. 4. In Sect. 5 we develop our combinatorial approach to analyze the energy landscapes corresponding to the hard-core model on grids. We finally present in Sect. 6 our conclusions and indicate future research directions.
3 Asymptotic Behavior of Hitting Times for Metropolis Markov Chains
In this section we present model-independent results valid for any Markov chains with Metropolis transition probabilities (2) defined in Sect. 2.1. In Sect. 3.1 we introduce the classical notion of a cycle. If the considered model allows only for a very rough energy landscape analysis, well-known results for cycles are shown to readily yield upper and lower bounds in probability for the hitting time \(\tau ^x_{A}\). Indeed, one can use the depth of the initial cycle \(C_{A}(x)\) as \(\Gamma _-(x,A)\) (see Propositions 3.4) and the maximum depth of a cycle in the partition of \(\mathcal {X}\setminus A\) as \(\Gamma _+(x,A)\) (see Proposition 3.7). If one has a good handle on the model-specific optimal paths from x to A, i.e., those paths along which the maximum energy is precisely the min-max energy barrier between x and A, sharper exponents can be obtained, as illustrated in Proposition 3.10, by focusing on the relevant cycle, where the process \({\{X^\beta _t \}_{t \in \mathbb N}}\) started in x spends most of its time before hitting the subset A. We sharpen these bounds in probability for the hitting time \(\tau ^x_{A}\) even further with Proposition 3.15 by studying the tube of typical paths from x to A or standard cascade, a task that in general requires a very detailed but local analysis of the energy landscape. To complete the study of the hitting time in the regime \(\beta \rightarrow \infty \), we prove in Sect. 3.5 the convergence of the first moment of the hitting time \(\tau ^x_{A}\) on a logarithmic scale under suitable assumptions (see Theorem 3.17) and give in Sect. 3.6 sufficient conditions for the scaled hitting time \(\tau ^x_{A}/ \mathbb E\tau ^x_{A}\) to converge in distribution as \(\beta \rightarrow \infty \) to an exponential unit-mean random variable, see Theorem 3.19. Furthermore, we illustrate in detail two special cases which fall within our framework, namely the classical transition from a metastable state to a stable state and the tunneling between two stable states, which is the relevant one for the model considered in this paper. In Sect. 3.7 we briefly present the hard-core model on a complete K-partite graph, which is an example of a model where the asymptotic exponentiality of the scaled hitting times does not always hold. Lastly, in Sect. 3.8 we present some results for the mixing time and the spectral gap of Metropolis Markov chains and show how they are linked with the critical depths of the energy landscape.
In the rest of this section and in Sect. 4, \(\{X_t\}_{t \in \mathbb N}\) will denote a general Metropolis Markov chain with energy landscape \((\mathcal {X}, H, q)\) and inverse temperature \(\beta \), as defined in Sect. 2.1.
3.1 Cycles: Definitions and Classical Results
We recall here the definition of a cycle and present some well-known properties.
A path \(\omega : x \rightarrow y\) has been defined in Sect. 2.1 as a finite sequence of states \(\omega _1,\ldots ,\omega _n \in \mathcal {X}\) such that \(\omega _1=x\), \(\omega _n=y\) and \(q(\omega _i,\omega _{i+1})>0\), for \(i=1,\ldots , n-1\). Given a path \(\omega =(\omega _1,\ldots ,\omega _n)\) in \(\mathcal {X}\), we denote by \(|\omega |:=n\) its length and define its height or elevation by
A subset \(A \subset \mathcal {X}\) with at least two elements is connected if for all \(x,y \in A\) there exists a path \(\omega : x \rightarrow y\), such that \(\omega _i \in A\) for every \(i=1,\ldots ,|\omega |\). Given a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\), we define \(\Omega _{x,A}\) as the collection of all paths \(\omega : x \rightarrow y\) for some \(y \in A\) that do not visit A before hitting y, i.e.,
We remark that only the endpoint of each path in \(\Omega _{x,A}\) belongs to A. The communication energy between a pair \(x,y\in \mathcal {X}\) is the minimum value that has to be reached by the energy in every path \(\omega : x \rightarrow y\), i.e.,
Given two nonempty disjoint subsets \(A,B \subset \mathcal {X}\), we define the communication energy between A and B by
Given a nonempty set \(A \subset \mathcal {X}\), we define its external boundary by
For a nonempty set \(A \subset \mathcal {X}\) we define its bottom \(\mathcal {F}(A)\) as the set of all minima of the energy function \(H(\cdot )\) on A, i.e.,
Let \(\mathcal {X}^s:=\mathcal {F}(\mathcal {X})\) be the set of stable states, i.e., the set of states with minimum energy. Since \(\mathcal {X}\) is finite, the set \(\mathcal {X}^s\) is always nonempty. Define the stability level \(\mathcal V_x\) of a state \(x \in \mathcal {X}\) by
where \(\mathcal {I}_{x}:=\{z \in \mathcal {X}~\mathbin {|}~H(z)<H(x) \}\) is the set of states with energy lower than x. We set \(\mathcal V_x:=\infty \) if \(\mathcal {I}_x\) is empty, i.e., when x is a stable state. The set of metastable states \(\mathcal {X}^m\) is defined as
We call a nonempty subset \(C \subset \mathcal {X}\) a cycle if it is either a singleton or a connected set such that
A cycle C for which condition (11) holds is called non-trivial cycle. If C is a non-trivial cycle, we define its depth as
Any singleton \(C=\{x\}\) for which condition (11) does not hold is called trivial cycle. We set the depth of a trivial cycle C to be equal to zero, i.e., \(\Gamma (C)=0\). Given a cycle C, we will refer to the set \(\mathcal {F}(\partial C)\) of minima on its boundary as its principal boundary. Note that
In this way, we have the following alternative expression for the depth of a cycle C, which has the advantage of being valid also for trivial cycles:
The next lemma gives an equivalent characterization of a cycle.
Lemma 3.1
A nonempty subset \(C \subset \mathcal {X}\) is a cycle if and only if it is either a singleton or a connected subset that satisfies
The proof easily follows from definitions (7), (8) and (11) and the fact that if C is not a singleton and is connected, then
We remark that the equivalent characterization of a cycle given in Lemma 3.1 is the “correct definition” of a cycle in the case where the transition probabilities are not necessarily Metropolis but satisfy the more general Friedlin-Wentzell condition
where \(\Delta (x,y)\) is an appropriate rate function \(\Delta : \mathcal {X}^2 \rightarrow \mathbb R^+ \cup \{\infty \}\). The Metropolis transition probabilities correspond to the case (see [17] for more details) where
The next theorem collects well-known results for the asymptotic behavior of the exit time from a cycle as \(\beta \) becomes large, where the depth \(\Gamma (C)\) of the cycle plays a crucial role.
Theorem 3.2
(Properties of the exit time from a cycle) Consider a non-trivial cycle \(C \subset \mathcal {X}\).
-
(i)
For any \(x \in C\) and for any \(\varepsilon >0\), there exists \(k_1>0\) such that for all \(\beta \) sufficiently large
$$\begin{aligned} {\mathbb P_{\beta }} \left( {\tau ^{x}_{\partial C} < e^{\beta (\Gamma (C) - \eta )} }\right) \le e^{-k_1 \beta }. \end{aligned}$$ -
(ii)
For any \(x \in C\) and for any \(\varepsilon >0\), there exists \(k_2>0\) such that for all \(\beta \) sufficiently large
$$\begin{aligned} \mathbb P_{\beta } \Big ( \tau ^{x}_{\partial C} > e^{\beta (\Gamma (C) + \varepsilon )} \Big )\le e^{-e^{k_2 \beta }}. \end{aligned}$$ -
(iii)
For any \(x,y \in C\), there exists \(k_3>0\) such that for all \(\beta \) sufficiently large
$$\begin{aligned} \mathbb P_{\beta } \Big ( \tau ^{x}_{y} > \tau ^{x}_{\partial C} \Big )\le e^{-k_3 \beta }. \end{aligned}$$ -
(iv)
There exists \(k_4>0\) such that for all \(\beta \) sufficiently large
$$\begin{aligned} \sup _{x \in C} \mathbb P_{\beta } \Big ( X_{\tau ^{x}_{\partial C}} \not \in \mathcal {F}(\partial C) \Big ) \le e^{- k_4 \beta }. \end{aligned}$$ -
(v)
For any \(x \in C\), \(\varepsilon >0\) and \(\varepsilon '>0\), for all \(\beta \) sufficiently large
$$\begin{aligned} \mathbb P_{\beta } \Big ( \tau ^{x}_{\partial C} < e^{\beta (\Gamma (C) + \varepsilon )}, \, X_{\tau ^{x}_{\partial C}} \in \mathcal {F}(\partial C) \Big ) \ge e^{- \varepsilon ' \beta }. \end{aligned}$$ -
(vi)
For any \(x \in C\), any \(\varepsilon >0\) and all \(\beta \) sufficiently large
$$\begin{aligned} e^{\beta (\Gamma (C) - \varepsilon )} < \mathbb E\tau ^{x}_{\partial C} < e^{\beta (\Gamma (C) + \varepsilon )}. \end{aligned}$$
The first three properties can be found in [37, Theorem 6.23], the fourth one is [37, Corollary 6.25] and the fifth one in [31, Theorem 2.17]. The sixth property is given in [35, Proposition 3.9] and implies that
The third property states that, given that C is a cycle, for any starting state \(x \in C\), the Markov chain \(\{X_t\}_{t \in \mathbb N}\) visits any state \(y \in C\) before exiting from C with a probability exponentially close to one. This is a crucial property of the cycles and in fact can be given as alternative definition, see for instance [11, 12]. The equivalence of the two definitions has been proved in [17] in greater generality for a Markov chain satisfying the Friedlin-Wentzell condition (15). Leveraging this fact, many properties and results from [11] will be used or cited.
We denote by \(\mathcal {C}(\mathcal {X})\) the set of cycles of \(\mathcal {X}\). The next lemma, see [37, Proposition 6.8], implies that the set \(\mathcal {C}(\mathcal {X})\) has a tree structure with respect to the inclusion relation, where \(\mathcal {X}\) is the root and the singletons are the leaves.
Lemma 3.3
(Cycle tree structure) Two cycles \(C, C' \in \mathcal {C}(\mathcal {X})\) are either disjoint or comparable for the inclusion relation, i.e., \(C \subseteq C'\) or \(C' \subseteq C\).
Lemma 3.3 also implies that the set of cycles to which a state \(x \in \mathcal {X}\) belongs is totally ordered by inclusion. Furthermore, we remark that if two cycles \(C,C' \in \mathcal {C}(\mathcal {X})\) are such that \(C \subseteq C'\), then \(\Gamma (C) \le \Gamma (C')\); this latter inequality is strict if and only if the inclusion is strict.
3.2 Classical Bounds in Probability for Hitting Time \(\tau ^x_{A}\)
In this subsection we start investigating the first hitting time \(\tau ^x_{A}\). Thus, we will tacitly assume that the target set A is a nonempty subset of \(\mathcal {X}\) and the initial state x belongs to \(\mathcal {X}\setminus A\). Moreover, without loss of generality, we will henceforth assume that
which means that we add to the original target subset A all the states in \(\mathcal {X}\) that cannot be reached from x without visiting the subset A. Note that this assumption does not change the distribution of the first hitting time \(\tau ^x_{A}\), since the states which we may have added in this way could not have been visited without hitting the original subset A first.
Given a nonempty subset \(A \subset \mathcal {X}\) and \(x \in \mathcal {X}\), we define the initial cycle \(C_{A}(x)\) by
If \(x \in A\), then \(C_{A}(x)= \{x\}\) and thus is a trivial cycle. If \(x \not \in A\), the subset \(C_{A}(x)\) is either a trivial cycle (when \(\Phi (x,A) = H(x)\)) or a non-trivial cycle containing x, if \(\Phi (x,A) > H(x)\). In any case, if \(x \not \in A\), then \(C_{A}(x)\cap A = \varnothing \). For every \(x\in \mathcal {X}\), we denote by \(\Gamma (x,A)\) the depth of the initial cycle \(C_{A}(x)\), i.e.,
Clearly if \(C_{A}(x)\) is trivial (and in particular when \(x \in A\)), then \(\Gamma (x,A)= 0\). Note that by definition the quantity \(\Gamma (x,A)\) is always non-negative, and in general
with equality if and only if \(x \in \mathcal {F}(C_{A}(x))\).
If \(x \not \in A\), then the initial cycle \(C_{A}(x)\) is, by construction, the maximal cycle (in the sense of inclusion) that contains the state x and has an empty intersection with A. Therefore, any path \(\omega : x \rightarrow A\) has at some point to exit from \(C_{A}(x)\), by overcoming an energy barrier not smaller than its depth \(\Gamma (x,A)\). The next proposition gives a probabilistic bound for the hitting time \( \tau ^x_{A}\) by looking precisely at this initial ascent up until the boundary of \(C_{A}(x)\).
Proposition 3.4
(Initial-ascent bound) Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\). For any \(\varepsilon >0\) there exists \(\kappa >0\) such that for \(\beta \) sufficiently large
The proof is essentially adopted from [37] and follows easily from Theorem 3.2(i), since by definition of \(C_{A}(x)\), we have that \(\tau ^x_{A}\ge _\text {st} \tau ^x_{\partial C_{A}(x)}\).
Before stating an upper bound for the tail probability of the hitting time \(\tau ^x_{A}\), we need some further definitions. Given a nonempty subset \(B \subset \mathcal {X}\), we denote by \(\mathcal {M}(B)\) the collection of maximal cycles that partitions B, i.e.,
Since every singleton is a cycle and Lemma 3.3 implies that every nonempty subset \(B \subset \mathcal {X}\) has a partition into maximal cycles, the collection \(\mathcal {M}(B)\) is well defined. Note that if \(C \in \mathcal {C}(\mathcal {X})\) is itself a cycle, then \(\mathcal {M}(C)=\{C\}\).
The following lemma shows that initial cycles can be used to obtain the partition in maximal cycles of any subset of the state space.
Lemma 3.5
[31, Lemma 2.26] Given a nonempty subset \(A \subset \mathcal {X}\), the collection \(\{C_{A}(x)\}_{x \in \mathcal {X}\setminus A}\) of initial cycles is the partition into maximal cycles of \(\mathcal {X}\setminus A\), i.e.,
We can extend the notion of depth to subsets \(B \subsetneq \mathcal {X}\) which are not necessarily cycles by using the partition of B into maximal cycles. More precisely, we define the maximum depth \({\widetilde{\Gamma }(B)}\) of a nonempty subset \(B \subsetneq \mathcal {X}\) as the maximum depth of a cycle contained in B, i.e.,
Trivially \(\widetilde{\Gamma }(C) = \Gamma (C)\) if \(C \in \mathcal {C}(\mathcal {X})\). The next lemma gives two equivalent characterizations of the maximum depth \({\widetilde{\Gamma }(B)}\) of a nonempty subset \(B \subsetneq \mathcal {X}\).
Lemma 3.6
(Equivalent characterizations of the maximum depth) Given a nonempty subset \(B \subsetneq \mathcal {X}\),
In view of Lemma 3.6, \(\widetilde{\Gamma }(B)\) is the maximum initial energy barrier that the process started inside B possibly has to overcome to exit from B. As illustrated by the next proposition, one can get a (super-)exponentially small upper bound for the tail probability of the hitting time \(\tau ^x_{A}\), by looking at the maximum depth \({\widetilde{\Gamma }(\mathcal {X}\setminus A)}\) of the complementary set \(\mathcal {X}\setminus A\), where the process resides before hitting the target subset A.
Proposition 3.7
(Deepest-cycle bound) [11, Proposition 4.19] Consider a nonempty subset \(A \subsetneq \mathcal {X}\) and \(x \not \in A\). For any \(\varepsilon >0\) there exists \(\kappa ' >0\) such that for \(\beta \) sufficiently large
By definition we have \(\Gamma (x,A) \le \widetilde{\Gamma }(\mathcal {X}\setminus A)\), but in general \(\Gamma (x,A) \ne \widetilde{\Gamma }(\mathcal {X}\setminus A)\) and neither bound presented in this subsection is actually tight, so we will proceed to establish sharper but more involved bounds in the next subsection.
3.3 Optimal Paths and Refined Bounds in Probability for Hitting Time \(\tau ^x_{A}\)
The quantity \(\Gamma (x,A)\) appearing in Proposition 3.4 only accounts for the energy barrier that has to be overcome starting from x, but there is such an energy barrier for every state \(z \not \in A\) and it may well be that to reach A it is inevitable to visit a state z with \(\Gamma (z,A) > \Gamma (x,A)\). Similarly, also the exponent \({\widetilde{\Gamma }(\mathcal {X}\setminus A)}\) appearing in Proposition 3.7 may not be sharp in general. For instance, the maximum depth \({\widetilde{\Gamma }(\mathcal {X}\setminus A)}\) could be determined by a deep cycle C in \(\mathcal {X}\setminus A\) that cannot be visited before hitting A or that is visited with a vanishing probability as \(\beta \rightarrow \infty \). In this subsection, we refine the bounds given in Propositions 3.4 and 3.7 by using the notion of optimal path and identifying the subset of the state space \(\mathcal {X}\) in which these optimal paths lie.
Given a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\), define the set of optimal paths \({\Omega ^{\mathrm {opt}}_{x,A}}\) as the collection of all paths \(\omega \in \Omega _{x,A}\) along which the maximum energy \(\Phi _\omega \) is equal to the communication height between x and A, i.e.,
Define the relevant cycle \(C^+_{A}(x)\) as the minimal cycle in \(\mathcal {C}(\mathcal {X})\) such that \(C_{A}(x)\subsetneq C^+_{A}(x)\), i.e.,
The cycle \(C^+_{A}(x)\) is well defined, since the cycles in \(\mathcal {C}(\mathcal {X})\) that contain x are totally ordered by inclusion, as remarked after Lemma 3.3. By construction, \(C^+_{A}(x)\cap A \ne \varnothing \) and thus \(C^+_{A}(x)\) contains at least two states, so it has to be a non-trivial cycle. The minimality of \(C^+_{A}(x)\) with respect to the inclusion gives that
and then, by using Lemma 3.1, one obtains
The choice of the name relevant cycle for \(C^+_{A}(x)\) comes from the fact that all paths the Markov chain will follow to go from x to A will almost surely not exit from \(C^+_{A}(x)\) in the limit \(\beta \rightarrow \infty \). Indeed, for the relevant cycle \(C^+_{A}(x)\) Theorem 3.2(iii) reads
The next lemma states that an optimal path from x to A is precisely a path from x to A that does not exit from \(C^+_{A}(x)\).
Lemma 3.8
(Optimal path characterization) Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\). Then
Lemma 3.8 implies that the relevant cycle \(C^+_{A}(x)\) can be equivalently defined as
where \(\delta _0\) is the minimum energy gap between an optimal and a non-optimal path from x to A, i.e.,
In view of Lemma 3.8 and (27), the Markov chain started in x follows in the limit \(\beta \rightarrow \infty \) almost surely an optimal path in \(\Omega ^{\mathrm {opt}}_{x,A}\) to hit A. It is then natural to define the following quantities for a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\):
and
Definition (29) implies that every optimal path \(\omega \in \Omega ^{\mathrm {opt}}_{x,A}\) has to enter at some point a cycle in \(\mathcal {M}(\mathcal {X}\setminus A)\) of depth at least \(\Psi _{\mathrm {min}}(x,A)\), while definition (30) means that every cycle visited by any optimal path \({\omega \in \Omega ^{\mathrm {opt}}_{x,A}}\) has depth less than or equal to \(\Psi _{\mathrm {max}}(x,A)\).
An equivalent characterization for the energy barrier \(\Psi _{\mathrm {max}}(x,A)\) can be given, but we first need one further definition. Define \(R_{A}(x)\) as the subset of states which belong to at least one optimal path in \({\Omega ^{\mathrm {opt}}_{x,A}}\), i.e.,
Note that \(A \cap R_{A}(x)\ne \varnothing \), since the endpoint of each path in \(\Omega _{x,A}\) belongs to A, by definition (6). In view of Lemma 3.8, \(R_{A}(x)\subseteq C^+_{A}(x)\). We remark that this latter inclusion could be strict, since in general \({R_{A}(x)\ne C^+_{A}(x)}\). Indeed, there could exist a state \({y \in C^+_{A}(x)}\) such that all paths \(\omega : x \rightarrow y\) that do not exit from \(C^+_{A}(x)\) always visit the target set A before reaching y, and thus they do not belong to \({\Omega ^{\mathrm {opt}}_{x,A}}\) [see definitions (6) and (24)], see Fig. 2.

Example of an energy landscape \(\mathcal {X}\) with highlighted the subset A (in black), the relevant cycle \(C^+_{A}(x)\) and the subset \(C^+_{A}(x)\setminus (R_{A}(x)\cup A)\) (with diagonal mesh). a The subset \(R_A\)(x) (in light gray), b the partition into maximal cycles of \(R_A\)(x), including the initial cycle \(C_A\)(x) (in dark gray)
The next lemma characterizes the quantity \(\Psi _{\mathrm {max}}(x,A)\) as the maximum depth of the subset \(R_{A}(x)\setminus A\) (see definition 21).
Lemma 3.9
(Equivalent characterization of \(\Psi _{\mathrm {max}}(x,A)\))
Using the two quantities \(\Psi _{\mathrm {min}}(x,A)\) and \(\Psi _{\mathrm {max}}(x,A)\), we can obtain sharper bounds in probability for the hitting time \(\tau ^x_{A}\), as stated in the next proposition.
Proposition 3.10
(Optimal paths depth bounds) Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \in \mathcal {X}\setminus A\). For any \(\varepsilon >0\) there exists \(\kappa >0\) such that for \(\beta \) sufficiently large
and
This proposition is in fact a sharper result than Propositions 3.4 and 3.7, since
Indeed, since the starting state x trivially belongs to every optimal path from x to A, we have that \(\Gamma (x,A) \le \max _{z \in \omega } \Gamma (z,A)\) for every \({\omega \in \Omega ^{\mathrm {opt}}_{x,A}}\) and thus \(\Gamma (x,A) \le \Psi _{\mathrm {min}}(x,A)\). Furthermore, since by definition \(C^+_{A}(x)\setminus A \subseteq \mathcal {X}\setminus A\), Lemma 3.9 yields that \(\Psi _{\mathrm {max}}(x,A)\le \widetilde{\Gamma }(\mathcal {X}\setminus A)\).
If \(\Gamma (x,A) = \widetilde{\Gamma }(\mathcal {X}\setminus A)\), it follows from (35) that \(\Psi _{\mathrm {min}}(x,A)=\Psi _{\mathrm {max}}(x,A)\). However, in general, the exponents \(\Psi _{\mathrm {min}}(x,A)\) and \(\Psi _{\mathrm {max}}(x,A)\) are not equal and may not be sharp either, as illustrated by the energy landscape in Fig. 3.

An example energy landscape for which \(\Psi _{\mathrm {max}}(x,A)\) is not sharp. a Energy profile of the energy landscape with the initial cycle \(C_A\)(x) (in gray) and the relevant cycle \(C^+_A\)(x) (below the dashed black line), b partition intomaximal cycles of \(\mathcal {X} \setminus A\) for the same energy landscape
In this example, there are two paths to go from x to A: The path \(\omega \) which goes from x to y and then follows the solid path until A, and the path \(\omega '\), which goes from x to y and then follows the dashed path through z and eventually hitting A. Note that \(\Phi _{\omega } = \Phi _{\omega '} = \Phi (x,A)\), so both \(\omega \) and \(\omega '\) are optimal paths from x to A. By inspection, we get that \(\Psi _{\mathrm {max}}(x,A)=\Gamma (z,A)\). However, the path \(\omega '\) does not exit the cycle \(C_{A}(y)\) passing by its principal boundary and, in view of Theorem 3.2(iv), it becomes less likely than the other path as \(\beta \rightarrow \infty \). In fact, the transition from x to A is likely to occur on a smaller time-scale than suggested by the upper bounds in Proposition 3.10 and in particular the exponent \(\Psi _{\mathrm {max}}(x,A)\) is not sharp in this example.
In the next subsection, we will show that a more precise control in probability of the hitting time \(\tau ^x_{A}\) is possible, at the expense of a more involved analysis of the energy landscape.
3.4 Sharp Bounds for Hitting Time \(\tau ^x_{A}\) Using Typical Paths
As illustrated at the end of the previous subsection, the exponents \(\Psi _{\mathrm {min}}(x,A)\) and \(\Psi _{\mathrm {max}}(x,A)\) appearing in the probability bounds (33) and (34) for the hitting time \(\tau ^x_{A}\) may not be sharp in general. In this subsection we obtain exponents that are potentially sharper than \(\Psi _{\mathrm {min}}(x,A)\) and \(\Psi _{\mathrm {max}}(x,A)\) by looking in more detail at the cycle decomposition of \(C^+_{A}(x)\setminus A\) and by identifying inside it the tube of typical paths from x to A. In particular, we focus on how the process moves from two maximal cycles in the partition of \(C^+_{A}(x)\setminus A\) and determine which of these transitions between maximal cycles are the most likely ones.
Some further definitions are needed. We introduce the notion of cycle-path and a way of mapping every path \(\omega \in \Omega _{x,A}\) into a cycle-path \(\mathcal {G}(\omega )\). Recall that for a nonempty subset \(A \subset \mathcal {X}\), \(\partial A\) is its external boundary and \(\mathcal {F}(A)\) is its bottom, i.e., the set of the minima of the energy function H in A. A cycle-path is a finite sequence \((C_1,\ldots , C_m)\) of (trivial and non-trivial) cycles \(C_1,\ldots , C_m \in \mathcal {C}(\mathcal {X})\) such that
It can be easily proved that, in a cycle-path \((C_1,\ldots , C_m)\), if \(C_i\) is a non-trivial cycle for some \(i=1,\ldots ,m\), then its predecessor \(C_{i-1}\) and successor \(C_{i+1}\) (if any) are trivial cycles, see [16, Lemma 2.5]. We can consider the collection \(\mathcal {P}_{x,A}\) of cycle-paths that lead from x to A and consist of maximal cycles in \(\mathcal {X}\setminus A\) only, namely
Recall that the the collection of cycles \(\mathcal {M}(C^+_{A}(x)\setminus A)\) can be constructed using initial cycles, as established by Lemma 3.5.
We constructively define a mapping \(\mathcal {G}: \Omega _{x,A}\rightarrow \mathcal {P}_{x,A}\) by assigning to a path \(\omega =(\omega _1,\ldots , \omega _n) \in \Omega _{x,A}\) the cycle-path \(\mathcal {G}(\omega )=(C_1,\ldots ,C_{m(\omega )}) \in \mathcal {P}_{x,A}\) as follows. Set \(t_0 = 1\), \(C_1 = C_{A}(x)\), and then define recursively
The path \(\omega \) is a finite sequence and \(\omega _n \in A\), so there exists an index \(m(\omega ) \in \mathbb N\) such that \({\omega _{t_{m(\omega )}}=\omega _n \in A}\) and there the procedure stops. The way the sequence \({(C_1,\ldots ,C_{m(\omega )})}\) is constructed shows that it is indeed a cycle-path. Moreover, by using the notion of initial cycle \(C_A(\cdot )\) to define \(C_1,\ldots ,C_{m(\omega )}\), they are automatically maximal cycles in \(\mathcal {M}(\mathcal {X}\setminus A)\). Lastly, the fact that \(\omega \in \Omega _{x,A}\) implies that \(x \in C_1\) and that \(\partial C_{m(\omega )} \cap A \ne \varnothing \), hence \(\mathcal {G}(\omega ) \in \mathcal {P}_{x,A}\) and the mapping is well-defined.
We remark that this mapping is not injective, since two different paths in \(\Omega _{x,A}\) can be mapped into the same cycle-path in \(\mathcal {P}_{x,A}\). In fact, a single cycle-path groups together all the paths that visit the same cycles (the same number of times and in the same order). Cycle-paths are the appropriate mesoscopic objects to investigate while studying the transition \(x \rightarrow A\): Indeed one neglects in this way the microscopic dynamics of the process and focuses only on the relevant mesoscopic transitions from one maximal cycle to another.
Furthermore, we note that for a given path \(\omega \in \Omega _{x,A}\), the maximum energy barrier along \(\omega \) is the maximum depth in its corresponding cycle-path \(\mathcal {G}(\omega )\), i.e.,
For every cycle \(C \in \mathcal {C}(\mathcal {X})\) define
to which we will refer as principal boundary of C, also in the case where C is a trivial cycle. In other words, if C is a non-trivial cycle, then its principal boundary is \(\mathcal {F}(\partial C)\), while when \(C=\{y\}\) is a trivial cycle, \(\mathcal {B}(C)\) is the subset of states connected to y with energy lower than y.
We say that a cycle-path \((C_1,\ldots , C_m)\) is connected via typical jumps to A or simply vtj-connected to A if
and denote by \(\mathcal {D}_{C,A}\) the collection of all cycle-paths \((C_1, \ldots , C_m)\) vtj-connected to A such that \(C_1=C\). Note that \(\mathcal {D}_{C,A}\) does not intersect A.
The next lemma, presented in [17], guarantees that there always exists a cycle-path from the initial cycle \(C_A(x)\) that is vtj-connected to A for any nonempty target subset \(A \subset \mathcal {X}\) and \(x \not \in A\).
Lemma 3.11
[17, Proposition 3.22] For any nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\), there exists a cycle-path \(\mathcal {C}^*=(C_1,\ldots ,C_{m^*})\) vtj-connected to A with \(x \in C_1\) and \(C_1, \ldots , C_m^* \subset \mathcal {X}\setminus A\).
By inspecting the proof of [17, Proposition 3.22], one notices that the given cycle-path \(\mathcal {C}^*=(C_1,\ldots ,C_{m^*})\) consists only of maximal cycles in \(\mathcal {X}\setminus A\), i.e., \(C_1,\ldots , C_{m^*} \in \mathcal {M}(\mathcal {X}\setminus A)\), and in particular \(C_1 = C_A(x)\). Hence \(\mathcal {C}^* \in \mathcal {P}_{x,A} \cap \mathcal {D}_{C_{A}(x),A}\) and therefore the collection \(\mathcal {P}_{x,A}\) is not empty.
We define \(\omega \in \Omega _{x,A}\) to be a typical path from x to A if its corresponding cycle-path \(\mathcal {G}(\omega )\) is vtj-connected to A, and we denote by \({\Omega ^{\mathrm {vtj}}_{x,A}}\) the collection of all typical paths from x to A, i.e.,
The existence of a vtj-connected cycle-path \(\mathcal {C}^*=(C_1,\ldots ,C_{m^*}) \in \mathcal {P}_{x,A} \cap \mathcal {D}_{C_{A}(x),A}\) guarantees that
Indeed, take \(y_0=x\), \(y_i \in B(C_i) \cap C_{i+1}\), \(i=1,\ldots , m^*-1\) and \(y_{m^*} \in \mathcal {B}(C_{m^*}) \cap A\) and consider a path \(\omega ^*\) that visits precisely the saddles \(y_0, \ldots , y_{m^*}\) in this order and stays in cycle \(C_i\) between the visit to \(y_{i-1}\) and \(y_i\). Then \(\omega ^*\) is a typical path from x to A.
The following lemma gives an equivalent characterization of a typical path from x to A.
Lemma 3.12
(Equivalent characterization of a typical path) Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\). Then
In particular, Lemma 3.12 shows that every typical path from x to A is an optimal path from x to A, i.e.,
since if \(\omega \in \Omega ^{\mathrm {vtj}}_{x,A}\), then \(\Phi (\omega _i,A) \le \Phi (\omega _1,A)=\Phi (x,A)\) for every \(i=2,\ldots ,|\omega |\) and thus \(\Phi _\omega = \Phi (x,A)\).
Let \(\mathrm {T}_{A}(x)\) be the tube of typical paths from x to A, which is defined as
In other words, \(\mathrm {T}_{A}(x)\) is the subset of states \(y \in \mathcal {X}\) that can be reached from x by means of a typical path which does not enter A before visiting y. The endpoint of every path in \(\Omega ^{\mathrm {vtj}}_{x,A}\) belongs to A, thus \(\mathrm {T}_{A}(x)\cap A \ne \varnothing \). Since by (40) every typical path is an optimal path, it follows from definitions (31) and (41) that
From definition (41), it follows that if \(z \in \mathrm {T}_{A}(x)\), then
Denote by \(\mathfrak {T}_{A}(x)\) the collection of all maximal cycles \(C \in \mathcal {M}(C^+_{A}(x)\setminus A)\) that belong to a cycle-path \(C_1,\ldots ,C_m \subset \mathcal {X}\setminus A\) vtj-connected to A and such that \(C_1=C_{A}(x)\), i.e.,
In other words, \(\mathfrak {T}_{A}(x)\) consists of all cycles maximal by inclusion that belong to at least one vtj-connected cycle path from \(C_{A}(x)\) to A. The cycles in \(\mathfrak {T}_{A}(x)\) form the partition into maximal cycles of \(\mathrm {T}_{A}(x)\setminus A\), i.e.,
and that, by construction, there exists \(C \in \mathfrak {T}_{A}(x)\) such that \(\mathcal {B}(C) \cap A \ne \varnothing \).

Example of an energy landscape with the tube of typical \(\mathrm {T}_{A}(x)\) highlighted in gray
The tube of typical paths \(\mathrm {T}_{A}(x)\) can be visualized as the standard cascade emerging from state x and reaching eventually A, in the sense that it is the part of the energy landscape that would be wet if a water source is placed at x and the water would “find its way” until the sink, that is subset A. This standard cascade consists of basins/lakes (non-trivial cycles), saddle points (trivial cycles) and waterfalls (trivial cycles). By considering the basins, saddle points and waterfalls that are maximal by inclusion, we obtain precisely the collection \(\mathfrak {T}_{A}(x)\) (see the illustration in Fig. 4).
The boundary of \(\mathrm {T}_{A}(x)\) consists of states either in A or in the non-principal part of the boundary of a cycle \(C \in \mathfrak {T}_{A}(x)\):
The typical paths in \(\Omega ^{\mathrm {vtj}}_{x,A}\) are the only ones with non-vanishing probability of being visited by the Markov chain \(\{X_t\}_{t \in \mathbb N}\) started in x before hitting A in the limit \(\beta \rightarrow \infty \), as illustrated by the next lemma.
Lemma 3.13
(Exit from the typical tube \(\mathrm {T}_{A}(x)\)) Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\). Then there exists \(\kappa >0\) such that for \(\beta \) sufficiently large
and
Given a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\), define the following quantities:
and
In other words, definition (45) means that every typical path \(\omega \in \Omega ^{\mathrm {vtj}}_{x,A}\) has to enter at some point a cycle of depth at least \(\Theta _{\mathrm {min}}(x,A)\). On the other hand, definition (30) implies that all cycles visited by any typical path \(\omega \in \Omega ^{\mathrm {vtj}}_{x,A}\) have depth less than or equal to \(\Theta _{\mathrm {max}}(x,A)\). Hence, \(\Theta _{\mathrm {max}}(x,A)\) can equivalently be characterized as the maximum depth (see definition (21)) of the tube \(\mathrm {T}_{A}(x)\) of typical paths from x to A, as stated by the next lemma.
Lemma 3.14
(Equivalent characterization of \(\Theta _{\mathrm {max}}(x,A)\))
Since by (40) every typical path from x to A is an optimal path from x to A, definitions (29), (30), (45) and (46) imply that
We now have all the ingredients needed to formulate the first refined result for the hitting time \(\tau ^x_{A}\). The main idea behind the next proposition is to look at the shallowest-typical gorge inside \(\mathrm {T}_{A}(x)\) that the process has to overcome to reach A and at the deepest-typical gorge inside \(\mathrm {T}_{A}(x)\) where the process has a non-vanishing probability to be trapped before hitting A.
Proposition 3.15
(Typical-cycles bounds) Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\). For any \(\varepsilon >0\) there exists \(\kappa >0\) such that for \(\beta \) sufficiently large
and
The proof, which is a refinement of that of Proposition 3.10, is presented in Sect. 4.
In general, the exponents \(\Theta _{\mathrm {min}}(x,A)\) and \(\Theta _{\mathrm {max}}(x,A)\) may not be equal, as illustrated by the energy landscape in Fig. 5.

An example energy landscape for which \(\Theta _{\mathrm {min}}(x,A)< \Theta _{\mathrm {max}}(x,A)\). a Energy profile of the energy landscape with the initial cycle \(C_A\)(x) (in gray) and the relevant cycle \(C^+_ A\)(x) (below the dashed black line), b partition into maximal cycles of \(\mathcal {X} \setminus A\) for the same energy landscape
Also in this example, there are two paths to go from x to A: The path \(\omega \) which goes from x to y and then follows the solid path until A, and the path \(\omega '\), which goes from x to y and then follows the dashed path through z and eventually hitting A. Both paths \(\omega \) and \(\omega '\) always move from a cycle to the next one visiting the principal boundary, hence they are both typical paths from x to A. By inspection, we get that \(\Theta _{\mathrm {max}}(x,A)=\Gamma (z,A)\), since the typical path \(\omega '\) visits the cycle \(C_A(z)\). Using the path \(\omega \) we deduce that \(\Theta _{\mathrm {min}}(x,A)= \Gamma (y,A)\) and therefore \(\Theta _{\mathrm {min}}(x,A)< \Theta _{\mathrm {max}}(x,A)\).
If the two exponents \(\Theta _{\mathrm {min}}(x,A)\) and \(\Theta _{\mathrm {max}}(x,A)\) coincide, then, in view of Proposition 3.15, we get sharp bounds in probability on a logarithmic scale for the hitting time \(\tau ^x_{A}\), as stated in the next corollary.
Corollary 3.16
Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\). Assume that
Then, for any \(\varepsilon >0\)
There are many examples of models and pairs (x, A) for which \(\Theta _{\mathrm {min}}(x,A)=\Theta _{\mathrm {max}}(x,A)\). The most classical ones are the models that exhibit a metastable behavior: If one takes \(x \in \mathcal {X}^m\) and \(A = \mathcal {X}^s\), then it follows that \(\Theta _{\mathrm {min}}(x,A)= \mathcal V_x = \Theta _{\mathrm {max}}(x,A)\) (recall the definition (9) of stability level) and Corollary 3.16 holds, see also [31, Theorem 4.1].
3.5 First Moment Convergence
We now turn our attention to the asymptotic behavior of the mean hitting time \(\mathbb E\tau ^x_{A}\) as \(\beta \rightarrow \infty \). In particular, we will show that it scales (almost) exponentially in \(\beta \) and we will identify the corresponding exponent. There may be some sub-exponential pre-factors, but, without further assumptions, one can only hope to get results on a logarithmic scale, due to the potential complexity of the energy landscape. We remark that a precise knowledge of the tube of typical paths is not always necessary to derive the asymptotic order of magnitude of the mean hitting time \(\mathbb E\tau ^x_{A}\), as illustrated by Proposition 3.18.
To prove the convergence of the quantity \(\frac{1}{\beta } \log \mathbb E\tau ^x_{A}\), we need the following assumption.
Assumption A (Absence of deep typical cycles) Given the energy landscape (X, H, q), we assume
-
(A1)
\(\displaystyle \Theta _{\mathrm {min}}(x,A)=\Theta (x,A)=\Theta _{\mathrm {max}}(x,A)\), and
-
(A2)
\(\displaystyle \Theta _{\mathrm {max}} (z,A) \le \Theta (x,A)\) for every \(z \in \mathcal {X}\setminus A\).
Condition (A1) says that every path \(\omega : x \rightarrow A\) visits one of the deepest typical cycles of the tube \(\mathrm {T}_{A}(x)\). Condition (A2) guarantees that by starting in another state \(z \ne x\), the deepest typical cycle the process can enter is not deeper than those in \(\mathrm {T}_{A}(x)\). Checking the validity of Assumption A can be very difficult in general, but we give a sufficient condition in Proposition 3.18 which is satisfied in many models of interest, including the hard-core model on rectangular lattices presented in Sect. 2.2, which will be revisited in Sect. 5. We further remark that (A1) is precisely the assumption of Corollary 3.16. Therefore, in the scenarios where Assumption A holds, we also have the asymptotic result (52) in probability for the hitting time \(\tau ^x_{A}\).
The next theorem says that if Assumption A is satisfied, then the asymptotic order-of-magnitude of the mean hitting time \(\mathbb E\tau ^x_{A}\) as \(\beta \rightarrow \infty \) is \(\Theta (x,A)\).
Theorem 3.17
(First moment convergence) If Assumption A is satisfied, then
In many models of interest, calculating \(\widetilde{\Gamma }(\mathcal {X}\setminus A)\) is easier than calculating \(\Theta _{\mathrm {min}}(x,A)\) or \(\Theta _{\mathrm {max}}(x,A)\). Indeed, even if \(\widetilde{\Gamma }(\mathcal {X}\setminus A)\) is a quantity that still requires a global analysis of the energy landscape, one needs to compute just the communication height \(\Phi (z,A)\) between any state \(z \in \mathcal {X}\setminus A\) and the target set A, without requiring a full understanding of the complex cycle structure of the energy landscape. Besides this fact, the main motivation to look at the quantity \(\widetilde{\Gamma }(\mathcal {X}\setminus A)\) is that it allows to give a sufficient condition for Assumption A, as illustrated in the following proposition.
Proposition 3.18
(Absence of deep cycles) If
then Assumption A holds.
Proof
From the inequality
we deduce that \(\Theta _{\mathrm {min}}(x,A)= \Theta _{\mathrm {max}}(x,A)\) and (A1) is proved. Moreover, by definition of \(\widetilde{\Gamma }(\mathcal {X}\setminus A)\), we have \(\Theta _{\mathrm {max}}(z,A) \le \widetilde{\Gamma }(\mathcal {X}\setminus A)\) for every \(z \in \mathcal {X}\setminus A\). This inequality, together with the fact that \(\Theta _{\mathrm {max}}(x,A)= \widetilde{\Gamma }(\mathcal {X}\setminus A)\), proves that (A2) also holds and thus assumption A is satisfied. \(\square \)
We now present two interesting scenarios for which (53) holds.
Example 1
(Metastability scenario)
Suppose that
In this first scenario, \(\tau ^x_{A}\) is the classical transition time between a metastable state and a stable state, a widely studied object in the statistical mechanics literature (see, e.g. [31]). Assumption A is satisfied in this case by applying Proposition 3.18, since condition (53) holds: The equality \(\Phi (x,\mathcal {X}^s) -H(x) = \widetilde{\Gamma }(\mathcal {X}\setminus \mathcal {X}^s)\) follows from the assumption \(x \in \mathcal {X}^m\), which means that there are no cycles in \(\mathcal {X}\setminus \mathcal {X}^s\) that are deeper than \(C_{\mathcal {X}^s}(x)\).
Example 2
(Tunneling scenario)
Suppose that \(x \in \mathcal {X}^s\), \(A = \mathcal {X}^s\setminus \{x\}\) and
In the second scenario, the hitting time \(\tau ^x_{A}\) is the tunneling time between any pair of stable states. Assumption (54) says that every cycle in the energy landscape which does not contain a stable state has depth strictly smaller than the cycle \(C_{A}(x)\) and we generally refer to this property as absence of deep cycles. This condition immediately implies that (53) holds, i.e., \(\widetilde{\Gamma }(\mathcal {X}\setminus A)= \Phi (x,A)-H(x)\), and hence in this scenario assumption A holds, thanks to Proposition 3.18.
The hard-core model on grids introduced in Sect. 2.2 falls precisely in this second scenario and, by proving the validity of Assumption A, we will get both the probability bounds (52) and the first-moment convergence for the tunneling time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\).
3.6 Asymptotic Exponentiality
We now present a sufficient condition for the scaled random variable \(\tau ^x_{A}/ \mathbb E\tau ^x_{A}\) to converge in distribution to an exponential unit-mean random variable as \(\beta \rightarrow \infty \). Define
If Assumption A holds, then we know that \(\Theta (x,A)=\Theta _*(x,A)\), but the result presented in this section does not require the exact knowledge of \(\Theta _*(x,A)\). We prove asymptotic exponentiality of the scaled hitting time under the following assumption.
Assumption B (“Worst initial state”) Given an energy landscape (X, H, q), we assume that
This assumption guarantees that the following “recurrence” result holds: From any state \(z \in \mathcal {X}\) the Markov chain reaches the set \(A \cup \{x\}\) on a time scale strictly smaller than that at which the transition \(x \rightarrow A\) occurs. Indeed, Proposition 3.7 gives that for any \(\varepsilon >0\)
We can informally say that Assumption B requires x to be the “worst initial state” for the Markov chain when the target subset is A.
Proposition 3.20 gives a sufficient condition for Assumption B to hold, which is satisfied in many models of interest, in particular in the hard-core model on grid graphs described in Sect. 2.2.
Theorem 3.19
(Asymptotic exponentiality) If Assumption B is satisfied, then
More precisely, there exist two functions \(k_1(\beta )\) and \(k_2(\beta )\) with \(\lim _{\beta \rightarrow \infty }k_1(\beta )=0\) and \(\lim _{\beta \rightarrow \infty }k_2(\beta )=0\) such that for any \(s>0\)
The proof, presented in Sect. 4, readily follows from the consequences of Assumption B discussed above and by applying [21, Theorem 2.3],
We now present a condition which guarantees that Assumption B holds and show that it holds in two scenarios similar to those described in the previous subsection.
Proposition 3.20
“The initial cycle \(C_{A}(x)\) is the unique deepest cycle” If
then Assumption B is satisfied.
The proof of this proposition is immediate from (35) and (48). We remark that if condition (58) holds, then the initial cycle \(C_{A}(x)\) is the unique deepest cycle in \(\mathcal {X}\setminus A\). Condition (58) is stronger than (56), but often easier to check, since one does not need to compute the exact value of \(\Theta _*(x,A)\), but only the depth \(\Gamma (x,A)\) of the initial cycle \(C_{A}(x)\). We now present two scenarios of interest.
Example 3
(Unique metastable state scenario)
Suppose that
We remark that this scenario is a special case of the metastable scenario presented in Example 1 in Sect. 3.5. This scenario was already mentioned in [31], in the discussion following Theorem 4.15, but we briefly discuss here how to prove asymptotic exponentiality within our framework. Indeed, we have that
thanks to the fact that z is the configuration in \(\mathcal {X}\setminus \mathcal {X}^s\) with the maximum stability level, which means that \(C_{\mathcal {X}^s}(z)\) is the deepest cycle in \(\mathcal {X}\setminus \mathcal {X}^s\). Moreover, the fact that z is the unique metastable state, implies that
since every configuration in \(\mathcal {X}\setminus (\mathcal {X}^s\cup \{z\})\) has stability level strictly smaller than \(\mathcal V_z\).
Example 4
(Two stable states scenario)
Suppose that
This scenario is a special case of the tunneling scenario presented in Example 2 in Sect. 3.5. In this case condition (58) is obviously satisfied. In particular, it shows that the scaled tunneling time \(\tau ^{s_1}_{s_2}\) between two stable states in \(\mathcal {X}\) is asymptotically exponential whenever \(\mathcal {X}^s= \{s_1,s_2\}\) and the condition \(\widetilde{\Gamma }(\mathcal {X}\setminus \{s_1,s_2\}) < \Phi (s_1,s_2) - H(s_1)\) is satisfied.
In Sect. 5 we will show that for the hard-core model on grids Assumption B holds, being precisely in this scenario, and obtain in this way the asymptotic exponentiality of the tunneling time between the two unique stable states.
3.7 An Example of Non-exponentiality
Assumption B is a rather strong assumption. In fact, for many models and for most of choices of x and A, the scaled hitting time \(\tau ^x_{A}/ \mathbb E\tau ^x_{A}\) does not have an exponential distribution in the limit \(\beta \rightarrow \infty \). Moreover, we do not claim that Assumption B is necessary to have asymptotically exponentiality of the scaled hitting time \(\tau ^x_{A}/ \mathbb E\tau ^x_{A}\). However, we will now show that for the hard-core model on complete K-partite graphs Assumption B does not hold and that the model exhibits non-exponentially distributed scaled hitting times.
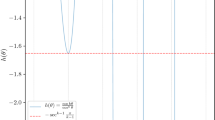
Take \(\Lambda \) to be a complete K-partite graph. This means that the sites in \(\Lambda \) can be partitioned into K disjoint sets \(V_1,\ldots , V_K\) called components, such that two sites are connected by an edge if and only if they belong to different components, see Fig. 6a.

Example of a complete K-partite graph \(\Lambda \) and of the resulting energy landscape for the hard-core model on \(\Lambda \). a K-partite graph \(\Lambda \) with \(K = 5\), b state space \(\mathcal {X}\) corresponding to the graph \(\Lambda \)
This choice for \(\Lambda \) results in a simpler state space \(\mathcal {X}\), for which a detailed analysis is possible. Moreover, for the same model the asymptotic behavior of the first hitting times between maximal-occupancy configurations is already well understood, see [43]. Before stating the results, we need some further definitions. Let \(L_k\) be the size of the Kth component \(V_k\), for \(k=1,\ldots ,K\). Clearly the total number of sites in \(\Lambda \) is \(N=\sum _{k=1}^K L_k\). Define \(L_{\text {max}}:=\max _{k=1,\ldots ,K} L_k\). For \(k=1,\ldots , K\) define the configuration \(\sigma _k \in \mathcal {X}\) as
The configurations \(\{\sigma _1,\ldots ,\sigma _K \}\) are all the local minima of the energy function H on the state space \(\mathcal {X}\). Moreover \(\sigma _k\) is a stable state if and only if \(L_k = L_\text {max}\). In addition, denote by \(\mathbf {0}\) the configuration in \(\mathcal {X}\) where all the sites are empty, i.e., the configuration such that \(\mathbf {0}(v)=0\) for every \(v \in \Lambda \). Given \(k_1,k_2 \in \{1,\ldots , K\}\), \(k_1 \ne k_2\), we take \(\sigma _{k_1}\) and \(\sigma _{k_2}\) as starting and target configurations, respectively. Define \(L_*=L_*(k_2):= \max _{k\ne k_2} L_k\) and let \(K_*=K_*(k_2):=\{ k \ne k_2 ~\mathbin {|}~L_k = L_*\}\) be the set of indices of the components of size \(L_*\) different from \(k_2\).
In [43] the same model has been considered, but in continuous time; the results therein (Theorems IV.1 and IV.2) can be translated to discrete time as follows. Given two functions \(f(\beta )\) and \(g(\beta )\), we write \(f \sim g\) as \(\beta \rightarrow \infty \) when \(\lim _{\beta \rightarrow \infty }f(\beta )/g(\beta ) =1\).
Proposition 3.21
(First moment convergence of the hitting time \({\tau ^{\sigma _{k_1}}_{\sigma _{k_2}}}\)) For any \(k_1,k_2 \in \{1,\ldots ,K\}\) with \(k_1 \ne k_2\), the first hitting time \(\tau ^{\sigma _{k_1}}_{\sigma _{k_2}}\) satisfies
In particular,
Proposition 3.22
(Asymptotic distribution of the hitting time \({\tau ^{\sigma _{k_1}}_{\sigma _{k_2}}}\)) Take \(k_1,k_2 \in \{1,\ldots ,K\}\) such that \(k_1 \ne k_2\). If \(k_1 \in K_*\), then
Instead, if \(k_1 \not \in K_*\), then
where \( Z \,{\buildrel d \over =}\,\sum _{i=1}^M Y_i\) and \((Y_i)_{i \ge 1}\) are i.i.d. exponential unit-mean random variables and M is an independent random variable with geometric distribution \(\mathbb P (M=n) = (1 - p)^n p\) for \(n\in \mathbb N\cup \{0\}\) with success probability \(p= L_{k_2} / (|K_*|L_*+L_{k_2})\).
As illustrated in Fig. 6b, the energy landscape consists of K cycles, one for each component of \(\Lambda \), and one trivial cycle \(\{\mathbf {0}\}\) which links all the others. The depth of each of the cycles is equal to the size of the corresponding component of \(\Lambda \). All the paths from \(\sigma _{k_1}\) to \(\sigma _{k_2}\) must at some point exit from the cycle corresponding to component \(k_1\), at whose bottom lies \(\sigma _{k_1}\). After hitting the configuration \(\mathbf {0}\), they can go directly into the target cycle, i.e., the one at which bottom lies \(\sigma _{k_2}\), or they may fall in one of the other \(K-1\) cycles. Formalizing these simple considerations, we can prove the following proposition.
Proposition 3.23
(Structural properties of the energy landscape) For any \(k_1,k_2 \in \{1,\ldots , K\}\), \(k_1 \ne k_2\),
and
In particular, if \(k_1 \not \in K_*(k_2)\), then it follows from Propositions 3.21 and 3.23 that
Assumption B is thus not satisfied for the the pair \((\sigma _{k_1},\{\sigma _{k_2}\})\). Indeed, there exists another configuration \(\sigma _{k'}\), for some \(k' \in K_*(k_2)\), \(k' \ne k_1\), for which the recurrence probability
does not vanish as \(\beta \rightarrow \infty \), since component \(V_{k'}\) has size \(L_* > L_{k_1}\). As illustrated in Proposition 3.22, the scaled hitting time \(\tau ^{\sigma _{k_1}}_{\sigma _{k_2}}/\mathbb E\tau ^{\sigma _{k_1}}_{\sigma _{k_2}}\) does not converge in distribution to an exponential random variable with unit mean as \(\beta \rightarrow \infty \).
3.8 Mixing Time and Spectral Gap
In this subsection we focus on the long-run behavior of the Metropolis Markov chain \({\{X^\beta _t \}_{t \in \mathbb N}}\) and in particular examine the rate of convergence to the stationary distribution. We measure the rate of convergence in terms of the total variation distance and the mixing time, which describes the time required for the distance to stationarity to become small. More precisely, for every \(0 < \epsilon < 1\), we define the mixing time \(t^{\mathrm {mix}}_\beta (\epsilon )\) by
where \(\Vert \nu - \nu ' \Vert _{\mathrm {TV}}:=\frac{1}{2} \sum _{x \in \mathcal {X}} |\nu (x)-\nu '(x)|\) for any two probability distributions \(\nu ,\nu '\) on \(\mathcal {X}\). Another classical notion to investigate the speed of convergence of Markov chains is the spectral gap, which is defined as
where \(1=a_{\beta }^{(1)} > a_{\beta }^{(2)} \ge \ldots \ge a_\beta ^{(|\mathcal {X}|)} \ge -1\) are the eigenvalues of the matrix \((P_\beta (x,y))_{x,y \in \mathcal {X}}\).
The spectral gap can be equivalently defined using the Dirichlet form associated with the pair \((P_\beta , \mu _\beta )\), see [30, Lemma 13.12]. The problem of studying the convergence rate towards stationarity for a Friedlin-Wentzell Markov chain has already been studied in [11, 26, 32, 39]. In particular, in [11] the authors characterize the order of magnitude of both its mixing time and spectral gap in terms of certain “critical depths” of the energy landscape associated with the Friedlin–Wentzell Markov chain. We summarize the results in the context of Metropolis Markov chains in the next proposition.
Proposition 3.24
(Mixing time and spectral gap for Metropolis Markov chains) For any \(0 < \epsilon < 1\) and any \(s\in \mathcal {X}^s\),
Furthermore, there exist two constants \(0 < c_1 \le c_2 < \infty \) independent of \(\beta \) such that for every \(\beta >0\)
4 Proof of Results for General Metropolis Markov Chain
In this section we prove the results presented in Sect. 3 for a Metropolis Markov chain \({\{X^\beta _t \}_{t \in \mathbb N}}\) with energy landscape \((\mathcal {X},H,q)\) and inverse temperature \(\beta \). For compactness, we will suppress the implicit dependence on the parameter \(\beta \) in the notation.
4.1 Proof of Lemma 3.8
If \(\omega \in \Omega ^{\mathrm {opt}}_{x,A}\), then trivially \(\omega \in \Omega _{x,A}\). Moreover, we claim that \(\omega \in \Omega ^{\mathrm {opt}}_{x,A}\) implies \(\omega \subseteq C^+_{A}(x)\). Indeed, by definition of an optimal path and inequality (26), it follows that an optimal path cannot exit from \(C^+_{A}(x)\) since
The reverse implication follows from the minimality of \(C^+_{A}(x)\), which guarantees that \(\Phi (x,A)=\max _{z \in C^+_{A}(x)} H(z)\). \(\square \)
4.2 Proof of Proposition 3.10
We first prove the lower bound (33) and, in the second part of the proof, the upper bound (34).
Consider the event \(\{\tau ^x_{A}< e^{\beta (\Psi _{\mathrm {min}}(x,A)-\varepsilon )}\}\) first. There are two possible scenarios: Either the process exits from the cycle \(C^+_{A}(x)\) before hitting A or not. Hence,
The quantity \(\mathbb P_{\beta } ( \tau ^x_{\partial C^+_{A}(x)} < e^{\beta (\Psi _{\mathrm {min}}(x,A)-\varepsilon )} )\) is exponentially small in \(\beta \) for \(\beta \) sufficiently large, thanks to Theorem 3.2(i) and to the fact that \({\Psi _{\mathrm {min}}(x,A)< \Gamma (C^+_{A}(x))}\). In order to derive an upper bound for the first term in the right-hand side of (61), we introduce the following set
By definition (29) of \(\Psi _{\mathrm {min}}(x,A)\), every optimal path \({\omega \in \Omega ^{\mathrm {opt}}_{x,A}}\) must inevitably visit a cycle of depth not smaller than \(\Psi _{\mathrm {min}}(x,A)\) and therefore it has to enter the subset \(\mathcal {Z}_{\mathrm {opt}}\) before hitting A. Hence, for every \(z \in \mathcal {Z}_{\mathrm {opt}}\), conditioning on the event \(\{ \tau ^x_{A}< \tau ^x_{\partial C^+_{A}(x)}, \, X_{\tau ^x_{\mathcal {Z}_{\mathrm {opt}}}} = z\}\), we can write
and, in particular, \(\tau ^x_{A}\ge _\text {st} \tau ^{z}_{A}\). Using this fact, we get that there exists some \(k_2>0\) such that for \(\beta \) sufficiently large
where we used Theorem 3.2(i) and the fact that \({\tau ^z_A \ge \tau ^z_{\partial C_A(z)}}\) and \(\Gamma (C_A(z)) = \Gamma (z,A)\) \(\ge \Psi _{\mathrm {min}}(x,A)\) for every \(z \in \mathcal {Z}_{\mathrm {opt}}\).
For the upper bound, we can argue that
The second term is exponentially small in \(\beta \) thanks to Theorem 3.2(iii) applied to the cycle \(C^+_{A}(x)\), to which both x and at least one state of A belong.
We now turn our attention to the first term. If the Markov chain \(\{X_t\}_{t \in \mathbb N}\) hits the target set A before exiting from the cycle \(C^+_{A}(x)\), then it has been following an optimal path and, in particular, before hitting A it can have visited only states in the set \(R_{A}(x)\setminus A\). Consider a state \(z \in R_{A}(x)\setminus A\). By definition of \(R_{A}(x)\), z can be reached from x by means of an optimal path, i.e., there exists a path \(\omega ^* : z \rightarrow x\) such that \(\Phi _{\omega ^*} \le \Phi (x,A)\). This fact implies that \(\Phi (z,A) \le \Phi (x,A)\) and thus for every path in \({\omega \in \Omega ^{\mathrm {opt}}_{z,A}}\), we can obtain a path that belongs to \({\Omega ^{\mathrm {opt}}_{x,A}}\) by concatenating \(\omega ^*\) and \(\omega \). Hence,
Lemma 3.11 guarantees the existence of a cycle-path \(C_1,\ldots ,C_n\) vtj-connected to A such that \(z \in C_1\) and \(C_1, \ldots C_n \in \mathcal {M}(\mathcal {X}\setminus A)\). From the fact that this cycle-path is vtj-connected and Lemma 3.12, it follows that \(H(\mathcal {B}(C_i)) \le \Phi (x,A)\). Definition (30), inclusion (40) and inequality (63) imply that
For every \(i = 2,\ldots , n\) take a state \(y_{i} \in \mathcal {B}(C_{i-1}) \cap C_{i}\).Furthermore, take \(y_{1} = z\) and \(y_{n+1} \in \mathcal {B}(C_n)\cap A\). Consider the set of paths
consisting of the paths constructed by the concatenation of any n-tuple of paths \(\omega ^{(1)},\omega ^{(2)},\ldots ,\) \(\omega ^{(n)}\) satisfying the following conditions:
-
(1)
The path \(\omega ^{(i)}\) has length \(|\omega ^{(i)}| \le e^{\beta (\Psi _{\mathrm {max}}(x,A)+\varepsilon /4)}\), for any \(i=1,\ldots ,n\);
-
(2)
The path \(\omega ^{(i)}\) joins \(y_{i}\) to \(y_{i+1}\), i.e., \(\omega ^{(i)} \in \Omega _{y_{i},y_{i+1}}\), for any \(i=1,\ldots ,n\);
-
(3)
All the states \(\omega ^{(i)}_{j}\) belong to \(C_{i}\) for any \(j=1,\ldots ,|\omega ^{(i)}|-1\), for any \(i=1,\ldots ,n\).
We stress that the first condition restricts the set \(\mathcal E_{\varepsilon ,z,A}\) to paths that spend less than \(e^{\beta (\Psi _{\mathrm {max}}(x,A)+\varepsilon /4)}\) time in cycle \(C_{i}\), for every \(i =1,\ldots n\). Note that the length of any path \(\omega \in \mathcal E_{\varepsilon ,z,A}\) satisfies the upper bound \(|\omega | \le |\mathcal {X}| e^{\beta (\Psi _{\mathrm {max}}(x,A)+\varepsilon /4)}\). Moreover, since the state space \(\mathcal {X}\) is finite, for \(\beta \) sufficiently large
Therefore, for every \(z \in R_{A}(x)\setminus A\)
Using the Markov property, we obtain that for any \(\varepsilon '>0\) and \(\beta \) sufficiently large
where the second last inequality follows from Theorem 3.2(v). Since \(e^{-\beta \varepsilon '|\mathcal {X}|}\) does not depend on the initial state z,
Applying iteratively the Markov property at the times \(k e^{\beta (\Psi _{\mathrm {max}}(x,A)+ \varepsilon /2)}\), with \(k=1,\ldots , e^{\beta \varepsilon /2}\), we obtain that
We remark that we can take the supremum over the states in \(R_{A}(x)\setminus A\), since all the other states in \(C^+_{A}(x)\setminus R_{A}(x)\) cannot be reached by means of an optimal path (i.e., without exiting from \(C^+_{A}(x)\)) before visiting the target subset A. Choosing \(\varepsilon ' > 0\) small enough and \(\beta \) sufficiently large, we get that \(e^{ -e^{ \beta (\varepsilon /2-\varepsilon ' |\mathcal {X}|)}} \le e^{-k\beta }\) for any \(k>0\). \(\square \)
4.3 Proof of Lemma 3.12
Take a path \({\omega \in \Omega _{x,A}}\) and the corresponding cycle-path \({\mathcal {G}(\omega )=(C_1,\ldots ,C_{m(\omega )})}\).
We first show that \(\omega \not \in \Omega ^{\mathrm {vtj}}_{x,A}\) implies that \(\Phi (\omega _{i+1},A) > \Phi (\omega _{i},A)\) for some \(1 \le i \le |\omega |\). If \({\omega \not \in \Omega ^{\mathrm {vtj}}_{x,A}}\), then the cycle-path \(\mathcal {G}(\omega )=(C_1,\ldots ,C_{m(\omega )})\) is not vtj-connected to A, which means that there exists an index \(1 \le k \le m(\omega )\) such that \(\partial C_{k} \cap C_{k+1} \ne \varnothing \), but \(\mathcal {B}(C_{k}) \cap C_{k+1} = \varnothing \). Take the corresponding index i in the path \(\omega \) such that \(\omega _i \in C_k\) and \(\omega _{i+1} \in \partial C_k \cap C_{k+1}\). From the fact that \(\omega _{i+1} \not \in \mathcal {B}(C_k)\), it follows that
Indeed, if \(C_k\) is a trivial cycle, i.e., \(C_k =\{\omega _{i}\}\), then \(\omega _{i+1} \not \in \mathcal {B}(C_k)\) implies \(H(\omega _{i+1}) > H(\omega _i)\) and thus
where the last equality holds since \(C_k\) is a trivial cycle in \(\mathcal {M}(\mathcal {X}\setminus A)\). In the case where \(C_k\) is a non-trivial cycle, then
where the last equality follows from the fact that \(C_k=C_A(\omega _i)\).
We now focus on the converse implication. We want to prove that if \({\omega \in \Omega ^{\mathrm {vtj}}_{x,A}}\) then \(\Phi (\omega _{i+1},A) \le \Phi (\omega _{i},A)\) for every \(i=1,\ldots , |\omega |\). Consider the index k such that \(\omega _i \in C_k\). If the states \(\omega _i\) and \(\omega _{i+1}\) both belong to \(C_k\), then \(C_A(\omega _i) = C_A(\omega _{i+1}) = C_k\) and \(\Phi (\omega _{i+1},A) = \Phi (\omega _{i},A)\). If instead \(\omega _i\) and \(\omega _{i+1}\) belongs to different cycles, then \(\omega _{i+1} \in \mathcal {B}(C_k) \cap C_{k+1}\) by definition of cycle-path. If \(C_k = C_A(\omega _i)\) is a non-trivial cycle, then \(H(\omega _{i+1})=H(\mathcal {F}(\partial C_k)\) and thus
Lastly, if \(C_k\) is instead a trivial cycle, then \(H(\omega _{i+1}) \le H(\omega _i) \le \Phi (\omega _i,A)\) and thus
\(\square \)
4.4 Proof of Lemma 3.13
In (44) we have used the fact that the only way to exit from the tube \(\mathrm {T}_{A}(x)\) without having hit the subset A first is to exit from the non-principal boundary of a cycle \(C \in \mathfrak {T}_{A}(x)\). Therefore
for some \(\kappa > 0\) and \(\beta \) sufficiently large. The second last inequality follows from Theorem 3.2(iv) when C is a non-trivial cycle and directly from definition (37) of \(\mathcal {B}(C)\) and the transition probabilities (2) when C is a trivial cycle. Thanks to the definition (41) of the typical tube, \(\mathbb P_{\beta } ( \tau ^x_{\partial \mathrm {T}_{A}(x)} = \tau ^x_{A} )=0\), since all the states of the target state A that can be hit starting from x by means of a typical path belong to \(\mathrm {T}_{A}(x)\) and not to \(\partial \mathrm {T}_{A}(x)\). The second statement follows applying the same reasoning to \(\partial ^{np} \mathfrak {T}_{A}(x)\) and using the fact \(\partial ^{np} \mathfrak {T}_{A}(x)\subset \partial \mathrm {T}_{A}(x)\). \(\square \)
4.5 Proof of Proposition 3.15
As mentioned in Sect. 3.4, this proposition is a refinement of Proposition 3.10, so instead of giving a full proof, we will just describe the necessary modifications.
We first prove (49). Consider the event \(\{\tau ^x_{A}< e^{\beta (\Theta _{\mathrm {min}}(x,A)-\varepsilon )}\}\) first. There are two possible scenarios: Either the process exits the tube \(\mathrm {T}_{A}(x)\) of typical paths before hitting A or it stays in \(\mathrm {T}_{A}(x)\) until it hits A. Hence,
Lemma 3.13 implies that the second term in the right-hand side of (64) is exponentially small in \(\beta \). In order to derive an upper bound for the first term in (64), we introduce the set
By definition (45) of \(\Theta _{\mathrm {min}}(x,A)\), every typical path \(\omega \in \Omega ^{\mathrm {vtj}}_{x,A}\) must inevitably visit a cycle of depth not smaller than \(\Theta _{\mathrm {min}}(x,A)\) and therefore has to enter the subset \(\mathcal {Z}_{\mathrm {vtj}}\) before hitting A. Hence, for every \(z \in \mathcal {Z}_{\mathrm {vtj}}\), conditioning on the event \(\{ \tau ^x_{A}< \tau ^x_{\partial \mathrm {T}_{A}(x)}, \, X_{\tau ^x_{\mathcal {Z}_{\mathrm {vtj}}}} = z\}\), we can write
and in particular we have that \(\tau ^x_{A}>_\text {st} \tau ^{z}_{A}\). Using this fact and arguing like in (62), we can prove that there exists \(\kappa >0\) such that \(\beta \) sufficiently large such that
We now turn our attention to the proof of the upper bound (50). First note that
where the the latter term is exponentially small in \(\beta \) for \(\beta \) sufficiently large, thanks to Lemma 3.13. For the first term in (65), we refine the argument given in the second part of the proof of Proposition 3.10. Consider a state \(z \in \mathrm {T}_{A}(x)\setminus A\). Since \(\mathrm {T}_{A}(z) \subseteq \mathrm {T}_{A}(x)\), it follows from (47) that
Thanks to Lemma 3.11, there exists a cycle-path of maximal cycles \(C_1,\ldots ,C_n \subset \) in \(\mathcal {X}\setminus A\) that is vtj-connected to A and such that \(z\in C_1\). The definition of vtj-connected cycle-path, Lemma 3.14 and inequality (66) imply that
For each \(i =2, \ldots , n\), take a state \(y_{i} \in \mathcal {B}(C_{i-1}) \cap C_{i}\). Furthermore, take \(y_{1} = z\) and \(y_{n+1} \in \mathcal {B}(C_n)\cap A\). We consider the collection of paths
which consists of all paths obtained by concatenating any n–tuple of paths \(\omega ^{(1)},\omega ^{(2)},\ldots ,\omega ^{(n)}\) satisfying the following conditions:
-
(1)
The path \(\omega ^{(i)}\) has length \(|\omega ^{(i)}| \le e^{\beta (\Theta _{\mathrm {max}}(x,A)+\varepsilon /4)}\), for any \(i=1,\ldots ,n\);
-
(2)
The path \(\omega ^{(i)}\) joins \(y_{i}\) to \(y_{i+1}\), i.e., \(\omega ^{(i)} \in \Omega _{y_{i},y_{i+1}}\), for any \(i=1,\ldots ,n\);
-
(3)
All the states \(\omega ^{(i)}_{j}\) belong to \(C_{i}\) for any \(j=1,\ldots ,|\omega ^{(i)}|-1\), for any \(i=1,\ldots ,n\).
This collection is similar to the collection \(\mathcal E_{\varepsilon ,z,A}\) described in the proof of Proposition 3.10, but condition (1) here is stronger. Using (67) and arguing as in the proof of Proposition 3.10, we obtain that
Since \(e^{-\beta \varepsilon '|\mathcal {X}|}\) does not depend on the initial state z, we get for any \(\varepsilon '>0\) and \(\beta \) sufficiently large
and thus
by applying iteratively the Markov property at the times \(k e^{\beta (\Theta _{\mathrm {max}}(x,A)+ \varepsilon /2)}\), with \(k=1,\ldots , e^{\beta \varepsilon /2}\). Choosing \(\varepsilon ' > 0\) small enough and \(\beta \) sufficiently large, we get that the right-hand side of inequality (68) is super-exponentially small in \(\beta \), which completes the proof of the upper bound (50). \(\square \)
4.6 Proof of Theorem 3.17
Since Assumption (A1) holds, we set \(\Theta (x,A) = \Theta _{\mathrm {min}}(x,A)= \Theta _{\mathrm {max}}(x,A)\). The starting point of the proof is the following technical lemma.
Lemma 4.1
(Uniform integrability) If Assumption (A2) holds, then for any \(\varepsilon >0\) the variables \(Y^x_{A}(\beta ) := \tau ^x_{A}e^{-\beta (\Theta (x,A) +\varepsilon )}\) are uniformly integrable, i.e., there exists \(\beta _0 >0\) such that for any \(\delta >0\) there exists \(K \in (0,\infty )\) such that for any \(\beta > \beta _0\)
Proof
The proof is similar to that of [31, Corollary 3.5]. It suffices to have exponential control of the tail of the random variable \(Y^x_{A}(\beta )\) for \(\beta \) sufficiently large, i.e.,
with \(a<1\). Assumption (A2) implies that \(\Theta _{\mathrm {max}}(z,A) \le \Theta (x,A)\) for every \(z \in \mathcal {X}\setminus A\). Then, iteratively using the Markov property gives
and the conclusion follows from Proposition 3.15. \(\square \)
Proposition 3.15 implies that the random variable \(Y^x_{A}(\beta ) := \tau ^x_{A}e^{-\beta (\Theta (x,A) +\varepsilon )}\) converges to 0 in probability as \(\beta \rightarrow \infty \). Lemma 4.1 guarantees that the sequence \((Y^x_{A}(\beta ))_{\beta \ge \beta _0}\) is also uniformly integrable and thus \(\lim _{\beta \rightarrow \infty }\mathbb E|Y^x_{A}(\beta )| = 0\). Therefore, for any \(\varepsilon >0\) we have that for \(\beta \) sufficiently large \(\mathbb E\tau ^x_{A}< e^{\beta (\Theta (x,A) +\varepsilon )}\). As far as the lower bound is concerned, for any \(\varepsilon >0\) Proposition 3.15 and the identity \(\Theta (x,A)=\Theta _{\mathrm {min}}(x,A)\) yield
Since \(\varepsilon \) is arbitrary, the conclusion follows. \(\square \)
4.7 Proof of Theorem 3.19
As mentioned before, the strategy is to show that the Markov chain \(\{X_t\}_{t \in \mathbb N}\) satisfies the assumptions of [21, Theorem 2.3], which for completeness we reproduce here. For \(R > 0\) and \(r \in (0,1)\), we say that the pair (x, A) with \(A \subset \mathcal {X}\) satisfies \(\text {Rec}(R, r)\) if
The quantities R and r are called recurrence time and recurrence error, respectively.
Theorem 4.2
[21, Theorem 2.3] Consider a nonempty subset \(A \subset \mathcal {X}\) and \(x \not \in A\) such that \(\mathrm {Rec}(R(\beta ),r(\beta ))\) holds and
-
(i)
\(\lim _{\beta \rightarrow \infty }R(\beta ) /\mathbb E\tau ^x_{A}(\beta ) = 0\),
-
(ii)
\(\lim _{\beta \rightarrow \infty }r(\beta )=0\).
Then there exist two functions \(k_1(\beta )\) and \(k_2(\beta )\) with \(\lim _{\beta \rightarrow \infty }k_1(\beta )=0\) and \(\lim _{\beta \rightarrow \infty }k_2(\beta )=0\) such that for any \(s>0\)
Since \(\widetilde{\Gamma }(\mathcal {X}\setminus (A\cup \{x\})) < \Theta (x,A)\) by assumption, we can take \(\varepsilon >0\) small enough such that \(\widetilde{\Gamma }(\mathcal {X}\setminus (A\cup \{x\})) +\varepsilon < \Theta (x,A)\). Proposition 3.7 implies that there exists \(\kappa >0\) such that the pair (x, A) satisfies \(\text {Rec}(e^{\beta \widetilde{\Gamma }(\mathcal {X}\setminus (A\cup \{x\}))+\varepsilon )}, e^{-\kappa \beta })\) for \(\beta \) sufficiently large, since
Clearly \(r(\beta )=e^{-e^{\kappa \beta }} \rightarrow 0\) as \(\beta \rightarrow \infty \) and thus assumption (ii) holds. Assumption (i) is also satisfied, since
\(\square \)
4.8 Proof of Proposition 3.24
The two limits in (59) are an almost immediate consequence of [11, Theorem 5.1] and [32, Proposition 2.1]. Indeed, we just need to show that the critical depths \(H_2\) and \(H_3\) (see below for their definitions) that appear in these two results are equal to \({\widetilde{\Gamma }( \mathcal {X}\setminus \{s\})}\), for any \(s \in \mathcal {X}^s\). The critical depth \(H_2\) is equal to \({\widetilde{\Gamma }( \mathcal {X}\setminus \{s\})}\) by definition, see [11]. Note that this quantity is well defined, since its value is independent of the choice of s, as stated in [11, Theorem 5.1]. This critical depth is also known in the literature as maximal internal resistance of the state space \(\mathcal {X}\), see [31, Remark 4.4].
The definition of the critical depth \(H_3\) is more involved and we need some further notation. Consider the two-dimensional Markov chain \(\{(X_t,Y_t)\}_{t \ge 0}\), where \(X_t\) and \(Y_t\) are two independent Metropolis Markov chains on the same energy landscape \((\mathcal {X},H,q)\) and indexed by the same inverse temperature \(\beta \). In other words, \(\{(X_t,Y_t)\}_{t \ge 0}\) is the Markov chain on \(\mathcal {X}\times \mathcal {X}\) with transition probabilities \(P_\beta ^{\otimes 2}\) given by
The critical depth \(H_3\) is then defined as
where \(D := \{ (x,x) ~\mathbin {|}~x \in \mathcal {X}\}\). Consider the null-cost graph on the set of stable states, i.e., the directed graph (V, E) with vertex set \(V=\mathcal {X}^s\) and edge set
[11, Theorem 5.1] guarantees that \(H_2 \le H_3\) and states that if the null-cost graph has an aperiodic component, then \(H_2=H_3\). We claim that this condition is always satisfied by a Metropolis Markov chain with energy landscape \((\mathcal {X},H,q)\) with a non-constant energy function H. It is enough to show that for any such a Markov chain there exists at least one stable state \(s \in \mathcal {X}^s\) such that
The subset \(\mathcal {X}\setminus \mathcal {X}^s\) is a non-empty set, since H is non-constant. Since q is irreducible, there exists a state \(s \in \mathcal {X}^s\) and \(x \in \mathcal {X}\setminus \mathcal {X}^s\) such that \(q(s,x) >0\). Furthermore, we can choose \(s \in \mathcal {X}^s\) and \(x \in \mathcal {X}\setminus \mathcal {X}^s\) such that the difference \(H(x)-H(s)\) is minimal. For this stable state s, the transition probability towards itself reads
Since q is a stochastic matrix, it follows that \(1- \sum _{s' \in \mathcal {X}^s, \, s'\ne s} q(s,s') >0\) independently of \(\beta \) and thus
since for every \(\varepsilon >0\) there exists \(\beta _0\) such that \(P_\beta (s,s) \ge 1 - \sum _{s' \in \mathcal {X}^s, \, s'\ne s} q(s,s') - e^{-\beta (H(x)-H(s))^+} > e^{- \beta \varepsilon }\) for \(\beta > \beta _0\). Finally, the bounds (60) follow immediately from [26, Theorem 2.1], since the quantity m which appears there is equal to \(\widetilde{\Gamma }( \mathcal {X}\setminus \{s\})\) thanks to Lemma 3.6. \(\square \)
5 Energy Landscape Analysis for the Hard-Core Model on Grids
This section is devoted to the analysis of the energy landscapes corresponding to the hard-core dynamics on the three different types of grids presented in Sect. 2. Starting from geometrical and combinatorial properties of the admissible configurations, we prove some structural properties of the energy landscapes \(\mathcal {X}_{T_{K,L}}, \mathcal {X}_{G_{K,L}}\) and \(\mathcal {X}_{C_{K,L}}\). These results are precisely the model-dependent characteristics that are needed to exploit the general framework developed in Sect. 3 to obtain the main results for the hard-core model on grids presented in Sect. 2.3. These structural properties are stated in the next three theorems and the rest of this section is devoted to their proofs.
Theorem 5.1
(Structural properties of \(\mathcal {X}_{T_{K,L}}\)) Consider the energy landscape corresponding to the hard-core model on the \(K\times L\) toric grid graph \(T_{K,L}\). Then,
-
(i)
\(\widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}) \le \min \{K,L\}\),
-
(ii)
\(\Gamma ({\mathbf {e}},\{{\mathbf {o}}\}) = \min \{K,L\}+1 = \widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {o}}\})\).
Theorem 5.1 implies that conditions (53) and (58) hold for the pair \(({\mathbf {e}},\{{\mathbf {o}}\})\) in the energy landscape \((\mathcal {X}_{T_{K,L}},H,q)\). Hence Assumptions A and B are satisfied and the statements of Theorems 2.1 and 2.2 for a toric grid graph \(T_{K,L}\) follow from Corollary 3.16 and Theorems 3.17 and 3.19, respectively.
Theorem 5.2
(Structural properties of \(\mathcal {X}_{G_{K,L}}\)) Consider the energy landscape corresponding to the hard-core model on the \(K\times L\) open grid graph \(G_{K,L}\). If \(KL \equiv 0 \pmod 2\), then
-
(i)
\(\widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}) \le \min \{\lceil K/2 \rceil , \lceil L/2 \rceil \}\),
-
(ii)
\(\Gamma ({\mathbf {e}},\{{\mathbf {o}}\}) = \min \{\lceil K/2 \rceil , \lceil L/2 \rceil \}+1 = \widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {o}}\})\).
If instead \(KL \equiv 1 \pmod 2\), then
-
(iii)
\(\widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}) < \min \{\lceil K/2 \rceil , \lceil L/2 \rceil \}\),
-
(iv)
\(\Gamma ({\mathbf {e}},\{{\mathbf {o}}\}) \!=\! \min \{\lceil K/2 \rceil , \lceil L/2 \rceil \}+1 \!=\! \widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {o}}\})\) and \(\Gamma ({\mathbf {o}},\{{\mathbf {e}}\}) = \min \{\lceil K/2 \rceil , \lceil L/2 \rceil \}= \widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {e}}\})\).
We remark that in the case \(KL \equiv 1 \pmod 2\), inequality in (iii) is strict, while inequality in (i) is not, and this fact is crucial in order to conclude that \({\mathbf {o}}\) is the unique metastable state of the state space \(\mathcal {X}_{G_{K,L}}\) when \(KL \equiv 1 \pmod 2\). Using Theorem 5.2, we can check that the pair \(({\mathbf {e}},\{{\mathbf {o}}\})\) satisfies both Assumptions A and B [since both conditions (53) and (58) hold] and thus prove the asymptotic properties in Theorems 2.1 and 2.2 for the hitting times \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) and \(\tau ^{\mathbf {o}}_{\mathbf {e}}\) when \(\Lambda \) is the open grid graph \(G_{K,L}\).
Theorem 5.3
(Structural properties of \(\mathcal {X}_{C_{K,L}}\)) Consider the energy landscape corresponding to the hard-core model on the \(K\times L\) cylindrical grid graph \(C_{K,L}\). Then
-
(i)
\(\widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}) \le \min \{K/2,L\}\),
-
(ii)
\(\Gamma ({\mathbf {e}},\{{\mathbf {o}}\}) = \min \{K/2,L\}+1 = \widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {o}}\})\).
Using Theorem 5.3, we can check that Assumptions A and B are satisfied by the pair \(({\mathbf {e}},\{{\mathbf {o}}\})\), and then the statements of Theorems 2.1 and 2.2 for a cylindrical grid graph \(C_{K,L}\) follow from Corollary 3.16 and Theorems 3.17 and 3.19. The ideas behind the proofs of these three theorems are similar, but for clarity we present them separately in Sects. 5.1, 5.2 and 5.3.
Denote \(\Gamma (\Lambda ):= \widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {e}}\})\), where \((\mathcal {X},H,q)\) is the energy landscape corresponding to the hard-core model on the grid graph \(\Lambda \). In the case \(\Lambda = G_{K,L}\) with \(KL \equiv 1 \pmod 2\), Theorem 5.2 gives that \(\Gamma (\Lambda )=\min \{ \lceil K/2 \rceil , \lceil L/2 \rceil \}\). In all the other cases by symmetry we have \({\widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {e}}\}) = \widetilde{\Gamma }(\mathcal {X}\setminus \{{\mathbf {o}}\})}\) and hence, from Theorems 5.1, 5.2 and 5.3 it then follows that
Besides appearing in the two main theorems (Theorems 2.1, 2.2), the exponent \(\Gamma (\Lambda )\) also characterizes the asymptotic order of magnitude of the mixing time \(t^{\mathrm {mix}}_\beta (\epsilon ,\Lambda )\) and of the spectral gap \(\rho _\beta (\Lambda )\) of the hard-core dynamics \(\{X_t\}_{t \in \mathbb N}\) on \(\Lambda \) (see Sect. 3.8), as established in the next theorem.
Theorem 5.4
(Mixing time and spectral gap) For any grid graph \(\Lambda \) and for any \(0 < \epsilon < 1\),
Furthermore, there exist two constants \(0 < c_1 \le c_2 < \infty \) independent of \(\beta \) such that for every \(\beta >0\)
The proof readily follows from the properties of the energy landscapes established in Theorems 5.1, 5.2 and 5.3 and by applying Proposition 3.24.
We next introduce some notation and definitions for grid graphs. Recall that \(\Lambda \) is a \(K \times L\) grid graph with \(K,L \ge 2\) which has \(N = KL\) sites in total. We define the energy wastage of a configuration \(\sigma \in \mathcal {X}\) on the grid graph \(\Lambda \) as the difference between its energy and the energy of the configuration \({\mathbf {e}}\), i.e.,
Since \(H({\mathbf {e}}) =- \lceil N/2 \rceil \), we have that
Moreover, since \({\mathbf {e}}\) is a stable state, \(U(\sigma ) \ge 0\). The function \(U: \mathcal {X}\rightarrow \mathbb R_+ \cup \{0\}\) is usually called virtual energy in the literature [11, 17] and satisfies the following identity
where \(\mu _\beta \) is the Gibbs measure (3) of the Markov chain \(\{X_t\}_{t \in \mathbb N}\).
We denote by \(c_j\), \(j=0,\ldots ,L-1\), the jth column of \(\Lambda \), i.e., the collection of sites whose horizontal coordinate is equal to j, and by \(r_i\), \(i=0,\ldots ,K-1\), the ith row of \(\Lambda \), i.e., the collection of sites whose vertical coordinate is equal to i, see Fig. 7. In particular, a vertex is identified by the coordinates (j, i) if it lies at the intersection of row \(r_i\) and column \(c_j\). In addition, define the i -th horizontal stripe, with \(i=1,\ldots ,\lfloor K/2 \rfloor \), as
and the j -th vertical stripe, with \(j=1,\ldots ,\lfloor L/2 \rfloor \) as
as illustrated in Fig. 7.

Illustration of row, column and stripe notation
An important feature of the energy wastage U for grid graphs, is that it can be seen as the sum of the energy wastages on each row (or on each horizontal stripe). More precisely, let \(U_j(\sigma )\) be the energy wastage of a configuration \(\sigma \in \mathcal {X}\) in the ith row, i.e.,
Similarly, let \(U^S_i(\sigma )\) be the energy wastage of a configuration \(\sigma \in \mathcal {X}\) on the ith horizontal stripe, i.e.,
Then, we can rewrite the energy wastage of a configuration \(\sigma \in \mathcal {X}\) as
Given two configurations \(\sigma ,\sigma ' \in \mathcal {X}\) and a subset of sites \(W \subset \Lambda \), we write
We say that a configuration \(\sigma \in \mathcal {X}\) has a vertical odd (even) bridge if there exists a column in which configuration \(\sigma \) perfectly agrees with \({\mathbf {o}}\) (respectively \({\mathbf {e}}\)), i.e., if there exists an index \(0 \le j \le L-1\) such that
We define horizontal odd and even bridges in an analogous way and we say that a configuration \(\sigma \in \mathcal {X}\) has an odd (even) cross if it has both vertical and horizontal odd (even) bridges; see some examples in Fig. 8.

Examples of configurations on the \(8 \times 8\) toric grid displaying odd bridges or crosses. a Horizontal odd bridge, b two vertical odd bridges, c odd cross
We remark that the structure of the grid graph \(\Lambda \) and the hard-core constraints prohibit the existence of two perpendicular bridges of different parity, e.g. a vertical odd bridge and a horizontal even bridge. Bridges and crosses are the geometric feature of the configurations which will be crucial in the following subsections to prove Theorems 5.1, 5.2 and 5.3.
5.1 Energy Landscape Analysis for Toric Grid Graphs (Proof of Theorem 5.1)
This subsection is devoted to the proof of Theorem 5.1 in the case where \(\Lambda \) is the toric grid graph \(T_{K,L}\). Without loss of generality, we assume henceforth that \(K \le L\), and that \(K + L > 4\), in view of the remark after Theorem 2.2. Recall that by construction of the toric grid graph, both K and L are even integers. In the remainder of the section we will write \(\mathcal {X}\) instead of \(\mathcal {X}_{T_{K,L}}\) to keep the notation light.
We first introduce a reduction algorithm, which is used to construct a specific path in \(\mathcal {X}\) from any given state in \(\mathcal {X}\setminus \{ {\mathbf {e}},{\mathbf {o}}\}\) to the subset \(\{{\mathbf {e}},{\mathbf {o}}\}\) and to show that
which proves Theorem 5.1(i). Afterwards, we show in Proposition 5.6 that
by giving lower bounds on the energy wastage along every path \({\mathbf {e}}\rightarrow {\mathbf {o}}\). The reduction algorithm is then used again in Proposition 5.7 to build a reference path \(\omega ^*: {\mathbf {e}}\rightarrow {\mathbf {o}}\) which shows that the lower bound is sharp and hence
which, together with (74), proves Theorem 5.1(ii).
The starting point of the energy landscape analysis is a very simple observation: A configuration in \(\mathcal {X}\) has zero energy wastage in a given row (column) if and only if it has an odd or even horizontal (vertical) bridge. The following lemma formalizes this property. We give the statement and the proof only for rows, since those for columns are analogous.
Lemma 5.5
(Energy efficient rows are bridges) For any \(\sigma \in \mathcal {X}\) and any \(i = 0, \ldots , K-1\),
Proof
The ith row of the toric grid graph \(\Lambda \) is a cycle graph with L / 2 even sites and L / 2 odd sites. If \(\sigma _{|r_i}={\mathbf {e}}_{|r_i}\) or \(\sigma _{|r_i}={\mathbf {o}}_{|r_i}\), then trivially there are L / 2 occupied sites and hence \(U_i(\sigma )=0\). Noticing that the configurations \({\mathbf {e}}_{|r_i}\) and \({\mathbf {o}}_{|r_i}\) on row i correspond to the only two maximum independent sets of the cycle graph \(r_i\) proves the converse implication. \(\square \)
5.1.1 Reduction Algorithm for Toric Grids
We now describe an iterative procedure which builds a path \(\omega \) in \(\mathcal {X}\) from a suitable initial configuration \(\sigma \) (with specific properties, see below) to state \({\mathbf {o}}\). We call it reduction algorithm, because along the path it creates the even clusters are gradually reduced and they eventually disappear, since the final configuration is \({\mathbf {o}}\).
The algorithm cannot be initialized in all configurations \(\sigma \in \mathcal {X}\setminus \{ {\mathbf {o}}\}\). Indeed, we require that the initial configuration \(\sigma \) is such that there are no particles in the even sites of the first vertical stripe \(C_1\), i.e.,
This technical assumption is required because the algorithm needs “some room” to start working, as will become clear later. The path \(\omega \) is the concatenation of L paths \(\omega ^{(1)}, \ldots , \omega ^{(L)}\). Path \(\omega ^{(j)}\) goes from \(\sigma _{j}\) to \(\sigma _{j+1}\), where we set \(\sigma _1=\sigma \) and recursively define for \(j=1,\ldots , L\)
Clearly, due to the periodic boundary conditions, the column index should be taken modulo L. It can be checked that indeed \(\sigma _{L+1}={\mathbf {o}}\). We now describe in detail how to construct each of the paths \(\omega ^{(j)}\) for \(j=1,\ldots ,L\). We build a path \(\omega ^{(j)}=(\omega ^{(j)}_{0}, \omega ^{(j)}_{1}, \ldots , \omega ^{(j)}_{K})\) of length \(K+1\) (but possibly with void moves), with \(\omega ^{(j)}_{0}=\sigma _j\) and \(\omega ^{(j)}_{K}=\sigma _{j+1}\). We start from configuration \(\omega ^{(j)}_0=\sigma _j\) and we repeat iteratively the following procedure for all \(i=0,\ldots ,K-1\):
-
If \(i \equiv 0 \pmod 2\), consider the even site \(v=(j+1, i+(j+1 \pmod 2))\).
-
If \(\omega ^{(j)}_{i}(v)=0\), we set \(\omega ^{(j)}_{i+1}=\omega ^{(j)}_{i}\) and thus \(H(\omega ^{(j)}_{i+1}) = H(\omega ^{(j)}_{i})\).
-
If \(\omega ^{(j)}_{i}(v)=1\), then we remove from configuration \(\omega ^{(j)}_{i}\) the particle in v increasing the energy by 1 and obtaining in this way configuration \(\omega ^{(j)}_{i+1}\), which is such that \(H(\omega ^{(j)}_{i+1}) = H(\omega ^{(j)}_{i})+1\).
-
-
If \(i \equiv 1 \pmod 2\), consider the odd site \(v=(j,i-1+(j+1 \pmod 2))\).
-
If \(\omega ^{(j)}_{i}(v)=1\), we set \(\omega ^{(j)}_{i+1}=\omega ^{(j)}_{i}\) and thus \(H(\omega ^{(j)}_{i+1}) = H(\omega ^{(j)}_{i})\).
-
If \(\omega ^{(j)}_{i}(v)=0\), then we add a particle in site v obtaining in this way a new configuration \(\omega ^{(j)}_{i+1}\), with energy \(H(\omega ^{(j)}_{i+1}) = H(\omega ^{(j)}_{i})-1\). This new configuration is admissible because all first neighboring sites of v are unoccupied by construction. In particular, the particle at its right [i.e., that at the site \(v+(1,0)\)] may have been removed exactly at the previous step.
-
Note that for the last path \(\omega ^{(L)}\) all the moves corresponding to even values of i are void (there are no particles in the even sites of \(c_0\)). The way the path \(\omega ^{(j)}\) is constructed shows that for every \(j=1,\ldots ,L\),
since the number of particles added in (the odd sites of) column \(c_j\) is greater than or equal to the number of particles removed in (the even sites of) column \(c_{j+1}\). Moreover,
since along the path \(\omega ^{(j)}\) every particle removal (if any) is always followed by a particle addition. These two properties imply that the path \(\omega : \sigma \rightarrow {\mathbf {o}}\) created by concatenating \(\omega ^{(1)},\ldots ,\omega ^{(L)}\) satisfies
Proof of Theorem 5.1(i)
It is enough to show that for every \(\sigma \in \mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}\)
since inequality (74) then follows the equivalent characterization of \(\widetilde{\Gamma }\) given in Lemma 3.6. To prove such an inequality, we have to exhibit for every \(\sigma \in \mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}\) a path \(\omega : \sigma \rightarrow {\mathbf {o}}\) in \(\mathcal {X}\) such that \(\Phi _{\omega }=\max _{\eta \in \omega } H(\eta ) \le H(\sigma )+K\). We construct such a path \(\omega \) as the concatenation of two shorter paths, \(\omega ^{(1)}\) and \(\omega ^{(2)}\), where \(\omega ^{(1)}: \sigma \rightarrow \sigma '\), \(\omega ^{(2)}: \sigma ' \rightarrow {\mathbf {o}}\) and \(\sigma '\) is a suitable configuration which depends on \(\sigma \) (see definition below).
Since \(\sigma \ne {\mathbf {e}}\) by assumption, the configuration \(\sigma \) must have a vertical stripe with strictly less than K even occupied sites. Without loss of generality (modulo a cyclic rotation of column labels) we can assume that this vertical stripe is the first one, \(C_1\), and we define
Define \(\sigma '\) as the configuration that differs from \(\sigma \) only in the even sites of the first vertical stripe, i.e.,
The path \(\omega ^{(1)}=(\omega ^{(1)}_1, \ldots , \omega ^{(1)}_{b+1})\), with \(\omega ^{(1)}_{1}=\sigma \) and \(\omega ^{(1)}_{b+1}=\sigma '\) can be constructed as follows. For \(i=1,\ldots ,b\), in step i we remove from configuration \(\omega ^{(1)}_{i}\) the first particle in \(C_1 \cap V_e\) in lexicographic order obtaining in this way configuration \(\omega ^{(1)}_{i+1}\), increasing the energy by 1. Therefore the configuration \(\sigma '\) is such that \(H(\sigma ')-H(\sigma ) = b\) and
The path \(\omega ^{(2)}: \sigma ' \rightarrow {\mathbf {o}}\) is then constructed by means of the reduction algorithm described earlier, choosing \(\sigma '\) as initial configuration and \({\mathbf {o}}\) as target configuration. The reduction algorithm guarantees that
The concatenation of the two paths \(\omega ^{(1)}\) and \(\omega ^{(2)}\) gives a path \(\omega : \sigma \rightarrow {\mathbf {o}}\) which satisfies the inequality \(\Phi _\omega \le H(\sigma )+b+1\), which, using (76), yields
\(\square \)
Proposition 5.6
(Lower bound for \(\Phi ({\mathbf {e}},{\mathbf {o}})\)) Consider the \(K \times L\) toric grid graph \(T_{K,L}\) with \(K \le L\). The communication height between \({\mathbf {e}}\) and \({\mathbf {o}}\) in the corresponding energy landscape satisfies
Proof
We need to show that in every path \(\omega : {\mathbf {e}}\rightarrow {\mathbf {o}}\), there is at least one configuration with energy wastage greater than or equal to \(K+1\). Take a path \(\omega =(\omega _1,\ldots , \omega _n) \in \Omega _{{\mathbf {e}},{\mathbf {o}}}\). Without loss of generality, we may assume that there are no void moves in \(\omega \), i.e., at every step either a particle is added or a particle is removed, so that \(H(\omega _{i+1}) = H(\omega _{i}) \pm 1\) for every \(i =1,\ldots ,n-1\). Since \({\mathbf {e}}\) has no odd bridge and \({\mathbf {o}}\) does, at some point along the path \(\omega \) there must be a configuration \(\omega _{m^*}\) which is the first to display an odd bridge, horizontal or vertical, or both simultaneously. In symbols
Clearly \(m^*>2\). We claim that \(U(\omega _{m^*-1}) \ge K+1\) or \(U(\omega _{m^*-2}) \ge L+1\). We distinguish the following three cases:
-
(a)
\(\omega _{m^*}\) displays an odd vertical bridge only;
-
(b)
\(\omega _{m^*}\) displays an odd horizontal bridge only;
-
(c)
\(\omega _{m^*}\) displays an odd cross.
These three cases cover all the possibilities, since the addition of a single particle cannot create more than one bridge in each direction.
For case (a), we claim that the energy wastage of configuration \(\omega _{m^*}\) on every row is greater than or equal to one. Suppose by contradiction that there exists a row r such that \(U^r(\sigma ) =0\). Then, by Lemma 5.5, there should be a bridge in row r; however, it cannot be an odd bridge, since otherwise we would be in case (c), and it cannot be an even bridge either, because it cannot coexist with the odd vertical bridge that configuration \(\omega _{m^*}\) has. Therefore,
The previous configuration \(\omega _{m^*-1}\) along the path \(\omega \) differs from \(\omega _{m^*}\) in a unique site \(v^*\). By definition of \(m^*\), \(v^*\) is an odd site and such that \(\omega _{m^*-1}(v^*) = 0\) and \(\omega _{m^*}(v^*)=1\). Thus,
For case (b) we can argue as in case (a), but interchanging the role of rows and columns, and obtain that
For case (c), the vertical and horizontal odd bridges that \(\omega _{m^*}\) has, must necessarily meet in the odd site \(v^*\). Having an odd cross, \(\omega _{m^*}\) cannot have any horizontal or vertical even bridge. Consider the previous configuration \(\omega _{m^*-1}\) along the path \(\omega \), which can be obtained from \(\omega _{m^*}\) by removing the particle in \(v^*\). From these considerations and from the definition of \(m^*\) it follows that \(\omega _{m^*-1}\) has no vertical bridge (neither odd or even) and thus, by Lemma 5.5, it has energy wastage at least one in every column, which amounts to
If there is at least one column in which \(\omega _{m^*-1}\) has energy wastage strictly greater than one, we get
and the claim is proved. Consider now the other scenario, in which the configuration \(\omega _{m^*-1}\) has energy wastage exactly one in every column, which means \(U(\omega _{m^*-1}) = L\). Consider its predecessor in the path \(\omega \), namely the configuration \(\omega _{m^*-2}\). We claim that
By construction, configuration \(\omega _{m^*-2}\) must differ in exactly one site from \(\omega _{m^*-1}\) and therefore
Consider the case where \(U(\omega _{m^*-2}) = U(\omega _{m^*-1})-1 = L -1\). In this case the configuration \(\omega _{m^*-2}\) must have a zero-energy-wastage column and by Lemma 5.5 it would be a vertical bridge. If it was an odd vertical bridge, the definition of \(m^*\) would be violated. If it was an even vertical bridge, it would be impossible to obtain the odd horizontal bridge (which \(\omega _{m^*}\) has) in just two single-site updates, since three is the minimum number of single-site updates needed. Therefore
\(\square \)
The next proposition shows that the lower bound in Proposition 5.6 is sharp and concludes the proof of Theorem 5.1(ii), in view of (74).
Proposition 5.7
(Reference path) There exists a path \(\omega ^*:{\mathbf {e}}\rightarrow {\mathbf {o}}\) in \(\mathcal {X}_{T_{K,L}}\) such that
Proof
We construct such a path \(\omega ^*\) as the concatenation of two shorter paths, \(\omega ^{(1)}\) and \(\omega ^{(2)}\), where \(\omega ^{(1)}: {\mathbf {e}}\rightarrow \sigma ^*\) and \(\omega ^{(2)}: \sigma ^* \rightarrow {\mathbf {o}}\), and prove that \(\Phi _{\omega ^{(1)}} = H(\sigma ^*) = H(\sigma ) + K\) and that \(\Phi _{\omega ^{(2)}} = H(\sigma ^*) + 1\) are satisfied, so that \(\Phi _{\omega ^*} = \max _{\eta \in \omega ^*} H(\eta ) = H({\mathbf {e}})+ K+1\) as desired. The reason why \(\omega \) is best described as the concatenation of two shorter paths is the following: The reduction algorithm cannot in general be started directly from \({\mathbf {e}}\) and the path \(\omega ^{(1)}\) indeed leads from \({\mathbf {e}}\) to \(\sigma ^*\), which is a suitable configuration to initialize the reduction algorithm. The configuration \(\sigma ^*\) differs from \({\mathbf {e}}\) only in the even sites of the first vertical stripe:
The path \(\omega ^{(1)}=(\omega ^{(1)}_{1},\ldots ,\omega ^{(1)}_{K+1})\), with \(\omega ^{(1)}_{1}={\mathbf {e}}\) and \(\omega ^{(1)}_{K+1}=\sigma ^*\) can be constructed as follows. For \(i=1,\ldots ,K\), at step i we remove from configuration \(\omega ^{(1)}_{i}\) the first particle in \(C_1 \cap V_e\) in lexicographic order, increasing the energy by 1 and obtaining in this way configuration \(\omega ^{(1)}_{i+1}\). Therefore the configuration \(\sigma ^*\) is such that \(H(\sigma ^*)-H({\mathbf {e}}) = K\) and \(\Phi _{\omega ^{(1)}} = H({\mathbf {e}})+K\). The second path \(\omega ^{(2)}: \sigma ^* \rightarrow {\mathbf {o}}\) is then constructed by means of the reduction algorithm, which can be used since the configuration \(\sigma ^*\) satisfies condition (75) and hence is a suitable initial configuration for the algorithm. The algorithm guarantees that \(\Phi _{\omega ^{(2)}} = H(\sigma ^*) +1\) and thus the conclusion follows. \(\square \)
5.2 Energy Landscape Analysis for Open Grid Graphs (Proof of Theorem 5.2)
We now prove Theorem 5.2 valid for the open grid graph \(G_{K,L}\). Also in this case, we assume without loss of generality that \(K \le L\). Recall that K and L are positive integers, not necessarily even as in the previous subsection. In the remainder of the section we will write \(\mathcal {X}\) instead of \(\mathcal {X}_{G_{K,L}}\).
We first introduce a modification of the previous reduction algorithm tailored for open grids. The scope of this reduction algorithm is twofold. It is used first to build a specific path in \(\mathcal {X}\) from any given state in \(\mathcal {X}\setminus \{ {\mathbf {e}},{\mathbf {o}}\}\) to the subset \(\{{\mathbf {e}},{\mathbf {o}}\}\) and to prove that if \(KL \equiv 0 \pmod 2\), then
which is Theorem 5.2(i). The same argument also shows that if \(KL \equiv 1 \pmod 2\), then
and also Theorem 5.2(iii) is proved. By giving a lower bound on the energy wastage along every path \({\mathbf {e}}\rightarrow {\mathbf {o}}\), we show in Proposition 5.9 that
Then, using again the reduction algorithm for open grids, we construct a reference path \(\omega ^*: {\mathbf {e}}\rightarrow {\mathbf {o}}\) which proves that the lower bound above is sharp and hence
In the special case \(KL \equiv 1 \pmod 2\), since \(\Phi ({\mathbf {o}},{\mathbf {e}})=\Phi ({\mathbf {e}},{\mathbf {o}})\) and \(H({\mathbf {o}})=H({\mathbf {e}})+1\), we can easily derive from the last equality that
Lastly, we combine inequality (77) and equation (79) to obtain
which concludes the proof of Theorem 5.2(ii). In the special case \(KL \equiv 1 \pmod 2\), inequality (78) and Eq. (80) prove Theorem 5.2(iv), since they yield that
We need one additional definition: Say that a configuration in \(\mathcal {X}\) displays an odd (even) vertical double bridge if there exists at least one vertical stripe \(S_i\) in which configuration \(\sigma \) perfectly agrees with \({\mathbf {o}}\) (respectively \({\mathbf {e}}\)), i.e., if there exists an index \(1 \le j \le \lfloor L/2 \rfloor \) such that
An odd (even) horizontal double bridge is defined analogously. The two types of double bridges are illustrated in Fig. 9.
Observe that an admissible configuration on the open grid has zero energy wastage in a horizontal (vertical) stripe if and only if it has an odd or even horizontal (vertical) bridge in that stripe. The next lemma formalizes this property. We give the statement and the proof only for horizontal stripes, since those for vertical stripes are analogous. In the special case of an open grid where \(KL \equiv 1 \pmod 2\), the topmost row and the leftmost column need special treatment, since they do not belong to any stripe. The second part of the following lemma shows that an admissible configuration has zero energy wastage in that row/column if and only if they agree perfectly with \({\mathbf {e}}\) therein. Again we will state and prove the result for the topmost row, the result for the leftmost column is analogous.

Examples of configurations on the \(8 \times 8\) open grid graph displaying an odd double bridge. a Odd horizontal double bridge, b odd vertical double bridges
Lemma 5.8
(Energy efficient stripes are double bridges) Consider a configuration \(\sigma \in \mathcal {X}\).
-
(i)
For any \(i = 0, \ldots , \lfloor K /2 \rfloor -1\), the energy wastage \(U^S_i(\sigma )\) in horizontal stripe \(S_i\) satisfies
$$\begin{aligned} U^S_i(\sigma )=0 \; \Longleftrightarrow \; \sigma _{|S_i}={\mathbf {e}}_{|S_i}\; \mathrm {or} \; \sigma _{|S_i}={\mathbf {o}}_{|S_i}. \end{aligned}$$ -
(ii)
If additionally \(KL \equiv 1 \pmod 2\), then the energy wastage in the topmost row \(U_{K-1}(\sigma )\) satisfies
$$\begin{aligned} U_{K-1}(\sigma )=0 \; \Longleftrightarrow \; \sigma _{|r_{K-1}}={\mathbf {e}}_{|r_{K-1}}. \end{aligned}$$
Proof
We prove statement (i) first. Consider the \(2 \times L\) grid graph induced by the horizontal stripe \(S_i\): It has L even sites and L odd sites. If \(\sigma _{|S_i}={\mathbf {e}}_{|S_i}\) or \(\sigma _{|S_i}={\mathbf {o}}_{|S_i}\), trivially \(U^S_i(\sigma )=0\). Let us prove the converse implication. Denote by \(e_t\) (\(e_b\)) the number of particles present in even sites in the top (bottom) row of stripe \(S_i\). Analogously, define \(o_t\) (\(o_b\)) as the number of particles present in odd sites in the top (bottom) row of stripe \(S_i\). We will show that:
-
(1)
\(U^S_i(\sigma )=0\) and \(e_t+e_b=0\) \(\Longleftrightarrow \) \(o_t+o_b=L\);
-
(2)
\(U^S_i(\sigma )=0\) and \(e_t+e_b>0\) \(\Longleftrightarrow \) \(o_t+o_b=L\).
Statements (1) and (2 \(\Leftarrow \)) are immediate. Thus we focus on the implication (2 \(\Rightarrow \)).
Note that if \(e_t+e_b \in [1, L -1]\) particles are present in even sites, then they block at least \(e_t+e_b +1\) odd sites, which must then be unoccupied. Indeed in the top row each of the \(e_t\) particles blocks the odd node at its right and in the bottom row each of the \(e_b\) particles blocks the odd node at its left. In one of the two rows, say the top one, there is at least one even unoccupied site and consider the even site at its right where a particle resides. This particle blocks also the odd site at its left. Hence \(o_t+o_b \le L-(e_t+e_b+1)\), which gives \(U^S_i(\sigma ) = L - (e_t+e_b+o_t+o_b) >0\).
We now turn to the proof of statement (ii). The topmost row has \(\frac{L+1}{2}\) even sites and \(\frac{L-1}{2}\) odd sites. Denote by \(e\) (respectively \(o\)) the number of particles present in even (respectively odd) sites in row \(r_{K-1}\). The energy wastage of \(\sigma \) on this row can be computed as \(U_{K-1}(\sigma )=\frac{L+1}{2}-e-o\). Trivially, if \(\sigma _{|r_{K-1}}={\mathbf {e}}_{|r_{K-1}}\), then \(e=\frac{L+1}{2}\) and thus \(U_{K-1}(\sigma )=0\). Let us prove the opposite implication. Assume that \(\sigma _{|r_{K-1}} \ne {\mathbf {e}}_{|r_{K-1}}\), i.e., \(e<\frac{L+1}{2}\). If \(e=0\), then \(U_{K-1}(\sigma )\ge 1\), since \(o\le \frac{L-1}{2}\). If instead \(e\in [1,\frac{L+1}{2}-1]\), then each particle residing in an even site blocks the odd site at its left, therefore \(o\le \frac{L-1}{2} - e\), which implies
\(\square \)
5.2.1 Reduction Algorithm for Open Grids
We now describe the reduction algorithm for open grids, which is a modification of the reduction algorithm for toric grids that builds a path \(\omega \) in \(\mathcal {X}\) from a given initial configuration \(\sigma \) to either \({\mathbf {o}}\) or \({\mathbf {e}}\). The reduction algorithm for open grids takes two inputs instead of one: The initial configuration \(\sigma \) and the target state which is either \({\mathbf {o}}\) or \({\mathbf {e}}\). This is the first crucial difference with the corresponding algorithm for toric grid, where the target configuration was always \({\mathbf {o}}\). In the following, we first assume that the target state is \({\mathbf {o}}\) and illustrate the procedure in this case. The necessary modifications when the target state is \({\mathbf {e}}\) are presented later.
The initial configuration \(\sigma \) for the reduction algorithm must be such that there are no particles in the even sites of the first column \(c_0\), i.e.,
This condition ensures that the algorithm has enough “room” to work properly. Note that condition (81) is different from condition (75) for the reduction algorithm for toric grids, which requires instead that the even sites of both the first two columns \(c_0\) and \(c_1\) should be empty.
The path \(\omega \) is the concatenation of L paths \(\omega ^{(1)}, \ldots ,\omega ^{(L)}\). Path \(\omega ^{(j)}\) goes from \(\sigma _{j}\) to \(\sigma _{j+1}\), where we set \(\sigma _1=\sigma \) and recursively define for \(j=1, \ldots , L\) as
This procedure guarantees that \(\sigma _{L+1}={\mathbf {o}}\). The path \(\omega ^{(j)}\) for \(j=1,\ldots ,L\) is constructed exactly as the path \(\omega ^{(j)}\) for the reduction algorithm for toric grids. Since their construction is identical, every path \(\omega ^{(j)}\) enjoys the same properties as those of the original reduction algorithm, namely
This means that the path \(\omega : \sigma \rightarrow {\mathbf {o}}\) created by their concatenation satisfies
In the scenario where the target state is \({\mathbf {e}}\), three modifications are needed. First the initial state \(\sigma \) must be such that there are no particles in the odd sites of the first column \(c_0\), i.e.,
Secondly, the sequence of intermediate configurations \(\sigma _j\), \(j=1,\ldots , L\) must be modified as follows: We set \(\sigma _1=\sigma \) and we define recursively \(\sigma _{j+1}\) from \(\sigma _{j}\) as
Lastly, for step i of path \(\omega ^{(j)}\), we need a different offset to select the site v, namely \(v=(j,i+(j \pmod 2))\) when \(i \equiv 0 \pmod 2\) and \(v=(j,i-1+(j \pmod 2))\) when \(i \equiv 1 \pmod 2\). One can check that the resulting path \(\omega : \sigma \rightarrow {\mathbf {e}}\) satisfies the inequality
Proof of Theorem 5.2 (i) and (ii)
It is enough to prove that for every \(\sigma \in \mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}\)
Indeed, this claim, together with the equivalent characterization of \(\widetilde{\Gamma }\) given in Lemma 3.6, proves simultaneously inequality (77) when \(KL \equiv 0 \pmod 2\) and the strict inequality (78) when \(KL \equiv 1 \pmod 2\), since in this case \( \lfloor K/2 \rfloor < \lceil K/2 \rceil \). To prove such an inequality, we have to exhibit for every \(\sigma \in \mathcal {X}\setminus \{{\mathbf {e}},{\mathbf {o}}\}\) a path \(\omega : \sigma \rightarrow \{{\mathbf {e}},{\mathbf {o}}\}\) in \(\mathcal {X}\) such that \(\Phi _{\omega }=\max _{\eta \in \omega } H(\eta ) \le H(\sigma )+\lfloor K/2 \rfloor \).
Let b be the number of particles present in configuration \(\sigma \) in the odd sites of the leftmost column of \(\Lambda \), i.e.,
Every column in \(\Lambda \) has \(\lfloor K/2 \rfloor \) odd sites, and hence \( 0 \le b \le \lfloor K/2 \rfloor \). Differently from the proof of Theorem 5.1(i), here the value of b determines how the path \(\omega \) will be constructed. We distinguish two cases: (a) \(b = \lfloor K/2 \rfloor \) and (b) \(b < \lfloor K/2 \rfloor \).
-
(a)
Assume that \(b = \lfloor K/2 \rfloor \). In this case, we construct a path \(\omega : \sigma \rightarrow {\mathbf {o}}\) by means of the reduction algorithm for open grids, choosing as initial configuration \(\sigma \) and as target configuration \({\mathbf {o}}\). The way this path is built guarantees that \(\Phi _{\omega } \le H(\sigma ) + 1\), which implies that
$$\begin{aligned} \Phi (\sigma ,{\mathbf {o}})-H(\sigma ) = 1 \le \lfloor K/2 \rfloor . \end{aligned}$$ -
(b)
Assume that \(b < \lfloor K/2 \rfloor \). In this case we create a path \(\omega : \sigma \rightarrow {\mathbf {e}}\) as the concatenation of two shorter paths, \(\omega ^{(1)}\) and \(\omega ^{(2)}\), where \(\omega ^{(1)}: \sigma \rightarrow \sigma '\), \(\omega ^{(2)}: \sigma ' \rightarrow {\mathbf {e}}\) and \(\sigma '\) is a suitable configuration which depends on \(\sigma \) (see definition below). The reason why \(\omega \) is best described as concatenation of two shorter paths is the following: Since \(b < \lfloor K/2 \rfloor \), the reduction algorithm can not be started directly from \(\sigma \) and the path \(\omega ^{(1)}\) indeed leads from \(\sigma \) to \(\sigma '\), which is a suitable configuration to initialize the reduction algorithm for open grids. The configuration \(\sigma '\) differs from \(\sigma \) only in the odd sites of the first column, that is
$$\begin{aligned} \sigma '(v):= {\left\{ \begin{array}{ll} \sigma (v) &{}\quad \text { if } v \in \Lambda \setminus (c_0 \cap V_o),\\ 0 &{}\quad \text { if } v \in c_0 \cap V_o. \end{array}\right. } \end{aligned}$$The path \(\omega ^{(1)}=(\omega ^{(1)}_{1},\ldots ,\omega ^{(1)}_{b+1})\), with \(\omega ^{(1)}_{1}=\sigma \) and \(\omega ^{(1)}_{b+1}=\sigma '\), can be constructed as follows. For \(i=1,\ldots ,b\), at step i we remove from configuration \(\omega ^{(1)}_{i}\) the topmost particle in \(c_0 \cap V_o\) increasing the energy by 1 and obtaining in this way configuration \(\omega ^{(1)}_{i+1}\). Therefore the configuration \(\sigma '\) is such that \(H(\sigma ')-H(\sigma ) = b\) and
$$\begin{aligned} \Phi _{\omega ^{(1)}} = \max _{\eta \in \omega ^{(1)}} H(\eta ) \le H(\sigma )+b. \end{aligned}$$The path \(\omega ^{(2)}: \sigma ' \rightarrow {\mathbf {e}}\) is then constructed by means of the reduction algorithm for open grids described earlier, using \(\sigma '\) as initial configuration and \({\mathbf {e}}\) as target configuration. The reduction algorithm guarantees that
$$\begin{aligned} \Phi _{\omega ^{(2)}} = \max _{\eta \in \omega ^{(2)}} H(\eta ) \le H\left( \sigma '\right) + 1. \end{aligned}$$The concatenation of the two paths \(\omega ^{(1)}\) and \(\omega ^{(2)}\) gives a path \(\omega : \sigma \rightarrow {\mathbf {e}}\) which satisfies the inequality \(\Phi _{\omega } \le H(\sigma )+ b + 1\) and therefore
$$\begin{aligned} \Phi (\sigma ,{\mathbf {e}})-H(\sigma ) = b+1 \le \lfloor K/2 \rfloor . \end{aligned}$$
\(\square \)
Proposition 5.9
(Lower bound for \(\Phi ({\mathbf {e}},{\mathbf {o}})\)) Consider the \(K \times L\) open grid graph \(G_{K,L}\) with \(K \le L\). The communication height between \({\mathbf {e}}\) and \({\mathbf {o}}\) in the corresponding energy landscape satisfies
Proof
It is enough to show that in every path \(\omega : {\mathbf {e}}\rightarrow {\mathbf {o}}\) there is at least one configuration with energy wastage greater than or equal to \(\lceil K/2 \rceil +1\). Take a path \(\omega =(\omega _1,\ldots , \omega _n) \in \Omega _{{\mathbf {e}},{\mathbf {o}}}\). Without loss of generality, we may assume that there are no void moves in \(\omega \), i.e., at every step either a particle is added or a particle is removed, so that \(H(\omega _{i+1}) = H(\omega _{i}) \pm 1\) for every \(i =1,\ldots ,n-1\). Since \({\mathbf {e}}\) does not have an odd bridge while \({\mathbf {o}}\) does, at some point along the path \(\omega \) there must be a configuration \(\omega _{m^*}\) which is the first to display an odd bridge, horizontal or vertical, or both simultaneously. In symbols
Clearly \(m^*>2\). We claim that \(U(\omega _{m^*-1}) \ge \lceil K/2 \rceil +1\) or \(U(\omega _{m^*-2}) \ge \lceil L/2 \rceil +1\). We distinguish the following three cases:
-
(a)
\(\omega _{m^*}\) displays an odd vertical bridge only;
-
(b)
\(\omega _{m^*}\) displays an odd horizontal bridge only;
-
(c)
\(\omega _{m^*}\) displays an odd cross.
These three cases cover all possibilities, since the addition of a single particle cannot create more than one bridge in each direction. Let \(v^* \in \Lambda \) be the unique site where configuration \(\omega _{m^*-1}\) and \(\omega _{m^*}\) differ.
For case (a), assume first that \(v^*\) belong to the \(i^*\)th horizontal stripe, i.e., \(v^* \in S_{i^*}\) for some \(0 \le i^*\le \lfloor K/2 \rfloor -1\). By construction, \(v^*\) must be an odd site and \(\omega _{m^*-1}(v^*) = 0\) and \(\omega _{m^*}(v^*)=1\) and thus \(U^S_{i^*}(\omega _{m^*-1}) \ge 1\). We claim that in fact
It is enough to show that \(U^S_{i^*}(\omega _{m^*-1}) \ne 1\). Suppose by contradiction that \(U^S_{i^*}(\omega _{m^*-1}) =1\), then it must be the case that \(U^S_{i^*}(\omega _{m^*}) =0\), due the addition of a particle in \(v^*\), and by Lemma 5.8 the horizontal stripe \(S_{i^*}\) must agree fully with \({\mathbf {o}}\) (\(\omega _{m^*}\ne {\mathbf {e}}\), since it has a particle residing in \(v^*\) which is an odd site). This fact would imply that \(\omega _{m^*}\) has an odd horizontal bridge, which contradicts our assumption for case (a).
Assume instead that K is odd and that \(v^*\) does not belong to any horizontal stripe and belongs instead to the topmost row, i.e., \(v^* \in r_{K-1}\). By construction, \(v^*\) must be an odd site and \(\omega _{m^*-1}(v^*) = 0\) and \(\omega _{m^*}(v^*)=1\) and thus \(U_{K-1}(\omega _{m^*-1}) \ge 1\). We claim that in fact
It is enough to show that \(U_{K-1}(\omega _{m^*-1}) \ne 1\). Suppose by contradiction that \(U_{K-1}(\omega _{m^*-1}) =1\), then it must be \(U_{K-1}(\omega _{m^*}) =0\), due to the addition of a particle in \(v^*\). By Lemma 5.8 \(\omega _{m^*}\) must agree fully with \({\mathbf {e}}\) on this topmost row, but this cannot be the case since \(\omega _{m^*}\) has a particle residing in \(v^*\) which is an odd site.
Moreover, we claim that the energy wastage in every horizontal stripe that does not contain site \(v^*\) (and in the topmost row if \(KL \equiv 1 \pmod 2\) and \(v^* \not \in r_{K-1}\)) is also greater than or equal to 1. Indeed, configuration \(\omega _{m^*-1}\) cannot display any horizontal odd bridge (by definition of \(i^*\)) and neither a horizontal even bridge, since \(\omega _{m^*-1}(v^*+(1,0)) = 0\) and \(\omega _{m^*-1}(v^*+(-1,0)) = 0\). Therefore for every \(i=1,\ldots ,\lfloor K/2 \rfloor \) such that \(v^* \not \in S_j\) we have \((\omega _{m^*})_{|S_i} \ne {\mathbf {o}}_{|S_i}, {\mathbf {e}}_{|S_i}\) and hence, by Lemma 5.8
If K is odd, then the topmost row \(r_{K-1}\) cannot be a horizontal odd bridge (our assumption would be violated) and neither a horizontal even bridge (it would be impossible to obtain the horizontal odd bridge which \(\omega _{m^*}\) has in a single step, the minimum number of steps needed is two). Therefore, by Lemma 5.8,
There are three possible scenarios:
-
K even: There are \(K/2-1\) horizontal stripes with positive energy wastage and \(U^S_{i^*}(\omega _{m^*-1}) \ge 2\);
-
K odd and \(v^* \not \in r_{K-1}\): There are \(\lfloor K/2 \rfloor -2\) horizontal stripes with positive energy wastage, \(U_{K-1}(\omega _{m^*-1}) \ge 1\) and \(U^S_{i^*}(\omega _{m^*-1}) \ge 2\);
-
K odd and \(v^* \in r_{K-1}\): There are \(\lfloor K/2 \rfloor -1\) horizontal stripes with positive energy wastage and \(U_{K-1}(\omega _{m^*-1}) \ge 2\).
In all three scenarios, by summing the energy wastage of the horizontal stripes (and possibly that of the topmost row) we obtain
For case (b) we can argue in a similar way, but interchanging the roles of rows and columns, and obtain that
For case (c), the vertical and horizontal odd bridges that \(\omega _{m^*}\) has, must necessarily meet in the odd site \(v^*\). Having an odd cross, \(\omega _{m^*}\) cannot display any horizontal or vertical even bridge. Consider the previous configuration \(\omega _{m^*-1}\) along the path \(\omega \), which can be obtained from \(\omega _{m^*}\) by removing the particle in \(v^*\). From these considerations and from the definition of \(m^*\) it follows that \(\omega _{m^*-1}\) has no vertical bridge (neither odd or even) and thus, by Lemma 5.8, it has energy wastage at least one in each of the \(\lfloor L/2 \rfloor \) vertical stripes and possibly in the leftmost column, if L is odd. In both cases, we have
If there is at least one column in which \(\omega _{m^*-1}\) has energy wastage strictly greater than one, then the proof is concluded, since
Consider now the other scenario, in which the configuration \(\omega _{m^*-1}\) has energy wastage exactly one in every vertical stripe (and possibly in the leftmost column, if L is odd), which means \(U(\omega _{m^*-1}) = \lceil L/2 \rceil \). Consider its predecessor in the path \(\omega \), namely the configuration \(\omega _{m^*-2}\). We claim that
Indeed, by construction, configuration \(\omega _{m^*-2}\) must differ in exactly one site from \(\omega _{m^*-1}\) and therefore
Consider the case where \(U(\omega _{m^*-2}) = U(\omega _{m^*-1})-1 = \lceil L/2 \rceil -1\). In this case the configuration \(\omega _{m^*-2}\) must have a zero-energy-wastage vertical stripe and by Lemma 5.8 it would be a vertical double bridge. If it was a vertical odd double bridge, the definition of \(m^*\) would be violated. If it was an even vertical double bridge, it would be impossible to obtain the horizontal odd bridge (which \(\omega _{m^*}\) has) in just two single-site updates, since three is the minimum number of single-site updates needed. Therefore
\(\square \)
The lower bound for the communication height \(\Phi ({\mathbf {e}},{\mathbf {o}})\) we just proved is sharp, as established by the next proposition in which a reference path from \({\mathbf {e}}\) to \({\mathbf {o}}\) is constructed.
Proposition 5.10
(Reference path) There exists a path \(\omega ^*:{\mathbf {e}}\rightarrow {\mathbf {o}}\) in \(\mathcal {X}_{G_{K,L}}\) such that
Proof
We describe just briefly how the reference path \(\omega ^*\) is constructed, since it is very similar to the one given in the proof of Proposition 5.7. Also in this case, the path \(\omega ^*\) is the concatenation of two shorter paths, \(\omega ^{(1)}\) and \(\omega ^{(2)}\), where \(\omega ^{(1)}: {\mathbf {e}}\rightarrow \sigma ^*\) and \(\omega ^{(2)}: \sigma ^* \rightarrow {\mathbf {o}}\), where \(\sigma ^*\) is the configuration that differs from \({\mathbf {e}}\) only in the even sites of the leftmost column:
The path \(\omega ^{(1)}\) consists of \(\lceil K/2 \rceil \) steps, at each of which we remove the first particle in \(c_0 \cap V_e\) in lexicographic order from the previous configuration. The last configuration is precisely \(\sigma ^*\), which has energy \(H(\sigma ^*)=H({\mathbf {e}})+ \lceil K/2 \rceil \), and, trivially, \(\Phi _{\omega ^{(1)}} = H({\mathbf {e}})+ \lceil K/2 \rceil \). The second path \(\omega ^{(2)}: \sigma ^* \rightarrow {\mathbf {o}}\) is then constructed by means of the reduction algorithm, which can be used since configuration \(\sigma ^*\) is a suitable initial configuration for it, satisfying condition (81). The algorithm guarantees that \(\Phi _{\omega ^{(2)}} = H(\sigma ^*) +1\) and thus the concatenation of the two paths \(\omega ^{(1)}\) and \(\omega ^{(2)}\) yields a path \(\omega ^*\) with \(\Phi _{\omega ^*} = \max _{\eta \in \omega } H(\eta ) = H({\mathbf {e}}) + \lceil K/2 \rceil +1\) as desired. \(\square \)
The statements (ii) and (iv) of Theorem 5.2 can then be easily obtained from Propositions 5.9 and 5.10, as illustrated at the beginning of Sect. 5.2.
5.3 Energy Landscape Analysis for Cylindrical Grid Graphs (Proof of Theorem 5.3)
In this subsection we briefly describe how to proceed to prove Theorem 5.3. The cylindrical grid graph \(C_{K,L}\) is a hybrid between the toric grid and the open grid graphs, since the columns of \(C_{K,L}\) have the same structure as the columns of the toric grid \(T_{K,L}\), while the horizontal stripes of \(C_{K,L}\) enjoy the same structural properties of those of the open grid \(G_{K,L}\). Along the lines of Lemmas 5.5 and 5.8 we can prove that the only columns with zero energy wastage are vertical bridges and the only horizontal stripes with zero energy wastage are horizontal double bridges.
In order to prove that
one can argue in a similar way as was done for the other two types of grids. Also for the cylindrical grid, in any path \(\omega : {\mathbf {e}}\rightarrow {\mathbf {o}}\) there must be a configuration \(\omega _{m^*}\) which is the first to display a horizontal odd bridge or a vertical odd bridge or both simultaneously, i.e.,
One can prove that
We distinguish two cases, depending on whether \(K/2 \ge L\) or \(K/2 < L\). In these two cases, the proof can be obtained by studying the energy wastage either in the columns or in the horizontal stripes, in the same spirit as for the toric and open grids in Sects. 5.1 and 5.2, respectively. Moreover, depending on whether \(K/2 \ge L\) or \(K/2 < L\), we can take the reference path \(\omega ^*\) to be the same as in Sects. 5.1 and 5.2, respectively. Lastly, one can show that
by exploiting what has been done in Sect. 5.1, if \(K/2 \ge L\), and the strategy adopted in Sect. 5.2, otherwise.
6 Conclusions
We have studied the first hitting times between maximum-occupancy configurations and mixing times for the hard-core interaction of particles on grid graphs. In order to do so, we extended the framework [31] for reversible Metropolis Markov chains. We expect that similar results for the first hitting time \(\tau ^x_{A}\) with a general initial state x and target subset A can be proved for irreversible Markov chains that satisfy the Friedlin-Wentzell condition (15). Furthermore, we developed a novel combinatorial method for grid graphs, valid for various boundary conditions, which shows that the energy landscape corresponding to hard-core dynamics on grid graphs has no deep cycles and yields the minimum energy barrier between the two chessboard configurations \({\mathbf {e}}\) and \({\mathbf {o}}\). We obtained in this way results for the asymptotic behavior of the first hitting time \(\tau ^{\mathbf {e}}_{\mathbf {o}}\) in the low-temperature regime. We expect that our combinatorial approach can be exploited to prove similar results for other graphs which can be embedded in a grid graph (e.g. triangular or hexagonal lattice) or for the hard-core model where there are two or more types of particles and the hard-core constraints exist only between particles of different type. As mentioned earlier, the study of the critical configurations and of the minimal gates along the transition from \({\mathbf {e}}\) to \({\mathbf {o}}\) was beyond the scope of this paper and will be the focus of future work.
References
Beltrán, J., Landim, C.: Tunneling and metastability of continuous time Markov chains. J. Stat. Phys. 140(6), 1065–1114 (2010)
Beltrán, J., Landim, C.: Metastability of reversible finite state Markov processes. Stoch. Process. Appl. 121(8), 1633–1677 (2011)
Benois, O., Landim, C., Mourragui, M.: Hitting times of rare events in Markov chains. J. Stat. Phys. 153(6), 967–990 (2013)
Borgs, C., Chayes, J.T., Frieze, A., Tetali, P., Vigoda, E., Van, H.V.: Torpid mixing of some Monte Carlo Markov chain algorithms in statistical physics. In: 40th Annual Symposium on Foundations of Computer Science, 1999, pp. 218–229 (1999)
Bovier, A., Eckhoff, M., Gayrard, V., Klein, M.: Metastability and low lying spectra in reversible Markov chains. Commun. Math. Phys. 228(2), 219–255 (2002)
Bovier, A., Eckhoff, M., Gayrard, V., Klein, M.: Metastability in reversible diffusion processes I. Sharp asymptotics for capacities and exit times. J. Eur. Math. Soc. 6(4), 399–424 (2004)
Bovier, A., Gayrard, V., Klein, M.: Metastability in reversible diffusion processes II: precise asymptotics for small eigenvalues. J. Eur. Math. Soc. 7(1), 69–99 (2005)
Cassandro, M., Galves, A., Olivieri, E., Vares, M.E.: Metastable behavior of stochastic dynamics: a pathwise approach. J. Stat. Phys. 35(5–6), 603–634 (1984)
Catoni, O.: Sharpe large deviations estimates for simulated annealing algorithms. Ann. Inst. Henri Poincaré 27(3), 291–383 (1991)
Catoni, O.: Rough large deviation estimates for simulated annealing: application to exponential schedules. Ann. Probab. 20(3), 1109–1146 (1992)
Catoni, O.: Simulated annealing algorithms and Markov chains with rare transitions. In: Séminaire de probabilités XXXIII. Volume 1709 of Lecture Notes in Mathematics, pp. 69–119. Springer, Berlin (1999)
Catoni, O., Cerf, R.: The exit path of a Markov chain with rare transitions. ESAIM Probab. Stat. 1, 95–144 (1997)
Catoni, O., Trouvé, A.: Parallel Annealing by Multiple Trials: A Mathematical Study. Simulated Annealing: Parallelization Techniques, pp. 129–144. Wiley, New York (1992)
Cirillo, E.N.M., Nardi, F.R.: Metastability for a stochastic dynamics with a parallel heat bath updating rule. J. Stat. Phys. 110(1–2), 183–217 (2003)
Cirillo, E.N.M., Nardi, F.R.: Relaxation height in energy landscapes: an application to multiple metastable states. J. Stat. Phys. 150(6), 1080–1114 (2013)
Cirillo, E.N.M., Nardi, F.R., Sohier, J.: A comparison between different cycle decompositions for Metropolis dynamics (2014). arXiv:1401.3522
Cirillo, E.N.M., Nardi, F.R., Sohier, J.: Metastability for general dynamics with rare transitions: escape time and critical configurations. J. Stat. Phys. (2015)
Cirillo, E.N.M., Nardi, F.R., Spitoni, C.: Metastability for reversible probabilistic cellular automata with self-interaction. J. Stat. Phys. 132(3), 431–471 (2008)
den Hollander, F., Nardi, F.R., Olivieri, E., Scoppola, E.: Droplet growth for three-dimensional Kawasaki dynamics. Probab. Theory Relat. Fields 125(2), 153–194 (2003)
den Hollander, F., Olivieri, E., Scoppola, E.: Metastability and nucleation for conservative dynamics. J. Math. Phys. 41(3), 1424 (2000)
Fernandez, R., Manzo, F., Nardi, F.R., Scoppola, E.: Asymptotically exponential hitting times and metastability: a pathwise approach without reversibility (2014). arXiv:1406.2637v1
Galvin, D.: Independent Sets in the Discrete Hypercube. Available on the Author’s Web Page, pp. 1–16 (2006)
Galvin, D.: Sampling independent sets in the discrete torus. Random Struct. Algorithms 33(3), 356–376 (2008)
Galvin, D., Tetali, P.: Slow mixing of Glauber dynamics for the hard-core model on regular bipartite graphs. Random Struct. Algorithms 28(4), 427–443 (2006)
Gaunt, D.S., Fisher, M.E.: Hard-sphere lattice gases. I. Plane-square lattice. J. Chem. Phys. 43(8), 2840–2863 (1965)
Holley, R.A., Stroock, D.W.: Simulated annealing via Sobolev inequalities. Commun. Math. Phys. 115(4), 553–569 (1988)
Kelly, F.P.: Loss networks. Ann. Appl. Probab. 1(3), 319–378 (1991)
Kotecký, R., Olivieri, E.: Droplet dynamics for asymmetric Ising model. J. Stat. Phys. 70(5–6), 1121–1148 (1993)
Lee, C.-H., Eun, D.Y., Yun, S.-Y., Yi, Y.: From glauber dynamics to metropolis algorithm: smaller delay in optimal CSMA. In: 2012 IEEE International Symposium on Information Theory (ISIT) Proceedings, pp. 2681–2685. IEEE (2012)
Levin, D.A., Peres, Y., Wilmer, E.L.: Markov Chains and Mixing Times. AMS, Providence (2009)
Manzo, F., Nardi, F.R., Olivieri, E., Scoppola, E.: On the essential features of metastability: tunnelling time and critical configurations. J. Stat. Phys. 115(1/2), 591–642 (2004)
Miclo, L.: About relaxation time of finite generalized Metropolis algorithms. Ann. Appl. Probab. 12(4), 1492–1515 (2002)
Nardi, F.R., Olivieri, E., Scoppola, E.: Anisotropy effects in nucleation for conservative dynamics. J. Stat. Phys. 119(3–4), 539–595 (2005)
Neves, E.J., Schonmann, R.H.: Critical droplets and metastability for a Glauber dynamics at very low temperatures. Commun. Math. Phys. 137(2), 209–230 (1991)
Olivieri, E., Scoppola, E.: Markov chains with exponentially small transition probabilities: first exit problem from a general domain. I. The reversible case. J. Stat. Phys. 79(3–4), 613–647 (1995)
Olivieri, E., Scoppola, E.: Markov chains with exponentially small transition probabilities: first exit problem from a general domain. II. The general case. J. Stat. Phys. 84(5–6), 987–1041 (1996)
Olivieri, E., Vares, M.E.: Large Deviations and Metastability. CUP, Cambridge (2005)
Randall, D.: Slow mixing of glauber dynamics via topological obstructions. In: Proceedings of SODA ’06, pp. 870–879 (2006)
Scoppola, E.: Renormalization and graph methods for Markov chains. In: Advances in Dynamical Systems and Quantum Physics, pp. 260–281. Capri (1993)
Trouvé, A.: Rough large deviation estimates for the optimal convergence speed exponent of generalized simulated annealing algorithms. Ann. Inst. H. Poincaré Probab. Stat. 32, 299–348 (1994)
van den Berg, J., Steif, J.E.: Percolation and the hard-core lattice gas model. Stoch. Process. Appl. 49(2), 179–197 (1994)
Wang, X., Kar, K.: Throughput modelling and fairness issues in CSMA/CA based ad-hoc networks. In: Proceedings INFOCOM, 2005, pp. 23–34. IEEE (2005)
Zocca, A., Borst, S.C., van Leeuwaarden, J.S.H.: Mixing properties of CSMA networks on partite graphs. In: Proceedings of VALUETOOLS 2012, pp. 117–126. IEEE (2012)
Zocca, A., Borst, S.C., van Leeuwaarden, J.S.H., Nardi, F.R.: Delay performance in random-access grid networks. Perform. Eval. 70(10), 900–915 (2013)
Acknowledgments
A. Zocca wishes to thank J. Sohier for the helpful discussions. F. R. Nardi, A. Zocca and S. C. Borst wish to thank J. S. H. van Leeuwaarden for the helpful discussions and suggestions at the early stages of the work. This work was financially supported by The Netherlands Organization for Scientific Research (NWO) through the TOP-GO Grant 613.001.012.
Author information
Authors and Affiliations
Corresponding author
Rights and permissions
Open Access This article is distributed under the terms of the Creative Commons Attribution 4.0 International License (http://creativecommons.org/licenses/by/4.0/), which permits unrestricted use, distribution, and reproduction in any medium, provided you give appropriate credit to the original author(s) and the source, provide a link to the Creative Commons license, and indicate if changes were made.
About this article

Cite this article
Nardi, F.R., Zocca, A. & Borst, S.C. Hitting Time Asymptotics for Hard-Core Interactions on Grids. J Stat Phys 162, 522–576 (2016). https://doi.org/10.1007/s10955-015-1391-x
Received:
Accepted:
Published:
Issue Date:
DOI: https://doi.org/10.1007/s10955-015-1391-x